 Задача сохранения настроек встречается в подавляющем большинстве современных устройств. Реже, но тоже очень часто, требуется хранение лог-файлов. Если речь идет о большом устройстве построенном на Линукс и содержащей как минимум SD карту, то с этими задачами не возникает проблем. Но если все устройство представляет из себя микроконтроллер, то возникает вопрос, где и в каком виде хранить подобные данные. В этом случае, обычно для настроек предлагают использовать сырые данные размещенные во внешнем eeprom. Но такой подход гораздо менее удобен чем вариант с файловой системой пусть даже с сильно ограниченными свойствами. Кроме того он плохо подходит для задач логирования. В данной статье мы расскажем как можно организовать удобное хранение файлов настроек и лог-файлов во внутренней флеш памяти микроконтроллера.
Задача сохранения настроек встречается в подавляющем большинстве современных устройств. Реже, но тоже очень часто, требуется хранение лог-файлов. Если речь идет о большом устройстве построенном на Линукс и содержащей как минимум SD карту, то с этими задачами не возникает проблем. Но если все устройство представляет из себя микроконтроллер, то возникает вопрос, где и в каком виде хранить подобные данные. В этом случае, обычно для настроек предлагают использовать сырые данные размещенные во внешнем eeprom. Но такой подход гораздо менее удобен чем вариант с файловой системой пусть даже с сильно ограниченными свойствами. Кроме того он плохо подходит для задач логирования. В данной статье мы расскажем как можно организовать удобное хранение файлов настроек и лог-файлов во внутренней флеш памяти микроконтроллера.Простейшая read-only файловая система
Начнем с самого понятия файловой системы. Когда речь заходит о файловой системе, то сразу возникает ощущение чего то большого, а следовательно и имеющего большие накладные расходы. Да, это правда, накладные расходы присутствуют, ведь для описания файлов, хотя бы их имен или идентификаторов, необходимо место. Да, существует проблема достаточно больших накладных расходов при применение универсальных файловых систем. Стремление сделать универсальные файловые менее ресурсоемкими привели к созданию littleFS, но даже она требует 10кб (RAM + ROM), что для микроконтроллера порой избыточно, ведь требуется всего лишь хранить несколько десятков параметров.
Но давайте можно ли ограничив функционал уменьшить накладные расходы?
Конечно можно, ведь файл это просто именованная последовательность упорядоченных данных. Давайте поместим наши параметры в некий блок данных, и присвоим этому блоку имя, и по сути дела получим файл. А теперь давайте сделаем несколько файлов с данными, запакуем их в cpio формат и поместим этот cpio в наше firmware, при этом сохраним адрес начала нашего архива.
Сделать это можно очень просто. Нужен ассемблерный файл в котором бинарные данные помещаются в специальную секцию
.section .rodata.embox.initfs
.incbin CONFIG_ROOTFS_IMAGEИ добавив линкер скрипт
SECTIONS {
.rodata.embox.initfs: {
_initfs_start = .;
*(.rodata.embox.initfs)
_initfs_end = .;
}
}Этого достаточно, теперь мы можем внутри программы ходить по файлам, метки и другие метаданные доступны. Наша файловая система упакована в очень простой формат cpio , который почти не требует накладных расходов. Собственно в Embox мы называем эту файловую систему initfs. Она является полноценной файловой read-only системой в которой доступны как файлы так и папки.
Файлы в этом случае представляют из себя описание файла содержащее имя и адрес начала данных и сами данные. Причем данные это просто массив байт. Аналогично можно представить файл в виде си-массива и включить его в проект при компиляции. Этот метод широко используется например при создании веб-сайтов на базе lwIP. Об преимуществах Embox при создании web-сайтов мы рассказывали в статье.
.
В итоге предлагаемый подход на основе cpio имеет сопоставимые накладные расходы по сравнению с внедрением массива байт, и они меньше по сравнению с littleFS. Что не удивительно, ведь мы создали еще более специализированное решение.
Общие сведения о файловой системе
Прежде чем продолжить нам необходимо сделать небольшое отступление и немного разобраться с общими принципами файловых систем. Ведь когда мы говорим об littleFS, имеют в виду тип файловой системы и драйвер для данного типа. А для того чтобы работать с файлами, потребуется еще несколько понятий. Например индексный дескриптор описывающий открытый файл. Который как минимум должен иметь методы чтения и записи этого файла.
Мы рассмотрим только несколько типов объектов без которых трудно обойтись. Начнем с описателей файла. Есть два типа описаний файла. Первый это описатель представления файла на носителе (inode ). Отмечу, что имя файла хранится не в самом inode, а в записи об этом файле в родительской директории (directory entry (dentry)). dentry хранит имя файла и ссылку на его inode эта информация нужна для поиска файла в файловой системе.
Вторым описателем файла является описатель открытого файла представленный в виде индексного дескриптора. Этот описатель получается с помощью стандартного POSIX вызова open(). Отмечу что объект FILE получаемый с помощью fopen() является описателем потока (stream) а не файла, хотя во многих вещах это одно и тоже. Индексный дескриптор для файла должен как минимум содержать текущую позицию по которой происходит чтение или запись и ссылку на его inode.
Тип файловой системы определяет формат в котором хранятся метаданные и данные в этой файловой системы. Драйвер файловой системы это реализацию функций работы с форматом для данного типа файловой системы, например, упомянутые littleFS и initfs (в Embox) это драйвера файловой системы.
Еще одним важным объектом является описатель файловой системы (superblock). В нем хранится информация о методах работы с файловой системой и ее состояние (например блочное устройство на котором оно работает).
Драйвер initFS
Вернемся к цели нашей статьи файловая система внутри микроконтроллера. Мы уже поняли, что создать удобную read-only файловую систему с очень маленькими накладными расходами возможно. Для удобной работы через привычные open/read/write нам не хватает совсем немного. Например нужно чтобы наш драйвер имел какое то API. Давайте рассмотрим некоторые функции драйвера в Embox, для общего понимания каким может быть это API.
static const struct fs_driver initfs_dumb_driver = {
.name = "initfs",
.fill_sb = initfs_fill_sb,
};
DECLARE_FILE_SYSTEM_DRIVER(initfs_dumb_driver);Определяем сам драйвер. У него есть имя файловой системы и функция заполнения superblock. В драйвере еще могут быть функция форматирования блочного устройства в формате файловой системы и очистка superblock, но у нас read-only файловая система и этого точно не требуется.
Функция заполнения superblock
static int initfs_fill_sb(struct super_block *sb, const char *source) {
struct initfs_file_info *fi;
fi = initfs_alloc_inode();
if (fi == NULL) {
return -ENOMEM;
}
sb->sb_iops = &initfs_iops;
sb->sb_fops = &initfs_fops;
sb->sb_ops = &initfs_sbops;
sb->bdev = NULL;
memset(fi, 0, sizeof(struct initfs_file_info));
inode_priv_set(sb->sb_root, fi);
return 0;
}В ней мы заполняем несколько указателей на различные функции работы с файловой системой. А также выделяем экземпляр структуры inode для данной файловой системы. Выделение нужно поскольку любая файловая система имеет точку монтирования, что тоже является файлом, точнее директорией.
static struct inode_operations initfs_iops = {
.create = initfs_create,
.lookup = initfs_lookup,
.iterate = initfs_iterate,
};Функция сreate() создает новую inode на файловой системе, в нашем случае она просто возвращает ошибку прав доступа. Нам же понадобятся пара функций для операций с inode: lookup функция поиска по имени в заданной папке и iterate — функция для перебора и получения имени всех inode в папке.
int initfs_iterate(struct inode *next, char *name, struct inode *parent, struct dir_ctx *ctx) {
…
}
struct inode *initfs_lookup(char const *name, struct inode const *dir) {
…
}На самом деле, если нужно только open/read/write то без iterate можно было бы попробовать обойтись. По сути дела она используется в readdir, но для красоты реализации (и универсальности конечно) функцию open() лучше выразить через readdir().
Итак функция iterate() получает указатель на новую inode и указатель на имя. Эти данные должны быть заполнены при наличии еще одного файла в папке. Входными параметрами являются inode родительской директории и контекст директории. Контекст директории должен содержать данные идентифицирующие текущий файл который прочитан из директории. Изначально данные пустые (0), а в случае обнаружения файле iterate заполняет контекст директории в соответсвии с прочитанным файлом, чтобы при следующем вызове искать следующий файл.
Функция lookup() ищет файл с указанным именем в директории и в случае обнаружения возвращает указатель на новую inode.
static struct super_block_operations initfs_sbops = {
.open_idesc = dvfs_file_open_idesc,
...
};Из функций superblock интересна open_idesc. Для регулярных файлов она должна выделить объект idesc, тот самый описатель файла по которому будут происходить операции read/write. inode который описывает файл на диске уже заполнен с помощью функции lookup.
struct file_operations initfs_fops = {
.write = initfs_read,
..
};Нам осталось рассмотреть только функции для работы с файлами read/write. write() будет пустой и просто вернет ошибку. Функция read() тоже не сложная:
static size_t initfs_read(struct file_desc *desc, void *buf, size_t size) {
struct initfs_file_info *fi;
off_t pos;
pos = file_get_pos(desc);
fi = file_get_inode_data(desc);
if (pos + size > file_get_size(desc)) {
size = file_get_size(desc) - pos;
}
memcpy(buf, (char *) (uintptr_t) (fi->start_pos + pos), size);
return size;
}
Переставляет текущий курсор и копирует данные в буфер.
Файловая система
Теперь когда у нас есть драйвер в нашей файловой системе, давайте посмотрим что это нам дает и оценим затраты.
Что дает хорошо видно на этом скриншоте.

Мы можем работать с данными размещенными внутри нашего образа, как с обычными файлами. Я вызываю обычную команду ‘ls’ и затем вывожу информацию с помощью обычной команды ‘cat’.
Сколько это стоит? То есть сколько требуется ресурсов для подобное удобство. Оказалось не так уж и много. Я использовал STM32F4-discovery и я сравнил образы с файловой системой и без, оказалось на text + rodata (то есть код и константы в том числе и сами файлы) нужно порядка 8 кБ. При этом я даже не включал оптимизацию. Для RAM потребовалось порядка 700 байт. Откуда они берутся. Нужен объект superblock, и inode для каждой примонтированной файловой системы, Нужны объекты dentry включающие inode для каждой открытой папки и файла. нужен idesc для каждого открытого файла.
Наверное кто то скажет что несколько кБ за read-only файловую систему для микроконтроллера много. Но нужно учитывать что я оценивал всю подсистему, причем вместе с файлами сайта которые занимали пару киллобайт, а не только драйвер. А добавление еще одного драйвера требует гораздо меньше ресурсов (если он простой конечно).
DumbFS
Давайте разработаем драйвер который может работать во внутренней флеш микроконтроллера. Наш драйвер для хранения настроек и лог-файлов, может быть очень простым. Например, нам не нужно хранить атрибуты файлов, мы можем обойтись без директорий, мы даже можем сказать что там нужно только 3 файла ведь на этапе проектирования, мы можем определить какие именно файлы нужны и можем задать их максимальных размер. Максимальный размер для файла может пригодиться, потому что мы сможем сразу отформатировать наше устройство хранение под заданные характеристики, зарезервировав и количество dentry (записей в директориях) и место под каждый файл.
Наш superblock может выглядеть следующим образом:
struct dfs_sb_info {
uint8_t magic[2];
uint8_t inode_count;
uint8_t max_inode_count;
uint32_t max_len;
uint32_t buff_bk; /* For buffer-based writing */
uint32_t free_space;
};Первые два байта это просто идентификатор файловой системы, для проверки что наше устройство хранения отформатировано нужным образом. Далее идут счетчик файлов, на случай если мы хотим не сразу отформатировать все файлы, а все таки иметь возможность создавать как в настоящей файловой системе. Далее идет максимальное количество этих файлов. Оба параметра имеют размер 1 байт, вряд ли нужно хранить больше 255 файлов на подобной системе. Затем идет максимальная длина файла. И дальше пара необязательных параметров. free_space это свободное нераспределенное пространство, хотя его можно вычислить в через inode_count. А buff_bk служит для определения буферизации. Он полезен поскольку во внутренней флешь памяти перед записью нужно стереть целый блок. Этот параметр тоже может быть вычислен и его не обязательно хранить на устройстве.
Далее мы можем сразу разместить записи для директории, она у нас одна поэтому данные могут располагаться сразу за superblock
struct dfs_dir_entry {
uint8_t name[DFS_NAME_LEN];
uint32_t pos_start;
uint32_t len;
uint32_t flags;
};Все просто, первый параметр имя файла. Второй смещение начала данных в устройстве хранения. Третий текущая длина. И четвертый необязательный флаги или атрибуты файла.
Рассмотрим некоторые функции драйвера:
static int dfs_fill_sb(struct super_block *sb, const char *source) {
..
sb->sb_ops = &dfs_sbops;
...
dfs_read_sb_info(dfs_sb()->sb_data);
dfs_read_dirent(0, &dtr);
sb->sb_root->i_no = 0;
sb->sb_root->length = dtr.len;
sb->sb_root->i_data = (void *) ((uintptr_t) dtr.pos_start);
return 0;
}Функция заполнения suberblock похоже на аналогичную в initfs тоже устанавливаем обработчики операций, но так как у нас реальная файловая система нужно считать данные superblock с устройства и еще заполнить inode для корневой папки
Функции iterate и lookup тоже аналогичны initfs, разница только в формате представления dentry.
Поскольку у нас добавилась возможность записи на файловую систему, то необходимо реализовать например функцию itruncate которая изменяет текущий размер файла.
static int dfs_itruncate(struct inode *inode, off_t new_len) {
...
dfs_read_dirent(inode->i_no, &entry);
if (new_len == inode->length) {
/* No need to write changes on drive */
return 0;
}
entry.len = new_len;
dfs_write_dirent(inode->i_no, &entry);
...
}Тут тоже все просто, считываем dentry для файла, меняем текущую длину и записываем.
Самая интересная функция конечно запись, ведь если чтение это просто копирование из определенного адреса (ну или считывание блока и копирование, если флешь все таки внешняя), то запись как известно достаточно сложная операция. Причем записать можно только ячейку которую предварительно стерли. То есть для того чтобы записать какой то блок данных, нужно сохранить (закешировать) блок при этом еще и вместо старых данных записать новые, стереть изначальный блок и записать его новыми данными.
static int dfs_write_raw(int pos, void *buff, size_t size) {
...
dfs_cache_erase(buff_bk);
dfs_cache(CACHE_OFFSET, start_bk * NAND_BLOCK_SIZE, pos);
if (start_bk == last_bk) {
if ((err = dfs_cache_write(CACHE_OFFSET + pos, buff, size))) {
return err;
}
pos += size;
...
dfs_cache(CACHE_OFFSET + pos, last_bk * NAND_BLOCK_SIZE + pos, NAND_BLOCK_SIZE - pos);
dfs_cache_restore(last_bk, buff_bk);
return 0;
}То есть мы сначала чистим ассоциативный кэш, затем копируем в этот кэш данные из блока которые не будут изменены, затем записываем новые данные, и копируем оставшиеся не измененные данные из старого блока. И наконец данные из кэш переносятся обратно в блок данных, перед этим он конечно стирается.
Зачем стирать кэш? Ведь обычно это просто массив данных в RAM размером с блок данных. Но в некоторых микроконтроллерах присутствует достаточно много flash памяти, но RAM ограничена. Пример STM32F4-discovery имеет 1024 кБ flash. Среди них 4 блока по 16кБ которые можно было бы использовать под наши нужды. Но при этом есть всего 128+64кБ ОЗУ. И не всегда есть достаточно памяти чтобы выделить 16 кБ в ОЗУ. Тогда для кэширования можно использовать второй блок по 16КБ.
Наша файловая система почти готова. Осталось только научиться писать в правильные блоки внутренней флешь. То есть нужно выделить несколько блоков памяти и превратить их в блочное устройство. Давайте поступим также как и с cpio архивом. Скажем линкеру зарезервировать соответствующую память.
SECTIONS {
.flash (NOLOAD): ALIGN(STM32_FLASH_SECTOR_SIZE) {
_flash_start = .;
. += STM32_FLASH_FLASH_SIZE;
_flash_end = .;
}
}Операции работать с блочным устройством рассматривать не будем, это выходит за рамки данной статьи.
Собственно все, у нас получилось сделать примитивную файловую систему с ограниченным количеством файлов, без директорий с ограниченной длиной файлов, но перезаписываемую имеющую минимально возможные накладные расходы, и позволяющую разместить ее где угодно, даже в 2 кБ внутренней памяти. (количество файлов и их максимальный размер будут соответствующие).
Результаты работы:
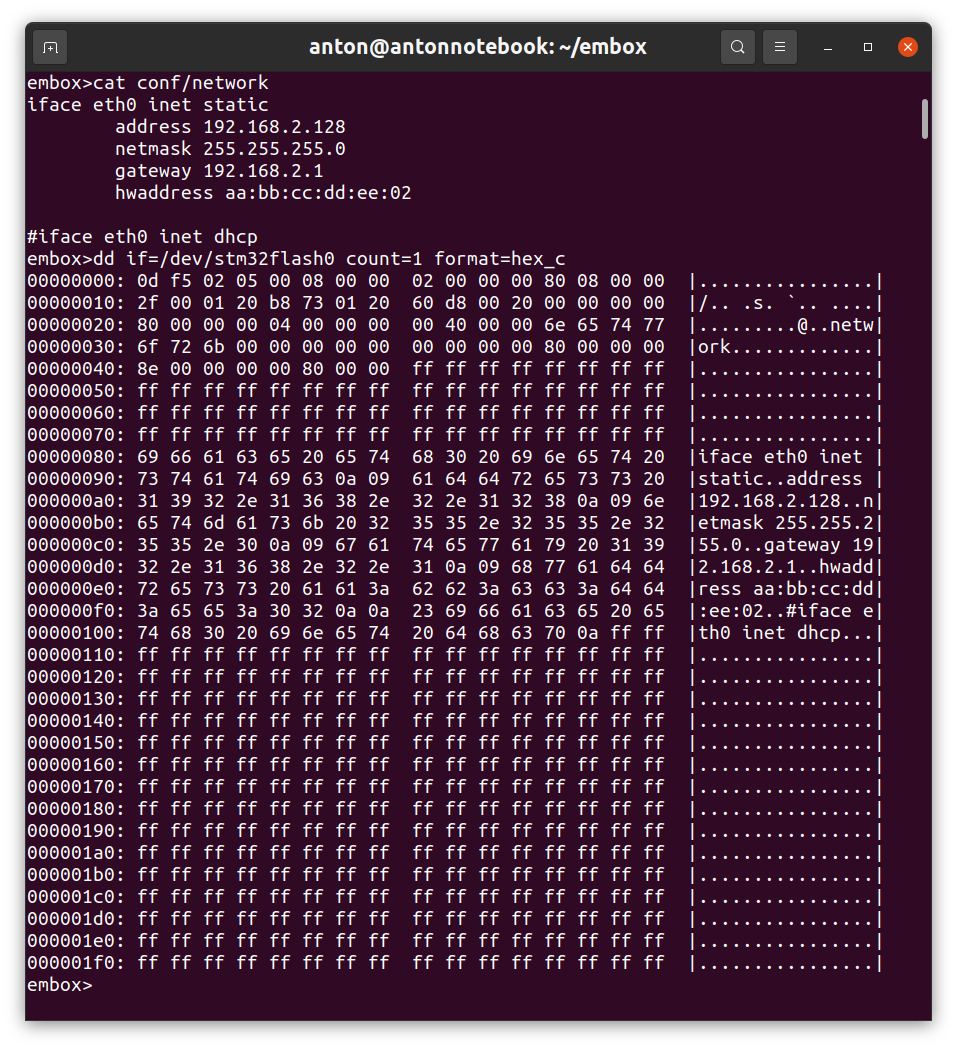
На этом скриншоте виден файл с настройками сети, которые могут быть изменены в процессе работы. А также приведены данные самой файловой системы. Можно увидеть и superblock и dentry и поскольку файл первый содержимое самого файла.
То же самое можно увидеть напрямую в памяти.
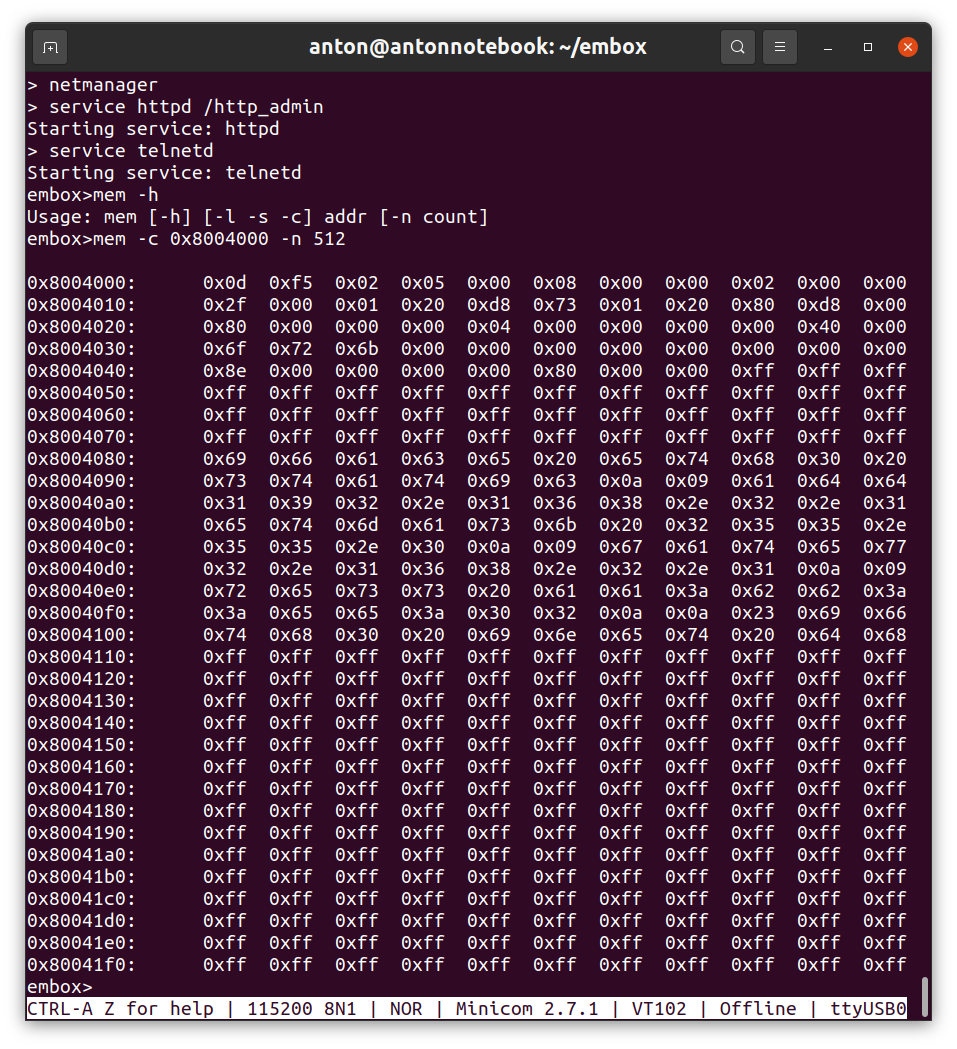
Остается отметить сколько нужно ресурсов. Сам драйвер занимает меньше килобайта, мы его почти весь разобрали. Накладные расходы на RAM, собственно их и нет, точнее они включены в расходы самой файловой системы, нужно иметь superblock и другие объекты, чтобы работать с файлами, но они у нас уже были включены для работы с initfs. Ну и конечно есть код драйвера для работы с flash, сама флешь и кэш буфер для нее. Но все это также нужно и при работе напрямую без файловой системы.
Лог-файлы
С настройками все оказалось более менее просто. Теперь давайте посмотрим как можно организовать лог-файл. Первое, что приходит на ум, это выделить блок и писать туда сообщения по кругу. Для удобства можно сделать сообщения одной длины и добавить счетчик сообщений. Для оптимизации количества перезаписей можно выделить два блока и стирать только один раз на множество записей, когда закончился очередной блок.
Для этого можно создать специальную файловую систему. Но у нас же есть файловая система, а по сути дела лог-файл, это просто файл который записывается по кругу. Таким образом мы можем разработать библиотеку и приложение, которое будет независимым от формата файловой системы, флешь памяти и самого микроконтроллера. Следовательно разрабатывать будет куда проще. Можно даже взять какой нибудь существующий логгер, но я все таки хочу добавить немного специфики. Пусть наш файл будет иметь ограниченное количество записей и записи будут одинакового размера.
Разрабатывать и отлаживать прикладной код можно прямо на Linux, но я это сделаю для Embox и запущу в qemu.
Функционал приложения для работы с лог-файлом следующий. Можно просмотреть весь лог который в него записан. И добавить сообщение в текстовом формате.
Функция печати лога:
static void print_log(void) {
int log_size;
int i;
char *buf;
int mes_size;
mes_size = loop_logger_message_size();
buf = malloc(mes_size + 1);
log_size = loop_logger_size();
for (i = 0; i < log_size; i++) {
memset(buf, 0, mes_size + 1);
loop_logger_read(i, buf, mes_size);
puts(buf);
}
free(buf);
}Функция записи сообщения
static void record_log(char *message) {
loop_logger_write(message);
}Приложение настолько простое что пояснять его не нужно.
Сама библиотека немного сложнее, ведь нам нужно знать откуда текущий указатель для записи сообщения и начала вывода файла. Самое простое это хранить этот указатель в начале файла. Но тогда нам придется его перезаписывать каждый раз при внесении очередного сообщения, а у нас файловая система предназначена для флешь памяти и это не очень хорошо.
Давайте добавим в начало каждой записи маркер. Достаточно иметь всего два состояния, тогда при сканировании файла, мы можем по изменению маркера определить нужный нам индекс лог сообщения. И давайте еще для удобства чтения как простого файла добавим номер сообщения. А количество записей ограничим 256 то есть в 16 разрядном формате нам потребуется два байта.
Таким образом формат нашей записи будет:
<marker><index>:”message”<whitespases>’\n’Функция записи сообщения
int loop_logger_write(char *message) {
int fd;
int start_idx = -1;
int flip;
char tmp_buf[4];
int len;
if (loop_logger_size() < RECORD_QUANTITY) {
start_idx = 0;
}
fd = open(LOGGER_FILE_NAME, O_RDWR);
if (fd < 0) {
return -1;
}
if (start_idx == -1) {
start_idx = find_current_record(fd, &flip);
} else {
start_idx = loop_logger_size();
flip = 0;
}
lseek(fd, start_idx * RECORD_SIZE, SEEK_SET);
memset(loop_logger_buf, 0, RECORD_SIZE);
//snprintf(loop_logger_buf, "%d%02X:%s\n",flip, start_idx,message);
itoa(flip, loop_logger_buf, 10);
itoa(start_idx, tmp_buf, 16);
if (strlen(tmp_buf) == 1) {
strcat(loop_logger_buf,"0");
}
strcat(loop_logger_buf, tmp_buf);
strcat(loop_logger_buf,":");
strncat(loop_logger_buf, message, RECORD_SIZE - 1);
len = strlen(loop_logger_buf);
if (len < (RECORD_SIZE - 1)) {
memset(&loop_logger_buf[len], ' ', (RECORD_SIZE - 1) - len);
}
loop_logger_buf[RECORD_SIZE - 1] = '\n';
write(fd, loop_logger_buf, RECORD_SIZE);
return 0;
}Функция чтения сообщения с индексом:
int loop_logger_read(int idx_mes, char *out_mes, int buf_size) {
int fd;
int start_idx = -1;
if (loop_logger_size() < RECORD_QUANTITY) {
start_idx = 0;
}
fd = open(LOGGER_FILE_NAME, O_RDONLY);
if (fd < 0) {
return -1;
}
if (start_idx == -1) {
int tmp;
start_idx = find_current_record(fd, &tmp);
}
start_idx += idx_mes;
start_idx %= RECORD_QUANTITY;
lseek(fd, start_idx * RECORD_SIZE + 4, SEEK_SET);
read(fd, out_mes, buf_size);
close(fd);
return 0;
}
И функция поиска индекса последнего записанного сообщения:
static int find_current_record(int fd, int *label) {
int res;
int i;
char cur_label;
res = read(fd, loop_logger_buf, RECORD_SIZE);
if (res != RECORD_SIZE) {
*label = 0;
return 0;
}
cur_label = loop_logger_buf[0];
for(i = 1; i < RECORD_QUANTITY; i++) {
res = read(fd, loop_logger_buf, RECORD_SIZE);
if (res != RECORD_SIZE) {
break;
}
if (loop_logger_buf[0] != cur_label) {
*label = (loop_logger_buf[0] == '0') ? 1 : 0;
return i;
}
}
*label = (cur_label == '0') ? 1 : 0;
return 0;
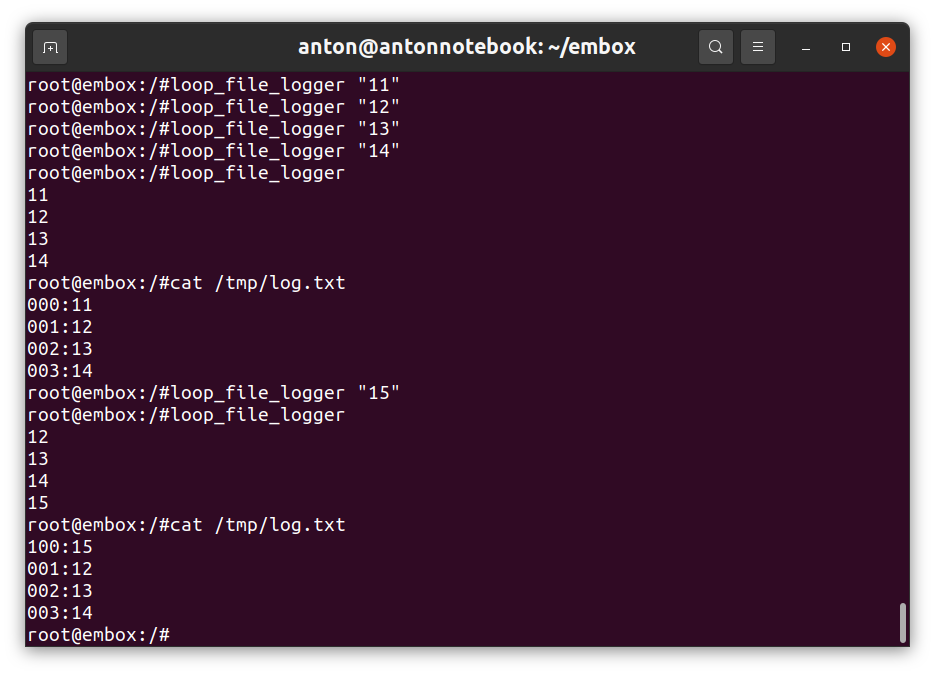
}Результаты хорошо видно на скриншоте:
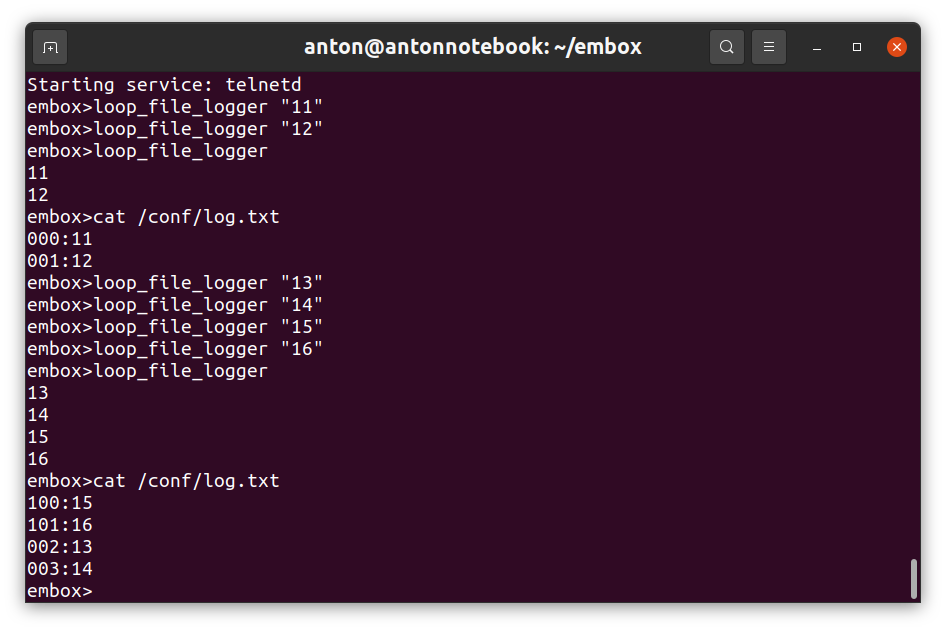
Добавим наш логгер в конфигурацию для платы STM32F4-Discovery. И получим тоже самое поведение:
Простое устройство
Файловая система это конечно хорошо, но давайте попробуем применить ее на каком нибудь простом устройстве.
Давайте немного улучшим устройство описанное в статье “Добавляем modbus в Embox RTOS и используем на STM32 и не только”.Напомню это сетевое устройство которое позволяет управлять светодиодами удаленно, через веб интерфейс или по Modbus TCP. Давайте добавим туда возможность изменения сетевых настрое и логгер который будет записывать состояние светодиоднов в моменты их изменения. Формат сообщения будет очень простым: “время: состояния светодиодов”
Здесь даже описывать нечего. Добавляем соотвествующие страницы и java script как описано в статье “Разрабатываем web-site для микроконтроллера“. Логгер у нас уже умеет выводить сообщения в текстовом формате, этого по сути достаточно, чтобы использовать его в CGI скриптах. Нужно просто использовать wrapper:
.controller("LogCtrl", ['$scope', '$http', function($scope, $http) {
$scope.update = function() {
$http.get('cgi-bin/cgi_cmd_wrapper?c=loop_file_logger').then(function (r) {
$scope.logger = r.data;
});
};
$scope.update();
}])Все, теперь просто скриншоты, на которых по моему мнению все понятно.
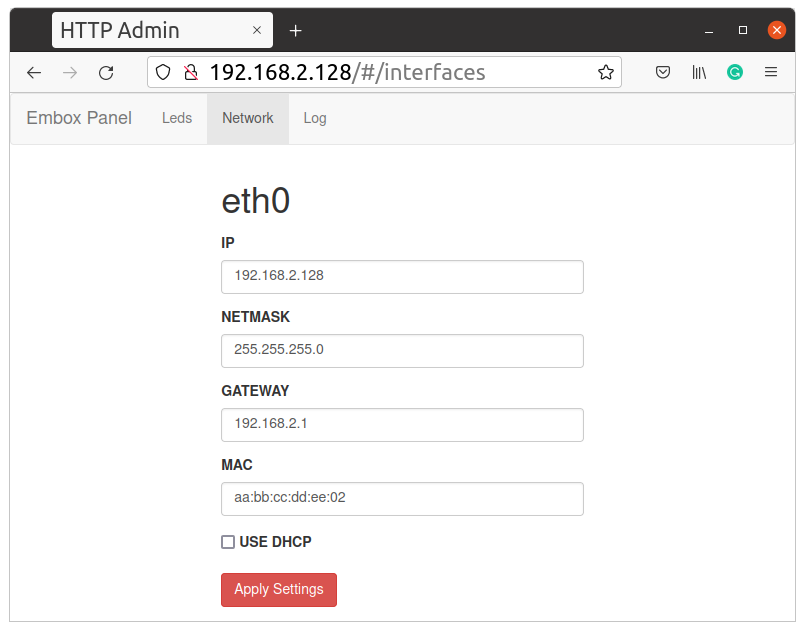
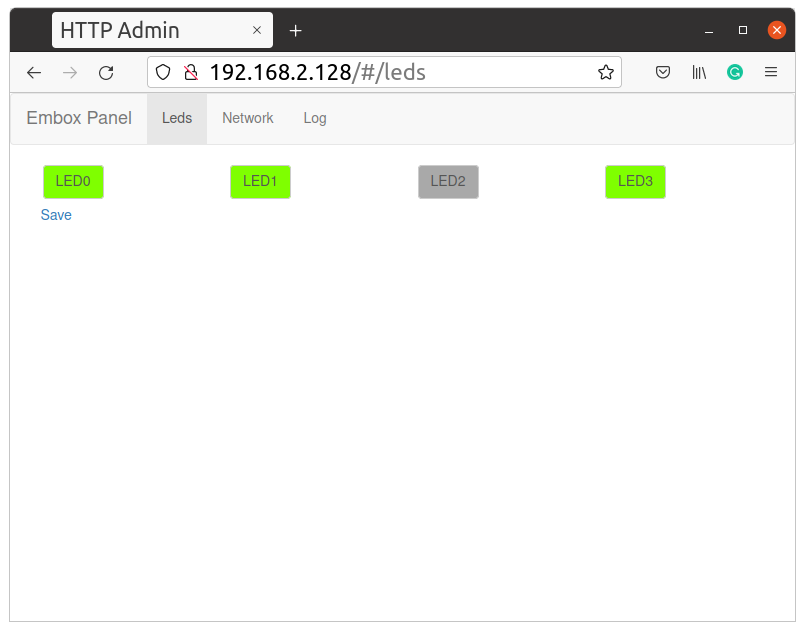
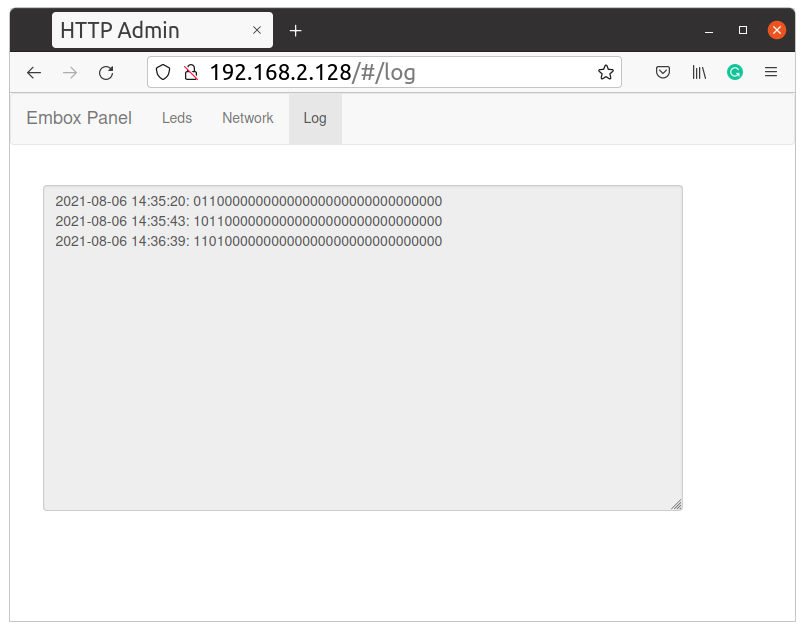
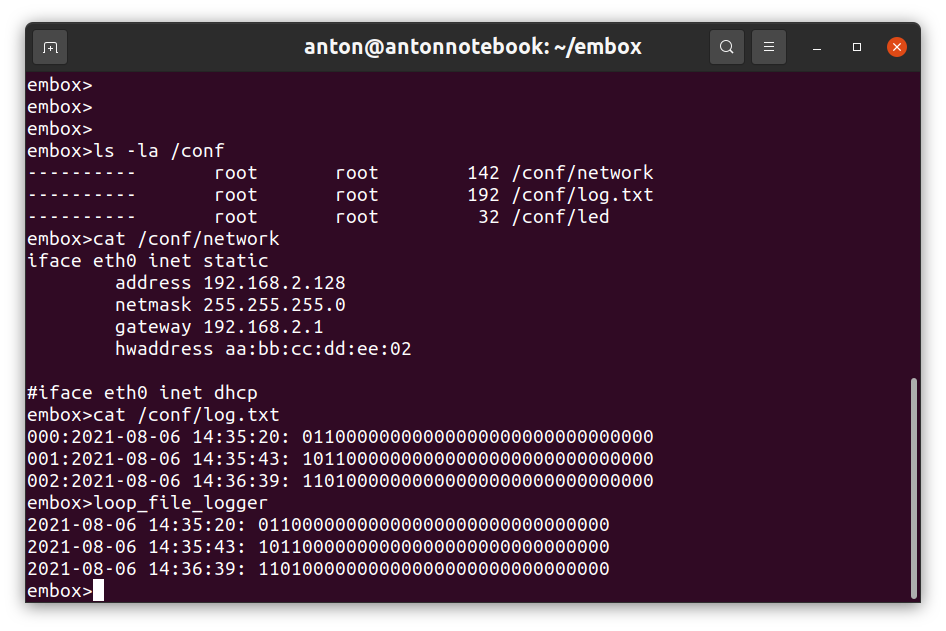
Заключение
Из статьи видно, что для организации файловой системы на микроконтроллере действительно требуются некоторые ресурсы. Но они не такие большие как кажется на первый взгляд. Несколько кБ если нужно сохранить 16 байт настроек, избыточны. Но с другой стороны большинство современных устройств и так имеют веб интерфейс или какой то другой интерфейс для управления, а значит в любом случае потребуются ресурсы для хранения этих данных.
Кроме того нужно учитывать, что флеш память имеет блочную структуру, следовательно если мы хотим хранить внутри микроконтроллера изменяемые настройки, нужно выделить как минимум один блок. А даже для f4 это 16 кБ.
Если же устройство имеет SD карту и требуется уметь читать FAT то в этом случае, добавление файловой системы для настроек и логирования, точно имеет смысл, поскольку за незаметные накладные расходы мы получаем удобство и универсальность решения. Например описанная в статье DumbFS работает на сериях STM32 (f3, f4, f7, h7) причем другие просто не пробовали. А сам приведенный в статье логгер вообще работает на любой файловой системе.
P.S. Спасибо за комментарии. Решил немного дополнить, изначально думал, что это понятно.
Статья направлена не на рассмотрение правильного способа сохранять настройки или логи в микроконтроллере. Есть разные способы это сделать. В статье показываются удобства и преимущества использования файловой системы и приводятся данные о том, что затраты могут быть очень небольшими. Поэтому этот подход можно использовать в том числе в микроконтроллерах.
В статье не разбираются особенности организации блочных устройств или flash памяти. Это отдельная тема. Все тоже самое, или только лог могут быть размещены не внутри микроконтроллера, а во внешней flash или другом носителе. Для этого нужен только драйвер этого устройства. Проблема учета износа ячеек также не рассматривается, это можно сделать либо на уровне драйвера блочного устройства, либо на уровне файловой системы. Ну и конечно, все исходники доступны в репозитории Embox
