Идеи разбиения больших проектов на мелкие части — так называемая микросервисная архитектура — получает последнее время все большее распространение среди разработчиков. Это хороший подход для организации кода, и разработки в целом, но что делать тем, у кого кодовая база начала складываться задолго до пика популярности микросервисной архитектуры? Этот же вопрос можно отнести и к тем, кому по нагрузкам комфортно на одном мощном сервере, да и время на переписывание кода просто нет. Говоря о собственном опыте: сейчас мы внедряем микросервисы, но изначально наш монолит проектировали «модульным», так, чтобы его было легко поддерживать, невзирая на объем. Кому интересно, как мы организовываем код — добро пожаловать под кат.
В книге «Совершенный код» Стива Макконнелла описана яркая философская идея, что основной вызов, который стоит перед разработчиком, — это управление сложностью кода. Одним из способов управления сложностью является декомпозиция. Собственно, о разделении большого куска кода на более простые и маленькие и пойдет речь.
Zend Framework предлагает нам делить наш код на модули. Чтобы не изобретать велосипед и идти в русле фреймворка, пусть наши части, на которые мы хотим логически разрезать проект, и будут модулями в терминах Zend Framework. Только мы доработаем межмодульное взаимодействие, чтобы каждый из них работал исключительно в своей области ответственности и ничего не знал о других модулях.
Каждый модуль состоит из набора классов с типовым назначением: контроллеры, слушатели событий, обработчики событий, обработчики команд, сервисы, команды, события, фильтры, сущности и репозитории. Все перечисленные типы классов организовываются в некоторую иерархию, где верхний слой знает о нижних слоях, но нижние ничего не знают о верхних (да, слоистая архитектура, она самая).
На вершине логической иерархии стоят контроллеры и слушатели событий. Первые принимают команды от пользователей в виде http-запросов, вторые реагируют на события в других модулях.
С контроллером все понятно — это обычный стандартный MVC-контроллер, предоставляемый фреймворком. Слушатель же событий мы решили сделать один на все модули. Он реализует интерфейс агрегатора слушателей Zend\EventManager\ListenerAggregateInterface и привязывает обработчики событий к событиям, взяв описание из конфигурации каждого из модулей.
После чего в каждом из модулей задается карта событий, на которые подписываются слушатели данного модуля.
Фактически модули общаются между собой исключительно посредством контроллеров и событий.
Если нам нужно подтянуть какую-то визуализацию данных из другого модуля (виджет), то мы используем вызов контроллера другого модуля через forward() и добавляем результат к текущей модели вида:
Если же нам нужно сообщить другим модулям, что у нас что-то произошло, мы кидаем событие, чтобы другие модули отреагировали.
Контроллеры и слушатели событий мы рассмотрели выше, теперь пройдемся по оставшимся классам модуля, которые в логической иерархии занимают более низкий слой: обработчики событий, обработчики команд, сервисы и репозитории.
Начну, пожалуй, с последних. Репозитории. Концептуально — это коллекция для работы с определенным типом сущностей, которая может хранить данные где-то в удаленном хранилище. В нашем случае в БД. Их можно реализовать, либо используя стандартные Zend-овские TableGateway и QueryBuilder, либо подключая любую ORM. Doctrine 2 — пожалуй, лучший инструмент для работы с БД в условиях крупного монолита. И репозитории как понятие там есть уже из коробки.
Например, в контексте Doctrine 2 репозиторий будет выглядеть так:
Для получения сущностей из репозитория могут использоваться как параметры простых типов, так и DTO-объекты, которые хранят набор параметров, по которым нужно организовать выборку из БД. В нашей терминологии — это фильтры (так их назвали, потому что с их помощью мы фильтруем сущности, возвращаемые из репозитория).
Сервисы — классы, которые либо выступают фасадами к логике приложения, либо инкапсулируют логику работы с внешними библиотеками и API.
Обработчики событий и обработчики команд — это фактически сервис с одним публичным методом handle(), при этом они занимаются изменением состояния системы, чего не делают ни одни другие шаблонные классы. Под изменением состояния системы мы подразумеваем любые действия по записи в БД, в файловую систему, отправка команд в сторонние API, которые приведут к изменению возвращаемых этим API данных и т.д.
В нашей реализации обработчик события отличается от обработчика команды лишь тем, что DTO, который в него передается в виде параметра, наследуется от Zend-овского Event. В то время как в обработчик команды может прийти команда в виде любой сущности.
Выше были описаны типовые классы, которые осуществляют логику работы приложения и взаимодействие приложения с внешними API и библиотеками. Но для согласованной работы всего вышеперечисленного нужен “клей”. Таким “клеем” выступают Data Transfer Objects, которые типизируют общение между различными частями приложения.
В нашем проекте они имеют разделение:
— Сущности — данные, которые представляют основные понятия в системе, как то: пользователь, словарь, слово и т.д. В основном, выбираются из БД и представляются в том или ином виде в скриптах вида.
— События — DTO, наследуемые от класса Event, содержащие данные о том, что было изменено в каком-то модуле. Их могут бросать обработчики команд или обработчики событий. А принимают и работают с ними исключительно обработчики событий.
— Команды — DTO, содержащие необходимые обработчику данные. Формируются в контроллерах. Используются в обработчиках команд.
— Фильтры — DTO, содержащие параметры выборки из БД. Формировать может кто угодно; используются в репозиториях для построения запроса к БД.
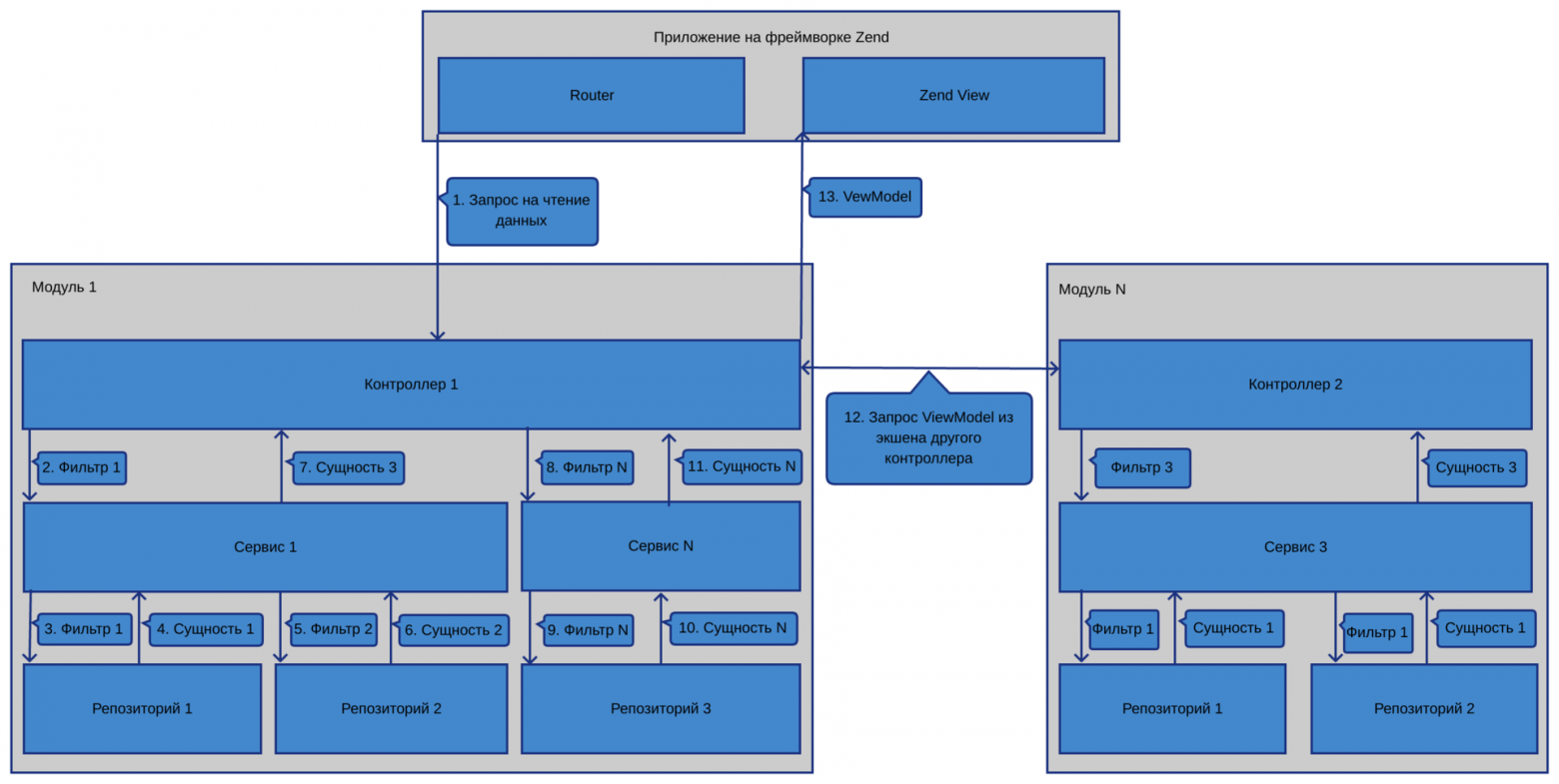
Взаимодействие с системой подразделяется на чтение данных и изменение данных. Если запрошенный URL должен только отдать данные, то взаимодействие построено таким образом:
1) Данные от пользователя в сыром виде приходят в экшн контроллера.
2) Используя Zend-овский InputFilter, фильтруем их и валидируем.
3) Если они валидные, то в контроллере формируем DTO фильтра.
4) Дальше все зависит от того, получаются ли результирующие данные из одного репозитория или компонуются из нескольких. Если из одного, то мы репозиторий вызываем из контроллера, передав в метод поиска сформированный на 3-ем шаге объект. Если же данные нужно компоновать, то мы создаем сервис, который выступит фасадом к нескольким репозиториям, и уже ему передаем DTO. Сервис же дергает нужные репозитории и компонует данные из них.
5) Полученные данные отдаем во ViewModel, после чего происходит рендеринг скрипта вида.
Визуализировать компоненты, участвующие в получении данных, а также движение этих данных можно с помощью схемы:
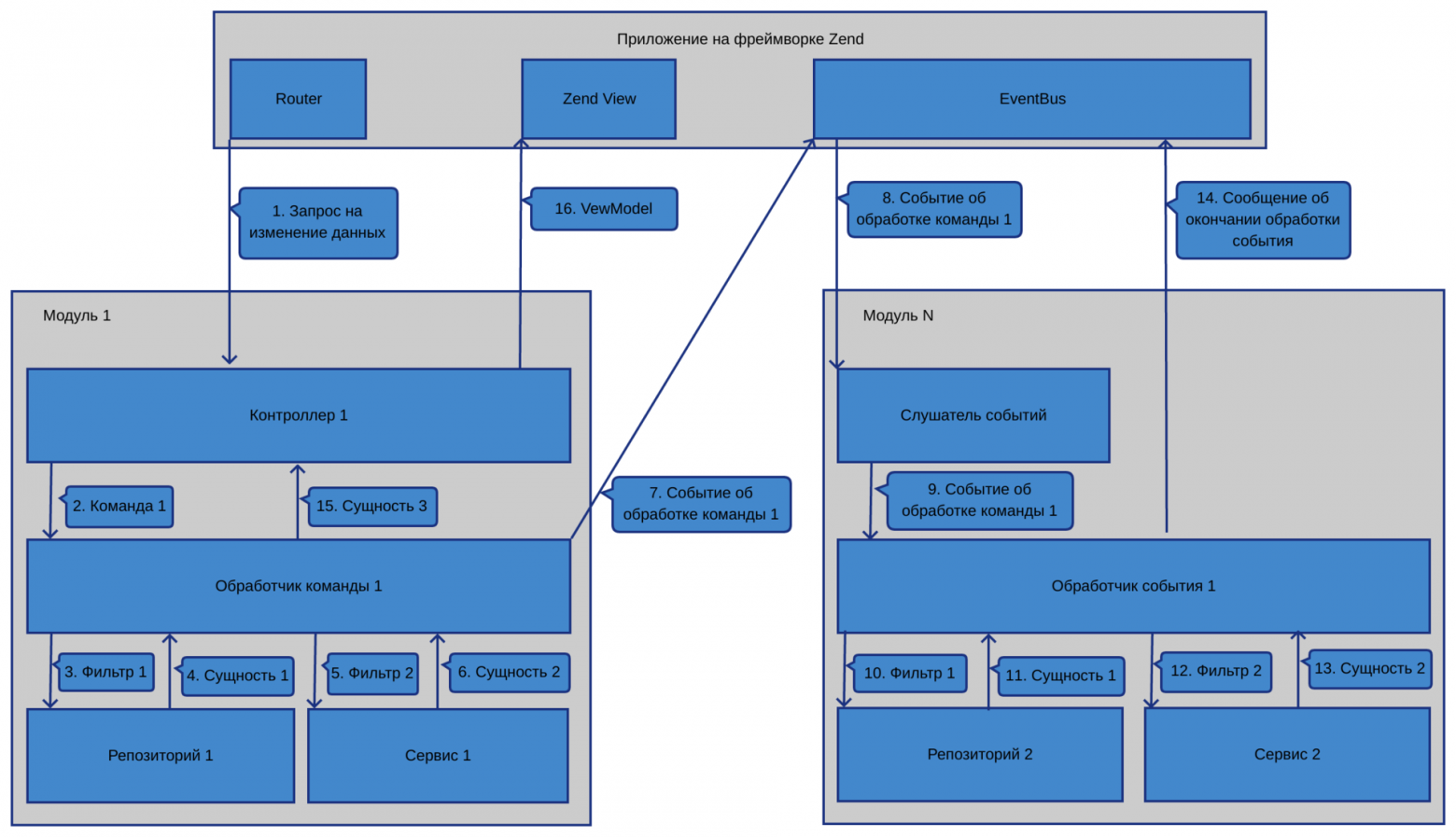
Если запрошенный URL должен изменить состояние системы:
1) Данные от пользователя в сыром виде приходят в экшн контроллера.
2) Используя Zend-овский InputFilter, фильтруем их и валидируем.
3) Если они валидные, то в контроллере формируем DTO команды.
4) Запускаем в контроллере обработчик команды, передав в него команду. Правильным считается передавать команду в шину команд. Мы использовали как шину Tactician. Но в итоге решили напрямую запускать обработчик, т.к. с шиной команд хоть и получали дополнительный уровень абстракции, который теоретически давал нам возможность часть команд пускать асинхронно, но в итоге испытывали неудобство в том, что приходилось подписываться на ответ от команды, чтобы узнать результат ее отработки. А так как у нас не распределенная система и выполнять что-то асинхронно — это скорее исключение, чем правило, то решили пренебречь абстракцией в угоду удобству использования.
5) Обработчик команды меняет данные, используя сервисы и репозитории, и формирует событие, передав туда измененные данные. После чего кидает событие в шину событий.
6) Обработчик(и) событий ловит событие и выполняет свои преобразования. Если необходимо, также кидает событие с информацией о том, какие преобразования были сделаны.
7) После отработки всех обработчиков событий поток управления возвращается от команды в контроллер, где при необходимости берется результат, возвращенный обработчиком команды, и посылается во ViewModel.
Схематически взаимосвязь между элементами, а также то, как происходят вызовы между компонентами, изображено на рисунке:
Самый простой и наглядный пример — это регистрация пользователя с отправкой письма для подтверждения email-адреса. В этой цепочке отрабатывают 2 модуля: User, который знает все о пользователях и имеет код, позволяющий оперировать сущностями пользователей (в том числе и регистрировать); а также модуль Email, который знает, как, что и кому отсылать.
Модуль пользователей ловит в свой контроллер данные из формы регистрации и сохраняет пользователя в базу, после чего генерирует событие UserRegisteredEvent($user), передавая ему сохраненного пользователя.
На данное событие могут быть подписаны от нуля до нескольких слушателей в других модулях. В нашем примере модуль Email, который формирует хеш подтверждения, передает хеш в шаблон письма и сгенерированное письмо отправляет пользователю. После чего, опять же, генерирует событие СonfirmationEmailSentEvent($user), куда подставляет сущность пользователя, к которой добавлен хеш подтверждения.
После чего уже модуль User должен будет поймать событие об отправке письма и сохранить хеш подтверждения в базу данных.
На этом межмодульное взаимодействие должно быть закончено. Да, часто хочется напрямую дернуть код из соседнего модуля, но это приведет к связанности модулей и убьет на корню возможность в долгосрочной перспективе вынести каждый из модулей в свой отдельный проект.
Таким, на самом деле, нехитрым структурированием кода можно добиться разделения проекта на независимые небольшие части. Нарезанный на подобные части проект поддерживать гораздо легче, чем проект, написанный сплошняком.
Кроме того, разрабатывая код с использованием подобного подхода, гораздо легче будет перейти к микросервисному подходу. Т.к. уже фактически будут существовать микросервисы, пусть и в контексте одного проекта. Нужно будет только вынести каждый модуль в свой отдельный проект и заменить Zend-овскую шину событий на свою реализацию, которая будет слать события по HTTP или через RabbitMQ. Но это уже чисто теоретические домыслы и пища для размышлений.
Онлайн-курсы
Мы дарим вам доступ на год к курсу английского для самостоятельного изучения «Онлайн курс».
Для получения доступа просто перейдите по ссылке. Срок активации промокода — до 1 сентября 2017 года.
Индивидуально по Скайпу
Летние интенсивные курсы английского — заявку оставляем по ссылке.
Занятия проходят в любое удобное для вас время.
Промокод на 35% скидки: 6habra25
Действителен до 22 мая. Введите его при оплате или воспользуйтесь ссылкой.
В книге «Совершенный код» Стива Макконнелла описана яркая философская идея, что основной вызов, который стоит перед разработчиком, — это управление сложностью кода. Одним из способов управления сложностью является декомпозиция. Собственно, о разделении большого куска кода на более простые и маленькие и пойдет речь.
Модули
Zend Framework предлагает нам делить наш код на модули. Чтобы не изобретать велосипед и идти в русле фреймворка, пусть наши части, на которые мы хотим логически разрезать проект, и будут модулями в терминах Zend Framework. Только мы доработаем межмодульное взаимодействие, чтобы каждый из них работал исключительно в своей области ответственности и ничего не знал о других модулях.
Каждый модуль состоит из набора классов с типовым назначением: контроллеры, слушатели событий, обработчики событий, обработчики команд, сервисы, команды, события, фильтры, сущности и репозитории. Все перечисленные типы классов организовываются в некоторую иерархию, где верхний слой знает о нижних слоях, но нижние ничего не знают о верхних (да, слоистая архитектура, она самая).
На вершине логической иерархии стоят контроллеры и слушатели событий. Первые принимают команды от пользователей в виде http-запросов, вторые реагируют на события в других модулях.
С контроллером все понятно — это обычный стандартный MVC-контроллер, предоставляемый фреймворком. Слушатель же событий мы решили сделать один на все модули. Он реализует интерфейс агрегатора слушателей Zend\EventManager\ListenerAggregateInterface и привязывает обработчики событий к событиям, взяв описание из конфигурации каждого из модулей.
Код слушателя
class ListenerAggregator implements ListenerAggregateInterface
{
/**
* @var array
*/
protected $eventsMap;
/**
* @var ContainerInterface
*/
private $container;
/**
* Attach one or more listeners
*
* Implementors may add an optional $priority argument; the EventManager
* implementation will pass this to the aggregate.
*
* @param EventManagerInterface $events
*
* @param int $priority
*/
public function attach(EventManagerInterface $events, $priority = 1)
{
$events->addIdentifiers([Event::DOMAIN_LOGIC_EVENTS_IDENTIFIER]);
$map = $this->getEventsMap();
$container = $this->container;
foreach ($map as $eventClass => $handlers) {
foreach ($handlers as $handlerClass) {
$events->getSharedManager()->attach(Event::EVENTS_IDENTIFIER, $eventClass,
function ($event) use ($container, $handlerClass) {
/* @var $handler EventHandlerInterface */
$handler = $container->get($handlerClass);
$handler->handle($event);
}
);
}
}
}
}
После чего в каждом из модулей задается карта событий, на которые подписываются слушатели данного модуля.
'events' => [
UserRegisteredEvent::class => [
UserRegisteredHandler::class,
],
]
Фактически модули общаются между собой исключительно посредством контроллеров и событий.
Если нам нужно подтянуть какую-то визуализацию данных из другого модуля (виджет), то мы используем вызов контроллера другого модуля через forward() и добавляем результат к текущей модели вида:
$comments = $this->forward()->dispatch(
'Dashboard\Controller\Comment',
[
'action' => 'browse',
'entity' => 'blog_posts',
'entityId' => $post->getId()
]
);
$view->addChild($comments, 'comments');
Если же нам нужно сообщить другим модулям, что у нас что-то произошло, мы кидаем событие, чтобы другие модули отреагировали.
Служебные классы
Контроллеры и слушатели событий мы рассмотрели выше, теперь пройдемся по оставшимся классам модуля, которые в логической иерархии занимают более низкий слой: обработчики событий, обработчики команд, сервисы и репозитории.
Начну, пожалуй, с последних. Репозитории. Концептуально — это коллекция для работы с определенным типом сущностей, которая может хранить данные где-то в удаленном хранилище. В нашем случае в БД. Их можно реализовать, либо используя стандартные Zend-овские TableGateway и QueryBuilder, либо подключая любую ORM. Doctrine 2 — пожалуй, лучший инструмент для работы с БД в условиях крупного монолита. И репозитории как понятие там есть уже из коробки.
Например, в контексте Doctrine 2 репозиторий будет выглядеть так:
Код репозитория
class UserRepository extends BaseRepository
{
/**
* @param UserFilter $filter
* @return City|null
*/
public function findOneUser(UserFilter $filter)
{
$query = $this->createQuery($filter);
Return $query->getQuery()->getOneOrNullResult();
}
/**
* @param UserFilter $filter
* @return \Doctrine\ORM\QueryBuilder
*/
private function createQuery(UserFilter $filter)
{
$qb = $this->createQueryBuilder('user');
if ($filter->getEmail()) {
$qb->andWhere('user.email = :email')
->setParameter('email', $filter->getEmail());
}
if ($filter->getHash()) {
$qb->andWhere('user.confirmHash =:hash')
->setParameter('hash', $filter->getHash());
}
return $qb;
}
}
Для получения сущностей из репозитория могут использоваться как параметры простых типов, так и DTO-объекты, которые хранят набор параметров, по которым нужно организовать выборку из БД. В нашей терминологии — это фильтры (так их назвали, потому что с их помощью мы фильтруем сущности, возвращаемые из репозитория).
Сервисы — классы, которые либо выступают фасадами к логике приложения, либо инкапсулируют логику работы с внешними библиотеками и API.
Обработчики событий и обработчики команд — это фактически сервис с одним публичным методом handle(), при этом они занимаются изменением состояния системы, чего не делают ни одни другие шаблонные классы. Под изменением состояния системы мы подразумеваем любые действия по записи в БД, в файловую систему, отправка команд в сторонние API, которые приведут к изменению возвращаемых этим API данных и т.д.
В нашей реализации обработчик события отличается от обработчика команды лишь тем, что DTO, который в него передается в виде параметра, наследуется от Zend-овского Event. В то время как в обработчик команды может прийти команда в виде любой сущности.
Пример обработчика события
class UserRegisteredHandler implements EventHandlerInterface
{
/**
* @var ConfirmEmailSender
*/
private $emailSender;
/**
* @var EventManagerInterface
*/
private $eventManager;
public function __construct(
ConfirmEmailSender $emailSender,
EventManagerInterface $eventManager
) {
$this->emailSender = $emailSender;
$this->eventManager = $eventManager;
}
public function handle(Event $event)
{
if (!($event instanceof UserRegisteredEvent)) {
throw new \RuntimeException('Неверно задан обработчик события');
}
$user = $event->getUser();
if (!$user->isEmailConfirmed()) {
$this->send($user);
}
}
protected function send(User $user)
{
$hash = md5($user->getEmail() . '-' . time() . '-' . $user->getName());
$user->setConfirmHash($hash);
$this->emailSender->send($user);
$this->eventManager->triggerEvent(new ConfirmationEmailSentEvent($user));
}
}
Пример обработчика команды
class RegisterHandler
{
/**
* @var UserRepository
*/
private $userRepository;
/**
* @var PasswordService
*/
private $passwordService;
/**
* @var EventManagerInterface
*/
private $eventManager;
/**
* RegisterCommand constructor.
* @param UserRepository $userRepository
* @param PasswordService $passwordService
* @param EventManagerInterface $eventManager
*/
public function __construct(
UserRepository $userRepository,
PasswordService $passwordService,
EventManagerInterface $eventManager
) {
$this->userRepository = $userRepository;
$this->passwordService = $passwordService;
$this->eventManager = $eventManager;
}
public function handle(RegisterCommand $command)
{
$user = clone $command->getUser();
$this->validate($user);
$this->modify($user);
$repo = $this->userRepository;
$repo->saveAndRefresh($user);
$this->eventManager->triggerEvent(new UserRegisteredEvent($user));
}
protected function modify(User $user)
{
$this->passwordService->encryptPassword($user);
}
/**
* @throws CommandException
*/
protected function validate(User $user)
{
if (!$user) {
throw new ParameterIsRequiredException('На заполнено поле user в команде RegisterCommand');
}
$this->validateIdentity($user);
}
protected function validateIdentity(User $user)
{
$repo = $this->userRepository;
$persistedUser = $repo->findByEmail($user->getEmail());
if ($persistedUser) {
throw new EmailAlreadyExists('Пользователь с таким email уже существует');
}
}
}
DTO объекты
Выше были описаны типовые классы, которые осуществляют логику работы приложения и взаимодействие приложения с внешними API и библиотеками. Но для согласованной работы всего вышеперечисленного нужен “клей”. Таким “клеем” выступают Data Transfer Objects, которые типизируют общение между различными частями приложения.
В нашем проекте они имеют разделение:
— Сущности — данные, которые представляют основные понятия в системе, как то: пользователь, словарь, слово и т.д. В основном, выбираются из БД и представляются в том или ином виде в скриптах вида.
— События — DTO, наследуемые от класса Event, содержащие данные о том, что было изменено в каком-то модуле. Их могут бросать обработчики команд или обработчики событий. А принимают и работают с ними исключительно обработчики событий.
— Команды — DTO, содержащие необходимые обработчику данные. Формируются в контроллерах. Используются в обработчиках команд.
— Фильтры — DTO, содержащие параметры выборки из БД. Формировать может кто угодно; используются в репозиториях для построения запроса к БД.
Как происходит взаимодействие частей системы
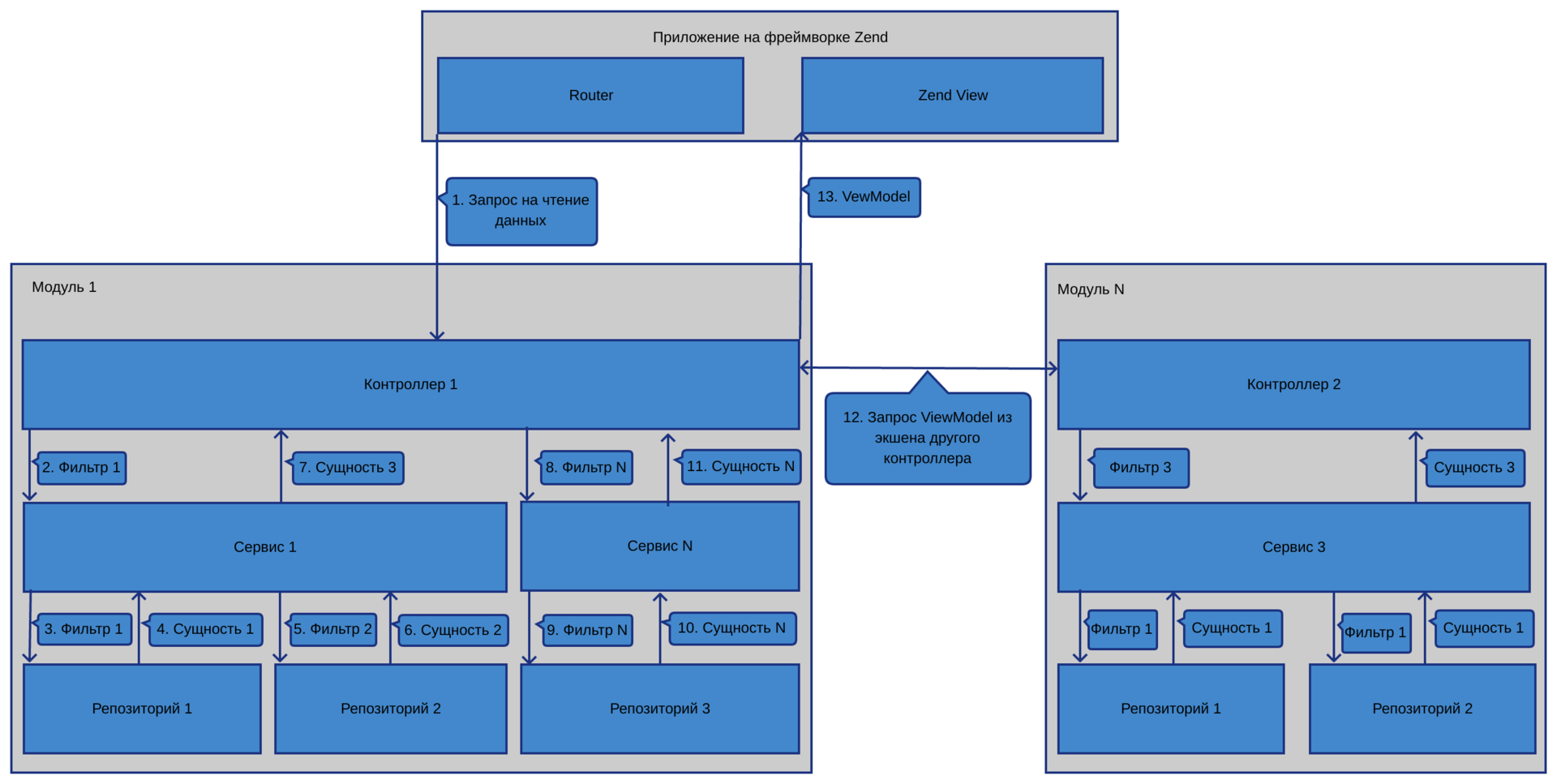
Взаимодействие с системой подразделяется на чтение данных и изменение данных. Если запрошенный URL должен только отдать данные, то взаимодействие построено таким образом:
1) Данные от пользователя в сыром виде приходят в экшн контроллера.
2) Используя Zend-овский InputFilter, фильтруем их и валидируем.
3) Если они валидные, то в контроллере формируем DTO фильтра.
4) Дальше все зависит от того, получаются ли результирующие данные из одного репозитория или компонуются из нескольких. Если из одного, то мы репозиторий вызываем из контроллера, передав в метод поиска сформированный на 3-ем шаге объект. Если же данные нужно компоновать, то мы создаем сервис, который выступит фасадом к нескольким репозиториям, и уже ему передаем DTO. Сервис же дергает нужные репозитории и компонует данные из них.
5) Полученные данные отдаем во ViewModel, после чего происходит рендеринг скрипта вида.
Визуализировать компоненты, участвующие в получении данных, а также движение этих данных можно с помощью схемы:
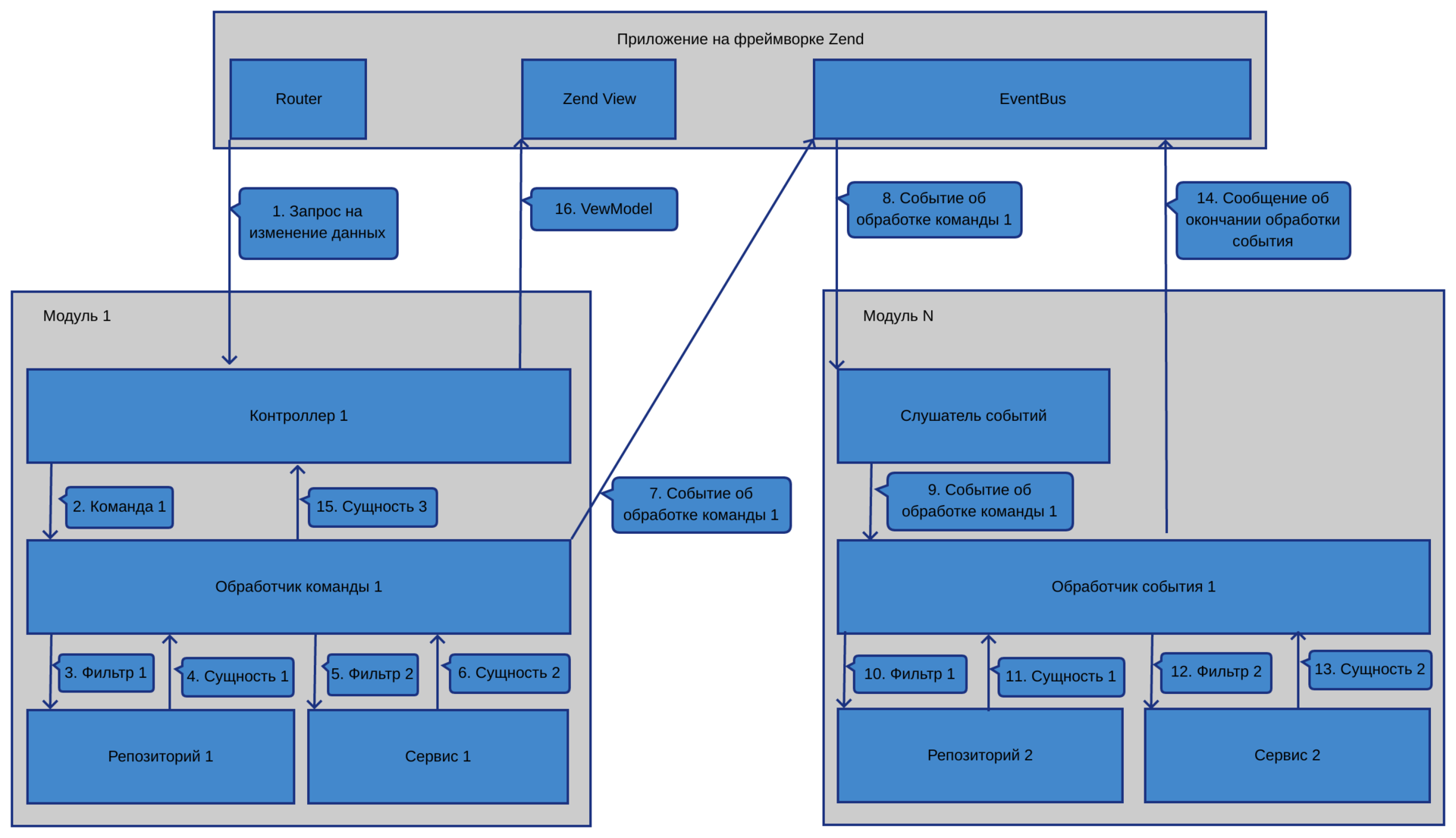
Если запрошенный URL должен изменить состояние системы:
1) Данные от пользователя в сыром виде приходят в экшн контроллера.
2) Используя Zend-овский InputFilter, фильтруем их и валидируем.
3) Если они валидные, то в контроллере формируем DTO команды.
4) Запускаем в контроллере обработчик команды, передав в него команду. Правильным считается передавать команду в шину команд. Мы использовали как шину Tactician. Но в итоге решили напрямую запускать обработчик, т.к. с шиной команд хоть и получали дополнительный уровень абстракции, который теоретически давал нам возможность часть команд пускать асинхронно, но в итоге испытывали неудобство в том, что приходилось подписываться на ответ от команды, чтобы узнать результат ее отработки. А так как у нас не распределенная система и выполнять что-то асинхронно — это скорее исключение, чем правило, то решили пренебречь абстракцией в угоду удобству использования.
5) Обработчик команды меняет данные, используя сервисы и репозитории, и формирует событие, передав туда измененные данные. После чего кидает событие в шину событий.
6) Обработчик(и) событий ловит событие и выполняет свои преобразования. Если необходимо, также кидает событие с информацией о том, какие преобразования были сделаны.
7) После отработки всех обработчиков событий поток управления возвращается от команды в контроллер, где при необходимости берется результат, возвращенный обработчиком команды, и посылается во ViewModel.
Схематически взаимосвязь между элементами, а также то, как происходят вызовы между компонентами, изображено на рисунке:
Пример межмодульного взаимодействия
Самый простой и наглядный пример — это регистрация пользователя с отправкой письма для подтверждения email-адреса. В этой цепочке отрабатывают 2 модуля: User, который знает все о пользователях и имеет код, позволяющий оперировать сущностями пользователей (в том числе и регистрировать); а также модуль Email, который знает, как, что и кому отсылать.
Модуль пользователей ловит в свой контроллер данные из формы регистрации и сохраняет пользователя в базу, после чего генерирует событие UserRegisteredEvent($user), передавая ему сохраненного пользователя.
public function handle(RegisterCommand $command)
{
$user = clone $command->getUser();
$this->validate($user);
$this->modify($user);
$repo = $this->userRepository;
$repo->saveAndRefresh($user);
$this->eventManager->triggerEvent(new UserRegisteredEvent($user));
}
На данное событие могут быть подписаны от нуля до нескольких слушателей в других модулях. В нашем примере модуль Email, который формирует хеш подтверждения, передает хеш в шаблон письма и сгенерированное письмо отправляет пользователю. После чего, опять же, генерирует событие СonfirmationEmailSentEvent($user), куда подставляет сущность пользователя, к которой добавлен хеш подтверждения.
protected function send(User $user)
{
$hash = md5($user->getEmail() . '-' . time() . '-' . $user->getName());
$user->setConfirmHash($hash);
$this->emailSender->send($user);
$this->eventManager->triggerEvent(new ConfirmationEmailSentEvent($user));
}
После чего уже модуль User должен будет поймать событие об отправке письма и сохранить хеш подтверждения в базу данных.
На этом межмодульное взаимодействие должно быть закончено. Да, часто хочется напрямую дернуть код из соседнего модуля, но это приведет к связанности модулей и убьет на корню возможность в долгосрочной перспективе вынести каждый из модулей в свой отдельный проект.
Вместо заключения
Таким, на самом деле, нехитрым структурированием кода можно добиться разделения проекта на независимые небольшие части. Нарезанный на подобные части проект поддерживать гораздо легче, чем проект, написанный сплошняком.
Кроме того, разрабатывая код с использованием подобного подхода, гораздо легче будет перейти к микросервисному подходу. Т.к. уже фактически будут существовать микросервисы, пусть и в контексте одного проекта. Нужно будет только вынести каждый модуль в свой отдельный проект и заменить Zend-овскую шину событий на свою реализацию, которая будет слать события по HTTP или через RabbitMQ. Но это уже чисто теоретические домыслы и пища для размышлений.
Бонусы для читателей Хабра
Онлайн-курсы
Мы дарим вам доступ на год к курсу английского для самостоятельного изучения «Онлайн курс».
Для получения доступа просто перейдите по ссылке. Срок активации промокода — до 1 сентября 2017 года.
Индивидуально по Скайпу
Летние интенсивные курсы английского — заявку оставляем по ссылке.
Занятия проходят в любое удобное для вас время.
Промокод на 35% скидки: 6habra25
Действителен до 22 мая. Введите его при оплате или воспользуйтесь ссылкой.
