Привет! 
Хочу поведать читателям Хабрахабра о сервисе Elastic Load Balancer, который входит в состав Enterprise Compute Cloud. Многие давно уже пользуются сервисом ELB, но не знают как работает сервис изнутри. Я немного владею этой информацией — многочасовые митинги с саппортом AWS иногда гораздо познавательнее документации на сайте.
Итак, начнём с основ, потом перейдём к нюансам.
Elastic Load Balancer — это сервис, предоставляющий балансировку запросов между инстансами EC2/VPC. Соответственно есть 2 типа ELB, которые
ELB умеет проксировать следующие протоколы:
Причём как слушатели, так и получатели могут быть любой комбинации. Например http-http (просто прокси) или tcp — https (если SSL терминация производится на стороне инстансов)
ELB умеет проксировать порты:
В консоли находим пункт Load Balancers и там тыцаем Create Load Balancer. Первый скрин — настройка портов и протоколов:
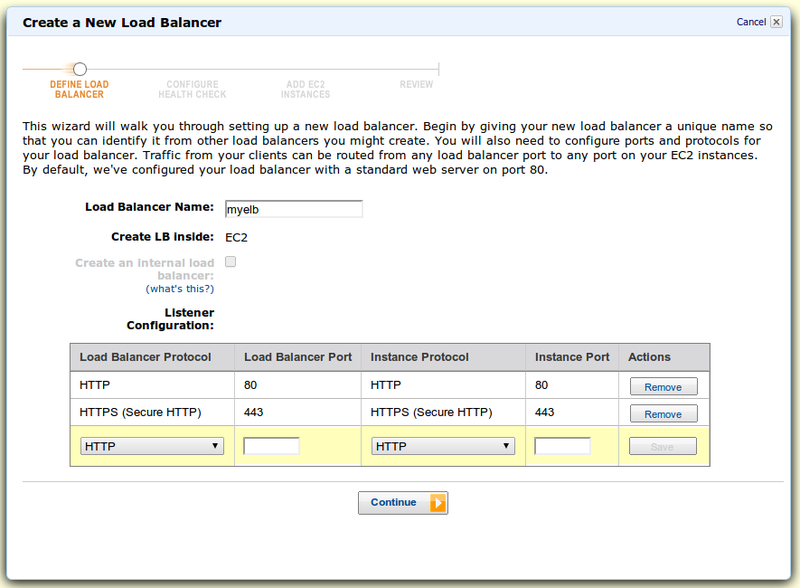
Далее, т.к. мы выбрали HTTPS, нам нужен сертификат для терминации SSL. AWS спрашивает у нас настройки:
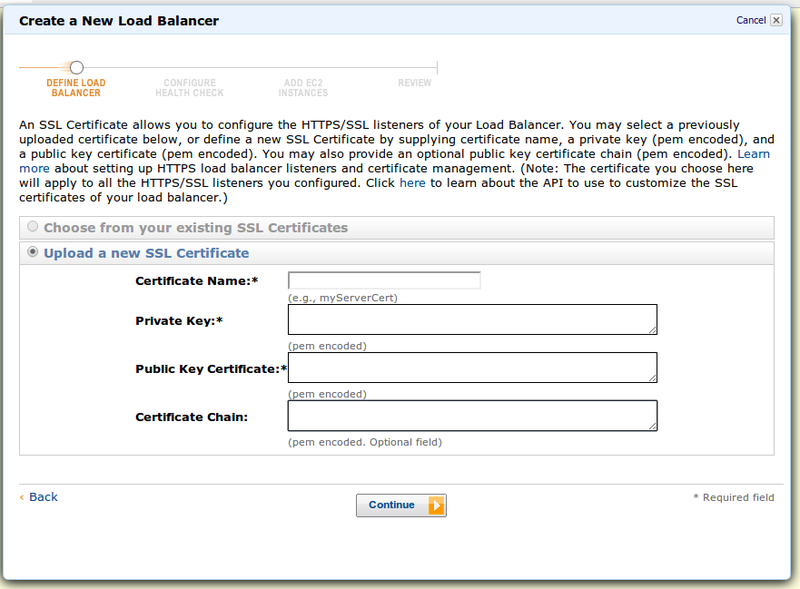
Далее настраиваем хелсчек — проверка здоровья хоста. Если хелсчек положительный, инстанс будет в списке на балансировку. Отрицательный — на инстанс не будут отправляться запросы:
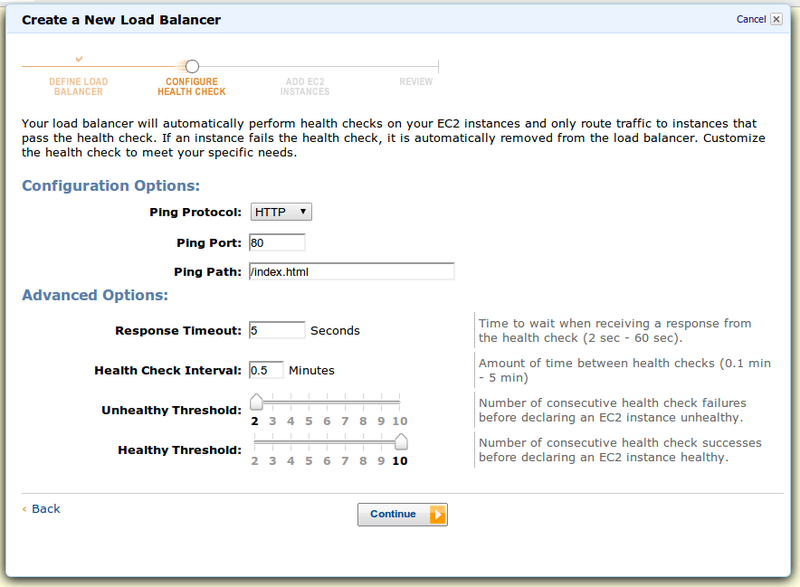
Хелсчеки можно настроить на те же протоколы, что и балансировку, на http/https можно добавить имя странички или путь.
Ну и в финале — нужно выбрать инстансы, которые вы хотите добавить под ELB (на скриншоте просто пример)
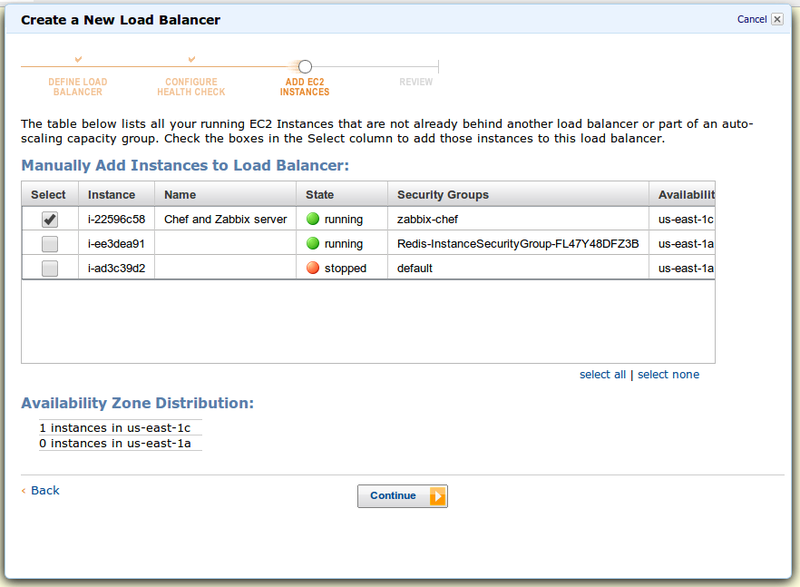
Последний скрин — как всегда проверка деталей:
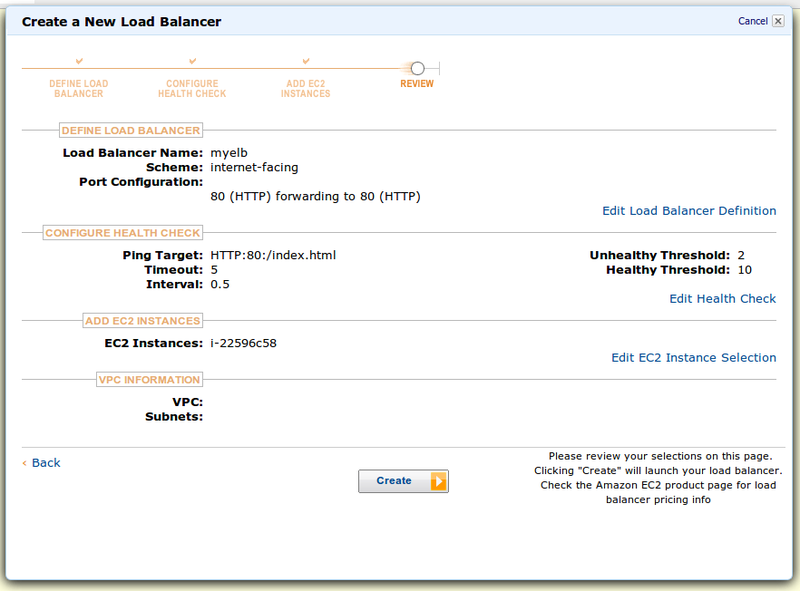
Просмотрели, решили, что всё ок и создали ELB.
У EC2 ELB есть 3 адреса, по которым к ним можно обращаться. Это не IP адреса, а URL:
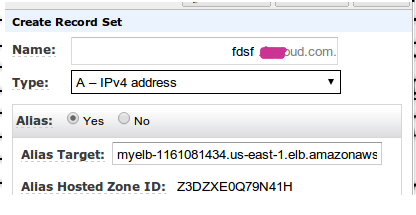
Есть 2 пути настроить свой домен на ELB и зависят они от того, какие серверы имён вы используете. Рекомендуется использовать Amazon Route 53, т.к. он интегрирован с ELB и там всё легко настраивается через A запись:
Если же вы используете другие DNS сервисы/серверы — ваш путь CNAME.
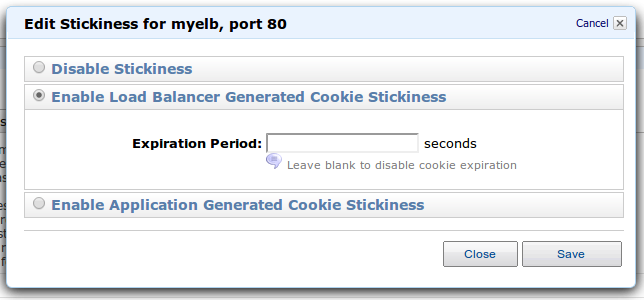
ELB способен обрабатывать куки для Sticky session. Эти функции можно настроить в конфигурации после создания ELB:
Тут хотелось бы рассказать о том, как масштабируется ELB и как он себя ведёт под нагрузкой. Я уже опубликовывал статью, в которой сравнивал производительность ELB, NGINX и HAproxy. Там я затронул момент масштабирования. ELB вертикально промасштабировался с t1.micto до m1.small:
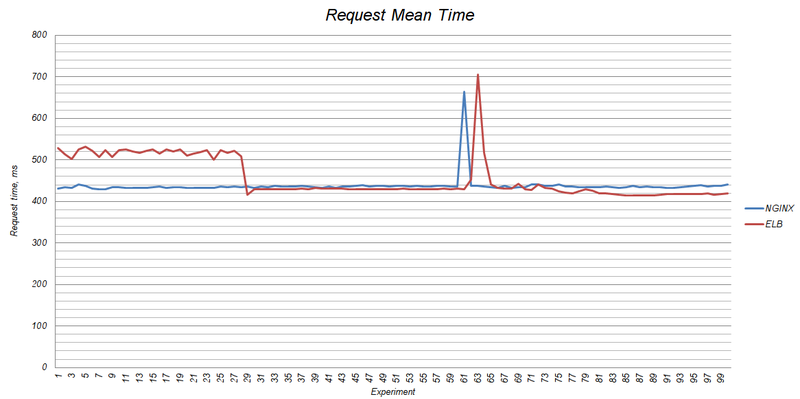
По словам представителей техподдержки Amazon Web Services при увеличении нагрузки на ELB проходит от одной до семи минут перед тем, как произойдёт масштабирование сервера. IP адрес может быть поменян, поэтому не рекомендуется использовать IP адреса для доменов (я описал выше выход из ситуации).
Для отдельных случаев ELB может быть «разогрет» до нужного шейпа, чтобы выдерживать большие нагрузки. «Разогрев производится» через запросы в техподдержку.
ELB играет немаловажную роль в автомасштабировании инстансов EC2. Имя ELB указывается в конфигах групп автомасштабирования и, собственно, всё крутится вокруг них. Подробнее об этом можно прочесто в моей статье.
У ELB ещё есть много нюансов работы, но основное я рассказал.
Есть ли у вас опыт работы с ELB? Интересные факты?

Хочу поведать читателям Хабрахабра о сервисе Elastic Load Balancer, который входит в состав Enterprise Compute Cloud. Многие давно уже пользуются сервисом ELB, но не знают как работает сервис изнутри. Я немного владею этой информацией — многочасовые митинги с саппортом AWS иногда гораздо познавательнее документации на сайте.
Итак, начнём с основ, потом перейдём к нюансам.
Что такое ELB.
Elastic Load Balancer — это сервис, предоставляющий балансировку запросов между инстансами EC2/VPC. Соответственно есть 2 типа ELB, которые
- видны из интернета — EC2/VPC
- не видны из интернета — VPC
Возможности ELB
ELB умеет проксировать следующие протоколы:
- http
- https
- tcp
- ssl (secure tcp)
Причём как слушатели, так и получатели могут быть любой комбинации. Например http-http (просто прокси) или tcp — https (если SSL терминация производится на стороне инстансов)
ELB умеет проксировать порты:
- 25
- 80
- 443
- 1024-65535
Настройка ELB
В консоли находим пункт Load Balancers и там тыцаем Create Load Balancer. Первый скрин — настройка портов и протоколов:
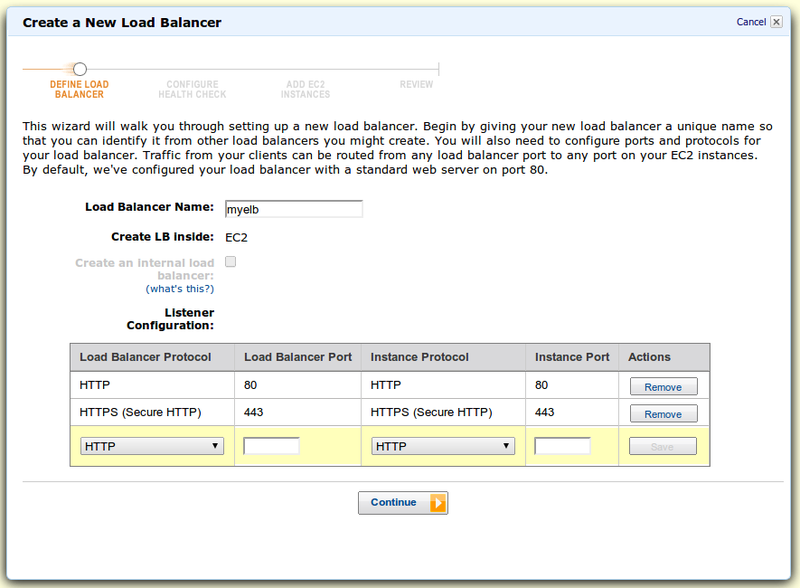
Далее, т.к. мы выбрали HTTPS, нам нужен сертификат для терминации SSL. AWS спрашивает у нас настройки:
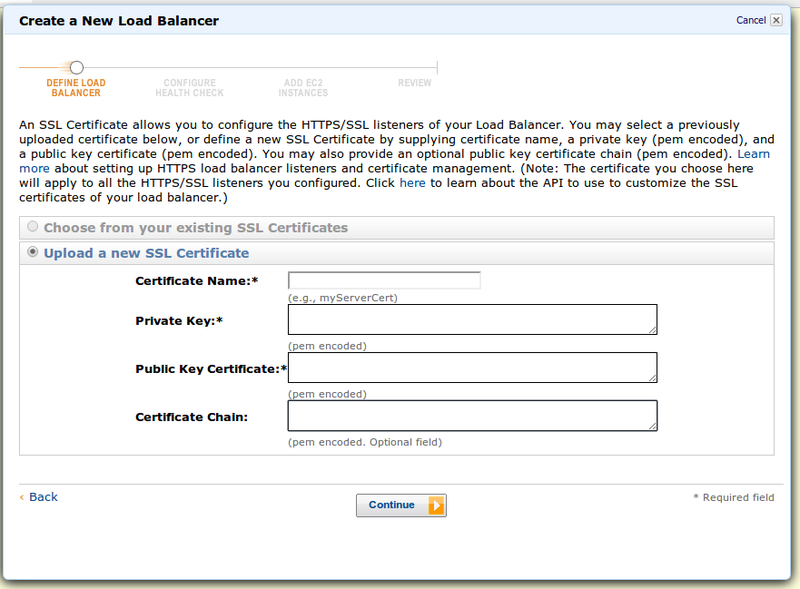
Далее настраиваем хелсчек — проверка здоровья хоста. Если хелсчек положительный, инстанс будет в списке на балансировку. Отрицательный — на инстанс не будут отправляться запросы:

Хелсчеки можно настроить на те же протоколы, что и балансировку, на http/https можно добавить имя странички или путь.
Ну и в финале — нужно выбрать инстансы, которые вы хотите добавить под ELB (на скриншоте просто пример)

Последний скрин — как всегда проверка деталей:
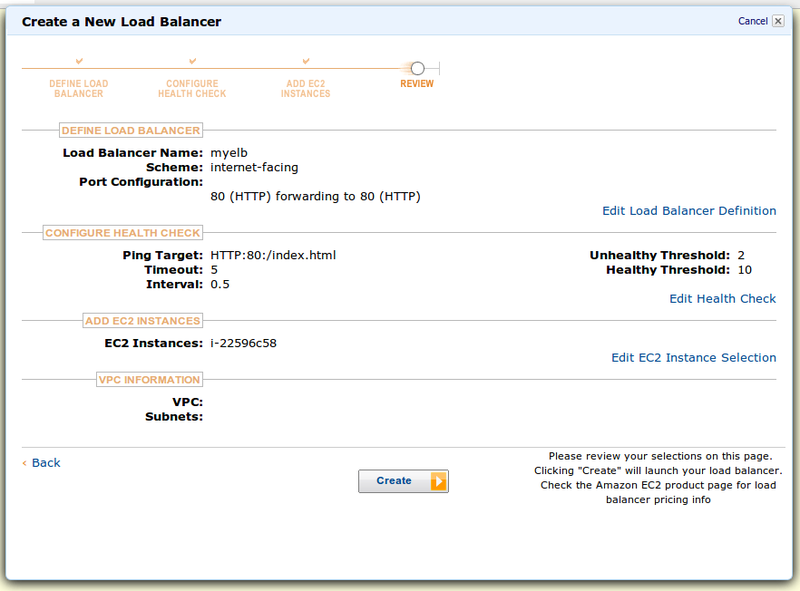
Просмотрели, решили, что всё ок и создали ELB.
Как настроить домен на ELB
У EC2 ELB есть 3 адреса, по которым к ним можно обращаться. Это не IP адреса, а URL:
- myelb-1161081434.us-east-1.elb.amazonaws.com (A Record)
- ipv6.myelb-1161081434.us-east-1.elb.amazonaws.com (AAAA Record)
- dualstack.myelb-1161081434.us-east-1.elb.amazonaws.com (A or AAAA Record)
Есть 2 пути настроить свой домен на ELB и зависят они от того, какие серверы имён вы используете. Рекомендуется использовать Amazon Route 53, т.к. он интегрирован с ELB и там всё легко настраивается через A запись:
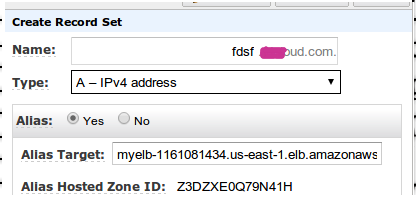
Если же вы используете другие DNS сервисы/серверы — ваш путь CNAME.
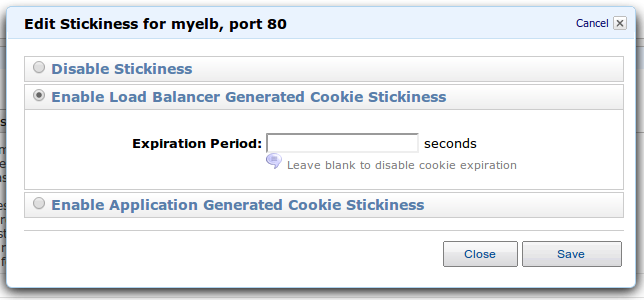
Sticky session
ELB способен обрабатывать куки для Sticky session. Эти функции можно настроить в конфигурации после создания ELB:
Автомасштабирование ELB
Тут хотелось бы рассказать о том, как масштабируется ELB и как он себя ведёт под нагрузкой. Я уже опубликовывал статью, в которой сравнивал производительность ELB, NGINX и HAproxy. Там я затронул момент масштабирования. ELB вертикально промасштабировался с t1.micto до m1.small:
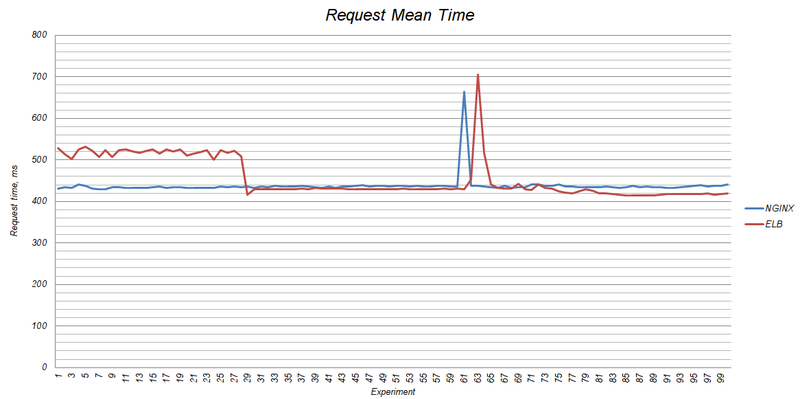
По словам представителей техподдержки Amazon Web Services при увеличении нагрузки на ELB проходит от одной до семи минут перед тем, как произойдёт масштабирование сервера. IP адрес может быть поменян, поэтому не рекомендуется использовать IP адреса для доменов (я описал выше выход из ситуации).
Для отдельных случаев ELB может быть «разогрет» до нужного шейпа, чтобы выдерживать большие нагрузки. «Разогрев производится» через запросы в техподдержку.
Автомасштабирование EC2/VPC
ELB играет немаловажную роль в автомасштабировании инстансов EC2. Имя ELB указывается в конфигах групп автомасштабирования и, собственно, всё крутится вокруг них. Подробнее об этом можно прочесто в моей статье.
У ELB ещё есть много нюансов работы, но основное я рассказал.
Есть ли у вас опыт работы с ELB? Интересные факты?
