Всем привет, мы - одна из команд GlowByte, специализируемся на DWH, потоковой аналитике, DevOps и факультативно-кастомной разработке.
Введение
Статья посвящена проблеме быстрой загрузки большого объема данных в HBase, когда стандартные методы вставки в таблицу не дают должной производительности. Опытом в ее решении и возникших в процессе трудностях хотим поделиться в рамках данной статьи.
Предпосылки
HBase используется нами как источник для быстрых лукапов в NRT-процессе, созданном на Apache Flink. В текущей задаче необходимо было подготовить агрегированные данные по карточным транзакциям клиентов и разово загрузить в HBase таблицу около 6 миллиардов строк по 2 поля в каждой (или иначе 12 миллиардов ячеек). Стандартные пакетные операции вставки в таблицу (HTable.putAll) при стандартных настройках HBase и распараллеливании вставки через Spark-приложение в лучшем случае выдавали скорость 35 тысяч записей в секунду. Оптимизации в виде отключения WAL (см. ниже) для вставок и увеличения кол-ва регионов на таблицу давали выигрыш в производительности максимум в 3 раза. Требовалось не менее 15 часов на загрузку такого объема данных в теории, а на практике около 24 часов (что является критичным для задачи), так как периодически в HBase запускался Major compaction и значительно снижал производительность вставки. Вывод: необходим более производительный метод загрузки данных.
Решение
HBase поддерживает механизм загрузки, называемый Bulk Load. Смысл данного механизма заключается в генерации HFile-ов (см. ниже) на стороне клиента и их подкладки стандартным механизмом в HBase. Данный механизм позволяет значительно снизить нагрузку на HBase и переложить ее на сторону клиента, обходя WAL и MemStore, создание списков для пакетной вставки, а также уменьшая нагрузку на сеть и т.д. Инструментом для генерации HFile-ов выбран Spark, как один из базовых и наиболее производительных инструментов экосистемы Hadoop, однако данный алгоритм можно повторить и с использованием MapReduce.
Ограничения
Обход WAL при загрузке данных в HBase является небезопасным и в случае падения HBase может привести к неконсистентности данных, поэтому его стоит использовать при инициализирующих загрузках либо при отсутствии жестких требований к их консистентности.
Архитектура HBase
HBase является распределенной базой данных (БД) типа key-value, которая может работать на большом наборе физических серверов. БД состоит из двух типов процессов, которые обслуживают систему - одной Master ноды и набора Region Server-ов. Для координации действий между процессами HBase использует Apache Zookeeper. Данные хранятся в виде отсортированных пар «ключ‑значение» в специальных HFile-ах в HDFS. Master нода отвечает за работу с метаданными HBase и административные действия. Region Server-a манипулируют пользовательскими данными, обслуживая один или несколько Region-ов (см. ниже); каждый регион отвечает за хранение некоторого набора HFile-ов.
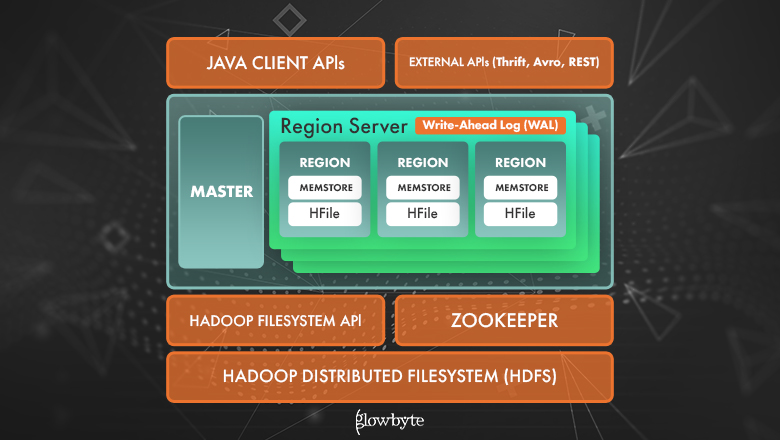
Master
Master - основной сервер в HBase-кластере. В кластере возможно настроить 2 мастера: active (текущий активный мастер) и backup (поднимается в случае падение активного). При подключении клиента происходит первичное обращение к Zookeeper, который возвращает адрес активной master-ноды. Master отвечает за:
Распределение регионов по Region Server-ам, обеспечивая балансировку.
Отслеживание работоспособности Region Server-ов через Zookeeper.
Создание/удаление таблиц (административные функции).
Запуск регулярных фоновых задач (minor/major compaction (ниже), split и т.д.).
Двумя наиболее важными фоновыми задачами в HBase являются:
Minor compaction - запускается автоматически и имеет низкий приоритет по сравнению с другими операциями HBase. Во время minor compaction происходит слияние нескольких HFile-ов в один для увеличения производительности (уменьшения дисковых операций). Физического удаления данных не происходит.
Major compaction - запускается как по некоторому набору триггеров (таймеры, низкая загруженность кластера, и тд), так и вручную. Имеет высокий приоритет среди остальных операций и может существенно замедлить работу кластера. Во время major compaction происходит: физическое удаление данных, дополнительное сжатие файлов (если требуется), слияние HFile-ов в один.
Region Server
Region server - сервер, который обслуживает один или несколько Region (регионов). Каждый регион работает с соответствующим диапазоном подряд идущих ключей и идентифицируется им в разрезе одного семейства колонок (см. далее в Структура таблиц). Также регион включает в себя:
Persistant Storage - основное хранилище данных. Физически данные располагаются в специальных файлах HFile в Hadoop FS и отсортированы по ключу.
Memstore - буфер на запись. Довольно дорого обновлять HFile для одной записи, так как все данные хранятся в отсортированном по ключу порядке (исключая быструю вставку в конец файла). Поэтому при записи данные накапливаются некоторое время в буфере. При наполнении MemStore до некоторого критического значения данные записываются в новый HFile.
На каждом из Region Server-ов расположен кэш на чтение, так называемый Block Cache. При любой конфигурации HBase всегда создается ровно один Block Cache на один Region Server. Он позволяет увеличить производительность чтения для записей, которые читаются часто. Чтение всегда происходит блоками, размер блоков и их загрузка в Block Cache настраивается для каждого семейства колонок (см. далее в “Структура таблиц”) отдельно, и составляет 64KB по умолчанию.
Также Region Server использует write ahead log (WAL) - лог-файл записи данных. Так как существует риск потери данных (сбой) при их попадании в Memstore, все записи первоначально попадают в лог-файл, что позволяет восстановить данные после сбоя.
Структура таблиц
Данные HBase организованы по таблицам. Каждая таблица содержит:
название таблицы, с заданным namespace (группа таблиц, аналогия схем в реляционных СУБД, например some_namespace:table_2) или без (например table_1)
row key - ключевое поле, обязательное для всех записей HBase, все значения которого уникальны в рамках одной таблицы и идентифицируют конкретную запись
набор column family (семейства колонок), где column family - группа колонок, данные которых физически хранятся рядом (в одном и том же HFile), с заданным алгоритмом сжатия (опционально), размером блока, bloom-фильтром и т.д. Множество колонок для разных строк в рамках одной column family может отличаться.
дополнительные метаданные таблицы (начальное кол-во регионов, алгоритм разделения (split-a) регионов и т.д.).
Рассмотрим некоторую тестовую таблицу table1, структура которой изображена на рисунке ниже. Первым и основным полем таблицы является RowKey, которое является полем ключей для всех записей, и содержит только уникальные значения. Название RowKey условное, оно не описывается в DDL и считается изначально заданным для всех таблиц. Данные в HFile-ах всегда отсортированы по RowKey (физически в файлах они также сортируются и по названию колонок). В таблице представлены 2 записи с ключами RowKey1 и RowKey2.

Обе строки содержат все Column Family или семейство колонок таблицы (ColumnFamily1, ColumnFamily2), множество которых фиксировано для всех строк и задается в DDL при создании таблицы. Разные строки в одном и том же семействе колонок могут содержать разные наборы колонок или Column/Qualifier (в терминах HBase), в том числе и пустые, что верно и в данном примере для записей с ключами RowKey1 и RowKey2 (в ColumnFamily1 и в ColumnFamily2 они содержат разные набор полей).
Ячейкой или Cell в HBase называется совокупность значений, идентификатором которых является связка RowKey+ColumnFamily+Qualifier. В данном случае связка RowKey1+ColumnFamily1+Column1 является идентификатором первой ячейки первой строки таблицы, содержащей список значений val1, val2. Каждому значению ячейки присваивается timestamp (ts:1, ts:2) - некоторое значение типа long, которое определяется либо пользователем, либо (по умолчанию) задается на основе текущего timestamp (System.currentTimestampMillis() в Java). Задание timestamp является в некотором роде версионированием значений одной ячейки. Значения хранятся отсортированными по timestamp (по убыванию) и по умолчанию, при обращении к конкретной ячейке, HBase возвращает значение с максимальным timestamp.
Bulk Load
Bulk Load - это API разработанное для быстрой (в сравнении с классической вставкой через put) инициализации большим объемом данных (<кол-во строк><среднее кол-во ячеек в строке> ~ 100 млн. и выше). Основной идеей Bulk Load является генерация HFile-ов вручную через MapReduce или Spark и затем их прямой подкладкой под таблицу с помощью стандартных утилит HBase, что позволяет избавиться от накладных расходов на MemStore, WAL, память серверов и загрузку кластера HBase, java GC и т.п.. Данное API не стоит использовать для загрузки данных при регламентной работе таблицы, так как падение загрузки может привести к их неконсистентному состоянию.
Рассмотрим один из возможных вариантов реализации Bulk Load с использованием Spark 2 и HBase Java Client API версии 1.2.0.
Реализация Bulk Load складывается из 2-ух основных этапов:
Генерация HFiles
Загрузка HFiles в HBase с помощью стандартных утилит
В свою очередь Генерация HFiles состоит из:
Конвертации строк датасета в набор ячеек
Сортировка всех ячеек по ключу
Конфигурации и запуска записи отсортированный ячеек в файлы (HFiles)
Ниже представлено подробное описание всех этапов загрузки.
Генерация HFiles
Генерация HFiles начинается с подключения к таблице HBase и создания конфигурации Bulk Load загрузчика. Для подключения к HBase и получения table и regionLocator используется стандартный HBase API. Создание конфигурации осуществляется через вызов MapReduce job-a (да, именно MapReduce, несмотря на загрузку Spark-ом, он используется только для переконфигурации загрузки). Также переконфигурация включает в себя задание целевого формата HFile-ов, для чего в различных версиях HBase используются классы HFileOutputFormat либо HFileOutputFormat2. Ниже представлен пример для библиотек HBase версии 2.2.5 и языка Java:
Конфигурация таблицы и формата загрузки данных
final TableName tableName = TableName.valueOf("tableName");
final Configuration HBaseConfiguration = HBaseConfiguration.create();
final Connection connection = ConnectionFactory.createConnection(configuration);
final Admin admin = connection.getAdmin();
final Table table = connection.getTable(tableName);
final RegionLocator regionLocator = connection.getRegionLocator(tableName);
final Job job = Job.getInstance(HBaseConfiguration);
HFileOutputFormat2.configureIncrementalLoad(job, table, regionLocator);
final Configuration jobConfiguration = job.getConfiguration();Предположим, что загружаемый RDD уже некоторым образом получен ранее в коде. Для загрузки его необходимо преобразовать в отсортированный по ключу+семейству+полю в порядке возрастания набор пар ключ-ячейка JavaPairRDD<...>. Пример подготовки RDD к загрузке в таблицу HBase с одним семейством и двумя полями (реализация RowKeyValueMapper зависит от формата данных в целевой таблице):
Генерация набора пар ключ-ячейка
static class RowKeyValueMapper implements PairFlatMapFunction<Row, ImmutableBytesWritable, KeyValue>, Serializable { … }
final JavaPairRDD<ImmutableBytesWritable, KeyValue> pairedRDD = rdd
.flatMapToPair(new RowKeyValueMapper())
.sortByKey();Непосредственно создание HFiles и их запись производится вызовом у JavaPairRDD метода saveAsNewAPIHadoopFile. Код генерации непосредственно самих HFile-ов для сформированного ранее RDD по пути “/some/hdfs/dir_path” в HDFS:
Генерация HFiles
pairedRDD.saveAsNewAPIHadoopFile(“some/hdfs/dir_path”, ImmutableBytesWritable.class, KeyValue.class, HFileOutputFormat2.class, jobConfiguration);Загрузка HFiles в HBase
Загрузка сгенерированных HFiles в HBase производится одним из утилитных классов библиотеки HBase:
org.apache.hadoop.hbase.tool.LoadIncrementalHFiles
org.apache.hadoop.hbase.tool.BulkLoadHFiles
Важно!!! С версии 2.2.0 класс org.apache.hadoop.hbase.tool.LoadIncrementalHFiles является deprecated, и с 3.0.0 его планируют удалить. Вместо этого предполагается использовать интерфейс org.apache.hadoop.hbase.tool.BulkLoadHFiles.
LoadIncrementalHFiles
Загрузка HFile-ов с помощью класса LoadIncrementalHFiles путем передачи конфигурации, имени таблицы и пути к ранее сгенерированным HFile-ам.
Загрузка HFiles с помощью LoadIncrementalHFiles
final LoadIncrementalHFiles loadIncrementalHFiles = new LoadIncrementalHFiles(jobConfiguration);
loadIncrementalHFiles.doBulkLoad(
new Path(“some/hdfs/dir_path”),
admin,
table,
regionLocator);BulkLoadHFiles
Загрузка HFiles с помощью BulkLoadHFiles
final BulkLoadHFiles bulkLoadHFiles = BulkLoadHFiles.create(jobConfiguration);
bulkLoadHFiles.bulkLoad(tableName, “some/hdfs/dir_path”);Оптимизация загрузки и рекомендации
Список рекомендаций/оптимизаций, с которыми стоит ознакомиться перед загрузкой:
HBase хранит данные в байтовом представлении. Если требуется чтение данных таблицы через утилиту hbase shell либо через Hue в человекочитаемом виде, то необходимо сначала преобразовать значения в строковый формат и только потом в байтовый.
Не стоит оценивать время записи в HBase только в количествах строк. Опираясь на чужую зависимость времени загрузки от кол-ва строк и линейно экстраполируя на свой случай, вы скорее всего ошибетесь. Важную роль играет среднее количество ячеек в строке и их суммарный средний объем в байтах. Для оценки в первом приближении будет достаточно показателя <среднее кол-во ячеек>=<кол-во строк><среднее кол-во полей> (при условии, что DDL таблицы и настройки HBase совпадают для всех загрузок). Для более точной оценки стоит вычислить средний размер всех ячеек строки через Result.getTotalSizeOfCells(...) для некоторой выборки строк вашего датасета.
Если ключи в строковом представлении распределены неравномерно, стоит использовать подсаливание ключей (например, добавление хэша от ключа либо хэша по модулю кол-ва регионов таблицы в виде префикса - <key_hash>|<key>). Данная оптимизация позволяет равномерно распределить загружаемые ячейки по executor-ам Spark-а и получить заметный выигрыш во времени (в особенности при сортировке ключей). Однако стоит не забывать тот факт, что при подсаливании ключи изменяются и при обращении к таблице по ключу необходимо заранее рассчитать соль.
При равномерном распределении ключей скорость загрузки данных для Bulk Load линейно масштабируется при изменении кол-ва регионов в таблице HBase и наличии должных вычислительных мощностей для Spark (на 1 регион таблицы поднимается 1 executor).
Правильно рассчитывайте минимальное кол-во регионов для таблицы при загрузке. В кластере HBase задан параметр hbase.hregion.max.filesize, равный по умолчанию 256Mb, который ограничивает размер HFile. В случае его превышения в фоновом режиме будет запущена одна из операций minor/major compaction, вызов которой (в меньшей или большей степени) скажется на производительности HBase. Чтобы этого не происходило, выбирайте кол-во регионов так, чтобы размер наибольшего региона не превышал заданного порога с некоторым запасом (например, при ограничении в размере файла в HBase в 256Mb для таблицы с 100 млн равномерно распределенных по ключам строк по 5 ячеек в каждой с средним размером ячейки в 10 байт общий объем равен 5^10 byte ~ 4768 Mb; минимальное кол-во регионов равно [ 4768 Mb / 256 Mb ] = 19 регионов; и с запасом выбираем 20 регионов).
Для таблиц большого размера (порядка миллиардов ячеек) стоит использовать сжатие семейства колонок (snappy, gz, ...). API Bulk Load использует данную информацию при чтении DDL в HBase и генерирует HFiles сразу в сжатом виде. Данная оптимизация дает заметное уменьшение количества дисковых операций.
Результаты
С помощью Bulk Load API, а также оптимизаций указанных выше, для загрузки 12 млрд равномерно распределенных по ключам ячеек в таблицу с 70 регионами и сжатием snappy для семейств колонок в среднем затрачивалось 4.5 часа (с учетом различной загрузки кластера это время могло варьироваться). В результате удалось добиться скорости примерно в 740 тыс. ячеек в секунду или 370 тыс. строк (из 2-ух полей каждая) в секунду, что в 4 раза быстрее чем средняя скорость загрузки через стандартные операции вставки.
Правильное использование Bulk Load API дает заметный выигрыш в скорости (~4 раза) вставки больших объемов данных в HBase и, с учетом описанных ограничений, рекомендуется к использованию только для инициализирующих загрузок, так как может привести к неконсистентному состоянию таблицы при ее регламентной работе.
