Comments 33
Строки без номера места — это решения, участвующие «вне конкурса».
решение, выдающее 36.12% — это, скорее всего, просто программная ошибка. Например, решение периодически возвращает undefined.
undefined расценивается как false (к ответу применяется
Так просто 36% не сделать, для этого нужно постараться. Решение, набирающее 36%, сделать так же сложно, как и решение, набирающее 64%. Доказательство: если бы существовало простое решение, набирающее 36%, то инверсией этого решения можно было бы получить 64%.
Единственная догадка — автор перепутал true и false в ответе, то есть случайно инвертировал своё решение.
!!).Так просто 36% не сделать, для этого нужно постараться. Решение, набирающее 36%, сделать так же сложно, как и решение, набирающее 64%. Доказательство: если бы существовало простое решение, набирающее 36%, то инверсией этого решения можно было бы получить 64%.
Единственная догадка — автор перепутал true и false в ответе, то есть случайно инвертировал своё решение.
это при условии одного if:
if (а) { return 0; } else { return 1; }
в таком коде это не сработает (нужно все инвертировать):
`if (a) return 0; if (b) return 1; if (c) return 0;...
Могли в какой-то доминирующей ветви инвертировать.
могли где угодно инвертировать (я не видел исходников). Ваше утверждение верно лишь при одном if.
Иначе это реально постараться нужно чтобы на 36% сделать.
судя по исходникам, пришлось реально стараться:
https://github.com/hola/challenge_word_classifier/blob/master/submissions/5732127f93f2f29d3c9acc28/solution.js
или была ошибка в строчке:
https://github.com/hola/challenge_word_classifier/blob/master/submissions/5732127f93f2f29d3c9acc28/solution.js
или была ошибка в строчке:
if (filters[ruleKey]())
return true;
Вы правы с ошибкой в строчке, это мое решение, изначально задумывалось как детектор не-слов, и чтобы логика была более «прямой» детектор возвращал true когда обнаруживал не-слово, что обратно логике которая нужна в задании. Инверсия же делалась в раннере, который я написал как отдельный модуль и который выполнял запросы и выводил результаты. Поменять перед отправкой, ну да, видимо забыл). Когда появился «официальный» раннер, времени запускать на нем свои решения не было, и интереса уже тоже. Забавно получилось, а сперва сильно расстроился увидев свое решение решительно самым последним))
Может, конкурсант понял, что первое место с начала ему не светит, и решил занять первое место с конца.
UFO just landed and posted this here
Очень интересное задание, будем ждать следующего конкурса :) Жаль, что времени не удалось много уделить этому конкурсу…
Nonwords from high-order Markov models are significantly more rare in the test set than those from low-order models. This is due to the particular algorithm the test generator uses: if a generated nonword happens to be in the dictionary, it is discarded, and a new nonword is generated, possibly from a different model. Because the output of high-order models very closely resembles English, this happens to them much more often. We decided not to correct for this phenomenon, and have low-similarity nonwords dominate the set.
Этот «феномен» очень заметно влияет на рейтинговую таблицу: если перенормировать итоги, считая все девять моделей не-слов равновероятными, то, например, программа с 7-ого места опускается на 37-ое.
Иначе говоря, часть победивших решений заточена не столько на «распознавание слов из предоставленного словаря», сколько на «распознавание не-слов из предоставленного генератора».
Идеальное решение — это хранить весь словарь, что довольно проблематично, учитывая ограничение в размере данных. Поэтому все решения заточены под текущий генератор, чьи-то больше, чьи-то меньше. Если бы генератор был другим, и решения были бы другими.
Это всё понятно. Я о том, что если бы не было условия «тестируем тем же генератором», или если бы генератор не был дан изначально — то решения были бы совсем другими.
В реальных задачах такого рода статистические свойства шума тоже обычно стабильные и могут учитываться при решении.
Так у меня нет претензий к условиям конкурса :-)
Я просто обращаю внимание на аспект этих условий, который не особенно акцентировался, но при этом оказал существенное влияние на результат.
Другая «интересная» особенность генератора — то, что он почти не выдаёт не-слов вида «допустимое слово + 's» или «допустимое слово + типичный английский суффикс», что позволило хитрецам существенно сжать хранимый словарь, оставив в нём только основы слов.
В выходные хочу прогнать опубликованные решения с такой «десятой моделью не-слов» и посмотреть, что получится.
Я просто обращаю внимание на аспект этих условий, который не особенно акцентировался, но при этом оказал существенное влияние на результат.
Другая «интересная» особенность генератора — то, что он почти не выдаёт не-слов вида «допустимое слово + 's» или «допустимое слово + типичный английский суффикс», что позволило хитрецам существенно сжать хранимый словарь, оставив в нём только основы слов.
В выходные хочу прогнать опубликованные решения с такой «десятой моделью не-слов» и посмотреть, что получится.
Непонятно, почему минусуют попытки анализа результатов: ведь именно заэтим результаты и выложены, чтобы с ними поиграться?
Вот результаты прогона всех решений на 100 блоках, когда все десять моделей не-слов (девять официальных и мой «суффиксатор») равновероятны:
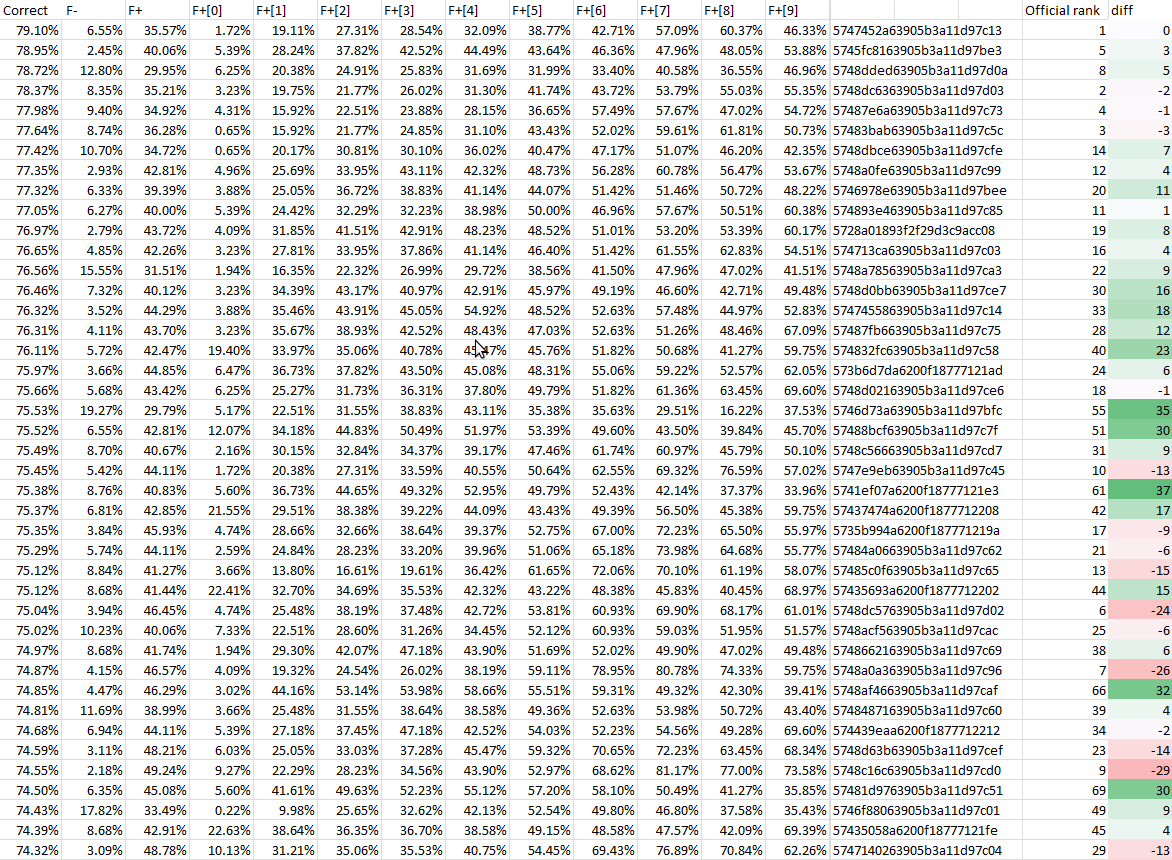
Решение №6 тут сильно опустилось, потому что выигрывало на самообучаемости. (Запустил на ночь тест на 10000 блоках, чтобы посмотреть на результат ещё и с самообучаемостью.)
Решение №9 сильно опустилось из-за моего суффиксатора, потому что основано на стеммере; но в целом на топ-40 мой суффиксатор не так уж сильно повлиял: F+9 у них в районе 40..60%, одного порядка с F+ на высокоуровневых моделях Маркова.
Несколько решений из пятого и шестого десятка официальной рейтинговой таблицы поднимаются в топ-40 за счёт выдающихся результатов на высокоуровневых моделях Маркова — лучших, чем на низкоуровневых! Наверное, стоит дать их авторам какой-нибудь поощрительный приз? (Моё собственное решение всё равно не вошло ни в официальный топ-40, ни в перенормированный, так что конфликта интересов у меня нет.)
Вот результаты прогона всех решений на 100 блоках, когда все десять моделей не-слов (девять официальных и мой «суффиксатор») равновероятны:

Решение №6 тут сильно опустилось, потому что выигрывало на самообучаемости. (Запустил на ночь тест на 10000 блоках, чтобы посмотреть на результат ещё и с самообучаемостью.)
Решение №9 сильно опустилось из-за моего суффиксатора, потому что основано на стеммере; но в целом на топ-40 мой суффиксатор не так уж сильно повлиял: F+9 у них в районе 40..60%, одного порядка с F+ на высокоуровневых моделях Маркова.
Несколько решений из пятого и шестого десятка официальной рейтинговой таблицы поднимаются в топ-40 за счёт выдающихся результатов на высокоуровневых моделях Маркова — лучших, чем на низкоуровневых! Наверное, стоит дать их авторам какой-нибудь поощрительный приз? (Моё собственное решение всё равно не вошло ни в официальный топ-40, ни в перенормированный, так что конфликта интересов у меня нет.)
Исходник суффиксатора
class SuffixModel {
constructor(dictionary){
this.dictionary = dictionary;
this.suffixes = ["'s", "'s", "'s", "'s", "'s", "'s", "'s", "'s", "'s", "'s", "'s", "'s", "'s", "'s",
"ed", "ed", "er", "er", "ing", "ing", "ness", "ion", "al"];
}
learn(){}
generate(random){
return this.dictionary[random.integer(0, this.dictionary.length-1)]+
this.suffixes[random.integer(0, this.suffixes.length-1)];
}
}
большинство решений было заточено под данный генератор, который, по условиям конкурса, остается неизменным.
Если б генератор был другим, то и решения были б другими — также и наоборот, нет смысла запускать изначальные решения под какой-то другой генератор.
Если б генератор был другим, то и решения были б другими — также и наоборот, нет смысла запускать изначальные решения под какой-то другой генератор.
Кто бы сомневался. Но исследование всё равно интересное: как проявят себя решения при изменении характеристик шума.
Мне интересны сильные и слабые стороны каждого подхода к решению задачи, а не тупо «кому достанется килобакс».
Если же интересоваться только судьбой килобакса, то действительно, смысла нет.
Если же интересоваться только судьбой килобакса, то действительно, смысла нет.
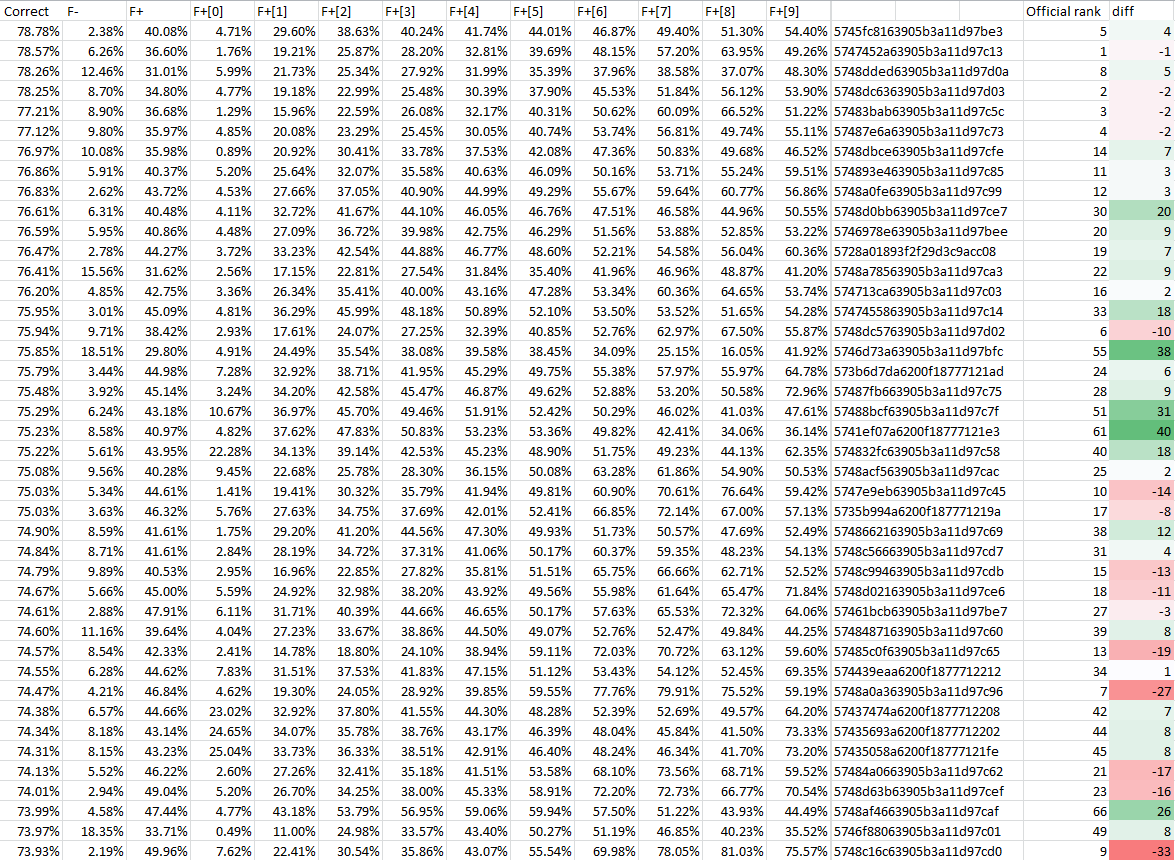
Результаты после 10000 блоков с моим «альтернативным» генератором: самообучающееся решение №6, как и ожидалось, сильно поднялось вверх; остальные решения слегка поменялись местами, но в целом картина по сравнению с после ста блоков не изменилась. Некоторые решения перескочили на ±10 позиций; я заглянул внутрь них, там разные комбинации «стеммер+блум», так что изменение их результата на десятые доли процента можно считать случайным.
Предваряя официальное объявление результатов самообучающихся решений, можно сделать вывод, что решение №6 (за авторством Balzac) — единственное, сильно выступающее и в «классическом», и в «самообучающемся» зачёте :-)
Предваряя официальное объявление результатов самообучающихся решений, можно сделать вывод, что решение №6 (за авторством Balzac) — единственное, сильно выступающее и в «классическом», и в «самообучающемся» зачёте :-)

хмм, а в этом списке все решения? Своего как-то не нашел
Простите, невнимательно прочитал пост. Список самых медленных будет опубликован?
я оказался не только самым тормозным на хабре но и самым тормозным по решению
Как вам это удалось? На что тратится время?
Предположил, что если слова состоят из двух склееных слов из словаря, то это некорректное слово. По скольку сильно урезаную версию словаря я туда все-таки загрузил, он проходит дважды по словарю. Неэффективно конечно, но решение отправил за несколько часов до конца конкурса, ещё учеба, работа и сон, поэтому оптимизацией заниматься не особо хотелось. Рассчитывал, что простые фильтры дадут результат лучше, но похоже, что у меня получилось сделать самое «странное» решение :)
Sign up to leave a comment.
Конкурс по программированию на JS: Классификатор слов (предварительные результаты)