Comments 247
Согласен полностью. Динамические языки это классно когда маленькие вещи пишешь а потом просто АД. Согласен что не просто так много новых языков они статические потому что есть спрос и понимание. Я нашол себе GO для этих вещей. Стаческий, быстры и код одинако похож у разных людей.
Вполне логично. Динамические языки это просто подмножество статических. Во многих статических языках вполне могут существовать типы any (dynamic) для «истинно динамического типа данных» и variant для суммы типов из фиксированного набора (алгебраический тип данных).
Динамический язык — это по сути статический, в котором из типов есть только «any».
Динамический язык — это по сути статический, в котором из типов есть только «any».
по-мойму как раз таки наоборот. Динамические языки имеют более общей смысл, как в математике натуральные числа являются подмножеством целых.
Мы же говорим не о математике, а о программировании.
Но даже если и сравнить с числами — никакого более общего смысла в динамических языках нет. В статических языках появляются дополнительная возможность — типизация на этапе компиляции, которой нет в динамических. При этом в современных статических языках есть все возможности из динамических. То есть этой типизацией можно пользоваться, а можно и не пользоваться. То есть динамические имеют меньше возможностей по сравнению с современными статическими (хотя их правильнее наверное называть комбинированными, т.к. они сочетают и динамику и статику), и поэтому яляются подмножеством. Чистая теория множеств:)
Но даже если и сравнить с числами — никакого более общего смысла в динамических языках нет. В статических языках появляются дополнительная возможность — типизация на этапе компиляции, которой нет в динамических. При этом в современных статических языках есть все возможности из динамических. То есть этой типизацией можно пользоваться, а можно и не пользоваться. То есть динамические имеют меньше возможностей по сравнению с современными статическими (хотя их правильнее наверное называть комбинированными, т.к. они сочетают и динамику и статику), и поэтому яляются подмножеством. Чистая теория множеств:)
А что при использовании динамического языка мешает:
а) указывать тип переменной каким-то образом (доки, спец. средства, вроде type hints для питона и т.п.)
б) сделать анализатор кода, который будет пытаться выводить тип переменных на основе подсказок о типе
в) запускать анализатор для всего проекта перед запуском самого проекта (и назвать эту операцию «компиляция»).
г) при ошибке анализатора о несоответствии типов запретить запускать программу
Понятно, что сделать анализатор кода для динамического языка намного труднее. Но и статический анализ для статических языков неидеален.
а) указывать тип переменной каким-то образом (доки, спец. средства, вроде type hints для питона и т.п.)
б) сделать анализатор кода, который будет пытаться выводить тип переменных на основе подсказок о типе
в) запускать анализатор для всего проекта перед запуском самого проекта (и назвать эту операцию «компиляция»).
г) при ошибке анализатора о несоответствии типов запретить запускать программу
Понятно, что сделать анализатор кода для динамического языка намного труднее. Но и статический анализ для статических языков неидеален.
что при использовании динамического языка мешает
Ничего, кроме того что вы предлагаете самому написать новый статический язык с новыми правилами… По сути, вы предлагаете самому написать аналог TypeScript для JavaScript, это, конечно, возможно, но смысл?
Но в моём случае это будет не другой язык. а тот же самый. И этап В в моём случае можно отключить, при этом программа будет работать.
Вообще, NeoCode писал, что проверять соответствие типов ещё до запуска можно только в статически типизированных языках. Однако, это не так. Просто в статических языках эта проверка входит в спецификацию языка, а для динамического — нет.
Уточню: указание типа на шаге А не должно никак влиять на работу программы. Тогда, с одной стороны, язык остаётся тем же, а с другой — появляются способы проверить программу на наличие ошибок с типами до её запуска.
Вообще, NeoCode писал, что проверять соответствие типов ещё до запуска можно только в статически типизированных языках. Однако, это не так. Просто в статических языках эта проверка входит в спецификацию языка, а для динамического — нет.
Уточню: указание типа на шаге А не должно никак влиять на работу программы. Тогда, с одной стороны, язык остаётся тем же, а с другой — появляются способы проверить программу на наличие ошибок с типами до её запуска.
Вы сейчас предлагаете сделать из динамического статический с помощью костылей и подпорок. Так как 90% кода с которым программист имеет дело это код библиотек языка и чужих библиотек, то реализация такой проверки лишь затруднит программирования и не даст нормального эффекта. По сути, вы предлагаете усложнить динамический язык определением типа, реализовать сложный парсер и статический анализатор и по сути все равно будите получать большую часть проблем динамического языка. Смысл если можно перейти на полностью статический или комбинированный (полустатический-полудинамический) язык?
UFO just landed and posted this here
И пока от этого нет спобоба уйти
Кстати, меня давно интересует вопрос, а почему не ввести в конце концов в JS опциональные статические типы? Это же никак не сломает старый код, а жизнь программистов на Node.js и т.п. станет значительно удобнее. Кстати, это позволит уйти от нелогичных приведений типов, которые почти все JS программисты сильно недолюбливают (знаю потому что у меня самого JS второй язык и часто общался с чистыми JS разработчиками)
Вообще, NeoCode писал, что проверять соответствие типов ещё до запуска можно только в статически типизированных языках. Однако, это не так.
Однако, это так. Статические анализаторы для динамически типизируемых языков могут вывести тип правой части присваивания только в достаточно простых случаях. И то, только когда речь о полной доступности исполняемого кода.
Вообще, NeoCode писал, что проверять соответствие типов ещё до запуска можно только в статически типизированных языках. Однако, это не так. Просто в статических языках эта проверка входит в спецификацию языка, а для динамического — нет.Как только вы добавите её в свой инструмент (неважно — запускаемый отдельно или прописанный в стандартной библиотеке как расширение) — вы получите статически типизированный язык.
Только смысла в этом нет. Статически типизированные языки хороши тем, что в ним программа состоит из «жёстких» кусков, где всё статически описано и чему можно верить. Ну и некоторое количество динамики там и сам (зыбкие места, где всё опасно и сложно — какой-нибудь парсер JSON'а типичный пример), которая опасна, но её мало, можно как-то смириться и аккуратно с ней разобраться. Когда же у вас в программе только маленькие кусочки описаны на статическом языке, то это общую картину мира меняет слабо.
Это будет интерпретируемый язык со статической (или почти статической) типизацией.
В отличие от этого, в современных статических языках динамика в каком-то виде уже встроена (полиморфизм в С++, система сообщений и динамические возможности ObjectiveC, dynamic в C#, any/variant в Boost, интерфейсы в Go и т.д.)
В отличие от этого, в современных статических языках динамика в каком-то виде уже встроена (полиморфизм в С++, система сообщений и динамические возможности ObjectiveC, dynamic в C#, any/variant в Boost, интерфейсы в Go и т.д.)
В статических языках появляются дополнительная возможность — типизация на этапе компиляции, которой нет в динамических.
Возьмём Common Lisp. Он компилируемый, при этом типизация в нём строгая, динамическая, с опциональными декларациями типов. Так вот в нём эта возможность есть.
при этом типизация в нём строгая, динамическая, с опциональными декларациями типов
С таким же успехом типизацию можно назвать строгой, статической с обширной системой динамических типов. На самом деле, это комбинированная типизация, которая не является ни полностью статической, ни полностью динамической, так что пример не подходит.
Но, следуя этой логике, C# тоже можно назвать языком с динамической строгой типизацией, с обширной системой статических типов. А значит, он не подходит для примера статического языка с динамическими возможностями.
Не подходит, поэтому не стоит рассматривать C# как пример чистого статического языка. Но в любом статическом языке есть возможность работать с Object и приводить Object к нужному интерфейсу и обратно к Object, этого достаточно для реализации любой динамической типизации. Да, при этом количества кода будет несколько больше чем в чистом динамическим языке, но динамическая типизация возможна в любом статическом языке (в ветке ниже описано как это сделать в 99.99% случаев).
И всё же она там не статическая. Типы вполне можно менять в рантайме. Более того, декларации типов нужны лишь чтобы получать более оптимизированный скомпилированный код. При несоответствии типов будут лишь ворнинги, хотя можно при возникновении ворнингов выдавать ошибку при сборке.
UFO just landed and posted this here
То есть, вы хотите сказать «Что мешает при использовании динамического языка сделать его статическим»? Да ничего, просто это же будет не динамический язык.
UFO just landed and posted this here
В динамически типизируемых языках появляется возможность менять типы переменных в рантайме, а не в статических возможность не менять. Компилятор статически типизируемого языка ограничивает набор допустимых выражений присваивания, ограничивает множество возможностей, доступных программисту.
Когда вам явно потребуется такая возможность, объявите переменную с типом Object и запихивайте в неё что хотите
А как из этого Object вытащить данные\вызвать метод? Без рефлексии, разумеется.
когда понадобится, приведите к нужному интерфейсу — даже «вытаскивать» не понадобится
И как мы узнаем к какому именно интерфейсу приводить?
А как мы узнаем в динамическом языке что у данной переменной есть нужный метод? По большему счету нет большей разницы между:
1. variable.myMethod()
и
2. interface MyMethodInterface { String myMethod()}
((MyMethodInterface) variable).myMethod()
И в том и другом случае если метода myMethod нет или переменная на самом деле не реализует этот интерфейс — будет ошибка.
P.S. Ну и не надо забывать про instanceOf оператор Java (и его аналоги в дргуих языках) позволяющий узнать какой реально тип сейчас в переменной и соотвестственно изменять логику.
1. variable.myMethod()
и
2. interface MyMethodInterface { String myMethod()}
((MyMethodInterface) variable).myMethod()
И в том и другом случае если метода myMethod нет или переменная на самом деле не реализует этот интерфейс — будет ошибка.
P.S. Ну и не надо забывать про instanceOf оператор Java (и его аналоги в дргуих языках) позволяющий узнать какой реально тип сейчас в переменной и соотвестственно изменять логику.
Совершенно разные интерфейсы могут иметь методы\поля с одинаковым названием. Этих самых интерфейсов может быть бесчисленное множество + пользователь может создавать свои.
Похоже не все понимают о чем идет речь, приведу пример. Пусть у нас есть 2 интерфейса:
Если делать так, как предлагаете вы, то в конечном итоге мы просто будем пытаться одурачить статическую типизацию жуткой пеленой if'ов:
А если програмист написал еще один интерфейс:
Динамической типизации абсолютно по барабану какой интерфейс у объекта, важно лишь то, что объект должен иметь метод\делегат\функтор\whatever Execute().
Похоже не все понимают о чем идет речь, приведу пример. Пусть у нас есть 2 интерфейса:
interface IProgram
{
void Execute();
}
interface IAction
{
void Execute();
}
Если делать так, как предлагаете вы, то в конечном итоге мы просто будем пытаться одурачить статическую типизацию жуткой пеленой if'ов:
void Foo(object obj)
{
if (obj is IProgram)
{
var program = (IProgram) obj;
program.Execute();
}
else if (obj is IAction)
{
var action = (IAction) obj;
action.Execute();
}
else ... // и т.д. 1000 раз для всех остальных интерфейсов с методом Execute()
}
А если програмист написал еще один интерфейс:
interface IPrisoner
{
void Execute();
}
IPrisoner prisoner = ...;
Foo(prisoner); // ???
Динамической типизации абсолютно по барабану какой интерфейс у объекта, важно лишь то, что объект должен иметь метод\делегат\функтор\whatever Execute().
void Foo(dynamic obj)
{
obj.Execute();
}
Надо просто объявить общий интерфейс IExecutable с единственным методом Execute(), а IProgram, IAction унаследовать от него. Так полностью соблюдается логика использования языка — контракт должен быть явно прописан.
Попытки же вызвать у любого объекта метод с просто совпадающим названием — это потенциальная ошибка. Название может совпадать у принципиально разных и несовместимых методов. Явно определение всего стремиться минимизировать число таких слепых вызовов. Если уж вы точно знаете, что делаете то используйте рефлексию, но это явно не типичная ситуация.
Попытки же вызвать у любого объекта метод с просто совпадающим названием — это потенциальная ошибка. Название может совпадать у принципиально разных и несовместимых методов. Явно определение всего стремиться минимизировать число таких слепых вызовов. Если уж вы точно знаете, что делаете то используйте рефлексию, но это явно не типичная ситуация.
Так и есть. В результате, мы всегда приходим к явно прописанному контракту, и в конечном итоге получаем криво-использованную-статическую-типизацию. Так что такое нельзя назвать заменой динамической типизации. А вот, например, dynamic в C# — можно.
Госсподя ты боже ж мой. Вопрос «сколько динамичности нам нужно в статически типизированных языках» он такой, филосовский: можно и полную динамику прикрутить, было бы желание… Да посмотрите на какие-нибудь сигнатуры в GNU C++, в конце-концов, а?
Да, это, в конце-концов, было решено не вносить в стандарт и в последних версиях GCC сигнатуры не поддерживаются, но это ведь было частью самого «ортодоксального» из языков со статической типизацией! Причём в GNU C++ сигнатуры поддерживались уже тогда, когда не то, что о «dynamic в C#» никто не слышал, а и когда самого C# ещё не было!
Да, это, в конце-концов, было решено не вносить в стандарт и в последних версиях GCC сигнатуры не поддерживаются, но это ведь было частью самого «ортодоксального» из языков со статической типизацией! Причём в GNU C++ сигнатуры поддерживались уже тогда, когда не то, что о «dynamic в C#» никто не слышал, а и когда самого C# ещё не было!
Не понимаю при чем здесь сигнатуры, и как они вообще связаны с динамической типизацией. Судя по вашей ссылке, это те же самые интерфейсы, только с утиной статической типизацией. Ну а шаблоны в C++ появились еще раньше сигнатур.
В то же время dynamic — это такой же ассоциативный массив, как например объекты в JS. Та что сравнение совершенно неуместно.
Но в любом случае я так и не понял к чему вы написали этот комментарий, без обид :) Я рассуждал о том, что «приведение к Object никак не может заменить динамическую типизацию».
В то же время dynamic — это такой же ассоциативный массив, как например объекты в JS. Та что сравнение совершенно неуместно.
Но в любом случае я так и не понял к чему вы написали этот комментарий, без обид :) Я рассуждал о том, что «приведение к Object никак не может заменить динамическую типизацию».
В результате, мы всегда приходим к явно прописанному контракту
Контракты в динамическом языке точно так же есть, вызывая переменную
var variable = getExecuteVariable();
variable.execute()
вы требуете чтобы полученный динамический тип реализовывал метод execute(), то есть предполагаете контракт «метод getExecuteVariable() вернет тип, который содержит метод execute» иначе у вас все сломается. В статическом языке контракты просто прописаны явно (по правилу явное всегда лучше неявного).
Object variable = getExecuteVariable();
((IExecutable) variable).execute()
Причем если раньше ещё можно было относить к плюсам динамического языка скорость кодирования, то с развитием умных компиляторов с их быстрыми подстановками типов и увеличением размеров программ это уже мало существенно.
P.S. Динамический язык хорош для небольших скриптов и программ, проблема в том что динамические языки, которые разрабатывались для написания коротких программ, вроде JavaScript и Php сейчас используются для создания гиганских приложений, на что они изначально не были рассчитаны. Конечно, они не исчезнут (legacy и привычки программистов очень сложно меняются), но рано или поздно в них появиться статическая типизация и они станут комбинированными языками. ИМХО.
В конце-концов использование чего-нибудь вроде JavaScript для создания гигантских приложений приведет к тому, что появится среда разработки которая будет достаточно подробно анализировать код, чтобы выявлять все эти неявные контракты, знать какие на самом деле методы и переменные есть в конкретный момент у данной переменной и явно указывать на данные ошибки.
Но это по-факту приведет к тому, что мы сделаем JavaScript типизированным языком, просто типы будут прикручены грубыми костылями.
Но это по-факту приведет к тому, что мы сделаем JavaScript типизированным языком, просто типы будут прикручены грубыми костылями.
В статическом языке контракты просто прописаны явно (по правилу явное всегда лучше неявного).
Да, я про это и говорю. Нам нужно явно привести объект к необходимому типу. Но для этого нужно знать тип. Да, если операторы is/instanceOf в C#/Java, но они лишь позволяют проверить на объект на соответствие определенному типу (который мы опять же указываем явно). Единственный способ вызвать метод Execute() у совершенно произвольного объекта — использовать рефлексию. Для обычных CLR объектов (которые не являются ExpandoObject) dynamic в конечном итоге приводит к рефлексии.
Честно говоря я не понимаю, почему у кого-то сложилось впечатление (судя по минусам не у вас одного) о том, что я сторонник динамической типизации. Нет-нет, я как раз таки всеми руками за статическую типизацию, собственно по тем же причинам, которые вы указали в P.S.
Тип мы и так известен — IExecutable. На объект наложен четкий контракт, что он должен быть исполняемым. Если уж вы так хотите исполнить метод у объекта который данный контракт не поддерживает, то не удивляйтесь что это приходиться делать через рефлексию.
Нету же никакого IExecutable.
Если вы так хотите несмотря ни на что вызывать метод у любого объекта, то используйте рефлексию. Чем она вас не устраивает?
А нормальный способ это создать общий интерфейс
А нормальный способ это создать общий интерфейс
А нормальный способ это создать общий интерфейсОбщий интерфейс мы можем сделать только для своего кода. В случае third-party бинарников или даже поделки коллег из соседнего отдела нужно или очень настойчиво попросить об этом автора или ildasm.
Чем она вас не устраивает?Небольшая вырезка из моего предыдущего комментария:
Единственный способ вызвать метод Execute() у совершенно произвольного объекта — использовать рефлексию. Для обычных CLR объектов (которые не являются ExpandoObject) dynamic в конечном итоге приводит к рефлексии.И только так. Если Borz считает иначе, пусть приведет пример. Для совершенно произвольного объекта, разумеется. Хоть буду знать, заслуженно ли я получил достаточно минусов (и в карму в том числе) за свою попытку проиллюстрировать его слова, или нет…
В случае third-party бинарников или даже поделки коллег из соседнего отдела нужно или очень настойчиво попросить об этом автора или ildasm.
Создаем пустые классы-наследники от классов third-party бинарников, которые реализуеют нужные нам интерфейсы и уже подобные wrapper классы, которые все реализуют один нужный нам интерфейс с методом execute.
То есть
public class ThridPartyClass { // чужой класс
public void execute() {
// что делает
}
}
public interface IExecuted {
void execute();
}
public class ThridPartyClassWrapper extends ThridPartyClass implements IExecuted {
}
ThridPartyClassWrapper вполне уже реализует IExecuted интерфейс и может использоваться для приведения типов.
я и не говорил, что без рефлексии обойтись можно при для вызова метода. Я говорил как запихнуть произвольный объект в переменную. Использование рефлексии в статическом и динамическом языке только в том — используется она в нужный нам момент или везде где только придётся.
А вызвать метод у произвольного объекта можно так (на основе вашего примера):
Да, с рефлексией, но с точечной.
P.S.: минусы не ставил
А вызвать метод у произвольного объекта можно так (на основе вашего примера):
public class Foo {
public Foo(Object obj) {
if (obj instanceof IExecutor) {
((IExecutor) obj).execute();
return;
}
// Тут пишем в лог ахтунг про "какого хера класс без нужного интерфейса?"
try {
final Method execute = obj.getClass().getDeclaredMethod("execute");
execute.invoke(obj);
} catch (NoSuchMethodException | InvocationTargetException | IllegalAccessException e) {
e.printStackTrace();
}
}
}
interface IExecutor {
void execute();
}
Да, с рефлексией, но с точечной.
P.S.: минусы не ставил
В статическом языке контракты просто прописаны явно (по правилу явное всегда лучше неявного).Да, я про это и говорю. Нам нужно явно привести объект к необходимому типу. Но для этого нужно знать тип. Да, если операторы is/instanceOf в C#/Java, но они лишь позволяют проверить на объект на соответствие определенному типу (который мы опять же указываем явно). Единственный способ вызвать метод Execute() у совершенно произвольного объекта — использовать рефлексию. Для обычных CLR объектов (которые не являются ExpandoObject) dynamic в конечном итоге приводит к рефлексии.
Честно говоря я не понимаю, почему у кого-то сложилось впечатление (судя по минусам не у вас одного) о том, что я сторонник динамической типизации. Нет-нет, я как раз таки всеми руками за статическую типизацию, собственно по тем же причинам, которые вы указали в P.S.
вызвать метод Execute() у совершенно произвольного объекта
Может привести хоть какой-то практический пример когда нужно вызвать метод у совершенно произвольного объекта? Так чтобы это не нарушало все принципы ООП и было хоть мало мальским оправданным с точки зрения качества кода?
Если мы говорим о своих объектах, то никто не мешает нам добавить им явный интерфейс, если мы используем чужие объекты с одинаковым методом, то фабрика, wrapper или proxy легко позволят привести их к одному виду. Ну и создавать публичный API, который принимает любой объект у которого есть метод Execute, тоже выглядит бредово. Честно говоря, не могу представить ни одного случая когда возможность «вызвать метод Execute() у совершенно произвольного объекта» было бы обоснованно, чем-то большим чем «так мы сможем наговнокодить на 5 минут быстрее».
Единственный способ вызвать метод Execute() у совершенно произвольного объекта — использовать рефлексию.
Нет, в Java можно ещё использовать кодегенерацию на лету, для отдельного объекта это дольше, но для огромного потока разных объектов — быстрее.
Может привести хоть какой-то практический пример когда нужно вызвать метод у совершенно произвольного объекта?Разумеется нормальный разработчик такой хренью страдать и не будет. Он одумается намного раньше.
Нет, в Java можно ещё использовать кодегенерацию на лету, для отдельного объекта это дольше, но для огромного потока разных объектов — быстрее.Не знаю как в Java, но в C# такой способ так или иначе сводится к рефлексии, ведь нам нужно достать MethodInfo в качестве операнда для инструкции callvirt.
Почему нужно? Берем и пишем строку «pakage mypackage; public class Class1234 { public void execute(» + object.getClass() + " p) {" + object.getClass() + ".execute() };" закидываем её в класс loader одной из библиотек по генерации байт кода, генерим класс и вызываем class1234.execute(object); Для одиночного класса — дорого, но если каждый раз приходят тысячи и десятки тысяч классов каждого типа, то создав мапу <тип, сгенеренный класс> можно их выполнять намного быстрее рефлексии.
Для упоротых извращенцев можно просто эмиттить что угодно без рефлексии, достаточно знать опкод и строковое название метода.
А в скале есть structural types:
Конечно, так почти не делают (без нужды), но техническая возможность удобный duck typing занести есть :)
import scala.languageFeature.reflectiveCalls
def executePoly(x: { def execute(): Unit }): Unit = {
x.execute()
}
class A {
def execute(): Unit = { println("Hello from A") }
}
class B {
def execute(): Unit = { println("Hello from B") }
}
class C
executePoly(new A)
executePoly(new B)
//Won't compile
//executePoly(new C)
Конечно, так почти не делают (без нужды), но техническая возможность удобный duck typing занести есть :)
Примерно так мы узнаем в динамическом языке:
>>> a = 1
>>> b = '1'
>>> hasattr(a, '__add__')
True
>>> hasattr(b, '__add__')
True
>>> a + a
2
>>> b + b
'11'
>>> a + b
Traceback (most recent call last):
File "", line 1, in TypeError: unsupported operand type(s) for +: 'int' and 'str'
>>> a = 1
>>> b = '1'
>>> hasattr(a, '__add__')
True
>>> hasattr(b, '__add__')
True
>>> a + a
2
>>> b + b
'11'
>>> a + b
Traceback (most recent call last):
File "", line 1, in TypeError: unsupported operand type(s) for +: 'int' and 'str'
Однако аналог классов типов в динамических языках сложно сделать. Мультиметоды все-таки не совсем то, хочется диспечеризации по ожидаемому типу результата.
Может я чего не понимаю в колбасных обрезках, но «диспечеризации по ожидаемому типу результата» — это вообще редкость. Обычно речь идёт про разные типы параметров и в этом смысле C++ и Java ведут себя так же, как Python или, прости господи, PHP…
UFO just landed and posted this here
Я и говорю — редкость. В скольки языках это есть из первых хотя бы 50 и сколько людей с ними «работают»? Только не говорите про C++ — там это есть в одном очень сильно исключительном месте. Если уж считать C++, то можно Perl засчитать…
UFO just landed and posted this here
Взятие адреса функции. Если одно и то же имя определяет много функций, то какой именно указатель вы получите зависит от того, куда вы захотите этот адрес засунуть (в сложных случаях можно сразу преобразовать имя фукнции к соответствующему указателю).
UFO just landed and posted this here
Можете показать пример?Тут скорее нужно разбирать пример, когда это не работает. Но вот, пожалуйста:
cat test.cc
#include <iostream>
void foo(void (*p)(int)) {
(*p)(0);
}
void bar(int) {
std::cout << "This is foo(int) !" << std::endl;
}
void bar(float) {
std::cout << "This is foo(float) !" << std::endl;
}
int main() {
foo(&bar);
}
$ g++ test.cc -o test
$ ./test
This is foo(int) !
Во всех случаях, с которыми я сталкивался, надо было руками делать static_cast к нужной сигнатуре.Эффект смещённой выборки, почти на 100%. Когда всё работает вы даже не задумываетесь над этим. Когда вдруг что-то не срабатывает — вы обращаете на проблему внимание. Скажем если бы foo была шаблонной функций и могла бы принять любой из двух адресов — это бы не сработало, нужен был бы static_cast — но static_cast не является чем-то исключительным, это просто одна из конструкций, которая гарантированно позволяет выбрать один из нескольких возможных вариантов!UFO just landed and posted this here
Но вот, пожалуйста:
Я, конечно, все понимаю, но это — диспетчеризация по типу параметра, а не по типу результата. Про тип результата мне самому очень интересно узнать.
Для того чтобы понять, что вы неправы нужно уметь считать до двух.
Вас, наверное, сбила с тольку похожесть этого примера на традиционный:
Они действительно очень похожи, но, обратите внимание, в первом случае у нас одна функция
Вас, наверное, сбила с тольку похожесть этого примера на традиционный:
cat test.cc
#include <iostream>
void foo(int) {
std::cout << "This is foo(int) !" << std::endl;
}
void foo(float) {
std::cout << "This is foo(float) !" << std::endl;
}
int main() {
foo(1.f);
}
$ g++ test.cc -o test
$ ./test
This is foo(float) !
Они действительно очень похожи, но, обратите внимание, в первом случае у нас одна функция
foo (хотя две функции bar), а во втором — их две. Подумайте над этим на досуге…Эмм, а какая разница, сколько функций
foo? У вас есть некая переменная, ее тип — void (*p)(int), вы присваете ей значение &bar (то, что оно потом передается в функцию уже, не важно). Выбор между bar происходит на основании того, что у одной из них параметр — int, а у другой — float. Я где-то не прав, я что-то не вижу?Вы не видите (или не хотите видеть) очевидного: у
Можно этот пример привести к такому:
&bar нет значения. Оно появляется когда вы &bar куда-нибудь засовываете. Во всех других местах в языке выражение x = y тип x никак не будет влиять на значение y, а тут будет.Можно этот пример привести к такому:
Всякие объявления
$ cat test.cc
#include <iostream>
void foo(void (*p)(int)) {
(*p)(0);
}
void z(int) {
std::cout << "This is foo(int) !" << std::endl;
}
void z(float) {
std::cout << "This is foo(float) !" << std::endl;
}
int main() {
void (*x)(int);
void (*y)(float);
x = z;
y = z;
std::cout << "x= " << (void *)x << std::endl;
std::cout << "y= " << (void *)y << std::endl;
}
$ g++ test.cc -o test
$ ./test
x= 0x4008b6
y= 0x4008df
Вы не видите (или не хотите видеть) очевидного: у &bar нет значения.Как это нет? А что присваивается влево?
Вот как бы когда то, что справа влияет на значение того что слева — это «диспечеризации по ожидаемому типу результата».
А, понятно, очередная терминологическая путаница. Для меня диспетчеризация по типу результата — это вот так:
int bar()
{
return 0;
}
string bar()
{
return "q";
}
int a = bar(); //0
string b = bar(); //q
Не понял где путаница.
Если для вас важны
Если для вас важны
int и string, тогда, конечно, ничего не поделать. В C++ все эти чудеса происходят только и исключительно с указателями на функцию. Но если хочется просто функцию вызвать, тогда это… всегда пожалуйста:Всякие объявления
$ cat test.cc
#include <iostream>
void foo(int) {
std::cout << "This is foo(int) !" << std::endl;
}
void foo(float) {
std::cout << "This is foo(float) !" << std::endl;
}
struct FOO {
typedef void (*PI)(int);
typedef void (*PF)(float);
operator PI() { return &foo; }
operator PF() { return &foo; }
};
struct FOO bar() {
return FOO();
}
int main() {
void (*x)(int);
void (*y)(float);
x = bar();
y = bar();
std::cout << "x= " << (void *)x << std::endl;
std::cout << "y= " << (void *)y << std::endl;
}
khim@khim-x1:/tmp/2$ g++ test.cc -o test
khim@khim-x1:/tmp/2$ ./test
x= 0x40089d
y= 0x4008c6
Если для вас важны int и string, тогда, конечно, ничего не поделать.
Для меня важен overload resolution. И в С++
Return types are not considered in overload resolution.
overload resolution касается только одного очень частого случая выражения: вызова функции. И возвращаемые из функции выражения там действительно нигде участвовать не могут.
Но кроме вызова функций в C++ есть целая куча разных видов выражений. И у них у большинства есть, представляете, результаты. И в некоторых случаях таки ожидаемый тип результата влияет на значение выражения.
Если происходит не вызов функции, а, скажем присваивание — то тип результата может влиять на значение выражения. И при возврате значения из функции с помощью
С чего вы решили, что я говорю именно про вызов функции — для меня загадка.
Но кроме вызова функций в C++ есть целая куча разных видов выражений. И у них у большинства есть, представляете, результаты. И в некоторых случаях таки ожидаемый тип результата влияет на значение выражения.
Если происходит не вызов функции, а, скажем присваивание — то тип результата может влиять на значение выражения. И при возврате значения из функции с помощью
return — тоже может. И ещё в нескольких местах. Во всех этих местах происходит выбор одного указателя из нескольких возможных.С чего вы решили, что я говорю именно про вызов функции — для меня загадка.
Динамический язык — это по сути статический, в котором из типов есть только «any».
Неправда. Тип подразумевает множество значений и операции над ними. Если в динамических языках только 1 тип, то как в них возможен полиформизм?
class A(object):
def foo(self, a):
print('A', a)
class B(A):
pass
class C(A):
def foo(self, a):
print('C', a)
b = B()
b.foo(1) # A 1
c = C()
c.foo(2) # C 2
Ну и
>>> abs('-1')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: bad operand type for abs(): 'str'
Просто в динамических языках тип определяется в рантайме, а в статических — на этапе компиляции. Они не подмножества/надмножества относительно друг друга.
Тип any/dynamic на деле не всегда означает динамическое устройство
c#
Runtime error
c#
dynamic x = "a";
x++;
Runtime error
Но ведь скомпилируется! А переопределить поведение в этом случае технически вполне возможно, только скорее всего никому не нужно.
Думаю, если в динамическом языке написать какую-нибудь фигню вроде инкремента сложного нечислового объекта, то тоже будет Runtime error.
Думаю, если в динамическом языке написать какую-нибудь фигню вроде инкремента сложного нечислового объекта, то тоже будет Runtime error.
Эта вот «фигня» для всех разная. Для меня, например, «5 + 2 + 'a'» тоже «фигня». Поэтому и есть сильная/слабая, статическая/динамическая типизация. В случае с первыми «фигня» строго задекларирована и не нужно гадать. Это про ту самую «неопределённость» из статьи.
В вашем примере именно строгая динамическая типизация. Как в питоне, например.
В вашем примере именно строгая динамическая типизация. Как в питоне, например.Даже если и так, что с того? Я лишь написал, что мне это не нравится («фигня»).
А это, как раз пример слабой типизации, а к статике/динамике вообще отношения нет.
Например в c# этот код скомпилируется, за счет неявного приведения, но конечный тип известен.
И вот еще, открыл песочницу с питоном, написал туда
print(5 + 2 + "a")
Вывод
TypeError: unsupported operand type(s) for +: 'int' and 'str'
Потому что в питоне, как уже замечено, типизация строгая.
А можно в питоне что вернет функция getIsEmailCorrect(«fff@mail.ru») чужого класса, если нет документации и код внутри черт ногу сломит? Я вот по названию могу предположить что он может вернуть как boolean, так и integer (1 — корректный, -1 — не корректный), String («правильно»/«не правильно») и даже какой-то Object. Иногда можно запустить код и проверить, а если это очень сложно (код работающий с базой данных/сетью/очень много сложных аргуементов и прочее) или банально долго?
На один шаг дальше:
ещё на один шаг дальше:
И с каждым таким шагом отладка становится всё веселее и веселее
a = 0
for x in [5, 2, "a"]:
a += x
print(a)
#
print(sum([5, 2, "a"]))
ещё на один шаг дальше:
for doc in db.x.find({}):
a += doc['x']
И с каждым таким шагом отладка становится всё веселее и веселее
Не обязательно, представьте миллион вызов функций getId() в коде из разных чужих классов. Во всех случаях, с которыми проверил getId() возвращает числовое значение, а в продакшене возьмет и вернет String из одного класса, потому что в одном из чужих классов решили что значение «не определенно» для id — корректное и у вас все упадет. Проблема в том что пока выполнение до этого класса не дойдет, вы не узнаете что он конкретно вернет (если не лазить по его внутренностям и это большими буквами не написано в его документации).
Так вот нет. В случае статической типизации, ты можешь явно указать контракт возвращаемого значения. Например, в c# указав int, ты никогда не получишь null или строку и т.д. Всегда будет число.
Можно, только с# это не динамический язык, по крайне мере не полностью динамический. Если ты пишешь String getId() — то что тут динамического? В scala тоже можно определять переменную как var result = 0, она же не считается динамическим языком.
Редкий статический язык поддерживает возможность описать функцию от Int, а передать в нее Any, предполагая что оно на самом деле целое.
Бессмысленный холивар, который опубликовал кто-то за бугром, это что прибавляет авторитетности статье?
А я вот интерпретируемые языки не люблю. И что? Кого это интересует?
>Знаете, какой DSL лучше всего описывает HTML? Я открою вам секрет: это HTML
Не стоит забывать что HTML (вместе с CSS и JS) — это прежде всего формат сериализации DOM. Ну и дополнительно — формат общения с поисковиками.
И, внезапно, чтобы писать веб-приложения — не обязательно использовать html! У меня вот веб-проект на React, который почти не использует html.
Что также удивительно — html довольно плохой формат сериализации DOM-а.
Не стоит забывать что HTML (вместе с CSS и JS) — это прежде всего формат сериализации DOM. Ну и дополнительно — формат общения с поисковиками.
И, внезапно, чтобы писать веб-приложения — не обязательно использовать html! У меня вот веб-проект на React, который почти не использует html.
Что также удивительно — html довольно плохой формат сериализации DOM-а.
Сдается мне это самообман. Ваш замечательный веб-проект отдает клиентскому браузеру именно HTML.
Да, а компилятор gcc выдает двоичные инструкции для процессора, и при этом программисту не нужно ничего о них знать — скажете вы.
Это верно, вот только HTML, в отличие от процессорных инструкций, постоянно развивается и рано или поздно вам может понадобиться залезть в самую глубину вашего React и что-то там подправить в генерации HTML-кода. буквально пару аттрибутов. А потом еще и еще.
Да, а компилятор gcc выдает двоичные инструкции для процессора, и при этом программисту не нужно ничего о них знать — скажете вы.
Это верно, вот только HTML, в отличие от процессорных инструкций, постоянно развивается и рано или поздно вам может понадобиться залезть в самую глубину вашего React и что-то там подправить в генерации HTML-кода. буквально пару аттрибутов. А потом еще и еще.
Ну это спорно.
Вы эти изменения сможете инкапсулировать в созданных вами React компонентах нижнего уровня. Остальные же компоненты даже об этом не узнают.
А возьмем проект на чистом HTML. Изменения затронут весь код.
Вы эти изменения сможете инкапсулировать в созданных вами React компонентах нижнего уровня. Остальные же компоненты даже об этом не узнают.
А возьмем проект на чистом HTML. Изменения затронут весь код.
Реакт-код попадает в браузер в виде JS-кода. Который потом напрямую строит DOM, посредством реакта. Т.е. рендеринг минует стадию HTML.
И как все это дружит с миллионом технологий кэширования страниц, картинок, стилей? Просто «всё то же самое, но своё» прикручивается как-то сбоку скриптами, кастомными хранилищами и прочим?..
Статика (включая сам JS-код) нормально кэшируется и на клиенте, и на сервере, поскольку это сетевой уровень, никакого отношения к HTML и DOM не имеющий. Более того, с различными клиент-сайд html-шаблонизаторами и DOM-генераторами кэширование зачастую лучше работает на динамических страницах (а их подавляющее большинство сейчас субъективно), поскольку статическая часть страницы передаётся только один раз, а не рендерится на сервере на каждый запрос, а по сети гуляют только данные с минимальным оверхидом.
UFO just landed and posted this here
А какой хороший?
Я так понимаю, что HTML язык разметки. Т.е. стояла такая задача, что есть у нас текст и надо его разметить — привязать какие-то атрибуты к кусочкам чтоб получился гипертекст.
Причем, наверное, вначале обычно пользовались просто текстовыми редакторами. Поэтому он такой. Какой-нибудь yaml было бы неудобно так использовать, т.к. надо было бы много в тексте менять. А тут вносишь локальную правку и все — кусочек помечен как ссылка, например.
Я так понимаю, что HTML язык разметки. Т.е. стояла такая задача, что есть у нас текст и надо его разметить — привязать какие-то атрибуты к кусочкам чтоб получился гипертекст.
Причем, наверное, вначале обычно пользовались просто текстовыми редакторами. Поэтому он такой. Какой-нибудь yaml было бы неудобно так использовать, т.к. надо было бы много в тексте менять. А тут вносишь локальную правку и все — кусочек помечен как ссылка, например.
Как язык разметки гипертекста — HTML неплох. Речь не об этом.
Была фраза: «Знаете, какой DSL лучше всего описывает HTML? Я открою вам секрет: это HTML». И тут есть логическая ошибка.
Получить HTML — не цель. Цель — получить DOM. А исходные данные — не гипертекст, а какая-то декларативная модель UI (кнопочки, блоки), и только внизу там где-то DIV-ы, завязанные на CSS и JS.
Поэтому применительно к шаблонам логика про «юзайте HTML в шаблонах» — не работает. А критикуемые автором eDSL — отлично работают.
Была фраза: «Знаете, какой DSL лучше всего описывает HTML? Я открою вам секрет: это HTML». И тут есть логическая ошибка.
Получить HTML — не цель. Цель — получить DOM. А исходные данные — не гипертекст, а какая-то декларативная модель UI (кнопочки, блоки), и только внизу там где-то DIV-ы, завязанные на CSS и JS.
Поэтому применительно к шаблонам логика про «юзайте HTML в шаблонах» — не работает. А критикуемые автором eDSL — отлично работают.
Мы хотели получить пусть большое и страшное, но генерируемое компилятором сообщение об ошибке, когда мы попытаемся записать null в булевое поле.
То ли я чего-то не понимаю, то ли автор:
object foo {
def foo(a: Boolean): Unit = {
println(a)
}
def bar(num: Int): Boolean = {
println("Hello from bar")
if (num == 0) {
return null
}
true
}
def main(args: Array[String]) {
foo(null)
foo(bar(1))
foo(bar(0))
}
}
При компиляции выдаёт ошибки.
Ну и для проблем с null вроде как есть Optional.
Даже для Python есть «type hints»
Это сделали не для того, чтобы добавить подобие статической типизации, а для более простого анализа кода в ИДЕ и подобными штуками. Что, в свою очередь, нужно в основном для документирования. Например, есть некая функция, которая принимает аргумент с именем phone. Ты не знаешь, какой тип аргумента с именем phone подразумевался автором. Если прописать в определении функции тип аргумента, то при зажатом ctrl при наведении на вызов этой функции, PyCharm покажет, какой тип нужен. В принципе, PyCharm мог это делать и через docstring, но там были свои ограничения на подсказку типа.
Вот вам пример: предметно-ориентированные языки (DSL) — это способ решения проблем, или ещё один способ их создания?
А при чём тут типизация? DSL можно и на статических языках делать.
Кто из нас не страдал от метапрограммирования в Ruby или мэпов в Clojure?
Опять же, причём тут типизация? Страдать от метапрограммирования можно на любом языке, который умеет его. Через интроспекцию и в java можно проблем себе создать. Чтобы не страдать, достаточно лишь использовать метапрограммирование с умом.
Это сделали не для того, чтобы добавить подобие статической типизации, а для более простого анализа кода в ИДЕ и подобными штуками.
Это типизация, так как значению приписывается тип и при этом она статическая, так как инструментам надо его знать до выполнения.
Через интроспекцию и в java можно проблем себе создать.
Как раз проблема интроспекции именно в том, что она динамически типизированная.
> Это типизация, так как значению приписывается тип и при этом она статическая, так как инструментам надо его знать до выполнения.
Типизация в Питоне уже есть, она динамическая и PEP на неё никак не повлиял. Никакой тип значению не приписывается: чтобы вы не написали в аннотациях к параметрам, тип переменных от этого не изменится никак. Инструментам не надо знать тип до выполнения: аннотации могут помочь IDE лучше (чем сейчас) угадывать тип переменной для удобства программиста, но не более того. Даже если вы везде пропишете точные type hints, не всегда будет возможно точно определить тип любой переменной в принципе.
Типизация в Питоне уже есть, она динамическая и PEP на неё никак не повлиял. Никакой тип значению не приписывается: чтобы вы не написали в аннотациях к параметрам, тип переменных от этого не изменится никак. Инструментам не надо знать тип до выполнения: аннотации могут помочь IDE лучше (чем сейчас) угадывать тип переменной для удобства программиста, но не более того. Даже если вы везде пропишете точные type hints, не всегда будет возможно точно определить тип любой переменной в принципе.
Значит теперь в Питоне две типизации — динамическая для рантайма и компилятора и статическая для IDE, причем они необязательно между собой согласованы.
Получается, чтобы предоставить какой-то уровень удобства им именно надо знать тип до выполнения. То есть это типизация и при этом статическая.
Инструментам не надо знать тип до выполнения: аннотации могут помочь IDE лучше (чем сейчас) угадывать тип переменной для удобства программиста, но не более того
Получается, чтобы предоставить какой-то уровень удобства им именно надо знать тип до выполнения. То есть это типизация и при этом статическая.
Ну тогда у питона давно две типизации, ведь в docstring тоже можно типы прописывать. И в js их 2. И в php тоже 2.
Это не статическая типизация, а попытка угадать тип без выполнения.
Где «угадать тип» == типизация, а «без выполнения» == статическая
Угадать — это не типизация. Нарушение типизации вызывает ошибку, а при угадывании в лучшем случае варнинг.
Поискал в википедии — там типизация == проверка статус сообщений о нарушении правил не указан
Исходный коммент был про «подобие» типизации. Я лично нахожу в статической проверке типов отличающийся только статусом сообщения много подобия :)
Исходный коммент был про «подобие» типизации. Я лично нахожу в статической проверке типов отличающийся только статусом сообщения много подобия :)
Стати́ческая типиза́ция — приём, широко используемый в языках программирования, при котором переменная, параметр подпрограммы, возвращаемое значение функции связывается с типом в момент объявления и тип не может быть изменён позже (переменная или параметр будут принимать, а функция — возвращать значения только этого типа)
Если тип не может быть изменён, то попытка его изменить вызывает ошибку. Если он всё же изменяется, пускай и с варнингом, то это не статическая типизация.
А что тот тип, который внутри себя приписывает редактор переменной по тайпхинту может быть изменен в рантайме?
То есть C++ и С это языки с динамической типизацией? Ведь там никто не мешает программисту взять и записать int в первый байт переменной double и вообще устроить ад с любыми типами через указатели.
Такая же ситуация и с Common Lisp: даже если задекларировать типы, компилятор лишь выдаст варнинг при их несоответствии. Декларация там нужна, чтобы компилировать более оптимизированный код. Типизация там от декларации типов не становится статической.
Знаете, какой DSL лучше всего описывает HTML? Я открою вам секрет: это HTML.Не всегда: необходимость закрывающих тэгов периодически доставляет неудовольствие…
Не могу не прорекламировать Red http://www.red-lang.org/
на мой взгляд крайне интересный язык
на мой взгляд крайне интересный язык
Бредятина. Чел экстраполирует личные фейлы на целый мир.
Есть среди фанатов статической типизации такая традиция: каждый год они собираются и хоронят языки с динамической типизацией. Ну-ну.

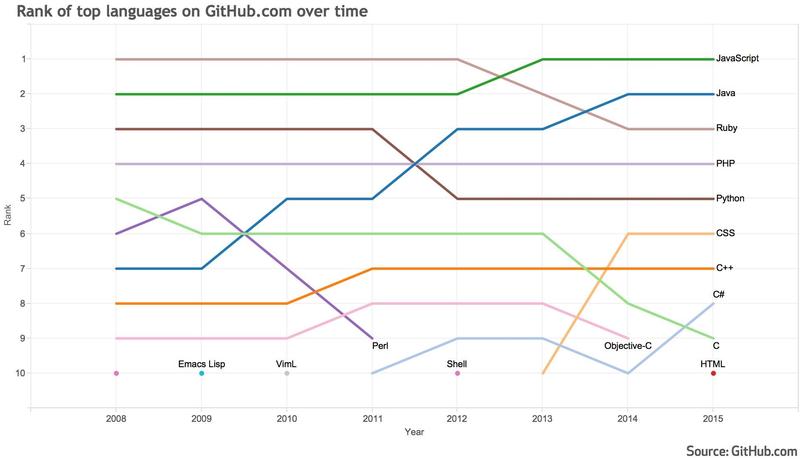
Ну, Джаваскрипт поднялся на 1 место, при этом Руби и Питон опустились на 2, а Джава поднялась на 5 мест и догоняет Джаваскрипт, у которого приличная фора.
Скорее аудитория C плавно перетекает Java, все остальное в мире стабильно
Кто это с си на джаву перетекает? С плюсов уж скорее, но там уже кто мог, уже перетёк. Джава скорее отражает популярность андроида.
UFO just landed and posted this here
Вообще было бы правильно смотреть на данные и по ним делать выводы.
Интересно, у гитхаба можно вытащить данные по всем коммитам человека за определенный период, либо хотя-бы за-star-енные репозитории? Если да, то можно было бы построить весьма интересный датасет.
Интересно, у гитхаба можно вытащить данные по всем коммитам человека за определенный период, либо хотя-бы за-star-енные репозитории? Если да, то можно было бы построить весьма интересный датасет.
UFO just landed and posted this here
Можно powerbi использовать :)
PHP сама стабильность. Прикольно звучит)
Что удивительно они их правильно хоронят. Есть определённый предел сложности программ, которые можно реализовать на динамических языках. Вот когда люди его достигают — они вдруг «прозревают» и уходят в статические языки (или пристраивают костыли к динамическим языкам чтобы они стали статически типизированными (всякие TypeScript, Closure и прочее).
Но при этом «прозревшие» забывают о том, что подавляющее большинство программистов по-прежнемц решают гораздо более простые задачи и у них нужды в статически типизированных языках не возникает! Что, собственно, и показывает ваш граф…
Но при этом «прозревшие» забывают о том, что подавляющее большинство программистов по-прежнемц решают гораздо более простые задачи и у них нужды в статически типизированных языках не возникает! Что, собственно, и показывает ваш граф…
Кстати, интересно почему в динамические языки вроде Php и JS, которые давно подбираются к этому пределу сложности все-таки не вводят новые опциональные статические типы? По-моему, это вполне логичный шаг для них получить комбинированную типизацию…
PHP давно последовательно вводит некое подобие статической типизации — тайп хинтинг в сигнатурах функций и методов. Описав типы параметров разработчик функции или метода может быть уверен, что они будут данного типа (в строгом режиме вызов функции вызовет ошибку, в обычном — типы приведутся к указанным), то же с возвращаемым значением функции — увидев что функция возвращает строку я уверен, что не придёт ни число, ни массив — транслятор этого не допустит.
О, спасибо. Жалко что ничто подобное пока не реализовано в JS.
Вообще тайп-хинты в JS наверняка помогли бы реализовать гораздо более эффективный рантайм, а значит мы бы сразу увидели преимущество TypeScript над JS в плане первоманса
Closure Compiler от Гугла ввел подобие типов для того чтобы js-to-js компилятор мог побольше соптимизировать developers.google.com/closure/compiler/docs/js-for-compiler?hl=en

А разве html и css это языки программирования? ИМХО это языки разметки (в общем случае — декларативного описания данных), вообще совершенно другая категория, ближе ко всяким ini-файлам, документам rtf, pdf и т.п.
На самом деле все дело привычки. Когда много пишешь на языках со статической типизацией, сложно переключиться на языки с динамической, и наоборот.
Статически типизированные ЯП могут приблизиться по элегантности и и краткости в части определения данных только тогда, когда используется динамический вывод типа. В общем случае он позволяет не указывать тип переменных явно, но выявить все типы на этапе компиляции, и главное, определить все ошибки неправильного использования объектов, связанные с типизацией.
Проблема заключается в том, что автоматический вывод типов на текущий момент не работает.
Например, давайте напишем небольшую функцию на python и вызовем ее с некорректными аргументами:
Ага! Нам сказали, что нельзя складывать строки с числами и указали конкретное место в коде, где произошла ошибка (ну, если бы это был файл)
И теперь тоже самое на Haskell
ШТА?? Место ошибки не указано, а Possible Fix только сбивает с толку
Статически типизированные ЯП могут приблизиться по элегантности и и краткости в части определения данных только тогда, когда используется динамический вывод типа. В общем случае он позволяет не указывать тип переменных явно, но выявить все типы на этапе компиляции, и главное, определить все ошибки неправильного использования объектов, связанные с типизацией.
Проблема заключается в том, что автоматический вывод типов на текущий момент не работает.
Например, давайте напишем небольшую функцию на python и вызовем ее с некорректными аргументами:
>>> addlen = lambda l: [e + len(l) for e in l]
>>> addlen(['3','4'])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 1, in <lambda>
TypeError: cannot concatenate 'str' and 'int' objects
Ага! Нам сказали, что нельзя складывать строки с числами и указали конкретное место в коде, где произошла ошибка (ну, если бы это был файл)
И теперь тоже самое на Haskell
Prelude> let addlen l = let x = fromIntegral $ length l in map (+x) l
Prelude> addlen ['3', '4']
<interactive>:47:1:
No instance for (Num Char) arising from a use of `addlen'
Possible fix: add an instance declaration for (Num Char)
In the expression: addlen ['3', '4']
In an equation for `it': it = addlen ['3', '4']
ШТА?? Место ошибки не указано, а Possible Fix только сбивает с толку
Давайте немножко покорректнее,
— статическая типизация сработала и обнаружила ошибку.
— динамическая сработала только тогда, когда вы дошли до выполнения именно этой ветки кода (т.е. динамическая как раз не сработала тогда, когда сработала статическая)
— вы использовали с одной стороны массовый python, с другой — академичный Haskell
— вид исходного кода то же другой.
Я переписал на F# ваш код и получил ошибку на этапе набора кода:
Можете сами попробовать www.tryfsharp.org/Create
— статическая типизация сработала и обнаружила ошибку.
— динамическая сработала только тогда, когда вы дошли до выполнения именно этой ветки кода (т.е. динамическая как раз не сработала тогда, когда сработала статическая)
— вы использовали с одной стороны массовый python, с другой — академичный Haskell
— вид исходного кода то же другой.
Я переписал на F# ваш код и получил ошибку на этапе набора кода:
let addLen = fun x -> [for e in x -> e + String.length e]
Можете сами попробовать www.tryfsharp.org/Create
Даже хуже — не "— динамическая сработала только тогда, когда вы дошли до выполнения именно этой ветки кода", а «динамическая сработала только тогда, когда вы дошли до выполнения именно этой ветки кода ПРИ КАКИХ-ТО ДОПОЛНИТЕЛЬНЫХ УСЛОВИЯХ»
Статическая типизация обнаружила наличие ошибки, а не саму ошибку! Тут большая разница
По языкам претензий вообще не понял, я ж не их долю на рынуке сравнивал
Ну и ссылка у вас не работет
По языкам претензий вообще не понял, я ж не их долю на рынуке сравнивал
Ну и ссылка у вас не работет
Например, давайте напишем небольшую функцию на python и вызовем ее с некорректными аргументами:Спасибо, вот теперь я впервые на конкретном примере увидел, как юнит-тестом заменяют статическую типизацию…
…
Ага! Нам сказали, что нельзя складывать строки с числами и указали конкретное место в коде, где произошла ошибка (ну, если бы это был файл)
Я то надеялся увидеть какие-то тренды, наблюдения, а тут… Давайте по порядку.
1. Пример с HTTP запросом на Clojure бредовый. Есть такая штука как REPL, который вроде как в Лиспах изначально и появился, а в Clojure вообще он один из лучших, которые я видел. Так вот в этом REPL можно создать запрос, отправить запрос, посмотреть его поля, вызвать методы, изменить и вообще проверить абсолютно всё, что вообще можно о нём узнать. В общем, аргумент не принят.
2. Про HTML и enlive. Насколько я помню enlive, он работает так: на вход подаётся страничка с шаблоном, над которым работал дизайнер. Эта страница трансформируется в родные структуры данных Clojure и предоставляется набор функций для заполнения отдельных кусков страницы нужными данными. Т.е. родные структуры данных Clojure используются для того, чтобы представить саму страничу. Где здесь DSL? Чем это хуже, чем набор каких-нибудь HTMLNode, которые делают то же самое, но имеют меньше методов для манипулирования? И самое главное, в случае с HTMLNode какой выигрыш дадут языки со статической типизацией? Правильно, никакой, потому что HTMLNode — это по определнию динамическая структура, как и нативные структуры Clojure.
3. Пример с опрелением роутов. Какое отношение плохой API имеет к динамической типизации. Хороший API на Clojure (как и на любом другом статические или динамически типизированном языке) может выглядеть как-то так:
И примерно так выглядит роутинг в большинстве более или менее популярных Clojure библиотеках. А вот про «прекрасный» роутинг скаловоского Spray почему-то никто не вспоминает. Статические языки гораздо понятней, ага.
4. Что касается частичного введения типизации, то, чёрт возьми, да, это хорошая возможность! Возможность опционально и лаконичным синтаксисом задать дополнительную проверку / документацию в коде — это дополнительная фича, так что почему бы и нет. Проблема в том, что не всё в программировании можно описать статическими типами. Вы не сможете описать HTML страницу строгими типами, вам понадобится обобщённый класс HTMLNode и динамическая проверка содержимого каждого узла. Вы не сможете представять в виде конкретного класса JSON значение — мы можете это отобразить на известный класс, но полностью его представить можно только с помощью обобщённого JSONValue. Вы не сможете реализовать систему акторов со строгой типизацией — скаловская Akka проглатывает любые сообщения и создаёт акторов динамически без проверки типов или даже количества аргументов.
5. Ну, и если всё-таки посмотреть на тренды, то вот список языков, набирающих популярность, из топа гугла (можете предложить другой):
4 из 9 — динамические. О да, это конец эпохи.
1. Пример с HTTP запросом на Clojure бредовый. Есть такая штука как REPL, который вроде как в Лиспах изначально и появился, а в Clojure вообще он один из лучших, которые я видел. Так вот в этом REPL можно создать запрос, отправить запрос, посмотреть его поля, вызвать методы, изменить и вообще проверить абсолютно всё, что вообще можно о нём узнать. В общем, аргумент не принят.
2. Про HTML и enlive. Насколько я помню enlive, он работает так: на вход подаётся страничка с шаблоном, над которым работал дизайнер. Эта страница трансформируется в родные структуры данных Clojure и предоставляется набор функций для заполнения отдельных кусков страницы нужными данными. Т.е. родные структуры данных Clojure используются для того, чтобы представить саму страничу. Где здесь DSL? Чем это хуже, чем набор каких-нибудь HTMLNode, которые делают то же самое, но имеют меньше методов для манипулирования? И самое главное, в случае с HTMLNode какой выигрыш дадут языки со статической типизацией? Правильно, никакой, потому что HTMLNode — это по определнию динамическая структура, как и нативные структуры Clojure.
3. Пример с опрелением роутов. Какое отношение плохой API имеет к динамической типизации. Хороший API на Clojure (как и на любом другом статические или динамически типизированном языке) может выглядеть как-то так:
(defroute GET "/" (do-stuff))
(defroute GET "/notes" (do-another-stuff))
(defroute POST "/notes/:id" (do-stuff-with-id))
И примерно так выглядит роутинг в большинстве более или менее популярных Clojure библиотеках. А вот про «прекрасный» роутинг скаловоского Spray почему-то никто не вспоминает. Статические языки гораздо понятней, ага.
4. Что касается частичного введения типизации, то, чёрт возьми, да, это хорошая возможность! Возможность опционально и лаконичным синтаксисом задать дополнительную проверку / документацию в коде — это дополнительная фича, так что почему бы и нет. Проблема в том, что не всё в программировании можно описать статическими типами. Вы не сможете описать HTML страницу строгими типами, вам понадобится обобщённый класс HTMLNode и динамическая проверка содержимого каждого узла. Вы не сможете представять в виде конкретного класса JSON значение — мы можете это отобразить на известный класс, но полностью его представить можно только с помощью обобщённого JSONValue. Вы не сможете реализовать систему акторов со строгой типизацией — скаловская Akka проглатывает любые сообщения и создаёт акторов динамически без проверки типов или даже количества аргументов.
5. Ну, и если всё-таки посмотреть на тренды, то вот список языков, набирающих популярность, из топа гугла (можете предложить другой):
- Erlang — динамический
- Go — статический
- Groovy — динамический
- OCaml — статический (и здесь «статический» значит гораздо больше, чем, скажем, в Scala)
- CoffeeScript — динамичесикй
- Scala — статический
- Dart — статический
- Haskell — статический
- Julia — динамический (с type guards)
4 из 9 — динамические. О да, это конец эпохи.
Groovy — динамический
Смысл языка именно в том чтобы дать возможность писать скрипты/программы с динамической типизацией в Java проектах. На самом деле, учитывая доступ к статическим типам Java это язык скорее с комбинированной типизацией. Как у C# есть dynamic, так у Java есть Groovy.
CoffeeScript — динамичесикй
Это не новый язык, а настройка на JavaScript, то есть его популярность идет от популярности JavaScript.
То есть только 2 из 9 — реально новые динамические языки.
UFO just landed and posted this here
И даже Java надстройка над JVM. У JVM какая типизация?
UFO just landed and posted this here
А JVM надстройка над машинными кодами (у регистров которых, кстати, вполне статическая типизация — флаги, указатели и числовые регистры это разные типы), но вообще говорить о типизации байт кода или машинных кодов весьма мало смысла.
У регистров и памяти как раз не статическая типизация, а полная динамическая, то есть отсутствие типизации в принципе. Тип регистра определяется оператором, если можно так выразиться. Оператор арифметического сложения, например, считает что в регистре число, а оператор двоичного умножения — множество битов. Если туда поместить код символа в Юникоде, то никто из них не заметит подвоха.
Да, но только для регистров общего назначения, однако есть флаговые (Boolean значения), индексные (числовые), указательные и сегментные (хранят указатели), так что давайте согласимся что у регистров комбинированная типизация. :)
у регистров комбинированная типизация
Вы уже второй раз используете словосочетание «кобминированная типизация», объясните, пожалуйста, его смысл.
Чистая динамическая типизация — тип определяется только во время выполнения, чисто статическая типизация — тип задается и проверяется на этапе компиляции, комбинированная — тип указывается лишь опционально, часть переменных получаются динамическими, часть статическими.
Тогда Java — это язык с комбинированной типизацией, потому что можно объявить переменную типа Object. Так получается?
Нет, Object это статический тип. В Java нельзя просто записать var x, нельзя выйти из системы статических типов, да можно Object привести к любому другому типу, но исключительно в рамках статической типизации, Object тут не отличается от любого другого статического типа, например Number'a. Более того Object вполне реальный класс Java.
В Java нельзя просто записать var x
Object x;
Object привести к любому другому типу, но исключительно в рамках статической типизации
Т.е. без проверки типа на этапе компиляции? Для меня звучит как динамическая типизация.
Более того Object вполне реальный класс Java
В отличие от чего? В Python, например, тоже есть вполне реальный класс object.
Пока что разницу между Java и Python я вижу только в том, что в Java надо писать так:
Foo x = (Foo)y;
а в Python можно просто:
x = y
Т.е. без проверки типа на этапе компиляции? Для меня звучит как динамическая типизация.
Вы будете удивлены, но динамичность типизации и тип трансляции никак не связаны. Равно как не связаны динамичность и время проверки типа. Статическая типизация означает лишь, что тип не может измениться после объявления, а всё остальное (компилируемость, проверка попыток изменения во время компиляции и т. д.) к статической типизации не относится, просто статистика создаёт паразитные ассоциации у многих.
Из Википедии:
Терминология тут очень скользкая, равно как и в самом процессе компиляции и рантайма (например, JIT-компиляция — это compile time или run time? а интерпретаторы, которые компилируют и выполняют код по одному выражению?). Я тут отталкиваюсь от основной цели статической типизации (как это подаётся здесь) — раннего выявления ошибок за счёт дополнительных ограничений. И вот тут я не вижу разницы между кодом, который я привёл выше для Julia и таким кодом на Scala (у Java нет REPL для демонстрации, но смысл тот же):
Уберите из программы на Scala аннотации типов и добавьте приведение к типу перед вызовом метода и получите чисто динамический язык.
Это всё, конечно, искусственные примеры и притянуто за уши, но ведь и изобретать некую магическую «комбинированную» типизацию — это не совсем често.
Static type-checking is the process of verifying the type safety of a program based on analysis of a program's text (source code).
…
Dynamic type-checking is the process of verifying the type safety of a program at runtime.
Терминология тут очень скользкая, равно как и в самом процессе компиляции и рантайма (например, JIT-компиляция — это compile time или run time? а интерпретаторы, которые компилируют и выполняют код по одному выражению?). Я тут отталкиваюсь от основной цели статической типизации (как это подаётся здесь) — раннего выявления ошибок за счёт дополнительных ограничений. И вот тут я не вижу разницы между кодом, который я привёл выше для Julia и таким кодом на Scala (у Java нет REPL для демонстрации, но смысл тот же):
scala> var x: Any = 1
x: Any = 1
scala> x = "hello"
x: Any = hello
scala> x = List(42, 84, 168)
x: Any = List(42, 84, 168)
Уберите из программы на Scala аннотации типов и добавьте приведение к типу перед вызовом метода и получите чисто динамический язык.
Это всё, конечно, искусственные примеры и притянуто за уши, но ведь и изобретать некую магическую «комбинированную» типизацию — это не совсем често.
del
но ведь и изобретать некую магическую «комбинированную» типизацию — это не совсем честно.
Вы ошибаетесь, никто комбинированную магическую типизацию не изобретал. Давно существуют языки программирования у которых официально есть и динамическая и статическая типизация одновременно, например Groovy. Естественно, отдельная переменная в каждый момент времени имеет либо статическую, либо динамическую типизацию. Видимо, такие языки и подразумевались под «комбинированной» типизацией.
Так динамическая и статическая типизация, а не какая-то третья «комбинированная». Просто не надо подменять понятия для докозательства своей точки зрения. Динамическая типизация востребована, как судя по статье, которую я привёл, так и по статистике GitHub и, я уверен, по куче других параметров.
чисто статическая типизация — тип задается и проверяется на этапе компиляции
В общем случае время задания типа сущности не имеет значения для определения типа типизации. Главное отличие статической от динамической: в первой тип не может меняться в ходе выполнения, а во второй — может. Просто традиционно статически типизируемые языки компилируемые и проверки типа осуществляются на этапе компиляции, но вообще язык может быть статически типизируемый, но интерпретируемый, может быть статически типизированный и компилированный, но проверка типа выполняться в рантайме
Хранят они то, что загружено в них явно или нет. Просто некоторые команды считают, что это не просто набор битов, а набор, имеющий четко определенную семантику, то есть тип. Это они так считают, но «транслятор» не гарантирует, что, например, в сегментном регистре хранится адрес регистра.
Возможно, хотя Scala скорее уже позиционируется как замена Java, в то время как CoffeeScript более похож на Project Lombok для Java. Надо просто понимать что у JavaScript нет альтернативы и CoffeeScript лишь обетка над синтаксисом JavaScript, как Java лямбды и Stream Api обертка над обычными методами Java 1-7, с таким же успехом синтаксис CoffeeScript мог стать частью синтаксиса JavaScript, если бы стандарт JavaScript не было так сложно менять.
P.S. Кстати у Julia — комбинированная типизация (опциональные аннотации типов и т.п.), то есть из чисто динамических универсальных новых популярных языков остается один Erlang.
P.S. Кстати у Julia — комбинированная типизация (опциональные аннотации типов и т.п.), то есть из чисто динамических универсальных новых популярных языков остается один Erlang.
UFO just landed and posted this here
P.S. Кстати у Julia — комбинированная типизация (опциональные аннотации типов и т.п.), то есть из чисто динамических универсальных новых популярных языков остается один Erlang.
julia> x = 1
1
julia> x = "hello"
"hello"
julia> x = [42, 84, 168]
3-element Array{Int64,1}:
42
84
168
В Julia динамическая типизация. Аннотации типов нужны для специализации при компиляции и полиморфизма. Т.е. вы можете объявить метод «add(a::Int, b::Int)» и метод «add(b::String, b::String)», и конкретный метод будет определён динамически в зависимости от переданных аргументов во время первого вызова. При этом до момента первого вызова компилятор / рантайм даже не почешется проверить типы:
julia> foo(x::Int) = 1
foo (generic function with 1 method)
julia> bar() = foo("some string")
bar (generic function with 1 method)
julia> bar()
ERROR: MethodError: `foo` has no method matching foo(::ASCIIString)
in bar at none:1
CoffeeScript лишь обетка над синтаксисом JavaScript
Все языки лишь обертки над машинными кодами. Да и сам язык машинных кодов в современных процессорах вроде как лишь обертка над аппаратными микрокомандами.
А так, все относительно высокоуровневые языки транслируются в другие языки, зачастую в несколько этапов, например Java транслируется в байт-код JVM, который транслируется в машинный код. А CofeeScript обычно транслируется в JavaScript-код, который транслируется в машинный код. В общем не путайте язык и его реализацию.
На самом деле, учитывая доступ к статическим типам Java это язык скорее с комбинированной типизацией.
Что вызов какого-то метода или функции библиотеки гарантированно возвращает конкретный тип не делает язык статически типизируемым. С точки зрения языка это просто такая библиотека. Динамическая типизация означает прежде всего возможность менять тип значений переменных в рантайме. Если она есть — язык динамически типизируемый.
Смысл языка именно в том чтобы дать возможность писать скрипты/программы с динамической типизацией в Java проектах. На самом деле, учитывая доступ к статическим типам Java это язык скорее с комбинированной типизацией. Как у C# есть dynamic, так у Java есть Groovy.
Любой динамический язык программирования имеет доступ к информации о точном типе объекта, просто эта информация не закрепляется за переменной во время компиляции.
Это не новый язык, а настройка на JavaScript, то есть его популярность идет от популярности JavaScript.
Ага, а C — это надстройка над языком ассемблера.
Если вы хотите позаниматься софистикой, то можно сказать, что Scala — динамически типизированный язык, потому что в нём есть Any, и Haskell — динамически типизированный, потому что в нём можно не указывать явно типы и т.д. Но давайте всё-таки придерживаться общепринятых определений, хотя бы из той же Википедии.
К слову, утверждение Groovy — динамический неверно, Groovy поддерживает как статическую, так и динамическую типизацию, причем позволяет в нужном месте использовать наиболее удобный подход.
Недавно в твиттере на тему понравилось
"Dynamic typing": The belief that you can't explain to a computer why your code works, but you can keep track of it all in your head.
— Chris Martin (@chris__martin) 10 августа 2015
UFO just landed and posted this here
в [...] Javascript вообще деббагинг никто не использует
Серьезно?
UFO just landed and posted this here
Угу, следующий вопрос: насколько популярен дебаггинг у тех программистов «статически-типизированных языков», которые активно используют юнит-тесты?
UFO just landed and posted this here
Так в статье написано «юнит тесты полезны для тестирования некоторой известной функциональности, а не для определения того, насколько что-то в результатах соответствует вашим явным или неявным ожиданиям.»
Это никак не отвечает на мой вопрос.
в статических и компилируемых языках дебаггингу отдается гораздо больше внимания, чем в динамических и интерпретируемых.
У вас есть конкретная статистика, подтверждающая это утверждение? А с поправкой на количество тестов, покрывающих код?
Есть большое подозрение, что типичные написанные на динамических и интерпретируемых языках программы гораздо меньше и проще устроенные. Сравните поиск ошибки в каком-нибудь рендеринг страницы, где число задействованных переменных и методов редко переваливает за два-три десятка и отладку какого-нибудь внутри системного компонента.
UFO just landed and posted this here
Элементарно, составьте SQL запрос на стековерфлоу по тегам 'deugging', в среднем на статически типизированных языках это тема всплывает намного чаще.
У вас есть конкретные цифры?
Ну и да, я еще раз повторюсь: а какое тестовое покрытие в тех проектах, где люди используют дебаггер?
UFO just landed and posted this here
Если вас это интересует, проведите исследование. Мне тоже было бы интересно на это посмотреть.
Я так и думал, что ваше утверждение ничем не подтверждено. Жаль.
(а в статье про юнит-тесты написана банальность, к вашему утверждению отношения не имеющая)
UFO just landed and posted this here
В статье четкий посыл, что ошибки времени компиляции помогают избежать последующих проблем.
И это действительно так.
Я указал, на то что если это так, то зачем нужны дебаггеры?
Затем, что не все ошибки отлавливаются на этапе компиляции.
А для динамически — atom.io
atom.io — это не IDE, а редактор. Еще он работает со статически типизированными языками. Еще в нем есть дебаггер для node.js (не из коробки, но это значит, что кому-то было настолько надо, что он пошел и написал пакет).
Так что мне все еще интересно услышать основания для вашего утверждения (извините, я его перефразирую) «программы на статически-типизированных языках отлаживают дебаггером, а для динамически-типизированных — только пишут юнит-тесты».
Типичные используемые для статических типизированных языков ide уже довольно зрелые продукты с большой функциональностью.
Всякие же небольшие редакторы Javascript полагают, что в случае необходимости отладку будут производить в браузере, а не в ide.
Элементарно, составьте SQL запрос на стековерфлоу по тегам 'deugging'
Есть небольшое подозрение, что занимающиеся дебагом кода использовали дебагер, а не отлаживались с помощью print или allert.
В браузерах используют, на Node.js редко кто прикручивает.
1) Потому что надо прикручивать, до сих пор далеко не каждая IDE может дебажить Node.js, поэтому «вообще деббагинг никто не использует» не от хорошей жизни и от любви к unit тестам,
2) Вы проводили статистическое исследование про «редко кто»? До сих пор главным преимуществом WebStorm перед другими IDE считается мощный дебагер,
3) Средний размер приложений и их сложность в Java, С++, C# несколько больше чем в Javascript,
Полагаю, что не в последнюю очередь это связано с тем, что в таких языках посмотреть, что представляет из себя переменная, можно только в отладчике. В динамических для этого есть всякие var_dump() и console.log(). С другой стороны, я часто использую отладчик в PHP, он хорошо помогает разобраться в работе плохо написанного кода или в дебрях абстракций и DI-контейнеров.
в таких языках посмотреть, что представляет из себя переменная, можно только в отладчике. В динамических для этого есть всякие var_dump() и console.log()
Эээ, вы правда верите, что в статических языках (Java, C#, C++) нет аналогов var_dump и console.log (другими словами логирования в принципе или возможности вывести тип переменной в лог)?
На всякий случай, чтобы в Java получить аналог var_dump и console.log достаточно использовать код log.debug(«переменная» + variable), где log — переменная логера.
Я правильно понимаю, что у variable в этом случае вызывается что-то типа toString(), который мы сами должны реализовать? Я имел в виду не невозможность логирования в принципе и не определение типа переменной, а сложность получить все поля с их типами и значениями для некоторой сложной структуры.
сложность получить все поля с их типами и значениями для некоторой сложной структуры.
Любая Java IDE позволяет автоматически сгенерить toString() для любого класса за секунду. Есть способы автоматически генерить toString для всех классов проекта. Все коллекции и важные библиотечные классы уже имеют переопределенный toString. В целом, это не проблема от слова совсем.
Любая Java IDE позволяет автоматически сгенерить toString() для любого класса за секундуили просто добавить аннотацию @ToString
Тем не менее, проще не менять исходники и посмотреть в отладчике. Речь была не только про Java, а про языки в целом.
Проблема скорее в том, что мало добавить строку записи в лог. Необходимо еще и пересобрать проект, а это не быстро занятие.
Во-первых, есть такая вещь как hot deploy (подкладывания одного класса на сервер), во-вторых, далеко не всегда пересборка проекта занимает долгое время и далеко не всегда пересборка проекта целиком вообще нужна (так как есть кеши уже скомпилированных классов), в-третьих, в ряде случаев, как например в GWT, можно проверить работу класса/виджета без запуска остального кода.
C++ hot deploy? Разве подобное существует?
Да и даже если использовать hot deploy на java — мороки куча. Промахнулся со строчкой — добавляй код и заново вызывай метод. Лучше уж использовать специально предназначенный инструмент.
Да и даже если использовать hot deploy на java — мороки куча. Промахнулся со строчкой — добавляй код и заново вызывай метод. Лучше уж использовать специально предназначенный инструмент.
C++ hot deploy
В C++ нет, но вы не только про C++ говорили.
hot deploy на java — мороки куча. Промахнулся со строчкой — добавляй код и заново вызывай мето
Эээ, что за морока, почему я никогда с ней не встречался за 10 лет в Java? И что значит промахнулся со строчкой?
Лучше уж использовать специально предназначенный инструмент.
Я и имел в виду hot deploy со специально предназначенными для этого инструментами…
И что значит промахнулся со строчкой?
Например вы ожидали, что ошибка будет в этом месте, добавили вывод, посмотрели результат, а там все нормально и на самом деле ошибка скрывается где-то ниже по коду. Придется двигаться дальше и смотреть.
Я и имел в виду hot deploy со специально предназначенными для этого инструментами…
Специально преднозначеный инструмент это дебагер. Он позволяет не только посмотреть содержимое переменных. Но и узнать стек вызова, поменять прямо в рантайме значение некоторых переменных, выполнить произвольный код, заморозить на время процесс и еще многое другое. При отладке через print все это делать гораздо неудобней.
Любая Java IDE позволяет автоматически сгенерить toString() для любого класса за секундуAspectJ вам в помощь — не только пересобирать, но и сам класс менять не придётся
UFO just landed and posted this here
потому что
1) язык со статической типизацией != компилируемый,
2) из списка C,C++,C#,Java — лишь половина компилируемые языки, ни С#, ни Java — не являются компилируемыми языками, это одновременно и интерпретируемые и компилируемые языки, а которых возможна и кодогенерация на лету и evel и работа в интерпретируемым режиме,
3) никакой проблемы в получении нормальный дамп нет ни в C#, ни в Java достаточно определить toString любым из ручных и автоматических способов, насчет С++ — не скажу,
4) полный аналог js «console.log(JSON.stringify(object))» на java записывается как «log.debug(gson.toJson(object))», на C# скорее всего не сложнее,
Вывод: утверждение «в таких языках посмотреть, что представляет из себя переменная, можно только в отладчике» совершенно неверно.
1) язык со статической типизацией != компилируемый,
2) из списка C,C++,C#,Java — лишь половина компилируемые языки, ни С#, ни Java — не являются компилируемыми языками, это одновременно и интерпретируемые и компилируемые языки, а которых возможна и кодогенерация на лету и evel и работа в интерпретируемым режиме,
3) никакой проблемы в получении нормальный дамп нет ни в C#, ни в Java достаточно определить toString любым из ручных и автоматических способов, насчет С++ — не скажу,
4) полный аналог js «console.log(JSON.stringify(object))» на java записывается как «log.debug(gson.toJson(object))», на C# скорее всего не сложнее,
Вывод: утверждение «в таких языках посмотреть, что представляет из себя переменная, можно только в отладчике» совершенно неверно.
иммутабельный — неизменяемый.
В ближайшие лет 10 актуальными станут типы данных вроде «подозрительный человек в маске с автоматом в левой руке и бананом в правой», или допустим «крутой поворот за угол слева от фонаря». Я с трудом себе представляю как с этим будут справляться языки с самыми современными системами статической типизации, и будет ли статическая типизация вообще актуальна для описания таких вещей.
Исходя из лично моего опыта могу сказать, что статическая типизация была практически бесполезна чтобы гарантировать правильную работу моих программ. Потому что статической типизацией почти невозможно отловить ошибки вызванные неправильной последовательностью передачи данных между десятком параллельно работающих модулей. Для этого наверное нужны какие-то новые математические теории типизации, основанные скажем на темпоральной логике или чем-то подобном.
Если вы про различные виды гонок, то тут проблема не в типизации, а в концепции разделяемых данных. Современные языки уже не разделяют память между потоками по умолчанию, вынуждая программистов строить межпоточное взаимодействие по протоколам, в реализации которых статическая типизация очень сильно помогает.
Ребятки, я понимаю что вы меня минусуете на хабре когда я веду себя довольно аггресивно по отношению к мнению других людей, возможно не обладая достаточной квалификацией для того чтобы вести с ними аргументированный спор. Но когда я говорю о собственном опыте в разработке ПО и вы ебошите минуса на мои комменты мне просто хочется чтобы вы пошли нахуй. Довольно адекватная и честная реакция, вы не находите? Спасибо за внимание.
Вы просто не забывайте, что вы оставляете свои минуса к комментариям под сверх-толстой статьей о «смерти» динамических языков в которой автор просто точно так же как и я делится с такими же как он своим опытом создания ПО.
Это так мило, когда пользователь с кармом 23 жалуется пользователю с кармой -15 на пару минусов в комментариях :-) да вы зажрались, батенька!
Я честно говоря вообще не понимаю значение этих цифр. Есть какая-нибудь таблица на этом ресурсе, в которой указаны диапазоны значений «кармы» и что они говорят о пользователе. Что значит -15?
В раздел помощь не пробовали заглянуть?
Как вы думаете, станут ли они популярными в мейнстриме? Для этого надо будет написать докторскую по компьютерным наукам или с этим справится обычный школьник?
UFO just landed and posted this here
Да фиг знает. Мне кажется, всякие code contracts приближают к этому. Еще вспомните что linq это монада, только Эрик Маер все переименовал для понятности массовыми кодерами.
Т.к. я на самом деле на знаю всех тонкостей ЗТ, то не могу сказать с уверенностью, но мне кажется, что результат будет примерно такой, что программер будет на доступном ему уровне чуть побольше описывать про типы данных, а компайлер будет на это интеллектуально ругаться.
Т.к. я на самом деле на знаю всех тонкостей ЗТ, то не могу сказать с уверенностью, но мне кажется, что результат будет примерно такой, что программер будет на доступном ему уровне чуть побольше описывать про типы данных, а компайлер будет на это интеллектуально ругаться.
Увы, мне лень читать все комментарии, и я не знаю, говорили уже или нет аналогичное моему мнению, но лично меня ужасно раздражают статьи с жёлтыми сенсационными заголовками. 'Конец эпохи динамических языков', 'Электронная почта давно мертва', 'Закат языка СИ' (ага, уже как сорок лет с лишним) и прочие. Прямо названия голливудских триллеров. Неужели их авторы серьёзны? Если так, видимо, они ожидали серебряной пули, а оказалось, что каждый язык имеет свои ограничения и, как следствие, свою нишу. Когда-то многие считали, что телевидение убьёт кинотеатры, но они, как видите, всё ещё живы.
Мне лень читать комментарии начинающиеся со слов «Мне лень читать комментарии», но меня раздражают комментарии, начинающиеся со слов «Мне лень читать комментарии», потому, что часто основная ценность статьи — это провокация на комментарии.
Наброс, как наброс.
С идиотскими аргументами типа —
«Посмотрите на этот метод! Пежде чем его использовать придется посмотреть в документацию!»
Напрашивается вопрос — «а при чем тут типизация?».
С идиотскими аргументами типа —
«Посмотрите на этот метод! Пежде чем его использовать придется посмотреть в документацию!»
Напрашивается вопрос — «а при чем тут типизация?».
«а при чем тут типизация?»
Так это известная проблема динамической типизации — IDE не может выдавать подсказки методов классов и типов параметров. Если при статической типизации код часто может быть самодокументированым, типы и названия переменных могут заменять комментарии, то при динамической типизации с этим несколько сложнее.
Все не настолько плохо, как описано в статье, но определенный недостаток динамической типизации тут есть.
Это понятно и с этим никто не спорит.
Но в примере у автора wrap-params, а это такая штука, которая принимает на вход request и на выход отдает тоже request. То есть речь о том, что автор за уши притягивает абсолютно не подходящие аргументы.
Или возьмем такую другой вариант передергивания — «какой DSL лучше всего описывает HTML?»
А кому вообще надо описывать html? Ведь у девелопера обычно совсем другая задача, а именно,
«каким-то образом запихать мою структуру данных в браузер, чтобы он ее понял».
Цепочка выглядит так
mydata -> templater -> html -> http(tcp,gzip,...) -> html -> parser -> dom
или вот так (в случае Clojure)
mydata -> hiccup -> html -> http(tcp,gzip,...) -> html -> parser -> dom
причем, во втором случае hiccup — это по сути тривиальное проеобразование теми же средствами, которые уже работают с mydata безо всяких дополнтельных «языков шаблонов» и т.п.
И ключевые моменты здесь «тривиальное» и «теми же средствами».
Но в примере у автора wrap-params, а это такая штука, которая принимает на вход request и на выход отдает тоже request. То есть речь о том, что автор за уши притягивает абсолютно не подходящие аргументы.
Или возьмем такую другой вариант передергивания — «какой DSL лучше всего описывает HTML?»
А кому вообще надо описывать html? Ведь у девелопера обычно совсем другая задача, а именно,
«каким-то образом запихать мою структуру данных в браузер, чтобы он ее понял».
Цепочка выглядит так
mydata -> templater -> html -> http(tcp,gzip,...) -> html -> parser -> dom
или вот так (в случае Clojure)
mydata -> hiccup -> html -> http(tcp,gzip,...) -> html -> parser -> dom
причем, во втором случае hiccup — это по сути тривиальное проеобразование теми же средствами, которые уже работают с mydata безо всяких дополнтельных «языков шаблонов» и т.п.
И ключевые моменты здесь «тривиальное» и «теми же средствами».
Лисперы — это и есть те самые легендарные «программисты на HTML'е», только об этом никто не догадывается, потому что все думают, что скобки-уголки фундаментально отличаются от круглых скобок.
А кому вообще надо описывать html?
Тому, кому нужно создать html (неважно на сервере или на клиенте, хотя чаще, имхо, на сервере), но его синтаксис не нравится. Как вариант — кажется избыточным. Одни закрывающие теги чего стоят.
вы ошибаетесь в основе — не надо создавать HTML, — надо создавать что-то, что будет видеть или с чем будет взаимодействовать пользователь и HTML просто одна из форм описания этого что-то. Так же, как и CSS и JS
И тем ни менее во всём этом прекрасном стеке абстракций всё-таки будет и слой, который из «чего-то» создаёт HTML для браузера и слой в браузере, который читает HTML и превращает во «что-то, что будет видеть пользователь». Обоим этим слоям нужно описывать html.
Я не пишу софт для пользователей, я пишу софт для программных агентов (в том числе пользовательских браузеров) и часто мне нужно отдавать HTML. В лучшем случае можно считать, что я пишу описание DOM на HTML и считаю, что HTML для этого неудобен, в частности избыточен, но другого способа сформировать DOM на клиенте у меня нет.
Все вот пишут на коком бы это языке написать, что по меньшей мере глупо. Пишут на библиотеке примитивов, собирают под свои нужды чужие разработки. Ну и какая разница на чем писать? Пишем на С++ быструю библиотеку и подставляем в интерпретатор. С++ можно использовать как будто он С без плюсов, поэтому С ваще не нужен. Но если человек написал на С++ примитивы, то ему просто легче на С++ набросать общую сборку. Но если в компании много девочек, то они хочут простой и понятный язык верхнего уровня, и все то им не нравится. C# хорош своими проработанными библиотеками NET, и нет особого смысла дописывать на C++. Другое дело что на 90% компьютер используется для игр где нет всех этих интерпретаторов, только хардкор. На 1% компьютер используется для научно-технических целей. Речь идет о 9% ПО для web служб, где нужно быстро и красиво, тут нужны пусть и не эффективные, но не глючные средства. Есть еще одна ниша — обработка данных. Тут свои заморочки — массив данных нужно обработать ровно один раз, а потом программу выбросить. Ну и как быть уверенным, что данные обработаны правильно? А никак. Ну давайте придумает такой язык, где все будет сразу и без ошибок — не получится. Обработка больших данных — это тот самый 1%.
Sign up to leave a comment.
Конец эпохи динамических языков