Казалось, закончились долгие обсуждения в форумах, как измерить время работы алгоритма, какие функции использовать, какую точность ожидать. Жаль, но опять придется вернуться к этому вопросу. На повестке дня, как лучше измерить скорость работы параллельного алгоритма.
Сразу скажу, что не дам точного рецепта. Я сам недавно столкнулся с проблемой измерения скорости работы параллельных алгоритмов и не являюсь экспертом в этом вопросе. Эта заметка носит скорее исследовательский характер. Я буду рад услышать ваше мнение и рекомендации. Думаю, вместе мы разберемся с проблемой и выработаем оптимальное решение.
Задача состоит в измерении времени работы участка пользовательского кода. Раньше для этой задачи я использовал класс следующего вида:
Данный класс основан на использовании функции GetThreadTimes, которая позволяет разделить время, затраченное на работу пользовательского кода, и время работы системных функций. Класс предназначен для оценки времени работы потока в пользовательском режиме, и поэтому используется только возвращаемый параметр lpUserTime.
Измерять время работы можно используя такие инструментальные средства, как Intel Parallel Amplifier, но часто удобно измерять время изнутри программы. Например, это позволяет записать значения в лог. Поэтому мы все-таки попробуем создать класс для замера скорости.
Рассмотрим пример кода, вычисляющий некоторое число. Используем для измерения времени работы класс Timing.
В таком виде механизм измерения времени ведет себя как ожидалось и на моей рабочей машине выдает, скажем, 7 секунд. Результат корректен даже для многоядерной машины, так как неважно какие ядра будут использованы в процессе работы алгоритма (см. рисунок 1).
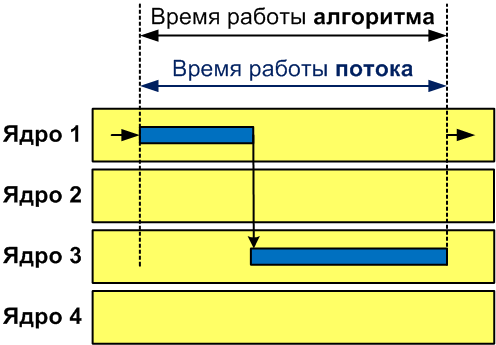
Рисунок 1 — Работа одного потока на многоядерной машине.
Теперь представим, что мы хотим использовать в нашей программе возможности многоядерных процессоров и хотим оценить, что нам дает распараллеливание алгоритма на основе технологии OpenMP. Распараллелим наш код, добавив одну строчку:
Теперь программа печатает на экран время работы 1.6 секунд. Поскольку используется машина с 4 ядрами, хочется сказать «Ура, мы получили ускорение в 4 раза и замер времени работы это подтверждает».
Огорчу. Мы измеряем не время работы алгоритма, а время работы главного потока. В данном случае измерение кажется достоверным, поскольку основной поток работал столько же, сколько и дополнительные. Поставим простой эксперимент. Явно укажем использовать 10 потоков, а не 4:
Логика подсказывает, что данный код должен работать приблизительно тоже время, что и код, распараллеливаемый на 4 потока. У нас четырех ядерный процессор, а следовательно от увеличения количества потоков можно ожидать только замедление. Однако на экране мы увидим значение порядка 0.7 секунд.
Это ожидаемый результат, хотя мы хотели получить совсем иное. Было создано 10 потоков. Каждый из которых отработал порядка 0.7 секунд. Именно это время работал и основной поток, время которого мы замеряем, используя класс Timing. Как видите, такой способ неприменим для измерения скорости программ с параллельными участками кода. Для наглядности отобразим это на рисунке 2.
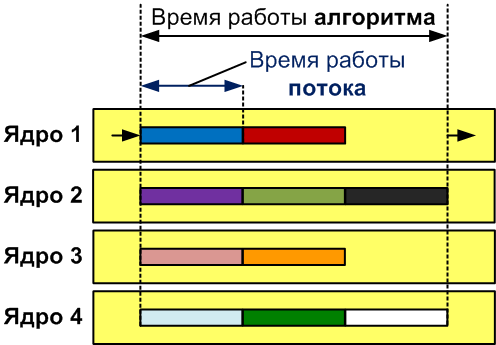
Рисунок 2 — Так может выглядеть работа 10 потоков, на машине с четырьмя ядрами.
Конечно, всегда можно использовать функцию time(), но ее разрешающая способность низкая, она не позволяет разделить время работы пользовательского и системного кода. Дополнительно на время могут влиять другие процессы, что также может сильно искажать измерения времени.
Любимой функцией многих разработчиков для измерения скорости является QueryPerformanceCounter. Давайте построим измерение скорости с ее использованием. В простом виде класс для измерения будет выглядеть следующим образом:
К сожалению, на многоядерной машине, так делать больше нельзя. :) Вот что сказано по поводу этой функции в MSDN:
On a multiprocessor computer, it should not matter which processor is called. However, you can get different results on different processors due to bugs in the basic input/output system (BIOS) or the hardware abstraction layer (HAL). To specify processor affinity for a thread, use the SetThreadAffinityMask function.
Произведем усовершенствования и привяжем главный поток к одному ядру:
Данный способ измерения по-прежнему подвержен тому же недостатку, что невозможно отделить время работы системного и пользовательского кода. Если на ядре выполняются другие задачи, то результат измерения также будет весьма неточен. Однако как мне кажется, такой способ все же применим к параллельному алгоритму в отличии GetThreadTimes. Если это не так, то прошу меня поправить!
Измерим, что покажут классы Timing и Timing2 на различном количестве потоков:
Сведем данные в таблицу, показанную на третьем рисунке.

Рисунок 3 — Время работы алгоритма в секундах измеренное с помощью функций GetThreadTimes и QueryPerformanceCounter на четырехядерной машине.
Как видно из таблицы, пока количество потоков не превышает количества ядер, функция GetThreadTimes дает результат схожий с QueryPerformanceCounter, что может приводить к ощущению, что производятся корректные измерения. Однако при большем количестве потоков на ее результат полагаться уже нельзя.
Жду ваших комментариев и описаний способов, как лучше измерять время работы параллельных алгоритмов.
Сразу скажу, что не дам точного рецепта. Я сам недавно столкнулся с проблемой измерения скорости работы параллельных алгоритмов и не являюсь экспертом в этом вопросе. Эта заметка носит скорее исследовательский характер. Я буду рад услышать ваше мнение и рекомендации. Думаю, вместе мы разберемся с проблемой и выработаем оптимальное решение.
Задача состоит в измерении времени работы участка пользовательского кода. Раньше для этой задачи я использовал класс следующего вида:
class Timing {
public:
void StartTiming();
void StopTiming();
double GetUserSeconds() const {
return double(m_userTime) / 10000000.0;
}
private:
__int64 GetUserTime() const;
__int64 m_userTime;
};
__int64 Timing::GetUserTime() const {
FILETIME creationTime;
FILETIME exitTime;
FILETIME kernelTime;
FILETIME userTime;
GetThreadTimes(GetCurrentThread(),
&creationTime, &exitTime,
&kernelTime, &userTime);
__int64 curTime;
curTime = userTime.dwHighDateTime;
curTime <<= 32;
curTime += userTime.dwLowDateTime;
return curTime;
}
void Timing::StartTiming() {
m_userTime = GetUserTime();
}
void Timing::StopTiming() {
__int64 curUserTime = GetUserTime();
m_userTime = curUserTime - m_userTime;
}Данный класс основан на использовании функции GetThreadTimes, которая позволяет разделить время, затраченное на работу пользовательского кода, и время работы системных функций. Класс предназначен для оценки времени работы потока в пользовательском режиме, и поэтому используется только возвращаемый параметр lpUserTime.
Измерять время работы можно используя такие инструментальные средства, как Intel Parallel Amplifier, но часто удобно измерять время изнутри программы. Например, это позволяет записать значения в лог. Поэтому мы все-таки попробуем создать класс для замера скорости.
Рассмотрим пример кода, вычисляющий некоторое число. Используем для измерения времени работы класс Timing.
int _tmain(int, _TCHAR*)
{
Timing t;
t.StartTiming();
unsigned sum = 0;
for (int i = 0; i < 1000000; i++)
{
char str[1000];
for (int j = 0; j < 999; j++)
str[j] = char(((i + j) % 254) + 1);
str[999] = 0;
for (char c = 'a'; c <= 'z'; c++)
if (strchr(str, c) != NULL)
sum += 1;
}
t.StopTiming();
printf("sum = %u\n", sum);
printf("%.3G seconds.\n", t.GetUserSeconds());
return 0;
}В таком виде механизм измерения времени ведет себя как ожидалось и на моей рабочей машине выдает, скажем, 7 секунд. Результат корректен даже для многоядерной машины, так как неважно какие ядра будут использованы в процессе работы алгоритма (см. рисунок 1).

Рисунок 1 — Работа одного потока на многоядерной машине.
Теперь представим, что мы хотим использовать в нашей программе возможности многоядерных процессоров и хотим оценить, что нам дает распараллеливание алгоритма на основе технологии OpenMP. Распараллелим наш код, добавив одну строчку:
#pragma omp parallel for reduction(+:sum)
for (int i = 0; i < 1000000; i++)
{
char str[1000];
for (int j = 0; j < 999; j++)
str[j] = char(((i + j) % 254) + 1);
str[999] = 0;
for (char c = 'a'; c <= 'z'; c++)
if (strchr(str, c) != NULL)
sum += 1;
}Теперь программа печатает на экран время работы 1.6 секунд. Поскольку используется машина с 4 ядрами, хочется сказать «Ура, мы получили ускорение в 4 раза и замер времени работы это подтверждает».
Огорчу. Мы измеряем не время работы алгоритма, а время работы главного потока. В данном случае измерение кажется достоверным, поскольку основной поток работал столько же, сколько и дополнительные. Поставим простой эксперимент. Явно укажем использовать 10 потоков, а не 4:
#pragma omp parallel for reduction(+:sum) num_threads(10)
Логика подсказывает, что данный код должен работать приблизительно тоже время, что и код, распараллеливаемый на 4 потока. У нас четырех ядерный процессор, а следовательно от увеличения количества потоков можно ожидать только замедление. Однако на экране мы увидим значение порядка 0.7 секунд.
Это ожидаемый результат, хотя мы хотели получить совсем иное. Было создано 10 потоков. Каждый из которых отработал порядка 0.7 секунд. Именно это время работал и основной поток, время которого мы замеряем, используя класс Timing. Как видите, такой способ неприменим для измерения скорости программ с параллельными участками кода. Для наглядности отобразим это на рисунке 2.

Рисунок 2 — Так может выглядеть работа 10 потоков, на машине с четырьмя ядрами.
Конечно, всегда можно использовать функцию time(), но ее разрешающая способность низкая, она не позволяет разделить время работы пользовательского и системного кода. Дополнительно на время могут влиять другие процессы, что также может сильно искажать измерения времени.
Любимой функцией многих разработчиков для измерения скорости является QueryPerformanceCounter. Давайте построим измерение скорости с ее использованием. В простом виде класс для измерения будет выглядеть следующим образом:
class Timing2 {
public:
void StartTiming();
void StopTiming();
double GetUserSeconds() const {
return value;
}
private:
double value;
LARGE_INTEGER time1;
};
void Timing2::StartTiming()
{
QueryPerformanceCounter(&time1);
}
void Timing2::StopTiming()
{
LARGE_INTEGER performance_frequency, time2;
QueryPerformanceFrequency(&performance_frequency);
QueryPerformanceCounter(&time2);
value = (double)(time2.QuadPart - time1.QuadPart);
value /= performance_frequency.QuadPart;
}К сожалению, на многоядерной машине, так делать больше нельзя. :) Вот что сказано по поводу этой функции в MSDN:
On a multiprocessor computer, it should not matter which processor is called. However, you can get different results on different processors due to bugs in the basic input/output system (BIOS) or the hardware abstraction layer (HAL). To specify processor affinity for a thread, use the SetThreadAffinityMask function.
Произведем усовершенствования и привяжем главный поток к одному ядру:
class Timing2 {
public:
void StartTiming();
void StopTiming();
double GetUserSeconds() const {
return value;
}
private:
DWORD_PTR oldmask;
double value;
LARGE_INTEGER time1;
};
void Timing2::StartTiming()
{
oldmask = SetThreadAffinityMask(::GetCurrentThread(), 1);
QueryPerformanceCounter(&time1);
}
void Timing2::StopTiming()
{
LARGE_INTEGER performance_frequency, time2;
QueryPerformanceFrequency(&performance_frequency);
QueryPerformanceCounter(&time2);
SetThreadAffinityMask(::GetCurrentThread(), oldmask);
value = (double)(time2.QuadPart - time1.QuadPart);
value /= performance_frequency.QuadPart;
} Данный способ измерения по-прежнему подвержен тому же недостатку, что невозможно отделить время работы системного и пользовательского кода. Если на ядре выполняются другие задачи, то результат измерения также будет весьма неточен. Однако как мне кажется, такой способ все же применим к параллельному алгоритму в отличии GetThreadTimes. Если это не так, то прошу меня поправить!
Измерим, что покажут классы Timing и Timing2 на различном количестве потоков:
int _tmain(int, _TCHAR*)
{
Timing t;
Timing2 t2;
t.StartTiming();
t2.StartTiming();
unsigned sum = 0;
//#pragma omp parallel for reduction(+:sum) num_threads(2)
//#pragma omp parallel for reduction(+:sum) num_threads(4)
//#pragma omp parallel for reduction(+:sum) num_threads(6)
//#pragma omp parallel for reduction(+:sum) num_threads(10)
for (int i = 0; i < 1000000; i++)
{
char str[1000];
for (int j = 0; j < 999; j++)
str[j] = char(((i + j) % 254) + 1);
str[999] = 0;
for (char c = 'a'; c <= 'z'; c++)
if (strchr(str, c) != NULL)
sum += 1;
}
t.StopTiming();
t2.StopTiming();
printf("sum = %u\n", sum);
printf("GetThreadTimes: %.3G seconds.\n",
t.GetUserSeconds());
printf("QueryPerformanceCounter: %.3G seconds.\n",
t2.GetUserSeconds());
return 0;
}Сведем данные в таблицу, показанную на третьем рисунке.

Рисунок 3 — Время работы алгоритма в секундах измеренное с помощью функций GetThreadTimes и QueryPerformanceCounter на четырехядерной машине.
Как видно из таблицы, пока количество потоков не превышает количества ядер, функция GetThreadTimes дает результат схожий с QueryPerformanceCounter, что может приводить к ощущению, что производятся корректные измерения. Однако при большем количестве потоков на ее результат полагаться уже нельзя.
Жду ваших комментариев и описаний способов, как лучше измерять время работы параллельных алгоритмов.
