
Статья написана по мотивам моего доклада на митапе. В нем я рассказываю историю того, как мы взяли и не распилили монолит на микросервисы, и что сделали вместо этого.
На тот момент наша команда работала над приложением, начало которому было положено еще в 2009 году не искушенными в архитектуре студентами. К 2018 это уже был типичный big ball of mud (большой ком грязи), или, этакий «монолит-копролит», как выразился один наш коллега :) Думаю, многим знакомо. Конкретно у нас это вызывало следующие проблемы:
Сложность независимого изменения компонентов приложения, соответственно сложность масштабирования разработки и хрупкость всей системы.
Проблемы с покрытием модульными тестами. Так как наша бизнес-логика зависела от деталей реализации, нам пришлось ввести тестовую базу данных, и модульные тесты перестали быть модульными, к тому же выполнялись долго.
Сложность перехода на другие инструменты, фреймворки, технологии. В 2018 году мы все еще использовали версию фреймворка 2009 года...
Моральная неудовлетворенность разработчиков, работающих с запутанным кодом, тоже не стоит сбрасывать со счетов.
В конце 2018 в корне поменялись бизнес-требования к одной из подсистем приложения, от которой зависели почти все остальные, и нам предстояло полностью ее переписать. Вот тут-то и обнажились все архитектурные проблемы, и это был шанс, чтобы решить их. А возможность параллельной разработки нескольких фич разными подкомандами вообще стало одним из главных требований бизнеса к новой архитектуре.
Вариант с вынесением подсистемы в микросервис(ы) и последующим распилом монолита казался очень заманчивым — попробовать что-то новое, модное, да ещё и решающее задачи бизнеса и проблемы существующего приложения. Тем более, что часть разработчиков уже прошли курсы по golang и просто рвались в бой. Но у нас не было готовой инфраструктуры для микросервисов, не было команды devops и опыта не только проектирования, но и поддержки микросервисной архитектуры. Все это требовало дополнительного времени (а вот его как раз и не было) и ресурсов, а уровень предсказуемости результата был невысок. К тому же очевидно, что и в этой архитектуре можно получить тот же big ball of mud, только распределенный.
Поэтому нам показалось достаточно разумным сначала применить принципы микросервисной архитектуры к монолиту:
декомпозировать систему;
провести строгие границы между подсистемами и определить четкие контракты взаимодействия;
упорядочить направления зависимостей;
ослабить связи.
Тогда если в будущем и возникнет реальная необходимость вынести какую-то из подсистем в микросервис, то это будет сделать гораздо проще. Так родилась идея модульного монолита, которая, конечно же, была не нова.
Итак, что же у нас получилось.
Декомпозиция. Domain-Driven Design.
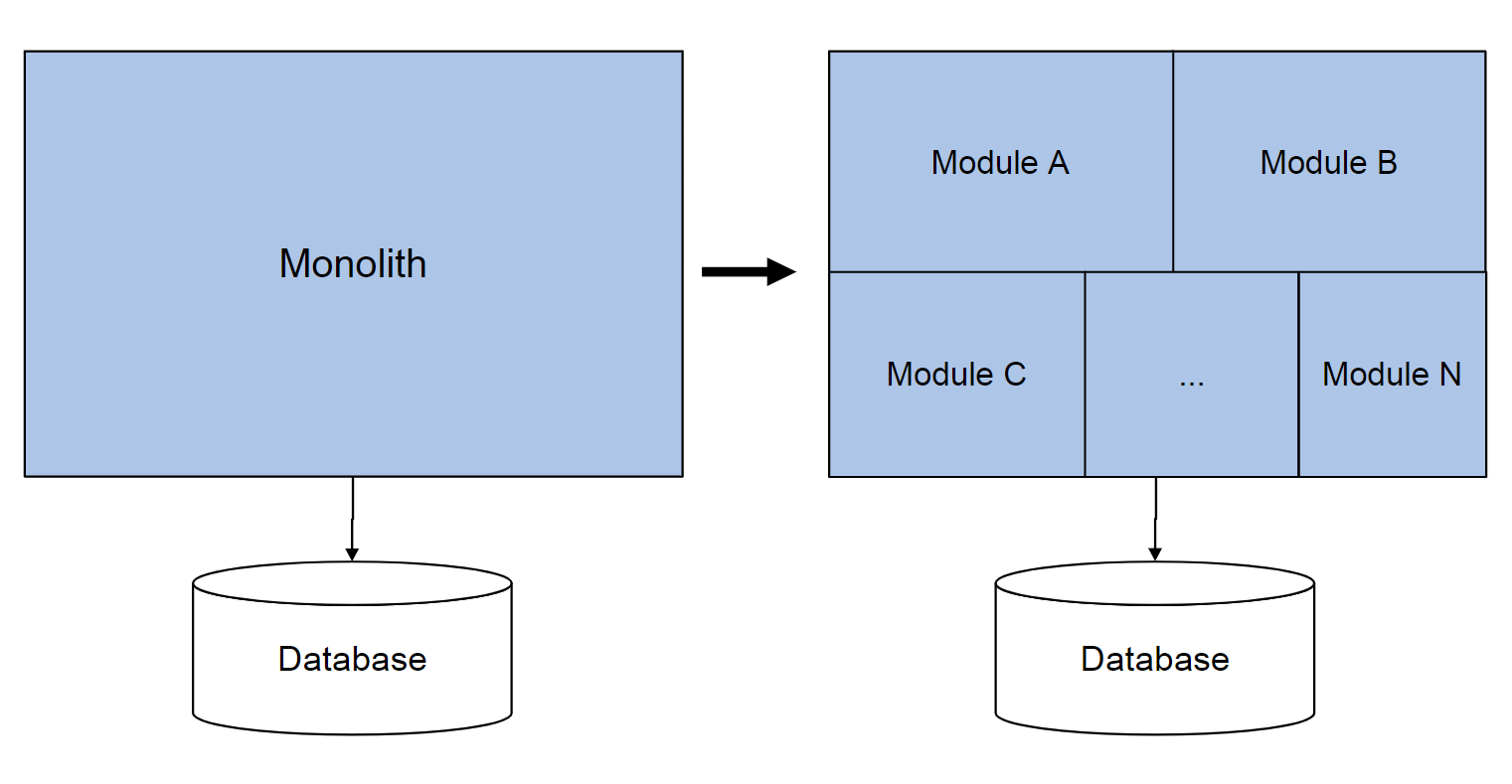
Для разделения приложения на модули мы использовали принципы и приемы предметно-ориентированного проектирования (Domain-Driven Design).
Domain-Driven Design декларирует, что у каждого приложения есть предметная область. В каждой предметной области можно выделить небольшие подобласти, которые называются ограниченными контекстами. Например, в e-commerce приложении можно выделить следующие ограниченные контексты: customer, product catalog, ordering, shipping. Каждому контексту будет соответствовать свой модуль. Физически он будет представлять собой отдельную папку со своим namespace'ом. Замечу, что БД по-прежнему остаётся общей, но об этом чуть ниже.
Подробнее про Domain-Driven Design можно почитать в книгах Eric Evans «Domain-Driven Design: Tackling Complexity in the Heart of Software» и Vaughn Vernon «Implementing Domain-Driven Design».
Чистая архитектура
Как уже упоминалось, одной из причин проблем нашего монолита была сильная зависимость бизнес-логики от деталей реализации. Для ее устранения мы воспользовались принципами «чистой архитектуры» (Роберт Мартин «Чистая архитектура. Искусство разработки программного обеспечения»), выделив внутри каждого модуля слои: domain, application, infrustructure.
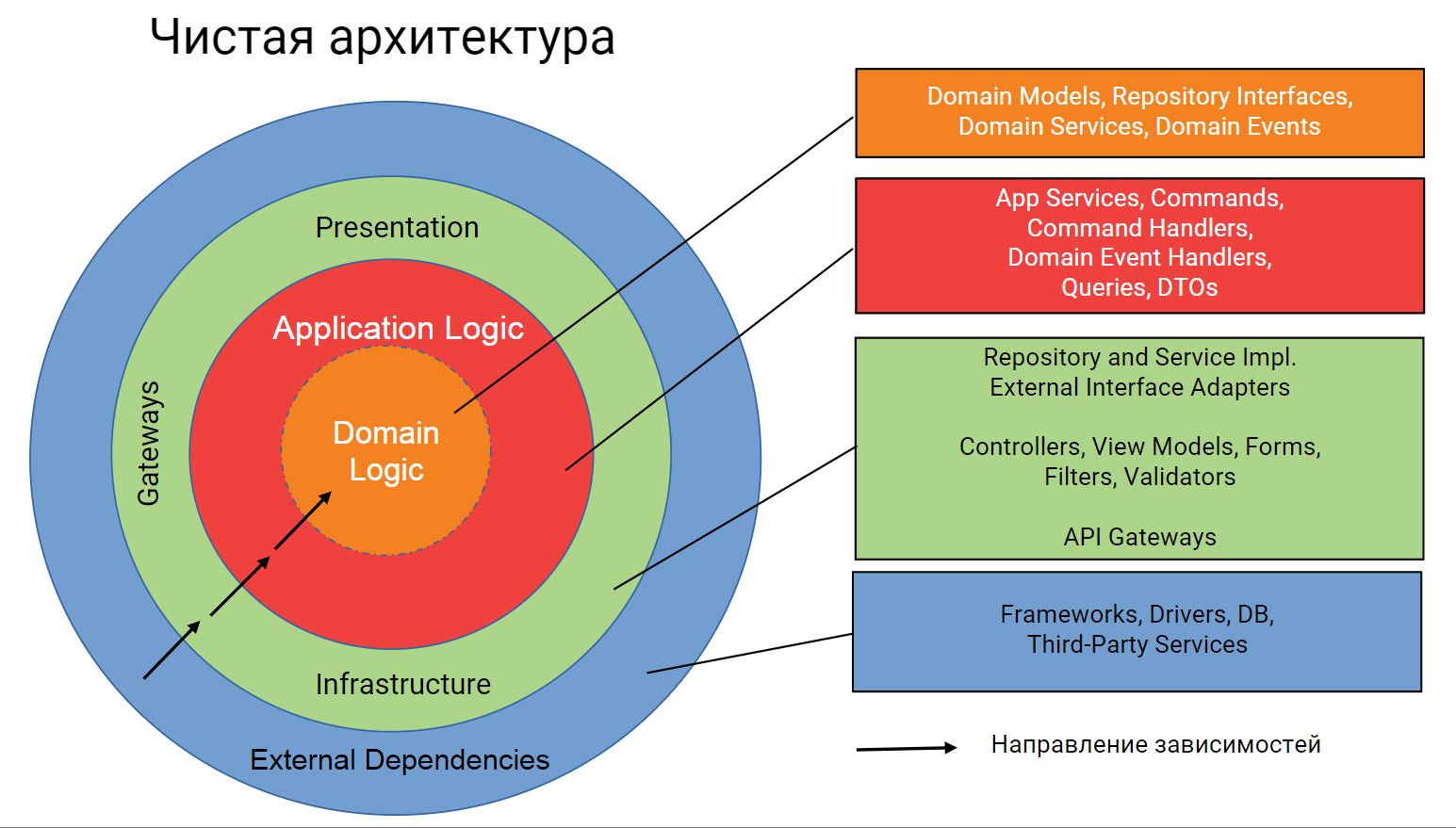
Согласно этой архитектуре, внутренний круг реализует логику предметной области, или домен. Этот слой не должен зависеть ни от чего, выходящего за его пределы. Вокруг доменной логики идет Application Logic — это классы, которые реализуют варианты использования моделей предметной области, то есть сценарии использования. Например, «добавить товар в корзину», «разместить заказ». Этот слой должен быть тонким, так как всего лишь манипулирует моделями доменного слоя и преобразует данные между доменом и внешним миром. Никакой сложной логики он содержать не должен и может зависеть только от домена. В следующем слою располагаются модели представления (view models), контроллеры, инфраструктурный код, реализации интерфейсов доменного слоя. Это более нестабильный код, поэтому внутренняя часть нашего приложения - ядро - не должна от него зависеть. На схеме стрелками показаны направления зависимостей слоев друг от друга. Это даёт нам то, что мы можем проектировать и сразу же тестировать бизнес-логику без реализации каких-то конкретных технологий.
Итак, основные принципы чистой архитектуры:
приложение строится вокруг независимой от других слоев объектной модели;
внутренние слои определяют интерфейсы, внешние слои содержат реализации интерфейсов;
направление зависимостей — от внешних слоев к внутренним;
при пересечении границ слоя данные должны преобразовываться.
Правило зависимостей (Dependency Rule) — ключевое правило. Для достижения такого направления зависимостей нам на помощь придет принцип инверсии зависимостей (dependency inversion). И если в традиционной трехслойной архитектуре бизнес-логика непосредственно зависела от слоя доступа к данным, то в чистой архитектуре она зависит только от интерфейса, который определен в этом же слое, а его реализация находится в слое инфраструктуры. Таким образом бизнес-сервис не зависит от инфраструктуры. В рантайме, конечно, вместо интерфейса будет подставлена конкретная реализация, и этого можно добиться за счет механизма dependency injection, который предоставляют, наверно, все современные фреймворки.

Итак, чистая архитектура дает нам независимость бизнес-слоя от:
UI
фреймворков
БД
сторонних сервисов
Соответственно, разработка модульных тестов сильно упрощается. Дополнительный бонус — ускорение выполнения модульных тестов, так как отсутствуют обращения к физической БД и шаги по ее инициализации тестовыми данными. Также мы получаем относительную простоту замены каких-либо реализаций.
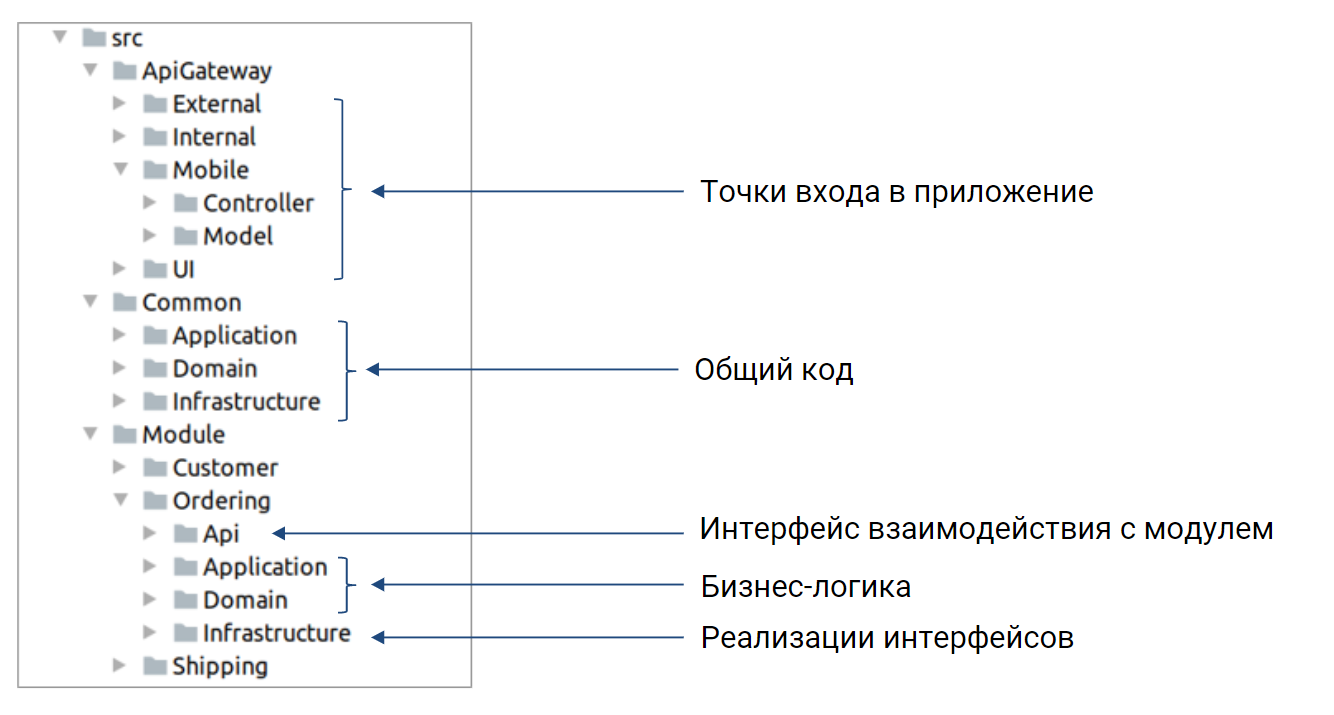
При такой архитектуре структура проекта выглядит следующим образом:
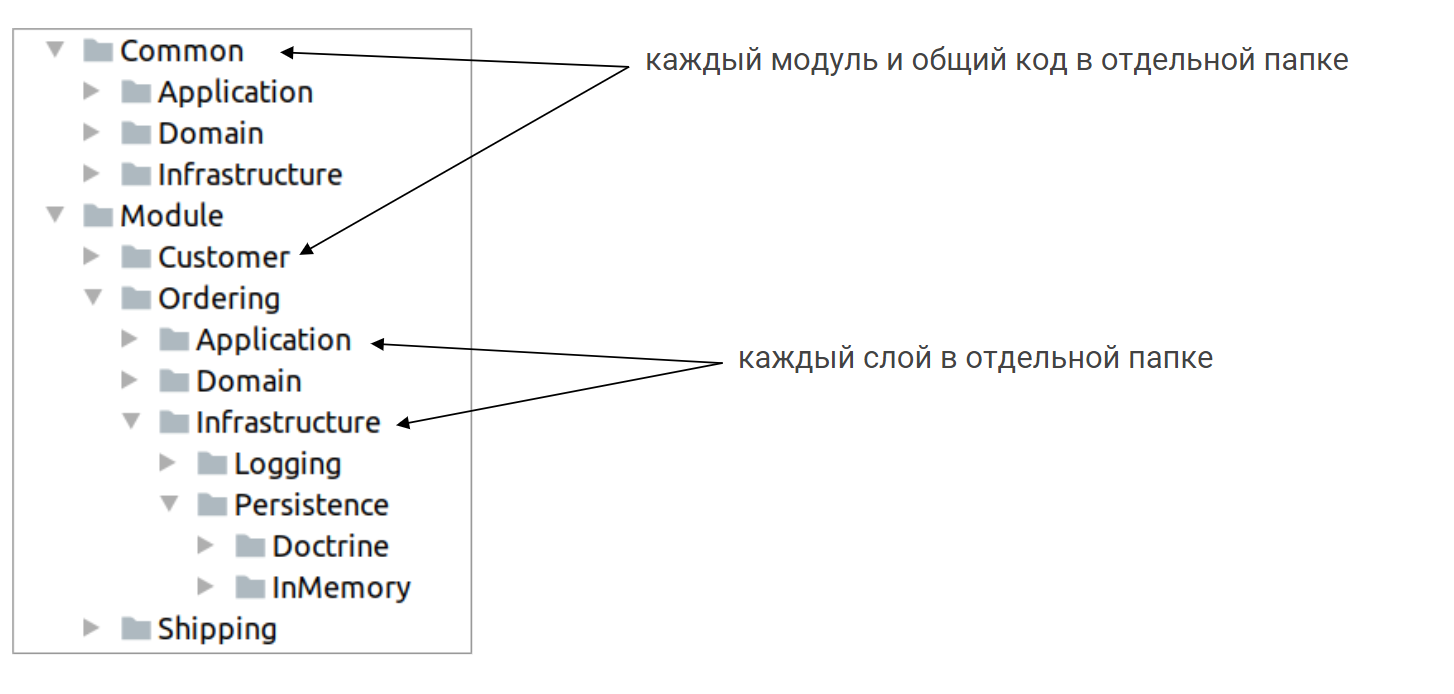
Каждый модуль выделен в отдельную папку, также как и каждый слой внутри модуля выделен в отдельную папку. Есть папка, которую мы назвали Common, там находится библиотечный код, не специфичный для какого либо домена.
Взаимодействие модулей. Anti-corruption Layer.
Еще один шаблон, который мы использовали, это Anti-corruption Layer. Он также впервые был введен Эриком Эвансом в книге «Domain-Driven Design»:
Create an isolating layer to provide clients with functionality in terms of their own domain model. The layer talks to the other system through its existing interface, requiring little or no modification to the other system. Internally, the layer translates in both directions as necessary between the two models.
ACL наших модулей представлен адаптерами, которые обращаются напрямую к API другого модуля, но преобразуют входные данные в модели вызываемого модуля, а выходные данные в модели вызывающего модуля.

Например, есть модуль заказов Ordering и модуль доставки Shipping. Сервис доставки получает информацию о заказах по их ids от модуля заказов. Для этого в модуле Ordering мы выделяем API, который будет являться контрактом для взаимодействия с ним. Сам модуль получает данные из таблиц общей БД, компонует их в DTO и через API отдает модулю Shipping. Если мы будем напрямую использовать это DTO в модуле доставки, мы создадим очень жесткую связь. При изменении контракта модуля заказов нам придется менять все места использования моделей этого модуля в других модулях, чего нам хотелось бы избежать. К тому же в модуле Shipping нужны не все данные заказа, а только некоторые из них, например, информация о клиенте, о его адресах доставки, способе доставки. Поэтому в модуле доставки определяется и используется своя модель заказа. К этой модели адаптер и преобразует полученные данные. И, пожалуй, это самый сильный аргумент в пользу адаптеров, ведь многим разработчикам кажется оверинжинирингом писать адаптеры к собственному коду.
Ниже показан пример организации кода.
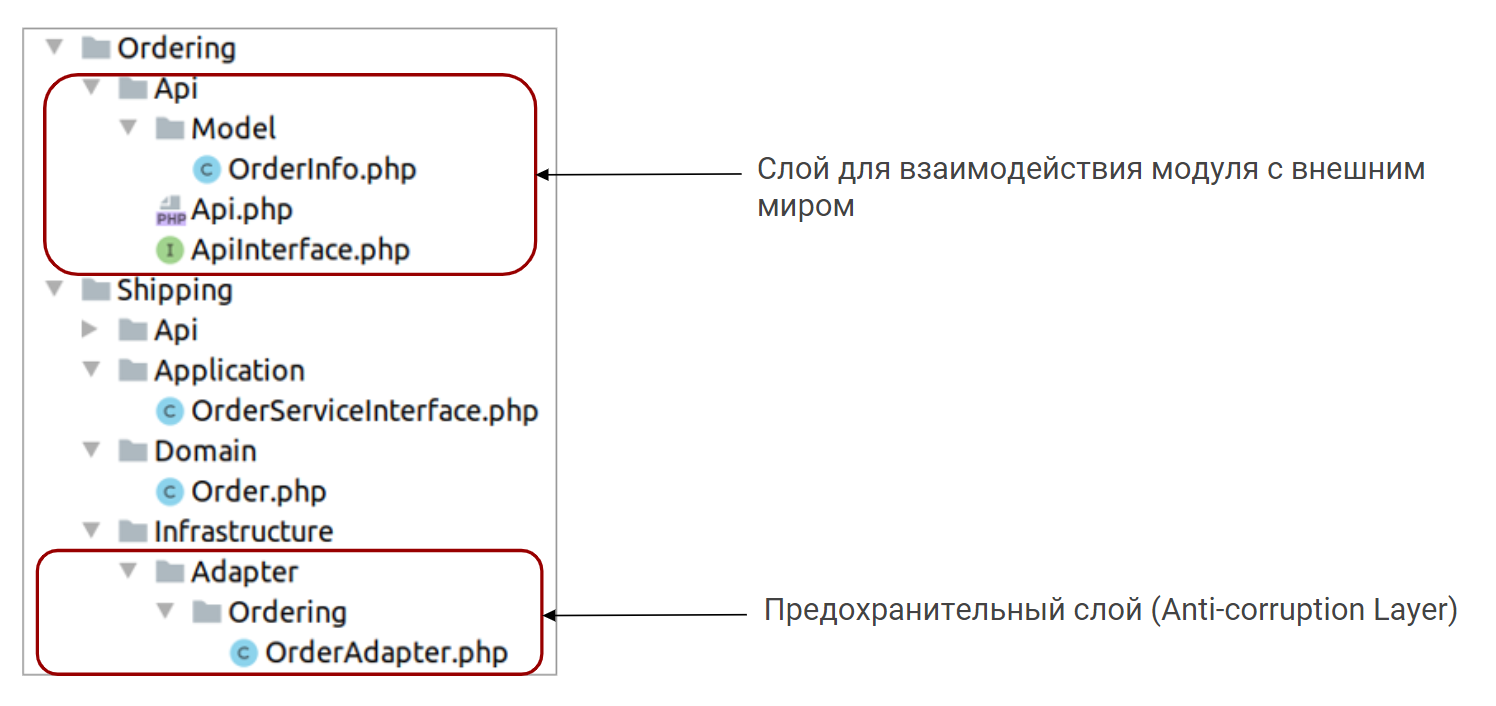
В модуле заказов есть папка Api, у нее есть своя модель OrderInfo, ApiInterface и реализация ApiInterface.
В модуле доставки на уровне инфраструктуры размещается папка Adapter. Там находятся классы, которые имеют право обращаться к другим модулям. Любые классы вне этой папки не имеют права взаимодействовать с другими модулями.
Важно учесть: так как у нас общая база данных, то все могут обращаться к ней напрямую. Но это создает жесткую связь по данным. Меняя структуру таблиц заказов, мы должны перепроверить, что остальные модули работают правильно, потому что мы могли их сломать. Чтобы избежать такой сильной зависимости, мы получаем «чужие» данные только через API модуля, напрямую в базу за ними не ходим.
На практике бывает сложно такое реализовать, особенно когда идет выборка для вьюшной модели, и там нужны данные из нескольких модулей. В этих случаях можно использовать CQRS.
Взаимодействие с внешним миром. API Gateways.
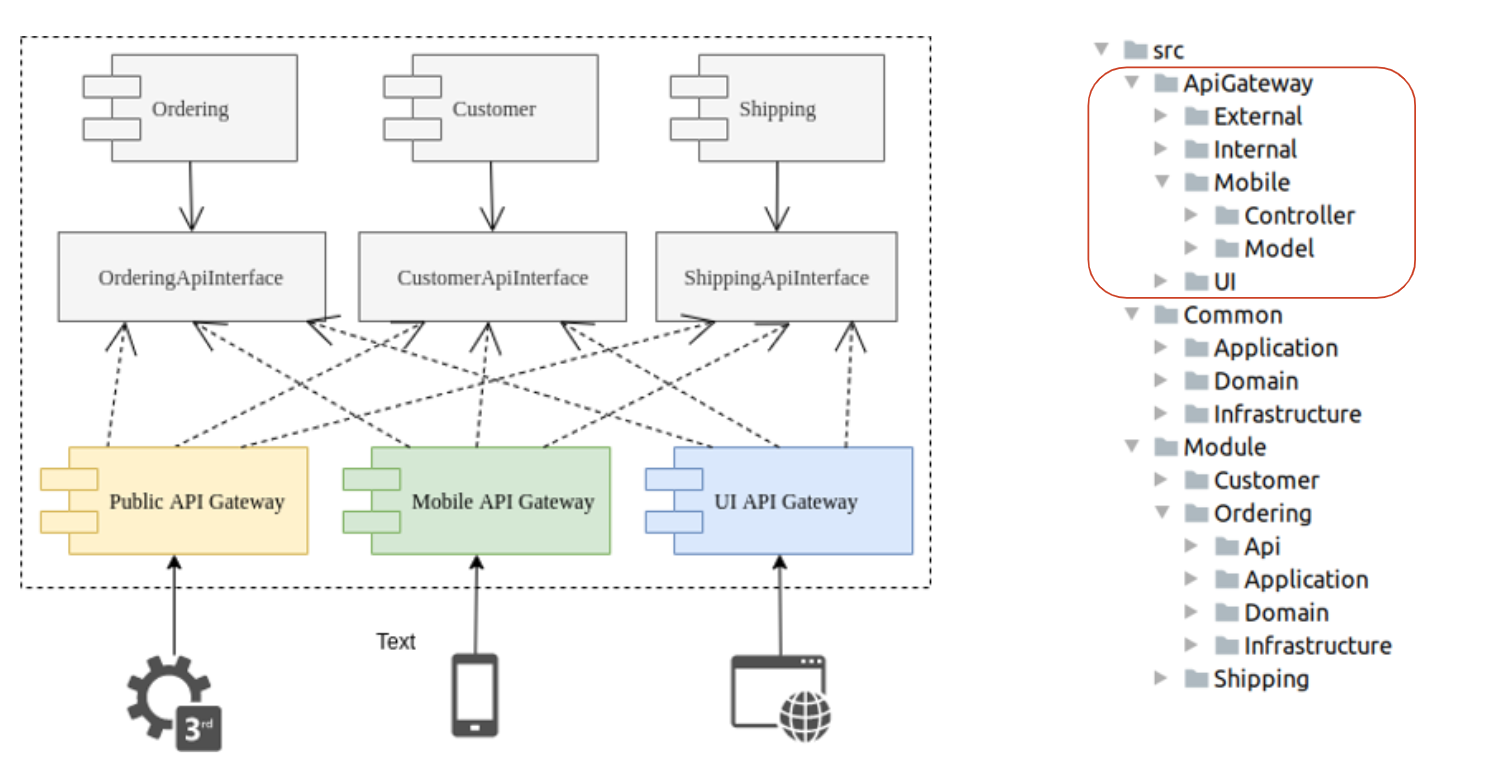
Клиентами нашего API могут быть внешние сервисы, мобильные приложения, UI. Для каждого из них мы выделили отдельный API Gateway, который может обращаться и собирать информацию из разных модулей через их API. Так как клиенты могут требовать данные от нескольких модулей, неразумно было размещать API Gateway непосредственно в модулях, поэтому мы их вынесли на верхний уровень.
Итоговая структура проекта
Контроль зависимостей
К сожалению, PHP не предоставляет механизмов контроля зависимостей между нашими модулями и инкапсуляции деталей их реализации. Без них очень сложно контролировать соблюдение принятых принципов, поэтому нужно реализовать этот контроль другими средствами. Мы используем статический анализатор кода deptrac для контроля зависимостей между классами. Он устанавливается через composer и запускается через командную строку. Проверка зависимостей встроена в наш CI/CD, и код, нарушающий архитектуру, не попадет ни в тестовое, ни в прод окружение.
Для настройки утилиты у нас есть два файла: один depfile-layers.yaml, контролирующий зависимости между слоями, и второй depfile-modules.yaml, описывающий зависимости между модулями приложения. В файле настроек зависимостей между слоями мы прописываем названия слоев и правила, по которым в этот слой попадает код:
Domain не может зависеть ни от чего;
Application только от Domain;
API от Domain и Application;
Infrastructure от всех внутренних слоев.
depfile-layers.yaml
paths:
- ./src
- ./vendor
exclude_files: ~
layers:
- name: Domain
collectors:
- type: directory
regex: /src/\w+/Domain/.*
- name: Application
collectors:
- type: directory
regex: /src/\w+/Application/.*
- name: Api
collectors:
- type: directory
regex: /src/\w+/Api/.*
- name: Infrastructure
collectors:
- type: bool
must:
- type: directory
regex: /src/\w+/Infrastructure/.*
- name: Vendor
collectors:
- type: directory
regex: /vendor/.*
ruleset:
Domain:
Application:
- Domain
Api:
- Domain
- Application
Infrastructure:
- Domain
- Application
- Api
- VendorС настройкой зависимостей между модулями было немного сложнее, так как deptrac не поддерживает такое понятие, как «модуль». Поэтому нам пришлось использовать модули как отдельные слои, для которых прописано правило, что они не могут зависеть друг от друга. В исключения добавлена папка Adapter, в которой лежат классы предохранительного слоя, и только через них мы можем взаимодействовать с другими модулями.
depfile-modules.yaml
paths:
- ./src
exclude_files:
- .\/src\/.*\/Infrastructure\/Adapter\/.*
layers:
- name: Customer
collectors:
- type: directory
regex: /src/Module/Customer/.*
- name: Ordering
collectors:
- type: directory
regex: /src/Module/Ordering/.*
- name: Shipping
collectors:
- type: directory
regex: /src/Module/Shipping/.*
ruleset: ~Ослабление связей. Event-Driven Design.
Разделив приложение на модули, мы все еще имеем сильную связанность по коду между модулями, так как им постоянно нужно взаимодействовать друг с другом. Рассмотрим ослабление связей на примере онлайн-заказа.
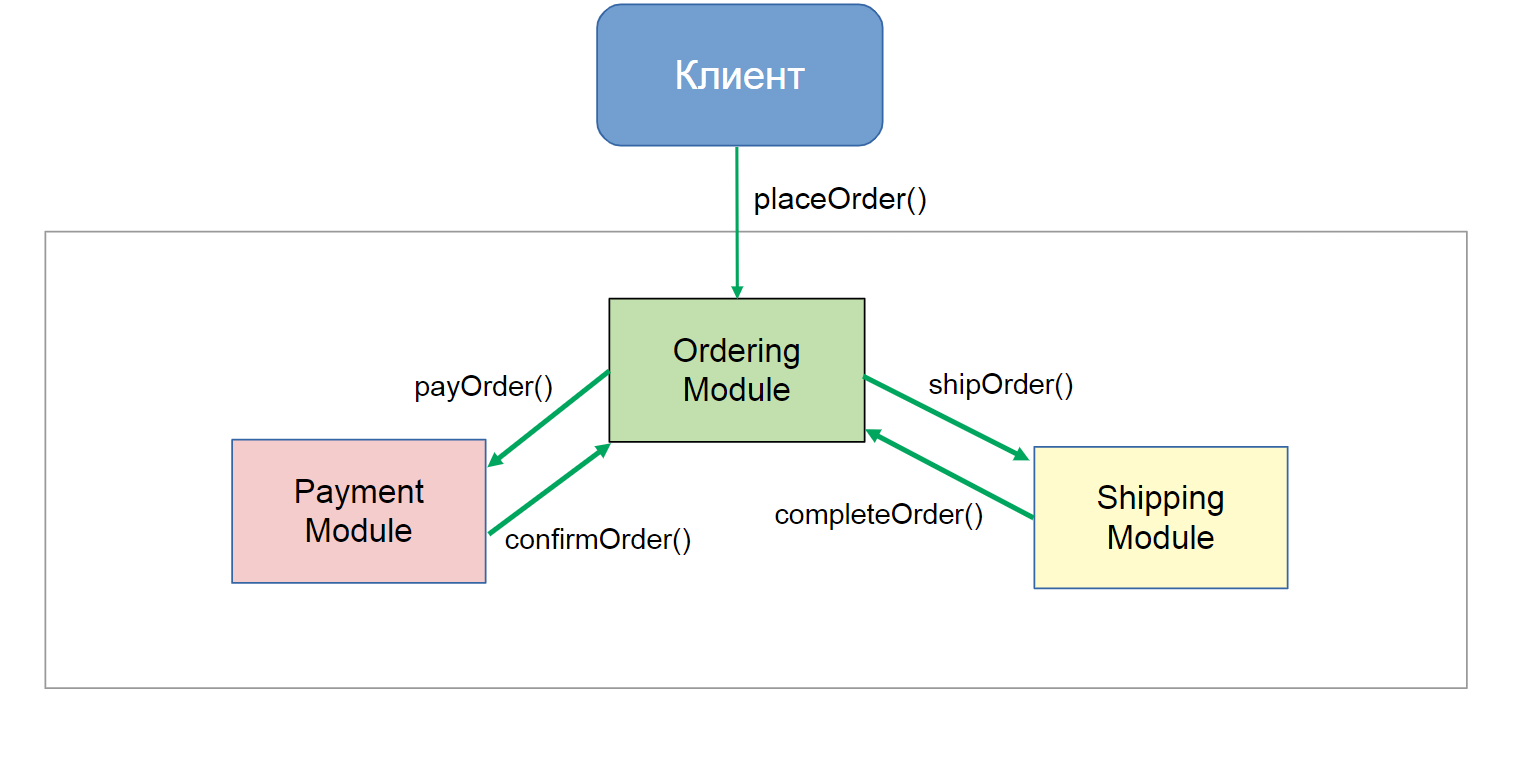
Клиент размещает заказ, он обращается к модулю заказов, модуль заказов обращается к платежному модулю, потом обратно возвращается к модулю заказов, чтобы подтвердить, что платеж прошел; модуль заказов обращается к модулю доставки, чтобы он доставил клиенту заказ. На лицо сильная зависимость модулей друг от друга.
Для решения проблемы мы можем внести в нашу инфраструктуру брокер сообщений и общаться между собой посредством событий.
Наша бизнес-модель может генерировать доменные события. Например, модуль заказов говорит о том, что он создал заказ, и забывает об этом. Событие попадает в очередь сообщений и все, кто заинтересован в этом событии, подписываются на него и производят действия, которые им нужны. В данном случае модуль оплаты требует просто оплатить заказ, потом генерирует свое событие, что заказ оплачен или не оплачен. На него подписан модуль заказов, он его соответствующим образом обрабатывает. С модулем доставки все то же самое.
Таким образом, мы ослабили зависимости тем, что теперь у нас модуль заказов ничего не знает о том, что существуют другие модули. Он просто умеет генерировать события и обрабатывать события других контекстов, которые ему интересны.
Также мы теперь можем легко добавить новый модуль, не затрагивая модуль заказов. Например, нам нужно отправлять клиентам уведомления о событиях (заказ оплачен, подтвержден и т.д.) и для этого у нас появляется модуль уведомлений, который подписывается на интересующие его события.
Важный момент. Для того чтобы участники действительно не были связаны по коду, нужно использовать так называемую weak-schema serialization, то есть простые форматы данных, такие как json, xml. В сериализованных событиях не должно быть никаких названий классов.
Например, класс OrderPlaced
class OrderPlaced implements DomainEventInterface
{
private const TYPE = 'order.order_placed';
// ...
public function __construct(string $orderId, Customer $customer, Products $products, float $total)
{
$this->orderId = $orderId;
$this->customer = $customer;
$this->products = $products;
$this->total = $total;
}
}может быть сериализован как json:
{
"orderId": 874,
"customer": {
"id": 87058,
"name": "John Doe",
"postalCode": "EC1-001",
"age": 35,
"status": "gold"
},
"products": [
{
"id": 84039,
"name": "ice cream"
},
{
"id": 1908,
"name": "burger"
}
],
"total": 17.95
}Заключение
Итак, подведем итог. Какие приемы мы использовали, чтобы избавиться от big ball of mud:
Разделение приложения на модули с использованием ограниченных контекстов DDD;
Разделение модулей на слои с использованием чистой архитектуры;
Взаимодействие модулей через предохранительный слой;
Ограничение на доступ к таблицам БД;
Ослабление связей с использованием событийно-ориентированной архитектуры;
Эффективная организация кодовой базы;
Контроль архитектуры с помощью deptrac.
Когда подходит такая архитектура?
Нет необходимости в независимом масштабировании отдельных частей приложения;
Нет средств, времени, опыта, знаний для развертывания микросервисной архитектуры;
Для стабилизации границ модулей перед выделением их в микросервисы;
Размеры команды разработки не мешают работать в рамках монолита.
Также можно посмотреть оценку зависимости стоимости разработки от количества и сложности фич, приведенную Sander Mac. Как мы видим, стоимость внедрения микросервисной архитектуры на начальном этапе очень высока. Самая низкая стоимость у монолита. Посередине находится модульный монолит.

В заключение хотелось бы привести цитату:
If you can't build a monolith, what makes you think microservices are the answer?
P.S.
На нижегородском PHP-митапе 24 апреля 2021 года Валентин Удальцов (ведущий каналов Пых и PHP Point) выступал с докладом «Как структурировать код, чтобы не получить большой ком грязи», в котором предлагает аналогичные подходы к организации монолита.
