
Люди учатся архитектуре по старым книжкам, которые писались для Java. Книжки хорошие, но дают решение задач того времени инструментами того времени. Время поменялось, C# уже больше похож на лайтовую Scala, чем Java, а новых хороших книжек мало.
В этой статье мы рассмотрим критерии хорошего кода и плохого кода, как и чем измерять. Увидим обзор типовых задач и подходов, разберем плюсы и минусы. В конце будут рекомендации и best practices по проектированию web-приложений.
Эта статья является расшифровкой моего доклада с конференции DotNext 2018 Moscow. Кроме текста, под катом есть видеозапись и ссылка на слайды.

Как вы, наверное, могли догадаться, сегодня я буду говорить про разработку корпоративного ПО, а именно, как можно структурировать современные веб-приложения:
Сформулируем критерии. Мне очень не нравится, когда разговоры про проектирование ведутся в стиле «моё кунг-фу сильнее твоего кунг-фу». У бизнеса есть, в принципе, один конкретный критерий, который называется «деньги». Все знают, что время — это деньги, поэтому две вот эти составляющие чаще всего самые важные.

Итак, критерии. В принципе бизнес чаще всего просит нас «как можно больше фич в единицу времени», но с одним нюансом — эти фичи должны работать. И первый этап, на котором это может сломаться, это код ревью. То есть, вроде бы, программист сказал: «Я за три часа сделаю». Три часа прошло, пришло в код ревью, а тимлид говорит: «Ой, нет, переделывай». Там ещё три — и сколько итераций код ревью прошло, на столько надо умножить три часа.
Следующий момент — это возвраты с этапа тестирования сдачи-приёмки. То же самое. Если фича не работает, значит, она не сделана, эти три часа растягиваются на неделю, две — ну там как обычно. Последний критерий это количество регрессии и багов, которые всё-таки, несмотря на тестирование и приёмку, прошли в продакшн. Это тоже очень плохо. С этим критерием есть одна проблема. Его сложно отслеживать, потому что связь между тем, что мы что-то такое запушивали в репозиторий, и тем, что потом через две недели что-то сломалось, бывает сложно отследить. Но, тем не менее, возможно.
Давным-давно, когда программисты только начинали писать программы, не было ещё никакой архитектуры, и все делали всё, как им нравится.

Поэтому получался вот такой архитектурный стиль. У нас это называется «лапшекод», за рубежом говорят «спагетти-код». Всё связано со всем: мы меняем что-то в точке А — в точке Б ломается, понять, что с чем связано, совершенно невозможно. Естественно, программисты довольно быстро сообразили, что так дело не пойдёт, и надо какую-то структуру сделать, и решили, что нам помогут какие-то слои. Вот если вы представите, что фарш — это код, а лазанья — это такие слои, вот вам иллюстрация слоёной архитектуры. Фарш остался фаршем, но теперь фарш из слоя № 1 не может просто так взять и пойти общаться с фаршем из слоя № 2. Мы придали коду какой-то форму: даже на картинке вы можете увидеть, что лазанья более оформлена.
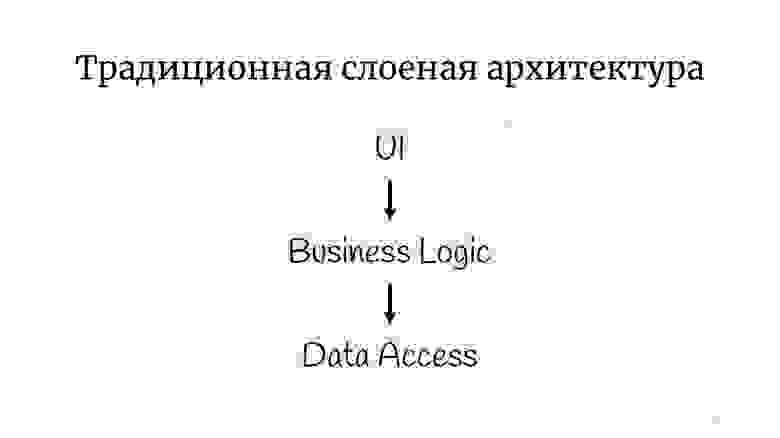
С классической слоёной архитектурой, наверное, все знакомы: есть UI, есть бизнес-логика и есть Data Access layer. Бывают ещё всякие сервисы, фасады и слои, названные по имени архитектора, который уволился из компании, их может быть неограниченно много.

Следующим этапом была так называемая луковая архитектура. Казалось бы, огромная разница: до этого были квадратик, а тут стали кружочки. Кажется, что абсолютно другое.
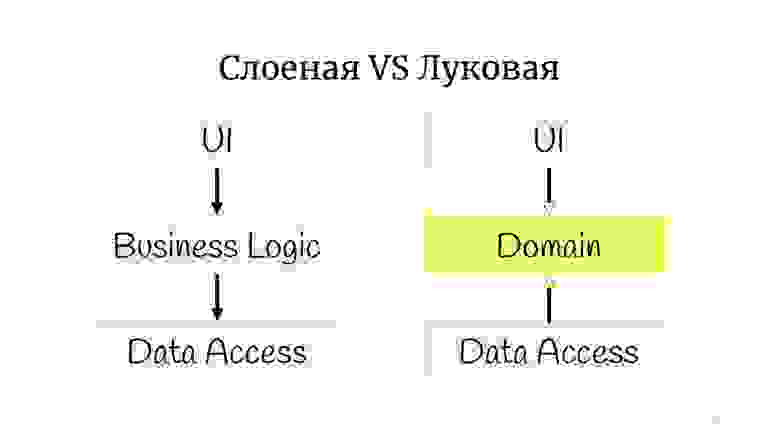
На самом деле нет. Вся разница в том, что где-то в это время сформулировали принципы SOLID, и выяснилось, что в классической луковой есть проблема с инверсией зависимостей, потому что абстрактный доменный код почему-то зависит от реализации, от Data Access, поэтому Data Access решили развернуть, и сделали так, чтобы Data Access зависел от домена.
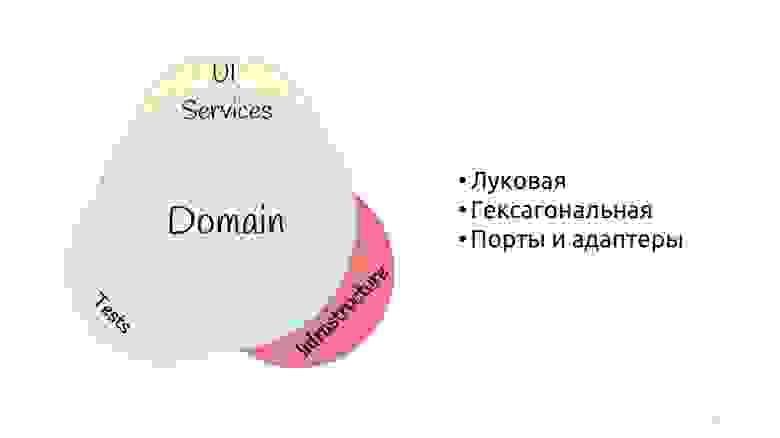
Я вот здесь поупражнялся в рисовании и нарисовал луковую архитектуру, но не классически «колечками». У меня получилось нечто среднее между многоугольником и кружками. Я это сделал, чтобы просто показать, что, если вы встречали слова «луковая», «гексагональная» или «порты и адаптеры» — это всё одно и то же. Смысл в том, что домен в центре, его заворачивают в сервисы, они могут быть доменные или application-сервисы, кому как больше нравится. А внешний мир в виде UI, тестов и инфраструктуры, куда переехал DAL — они общаются с доменом через этот сервисный слой.
Давайте посмотрим, как в такой парадигме будет выглядеть простой use case — обновление email'а пользователя.

Нам нужно отправить запрос, провести валидацию, обновить в базе данных значение, отправить на новый email уведомление: «Всё в порядке, вы поменяли email, мы знаем, всё хорошо», и ответить браузеру «200» — всё окей.
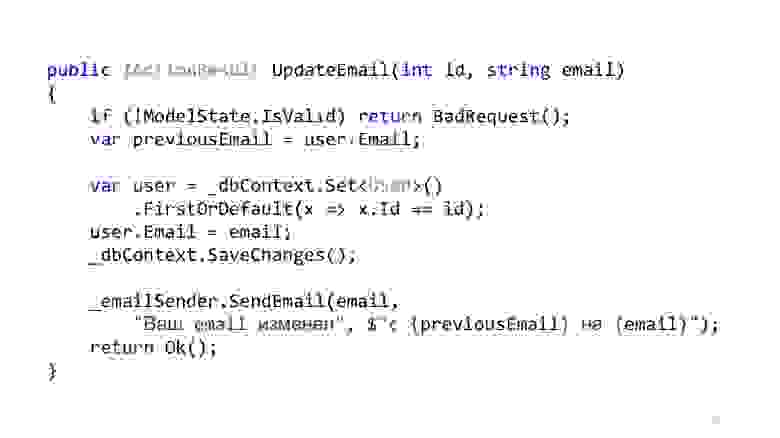
Код может выглядеть примерно как-то так. Вот у нас есть стандартная ASP.NET MVC-валидация, есть ORM, чтобы прочитать и обновить данные, и есть какой-нибудь email-sender, который отправляет нотификацию. Вроде как всё хорошо, да? Один нюанс — в идеальном мире.
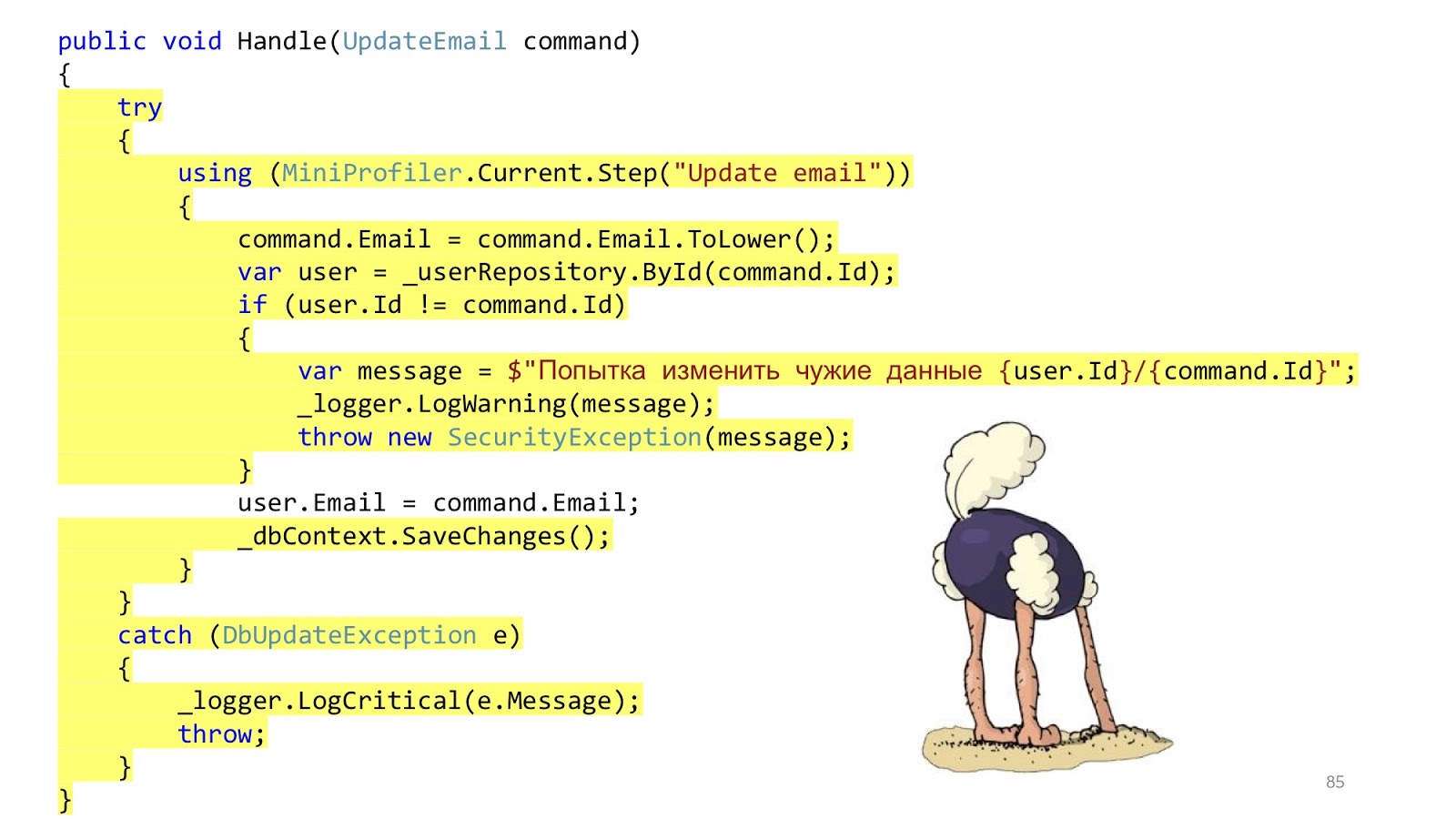
В реальном мире ситуация чуть-чуть отличается. Смысл в том, что надо добавить авторизацию, проверку ошибок, форматирование, логирование и профилирование. Это всё не имеет никакого отношения к нашему use case'у, но это всё должно быть. И вот тот маленький кусочек кода стал большим и страшным: с большой вложенностью, с большим количеством кода, с тем, что это тяжело читать, а главное, что инфраструктурного кода больше, чем доменного.

«Где же сервисы?» — скажете вы. Я же записал всю логику в контроллеры. Конечно, это проблема, сейчас я добавлю сервисы, и всё будет хорошо.

Добавляем сервисы, и действительно становится лучше, потому что вместо большой портянки получилась одна маленькая красивая строчка.
Стало лучше? Стало! А еще мы теперь этот метод можем повторно использовать в разных контроллерах. Результат налицо. Давайте посмотрим на реализацию этого метода.

А вот здесь уже всё не так хорошо. Этот код никуда не делся. Всё то же самое мы просто перенесли в сервисы. Мы решили не решать проблему, а просто её замаскировать и перенести в другое место. Вот и всё.

Дополнительно к этому появляются некоторые другие вопросы. А валидацию мы должны делать в контроллере или здесь? Ну, вроде как, в контроллере. А если надо сходить в базу данных и посмотреть, что такой ID есть или что нет другого пользователя с таким email'ом? Хмм, ну тогда в сервисе. А вот обработка ошибок здесь? Эту обработку ошибок, наверное, здесь, а ту обработку ошибок, которая будет отвечать браузере, в контроллере. А метод SaveChanges, он в сервисе или надо перенести его в контроллер? Может быть и так, и так, потому что, если сервис вызывается один, логичнее вызвать в сервисе, а если у вас в контроллере три метода сервисов, которые надо вызвать, тогда надо вызывать его за пределами этих сервисов, чтобы транзакция была одна. Вот такие размышления наводят на мысль, что, может быть, слои не решают каких-то проблем.

И эта идея пришла в голову не одному человеку. Если погуглить, по крайней мере три вот этих почтенных мужа пишут примерно об одном и том же. Сверху вниз: Стивен .NET Junkie (к сожалению, не знаю его фамилию, потому что она нигде в интернете не фигурирует), автор IoС-контейнера Simple Injector. Дальше Джимми Богард — автор AutoMapper'а. И внизу Скотт Влашин, автор сайта «F# for fun and profit».
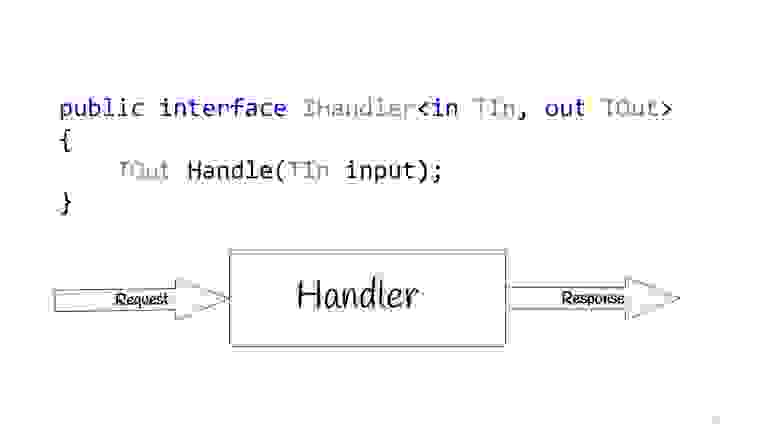
Все эти люди говорят об одном и том же и предлагают строить приложения не на основе слоёв, а на основе вариантов использования, то есть тех требований, о которых бизнес нас просит. Соответственно, вариант использования в C# может быть определён с помощью интерфейса IHandler. У него есть входные значения, есть выходные значения и есть сам метод, который собственно выполняет этот сценарий использования.

А внутри этого метода может быть как доменная модель, так и какая-нибудь денормализованная модель для чтения, может быть с помощью Dapper'а или с помощью Elastic Search'а, если надо что-то искать, а, возможно, у вас есть Legacy-система с хранимыми процедурами — нет проблем, а также сетевые запросы — ну и вообще всё что угодно, что вам там может потребоваться. Но если слоёв нет, как же быть?

Для начала давайте избавляться от UserService. Уберём метод и создадим класс. И ещё уберём, и снова уберём. А потом возьмём и уберём класс.

Давайте подумаем, эти классы эквивалентны или нет? Класс GetUser возвращает данные и ничего не меняет на сервере. Это, например, про запрос «Дай мне ID пользователя». Классы UpdateEmail и BanUser возвращают результат операции и изменяют состояние. Например, когда мы говорим серверу: «Пожалуйста, измени состояние, надо вот что-то поменять».
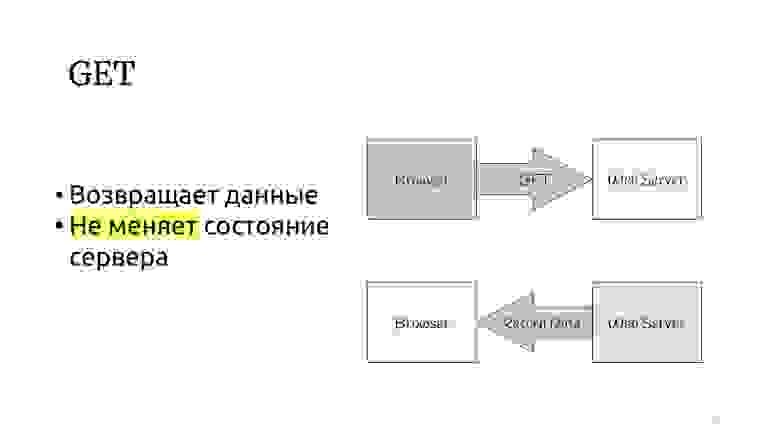
Посмотрим на протокол HTTP. Есть метод GET, который по спецификации протокола HTTP должен возвращать данные и не менять состояние сервера.
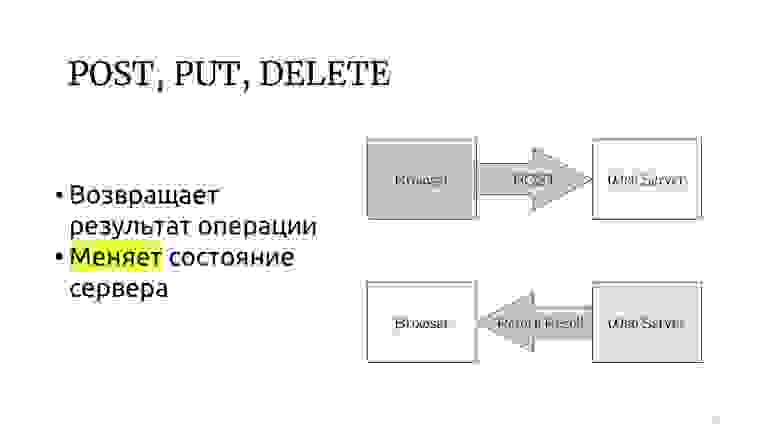
И есть другие методы, которые могут менять состояние сервера и возвращать результат операции.

Парадигма CQRS как будто специально создана для протокола HTTP. Query — это GET-операции, а команды — это PUT, POST, DELETE — не надо ничего придумывать.

Доопределим наш Handler и определим дополнительные интерфейсы. IQueryHandler, который отличается только тем, что мы повесили constraint о том, что тип входных значений – это IQuery. IQuery — это маркерный интерфейс, в нём ничего нет, кроме вот этого дженерика. Дженерик нам нужен для того, чтобы поставить constraint в QueryHandler'е, и теперь, объявляя QueryHandler, мы не можем туда передать не Query, а передавая туда объект Query, мы знаем его возвращаемое значение. Это удобно, если у вас одни интерфейсы, чтобы потом не искать в коде их реализации, и опять же чтобы не напутать. Вы пишете IQueryHandler, пишете туда реализацию, и в TOut вы не можете подставить другой тип возвращаемого значения. Это просто не скомпилируется. Таким образом сразу видно, какие входные значения соответствуют каким входным данным.

Абсолютно аналогичная ситуация для CommandHandler за одним исключением: вот этот дженерик потребуется ещё для одного трюка, который мы посмотрим чуть дальше.
Handler'ы мы объявили, какая же у них реализация?
Какая-то проблема есть, да? Кажется, что-то не помогло.
А не помогло, потому что мы ещё в середине пути, нам нужно ещё немножечко доработать, и на этот раз потребуется воспользоваться паттерном декоратор, а именно его замечательной особенностью компоновки. Декоратор можно завернуть в декоратор, завернуть в декоратор, завернуть в декоратор — продолжайте, пока не надоест.

Тогда у нас всё будет выглядеть следующим образом: есть входное Dto, оно входит в первый декоратор, во второй, третий, дальше мы заходим в Handler и так же выходим из него, проходим через все декораторы и возвращаем обратно Dto в браузере. Объявляем абстрактный базовый класс для того, чтобы потом наследовать, в конструктор передаётся само тело Handler'а, и объявляем абстрактный метод Handle, в котором и будет навешиваться дополнительная логика декораторов.
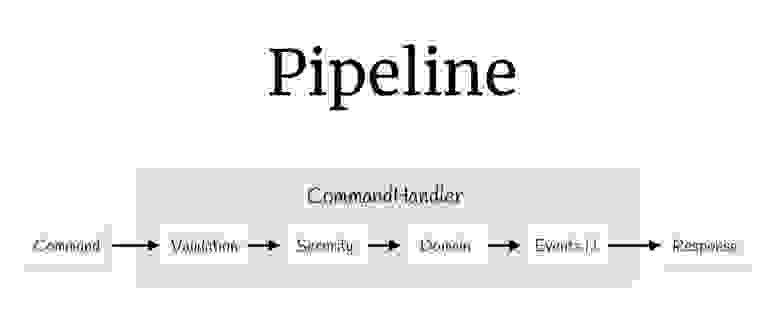
Теперь с помощью декораторов можно собрать целый pipeline. Начнём с команд. Что у нас было? Входные значения, валидация, проверка прав доступа, сама логика, какие-то события, которые случаются в результате этой логики, и возвращаемые значения.

Начнём с валидации. Объявляем декоратор. В конструктор этого декоратора приходит IEnumerable из валидаторов типа T. Мы их все выполняем, проверяем, если валидация не прошла и тип возвращаемого значения — это
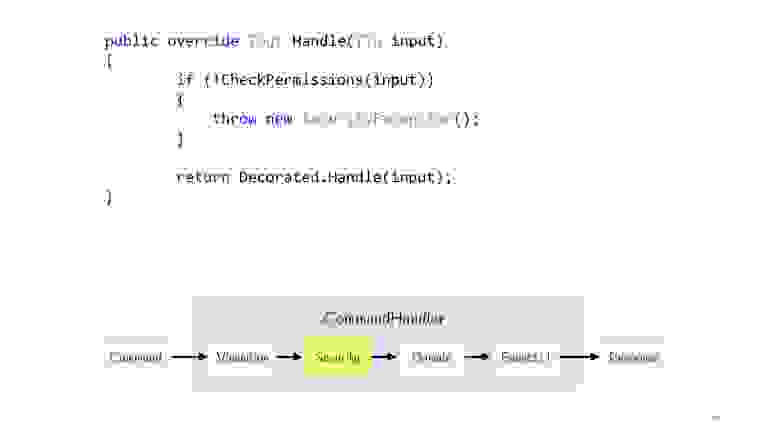
Следующий этап — это Security. Так же объявляем декоратор, делаем метод CheckPermission, проверяем. Если вдруг что-то пошло не так, всё, не продолжаем. Теперь после того, как мы провели все проверки и уверены, что всё хорошо, мы можем выполнять нашу логику.
Прежде чем показать реализацию логики, я хочу начать немножечко чуть раньше, а именно с входных значений, которые туда приходят.
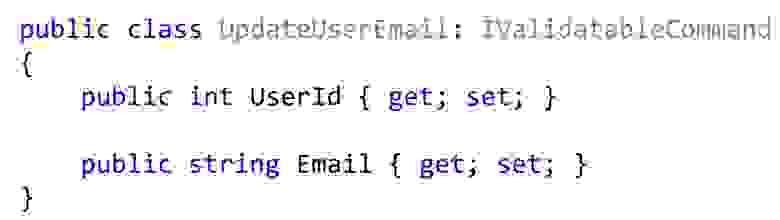
Вот если мы так выделяем такой класс, то чаще всего он может выглядеть как-то вот так. По крайней мере такой код, который я вижу в повседневной работе.

Чтобы валидация работала, мы добавляем сюда какие-то атрибуты, которыми рассказываем, что это за валидация. Это поможет с точки зрения структуры данных, но не поможет с такой валидацией, как проверка значений в БД. Здесь просто EmailAddress, непонятно, как, где проверять, как эти атрибуты использовать для того, чтобы в базу сходить. Вместо атрибутов, можно перейти к специальным типам, тогда эта проблема решится.

Вместо примитива
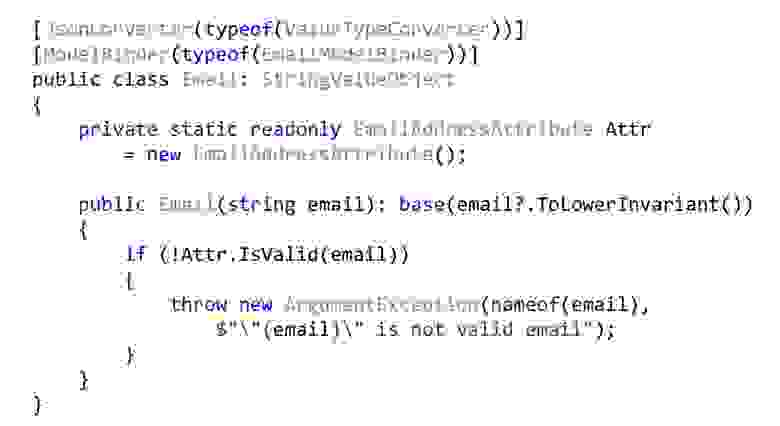
Аналогично поступаем с Email. Преобразуем все Email'ы к нижней строке, чтобы у нас всё выглядело одинаково. Дальше берём Email-атрибут, объявляем его как статический для совместимости с валидацией ASP.NET и здесь его просто вызываем. То есть так тоже можно делать. Для того, чтобы инфраструктура ASP.NET всё это подхватила, придётся немножко изменить сериализацию и/или ModelBinding. Кода там не очень много, он сравнительно простой, поэтому я не буду на этом останавливаться.
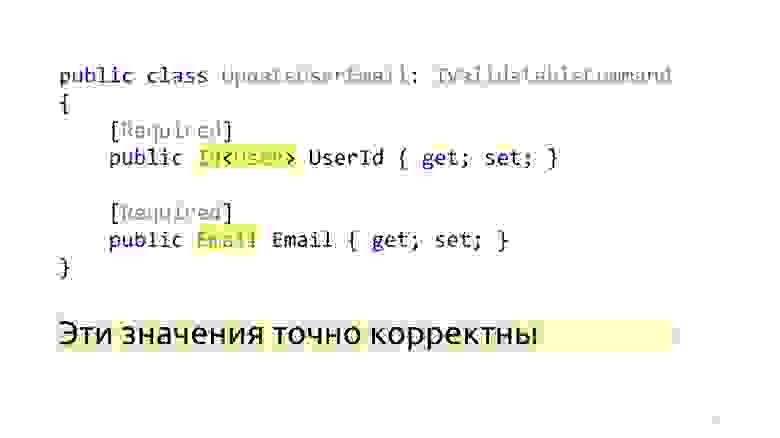
После этих изменений, вместо примитивных типов, у нас здесь появляются специализированные типы: Id и Email. И после того, как отработали вот эти ModelBinder и обновлённый десериализатор, мы точно знаем, что эти значения корректны и в том числе, что такие значения есть в БД. «Инварианты»

Следующий момент, на котором я хотел бы остановиться, это состояние инвариантов в классе, потому что довольно часто используется анемичная модель, в которой есть просто класс, много геттеров-сеттеров, совершенно непонятно, как они должны работать вместе. Мы работаем со сложной бизнес-логикой, поэтому нам важно, чтобы код был самодокументируемым. Вместо этого лучше объявить настоящий конструктор вместе с пустым для ORM, его можно объявлять protected, чтобы программисты в своём прикладном коде не смогли его вызвать, а ORM смогла. Здесь мы передаём уже не примитивный тип, а тип Email, он уже точно корректный, если это null, мы всё ещё выбрасываем Exception. Можно использовать какие-нибудь Fody, PostSharp, но скоро выходит C# 8. Соответственно, там будет Non-nullable reference type, и лучше дождаться его поддержки в языке. Следующий момент, если мы хотим поменять имя и фамилию, скорее всего мы хотим их менять вместе, поэтому должен быть соответствующий публичный метод, который меняет их вместе.

В этом публичный методе мы также проверяем, что длина этих строк соответствует тому, что мы используем в базе данных. И если что-то не так, то останавливаем выполнение. Здесь я использую тот же самый приём. Объявляю специальный атрибут и просто его вызываю в прикладном коде.
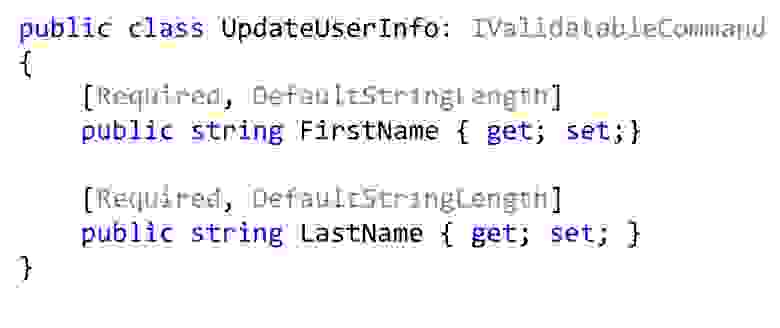
Причём такие атрибуты можно повторно использовать в Dto. Вот если я хочу менять имя и фамилию, у меня может быть такая команда на изменение. А стоит ли добавлять тут специальной конструктор? Вроде как стоит. Оно же лучше станет, никто не поменяет эти значения, не сломает их, они будут точно правильные.

На самом деле не совсем. Дело в том, что Dto в общем-то не совсем объекты. Это такой словарик, в который мы засовываем десериализованные данные. То есть они притворяются объектами, конечно, но у них есть всего одна ответственность — это быть сериализованными и десериализованными. Если мы попытаемся бороться с этой структурой, начнём объявлять какие-то ModelBinder'ы с конструкторами, что-то такое делать, это невероятно утомительно, и, главное, это будет ломаться с новыми выходами новых фреймворков. Всё это хорошо описал Марк Симон в статье «На границах программы не объектно-ориентированы», если интересно — лучше прочитайте его пост, там всё это подробно описано.

Если коротко, то у нас есть грязный внешний мир, мы ставим на входе проверки, преобразуем его к нашей чистой модели, и дальше передаём всё это обратно в сериализацию, в браузер, снова в грязный внешний мир.
После того, как вот эти все изменения внесены, как у нас будет выглядеть Hander?
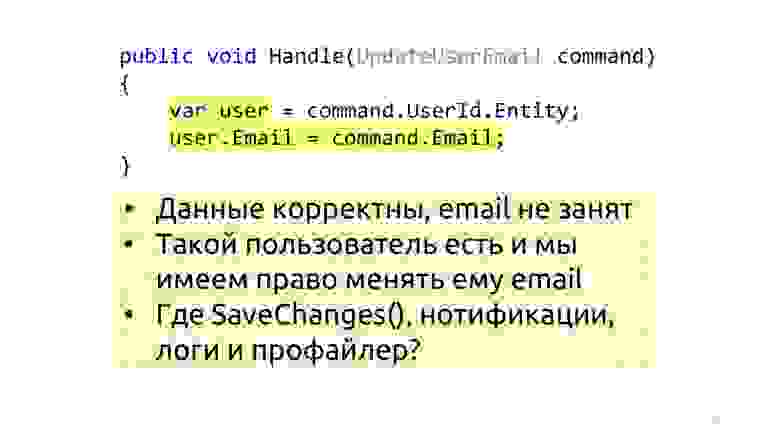
Я здесь написал две строчки для того, чтобы удобнее было читать, а вообще можно записать в одну. Данные точно корректны, потому что нас есть система типов, есть валидация, то есть железобетонно корректные данные, проверять их повторно не нужно. Такой пользователь тоже есть, другого пользователя с таким занятым email'ом нету, всё можно делать. Однако ещё нет вызова метода SaveChanges, нет нотификации и нет логов и профайлеров, да? Двигаемся дальше.
Доменные события.
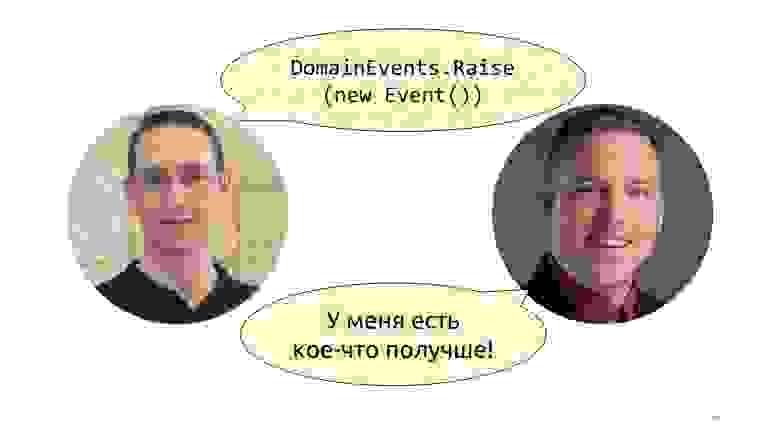
Наверное, в первый раз популяризовал эту концепцию Уди Дахан в его посте «Domain Events – Salvation». Там он предлагает просто объявить статический класс с методом Raise и выкидывать такие события. Чуть позже позже Джимми Богард предложил лучшую реализацию, она так и называется «A better domain events pattern».
Я буду показывать сериализацию Богарда с одним небольшим изменением, но важным. Вместо того, чтобы выбрасывать события, мы можем объявить какой-то список, и в тех местах, где должна происходить какая-то реакция, прямо внутри сущности сохранять эти события. В данном случае вот этот геттер
Далее, в тот момент, когда мы будем вызывать метод SaveChanges, мы берём ChangeTracker, смотрим, а есть ли там какие-то сущности, которые реализуют интерфейс, есть ли у них доменные события. И если есть, давайте-ка заберём все эти доменные события и отправим в какой-то диспетчер, который знает, что с ними делать.
Реализация этого диспетчера — это тема отдельного разговора, там есть некоторые сложности с multiple dispatch в C#, но это всё тоже делается. С таким подходом есть ещё одно неочевидное преимущество. Теперь, если у нас есть два разработчика, один может писать код, который изменяет вот этот самый email, а другой может делать модуль нотификаций. Они абсолютно не связаны друг с другом, они пишут разный код, они связаны только на уровне этого доменного события одного класса Dto. Первый разработчик этот класс просто в какой-то момент выбрасывает, второй на него реагирует и знает, что это надо отправлять на email, SMS, push-уведомления на телефон и все остальные миллион уведомлений с учётом всяких предпочтений пользователей, которые обычно бывают.

Вот то самое небольшое, но важное замечание. В статье Джимми используется перегрузка метода SaveChanges, и лучше этого не делать. А сделать это лучше в декораторе, потому что, если мы перегружаем метод SaveChanges и нам в Handler'е потребовался dbContext, мы получим циклические зависимости. С этим можно работать, но решения получаются чуть менее удобные и чуть менее красивые. Поэтому, если pipeline построен на декораторах, то смысла делать по-другому я не вижу.
Вложенность кода осталась, но в первоначальном примере у нас был сначала using MiniProfiler, потом — try catch, потом — if. Итого было три уровня вложенности, теперь каждый этот уровень вложенности находится в своем декораторе. И внутри декоратора, который у нас отвечает за профилирование, у нас только один уровень вложенности, код читается отлично. Кроме того, видно, что в этих декораторах только одна ответственность. Если декоратор отвечает за логирование, то он будет только логировать, если за профилирование, соответственно, только профилировать, всё остальное находится в других местах.
После того, как весь pipeline отработал, нам остается только взять Dto и отправить дальше браузеру, сериализовать JSON.
Но ещё одна маленькая-маленькая такая вещь, которую иногда забывают: на каждом этапе здесь может случиться Exception, и вообще-то надо как-то их обрабатывать.

Не могу здесь не упомянуть ещё раз Скотта Влашина и его доклад «Railway oriented programming». Почему? Оригинальный доклад целиком и полностью посвящён работе с ошибками на языке F#, тому, как можно организовать flow немножко по-другому и почему такой подход может быть более предпочтительным, чем использование Exception'ов. В F# это действительно работает очень хорошо, потому что F# — это функциональный язык, и Скотт использует возможности функционального языка.

Так как, наверное, большинство из вас всё-таки пишет на C#, то, если написать аналог на C#, то этот подход будет выглядеть примерно следующим образом. Вместо того, чтобы выбрасывать исключения, мы объявляем такой класс Result, у которого есть успешная ветка и есть неуспешная ветка. Соответственно два конструктора. Класс может находиться только в одном состоянии. Этот класс является частным случаем типа-объединения, discriminated union из F#, но переписанный на C#, потому что встроенной поддержки в C# нет.

Вместо того, чтобы объявлять публичные геттеры, которые в коде кто-то может не проверить на null, используется Pattern Matching. Опять же, в F# это был бы встроенный в язык Pattern Matching, в C# приходится писать отдельный метод, в который мы передадим одну функцию, которая знает, что делать с успешным результатом операции, как его преобразовать дальше по цепочке, и что с ошибкой. То есть независимо от того, какая ветка у нас сработала, мы должны скастить это к одному возвращаемому результату. В F# это всё работает очень хорошо, потому что там есть функциональная композиция, ну и всё остальное, что я уже перечислил. В .NET это работает несколько хуже, потому что как только у вас происходит не один Result, а много — а практически каждый метод может по тем или иным причинам закончиться неудачей — почти все ваши результирующие типы функции становятся типа Result, и вам надо их как-то комбинировать.

Самый простой способ их скомбинировать — использовать LINQ, потому что вообще-то LINQ работает не только с IEnumerable, если доопределить методы SelectMany и Select правильным образом, тогда компилятор C# увидит, что можно использовать для этих типов LINQ-синтаксис. В общем-то получается калька с do-нотации Haskell или с тех же самых Computation Expressions в F#. Как это следует читать? Вот у нас есть три результата операции, и если там во всех трёх случаях всё хорошо, тогда возьми эти результаты r1 + r2 + r3 и сложи. Тип результирующего значения тоже будет Result, но новый Result, который мы объявляем в Select'е. В общем-то, это даже рабочий подход, если бы не одно но.

Для всех остальных разработчиков, как только вы начинаете писать такой код на C#, вы начинаете выглядеть примерно вот так. «Это плохие страшные Exception'ы, не пишите их! Они — зло! Лучше пишите код, который никто не понимает и не сможет отладить!»
C# — это не F#, он несколько отличается, там нет разных концепций, на основе которых это делается, и когда мы так пытаемся натянуть сову на глобус, получается, мягко говоря, непривычно.

Вместо этого можно использовать встроенные нормальные средства, которые задокументированы, которые все знают и которые не будут вызывать у разработчиков когнитивный диссонанс. В ASP.NET есть глобальный Handler Exception'ов.

Мы знаем, что, если с валидацией какие-то проблемы, надо вернуть код 400 или 422 (Unprocessable Entity). Если проблема с аутентификацией и авторизацией, есть 401 и 403. Если что-то пошло не так, то что-то пошло не так. А если что-то пошло не так и вы хотите сказать пользователю, что именно, определите свой тип Exception'а, скажите, что это IHasUserMessage, объявите в этом интерфейсе геттер Message и просто проверьте: если этот интерфейс реализован, значит, можно взять сообщение из Exception'а и передать его в JSON пользователю. Если этот интерфейс не реализован, значит, там какая-то системная ошибка, и пользователям мы скажем просто, что что-то пошло не так, мы уже занимаемся, мы всё знаем — ну как обычно.
На этом с командами завершаем и смотрим, что же у нас в Read-стеке. То, что касается непосредственно запроса, валидации, ответа — это примерно всё то же самое, не будем отдельно останавливаться. Здесь может быть ещё дополнительно кэш, но в общем-то с кэшем тоже нет каких-то больших проблем.
Посмотрим лучше на проверку безопасности. Там может быть тоже такой же декоратор Security, который проверяет, можно ли делать этот запрос или нет:

Но есть ещё один случай, когда мы выводим не одну запись, а выводим списки, и каким-то пользователям мы должны вывести полный список (например, каким-нибудь суперадминистраторам), а другим пользователям мы должны вывести ограниченные списки, третьим — ограниченные по-другому, ну и как это часто бывает в корпоративных приложениях, права доступа могут быть крайне изощренными, поэтому нужно быть точно уверенными, что в эти списки не пролезут данные, которые этим пользователям не предназначаются.
Проблема решается довольно просто. Мы можем доопределить интерфейс (IPermissionFilter), в который приходит оригинальный queryable и возвращается queryable. Разница в том, что к тому queryable, который возвращается, мы уже навесили дополнительные условия where, проверили текущего пользователя и сказали: «Вот этому пользователю верни только те данные, которые…» — а дальше вся ваша логика, которая связана с permission'ами. Опять же, если у вас есть два программиста, один программист идёт писать permission'ы, он знает, что ему надо написать просто очень много permissionFilter'ов и проверить, что по всем сущностям они работают правильно. А другие программисты ничего не знают про permission'ы, в их списке просто всегда проходят правильные данные, вот и всё. Потому что они получают на входе уже не оригинальный queryable из dbContext, а ограниченный фильтрами. У такого permissionFilter'а тоже есть свойство компоновки, мы можем все permissionFilter'ы сложить и применить. В итоге получаем результирующий permissionFilter, который максимально сузит выборку данных с учётом всех условий, которые для данной сущности подходят.
Почему это не делать встроенными средствами ORM, например, Global Filters в entity-фреймворке? Опять же для того, чтобы не городить себе всякие циклические зависимости и не тащить в context всякую дополнительную историю про ваш бизнес-слой.
Осталось посмотреть на модель чтения. В парадигме CQRS не используется доменная модель в стеке чтения, вместо этого мы просто сразу формируем те Dto, которые нужны браузеру в данный момент.
Если мы пишем на C#, то, скорее всего, мы используем LINQ, если нет только каких-то чудовищных требований по производительности, а если они есть, то, возможно, у вас не корпоративное приложение. Вообще эту задачу можно решить раз и навсегда вот таким LinqQueryHandler'ом. Здесь довольно страшный constraint на дженерик: это вот Query, который возвращает список проекций, и она ещё может фильтровать вот эти проекции и сортировать вот эти проекции. Ещё она работает только с какими-то типами сущностей и знает, как эти сущности преобразовать к проекциям и вернуть список таких проекций уже в виде Dto в браузер.
Реализация метода Handle может быть такая, довольно простая. На всякий случай проверим, реализует ли этот TQuery фильтр для изначальной сущности. Дальше делаем проекцию, это queryable extension AutoMapper'а. Если кто-то до сих пор не знает, AutoMapper может строить проекции в LINQ, то есть те, которые будут строить метод Select, а не маппить это в памяти.
Дальше применяем фильтрацию, сортировку и выдаём всё это в браузер. Как именно всё это делается, я рассказывал в Питере на DotNext, это ещё один целый доклад, он уже выложен в свободный доступ и расшифрован на Хабре, можете послушать, посмотреть, прочитать, как написать с помощью expression'ов фильтрацию, сортировку и проекции для чего угодно один раз и дальше повторно использовать.
Не все выражения одинаково
Двигаемся дальше. Одна тема, которую я не осветил на прошлом DotNext'е, — это проблемы с трансляцией в SQL. Потому что в Select мы, конечно, можем написать всё что мы хотим, но queryable-провайдеры не всё разберут.
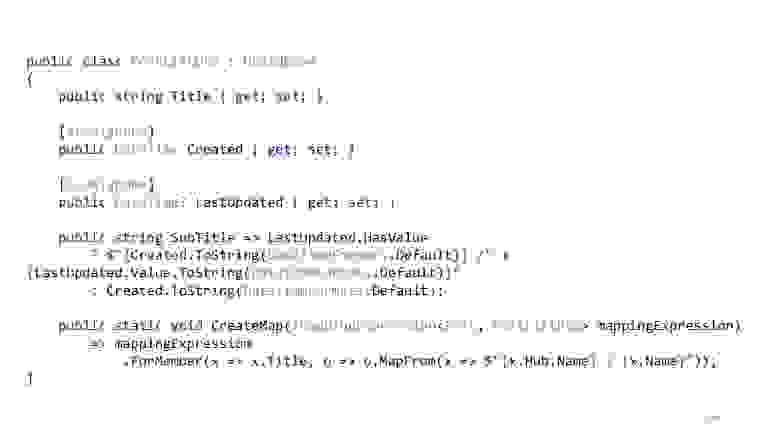
Раз уж речь зашла про Хабр, давайте на примере Хабра. У нас есть список постов, у них есть Title, и Title мы хотим вводить как название хаба, а потом название самого поста. Вот с этой проекцией проблем нет, всё преобразуется. А вот если мы хотим вывести такой SubTitle, когда в последний раз обновляли статью, когда её создали, и хотим ещё использовать какой-то свой кастомный формат для этих дат, вот с этим queryable-провайдер уже не справится. Он не в курсе, что за кастомный формат объявлен в нашем коде.
И есть один довольно простой трюк, который эту проблему решает. Вместо того, чтобы пытаться сделать проекцию, мы делаем проекцию на примитивы. То есть вытаскиваем всё, что нам нужно, сначала. Далее помечаем это всё «JsonIgnore», чтобы сериализатор проигнорировал эти поля. И объявляем тот метод, который нам нужен, в Dto. То есть вместо того, чтобы делать это в проекции, мы это делаем уже в памяти. Когда сериализатор начнёт преобразование класса в JSON, он увидит, что Created и LastUpdated он должен пропустить, а SubTitle — это публичное свойство, надо его взять. Тогда он возьмёт его, вызовет этот метод, и дальше мы уже в памяти домаппим то, что нам нужно, то, что мы не смогли преобразовать в проекции. В большинстве случаев такой простой трюк решает проблему с тем, что какие-то выражения не могут быть преобразованы.
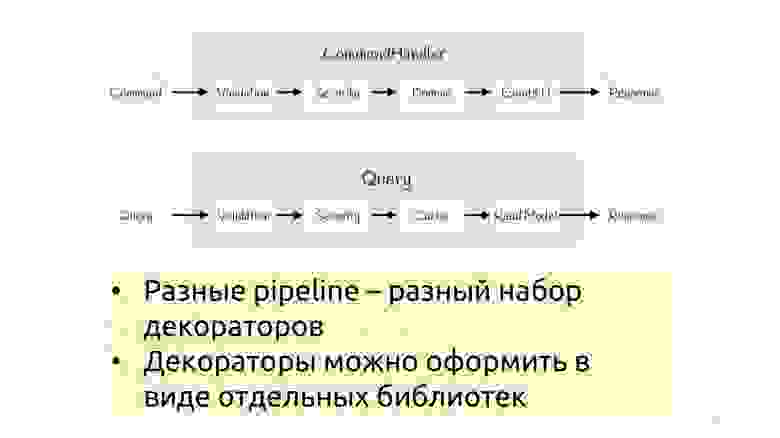
Давайте посмотрим на оба стека вместе. Они, в общем-то, довольно похожи и отличаются только тем, какие шаги мы собрали. В зависимости от того, какой pipeline, мы можем применять разные декораторы. Вот запросы мы будем кэшировать — а в командах это уже нам, допустим, не потребуется. Аналогично, команды мы хотим вызывать в SaveChanges, а в Query не надо вызывать SaveChanges. Когда пайплайны собраны и мы понимаем, что их ограниченное количество, такие декораторы можно взять и оформить в виде отдельных библиотек, положить на NuGet, и дальше просто подключать в виде повторно используемых модулей.
Потому что в коде декораторов нет ничего про домен. Вы можете отдельно писать домен, а инфраструктуру передать какому-то другому разработчику, которой оформит вам эти модули, и вы будете ими пользоваться. Если вы знакомы, например, с трудами Брукса, наверное, знаете, что самый простой способ написать код — это его купить. Соответственно, отличный вариант, если вы можете взять и сказать: «Нам нужны вот такие декораторы», — и их купить. Никакой ответственности.
Если декораторы такие замечательные, как же их регистрировать?

Регистрировать их придётся как-то вот так. Не совсем красиво.
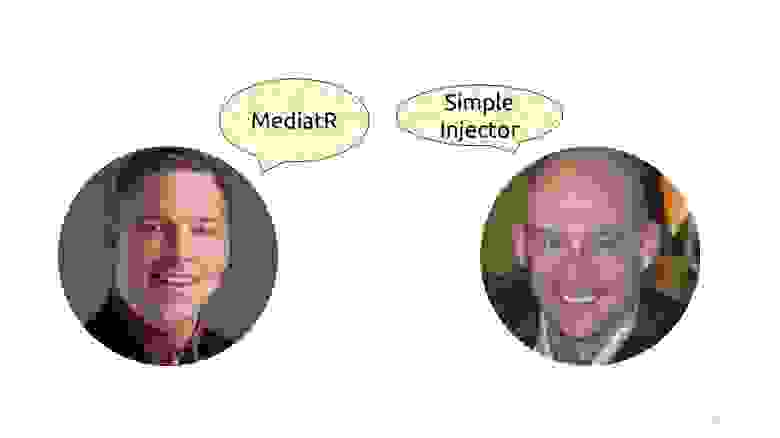
Хотя руками, конечно, никто это не делает, это всё происходит через контейнеры. Можно взять MediatR Джимми Богарда, в котором это всё уже есть и есть документация. Всё, о чём я рассказывал, такие же декораторы — правда, у него в MediatR это называется pipeline behaviour. Но смысл тот же, там так же определены методы Request/Response, RequestHandler’ы и методы для регистрации этих декораторов. А можно взять Simple Injector, у которого декоратор — это прямо фишка фреймворка.

И сейчас вернёмся вот на этот слайд, помните, я говорил, что нам потребуется ещё раз этот дженерик, где TIn: ICommand.

Вот в Simple Injector’е поддерживается регистрация декораторов на основе constraint’ов дополнительно. То есть вы можете там, где будете регистрировать декоратор, указать, что если декоратор с constraint’ом, то он будет применяться только к тем Handler’ам, у которых есть такой constraint. Соответственно, если у нас есть constraint ICommand, мы можем сделать декоратор на SaveChanges тоже с constraint’ом на ICommand, и Simple Injector автоматически поймёт, что эти два constraint’а одинаковые, и будет применять этот декоратор только к соответствующему Handler’у. Ну, получается ещё одна маленькая красивая фишечка, которая позволяет на системе типов строить вот такую логику приложения, что к чему должно применяться.
Что использовать? Simple Injector или MeriatR — в принципе, на вкус и цвет все фломастеры разные, кроме того в Autofac’е, по-моему, тоже есть декораторы и в других контейнерах может быть тоже, я просто не слежу, не знаю. Если интересно, посмотрите.
Во всём моём текущем докладе не хватает ещё одного слова, чтобы кричать «бинго».
Даже двух слов, а именно «Clean architecture». Нельзя же было упомянуть много умных людей и забыть про дядюшку Боба Мартина.

Современные веб-приложения почему-то очень любят рассказывать о том, что они MVC, какие они замечательные, какая у них структура.

Вместо этого, и Боб Мартин, и многие другие, и в том числе Angular, кстати, уже предлагает структурировать приложение на основе того, какие там есть модули в системе, то есть какая функциональность. Вместо того, чтобы сказать: «Я — MVC-приложение», можно сказать: «У меня есть следующие Features, то есть такая функциональность: у меня есть менеджмент аккаунтов, у меня есть Blog и у меня есть какой-то Import, то есть три каких-то больших модуля».
Может быть, программистам, конечно, удобнее знать, что это MVC-приложение, нам нравится, что там какие-то технические подробности, детали. Но для менеджмента MVC абсолютно неважно. А вот такая структура, когда человек понимает, сколько у него есть фич — это для бизнеса гораздо важнее. То есть эта структура соответствует функциональности системы.

Я же обещал всё-таки не давить авторитетами и тем, что кунг-фу сильнее другого кунг-фу, поэтому я приведу и другие преимущества такого оформления.
Во-первых, код в таком случае добавляется, а не редактируется. Если у нас есть разные модули и мы хотим добавить новый модуль, это новая папка. Не получится такого, что в модуле А и в модуле Б есть какая-то работа с юзерами, поэтому программисты Вася и Петя оба пошли исправлять User Service, дальше отправили pull request’ы, и тут внезапно случился конфликт, потому что они оба изменили этот User Service в соответствии с тем, как считали нужным. Причём даже без того, что они изменили сигнатуры или что-то вроде, а просто у них где-то поменялись строчки, типы. Какие-то банальные технические вещи могут приводить к тому, что на этапе код ревью может случиться конфликт и это затянет релизный цикл.
Следующий момент. Такая организация кода побуждает нас лучше думать о том, какие контексты есть в приложении и как его правильно делить. То есть, если мы делим правильно, то в идеале мы должны не создавать вообще лишних зависимостей между модулями там, где их нет. Соответственно, там, где есть, мы узнаем, что они есть, на этапе разделения по модулям, потому что мы увидим, что вот этот модуль почему-то зависит от другого. И если так получилось, что наши модули полностью независимы (а так тоже можно сделать, но с некоторыми оговорками), тогда фичу можно будет удалить, просто нажав кнопочку «Delete»: мы удаляем папку, и её больше нет в программе, и всё. Довольно удобно.
В практике нам раза два приходилось проводить такие действия — слово «рефакторинг», наверное, не совсем правильно, когда выбрасываешь весь код и заново переписываешь, это скорее рерайт. И если бы код был написан в обычном слоёном стиле, так бы не получилось: все эти сервисы, относящиеся к разным модулям, мы бы не смогли выкинуть, потому что были бы лишние зависимости. А так мы просто выкинули несколько косячных модулей и потом переписали, когда руки дошли. Я не буду вдаваться в подробности, почему так пришлось сделать, но иногда бывает. То есть это произошло не потому, что были плохие и глупые программисты, а потому что так сложились обстоятельства.
И последний момент: такое разделение упрощает работу численными методами и коммуникацию. Когда я говорю «численными методами», я опять же делаю реверанс в сторону менеджмента: мы начинаем считать количество фич, количество возвратов с код ревью, количество возвратов с тестирования и вот это вот всё. Помните, когда я формулировал критерии, обратил внимание на то, что довольно сложно отслеживать связь между регрессией, багами, которые дошли до продакшна, и тем, почему так произошло. А когда мы начинаем класть код таким образом, становится чуть легче. Потому что, если приходит какой-то pull request на редактирование существующих модулей, вариант номер один — изменились требования, вариант номер два — что-то пошло не так, баг пролез на продакшн. И вот дальше мы уже смотрим историю изменения в VCS именно по этому модулю: а что ж он пролез-то на продакшн, какие там коммиты были? Если эти коммиты находятся в этом модуле, в них ещё как-то можно разобраться, а если они просто размазаны по всем нашим слоям, разбираться становится сильно сложнее.

Несмотря на это, всё, о чем я говорил, не лишено недостатков. А именно: это не работает из коробки. То есть если вы возьмёте просто шаблон проекта, вам придётся дописывать инфраструктурный код. В идеале, написать свой шаблон проекта, в который уже будет подключено всё, что нужно, будет структура проектов. Но уходит на это, наверное, не меньше рабочего дня, если вы с нуля это делаете. Ну, один раз, допустим. Когда я говорю «рабочий день», это в смысле у нас уже всё готово, вам надо только зависимости собрать. На то, чтобы собрать зависимости, у меня ушло несколько лет — с тем, как изменялась моя мысль о том, как писать код.
Это иллюстрирует второй пункт данного слайда: этот инфраструктурный код писать, что-то переопределять, дописывать. То есть к нему предъявляются более серьёзные требования в плане качества. В каком-то прикладном коде вы можете писать так, как у вас принято, потому что, если придёт баг, вы поправите. А вот если вы начинаете публиковать какие-то библиотеки в свободный доступ и они с косяками, и кто-то их подключил и это уже не один проект, а на этом завязана у вас, допустим, работа всей компании или проекта клиентов, это становится сильно сложнее. Риски этого дела выше.

Резюмируем. Если вы захотите организовать работу с кодом следующим образом, вам нужно будет объявить вот такой IHandler в качестве основного строительного блока. Он будет выполнять операции.
Дальше этот IHandler расширяем двумя интерфейсами ICommandHandler и IQueryHandler и говорим, что это холистические абстракции. Очень круто звучащее словосочетание, значит на самом деле просто, что оно выполняется в рамках одной транзакции. То есть, если есть CommandHandler, внутри него не будет другого CommandHandler’а, он действует на протяжении всего этого запроса.
Почему так? Это исключает флейм на тему того, что можно там Query использовать в командах, команды в Query — вот это всё. Если вам нужен повторно используемый код, который придётся использовать и там, и там, тогда вы объявляете Hander, если вы объявляете CommandHandler или QueryHandler, это значит какой-то конкретный use case, это не должно повторно использоваться.
Декораторы — это отличный инструмент для того, чтобы разделить вот эту всю логику, разделить ответственности, обязанности между разными классами, чтобы их регистрировать потребуется инфраструктура: либо контейнер, либо фреймворк.
Система типов и инварианты сильно лучше, чем валидация. Потому что позволяет на этапе компиляции узнавать об ошибках, а не в рантайме. Но не на границах, потому что на границах программы не объектно-ориентированы.
И мы всё ещё ждём C# 8, чтобы появился nullable reference type и наша система типов стала получше. Не такая, конечно, крутая, как в функциональных языках программирования, но лучше.
События можно трекать в рамках транзакции с помощью ChangeTracker’а ORM.
И Exception’ы — это нормальный вариант для ошибок, если не писать на F#, если мы пишем на C#. Есть вариант, в котором всё-таки надо отказаться от этих исключений, там может быть какое-то ограничение по производительности, например. Но если у вас возникают ограничения по производительности, связанные с тем, что у вас слишком много Exception’ов, возможно, вам не нужен там и LINQ, и всё остальное, и всё, что я вам рассказывал, это не совсем для вас, вам нужны хранимые процедуры, Dapper и что-то ещё, и, может быть, даже не .NET.
А если у нас нет таких страшных требований к производительности, тогда LINQ, автоматические проекции, permission’ы — это всё отлично. Да, это всё действительно тормозит, но тормозит какие-то миллисекунды, то есть это меньше, чем сетевые задержки к вашей базе данных. Ну и структурирование приложения по фиче, а не по слоям — более предпочтительный способ.
Я упомянул в докладе много людей и идей. Вот ссылки:

Последний слайд — немножко рекомендуемой литературы. Слева у нас нетленочка Эрика Эванса. Вторая книжка — это книга Скотта Влашина «Domain Modeling Made Functional», она про F#, но даже если вы не хотите никогда писать на F#, я всё равно её рекомендую прочитать, потому что она здорово структурирована, там очень чётко изложены мысли, просто с точки зрения здравого смысла и того, что два плюс два равно четыре. То есть идеи можно и на C# переносить, но за одним исключением, чтобы не выглядеть как на том слайде про Exception’ы.
И последняя, может быть, неочевидная книга — это «Entity Framework Core In Action». Я её здесь разместил не потому, что она про Entity Framework, а потому что там есть целый раздел про то, как использовать всякие варианты DDD с ORM, то есть то, где нам ORM начинает мешать в плане реализации DDD и как это обходить.
В этой статье мы рассмотрим критерии хорошего кода и плохого кода, как и чем измерять. Увидим обзор типовых задач и подходов, разберем плюсы и минусы. В конце будут рекомендации и best practices по проектированию web-приложений.
Эта статья является расшифровкой моего доклада с конференции DotNext 2018 Moscow. Кроме текста, под катом есть видеозапись и ссылка на слайды.

Слайды и страница доклада на сайте.Коротко обо мне: я из Казани, работаю в компании «Хайтек Груп». Мы занимаемся разработкой ПО для бизнеса. С недавнего времени я преподаю в Казанском Федеральном Университете курс, который называется «Разработка корпоративного ПО». Время от времени я ещё пишу статьи на Хабр про инженерные практики, про разработку корпоративного ПО.
Как вы, наверное, могли догадаться, сегодня я буду говорить про разработку корпоративного ПО, а именно, как можно структурировать современные веб-приложения:
- критерии
- краткая история развития архитектурной мысли (что было, что стало, какие проблемы есть);
- обзор недостатков классической слоеной архитектуры
- решение
- пошаговый разбор реализации без погружения в детали
- итоги.
Критерии
Сформулируем критерии. Мне очень не нравится, когда разговоры про проектирование ведутся в стиле «моё кунг-фу сильнее твоего кунг-фу». У бизнеса есть, в принципе, один конкретный критерий, который называется «деньги». Все знают, что время — это деньги, поэтому две вот эти составляющие чаще всего самые важные.

Итак, критерии. В принципе бизнес чаще всего просит нас «как можно больше фич в единицу времени», но с одним нюансом — эти фичи должны работать. И первый этап, на котором это может сломаться, это код ревью. То есть, вроде бы, программист сказал: «Я за три часа сделаю». Три часа прошло, пришло в код ревью, а тимлид говорит: «Ой, нет, переделывай». Там ещё три — и сколько итераций код ревью прошло, на столько надо умножить три часа.
Следующий момент — это возвраты с этапа тестирования сдачи-приёмки. То же самое. Если фича не работает, значит, она не сделана, эти три часа растягиваются на неделю, две — ну там как обычно. Последний критерий это количество регрессии и багов, которые всё-таки, несмотря на тестирование и приёмку, прошли в продакшн. Это тоже очень плохо. С этим критерием есть одна проблема. Его сложно отслеживать, потому что связь между тем, что мы что-то такое запушивали в репозиторий, и тем, что потом через две недели что-то сломалось, бывает сложно отследить. Но, тем не менее, возможно.
Развитие архитектуры
Давным-давно, когда программисты только начинали писать программы, не было ещё никакой архитектуры, и все делали всё, как им нравится.

Поэтому получался вот такой архитектурный стиль. У нас это называется «лапшекод», за рубежом говорят «спагетти-код». Всё связано со всем: мы меняем что-то в точке А — в точке Б ломается, понять, что с чем связано, совершенно невозможно. Естественно, программисты довольно быстро сообразили, что так дело не пойдёт, и надо какую-то структуру сделать, и решили, что нам помогут какие-то слои. Вот если вы представите, что фарш — это код, а лазанья — это такие слои, вот вам иллюстрация слоёной архитектуры. Фарш остался фаршем, но теперь фарш из слоя № 1 не может просто так взять и пойти общаться с фаршем из слоя № 2. Мы придали коду какой-то форму: даже на картинке вы можете увидеть, что лазанья более оформлена.
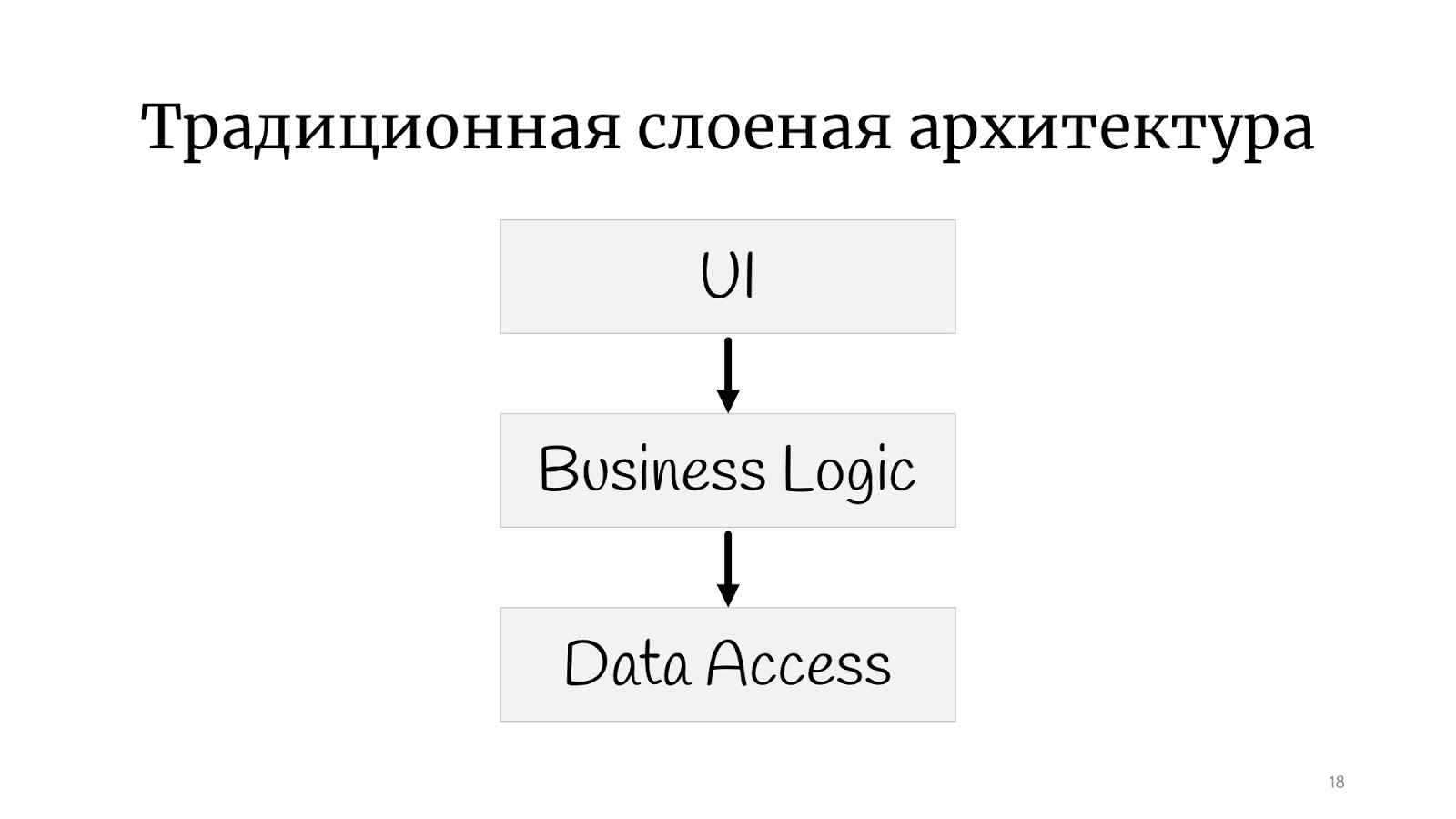
С классической слоёной архитектурой, наверное, все знакомы: есть UI, есть бизнес-логика и есть Data Access layer. Бывают ещё всякие сервисы, фасады и слои, названные по имени архитектора, который уволился из компании, их может быть неограниченно много.

Следующим этапом была так называемая луковая архитектура. Казалось бы, огромная разница: до этого были квадратик, а тут стали кружочки. Кажется, что абсолютно другое.
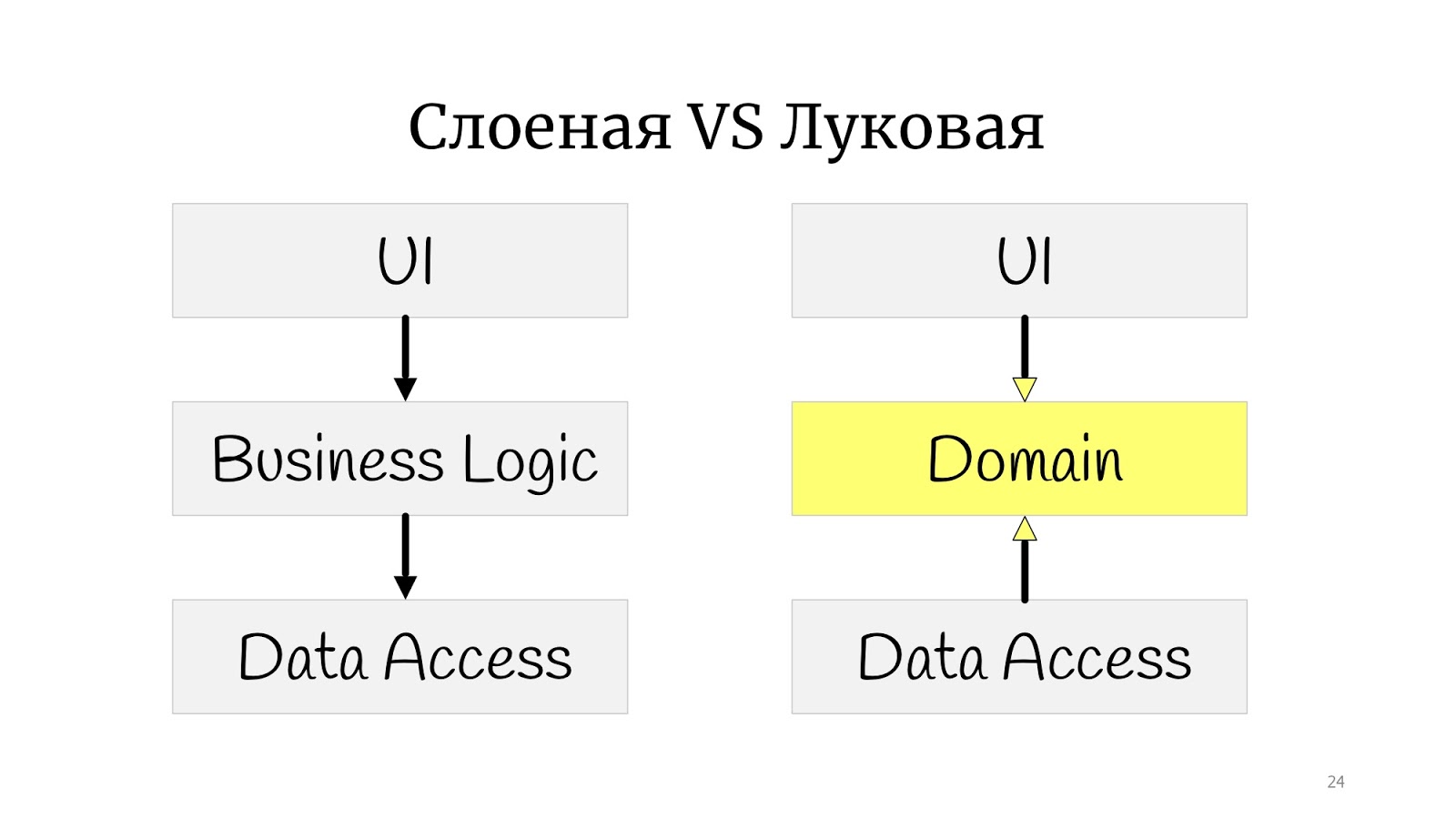
На самом деле нет. Вся разница в том, что где-то в это время сформулировали принципы SOLID, и выяснилось, что в классической луковой есть проблема с инверсией зависимостей, потому что абстрактный доменный код почему-то зависит от реализации, от Data Access, поэтому Data Access решили развернуть, и сделали так, чтобы Data Access зависел от домена.

Я вот здесь поупражнялся в рисовании и нарисовал луковую архитектуру, но не классически «колечками». У меня получилось нечто среднее между многоугольником и кружками. Я это сделал, чтобы просто показать, что, если вы встречали слова «луковая», «гексагональная» или «порты и адаптеры» — это всё одно и то же. Смысл в том, что домен в центре, его заворачивают в сервисы, они могут быть доменные или application-сервисы, кому как больше нравится. А внешний мир в виде UI, тестов и инфраструктуры, куда переехал DAL — они общаются с доменом через этот сервисный слой.
Простой пример. Обновление email
Давайте посмотрим, как в такой парадигме будет выглядеть простой use case — обновление email'а пользователя.
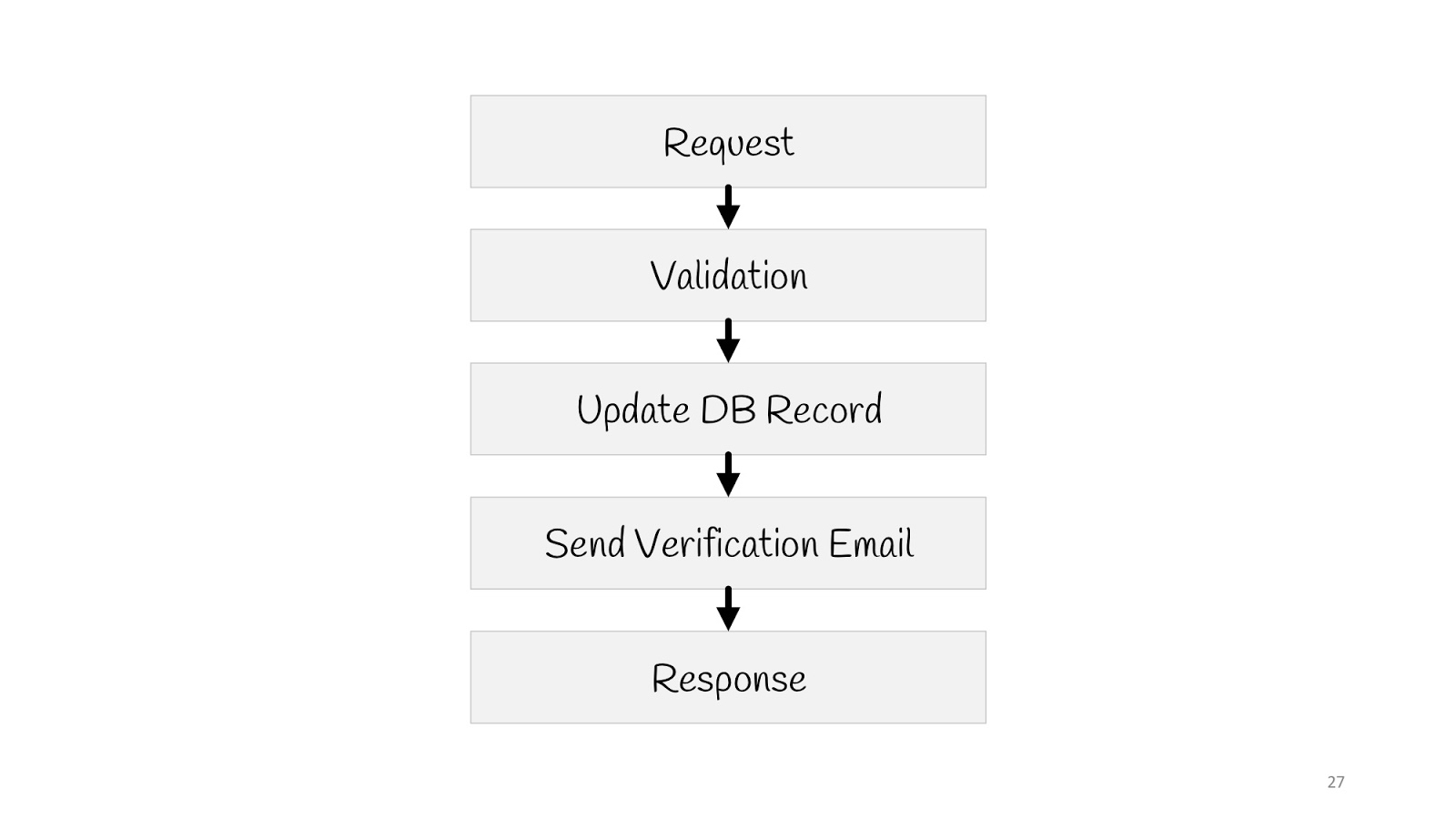
Нам нужно отправить запрос, провести валидацию, обновить в базе данных значение, отправить на новый email уведомление: «Всё в порядке, вы поменяли email, мы знаем, всё хорошо», и ответить браузеру «200» — всё окей.
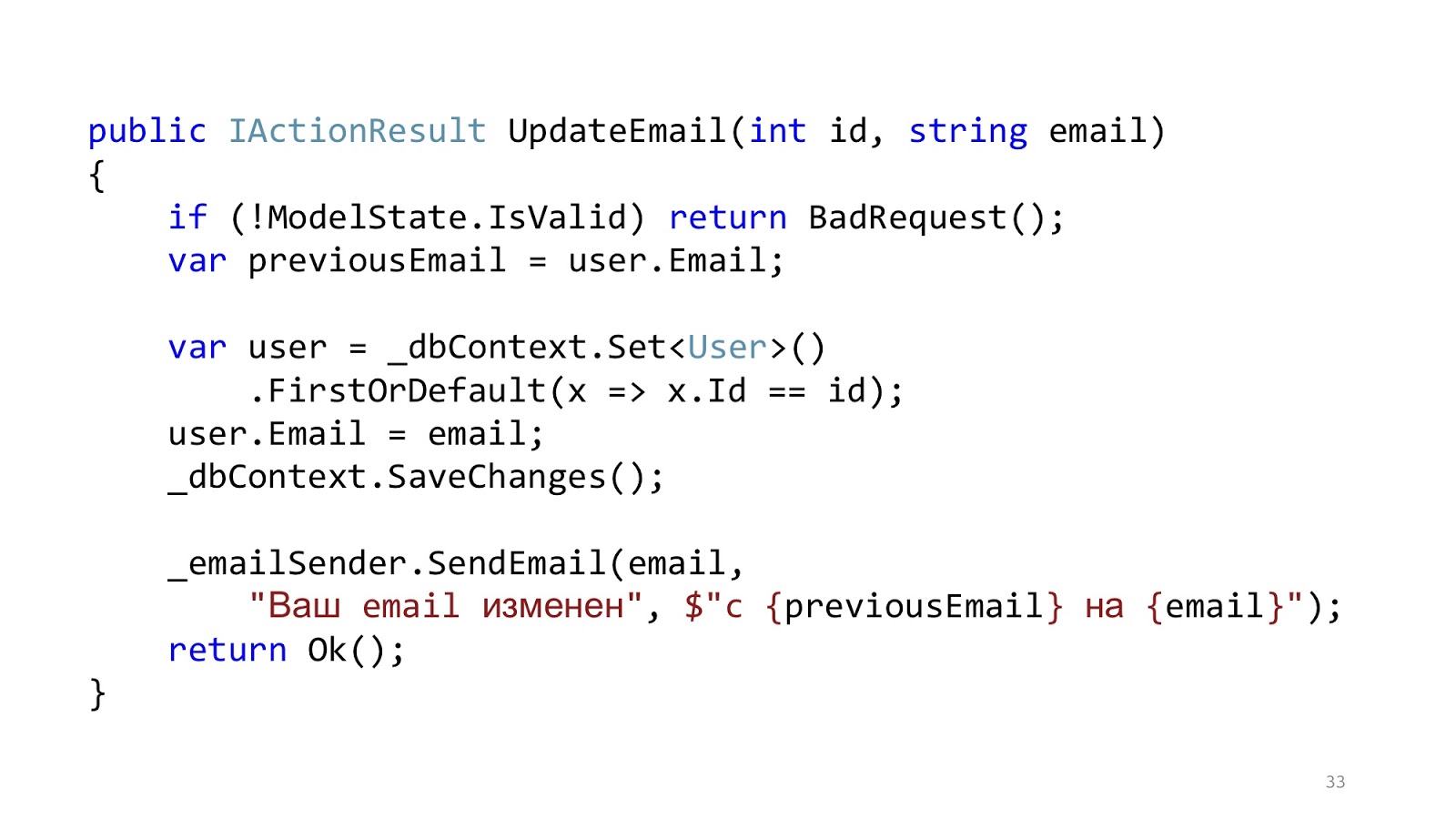
Код может выглядеть примерно как-то так. Вот у нас есть стандартная ASP.NET MVC-валидация, есть ORM, чтобы прочитать и обновить данные, и есть какой-нибудь email-sender, который отправляет нотификацию. Вроде как всё хорошо, да? Один нюанс — в идеальном мире.
В реальном мире ситуация чуть-чуть отличается. Смысл в том, что надо добавить авторизацию, проверку ошибок, форматирование, логирование и профилирование. Это всё не имеет никакого отношения к нашему use case'у, но это всё должно быть. И вот тот маленький кусочек кода стал большим и страшным: с большой вложенностью, с большим количеством кода, с тем, что это тяжело читать, а главное, что инфраструктурного кода больше, чем доменного.

«Где же сервисы?» — скажете вы. Я же записал всю логику в контроллеры. Конечно, это проблема, сейчас я добавлю сервисы, и всё будет хорошо.

Добавляем сервисы, и действительно становится лучше, потому что вместо большой портянки получилась одна маленькая красивая строчка.
Стало лучше? Стало! А еще мы теперь этот метод можем повторно использовать в разных контроллерах. Результат налицо. Давайте посмотрим на реализацию этого метода.
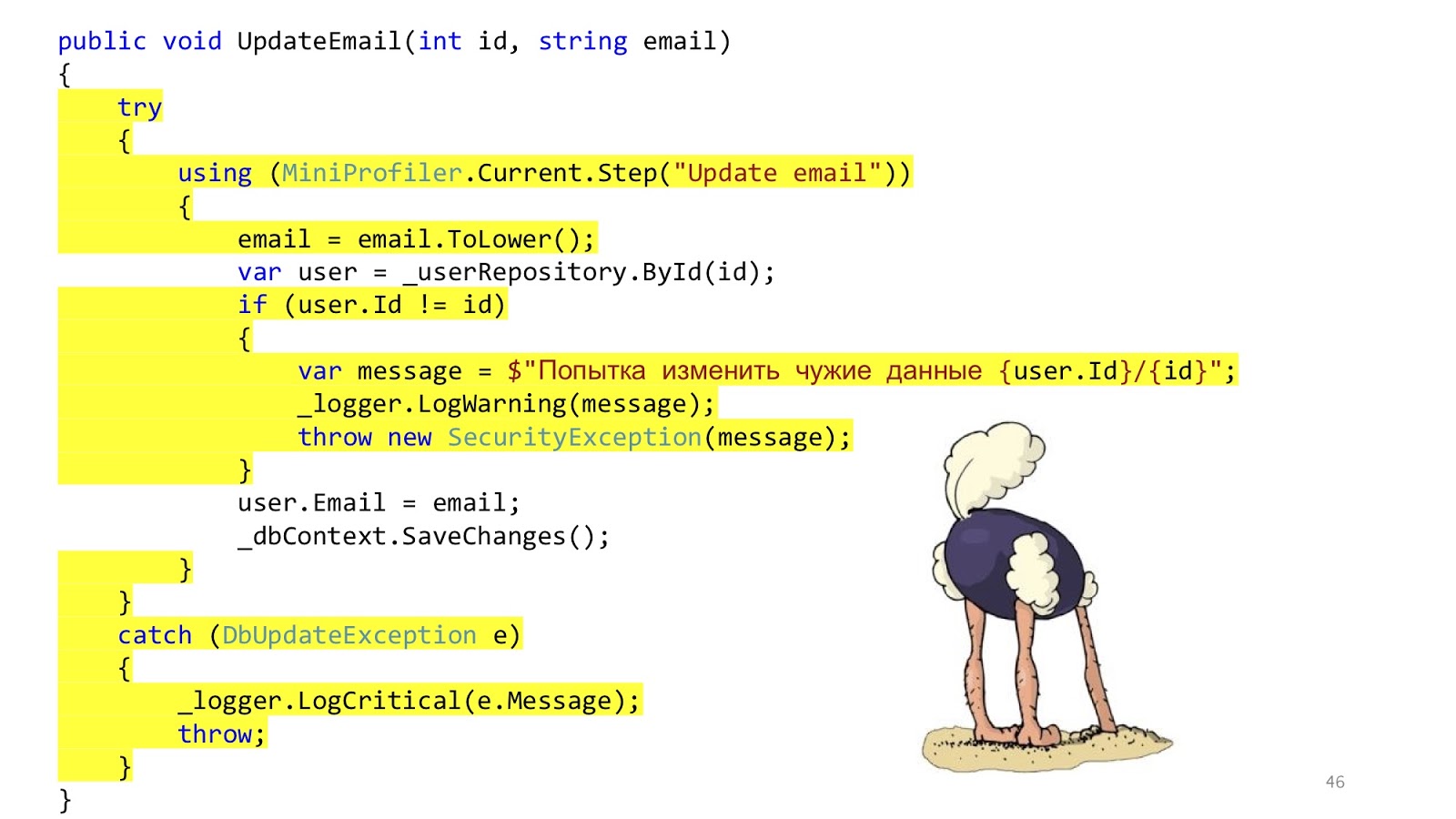
А вот здесь уже всё не так хорошо. Этот код никуда не делся. Всё то же самое мы просто перенесли в сервисы. Мы решили не решать проблему, а просто её замаскировать и перенести в другое место. Вот и всё.

Дополнительно к этому появляются некоторые другие вопросы. А валидацию мы должны делать в контроллере или здесь? Ну, вроде как, в контроллере. А если надо сходить в базу данных и посмотреть, что такой ID есть или что нет другого пользователя с таким email'ом? Хмм, ну тогда в сервисе. А вот обработка ошибок здесь? Эту обработку ошибок, наверное, здесь, а ту обработку ошибок, которая будет отвечать браузере, в контроллере. А метод SaveChanges, он в сервисе или надо перенести его в контроллер? Может быть и так, и так, потому что, если сервис вызывается один, логичнее вызвать в сервисе, а если у вас в контроллере три метода сервисов, которые надо вызвать, тогда надо вызывать его за пределами этих сервисов, чтобы транзакция была одна. Вот такие размышления наводят на мысль, что, может быть, слои не решают каких-то проблем.

И эта идея пришла в голову не одному человеку. Если погуглить, по крайней мере три вот этих почтенных мужа пишут примерно об одном и том же. Сверху вниз: Стивен .NET Junkie (к сожалению, не знаю его фамилию, потому что она нигде в интернете не фигурирует), автор IoС-контейнера Simple Injector. Дальше Джимми Богард — автор AutoMapper'а. И внизу Скотт Влашин, автор сайта «F# for fun and profit».
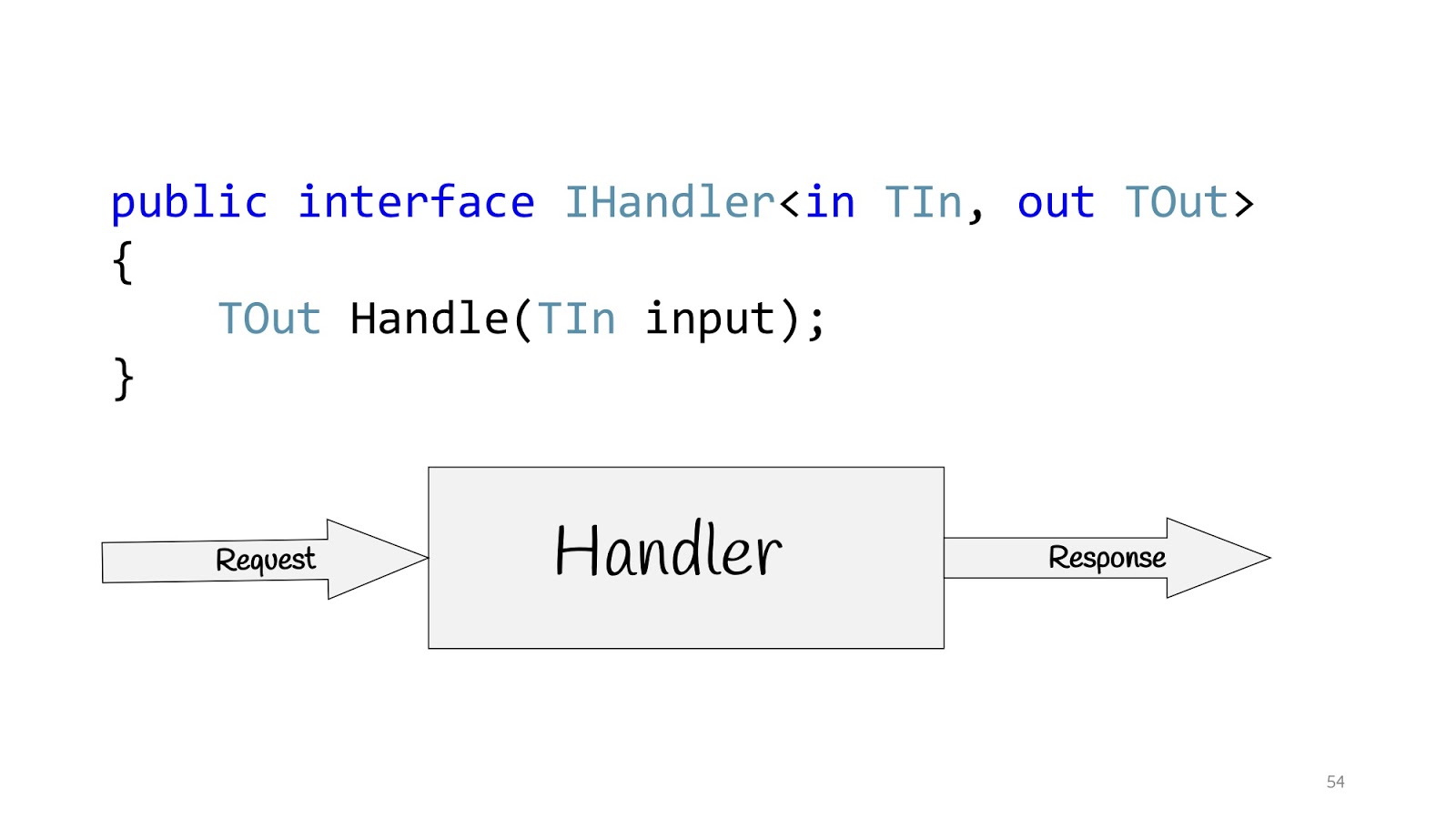
Все эти люди говорят об одном и том же и предлагают строить приложения не на основе слоёв, а на основе вариантов использования, то есть тех требований, о которых бизнес нас просит. Соответственно, вариант использования в C# может быть определён с помощью интерфейса IHandler. У него есть входные значения, есть выходные значения и есть сам метод, который собственно выполняет этот сценарий использования.

А внутри этого метода может быть как доменная модель, так и какая-нибудь денормализованная модель для чтения, может быть с помощью Dapper'а или с помощью Elastic Search'а, если надо что-то искать, а, возможно, у вас есть Legacy-система с хранимыми процедурами — нет проблем, а также сетевые запросы — ну и вообще всё что угодно, что вам там может потребоваться. Но если слоёв нет, как же быть?

Для начала давайте избавляться от UserService. Уберём метод и создадим класс. И ещё уберём, и снова уберём. А потом возьмём и уберём класс.

Давайте подумаем, эти классы эквивалентны или нет? Класс GetUser возвращает данные и ничего не меняет на сервере. Это, например, про запрос «Дай мне ID пользователя». Классы UpdateEmail и BanUser возвращают результат операции и изменяют состояние. Например, когда мы говорим серверу: «Пожалуйста, измени состояние, надо вот что-то поменять».
Посмотрим на протокол HTTP. Есть метод GET, который по спецификации протокола HTTP должен возвращать данные и не менять состояние сервера.

И есть другие методы, которые могут менять состояние сервера и возвращать результат операции.

Парадигма CQRS как будто специально создана для протокола HTTP. Query — это GET-операции, а команды — это PUT, POST, DELETE — не надо ничего придумывать.
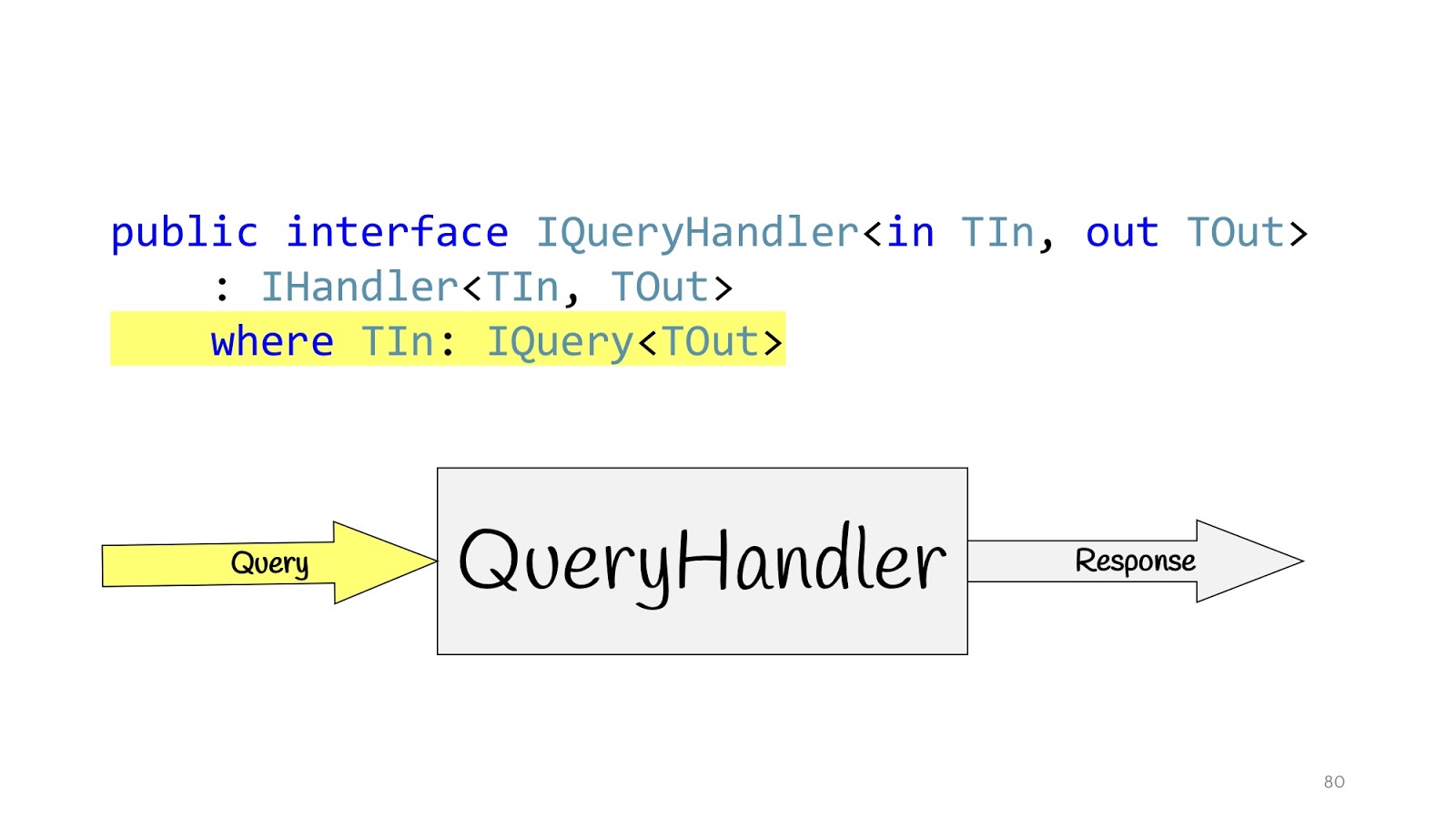
Доопределим наш Handler и определим дополнительные интерфейсы. IQueryHandler, который отличается только тем, что мы повесили constraint о том, что тип входных значений – это IQuery. IQuery — это маркерный интерфейс, в нём ничего нет, кроме вот этого дженерика. Дженерик нам нужен для того, чтобы поставить constraint в QueryHandler'е, и теперь, объявляя QueryHandler, мы не можем туда передать не Query, а передавая туда объект Query, мы знаем его возвращаемое значение. Это удобно, если у вас одни интерфейсы, чтобы потом не искать в коде их реализации, и опять же чтобы не напутать. Вы пишете IQueryHandler, пишете туда реализацию, и в TOut вы не можете подставить другой тип возвращаемого значения. Это просто не скомпилируется. Таким образом сразу видно, какие входные значения соответствуют каким входным данным.

Абсолютно аналогичная ситуация для CommandHandler за одним исключением: вот этот дженерик потребуется ещё для одного трюка, который мы посмотрим чуть дальше.
Реализация Handler
Handler'ы мы объявили, какая же у них реализация?
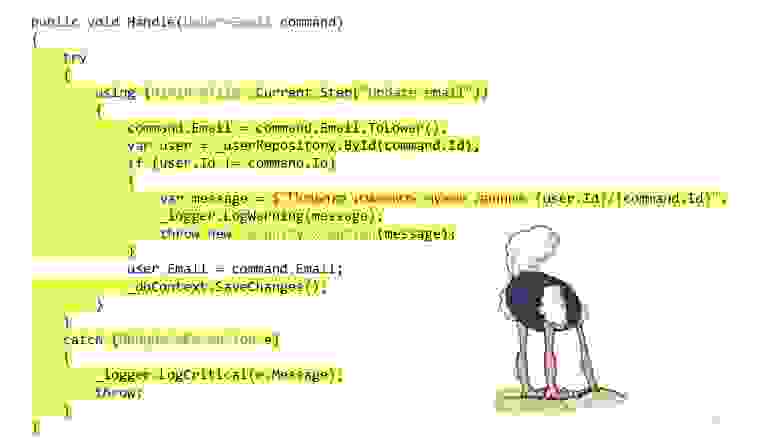
Какая-то проблема есть, да? Кажется, что-то не помогло.
Декораторы спешат на помощь
А не помогло, потому что мы ещё в середине пути, нам нужно ещё немножечко доработать, и на этот раз потребуется воспользоваться паттерном декоратор, а именно его замечательной особенностью компоновки. Декоратор можно завернуть в декоратор, завернуть в декоратор, завернуть в декоратор — продолжайте, пока не надоест.
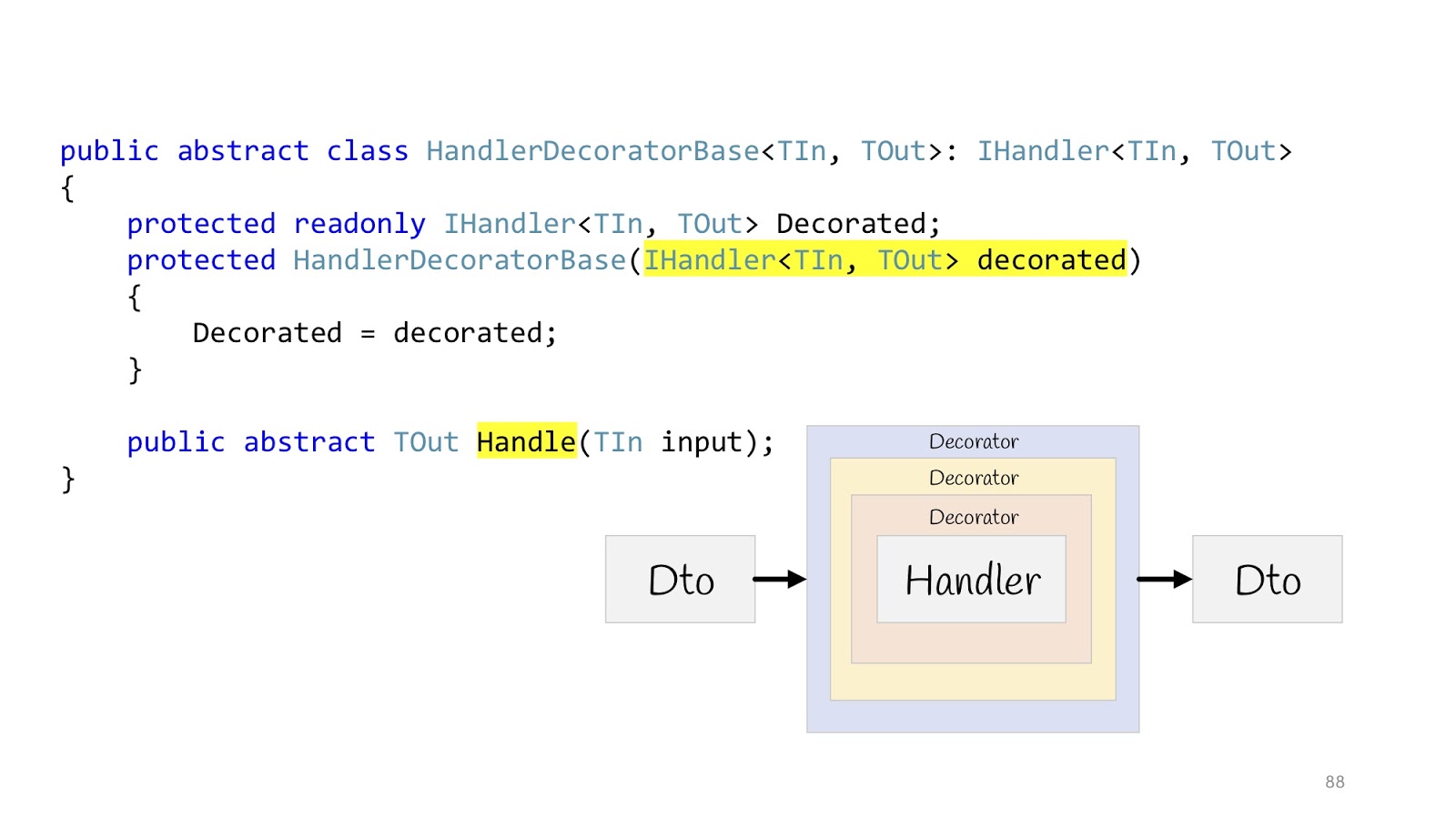
Тогда у нас всё будет выглядеть следующим образом: есть входное Dto, оно входит в первый декоратор, во второй, третий, дальше мы заходим в Handler и так же выходим из него, проходим через все декораторы и возвращаем обратно Dto в браузере. Объявляем абстрактный базовый класс для того, чтобы потом наследовать, в конструктор передаётся само тело Handler'а, и объявляем абстрактный метод Handle, в котором и будет навешиваться дополнительная логика декораторов.
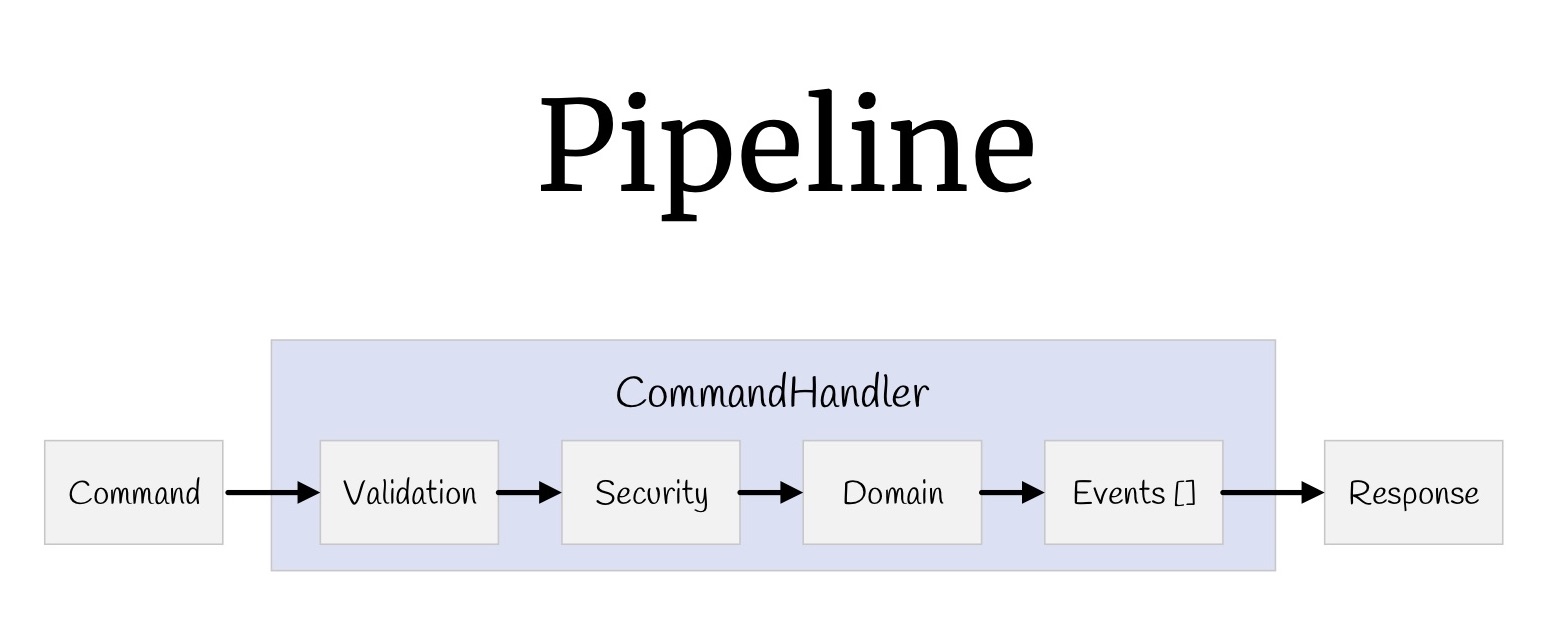
Теперь с помощью декораторов можно собрать целый pipeline. Начнём с команд. Что у нас было? Входные значения, валидация, проверка прав доступа, сама логика, какие-то события, которые случаются в результате этой логики, и возвращаемые значения.

Начнём с валидации. Объявляем декоратор. В конструктор этого декоратора приходит IEnumerable из валидаторов типа T. Мы их все выполняем, проверяем, если валидация не прошла и тип возвращаемого значения — это
IEnumerable<validationresult>, тогда мы его можем вернуть, потому что типы совпадают. А если это какой-то другой Hander, ну тогда придётся выкинуть Exception, потому что нету здесь никакого результата, тип другой возвращаемого значения.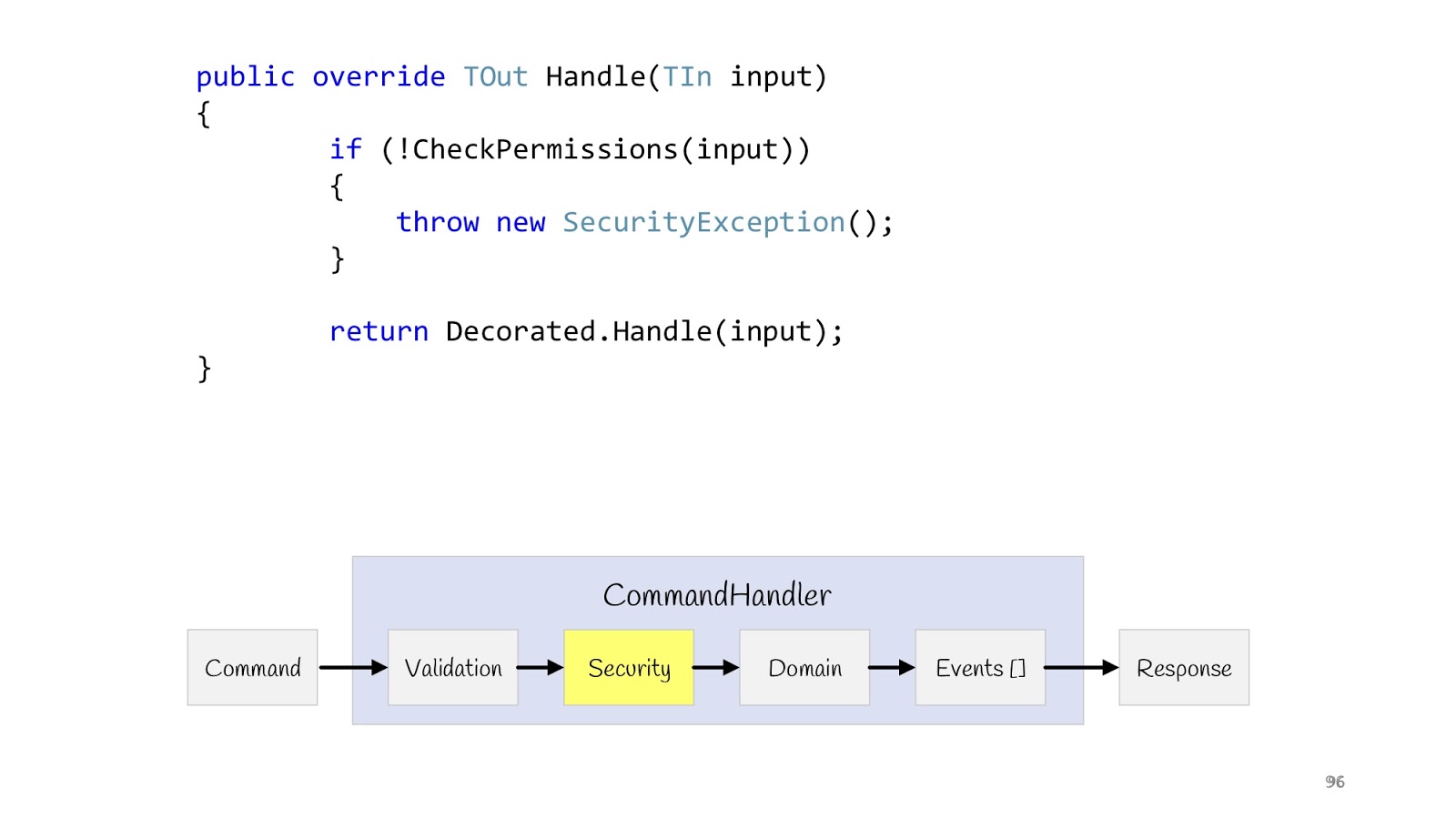
Следующий этап — это Security. Так же объявляем декоратор, делаем метод CheckPermission, проверяем. Если вдруг что-то пошло не так, всё, не продолжаем. Теперь после того, как мы провели все проверки и уверены, что всё хорошо, мы можем выполнять нашу логику.
Одержимость примитивами
Прежде чем показать реализацию логики, я хочу начать немножечко чуть раньше, а именно с входных значений, которые туда приходят.
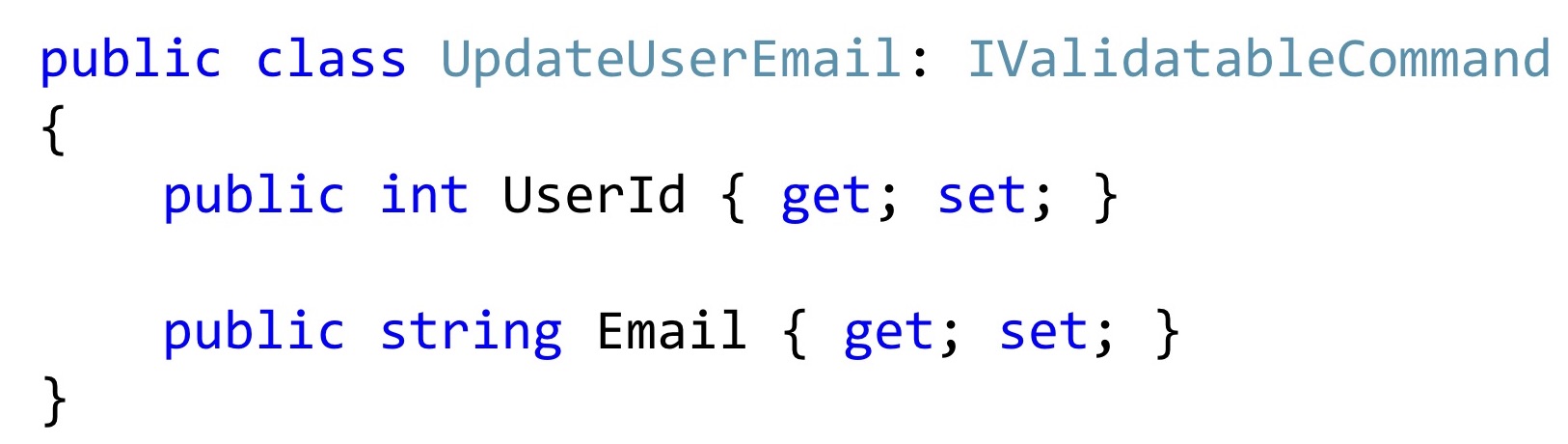
Вот если мы так выделяем такой класс, то чаще всего он может выглядеть как-то вот так. По крайней мере такой код, который я вижу в повседневной работе.
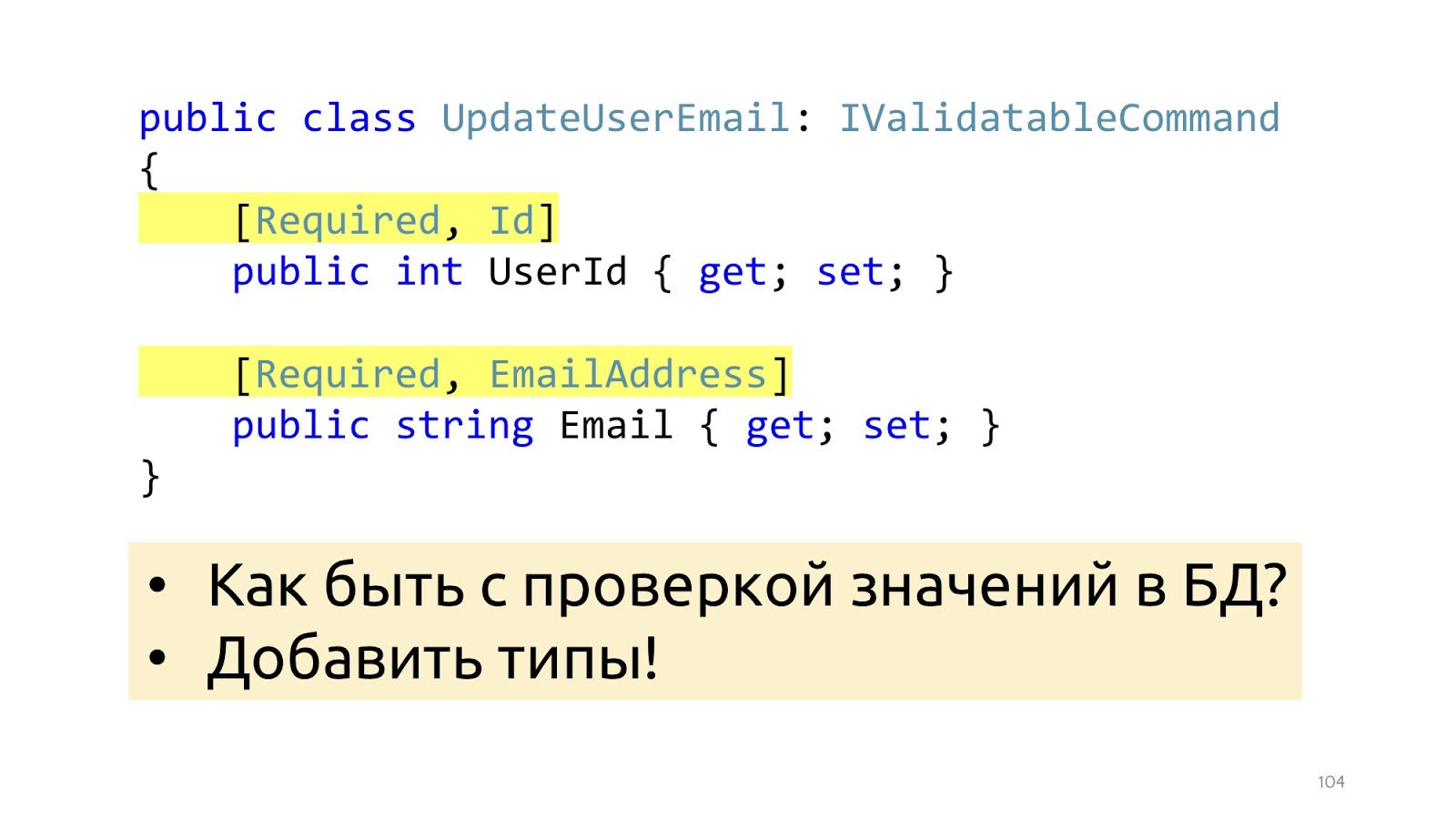
Чтобы валидация работала, мы добавляем сюда какие-то атрибуты, которыми рассказываем, что это за валидация. Это поможет с точки зрения структуры данных, но не поможет с такой валидацией, как проверка значений в БД. Здесь просто EmailAddress, непонятно, как, где проверять, как эти атрибуты использовать для того, чтобы в базу сходить. Вместо атрибутов, можно перейти к специальным типам, тогда эта проблема решится.

Вместо примитива
int объявим такой тип Id, у которого есть дженерик, что это вот определённая сущность с int'овым ключом. И в конструктор мы либо передаём эту сущность, либо передаём её Id, но при этом мы должны передать функцию, которая по Id может взять и вернуть, проверить, null там или не null.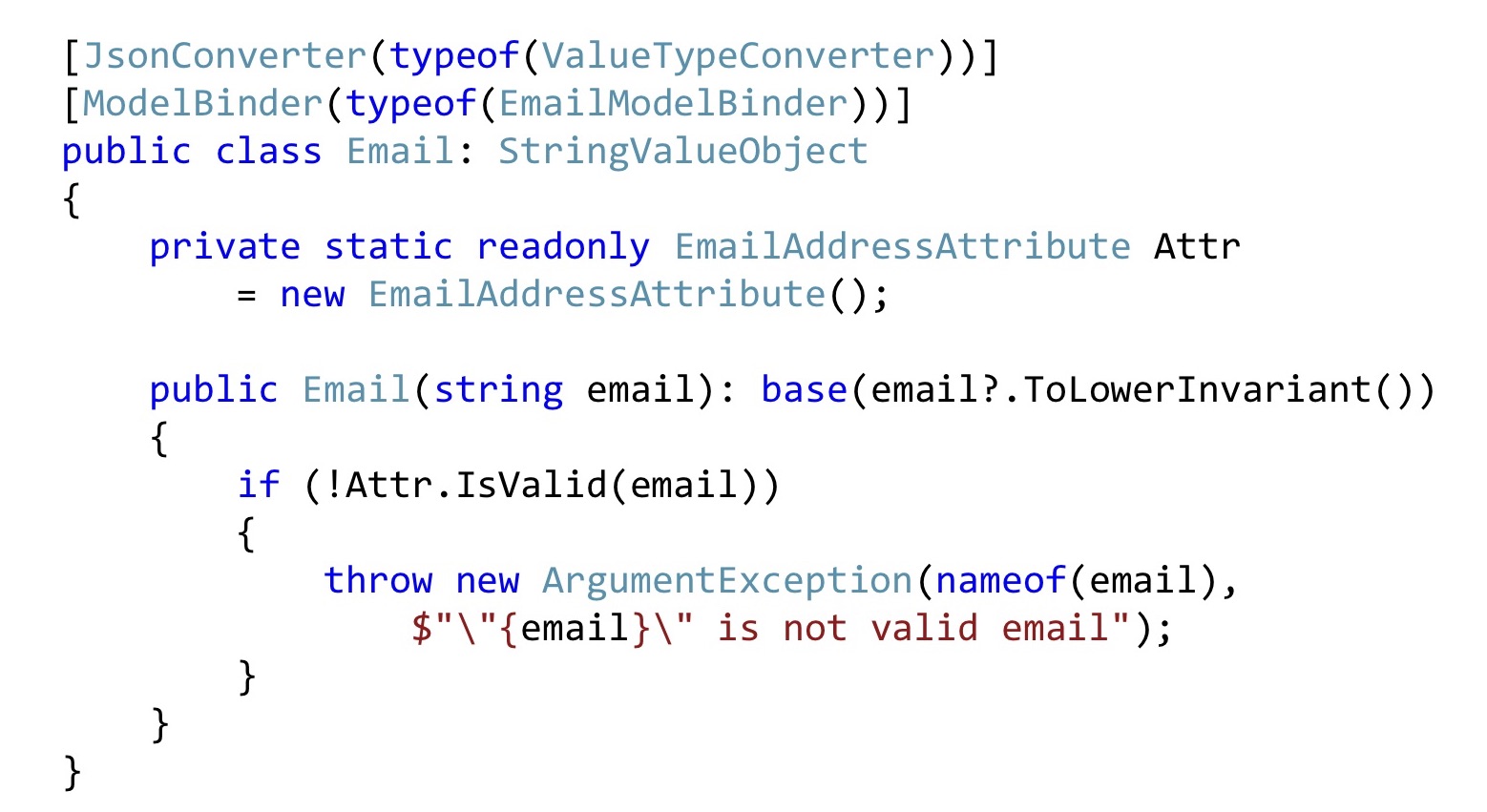
Аналогично поступаем с Email. Преобразуем все Email'ы к нижней строке, чтобы у нас всё выглядело одинаково. Дальше берём Email-атрибут, объявляем его как статический для совместимости с валидацией ASP.NET и здесь его просто вызываем. То есть так тоже можно делать. Для того, чтобы инфраструктура ASP.NET всё это подхватила, придётся немножко изменить сериализацию и/или ModelBinding. Кода там не очень много, он сравнительно простой, поэтому я не буду на этом останавливаться.
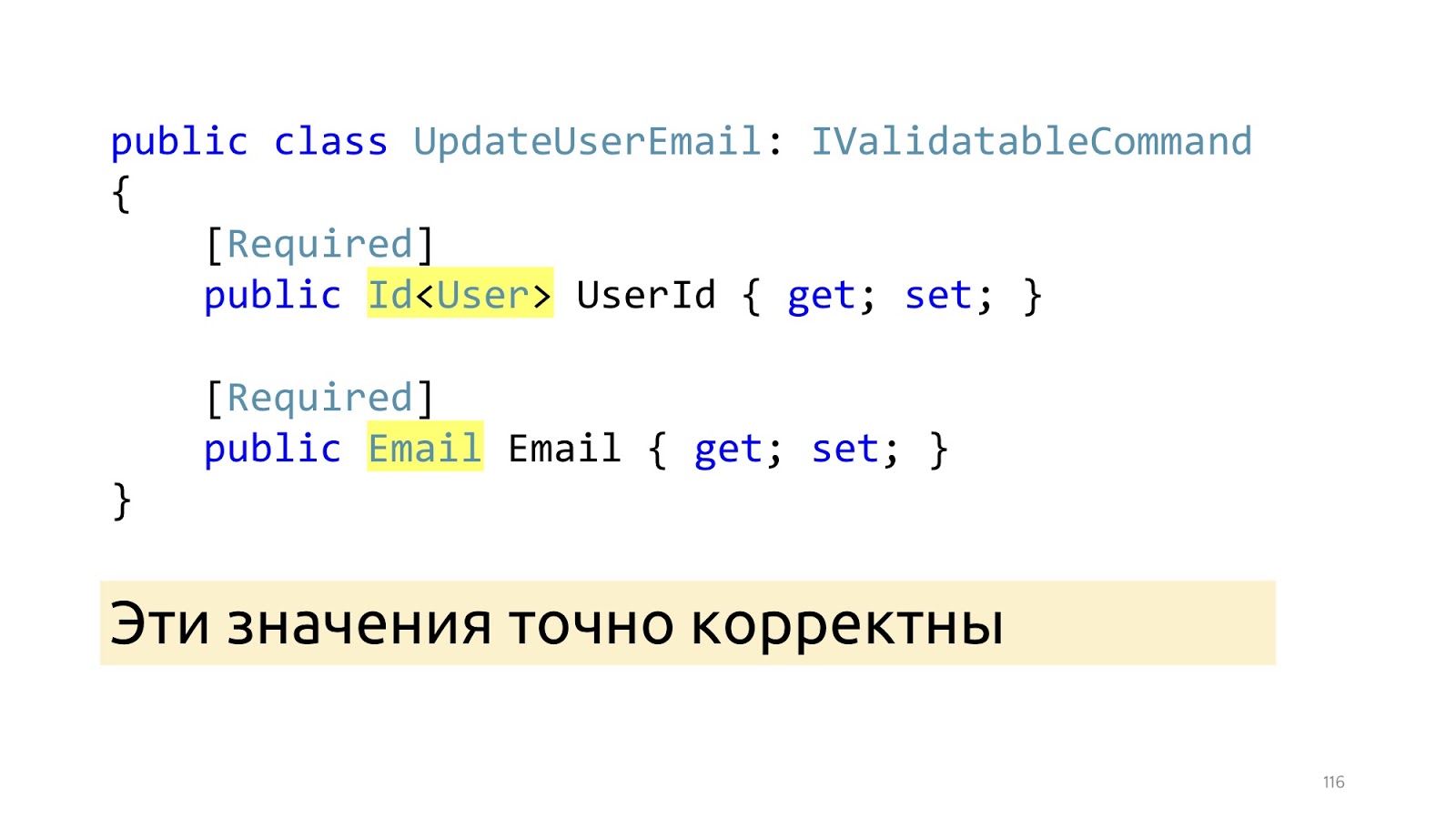
После этих изменений, вместо примитивных типов, у нас здесь появляются специализированные типы: Id и Email. И после того, как отработали вот эти ModelBinder и обновлённый десериализатор, мы точно знаем, что эти значения корректны и в том числе, что такие значения есть в БД. «Инварианты»

Следующий момент, на котором я хотел бы остановиться, это состояние инвариантов в классе, потому что довольно часто используется анемичная модель, в которой есть просто класс, много геттеров-сеттеров, совершенно непонятно, как они должны работать вместе. Мы работаем со сложной бизнес-логикой, поэтому нам важно, чтобы код был самодокументируемым. Вместо этого лучше объявить настоящий конструктор вместе с пустым для ORM, его можно объявлять protected, чтобы программисты в своём прикладном коде не смогли его вызвать, а ORM смогла. Здесь мы передаём уже не примитивный тип, а тип Email, он уже точно корректный, если это null, мы всё ещё выбрасываем Exception. Можно использовать какие-нибудь Fody, PostSharp, но скоро выходит C# 8. Соответственно, там будет Non-nullable reference type, и лучше дождаться его поддержки в языке. Следующий момент, если мы хотим поменять имя и фамилию, скорее всего мы хотим их менять вместе, поэтому должен быть соответствующий публичный метод, который меняет их вместе.

В этом публичный методе мы также проверяем, что длина этих строк соответствует тому, что мы используем в базе данных. И если что-то не так, то останавливаем выполнение. Здесь я использую тот же самый приём. Объявляю специальный атрибут и просто его вызываю в прикладном коде.
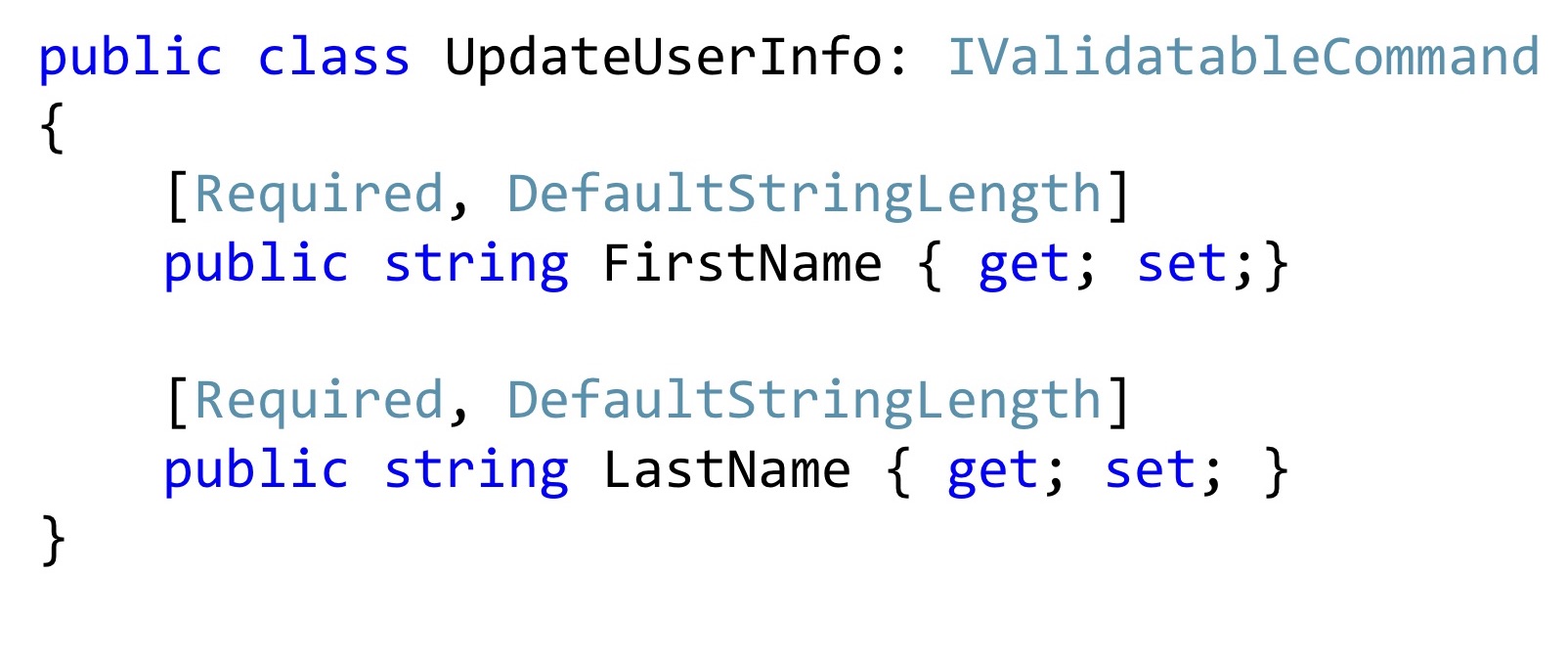
Причём такие атрибуты можно повторно использовать в Dto. Вот если я хочу менять имя и фамилию, у меня может быть такая команда на изменение. А стоит ли добавлять тут специальной конструктор? Вроде как стоит. Оно же лучше станет, никто не поменяет эти значения, не сломает их, они будут точно правильные.

На самом деле не совсем. Дело в том, что Dto в общем-то не совсем объекты. Это такой словарик, в который мы засовываем десериализованные данные. То есть они притворяются объектами, конечно, но у них есть всего одна ответственность — это быть сериализованными и десериализованными. Если мы попытаемся бороться с этой структурой, начнём объявлять какие-то ModelBinder'ы с конструкторами, что-то такое делать, это невероятно утомительно, и, главное, это будет ломаться с новыми выходами новых фреймворков. Всё это хорошо описал Марк Симон в статье «На границах программы не объектно-ориентированы», если интересно — лучше прочитайте его пост, там всё это подробно описано.

Если коротко, то у нас есть грязный внешний мир, мы ставим на входе проверки, преобразуем его к нашей чистой модели, и дальше передаём всё это обратно в сериализацию, в браузер, снова в грязный внешний мир.
Handler
После того, как вот эти все изменения внесены, как у нас будет выглядеть Hander?

Я здесь написал две строчки для того, чтобы удобнее было читать, а вообще можно записать в одну. Данные точно корректны, потому что нас есть система типов, есть валидация, то есть железобетонно корректные данные, проверять их повторно не нужно. Такой пользователь тоже есть, другого пользователя с таким занятым email'ом нету, всё можно делать. Однако ещё нет вызова метода SaveChanges, нет нотификации и нет логов и профайлеров, да? Двигаемся дальше.
Events
Доменные события.

Наверное, в первый раз популяризовал эту концепцию Уди Дахан в его посте «Domain Events – Salvation». Там он предлагает просто объявить статический класс с методом Raise и выкидывать такие события. Чуть позже позже Джимми Богард предложил лучшую реализацию, она так и называется «A better domain events pattern».
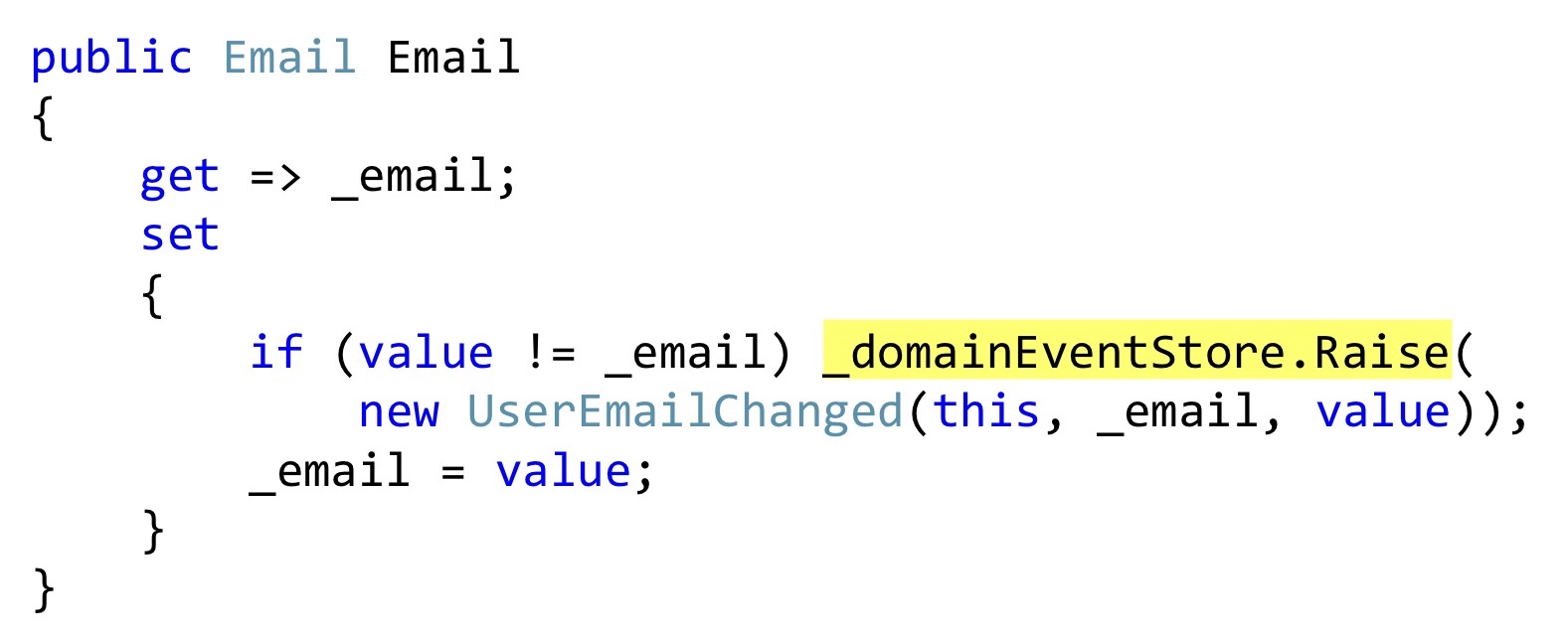
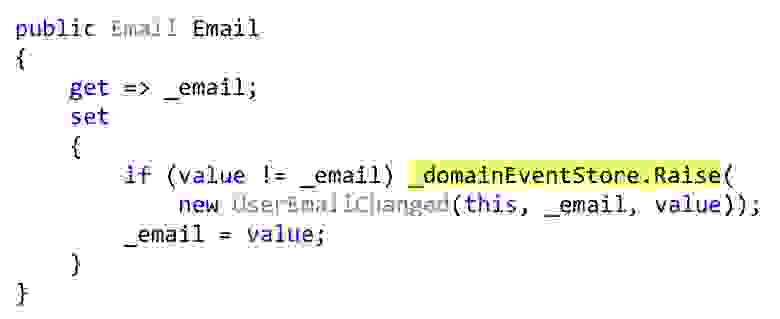
Я буду показывать сериализацию Богарда с одним небольшим изменением, но важным. Вместо того, чтобы выбрасывать события, мы можем объявить какой-то список, и в тех местах, где должна происходить какая-то реакция, прямо внутри сущности сохранять эти события. В данном случае вот этот геттер
email — это также класс User, и этот класс, это свойство не притворяется свойством с автогеттерами и сеттерами, а действительно что-то добавляет к этому. То есть это настоящая инкапсуляция, а не профанация. Когда меняем, мы проверяем, что email другой, и выбрасываем событие. Это событие пока никуда не попадает, оно у нас есть только во внутреннем списке сущностей.
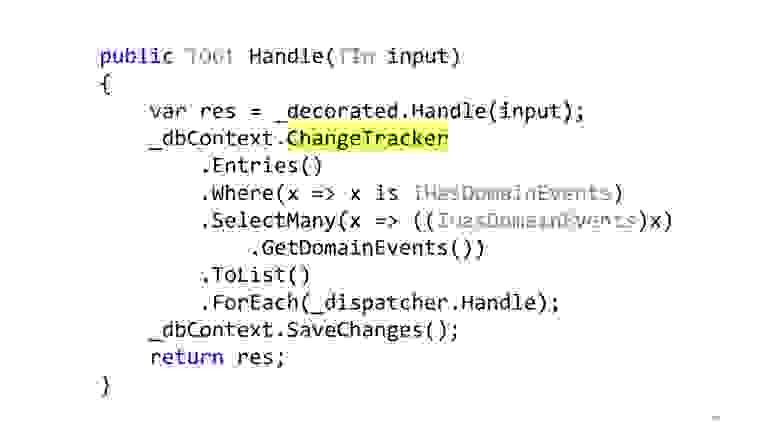
Далее, в тот момент, когда мы будем вызывать метод SaveChanges, мы берём ChangeTracker, смотрим, а есть ли там какие-то сущности, которые реализуют интерфейс, есть ли у них доменные события. И если есть, давайте-ка заберём все эти доменные события и отправим в какой-то диспетчер, который знает, что с ними делать.
Реализация этого диспетчера — это тема отдельного разговора, там есть некоторые сложности с multiple dispatch в C#, но это всё тоже делается. С таким подходом есть ещё одно неочевидное преимущество. Теперь, если у нас есть два разработчика, один может писать код, который изменяет вот этот самый email, а другой может делать модуль нотификаций. Они абсолютно не связаны друг с другом, они пишут разный код, они связаны только на уровне этого доменного события одного класса Dto. Первый разработчик этот класс просто в какой-то момент выбрасывает, второй на него реагирует и знает, что это надо отправлять на email, SMS, push-уведомления на телефон и все остальные миллион уведомлений с учётом всяких предпочтений пользователей, которые обычно бывают.
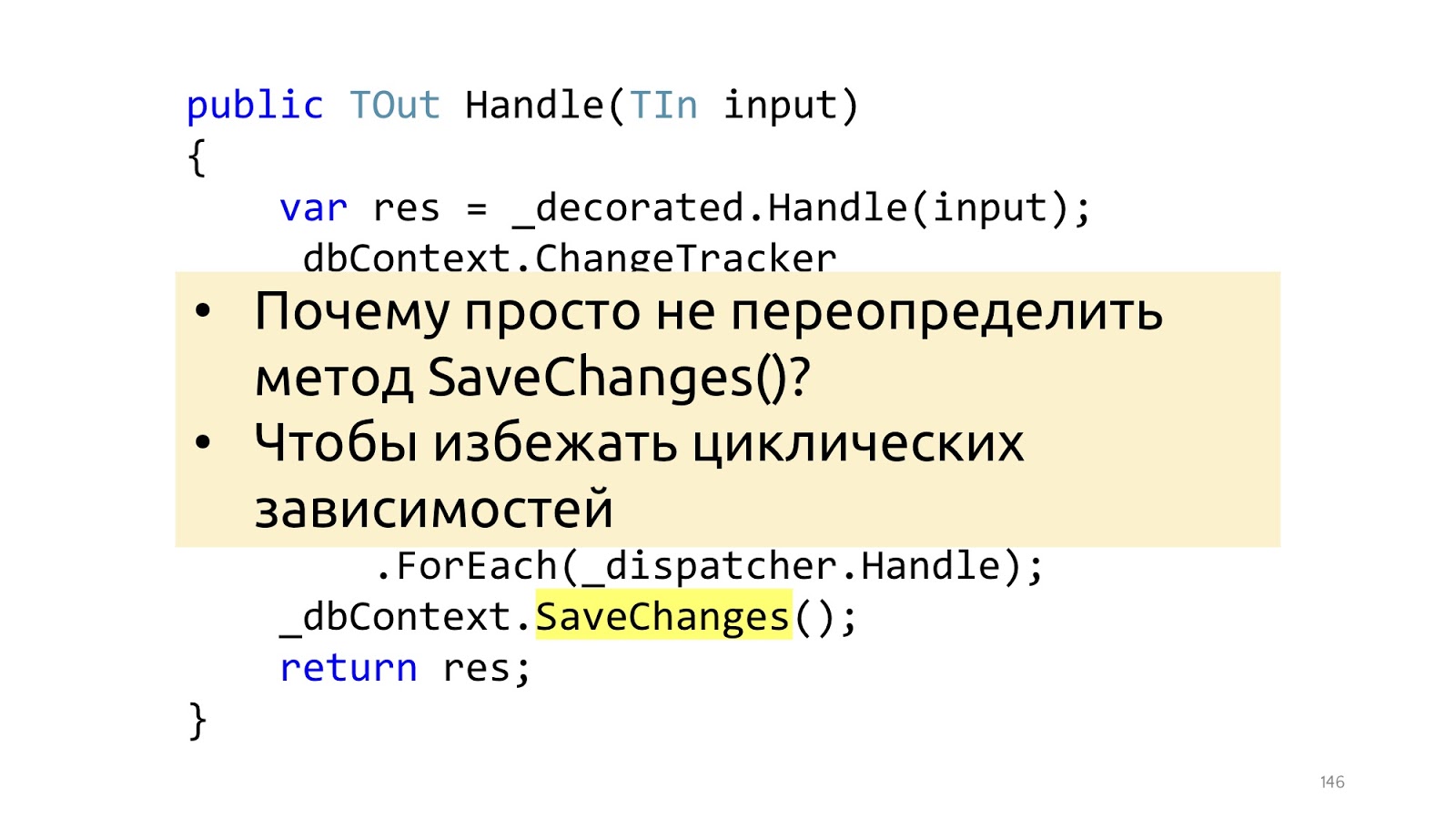
Вот то самое небольшое, но важное замечание. В статье Джимми используется перегрузка метода SaveChanges, и лучше этого не делать. А сделать это лучше в декораторе, потому что, если мы перегружаем метод SaveChanges и нам в Handler'е потребовался dbContext, мы получим циклические зависимости. С этим можно работать, но решения получаются чуть менее удобные и чуть менее красивые. Поэтому, если pipeline построен на декораторах, то смысла делать по-другому я не вижу.
Логирование и профилирование

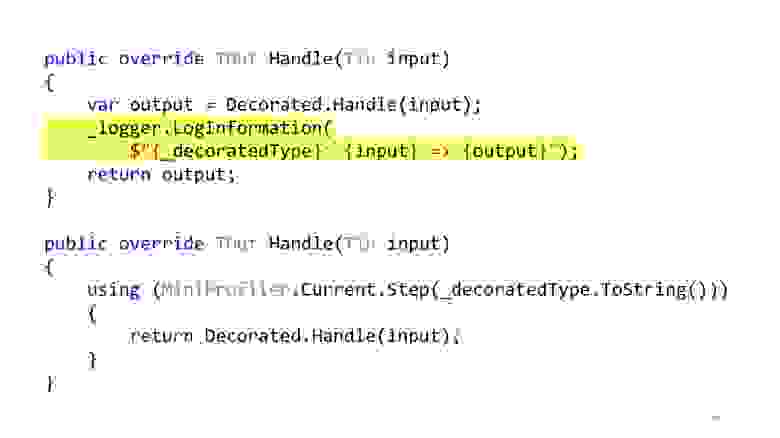
Вложенность кода осталась, но в первоначальном примере у нас был сначала using MiniProfiler, потом — try catch, потом — if. Итого было три уровня вложенности, теперь каждый этот уровень вложенности находится в своем декораторе. И внутри декоратора, который у нас отвечает за профилирование, у нас только один уровень вложенности, код читается отлично. Кроме того, видно, что в этих декораторах только одна ответственность. Если декоратор отвечает за логирование, то он будет только логировать, если за профилирование, соответственно, только профилировать, всё остальное находится в других местах.
Response
После того, как весь pipeline отработал, нам остается только взять Dto и отправить дальше браузеру, сериализовать JSON.
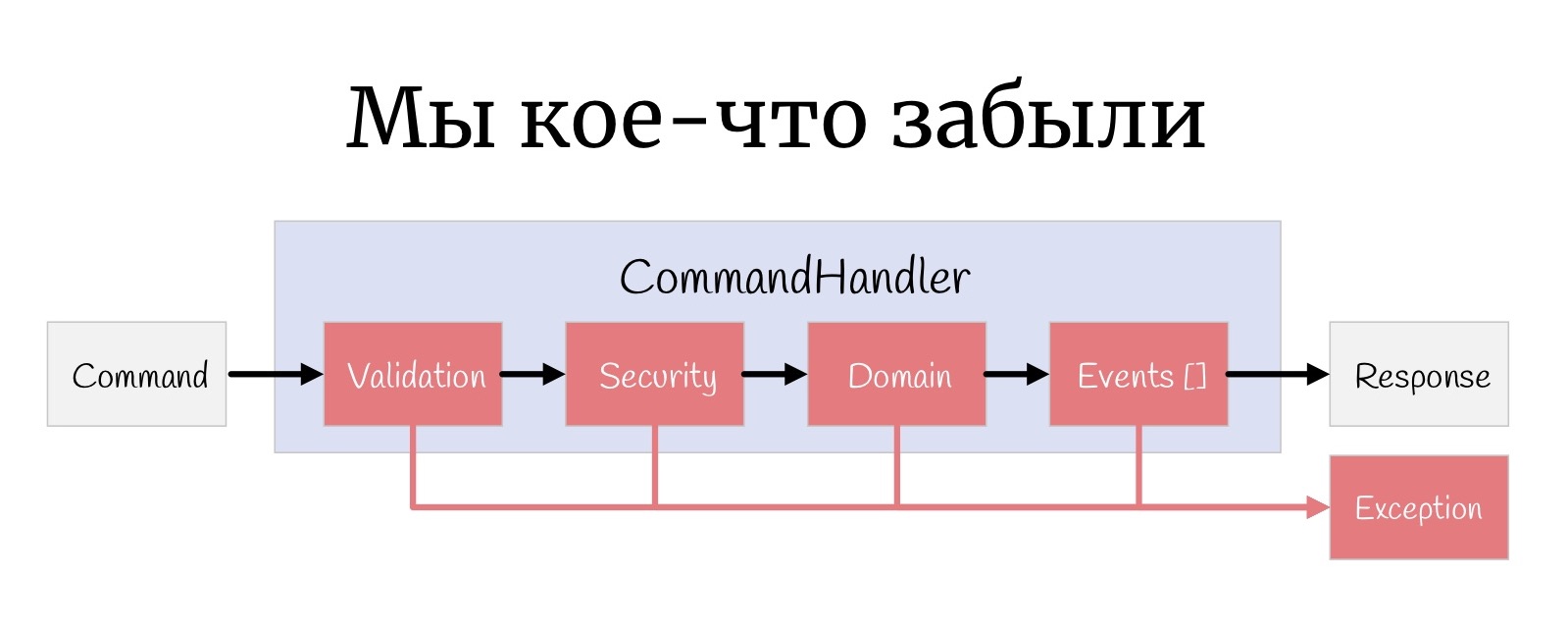
Но ещё одна маленькая-маленькая такая вещь, которую иногда забывают: на каждом этапе здесь может случиться Exception, и вообще-то надо как-то их обрабатывать.

Не могу здесь не упомянуть ещё раз Скотта Влашина и его доклад «Railway oriented programming». Почему? Оригинальный доклад целиком и полностью посвящён работе с ошибками на языке F#, тому, как можно организовать flow немножко по-другому и почему такой подход может быть более предпочтительным, чем использование Exception'ов. В F# это действительно работает очень хорошо, потому что F# — это функциональный язык, и Скотт использует возможности функционального языка.

Так как, наверное, большинство из вас всё-таки пишет на C#, то, если написать аналог на C#, то этот подход будет выглядеть примерно следующим образом. Вместо того, чтобы выбрасывать исключения, мы объявляем такой класс Result, у которого есть успешная ветка и есть неуспешная ветка. Соответственно два конструктора. Класс может находиться только в одном состоянии. Этот класс является частным случаем типа-объединения, discriminated union из F#, но переписанный на C#, потому что встроенной поддержки в C# нет.

Вместо того, чтобы объявлять публичные геттеры, которые в коде кто-то может не проверить на null, используется Pattern Matching. Опять же, в F# это был бы встроенный в язык Pattern Matching, в C# приходится писать отдельный метод, в который мы передадим одну функцию, которая знает, что делать с успешным результатом операции, как его преобразовать дальше по цепочке, и что с ошибкой. То есть независимо от того, какая ветка у нас сработала, мы должны скастить это к одному возвращаемому результату. В F# это всё работает очень хорошо, потому что там есть функциональная композиция, ну и всё остальное, что я уже перечислил. В .NET это работает несколько хуже, потому что как только у вас происходит не один Result, а много — а практически каждый метод может по тем или иным причинам закончиться неудачей — почти все ваши результирующие типы функции становятся типа Result, и вам надо их как-то комбинировать.

Самый простой способ их скомбинировать — использовать LINQ, потому что вообще-то LINQ работает не только с IEnumerable, если доопределить методы SelectMany и Select правильным образом, тогда компилятор C# увидит, что можно использовать для этих типов LINQ-синтаксис. В общем-то получается калька с do-нотации Haskell или с тех же самых Computation Expressions в F#. Как это следует читать? Вот у нас есть три результата операции, и если там во всех трёх случаях всё хорошо, тогда возьми эти результаты r1 + r2 + r3 и сложи. Тип результирующего значения тоже будет Result, но новый Result, который мы объявляем в Select'е. В общем-то, это даже рабочий подход, если бы не одно но.

Для всех остальных разработчиков, как только вы начинаете писать такой код на C#, вы начинаете выглядеть примерно вот так. «Это плохие страшные Exception'ы, не пишите их! Они — зло! Лучше пишите код, который никто не понимает и не сможет отладить!»

C# — это не F#, он несколько отличается, там нет разных концепций, на основе которых это делается, и когда мы так пытаемся натянуть сову на глобус, получается, мягко говоря, непривычно.

Вместо этого можно использовать встроенные нормальные средства, которые задокументированы, которые все знают и которые не будут вызывать у разработчиков когнитивный диссонанс. В ASP.NET есть глобальный Handler Exception'ов.

Мы знаем, что, если с валидацией какие-то проблемы, надо вернуть код 400 или 422 (Unprocessable Entity). Если проблема с аутентификацией и авторизацией, есть 401 и 403. Если что-то пошло не так, то что-то пошло не так. А если что-то пошло не так и вы хотите сказать пользователю, что именно, определите свой тип Exception'а, скажите, что это IHasUserMessage, объявите в этом интерфейсе геттер Message и просто проверьте: если этот интерфейс реализован, значит, можно взять сообщение из Exception'а и передать его в JSON пользователю. Если этот интерфейс не реализован, значит, там какая-то системная ошибка, и пользователям мы скажем просто, что что-то пошло не так, мы уже занимаемся, мы всё знаем — ну как обычно.
Query Pipeline
На этом с командами завершаем и смотрим, что же у нас в Read-стеке. То, что касается непосредственно запроса, валидации, ответа — это примерно всё то же самое, не будем отдельно останавливаться. Здесь может быть ещё дополнительно кэш, но в общем-то с кэшем тоже нет каких-то больших проблем.
Security
Посмотрим лучше на проверку безопасности. Там может быть тоже такой же декоратор Security, который проверяет, можно ли делать этот запрос или нет:

Но есть ещё один случай, когда мы выводим не одну запись, а выводим списки, и каким-то пользователям мы должны вывести полный список (например, каким-нибудь суперадминистраторам), а другим пользователям мы должны вывести ограниченные списки, третьим — ограниченные по-другому, ну и как это часто бывает в корпоративных приложениях, права доступа могут быть крайне изощренными, поэтому нужно быть точно уверенными, что в эти списки не пролезут данные, которые этим пользователям не предназначаются.
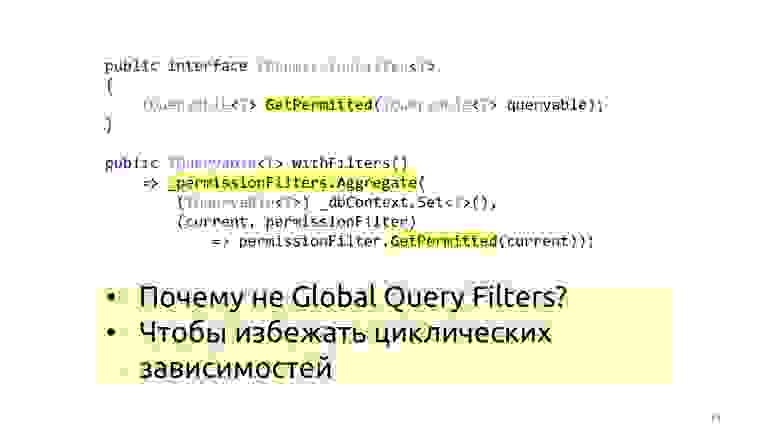
Проблема решается довольно просто. Мы можем доопределить интерфейс (IPermissionFilter), в который приходит оригинальный queryable и возвращается queryable. Разница в том, что к тому queryable, который возвращается, мы уже навесили дополнительные условия where, проверили текущего пользователя и сказали: «Вот этому пользователю верни только те данные, которые…» — а дальше вся ваша логика, которая связана с permission'ами. Опять же, если у вас есть два программиста, один программист идёт писать permission'ы, он знает, что ему надо написать просто очень много permissionFilter'ов и проверить, что по всем сущностям они работают правильно. А другие программисты ничего не знают про permission'ы, в их списке просто всегда проходят правильные данные, вот и всё. Потому что они получают на входе уже не оригинальный queryable из dbContext, а ограниченный фильтрами. У такого permissionFilter'а тоже есть свойство компоновки, мы можем все permissionFilter'ы сложить и применить. В итоге получаем результирующий permissionFilter, который максимально сузит выборку данных с учётом всех условий, которые для данной сущности подходят.

Почему это не делать встроенными средствами ORM, например, Global Filters в entity-фреймворке? Опять же для того, чтобы не городить себе всякие циклические зависимости и не тащить в context всякую дополнительную историю про ваш бизнес-слой.
Query Pipeline. Read Model
Осталось посмотреть на модель чтения. В парадигме CQRS не используется доменная модель в стеке чтения, вместо этого мы просто сразу формируем те Dto, которые нужны браузеру в данный момент.

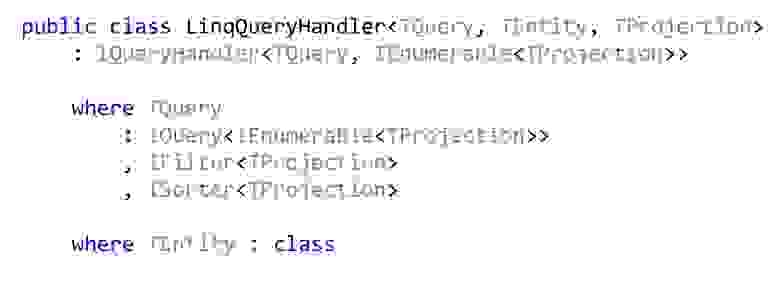
Если мы пишем на C#, то, скорее всего, мы используем LINQ, если нет только каких-то чудовищных требований по производительности, а если они есть, то, возможно, у вас не корпоративное приложение. Вообще эту задачу можно решить раз и навсегда вот таким LinqQueryHandler'ом. Здесь довольно страшный constraint на дженерик: это вот Query, который возвращает список проекций, и она ещё может фильтровать вот эти проекции и сортировать вот эти проекции. Ещё она работает только с какими-то типами сущностей и знает, как эти сущности преобразовать к проекциям и вернуть список таких проекций уже в виде Dto в браузер.

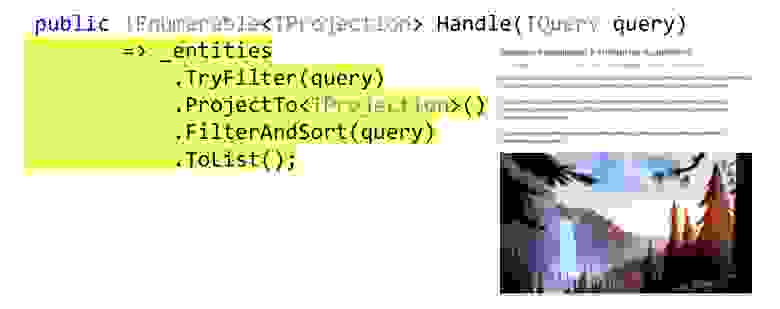
Реализация метода Handle может быть такая, довольно простая. На всякий случай проверим, реализует ли этот TQuery фильтр для изначальной сущности. Дальше делаем проекцию, это queryable extension AutoMapper'а. Если кто-то до сих пор не знает, AutoMapper может строить проекции в LINQ, то есть те, которые будут строить метод Select, а не маппить это в памяти.
Дальше применяем фильтрацию, сортировку и выдаём всё это в браузер. Как именно всё это делается, я рассказывал в Питере на DotNext, это ещё один целый доклад, он уже выложен в свободный доступ и расшифрован на Хабре, можете послушать, посмотреть, прочитать, как написать с помощью expression'ов фильтрацию, сортировку и проекции для чего угодно один раз и дальше повторно использовать.
Не все выражения одинаково полезны транслируются в SQL
Двигаемся дальше. Одна тема, которую я не осветил на прошлом DotNext'е, — это проблемы с трансляцией в SQL. Потому что в Select мы, конечно, можем написать всё что мы хотим, но queryable-провайдеры не всё разберут.
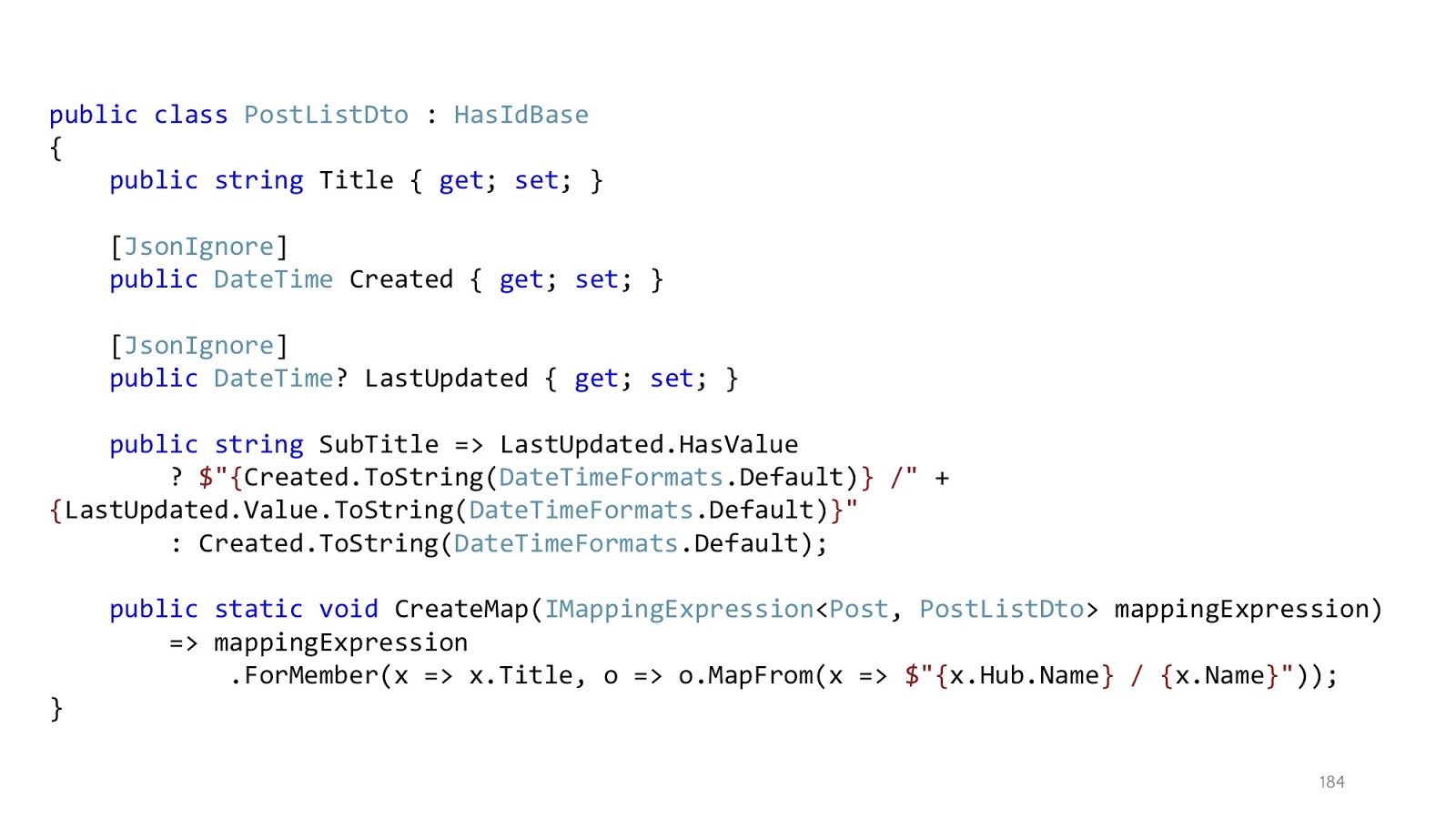
Раз уж речь зашла про Хабр, давайте на примере Хабра. У нас есть список постов, у них есть Title, и Title мы хотим вводить как название хаба, а потом название самого поста. Вот с этой проекцией проблем нет, всё преобразуется. А вот если мы хотим вывести такой SubTitle, когда в последний раз обновляли статью, когда её создали, и хотим ещё использовать какой-то свой кастомный формат для этих дат, вот с этим queryable-провайдер уже не справится. Он не в курсе, что за кастомный формат объявлен в нашем коде.
И есть один довольно простой трюк, который эту проблему решает. Вместо того, чтобы пытаться сделать проекцию, мы делаем проекцию на примитивы. То есть вытаскиваем всё, что нам нужно, сначала. Далее помечаем это всё «JsonIgnore», чтобы сериализатор проигнорировал эти поля. И объявляем тот метод, который нам нужен, в Dto. То есть вместо того, чтобы делать это в проекции, мы это делаем уже в памяти. Когда сериализатор начнёт преобразование класса в JSON, он увидит, что Created и LastUpdated он должен пропустить, а SubTitle — это публичное свойство, надо его взять. Тогда он возьмёт его, вызовет этот метод, и дальше мы уже в памяти домаппим то, что нам нужно, то, что мы не смогли преобразовать в проекции. В большинстве случаев такой простой трюк решает проблему с тем, что какие-то выражения не могут быть преобразованы.

Давайте посмотрим на оба стека вместе. Они, в общем-то, довольно похожи и отличаются только тем, какие шаги мы собрали. В зависимости от того, какой pipeline, мы можем применять разные декораторы. Вот запросы мы будем кэшировать — а в командах это уже нам, допустим, не потребуется. Аналогично, команды мы хотим вызывать в SaveChanges, а в Query не надо вызывать SaveChanges. Когда пайплайны собраны и мы понимаем, что их ограниченное количество, такие декораторы можно взять и оформить в виде отдельных библиотек, положить на NuGet, и дальше просто подключать в виде повторно используемых модулей.
Потому что в коде декораторов нет ничего про домен. Вы можете отдельно писать домен, а инфраструктуру передать какому-то другому разработчику, которой оформит вам эти модули, и вы будете ими пользоваться. Если вы знакомы, например, с трудами Брукса, наверное, знаете, что самый простой способ написать код — это его купить. Соответственно, отличный вариант, если вы можете взять и сказать: «Нам нужны вот такие декораторы», — и их купить. Никакой ответственности.
Регистрация декораторов
Если декораторы такие замечательные, как же их регистрировать?

Регистрировать их придётся как-то вот так. Не совсем красиво.

Хотя руками, конечно, никто это не делает, это всё происходит через контейнеры. Можно взять MediatR Джимми Богарда, в котором это всё уже есть и есть документация. Всё, о чём я рассказывал, такие же декораторы — правда, у него в MediatR это называется pipeline behaviour. Но смысл тот же, там так же определены методы Request/Response, RequestHandler’ы и методы для регистрации этих декораторов. А можно взять Simple Injector, у которого декоратор — это прямо фишка фреймворка.

И сейчас вернёмся вот на этот слайд, помните, я говорил, что нам потребуется ещё раз этот дженерик, где TIn: ICommand.

Вот в Simple Injector’е поддерживается регистрация декораторов на основе constraint’ов дополнительно. То есть вы можете там, где будете регистрировать декоратор, указать, что если декоратор с constraint’ом, то он будет применяться только к тем Handler’ам, у которых есть такой constraint. Соответственно, если у нас есть constraint ICommand, мы можем сделать декоратор на SaveChanges тоже с constraint’ом на ICommand, и Simple Injector автоматически поймёт, что эти два constraint’а одинаковые, и будет применять этот декоратор только к соответствующему Handler’у. Ну, получается ещё одна маленькая красивая фишечка, которая позволяет на системе типов строить вот такую логику приложения, что к чему должно применяться.
Что использовать? Simple Injector или MeriatR — в принципе, на вкус и цвет все фломастеры разные, кроме того в Autofac’е, по-моему, тоже есть декораторы и в других контейнерах может быть тоже, я просто не слежу, не знаю. Если интересно, посмотрите.
Организация по модулям, а не слоям
Во всём моём текущем докладе не хватает ещё одного слова, чтобы кричать «бинго».
Даже двух слов, а именно «Clean architecture». Нельзя же было упомянуть много умных людей и забыть про дядюшку Боба Мартина.

Современные веб-приложения почему-то очень любят рассказывать о том, что они MVC, какие они замечательные, какая у них структура.

Вместо этого, и Боб Мартин, и многие другие, и в том числе Angular, кстати, уже предлагает структурировать приложение на основе того, какие там есть модули в системе, то есть какая функциональность. Вместо того, чтобы сказать: «Я — MVC-приложение», можно сказать: «У меня есть следующие Features, то есть такая функциональность: у меня есть менеджмент аккаунтов, у меня есть Blog и у меня есть какой-то Import, то есть три каких-то больших модуля».
Может быть, программистам, конечно, удобнее знать, что это MVC-приложение, нам нравится, что там какие-то технические подробности, детали. Но для менеджмента MVC абсолютно неважно. А вот такая структура, когда человек понимает, сколько у него есть фич — это для бизнеса гораздо важнее. То есть эта структура соответствует функциональности системы.


Я же обещал всё-таки не давить авторитетами и тем, что кунг-фу сильнее другого кунг-фу, поэтому я приведу и другие преимущества такого оформления.
Во-первых, код в таком случае добавляется, а не редактируется. Если у нас есть разные модули и мы хотим добавить новый модуль, это новая папка. Не получится такого, что в модуле А и в модуле Б есть какая-то работа с юзерами, поэтому программисты Вася и Петя оба пошли исправлять User Service, дальше отправили pull request’ы, и тут внезапно случился конфликт, потому что они оба изменили этот User Service в соответствии с тем, как считали нужным. Причём даже без того, что они изменили сигнатуры или что-то вроде, а просто у них где-то поменялись строчки, типы. Какие-то банальные технические вещи могут приводить к тому, что на этапе код ревью может случиться конфликт и это затянет релизный цикл.
Следующий момент. Такая организация кода побуждает нас лучше думать о том, какие контексты есть в приложении и как его правильно делить. То есть, если мы делим правильно, то в идеале мы должны не создавать вообще лишних зависимостей между модулями там, где их нет. Соответственно, там, где есть, мы узнаем, что они есть, на этапе разделения по модулям, потому что мы увидим, что вот этот модуль почему-то зависит от другого. И если так получилось, что наши модули полностью независимы (а так тоже можно сделать, но с некоторыми оговорками), тогда фичу можно будет удалить, просто нажав кнопочку «Delete»: мы удаляем папку, и её больше нет в программе, и всё. Довольно удобно.
В практике нам раза два приходилось проводить такие действия — слово «рефакторинг», наверное, не совсем правильно, когда выбрасываешь весь код и заново переписываешь, это скорее рерайт. И если бы код был написан в обычном слоёном стиле, так бы не получилось: все эти сервисы, относящиеся к разным модулям, мы бы не смогли выкинуть, потому что были бы лишние зависимости. А так мы просто выкинули несколько косячных модулей и потом переписали, когда руки дошли. Я не буду вдаваться в подробности, почему так пришлось сделать, но иногда бывает. То есть это произошло не потому, что были плохие и глупые программисты, а потому что так сложились обстоятельства.
И последний момент: такое разделение упрощает работу численными методами и коммуникацию. Когда я говорю «численными методами», я опять же делаю реверанс в сторону менеджмента: мы начинаем считать количество фич, количество возвратов с код ревью, количество возвратов с тестирования и вот это вот всё. Помните, когда я формулировал критерии, обратил внимание на то, что довольно сложно отслеживать связь между регрессией, багами, которые дошли до продакшна, и тем, почему так произошло. А когда мы начинаем класть код таким образом, становится чуть легче. Потому что, если приходит какой-то pull request на редактирование существующих модулей, вариант номер один — изменились требования, вариант номер два — что-то пошло не так, баг пролез на продакшн. И вот дальше мы уже смотрим историю изменения в VCS именно по этому модулю: а что ж он пролез-то на продакшн, какие там коммиты были? Если эти коммиты находятся в этом модуле, в них ещё как-то можно разобраться, а если они просто размазаны по всем нашим слоям, разбираться становится сильно сложнее.

Несмотря на это, всё, о чем я говорил, не лишено недостатков. А именно: это не работает из коробки. То есть если вы возьмёте просто шаблон проекта, вам придётся дописывать инфраструктурный код. В идеале, написать свой шаблон проекта, в который уже будет подключено всё, что нужно, будет структура проектов. Но уходит на это, наверное, не меньше рабочего дня, если вы с нуля это делаете. Ну, один раз, допустим. Когда я говорю «рабочий день», это в смысле у нас уже всё готово, вам надо только зависимости собрать. На то, чтобы собрать зависимости, у меня ушло несколько лет — с тем, как изменялась моя мысль о том, как писать код.
Это иллюстрирует второй пункт данного слайда: этот инфраструктурный код писать, что-то переопределять, дописывать. То есть к нему предъявляются более серьёзные требования в плане качества. В каком-то прикладном коде вы можете писать так, как у вас принято, потому что, если придёт баг, вы поправите. А вот если вы начинаете публиковать какие-то библиотеки в свободный доступ и они с косяками, и кто-то их подключил и это уже не один проект, а на этом завязана у вас, допустим, работа всей компании или проекта клиентов, это становится сильно сложнее. Риски этого дела выше.

Резюмируем. Если вы захотите организовать работу с кодом следующим образом, вам нужно будет объявить вот такой IHandler в качестве основного строительного блока. Он будет выполнять операции.
Дальше этот IHandler расширяем двумя интерфейсами ICommandHandler и IQueryHandler и говорим, что это холистические абстракции. Очень круто звучащее словосочетание, значит на самом деле просто, что оно выполняется в рамках одной транзакции. То есть, если есть CommandHandler, внутри него не будет другого CommandHandler’а, он действует на протяжении всего этого запроса.
Почему так? Это исключает флейм на тему того, что можно там Query использовать в командах, команды в Query — вот это всё. Если вам нужен повторно используемый код, который придётся использовать и там, и там, тогда вы объявляете Hander, если вы объявляете CommandHandler или QueryHandler, это значит какой-то конкретный use case, это не должно повторно использоваться.
Декораторы — это отличный инструмент для того, чтобы разделить вот эту всю логику, разделить ответственности, обязанности между разными классами, чтобы их регистрировать потребуется инфраструктура: либо контейнер, либо фреймворк.
Система типов и инварианты сильно лучше, чем валидация. Потому что позволяет на этапе компиляции узнавать об ошибках, а не в рантайме. Но не на границах, потому что на границах программы не объектно-ориентированы.
И мы всё ещё ждём C# 8, чтобы появился nullable reference type и наша система типов стала получше. Не такая, конечно, крутая, как в функциональных языках программирования, но лучше.
События можно трекать в рамках транзакции с помощью ChangeTracker’а ORM.
И Exception’ы — это нормальный вариант для ошибок, если не писать на F#, если мы пишем на C#. Есть вариант, в котором всё-таки надо отказаться от этих исключений, там может быть какое-то ограничение по производительности, например. Но если у вас возникают ограничения по производительности, связанные с тем, что у вас слишком много Exception’ов, возможно, вам не нужен там и LINQ, и всё остальное, и всё, что я вам рассказывал, это не совсем для вас, вам нужны хранимые процедуры, Dapper и что-то ещё, и, может быть, даже не .NET.
А если у нас нет таких страшных требований к производительности, тогда LINQ, автоматические проекции, permission’ы — это всё отлично. Да, это всё действительно тормозит, но тормозит какие-то миллисекунды, то есть это меньше, чем сетевые задержки к вашей базе данных. Ну и структурирование приложения по фиче, а не по слоям — более предпочтительный способ.
Я упомянул в докладе много людей и идей. Вот ссылки:
- Vertical Slices
- Одержимость примитивами
- Domain Events
- DDD
- ROP
- LINQ и Expressions:
- Clean Architecture

Последний слайд — немножко рекомендуемой литературы. Слева у нас нетленочка Эрика Эванса. Вторая книжка — это книга Скотта Влашина «Domain Modeling Made Functional», она про F#, но даже если вы не хотите никогда писать на F#, я всё равно её рекомендую прочитать, потому что она здорово структурирована, там очень чётко изложены мысли, просто с точки зрения здравого смысла и того, что два плюс два равно четыре. То есть идеи можно и на C# переносить, но за одним исключением, чтобы не выглядеть как на том слайде про Exception’ы.
И последняя, может быть, неочевидная книга — это «Entity Framework Core In Action». Я её здесь разместил не потому, что она про Entity Framework, а потому что там есть целый раздел про то, как использовать всякие варианты DDD с ORM, то есть то, где нам ORM начинает мешать в плане реализации DDD и как это обходить.
Минутка рекламы. 15-16 мая 2019 состоится .NET-конференция DotNext Piter, где я состою в программном комитете. Программу можно посмотреть по ссылке, там же на сайте можно приобрести билеты.
