Comments 90
Не, ну понятно, что "пых, традиционно — фу, питон — рулит", но всё же, без претензий на холивар, но в php начиная с 7.0+, имхо — лучшая на данный момент реализация типизации и почти что идеальный баланс из строгости уровня Java/C#/Haxe и гибкости языка уровня Ruby/Js. Единственный минус — это strict_types в 0 по-умолчанию.
Ну, лобзиком и дженерики можно запилить, например с помощью инвариантов и верифаев, как-нибудь так:
/** @Invariant("Generic::int($this->items)") */
class Set implements IteratorAggregate {}
// ...
/** @Verify("Generic::isInt($generic)") */
public function a(\Traversable $generic) {}https://wiki.php.net/rfc/generics — вот для них и rfc есть.
Ишь чего захотел! Может ещё интерфейсы в питон добавить?
Даже помимо вкусовщины могут быть неприятные сценарии. Пусть автор библиотеки пишет функцию, которая берёт на вход массив чисел и считает для него некие хитроумные показатели. А у меня есть класс DatapointWithNumberRepresentation, который умеет совершать математические операции с себе подобными (и вообще крякает как число), но помимо этого содержит оценку качества данных и при каждой операции запоминает, из каких данных был получен результат и насколько он, следовательно, сам надёжен. До введения строгого контроля типов я его спокойно везде подсовывал, библиотеки думали, что работают с числами, а я получал дополнительный функционал. А тут обновился не подумавши. Так вот, нагенерировал я своих датапойнтов, отдал в функцию, а там где-нибудь посередине промежуточный результат записывается исключительно во float. Функция либо крашится с криком «Я хотела float, а мне подсунули какую-то дрянь» и я с матами переписываю её с поддержкой моего типа, либо тихо преобразует результат во float, а я потом полдня разбираюсь, куда подевались мои драгоценные метаданные.
Может звучать несколько надуманно, но замените мой вымышленный класс на любой из нумпаевских числовых типов или сложный контейнер с кучей внутренней логики, который предоставляет интерфейс списка для простоты доступа к отдельным элементам. Вроде бы да, я сам дурак и должен был читать документацию, прежде чем пихать в функцию что ни попадя. Но если для всех библиотек, написанных до дня Х, и половины библиотек, написаных позже, это прокатывает, то таких дураков будет пол-сообщества.
Контроль типов — величайшее изобретение в разработке ПО
Вот Вы сейчас сделали больно все поклонникам языков с динамической типизацией, включая безтиповые. ;))
Вы смешиваете динамическую/статическую типизацию переменных/биндингов и слабую/сильную/строгую типизацию самих значений. Тот же python имеет динамическую сильную типизацию для, как минимум, части операций. Наличие TypeError на это кагбэ намекаэ.
А уж внезапный «TypeError» — вообще невообразимое счастье.
Есть и контрпримеры: rust (и ocaml из которого это туда приехало) позволяет делать rebind, тип биндинга меняется, но всё строго: в функцию, принимающую i32 вы, скажем, &str передать не сможете.
Да, вы правы. Проверки на основе системы типов у них проводятся на этапе компиляции, когда для динамической типизации характерна проверка во время исполнения.
У меня была стойкая ассоциация ребиндинг — динамическая система типов, очевидно, некорректная. Я не знаю языков с динамической типизацией, запрещающих ребиндинг (это бы было крайне неудобно), но это не означает, что этого не может быть. Равно и наоборот, популярные языки со статической типизацией обычно не разрешают ребиндинг, ocaml и, соответственно, rust здесь несколько выбиваются
Новогодний торт.
Top 10 Python libraries of 2016
https://tryolabs.com/blog/2016/12/20/top-10-python-libraries-of-2016/
-> пункт 2. Sanic + uvloop
Цитата:
«According to the Sanic author’s benchmark, uvloop could power this beast to handle more than 33k requests/s which is just insane (and faster than node.js). „
and faster than node.js
не нашёл по ссылке никаких подтверждений этому заявлению. На моей локальной машине sanic отрабатывает в 2 раза медленее чем аналогичный код для Node.js
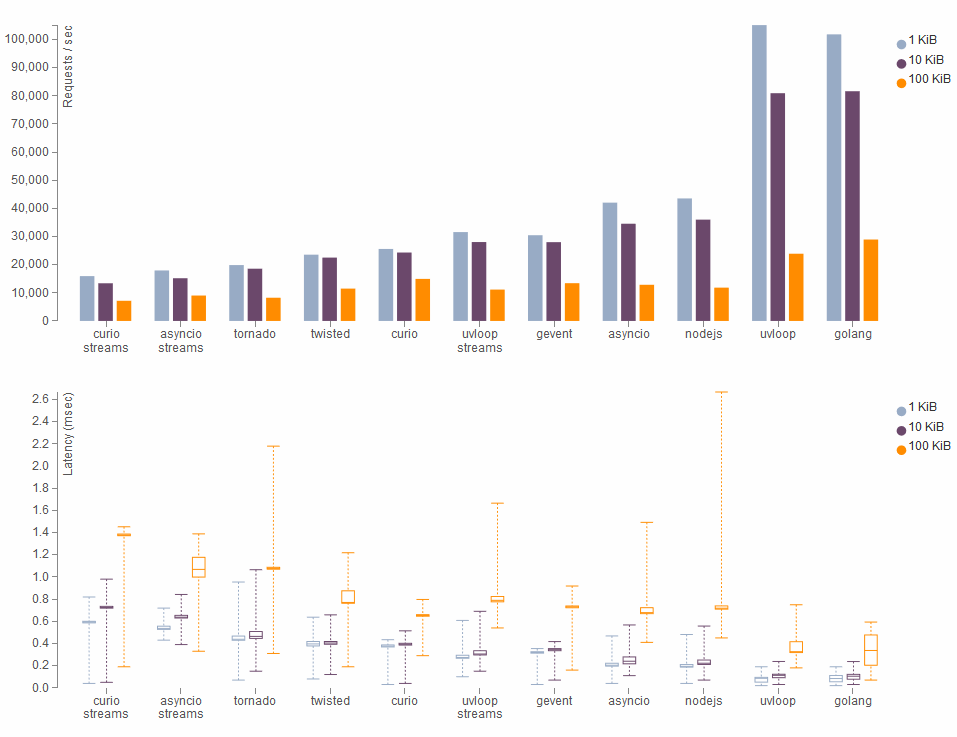

К сожалнию, первый бенчмарк мне не удалось повторить у себя, т.к. сервер uvloop не работает в текущей версии докер-контейнера, правила сборки которого лежат в гитхабе https://github.com/MagicStack/vmbench
TCP echo server (uvloop)
========================
Starting server...
docker run --rm -t -p 25000:25000 -e UID=0 -e GID=0 -v /tmp/vmbench/.cache:/var/lib/cache -v /tmp/vmbench/sockets:/tmp/sockets --name magicbench magic/benchmark vex bench python /usr/src/servers/asyncioecho.py --addr=0.0.0.0:25000 --proto --uvloop
Trying to connect to server at address 127.0.0.1:25000
Could not start server
----------------------
Traceback (most recent call last):
File "/usr/src/servers/asyncioecho.py", line 4, in <module>
import uvloop
File "/usr/local/python-venvs/bench/lib/python3.5/site-packages/uvloop/__init__.py", line 7, in <module>
from .loop import Loop as __BaseLoop, Future
File "uvloop/includes/stdlib.pxi", line 31, in init uvloop.loop (uvloop/loop.c:108082)
AttributeError: module 'asyncio.base_events' has no attribute '_check_resolved_address'Что касается второго бенчмарка, то он текстирует скорее реализацию библиотеки для работы с постгресом, чем скорость vm.
Смотря как готовить.
Во-первых не "уже может", а 15 лет уже как может с момента появления фреймворка Twisted (NodeJS еще и в помине не было).
Во-вторых, будет работать даже быстрее, но есть несколько "но".
Вот пример (мой личный бенчмарк на DigitalOcean):
ОС: Ubuntu 14.04
Результаты не с первого, а с 3-4 запуска. Тест банальным ab -n10000 -c100 http://127.0.0.1:8080/
NodeJS 6.9.1
Requests per second: 4286.70 [#/sec] (mean)
Requests per second: 4498.13 [#/sec] (mean)
Requests per second: 4377.65 [#/sec] (mean)
Requests per second: 4446.08 [#/sec] (mean)
Python 2.7.6
Requests per second: 1449.34 [#/sec] (mean)
Requests per second: 1290.49 [#/sec] (mean)
Requests per second: 1392.39 [#/sec] (mean)
Requests per second: 1381.58 [#/sec] (mean)
PyPy 5.4.1 (Python 2.7.10)
Первый запуск:
Requests per second: 1675.07 [#/sec] (mean)
Последующие запуски
Requests per second: 5051.65 [#/sec] (mean)
Requests per second: 4724.00 [#/sec] (mean)
Requests per second: 5120.28 [#/sec] (mean)
Requests per second: 5441.70 [#/sec] (mean)
Код JS:
var http = require('http');
function handleRequest(request, response){
response.end('Hello World!');
}
var server = http.createServer(handleRequest);
server.listen(8080, function(){
console.log("Server listening on: http://localhost:%s", 8080);
});Код на Python (Twisted)
from twisted.web import server, resource
from twisted.internet import reactor, endpoints
class Root(resource.Resource):
isLeaf = True
def render_GET(self, request):
return "Hello World!"
endpoints.serverFromString(reactor, "tcp:8080").listen(server.Site(Root()))
print "Server listening on: http://127.0.0.1:8080/"
reactor.run()И вот здесь начинаются всевозможные "но":
- Тестируется производительность только HTTP сервера
- Используется фреймворк Twisted — кто юзал, знает что это не самый быстрый и легковесный способ гонять такие тесты на Python
- Как видно из теста, Python напрямую не может конкурировать с NodeJS, поскольку тут нет JIT-компиляции. Поэтому сравнивать надо определенно с PyPy (кастомный интерпретатор Python с JIT-компиляцией)
- Видно что PyPy уделывает NodeJS в тесте. Другая сторона медали — инстанс NodeJS при множественном прогоне разрастается почти до 50Mb памяти (значение RSS), а PyPy до 100Mb при тех же условиях
- PyPy не совсем production-ready (может крашиться при определенных настройках)
- В тесте не используется Python 3.6 (т.е. к теме статьи не относится, просто решил ответить на Ваш вопрос)
- Для Python есть огромное количество реализаций event-loop'ов и всяких асинхронных вкусностей. К примеру реализация HTTP-сервера на C: FAPWS. С этим веб-сервером даже стандартный интерпретатор Python уделывает и NodeJS и PyPy (over 9000 RPS).
В общем и целом жить можно, но NodeJS все-таки занимает свою нишу и иногда удобнее взять его
Теперь проблем не будет.
Вы зря про новую реализацию словаря не написали — там на мой взгляд сделали очень интересную штуку.
А что конкретно там сделали крутого? Видел в аннотации к релизу, что уменьшили потребление памяти на 20%
А еще order-preserving aspect на который мы should not be relied upon ;)
Вообще там всё довольно странно с порядком.
I'd like to handwave on the ordering of all other dicts. Yes, in
CPython 3.6 and in PyPy they are all ordered, but it's an
implementation detail. I don't want to force all other
implementations to follow suit. I also don't want too many people
start depending on this, since their code will break in 3.5.
Я имел ввиду, что странно такое половинчатое решение, когда в двух доминирующих реализациях словари по факту будут упорядоченными, но стандарт этого не будет гарантировать. И не совсем понятно, как на это должен реагировать разработчик: затачиваться на реализацию или продолжать допускать неупорядоченность.
Так в питоне 3.6 **kawrgs, в отличие от остальных dict, должны быть гарантированно упорядочены. см. https://www.python.org/dev/peps/pep-0468/
Это совсем не то же самое: упорядоченность — это «особенность реализации», а не «экспериментальный функционал». Если бы это был «экспериментальный функционал», то говорили бы о возможности включения упорядоченности в спецификацию в будущем (если эксперимент покажет себя хорошо). Но говорят обратное — упорядоченность могут выпилить.
В том, что официально это «деталь реализации». Назвать «экспериментальным функционалом» могут разработчики, а никак не вы. И я бы не назвал будущее включение таким уж очевидным — во‐первых, далеко не во всех программах на упорядоченность словаря есть что завязывать, так что ущерб будет меньше, чем вы, возможно, думаете. Во‐вторых, авторы Python не слишком боятся принимать непопулярные решения.
В частности, «экспериментальность» предполагает, что разработчики проводят какой‐то эксперимент. Но упорядоченность возникла не вследствие проведения какого‐то эксперимента, а вследствие желания оптимизировать одну из наиболее часто используемых структур данных.
И тут лично вы, запрещаете что-либо называть уткой лично мне, на том основании, что с вашей точки зрения я не отношусь к некоторой группе лиц. Я вообще считал что называть вещи своими именами может любой, руководствуясь Здравым Смыслом (с), а не какой либо формой сегрегации. Что забавно, по вашей логике вы также не можете это называть НЕ экспериментальным функционалом по тем же самым причинам.
В Питоне вы не можете провести черту и выделить где то его спецификацию в отрыве от референсной реализации — в ней нет потребности, и по этому как отдельная сущность она отсутствует.
Картинка в тему:

Я называю это «не экспериментальным функционалом», потому что указанная группа лиц не называет рассматриваемый функционал экспериментальным. Этого более чем достаточно. Словосочетание «экспериментальный функционал» имеет конкретный смысл. Вы не можете ставить и контролировать эксперименты над пользователями Python — значит, вы не можете назвать функционал экспериментальным. Здесь нет ничего, что бы крякало как утка и не появится, пока авторы явно не поставят эксперимент (хотя бы просто объявив «мы не приняли решение, следует ли сохранять упорядоченность в будущем, ждём отзывов» — за маркировкой «экспериментальный функционал» редко скрываются эксперименты по всем правилам проведения научных экспериментов).
Вы не называете вещи «своими именами». Вы пытаетесь присвоить себе полномочия, которыми не обладаете. Сделайте свой форк и называйте любой функционал в нём экспериментальным, если хотите; только это не сделает что‐то экспериментальным в upstream. Ни за что не поверю, что концепция «чтобы назвать X Y (к примеру, ГОСТом) нужно обладать полномочиями Z (к примеру, Межгосударственного совета по стандартизации, метрологии и сертификации)» для вас нова.
Подход «любое изменение по сути своей эксперимент» делает термин «экспериментальный функционал» относящимся к любому изменению. Т.е. «экспериментальный функционал» становится синонимом «изменение функционала», что делает термин абсолютно бесполезным — зачем обзывать вносимые изменения странным длинным термином, если их можно просто продолжать называть их изменениями?
Мне уже просто интересно, насколько огромная чушь должна последовать из это цепочки, что бы вы признали весьма очевидны факт, что argumentum ad hominem было неправильно.
Вы передёргиваете. Функционал не экспериментален «по умолчанию», иначе практически ничем нельзя было бы пользоваться во многих проектах, где нужна гарантируемая авторами стабильность. Полномочия нужны только для определённых статусов, и «прекрасный» в них не входит, в отличие от «экспериментального».
В словарях, конечно. Я требую полномочий по определению «экспериментальный» (на dic.academic.ru почему‐то есть только единственное определение «основывающийся на опыте», хотя все три значения ниже можно найти и в русских текстах; где выкопать более адекватный русский толковый словарь я не знаю):
(в отношении нового изобретения или продукта) Основанный на непроверенных идеях или технических приёмах и ещё неналажённый или незавершённый.
- Относящийся к научным экспериментам.
- (в отношении исскуства или художественного приёма) Использующий радикально новый, передовой стиль.
- (устаревшее) Основывающийся на опыте, в отличие от авторитета или предположения.
Третье значение, очевидно, не имеет никакого отношения к «экспериментальному функционалу». Второе не имеет отношения, потому что, во‐первых, речь идёт не об искусстве или художественном приёме. Впрочем, авторы могут заявить, что они относятся к программированию как к искусству (и я не знаю, заявлял ли кто‐либо из них, что он считает свой вклад в CPython произведением искусства), поэтому, во‐вторых, ничего радикально нового и передового в упорядоченных словарях нет.
Первое значение — это именно то, как слово «экспериментальный» воспринимается мной в словосочетании «экспериментальный функционал» и здесь для вас тоже «всё плохо»:
0. К научным экспериментам рассматриваемые упорядоченные словари не относятся точно.
1. Технический приём, сделавший словари упорядоченными «проверялся» в PyPy. В принципе, эту часть можно оспорить и не будучи автором, но там стоит «и», а второе:
2. Авторы CPython включили упорядоченные словари в релиз без соответствующей пометки, тем самым объявив, что они налажены и завершены. Здесь вы либо доверяете компетенции авторов CPython, соглашаясь с их полномочиями объявлять функционал (не) экспериментальным — (не) налаженным или (не) завершённым. Либо одновременно заявляете «я считаю, что объявившие функционал налаженным и завершённым авторы некомпетентны» и «функционал экспериментальный». В последнем случае вам уже не нужно относится к авторам CPython, но это совершенно другое заявление, закономерно вызывающее сомнения в вашей компетенции либо требующее обоснования — примеров действий команды разработчиков CPython, в которых они показали свою некомпетентность.
Помимо этого есть почему‐то отсутствующее в oxforddictonaries значение «сделанный, чтобы посмотреть как что‐то работает» (к примеру, отсюда) — второй вариант восприятия «экспериментальный функционал», — но в этом случае у вас тоже нет возможности взять и назвать функционал экспериментальным — только авторы могут сказать, зачем они его вносили.
PS. Понятие «прекрасный» по сути субъективно, поэтому вы всегда можете назвать что‐то прекрасным, я могу назвать что‐то уродливым, и мы оба будем правы.
Я: Это экспериментальный функционал
Вы: Это ваше личное субъективное оценочное суждение.
Я: Да, конечно.
При таком развитии событий возникают какие либо проблемы с принадлежностью к группам лиц, правами на высказывания, или чем то подобным?
Заявление о прекрасности просто показывает мнение автора. Заявление об экспериментальности запрещает пользоваться функционалом в проектах, где важна стабильность используемых инструментов. Именно поэтому такое сопротивление, и именно поэтому нужны либо полномочия, либо авторитет.
Относительно проблем: как я сказал выше, если вы хотите без полномочий объявить нечто «экспериментальным функционалом», будьте готовы, что это воспримут как высказанное вами сомнение в компетентности авторов CPython. То есть вы оскорбляете авторов CPython, которых я лично уважаю. При этом, судя по первому сообщению вы просто неправильно воспринимаете термин «экспериментальный функционал», а не оскорбляете кого‐то. Если это не так, то, пожалуйста, объясните, каким образом упорядоченность словаря является экспериментальной, используя любое из определений слова «экспериментальный» выше.
И уточнение — термин «прекрасный» является субъективным. Термин «экспериментальный» (кроме второго значение, которое к коду не относится) — нет: четвёртое (которое отсутствующее в oxforddictionaries) значение основывается на заявлениях авторов (существование которых объективно; заявлениях — т.к. мы не можем влезть им в голову и узнать, зачем они делали упорядоченность), первое значение также объективно, поскольку объективно существование функционала в других проектах (здесь PyPy, я про «непроверенность»), количество существующих ошибок (я про «неналаженность») и наличие/отсутствие заявлений о завершённости. Субъективно лишь доверие к тем, кто может (не) объявлять код незавершённым или созданным для проверки идеи.
То что вы делаете странные и пространные умопостроения, которые от слов «экспериментальный функционал» выводят оскорбления сообществ — то это тоже ваши личные умозаключения и не нужно их мне приписывать. Вы можете из этого хоть призывы к свержению власти выводить — все будет лишь плод ваших фантазий.
Вы удивитесь, но заявления авторов объективными не являются по определению(хотя само существование этих заявлений можно принимать объективным). Если вы откроете википедию, от обнаружите следующее определение субъективности:
«Субъекти́вность — это выражение представлений человека (мыслящего субъекта) об окружающем мире, его точки зрения, чувства, убеждения и желания»
Другими словами любые высказывания, будь то мои, ваши, или разработчиков питона являются субъективными, поскольку так или иначе являются представлением мыслящих субъектов о положении вещей.
Количество ошибок можно с натягом считать объективным, а вот налаженность нет, по скольку это уже субъективная оценка, которая зависит от неких, принятых мыслящими субъектами критериев. Тоже самое касается «проверенности» и «завершенности». С последним, кстати говоря интересно сочетается призыв авторов не полагаться на особенности текущей реализации. Каким образом, основываясь на куче субъективных вещей, вы хотите вывести нечто «объективное» и еще впихнуть в мое личное мнение, не потеряв этого качества, мне лично не понятно.
Я не утверждал, что заявления авторов объективны, я утверждал, что объективно их (не) существование. Выбор критериев субъективен, но не оценка на их основе, при условии, что выбраны объективные критерии. Впрочем, с субъективностью первого (но не четвёртого) значения экспериментальный я вынужден согласится, поскольку не имею способов настоять (глобально) на определённых критериях, а соглашения только в рамках данной дискуссии не достаточно.
А оскорбление есть, поскольку что неналаженный, что незавершённый, что непроверенный функционал в стабильном релизе без пометок говорит о некомпетентности авторов. Независимо от того, считаете ли вы налаженность, завершённость или проверенность объективными или субъективными свойствами. Хотя обсуждать наличие либо отсутствие оскорбления бесперспективно, т.к. само наличие субъективно — в пред‐предыдущем комментарии я прямо говорил, что считаю, что вы оскорбили авторов CPython и одновременно, что не считаю, что вы их намеренно оскорбляли.
И вы так и не ответили, как с вашей точки зрения упорядоченность словарей соотносится со значением слова «экспериментальный».
А ещё для меня странный выглядит это нововведение в свете того, что в том же Perl c 5.18 наоборот сделали более строгую рандомизацию словарей.
Более строгая рандомизация хешей
Отдельное внимание было уделено проблеме. известной как Hash Collision Complexity Attack. Несмотря на то, что возможность данной атаки была сведена к нулю начиная с perl 5.8.1 (25-е сентября 2003-го), разработчики пошли дальше (возможно, в связи с недавними событиями вокруг некоторых известных языков, применяемых в веб-разработке) и усовершенствовали механизм рандомизации хешей. Теперь порядок вывода одного и того же хеша отличается от запуска к запуску. Помимо этого каждый хеш имеет свой собственный порядок итерирования, поэтому порядок вывода двух хешей с одинаковыми значениями может отличаться. Также был добавлен ряд новых хеширующих функций, а выбрать конкретную можно на этапе компиляции интерпретатора perl.
Если кратко: оптимизировали потребление памяти хэш-таблицей, которая лежит в основе словаря и множества. А поскольку в Питоне очень много завязано на словари (как минимум, импорт, объектная система и еще масса всего), то я ожидаю, что общее потребление памяти будет на, условно, 10-15% меньше (конечно, будет зависеть от того, как и какая программа написана). И, кроме того, поскольку теперь больше вероятность, что хэш-таблица окажется целиком в кэше процессора, а это может сильно помочь быстродействию.
По скорости: статья от Pypy: https://morepypy.blogspot.com.by/2015/01/faster-more-memory-efficient-and-more.html (еще не разобрался полностью, но вроде эти идеи использовали для и Python 3.6)
По использованию словарей внутри языка был доклад Кирилла Лашкевича, видео тут: https://habrahabr.ru/company/wargaming/blog/195382/
Так что PyPy делается не зря, как многим кажется.
В качестве примера разработчики приводят такой фрагмент:
>>> name = «Fred»
Хм, в официальном what's new приводят вот это
>>> name = "Fred"
А то что вы привели даже не запустится.
Специфика хабровской разметки
Специфика кривых рук, не более. Написал час назад об этом автору, но так как это пост от компании, то скорее всего это контент-менеджер, у которого сегодня выходной, так что на это забьют.
Для меня загадка, как можно насколько не иметь глаз и не любить то, что ты делаешь, чтобы фигачить как придется и даже не смотреть что получилось.
PEP 528 and PEP 529, Windows filesystem and console encoding changed to UTF-8.
Возможно ли в Питоне/PyCharm'e сделать подсказку по переменным?
Поясню.
Есть у нас, к примеру, vaqriable_with_very_long_name
Пара таких в выражении — и читать код становится трудно.
Если же задать имя вида v_w_v_l_n то впоследствии бывает сложно вспомнить что это обозначает.
Возможно ли создание неких __doc__ для переменных — как это в реализовано в виде докстрингов при описании функций/классов — которые при наведении мышки показывали бы подсказку?
Может это реализовано в PyCharm?
Sphinx вполне понимает, когда вы пишете
foo = None
'''Foo variable is FUBAR'''Про PyCharm не скажу, но в IPython эти данные, вроде бы, достать не получится — как __doc__ они не сохраняются, sphinx просто выдирает что ему нужно из AST. Ну, или я чего‐то не знаю.
Ещё у sphinx есть вариант в виде использования специальных комментариев, но я всё время использую именно такие псевдо‐«docstrings» (псевдо‐ — потому что в __doc__ не сохраняются). Т.к. не использую PyCharm, то не скажу, понимает ли он какую‐либо из этих возможностей sphinx.
Релиз Python 3.6 — да, теперь он с нами