
Полгода назад я уже начинал рассказывать об обновлении линейки СХД компании Huawei – Dorado V6. На самом деле, мне удалось познакомиться с ними еще до официального анонса, и логично, что тогда у меня не было возможности потрогать их в работе собственными руками. В своей статье «Huawei Dorado V6: Сычуаньская жара» я делал упор на старшие модели Dorado 8000 и 18000 V6, так как с точки зрения архитектуры они в тот момент меня больше всего заинтересовали. Наконец у меня появилась возможность провести тестирование системы 5000V6 в нашей лаборатории и подробнее рассказать о технической стороне этих систем.
С одной стороны, это обзор и тестирование системы 5000V6, с другой — логическое продолжение предыдущей статьи, т.к. за прошедшие полгода появилось больше подробностей о различных компонентах системы, логике работы и реализованном функционале.
Но перейдем сразу к делу. Поскольку эта система является более привычной — двухконтроллерной системой, она лишилась и некоторых преимуществ своих старших сестер.
- Отсутствие shared Frontend и Backend.

- Также в системах 5000V6 и 6000V6 установлено всего два процессора Kunpeng 920 на каждый из контроллеров, а в 3000V6 – один.
- Если для 5000V6 и 6000V6 поставляются те же полки, что и для 8000V6 и 18000V6 с чипами Kunpeng, которые призваны ускорить процесс ребилда, и эти полки подключаются по 100Gb RDMA, то для младшей модели 3000V6 доступны только SAS полки.

- 5000V6 и 6000V6 рассчитаны на установку 36 PALM SSD или 25 x 2.5» «обычных» SAS SSD (выбирается при конфигурировании системы при заказе), то младшая 3000V6 поддерживает только 25 SAS SSD.
- 3000V6 поддерживает установку до трех hot-swappable интерфейсных карт на контроллер, 5000V6 и 6000V6 поддерживают шесть карточек.


Как и в предыдущей статье, есть сноска, относительно End-to-End NVMe: на сегодняшний день планируется в скором времени поддержка NVMe over RoCE v2 и NVMe over TCP/IP.
Архитектурно двухконтроллерные системы, естественно, тоже отличаются.

OceanStor Dorado V6 использует active-active архитектуру, в которой есть следующие технологии.
- Алгоритм балансировки нагрузки: балансирует запросы на чтение и запись, полученные каждым контроллером.
- Глобальный кеш: позволяет, чтобы LUN не имели владельцев. Каждый контроллер обрабатывает полученные запросы на чтение и запись, обеспечивая балансировку нагрузки между контроллерами.
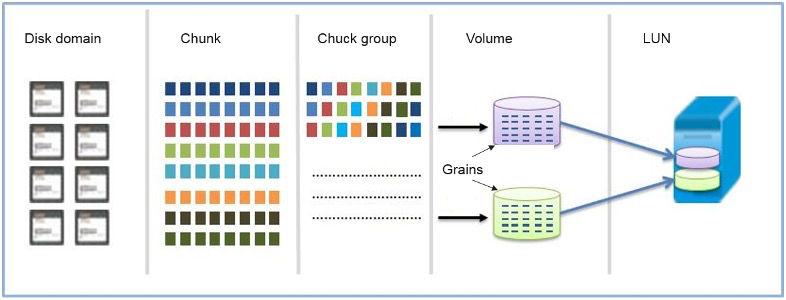
- RAID 2.0+: равномерно распределяет данные по всем дискам в пуле хранения, балансируя нагрузку на диск.
RAID 2.0+
Если данные неравномерно хранятся на SSD, некоторые сильно загруженные SSD могут стать узким местом системы. OceanStor Dorado V6 использует RAID 2.0+ для равномерного распределения данные по всем LUN на каждом SSD, балансируя нагрузку между накопителями. OceanStor Dorado V6 реализует RAID 2.0+ следующим образом:
- несколько SSD образуют пул хранения
- каждый SSD разделен на чанки фиксированного размера (обычно 4 МБ на чанк) для упрощения управления логическим пространством
- чанки из разных SSD образуют чанковую группу на основе настроенной пользователем политики RAID
- чанковая группа делится на «зерна» (обычно 8 КБ), которые являются наименьшей единицей для объемов
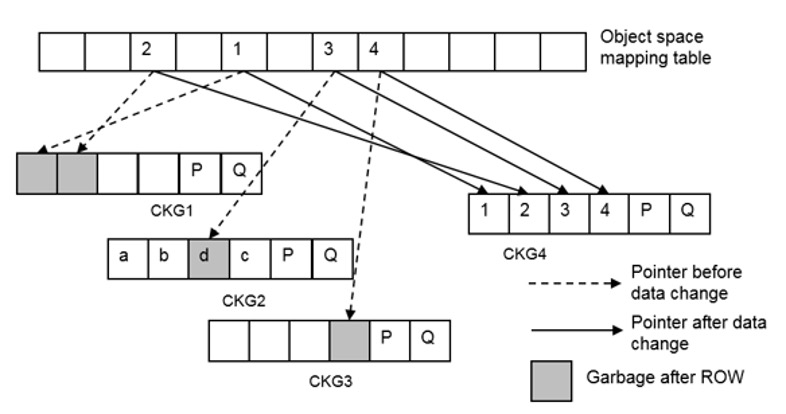
ROW Full-Stripe Write
Микросхемы флэш-памяти на SSD могут стираться ограниченное количество раз. В традиционном режиме перезаписи RAID (запись на место) горячие данные на твердотельном накопителе непрерывно перезаписываются, и его флэш-чипы быстро изнашиваются. OceanStor Dorado V6 использует запись с полной полосой перенаправления при записи (ROW) как для новых, так и для старых данных. Он выделяет новую флеш-микросхему для каждой записи, балансируя количество раз стирания всех флеш-микросхем. Это значительно снижает нагрузку на процессор самого контроллера и нагрузку чтения/записи на SSD в процессе записи, повышая производительность системы на различных уровнях RAID.
End-to-End I/O приоритезация
Чтобы обеспечить стабильную задержку для определенных типов I/O, контроллеры OceanStor Dorado V6 маркируют каждую операцию I/O с приоритетом в соответствии с его типом. Это позволяет системе планировать ЦП и другие ресурсы и расставлять их по приоритетам, предлагая гарантию задержки на основе приоритетов ввода-вывода. В частности, после приема нескольких I/O твердотельные накопители проверяют свои приоритеты и обрабатывают в первую очередь операции с более высоким приоритетом.
OceanStor Dorado V6 классифицирует операции ввода-вывода на следующие пять типов и назначает их приоритеты в порядке убывания, обеспечивая оптимальный внутренний и внешний отклик ввода-вывода:
- операции чтения/записи
- расширенные функции I/O
- ребилд
- сброс кэша
- Garbage collection

На каждом диске в дополнение к назначению приоритетов для операций ввода-вывода OceanStor Dorado V6 также позволяет высокоприоритетным запросам на чтение прерывать текущие операции записи и стирания. В этом случае задержка чтения диска (если данных не оказалось в кэше) напрямую влияет на задержку чтения хоста. Как правило, на флэш-носителе SSD выполняются три операции: чтение, запись и стирание. Задержка стирания составляет от 5 мс до 15 мс, задержка записи – от 2 мс до 4 мс, а задержка чтения – от десятков мкс до 100 мкс. Когда флэш-чип выполняет операцию записи или стирания, операция чтения должна ждать, пока текущая операция не будет завершена, что приводит к значительному увеличению задержки чтения.
Smart Disk Enclosure
Как я уже писал в предыдущей статье, новые дисковые полки оснащаются собственным процессором и оперативной памятью. Это позволяет перенести такие задачи, как восстановление после сбоя диска, с контроллеров. Это значительно снижает нагрузку на контроллеры в случае восстановления данных из-за сбоев диска. На следующем рисунке показан процесс восстановления данных в рамках одной дисковой полки с использованием RAID 6 (21 + 2) в качестве примера. Если диск D1 неисправен, контроллер должен прочитать D2-D21 и P, а затем пересчитать D1. Всего с дисков должен быть прочитан 21 блок данных. Операции чтения и восстановления данных потребляют большие ресурсы процессора.
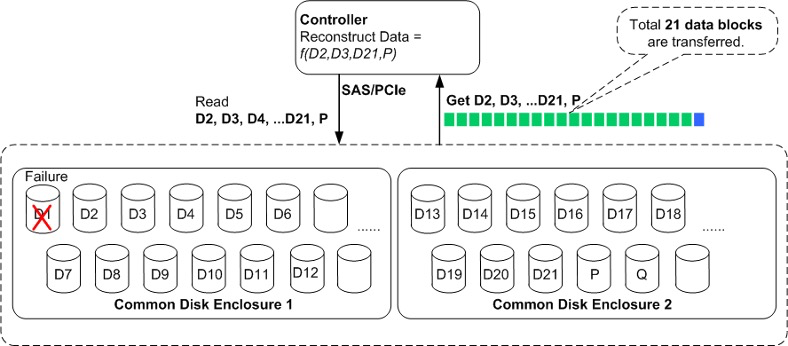
Полка Smart Disk Enclosure получает запрос на восстановление и считывает данные для локального вычисления данных о чётности. Затем ей нужно только передать данные контроля чётности в контроллер. На следующем рисунке видно, что между контроллером и дисковой полкой необходимо передать только четыре блока данных о четности. Это позволяет сохранить производительность операций восстановления, уменьшив пропускную способность сети в пять раз.
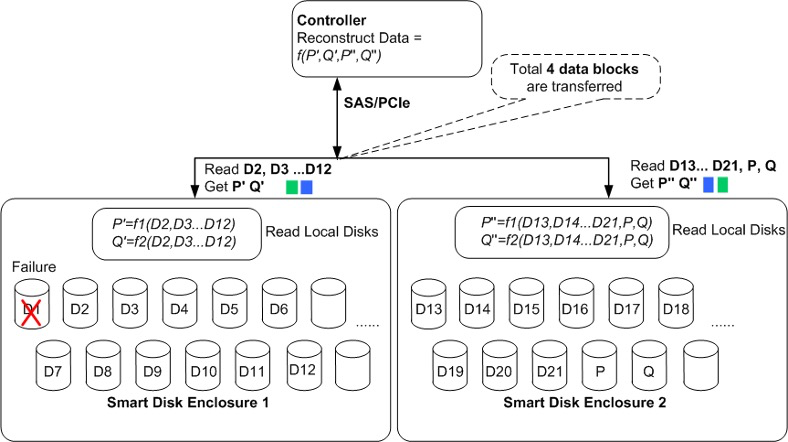
В итоге, перенося данную нагрузку на процессоры в полке, удаётся снизить нагрузку на контроллеры от задачи ребилда до менее 10%.
SmartDedupe и SmartCompression
OceanStor Dorado V6 автоматически выполняет адаптивную дедупликацию и сжатие на основе характеристик пользовательских данных, максимизируя коэффициент эффективности. Адаптивный процесс дедупликации и сжатия выглядит следующим образом.
- Когда записываются пользовательские данные, адаптивный модуль идентифицирует данные, которые с высокой вероятностью могут быть дедуплицированы в режиме онлайн на основе типов данных. Затем модуль выполняет встроенную дедупликацию, которая поддерживает только дедупликацию фиксированной длины. Данные сжимаются после встроенной дедупликации и затем сохраняются в пуле хранения.
- Если встроенная дедупликация не может быть выполнена с высокой вероятностью, система вычисляет «аналогичный» отпечаток (SFP) данных и вставляет его в таблицу «возможностей». Затем система сжимает пользовательские данные, записывает сжатые данные в пул хранения и возвращает сообщение об успешной записи.
- Когда несколько идентичных SFP в таблице «возможностей» накапливаются, данные, соответствующие этим SFP, считываются с дисков для дедупликации после обработки. После завершения дедупликации таблица отпечатков обновляется.
Перед сжатием данных OceanStor Dorado V6 использует собственный алгоритм предварительной обработки для определения части, которую сложно сжать в блоках данных, на основе формата данных.
OceanStor переупорядочивает данные, разделяя их на две части:
- для части, которую трудно сжать, система сжимает ее, используя специально разработанный Huawei алгоритм сжатия
- для другой части система использует общий алгоритм сжатия
Некоторые производители СХД уже используют data compaction в своём арсенале. Но обычно используют блок 4K или 1K для уплотнения данных. Компания Huawei пошла дальше и использует побайтовое выравнивание. Думаю, иллюстрация наглядна.
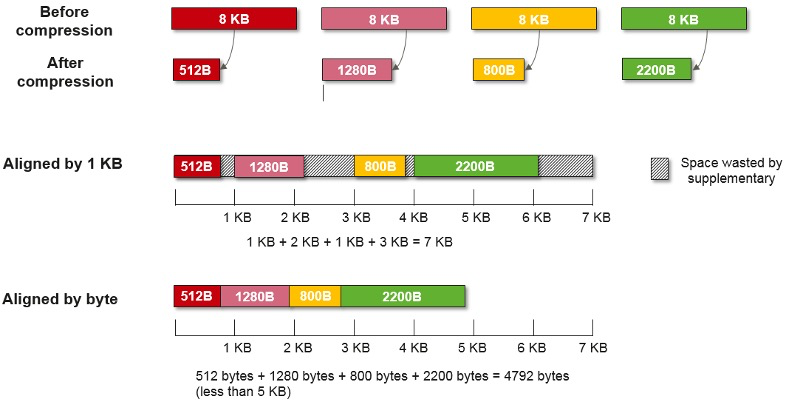
Таким образом, 32KB пользовательских данных мы уместили менее чем в 5KB.
Компрессия и дедупликация работают теперь всегда с момента, как вы установите соответствующую лицензию Storage Efficency. Её нельзя отключить из Device Mabager, но если очень сильно хочется, это можно сделать через CLI. По логике вендора, на SSD технологии экономии места должны работать всегда.
Один важный момент по всей линейке. Хотя моделей всего пять, они помимо прочего отличаются между собой объёмом кэша каждого контроллера:
- OceanStor Dorado 3000 V6: 192 GB
- OceanStor Dorado 5000 V6: 256 GB/512 GB
- OceanStor Dorado 6000 V6: 1024 GB
- OceanStor Dorado 8000 V6: 512 GB/1024 GB/2048 GB
- OceanStor Dorado 18000 V6: 512 GB/1024 GB/2048 GB
Как можно заметить, общий объём у старших моделей не меняется, но меняется количество накопителей. По заявлениям инженеров Huawei, у них просто не было возможности проверить системы на большем объёме, чем 2Пб. Теоретически они поддерживают и больше.
Максимальное количество дисков/максимальный объем:
- OceanStor Dorado 3000 V6 – 1000/500TiB
- OceanStor Dorado 5000 V6 – 1200/1024TiB
- OceanStor Dorado 6000 V6 – 1500/2048TiB
- OceanStor Dorado 8000 V6 – 3200/2048TiB
- OceanStor Dorado 18000 V6 – 6400/2048TiB
В прошлой статье я забыл упомянуть о том, какие интерфейсные карты вообще имеются:

Я уже говорил (и в предыдущей статье, и в этой), что в качестве накопителей компания Huawei предлагает SSD собственной разработки – Palm Size, или, как они сами их называют, Huawei-developed SSDs (HSSD).
Помимо того, что компания считает их разработку более быстрой, она предлагает и некоторые ключевые особенности.
- Выравнивание износа
Контроллер SSD использует программные алгоритмы для контроля и балансировки циклов чтения/записи для блоков во флэш-памяти NAND. Это предотвращает выход из строя чрезмерно используемых блоков и увеличивает срок службы флэш-памяти NAND.
HSSD поддерживают динамическое и статическое выравнивание износа. Динамическое выравнивание износа позволяет SSD записывать данные преимущественно в менее изношенные блоки, чтобы сбалансировать циклы чтения/записи. Статическое выравнивание износа позволяет SSD периодически обнаруживать блоки с меньшим количеством циклов чтения/ записи и восстанавливать их данные, гарантируя, что блоки, хранящие холодные данные, могут участвовать в выравнивании износа. - Управление повреждёнными блоками (Bad Block)
Повреждённые блоки могут возникать при изготовлении или использовании флэш-памяти NAND. HSSD идентифицируют поврежденные блоки в соответствии с циклами чтения/записи, типом ошибки и частотой ошибок флэш-памяти NAND. Если существует неисправный блок, SSD восстанавливает данные с использованием данных четности (XOR) и сохраняет их в новом блоке. HSSD имеют зарезервированное пространство для замены поврежденных блоков, обеспечивая достаточную доступную ёмкость и безопасность пользовательских данных. - Фоновая проверка
После длительного хранения данных во флэш-памяти NAND могут возникнуть ошибки данных из-за помех чтения, помех записи или случайных сбоев. HSSD периодически считывают данные с флэш-памяти NAND, проверяют изменения битов и записывают данные с изменениями битов на новые страницы. Этот процесс заранее обнаруживает и обрабатывает риски, что эффективно предотвращает потерю данных и повышает безопасность и надежность данных.
Итак, перейдём непосредственно к тестам. Мы тестировали обе вариации контроллеров 5000V6, как с 256 GB, так и 512 GB кэша.
Первый тест был, так сказать, разогревочный.
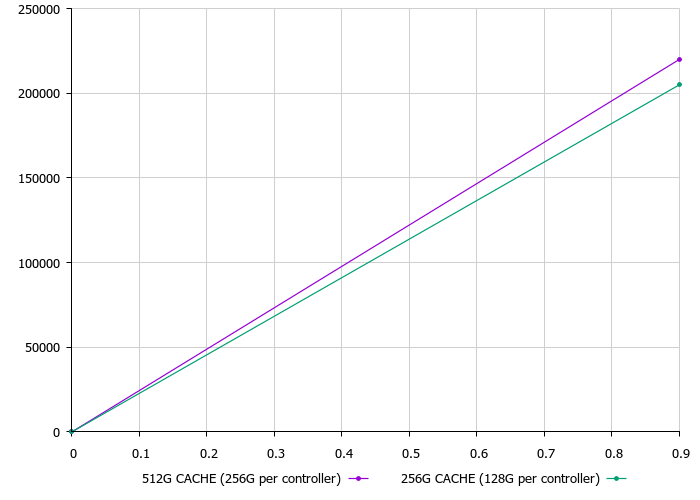
Как мы видим, на данном профиле нагрузки 8k 50r/50rw разница составила порядка 7% (220 kIOPs против 205 kIOPs) и сказалась только на итоговом количество IOPS, а время отклика оставалось на том же уровне – 0.9 ms.
Кстати, было очень просто определить, что мы стали упираться в контроллер, система сама сообщила о высокой утилизации процессоров контроллеров.

Второй тест, который мы используем для всех систем на SSD, – для их оценки и сравнения более сложным профилем.
Профиль
[global]
direct=1
thread=1
iodepth=16
filename=/dev/sdb
ioengine=libaio
runtime=3600000
group_reptorting
time_based
[8r]
rw=randread
numjobs=24
bs=8k
[8w]
rw=randwrite
numjobs=24
bs=8k
[32r]
rw=randread
bs=32k
numjobs=1
[32w]
rw=randwrite
numjobs=1
bs=32k
[128r]
rw=read
bs=128k
numjobs=1
[128w]
rw=write
bs=128k
numjobs=1
[512r]
rw=read
bs=512k
numjobs=1
[512w]
rw=write
bs=512k
numjobs=1
direct=1
thread=1
iodepth=16
filename=/dev/sdb
ioengine=libaio
runtime=3600000
group_reptorting
time_based
[8r]
rw=randread
numjobs=24
bs=8k
[8w]
rw=randwrite
numjobs=24
bs=8k
[32r]
rw=randread
bs=32k
numjobs=1
[32w]
rw=randwrite
numjobs=1
bs=32k
[128r]
rw=read
bs=128k
numjobs=1
[128w]
rw=write
bs=128k
numjobs=1
[512r]
rw=read
bs=512k
numjobs=1
[512w]
rw=write
bs=512k
numjobs=1

Здесь картина уже совсем иная. Если разница в количестве IOPS в две тысячи (172 kIOPs против 170 kIOPs) совсем не существенна, то возросшая в пять раз задержка (с 0.4 ms до 2,1 ms), говорит нам о том, что при работе с большим блоком большее количество кэша даёт преимущество системе.
В прошлом году мы с коллегами уже проводили тестирование Huawei Dorado 5000 V3, так что теперь мы можем сравнить между собой эти две системы.
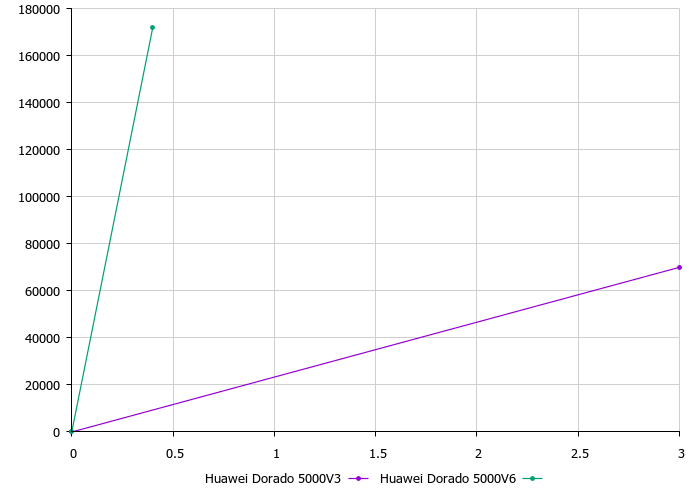
Прогресс на лицо. Профиль нагрузки и методика тестирования в обоих случаях использовались одни и те же.
Конечно, было бы хорошо провести ещё и сравнение с конкурентами, лично у меня очень чесались руки сравнить с NetApp AFF A400, Full NVMe системой, которая появилась не так давно. К сожалению, в нашей тестовой лаборатории она ещё не побывала, а сравнивать с AFF A300 не совсем логично, даже несмотря на то, что предыдущая модель Dorado 5000 V3 компанией Huawei позиционировалась как её конкурент.
На дворе XXI век, многие компании предлагают различные программы для увеличения привлекательности их систем. Компания Huawei решила не отставать и в этом направлении.
Effective Capacity Guarantee
Приобретая новые системы хранения линейки V6, вы можете смело полагаться на эффективное хранение данных при помощи компрессии и дедупликации. В целом, многие вендоры на рынке уже предлагают подобные программы, которые за счёт более эффективного хранения позволяют гарантированно хранить больше данных на приобретаемом полезном объёме системы хранения данных.
Стоимость каждого терабайта SSD по-прежнему остаётся довольно высокой, поэтому технологии сжатия и дедупликации крайне полезны, и на многих типах данных они показывают высокую эффективность. Если ваши данные являются видео, аудио, изображениями, научными данными, PDF, XML или зашифрованными данными, то дедупликация не будет эффективна, в ином случае гарантия работает. Даже если вы приобрели систему с максимальным количеством установленных накопителей, то вместе с накопителями по программе вы получите ещё и полку расширения.
FlashEver
Если вместе с массивом вы приобретаете программу Huawei Hi-Care Onsite или Co-Care или выше, то вы можете рассчитывать на бесплатное обновление контроллеров до новых моделей той же линейки. Это позволяет иметь наиболее современную и производительную систему без необходимости покупки новых систем или миграции данных. Процесс замены контроллеров происходит также без прерывания сервиса.
Если вы любитель интерфейсов и хотите посмотреть на обновлённый Device Manager, то на портале Huawei уже доступен OceanStor Dorado 18000 V6 6.0.0 DeviceManager.
К сожалению, данная система была у нас на тестах всего пару дней, так что мы успели провести только замеры производительности. Но ещё хотелось бы провести функциональные тесты, наши любимые тесты на отказ и проверить некоторые нарекания по производительности, которые были к предыдущей линейке V3 при выполнении некоторых операций – важно понять, какие изменения в новой линейке (и, соответственно, в ПО) там произошли и какой эффект они принесли.
Хочу отметить, что большинство тестов, которые я провожу для своих статей, являются командной работой. Выражаю огромную благодарность моим коллегам из группы интеграции компании «Онланта», с которыми я работаю.
Кстати, в нашу команду мы ищем системного архитектора.
