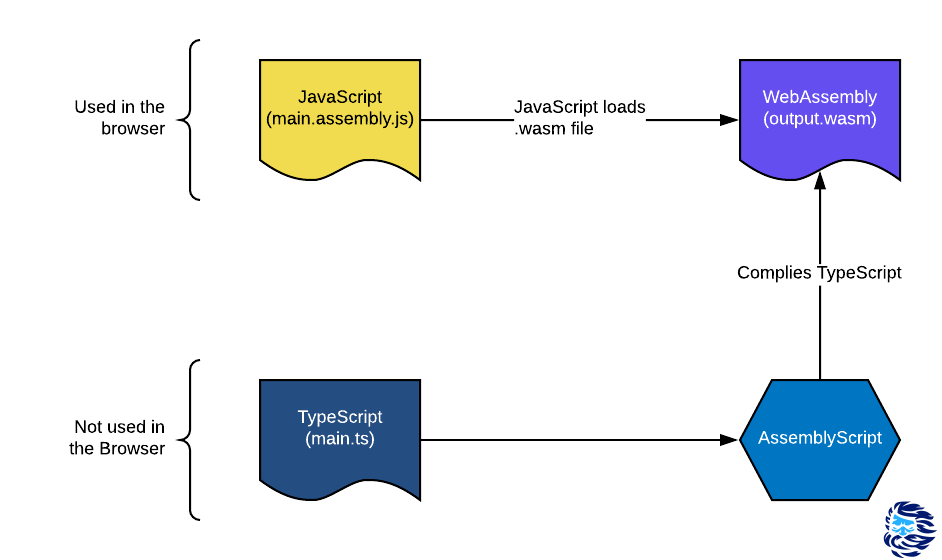
Чтобы повысить производительность web-приложений, используйте WebAssembly в связке с AssemblyScript, чтобы переписать критически важные для производительности компоненты web-приложения, написанные на JavaScript. «И это действительно поможет?», — спросите вы.
К сожалению, на этот вопрос нет чёткого ответа. Всё зависит от того, как вы будете их использовать. Вариантов много: в одних случаях ответ будет отрицательный, в других — положительный. В одной ситуации лучше выбрать JavaScript вместо AssemblyScript, а в другой — наоборот. На это влияет множество различных условий.
В данной статье мы проанализируем эти условия, предложим ряд решений и проверим их на нескольких тестовых примерах кода.
Кто я такой и почему занимаюсь этой темой?
(Данный раздел можете пропустить, это несущественно для понимания дальнейшего материала).
Мне по-настоящему нравится язык AssemblyScript. Я даже в какой-то момент начал помогать разработчикам финансово. У них небольшая команда, в которой каждый серьёзно увлечён этим проектом. AssemblyScript — очень молодой язык, похожий на TypeScript и способный компилироваться в WebAssembly (Wasm). Именно в этом и заключается одно из его преимуществ. Раньше, чтобы использовать Wasm, web-разработчик должен был учить чуждые ему языки типа С, C++, C#, Go или Rust, так как в WebAssembly изначально могли компилироваться именно такие высокоуровневые языки со статической типизацией.
Хотя AssemblyScript (ASC) и похож на TypeScript (TS), он не связан с этим языком и не компилируется в JS. Схожесть в синтаксисе и семантике нужна, чтобы облегчить процесс «портирования» с TS на ASC. Такое портирование в основном сводится к добавлению аннотаций типов.
Мне всегда было интересно взять код на JS, портировать его на ASC, скомпилировать в Wasm и сравнить производительность. Когда мой коллега Ингвар прислал мне фрагмент JavaScript-кода для размытия изображений, я решил использовать его. Я провёл небольшой эксперимент, чтобы понять, стоит ли более глубоко изучать эту тему. Оказалось, стоит. В результате появилась эта статья.
Чтобы лучше познакомиться с AssemblyScript, можно изучить материалы на официальном сайте, присоединиться к каналу в Discord или посмотреть вводное видео на моём Youtube-канале. А мы идём дальше.
Преимущества WebAssembly
Как я уже писал выше, долгое время главной задачей Wasm оставалась возможность компиляции кода, написанного на высокоуровневых языках общего назначения. Например, в Squoosh (онлайн-инструмент для обработки изображений) мы используем библиотеки из экосистемы C/C ++ и Rust. Изначально эти библиотеки не были предназначены для использования в web-приложениях, но благодаря WebAssembly это стало возможным.
Кроме того, согласно распространённому мнению, компиляция исходного кода в Wasm нужна ещё и потому, что использование Wasm-бинарников позволяет ускорить работу web-приложения. Я соглашусь, как минимум, с тем, что в идеальных (лабораторных) условиях WebAssembly и JavaScript-бинарники могут обеспечить примерно равные значения пиковой производительности. Вряд ли это возможно на боевых web-проектах.
На мой взгляд, разумнее рассматривать WebAssembly как один инструментов оптимизации средних, рабочих значений производительности. Хотя недавно у Wasm появилась возможность использовать SIMD-инструкции и потоки с разделяемой памятью. Это должно повысить его конкурентоспособность. Но в любом случае, как я писал выше, всё зависит от конкретной ситуации и начальных условий.
Ниже рассмотрим несколько таких условий:
Отсутствие разогрева
JS-движок V8 обрабатывает исходный код и представляет его в виде абстрактного синтаксического дерева (АСТ). Основываясь на построенном АСТ, оптимизированный интерпретатор Ignition генерирует байткод. Полученный байткод забирает компилятор Sparkplug и на выходе выдаёт пока ещё не оптимизированный машинный код, с большим объёмом футпринта. В процессе исполнения кода V8 собирает информацию о формах (типах) используемых объектов и затем запускает оптимизирующий компилятор TurboFan. Он формирует низкоуровневые машинные инструкции, оптимизированные для целевой архитектуры с учётом собранной информации об объектах.
С тем, как устроены JS-движки можно разобраться, изучив перевод этой статьи.

Пайплайн JS-движка. Общая схема
С другой стороны, в WebAssembly используется статическая типизация, поэтому из него можно сразу сгенерировать машинный код. У движка V8 есть потоковый компилятор Wasm под названием Liftoff. Он, как и Ignition, помогает быстро подготовить и запустить неоптимизированный код. И после этого просыпается всё тот же TurboFan и оптимизирует машинный код. Он будет работать быстрее, чем после компиляции Liftoff, но для его генерации потребуется больше времени.
Принципиальное отличие пайплайна JavaScript от пайплайна WebAssembly: движку V8 незачем собирать информацию об объектах и типах, так как у Wasm типизация статическая и всё известно заранее. Это экономит время.
Отсутствие деоптимизации
Машинный код, который TurboFan генерирует для JavaScript, можно использовать только до тех пор, пока сохраняются предположения о типах. Допустим, TurboFan сгенерировал машинный код, например, для функции f с числовым параметром. Тогда, встретив вызов этой функции с объектом вместо числа, движок опять задействует Ignition или Sparkplug. Это называется деоптимизацией.
У WebAssembly в процессе выполнения программы типы измениться не могут. Поэтому в такой деоптимизации нет необходимости. А сами типы, которые поддерживает Wasm, органично переводятся в машинный код.
Минимизация бинарников для больших проектов
Wasm изначально спроектирован с учётом формата компактных бинарных файлов. Поэтому такие бинарники быстро загружаются. Но во многих случаях они всё-таки получаются больше, чем хотелось бы (по крайней мере, с точки зрения объёмов, принятых в сети). Однако с помощью gzip или brotli эти файлы хорошо сжимаются.
За годы своей жизни JavaScript много чего научился делать из коробки: массивы, объекты, словари, итераторы, обработка строк, прототипное наследование и так далее. Всё это встроено в его движок. А язык С++, например, может похвастаться гораздо большим размахом. И каждый раз, когда вы используете любую из таких абстракций языка при компиляции в WebAssembly, соответствующий код из-под капота должен быть включен в ваш бинарный файл. Это одна из причин разрастания двоичных файлов WebAssembly.
Wasm толком ничего не знает про C++ (или любой другой язык). Поэтому среда исполнения Wasm не предоставляет стандартную библиотеку C++ и компилятору её приходится добавлять в каждый бинарный файл. Но такой код достаточно подключить всего один раз. Поэтому для более крупных проектов это не сильно влияет на результирующий размер Wasm-бинарника, который в итоге часто оказывается меньше других бинарников.
Понятно что, не во всех случаях можно принять взвешенное решение, сравнивая только размеры бинарников. Если, например, исходный код на AssemblyScript скомпилировать в Wasm, то бинарник действительно получится очень компактным. Но насколько быстро он будет работать? Я поставил перед собой задачу сравнить разные варианты JS- и ASC-бинарников сразу по двум критериям — скорость работы и размер.
Портирование на AssemblyScript
Как я уже писал, TypeScript и ASC сильно похожи по синтаксису и семантике. Легко предположить, что есть сходство и с JS.Поэтому портирование в основном сводится к добавлению аннотаций типов (или к замене типов). Для начала портируем glur, JS-библиотеку для размытия изображений.
Сопоставление типов данных
Встроенные типы AssemblyScript реализованы по аналогии с типами виртуальной машины Wasm (WebAssembly VM). Если в TypeScript, например, тип Number реализован как 64-битное число с плавающей запятой (по стандарту IEEE754), то в ASC есть целый ряд числовых типов: u8, u16, u32, i8, i16, i32, f32 и f64. Кроме того, в стандартной библиотеке AssemblyScript можно обнаружить распространённые составные типы данных (string, Array, ArrayBuffer, Uint8Array и так далее), которые, с определёнными оговорками, присутствуют в TypeScript и JavaScript. Рассматривать здесь таблицы соответствия типов AssemblyScript, TypeScript и Wasm VM я не буду, это тема другой статьи. Единственное, что хочу отметить: в ASC реализован тип StaticArray, для которого я не нашёл аналогов в JS и WebAssembly VM.
Переходим, наконец, к нашему примеру кода из библиотеки glur.
JavaScript:
function gaussCoef(sigma) {
if (sigma < 0.5)
sigma = 0.5;
var a = Math.exp(0.726 * 0.726) / sigma;
/* ... more math ... */
return new Float32Array([
a0, a1, a2, a3,
b1, b2,
left_corner, right_corner
]);
}
AssemblyScript:
function gaussCoef(sigma: f32): Float32Array {
if (sigma < 0.5)
sigma = 0.5;
let a: f32 = Mathf.exp(0.726 * 0.726) / sigma;
/* ... more math ... */
const r = new Float32Array(8);
const v = [
a0, a1, a2, a3,
b1, b2,
left_corner, right_corner
];
for (let i = 0; i < v.length; i++) {
r[i] = v[i];
}
return r;
}Фрагмент кода на AssemblyScript содержит дополнительный цикл в конце, так как нет возможности инициализировать массив через конструктор. В ASC не реализована перегрузка функций, поэтому в данном случае у нас есть только один конструктор Float32Array (lengthOfArray: i32). В AssemblyScript есть callback-функции, но отсутствуют замыкания, поэтому нет возможности использовать .forEach() для заполнения массива значениями. Вот и пришлось использовать обычный цикл for для копирования по одному элементу.
Возможно вы заметили, что во фрагменте кода наAssemblyScript я вызываю функции не из библиотеки Math, а из Mathf. Дело в том, что первая предназначена для 64-битных чисел с плавающей запятой, а вторая — для 32-битных. Я мог бы использовать Math и каждый раз выполнять приведение типов. Но операции для чисел с двойной точностью всё-таки работают чуть медленнее, а мне это не нужно, так как всюду использую тип f32. Хотя в принципе можно было сделать и так. В данном случае это не является узким местом.
На всякий случай: следите за знаками
Мне потребовалось много времени, чтобы понять: выбор типов очень важен. Размытие изображения включает операции свёртки, а это целая куча циклов for, пробегающих все пиксели. Наивно было думать, что, если все индексы пикселей положительны, счётчики цикла тоже будут положительными. Зря я выбрал для них тип u32 (32-битное целое без знака). Если какой-либо из этих циклов будет бежать в обратном направлении, он станет бесконечным (программа зациклится):
let j: u32;
// ... many many lines of code ...
for (j = width — 1; j >= 0; j--) {
// ...
}Других сложностей при портировании я не обнаружил.
Бенчмарки с командной оболочкой d8
Хорошо, фрагменты кода на двух языках готовы. Теперь можно компилировать ASC в Wasm и запускать первые тесты производительности.
Несколько слов про d8: это командная оболочка для движка V8 (сам он не имеет своего интерфейса), позволяющая выполнять все необходимые действия как с Wasm, так и с JS. В принципе, d8 можно сравнить с Node, которому вдруг отрубили стандартную библиотеку и остался только чистый ECMAScript. Если у вас нет скомпилированной версии V8 на локале (как её скомпилировать — описано здесь), использовать d8 вы не сможете. Чтобы установить d8, используйте инструмент jsvu.
Однако, поскольку в заголовке этого раздела есть слово «Бенчмарки», я считаю важным дать здесь своего рода дисклеймер: полученные мною цифры и результаты относятся к коду, который я написал на выбранных мною языках, запущенном на моем компьютере ( MacBook Air M1 2020 года), используя созданные мной тестовые скрипты. Результаты в лучшем случае являются приблизительными ориентирами. Поэтому было бы опрометчиво на их основе давать обобщённые количественные оценки производительности AssemblyScript с WebAssembly или JavaScript с V8.
У вас может возникнуть ещё один вопрос: почему я выбрал d8 и не стал запускать скрипты в браузере или Node? Я считаю, что и браузер, и Node, скажем так, недостаточно стерильны для моих экспериментов. Помимо необходимой стерильности, d8 даёт возможность управлять пайплайном движка V8. Я могу зафиксировать любой сценарий оптимизации и использовать, например, только Ignition, только Sparkplug или Liftoff, чтобы характеристики производительности не изменились в середине теста.
Методика эксперимента
Как я уже писал выше, у нас есть возможность «разогреть» движок JavaScript перед запуском теста производительности. В процессе такого разогрева V8 делает необходимую оптимизацию. Поэтому я запускал программу размытия изображения 5 раз, прежде чем начать измерения, затем выполнял 50 запусков и игнорировал 5 самых быстрых и самых медленных прогонов, чтобы удалить потенциальные выбросы и слишком сильные отклонения в цифрах.
Посмотрите, что получилось:

С одной стороны, я обрадовался, что Liftoff выдал более быстрый код в сравнении с Ignition и Sparkplug. Но то, что AssemblyScript, скомпилированный в Wasm с применением оптимизации, оказался в несколько раз медленнее связки JavaScript — TurboFan, меня озадачило.
Хотя позже я всё-таки признал, что силы изначально не равны: над JS и его движком V8 много лет работает огромная команда инженеров, реализующих оптимизацию и другие умные вещи. AssemblyScript — относительно молодой проект с небольшой командой. Компилятор ASC, сам по себе, однопроходный и перекладывает все усилия по оптимизации на библиотеку Binaryen. Это означает, что оптимизация выполняется на уровне байт-кода Wasm VM после того, как большая часть семантики высокого уровня уже скомпилирована. V8 имеет здесь явное преимущество. Однако код размытия очень прост — это обычные арифметические действия со значениями из памяти. Казалось, с этой задачей ASC и Wasm должны были справиться лучше. В чём же тут дело?
Копнём глубже
Я быстро проконсультировался с умными ребятами из команды V8 и с не менее умными парнями из команды AssemblyScript (спасибо Дэниелу и Максу!). Выяснилось, что при компиляции ASC не запускается «проверка границ» (граничных значений).
V8 может в любой момент посмотреть исходный JS-код и разобраться в его семантике. Он использует эту информацию для повторной или дополнительной оптимизации. Например, у вас есть объект типа ArrayBuffer, содержащий набор бинарных данных. В этом случае V8 ожидает, что наиболее разумным будет не просто хаотично бегать по ячейкам памяти, а использовать итератор посредством цикла for ...of.
for (<i>variable</i> of <i>iterableObject</i>) {
<i>statement</i>
}
Семантика этого оператора гарантирует, что мы никогда не выйдем за границы массива. Соответственно, компилятор TurboFan не занимается проверкой граничных значений. Но перед компиляцией ASC в Wasm семантика языка AssemblyScript не используется для такой оптимизации: вся оптимизация выполняется на уровне виртуальной машины WebAssembly.
К счастью, у ASC всё-таки есть козырь в рукаве — аннотация unchecked(). Она указывает на то, какие значения нужно проверять на возможность выхода за границы.
— prev_prev_out_r = prev_src_r * coeff[6];
— line[line_index] = prev_out_r;
Предыдущие 2 строки нужно переписать так:
+ prev_prev_out_r = prev_src_r * unchecked(coeff[6]);
+ unchecked(line[line_index] = prev_out_r);
Да, есть кое-что ещё. В AssemblyScript типизированные массивы (Uint8Array, Float32Array и так далее) реализованы по образу и подобию ArrayBuffer’a. Однако из-за отсутствия высокоуровневой оптимизации для доступа к элементу массива с индексом i каждый раз приходится обращаться к памяти дважды: первый раз — для загрузки указателя на первый элемент массива и второй раз — для загрузки элемента по смещению i*sizeOfType. То есть приходится обращаться к массиву как к буферу (через указатель). В случае с JS чаще всего этого не происходит, так как V8 удаётся сделать высокоуровневую оптимизацию доступа к массиву, используя однократное обращение к памяти.
Для повышения производительности в AssemblyScript реализованы статические массивы (StaticArray). Они похожи на Array, только имеют фиксированную длину. А следовательно пропадает необходимость хранения указателя на первый элемент массива. Если есть возможность — используйте эти массивы для ускорения работы ваших программ.
Итак, я взял связку AssemblyScript — TurboFan (она работала быстрее) и назвал её naive. Затем я добавил к ней две оптимизации, о которых говорил в этом разделе, и получил вариант под названием optimized.

Намного лучше! Мы существенно продвинулись. Хотя AssemblyScript всё ещё работает медленнее, чем JavaScript. Неужели это всё, что мы можем сделать? [спойлер: нет]
Ох уж эти умолчания
Ребята из команды AssemblyScript также рассказали мне, что флаг --optimize эквивалентен -O3s. Он хорошо оптимизирует скорость работы, но не доводит её до максимума, так как одновременно препятствует разрастанию бинарного файла. Флаг -O3 оптимизирует только скорость и делает это до конца. Использовать -O3s по умолчанию вроде бы правильно, так как в web-разработке принято сокращать размеры бинарников, но стоит ли оно того? По крайней мере, в этом конкретном примере ответ отрицательный: -O3s экономит ничтожные ~ 30 байт, но закрывает глаза на существенное падение производительности:

Один единственный флаг оптимизатора просто переворачивает игру: наконец-то, AssemblyScript обогнал JavaScript (в этом конкретном тестовом примере!).
Я больше не буду указывать в таблице флаг O3, но будьте уверены: отныне и до конца статьи он будет с нами незримо.
Сортировка методом пузырька
Чтобы убедиться, что пример с размытием изображения — не просто случайность, я решил взять ещё один. Я взял реализацию сортировки на StackOverflow и проделал тот же процесс:
- портировал код, добавив типы;
- запустил тест;
- оптимизировал;
- снова запустил тест.
(Создание и заполнение массива для пузырьковой сортировки я не тестировал).
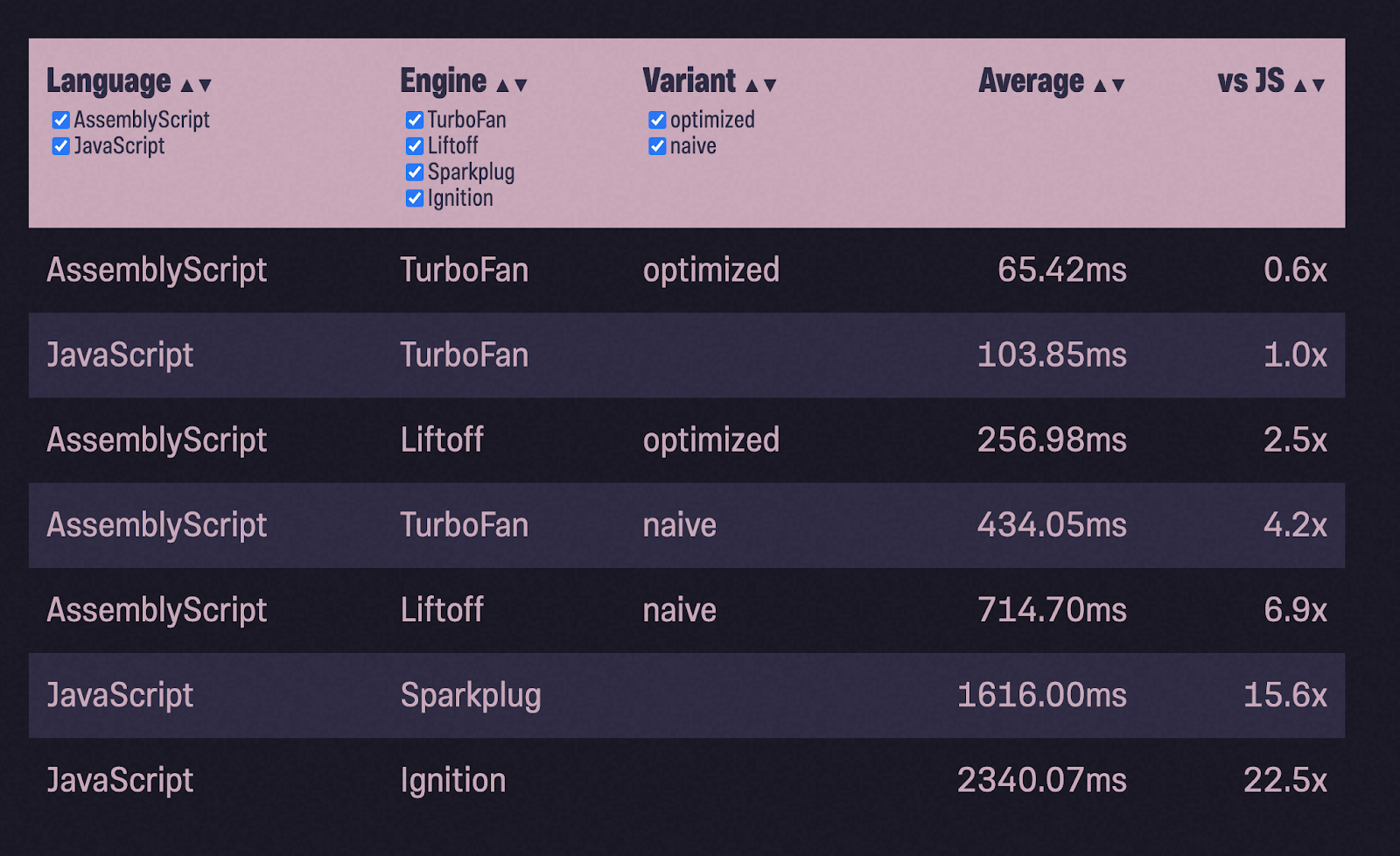
Мы сделали это снова! На этот раз с ещё большим выигрышем по скорости: оптимизированный AssemblyScript почти в два раза быстрее, чем JavaScript. Но и это ещё не всё. Далее меня опять ждут взлёты и падения. Пожалуйста, не переключайтесь!
Управление памятью
Некоторые из вас, возможно, заметили, что в обоих этих примерах толком не показана работа с памятью. В JavaScript V8 берёт на себя всё управление памятью (и сборку мусора) за вас. В WebAssembly, с другой стороны, вы получаете кусок линейной памяти, и вам нужно решить, как его использовать (или, скорее, Wasm должен решить). Насколько сильно изменится наша таблица, если мы будем интенсивно использовать динамическую память?
Я решил взять новый пример с реализацией двоичной кучи. В процессе тестирования я заполняю кучу 1 миллионом случайных чисел (любезно предоставленных Math.random()) и pop() возвращает их обратно, проверяя, находятся ли числа в порядке возрастания. Общая схема работы осталась той же: портировать JS-код в ASC, скомпилировать с конфигурацией naive, запустить тесты, оптимизировать и снова запустить тесты:
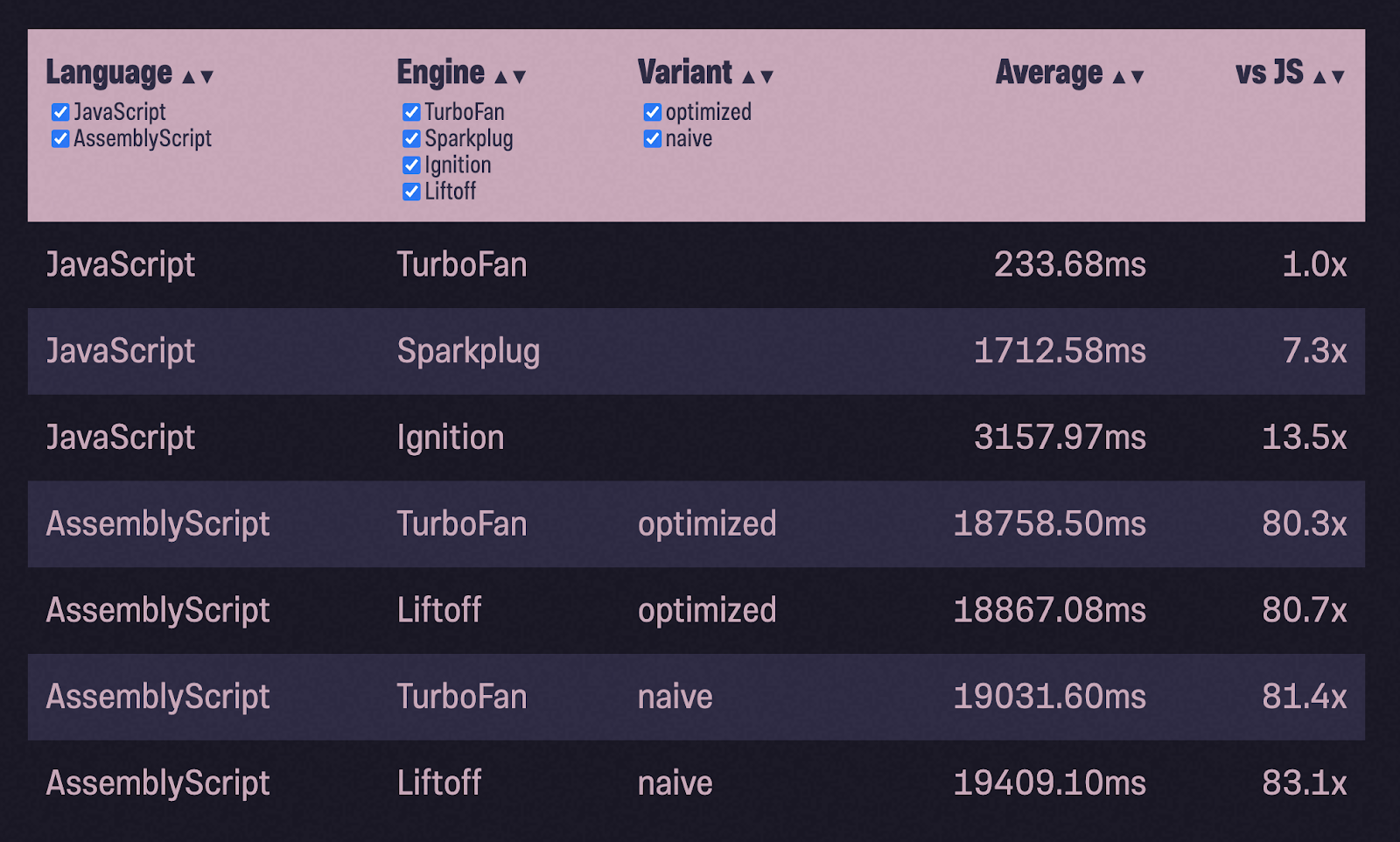
В 80 раз медленнее, чем JavaScript с TurboFan?! И в 6 раз медленнее, чем с Ignition! Что же пошло не так?
Настройка среды исполнения
Все данные, которые мы генерируем в AssemblyScript, должны храниться в памяти. Но нам нужно убедиться, что мы не перезаписываем что-либо ещё, что уже там хранится. Поскольку AssemblyScript стремится подражать поведению JavaScript, у него тоже есть сборщик мусора и при компиляции он добавляет этот сборщик в модуль WebAssembly. ASC не хочет, чтобы вы беспокоились о том, когда выделять, а когда освобождать память.
В таком режиме (он называется incremental) он работает по умолчанию. При этом в Wasm-модуль добавляется всего около 2 КБ в архиве gzip. AssemblyScript также предлагает альтернативные режимы — minimal и stub. Режимы можно выбирать с помощью флага --runtime. Minimal использует тот же аллокатор памяти, но более лёгковесный сборщик мусора, который не запускается автоматически, а должен быть вызван вручную. Это может понадобиться при разработке высокопроизводительных приложений (например, игр), где вы хотите контролировать момент, когда сборщик мусора приостановит вашу программу. В режиме stub в Wasm-модуль добавляется очень мало кода (~ 400 Б в формате gzip). Он работает быстро, так как используется резервный аллокатор (подробнее про аллокаторы написано здесь).
Резервные аллокаторы работают очень быстро, но не могут освобождать память. Пусть это звучит глупо, но такое бывает полезно для «одноразовых» экземпляров модулей, где после выполнения задачи вы вместо освобождения памяти удаляете весь экземпляр WebAssembly и создаете новый.
Давайте посмотрим, как будет работать наш модуль в разных режимах:

И minimal, и stub резко приблизили нас к уровню производительности JavaScript. Интересно, почему? Как упоминалось выше, minimal и incremental используют один и тот же аллокатор. У обоих также есть сборщик мусора, но minimal не запускает его, если он не вызван явно (а я его как раз не вызываю). Значит, всё дело в том, что incremental запускает сборку мусора автоматически, и зачастую делает это без необходимости. Ну и зачем это нужно, если он должен отслеживать всего лишь один массив?
Проблема с распределением памяти
Несколько раз запустив Wasm-модуль в режиме отладки (--debug), я обнаружил, что скорость работы замедляется из-за библиотеки libsystem_platform.dylib. Она содержит примитивы уровня ОС для работы с потоками и управления памятью. Вызовы в эту библиотеку выполняются из __new() и __renew(), которые, в свою очередь, вызываются из Array#push:
[Bottom up (heavy) profile]:
ticks parent name
18670 96.1% /usr/lib/system/libsystem_platform.dylib
13530 72.5% Function: *~lib/rt/itcms/__renew
13530 100.0% Function: *~lib/array/ensureSize
13530 100.0% Function: *~lib/array/Array#push
13530 100.0% Function: *binaryheap_optimized/BinaryHeap#push
13530 100.0% Function: *binaryheap_optimized/push
5119 27.4% Function: *~lib/rt/itcms/__new
5119 100.0% Function: *~lib/rt/itcms/__renew
5119 100.0% Function: *~lib/array/ensureSize
5119 100.0% Function: *~lib/array/Array#push
5119 100.0% Function: *binaryheap_optimized/BinaryHeap#pushЯсно: здесь проблема с управлением памятью. Но JavaScript каким-то образом умудряется быстро обрабатывать постоянно растущий массив. Так почему же этого не может AssemblyScript? К счастью, исходники стандартной библиотеки AssemblyScript есть в открытом доступе, так что давайте взглянем на эту зловещую функцию push () класса Array:
export class Array<T> {
// ...
push(value: T): i32 {
var length = this.length_;
var newLength = length + 1;
ensureSize(changetype<usize>(this), newLength, alignof<T>());
// ...
return newLength;
}
// ...
}Пока всё верно: новая длина массива равна текущей длине, увеличенной на 1. Далее следует вызов функции ensureSize (), чтобы убедиться, что в буфере достаточно места (Capacity) для нового элемента.
function ensureSize(array: usize, minSize: usize, alignLog2: u32): void {
// ...
if (minSize > <usize>oldCapacity >>> alignLog2) {
// ...
let newCapacity = minSize << alignLog2;
let newData = __renew(oldData, newCapacity);
// ...
}
}Функция ensureSize (), в свою очередь, проверяет: Capacity меньше, чем новый minSize? Если да, выделяет новый буфер размером minSize с помощью функции__renew(). Это влечёт за собой копирование всех данных из старого буфера в новый буфер. По этой причине наш тест с заполнением массива 1 миллионом значений (один элемент за другим), приводит к перераспределению большого количества памяти и создаёт много мусора.
В других библиотеках (как std::vec в Rust или slices в Go), новый буфер имеет вдвое большую ёмкость (Capacity), чем старый, что помогает сделать процесс работы с памятью не таким затратным и медленным. Я работаю над этой проблемой в ASC, и пока единственное решение — это создать собственный CustomArray , с собственной оптимизацией работы с памятью.

Теперь incremental работает так же быстро, как minimal и stub. Но JavaScript в этом тестовом примере всё равно остаётся лидером. Вероятно, я мог бы сделать больше оптимизаций на уровне языка, но это не статья о том, как оптимизировать сам AssemblyScript. Я и так уже погрузился достаточно глубоко.
Есть много простых оптимизаций, которые мог бы сделать за меня компилятор AssemblyScript. С этой целью команда ASC работает над высокоуровневым оптимизатором IR (Intermediate Representation) под названием AIR. Сможет ли это сделать работу быстрее и избавить меня от необходимости каждый раз вручную оптимизировать доступ к массиву? Скорее всего. Будет ли он быстрее, чем JavaScript? Трудно сказать. Но в любом случае мне было интересно побороться за ASC, оценить возможности JS и увидеть, чего может достичь более «зрелый» язык с «очень умными» инструментами компиляции.
Rust & C++
Я переписал код на Rust, максимально идиоматично (как мог), и скомпилировал его в WebAssembly. Он оказался быстрее, чем AssemblyScript (naive), но медленнее, чем наш оптимизированный AssemblyScript с CustomArray . Далее я оптимизировал модуль, скомпилированный из Rust примерно по той же схеме, что и AssemblyScript. С такой оптимизацией Wasm-модуль на базе Rust работает быстрее, чем наш оптимизированный AssemblyScript, но всё же медленнее, чем JavaScript.
Я применил тот же подход к C ++, для компиляции в WebAssembly использовал Emscripten. К моему удивлению, даже первый вариант без оптимизации оказался не хуже JavaScript.

Здесь URL картинки нет. Я сам делал скриншот
Версии, помеченные как idiomatic («идиоматические»), в любом случае создавались под влиянием исходного кода JS. Я пытался использовать свои знания идиом Rust, C++, но в моей голове прочно сидела установка, что я занимаюсь портированием. Я уверен, что тот, у кого больше опыта в этих языках мог бы реализовать задачу с нуля, и код выглядел бы иначе.
Я почти уверен, что модули с Rust и C ++ могли бы работать ещё быстрее. Но у меня не хватило глубоких знаний этих языков, чтобы выжать из них больше.
Опять про размеры бинарников
Посмотрим на размеры бинарных файлов после сжатия с помощью gzip. По сравнению с Rust и C++, бинарники AssemblyScript действительно намного легче по весу.
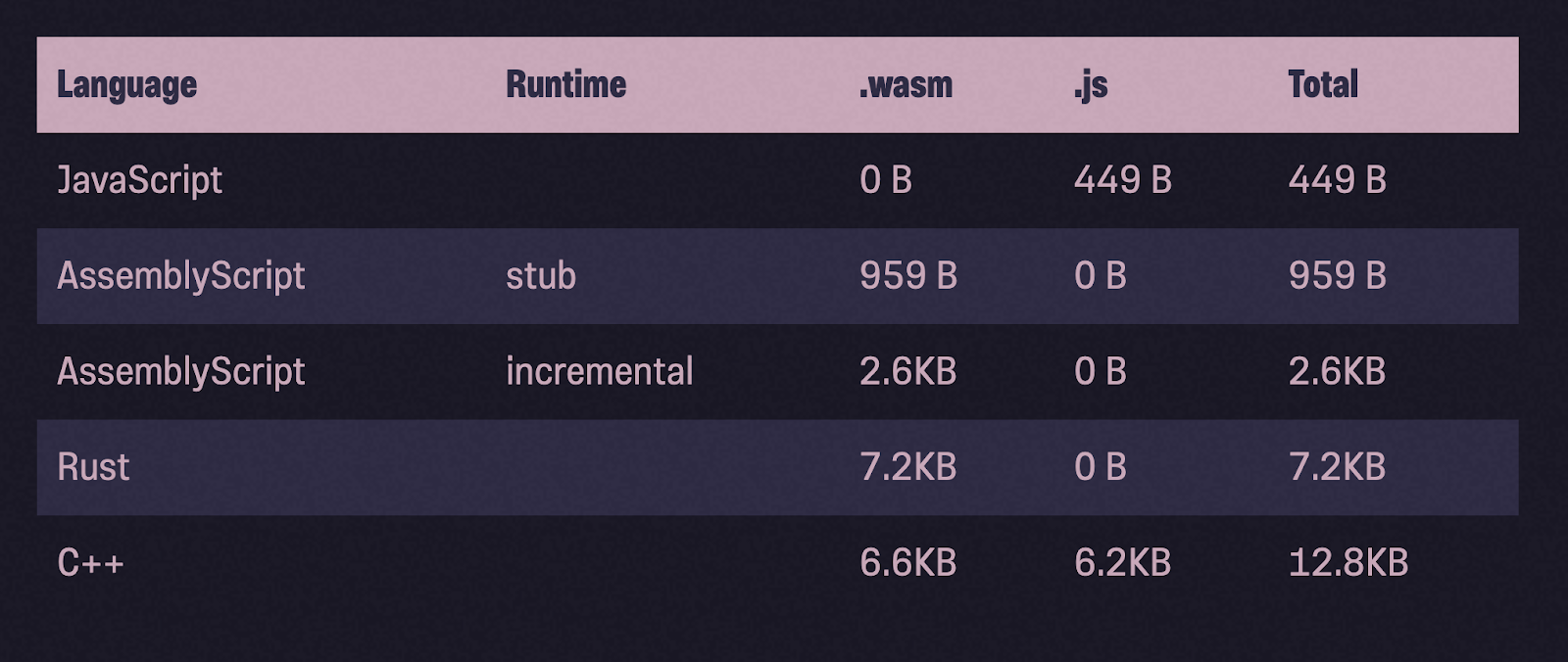
И всё-таки… рекомендации
Я писал об этом в начале статьи, повторю и сейчас: результаты в лучшем случае являются приблизительными ориентирами. Поэтому было бы опрометчиво на их основе давать обобщённые количественные оценки производительности. Например, нельзя сказать, что Rust во всех случаях в 1,2 раза медленнее JavaScript. Эти числа очень сильно зависят от кода, который я написал, оптимизаций, которые я применил, и машины, которую я использовал.
И всё-таки, я думаю, есть несколько общих рекомендаций, которые мы можем извлечь, чтобы помочь вам лучше разбираться в теме и принимать более обоснованные решения:
- Компилятор Liftoff в связке с AssemblyScript будет генерировать Wasm-код, который выполняется значительно быстрее, чем код, который выдаёт Ignition или SparkPlug в связке с JavaScript. Если вам нужна производительность и нет времени на разогрев JS-движка, WebAssembly — лучший вариант.
- V8 действительно хорошо компилирует и оптимизирует JavaScript-код. Хотя WebAssembly может работать быстрее, чем JavaScript, вполне вероятно, что для этого вам придётся заниматься оптимизацией вручную.
- Более медленный язык и компилятор, с годами обросший разнообразными способами оптимизации, даст фору шустрому языку и молодому компилятору.
- Модули AssemblyScript, как правило, весят намного меньше, чем Wasm-модули, скомпилированные из других языков. В этой статье бинарник с AssemblyScript не был меньше бинарника с JavaScript, но для более крупных модулей ситуация обратная, как утверждает команда разработки ASC.
Если вы мне не верите (а вы и не обязаны) и хотите самостоятельно разобраться в коде тестовых примеров, вот они.
Наши виртуальные серверы можно использовать для разработки на WebAssembly.
Зарегистрируйтесь по ссылке выше или кликнув на баннер и получите 10% скидку на первый месяц аренды сервера любой конфигурации!

