
Привет, Хабр! В феврале исполняется два года проекту Техносфера. За прошедший год произошло три больших изменения, повлиявших на процесс обучения. Первое из них касалось отбора студентов — технических собеседований. Раньше студент шел на техническое собеседование, не зная, какие задачи ему предложат решить. Теперь же мы отправляем студентам кейс, некую техническую задачу, решить которую нужно заранее и на месте объяснить преподавателям ее решение. После добавления кейса успеваемость резко улучшилась. Перевод на второй семестр в Техносфере составил 27 студентов из 40, то есть 67% вместо обычных 40–50%.
Во-вторых, при Техносфере создана лаборатория, в которой студенты занимаются решением практических задач Mail.Ru Group, а также внешних заказчиков. Например, они исследуют алгоритмы таргетинга для рекламных кампаний, а также пытаются создать эвристики, которые позволяют улучшить качество рекламной выдачи. По сути, лаборатория — это альтернатива стажировке в компании. В ней можно работать над решением различных практических задач с рынка, но при этом не тратить время на дорогу в офис, делая все прямо на своем факультете.
Третьим важным шагом стало решение перейти на двухгодичное обучение. В этом году мы выпустили последнюю группу ребят, которые учились по годовой программе. Предметы, которые они осваивали в течение года, были: алгоритмы интеллектуальной обработки больших объемов данных, многопоточное программирование на С/С++, СУБД, Hadoop, методы обработки больших объемов данных и информационный поиск.
Сейчас мы хотели бы поставить точку в годовой программе обучения, показав вам один из выпускных проектов по предмету «Информационный поиск». В течение семестра ребятам давались домашние задания, которые в итоге вылились в большой итоговый проект. Правила были таковы:
- Ребята разбивались на команды по 2–3 человека.
- Задача: сделать полноценный поиск по одному из предложенных сайтов. По задумке ваш поиск должен состоять из объединенных домашек + фронтенд + какая-нибудь плюшка, например spellchecker.
 Святослав Фельдшеров
Святослав ФельдшеровНаш поисковик работал по сайту povarenok.ru. Я в нашем проекте занимался тем, что собирал вместе все компоненты и делал веб. Изначально на курсе все задания были на Python 2.7, и мы как-то по инерции начали делать проект на нем же. Поэтому для создания веб-приложения мы взяли Django. Сейчас есть ощущение, что это был перебор и можно было обойтись чем-то сильно более простым, но об этом чуть позже.
В самом начале у нас была очень простая идея: взять уже написанные домашние работы, склеить их и получить почти готовый проект. Так у нас появилась первая поисковая машина, на проекте мы назвали ее черновой. В тот момент все складывалось очень удобно: было Django-приложение, которое летало, в нужном месте вызывалась функция, возвращающая результаты поиска, — и победа. Но вся конструкция начинала дико тормозить при запросе популярного слова на полном индексе. У нас была пара попыток ускорить Python, но ничего хорошего из этого не вышло. Тогда Денис взял и переписал всю поисковую часть на C++. Теперь с моей стороны все выглядело так: попробуй поискать в быстром поисковике, если он лежит, иди в питоновский поиск, пусть медленно, но это лучше, чем никак.
Ещё одна эпопея случилась со сниппетами и прямым индексом. Моя первая идея была просто брать summary рецепта и показывать это в качестве сниппета. Сначала казалось, что это неплохо работает. Но если покопаться на сайте, можно найти что-нибудь такое: «Этот рецепт был заявлен автором, талантливым кулинаром Олечкой-Сарочка как „Самый вкусный тирамису“. И я не стала менять название. Как бы во избежание...». Такая изобретательность пользователей порушила все мои надежды на простые сниппеты. Где-то к этому моменту Даниил выкатил свой snippet builder, и у нас снова получился некоторый запас прочности: если упал snippet builder, то поищи summary, а если и его нет, то увы. Кстати, именно здесь Python 2.7 особенно хорош, когда тебе внезапно на странице попадается битая кодировка.
Следующая вещь, с которой мне пришлось иметь дело, — это spellchecker, но там все было без особых приключений. И последнее мое творение — это front-end ко всему этому, большой, трудоемкий для нас кусок, но про него абсолютно нечего рассказывать :). Кто умеет, тому неинтересны мои велосипеды, а кто не умеет, то мы явно не лучший пример для обучения.
 Денис Купляков
Денис КупляковМоя часть курсовой работы состояла в реализации булева поиска с ранжированием по данной базе загруженных страниц, т. е. на вход поступает текстовый запрос, а на выходе должны быть URL’ы страниц по убыванию их релевантности. Очень хочется, чтобы поиск работал быстро: ответ на запрос не дольше секунды.
Я решил реализовать поиск как отдельный процесс с несколькими обрабатывающими потоками, для подачи запросов использовать сокеты. В качестве основного языка программирования выбрал C++. Это позволило обеспечить высокую скорость работы и эффективное управление памятью. В итоге была разработана следующая архитектура:
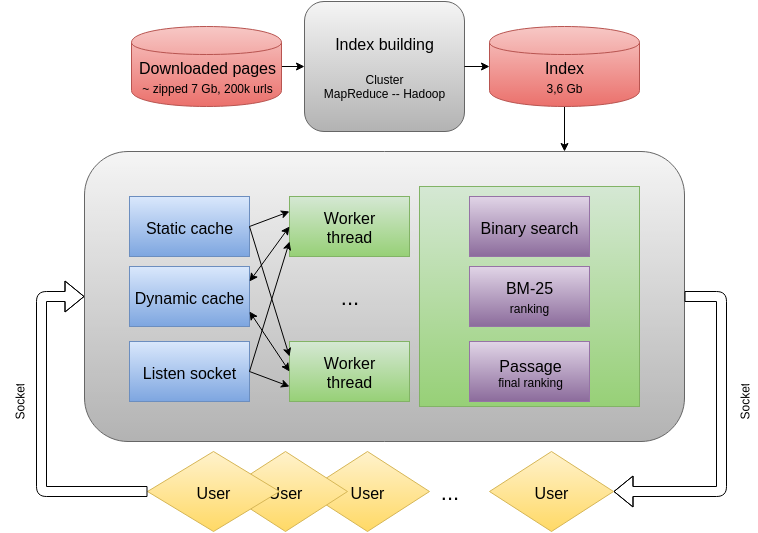
Исходные данные представляют собой загруженные страницы сайта povarenok.ru. Всего имелось примерно 200 тысяч различных URL’ов, сжатых zip’ом и записанных в Base64. Чтобы успешно производить поиск по большому количеству страниц, необходимо построить по ним обратный индекс: каждому слову сопоставляется список страниц, на которых он представлен. Также необходимы списки позиций вхождений слов в страницах — они используются на этапе ранжирования. Чтобы их построить достаточно быстро, был использован учебный кластер с Hadoop. Обработка производилась на Python в режиме streaming. Ниже представлена общая схема обработки:
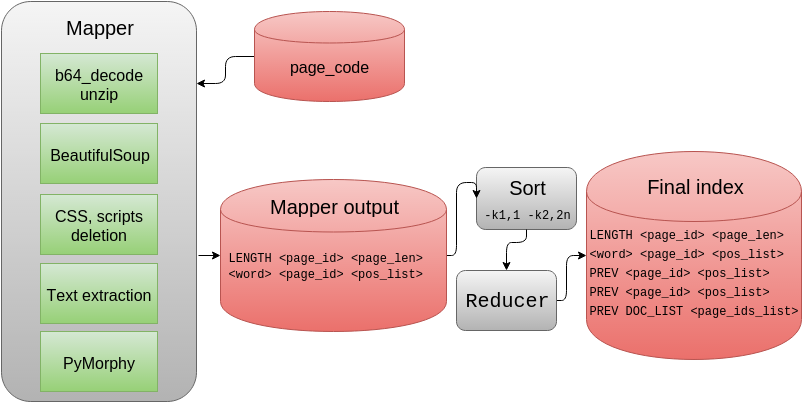
Для работы с содержимым веб-страниц была использована библиотека Beautiful Soup, которая позволяет легко удалить из страницы CSS, скрипты и выделить текст. Слова приводятся к нормальной форме с помощью pymorphy2.
После операции Map на выходе получаются записи о длине (количестве слов) на страницах и списки позиций слов. Слова кодируются в Base64, чтобы избежать проблем с кодировками, списки сжимаются алгоритмом simple-9 и также записываются в Base64.
MapReduce конфигурируется на сортировку по двум первым полям (второе трактуется как число), и далее на этапе Reduce записи о длинах сохраняются, списки для слов группируются, при этом само слово записывается один раз, а далее применяется специальная строка PREV (использовать предыдущее слово). Данный трюк позволил сократить индекс на 20 процентов. LENGTH, DOC_LIST и PREV — специальные строки, содержащие не используемые в Base64 символы.
Сетевое взаимодействие было реализовано при помощи библиотеки libevent. Для создания потоков был использован std::thread из C++11. Приходящие запросы помещаются в очередь, откуда вынимаются worker’ами. Для параллельного использования очередь «защищается» std::mutex.
Булев поиск. Приходящий запрос делится на слова, для них загружаются из индекса списки страниц. Списки отсортированные и быстро пересекаются. Чтобы не искать аналог pymorphy2 для C++, пользователь сам нормирует слова в запросе (запрашивающий код использует Python). В итоге получаем список страниц, на которых есть все слова.
Черновое ранжирование: BM25. Полученные страницы необходимо отранжировать, но делать это качественно для всех сразу выходит вычислительно затратно и потому долго. По этой причине сначала производится черновое ранжирование алгоритмом Okapi BM25. Подробно про него можно прочесть в Википедии. Параметры я использовал стандартные: k1 = 2.0, b = 0.75. От индекса на данном этапе нам требуется для пары (слово, страница) получать длину списка вхождений.
Окончательное ранжирование: пассажное. Данное ранжирование применяется только к самым релевантным страницам после чернового ранжирования (например, к трем первым сотням). Идея алгоритма: в тексте страницы выделяются окна, содержащие поисковые слова, для каждого окна вычисляются следующие характеристики:
- близость окна к началу страницы;
- отношение слов из запроса к общему количеству слов в окне;
- суммарный TF-IDF слов в окне;
- степень похожести порядка слов в окне к тому порядку, что был в запросе.
Эти характеристики приводятся к одному масштабу и складываются в линейную комбинацию — максимальная такая характеристика по всем окнам становится рангом документа. Правильно было бы подбирать коэффициенты для достижения наилучшего результата, но я использовал равные коэффициенты. От индекса на данном этапе нужно подгружать для пар (слово, страница) сами списки вхождений.
Понижающие коэффициенты на основании структуры сайта. Очевидное соображение: страницы с комментариями, анекдотами (да, и такое есть на «Поваренке») не так нужны пользователю, как рецепты. Чтобы выделить структуру сайта, я сопоставил каждому URL’у некий набор признаков, основанных на вхождении определенных сегментов в адрес. Затем провел кластеризацию. В итоге получилось разбиение URL’ов на группы: блоги, рецепты, альбомы и пр. Затем для некоторых из них я ввел подобранные эмпирическим путем понижающие коэффициенты — они умножаются на ранги, выдаваемые BM25 и пассажным алгоритмом. Это позволило понизить в выдаче страницы мобильной версии, страницы с комментариями, блоги и т. д.
Узким местом в поиске является обращение к жесткому диску. Чтобы все работало быстро, нужно уменьшить их количество. Для этого я постарался как можно больше информации положить в память. Памяти нашего сервера было недостаточно, чтобы сохранить все, и дополнительно необходимо учесть, что много дополнительной памяти требуется для организации произвольного доступа (указатели и пр.).
Статический кэш. В начале работы поиска зачитывается весь индекс и в память загружаются:
- для каждого слова смещение списка страниц в файле индекса;
- длины всех страниц;
- для всех пар (слово, страница) длина списка позиций;
- для всех пар (слово, страница) смещение этого списка в файле индекса.
Первое позволяет на этапе булева поиска быстро подгружать списки с жесткого диска. Второе и третье позволяют вычислять BM25, не обращаясь к жесткому диску. Четвертое аналогично первому, но для ускорения пассажного алгоритма.
Динамический кэш. Так как поиск работает по страницам кулинарного сайта, то некоторые слова типа «рецепт», «пирог» встречаются очень часто. Сразу возникает мысль кэшировать обращения к жесткому диску. Для этого, воспользовавшись boost::shared_lock и шаблонами C++, я реализовал кэш, который можно использовать из различных потоков. Время жизни записей ограничено временем, стратегия вытеснения — LRU.
Оценка качества поиска. Для оценки нам был выдан набор из 1000 пар запросов и страниц-маркеров, которые считаются наиболее релевантными друг другу. О качестве можно судить по средней позиции маркера среди результатов.
Для автоматизации тестирования был написан Python-скрипт, который в несколько потоков посылает запросы и генерирует отчет с графиками. Это позволило быстро отслеживать появление багов и эффективность модификаций. Вот такую статистику имела та версия поиска, которую мы презентовали на защите проекта:
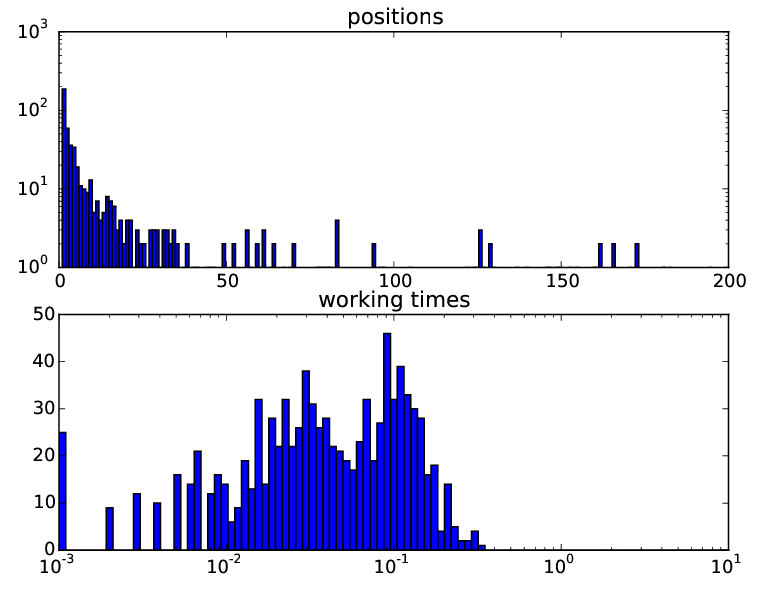
На верхнем графике представлено распределение количества маркеров по позициям в выдаче. Как видно, большинство маркеров попадают в топ-20.
На нижнем графике представлено распределение запросов по времени выполнения. Среднее время запроса составило 58 мс, что в сочетании с остальными компонентами проекта позволило уложиться в секунду времени на запрос.
 Даниил Полыковский
Даниил ПолыковскийПод моей ответственностью была разработка трех компонентов проекта: опечаточника (spellchecker), прямого индекса и сниппетов.
Опечаточник был основан на теории вероятностей (формула Байеса). Для исправления ошибок необходимо было сравнивать «похожесть» двух слов. Для этого было использовано модифицированное расстояние Дамерау — Левенштейна. В русском языке характерны ошибки, связанные с удвоением некоторых букв. Такие ошибки считались более вероятными, нежели, например, пропуск буквы, причем удвоение буквы н каралось значительно меньше, чем удвоение буквы е. Также опечаточник умел восстанавливать регистр, что помогало улучшить его визуальную составляющую. Интересной частью разработки был сбор статистики слов. Изначально был использован словарь, построенный на сайте povarenok.ru, однако позже он был дополнен частотным словарем русского языка (О. Н. Ляшевская, С. А. Шаров, 2009). В результате получилась весьма точная система, которая могла очень быстро исправлять до двух ошибок, в том числе склейку-расклейку слов. К моменту защиты проекта мы смогли найти одну ошибку в опечаточнике: фраза «печень по-барски» заменялась на «печень по-царски».
Второй частью было разбиение текста на предложения и построение сниппетов (краткого содержания страницы). Для разбиения использовалось машинное обучение. Подбор признаков оказался очень интересной задачей, в результате удалось придумать их около 20. Результат был довольно высок, и его удалось еще улучшить, добавив несколько регулярных выражений. Обучение проводилось на наборе данных OpenCorpora, поэтому остались ошибки, связанные со словами, специфичными для кулинарной тематики: например, сокращение ч. л. (чайная ложка) разбивалось на два предложения. На многих страницах сайта povarenok.ru было размечено краткое содержание статьи, чем мы не могли не воспользоваться. В случае если все слова из запроса встречались лишь в заголовке страницы, то в качестве сниппета показывалось именно оно.
***
Возможно, в будущем мы продолжим публикации выпускных проектов, следите за обновлениями нашего блога!
Техносфера Mail.Ru — один из многих образовательных проектов Mail.Ru Group, объединенных на платформе IT.Mail.Ru, созданной для тех, кто увлекается IT и стремится профессионально развиваться в этой сфере. На ней также представлены чемпионаты Russian Ai Cup, Russian Code Cup и Russian Developers Cup, образовательные проекты Технопарк в МГТУ им. Баумана и Технотрек в МФТИ. Кроме того, на IT.Mail.Ru можно с помощью тестов проверить свои знания по популярным языкам программирования, узнать важные новости из мира IT, посетить или посмотреть трансляции с профильных мероприятий и лекции на IT-тематику.
