

Всем привет. Кто-то из вас, возможно, уже знаком с СУБД для данных в оперативной памяти, но на всякий случай — по ссылке можно найти их общее описание. Если вкратце, такие СУБД хранят данные целиком в оперативной памяти. Что это означает? Каждый раз, отправляя запрос на поиск или обновление данных, вы обращаетесь только к оперативной памяти в обход жесткого диска — на нем никакие операции не производятся. И это хорошо, потому что оперативная память работает намного быстрее любого диска. Примером такой СУБД является Memcached.
Секундочку, скажете вы, а как же восстановить данные после перезагрузки или поломки машины с такой СУБД? Если на машине установлена СУБД для хранения данных только в оперативной памяти, о них можно забыть: при отключении питания данные бесследно исчезнут.
Можно ли объединить достоинства хранения данных в оперативной памяти с надежностью проверенных временем СУБД вроде MySQL или Postgres? Конечно! Повлияет ли это на производительность? Вы удивитесь, но нет!
Встречайте СУБД для данных в оперативной памяти, обеспечивающие их сохранность: Redis, Aerospike, Tarantool.
Вы можете спросить, как же эти СУБД обеспечивают сохранность данных? Фокус в том, что все данные по-прежнему хранятся в оперативной памяти, но каждая операция вдобавок записывается в расположенный на диске журнал транзакций. Посмотрите на изображение ниже:
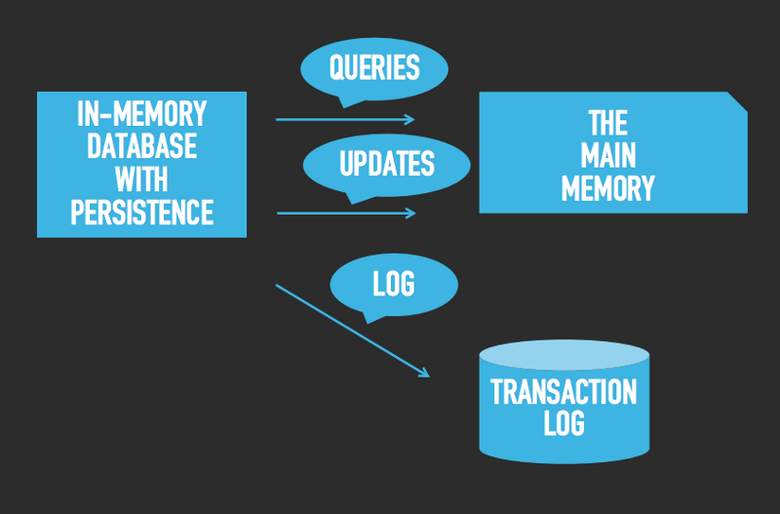
Первое, что вы, возможно, вынесете из этой схемы, — скорость исполнения запросов нисколько не страдает, несмотря на то что теперь СУБД постоянно создает записи в журнале. Производительность при этом не проседает, потому что все запросы по-прежнему обращаются напрямую к оперативной памяти. Отличные новости! :-) А как обстоят дела с обновлением данных? Каждое обновление (назовем его транзакцией) не только происходит в оперативной памяти, но и записывается на диск. На медленный диск. Такая ли это проблема? Давайте посмотрим на следующее изображение:

Транзакции всегда записываются в самый конец журнала. В чем плюс такого подхода? Диск работает довольно быстро. Если говорить о классическом жестком диске (HDD), он может записывать данные в конец файла со скоростью до 100 Мбайт/с. Не верите? Запустите этот тест из командной строки в Unix/Linux/macOS:
cat /dev/zero >some_fileИ посмотрите, как быстро увеличивается размер
some_file. Итак, жесткий диск весьма проворен при последовательной записи, однако его скорость резко падает при произвольной записи: обычно он способен выполнить около 100 таких операций. При побайтовой записи, когда каждый байт записывается в произвольное место на жестком диске, вы можете увидеть, что реальная максимальная производительность диска составляет 100 байтов/с. Еще раз, всего-навсего 100 байтов/с! Разница в шесть порядков между пессимистичной (100 байтов/с) и оптимистичной (100 000 000 байтов/с) оценками скорости доступа к диску столь велика потому, что для поиска по произвольному сектору на диске требуется физическое движение головки диска, тогда как при последовательном доступе можно считывать данные по мере вращения диска; головка при этом остается неподвижной.
Если говорить о твердотельном накопителе (SSD), здесь ситуация лучше из-за отсутствия движущихся частей. Однако соотношение пессимистичной (1—10 тысяч операций в секунду) и оптимистичной (200—300 Мбайт/с) оценок остается практически неизменным: четыре-пять порядков. Подробнее с этими показателями можно ознакомиться по ссылке.
Таким образом, наша СУБД для данных в оперативной памяти, по сути, наводняет журнал транзакциями со скоростью до 100 Мбайт/с. Достаточно ли это быстро? Очень быстро. Предположим, размер транзакции составляет 100 байтов, тогда скорость будет равняться миллиону транзакций в секунду! Это настолько хороший показатель, что вам абсолютно точно не придется волноваться о производительности диска при использовании подобной СУБД. По ссылке ниже находится подробный тест производительности одной СУБД в оперативной памяти при обработке миллиона транзакций в секунду, где проблемным элементом является не диск, а процессор:
→ https://gist.github.com/danikin/a5ddc6fe0cedc6257853.
Подведем итог всему вышесказанному о дисках и СУБД в оперативной памяти:
- СУБД в оперативной памяти не обращаются к диску при обработке запросов, не изменяющих данные.
- СУБД в оперативной памяти все-таки обращаются к диску при обработке запросов, изменяющих данные, но работают с ним на максимальной скорости.
Почему же традиционные дисковые СУБД не берут на вооружение описанные техники? Во-первых, в отличие от СУБД в оперативной памяти, в традиционных СУБД необходимо считывать данные с диска при каждом запросе (давайте ненадолго забудем про кеширование, это тема для отдельной статьи). Заранее неизвестно, каков следующий запрос, поэтому можно считать, что каждый раз будет требоваться произвольный доступ к диску, а это, напомню, пессимистичный сценарий.
Во-вторых, дисковые СУБД должны сохранять данные таким образом, чтобы измененные данные можно было немедленно считать, в отличие от СУБД в оперативной памяти, которые не считывают с диска, за исключением случаев, когда при старте запускается восстановление. Именно поэтому для быстрого считывания дисковым СУБД нужны особые структуры данных, чтобы избежать полного сканирования журнала транзакций.
Одна из таких структур — B/B+-дерево, ускоряющее считывание данных. Недостатком этого дерева является необходимость изменять его при каждом меняющем данные запросе, что может привести к падению производительности из-за произвольного доступа к диску. Довольно много движков СУБД основано на B/B+-деревьях, из популярных можно назвать InnoDB от MySQL и движок Postgres.
Существует другая структура, которая лучше справляется с записью данных, — LSM-дерево. Это относительно новый тип деревьев, который не решает проблему произвольного считывания, но помогает избавиться от части проблем, связанных с произвольной записью. Примерами движков, использующих такие деревья, могут служить RocksDB, LevelDB или Vinyl. На изображении ниже приведена сводная информация о типах СУБД и используемых ими деревьях:

Резюмируем вышесказанное: СУБД в оперативной памяти, обеспечивающие сохранность данных, как при считывании, так и при записи могут работать очень быстро, а точнее — так же быстро, как и СУБД в оперативной памяти, которые не сохраняют данные на диске: первые используют диск настолько эффективно, что он никогда не становится проблемным местом.
P. S.
Последняя — по порядку, но не по значимости — тема, которую я хотел бы затронуть в статье, посвящена снимкам состояния. Снятие таких снимков необходимо для компактификации журналов транзакций. Снимок состояния базы данных — это копия всех имеющихся данных. Снимка и журналов с последними транзакциями достаточно для восстановления состояния вашей базы данных. Поэтому, имея свежий снимок состояния, можно удалять все старые журналы транзакций, предшествующие дате снимка.
Зачем компактифицировать журналы? Потому что чем больше журналов, тем дольше будет восстановление базы данных. И потом, вам ведь не хочется захламлять диск устаревшей и бесполезной информацией (ну хорошо, старые журналы иногда здорово выручают, но давайте поговорим об этом в отдельной статье).
По сути, периодически делая снимки состояния, вы целиком копируете базу данных из оперативной памяти на диск. Как только копирование закончилось, можно смело удалять все журналы, в которых нет транзакций, записанных позже последней транзакции в вашем снимке состояния. Довольно просто, не так ли? А все потому, что все транзакции начиная с самого первого дня попадают в снимок.
Вы могли задаться вопросом: как сохранить консистентное состояние базы данных на диск и как определить последнюю зафиксированную в снимке транзакцию при условии постоянного поступления новых транзакций? Об этом мы поговорим в следующей статье.
