

Сегодня в Лондоне стартовала одна из главных Data Science-конференций года, постараюсь оперативно рассказывать о том, что интересного удалось услышать.
Начало выдалось нервным: в то же утро в этом же центре организовалась массовая встреча свидетелей Иеговы, поэтому найти стойку регистрации КДД было непросто, а когда в итоге нашел — очередь была длиною метров 150-200. Тем не менее, после ~20 минут ожидания получил вожделенный бэйдж и оправился на мастер-класс.
Приватность в анализе данных
Первый мастер-класс был посвящен сохранению приватности при анализе данных. На начало я опоздал, но, судя по всему, особо ничего не потерял — там рассказывали о том, как важна приватность и как злоумышленники могут нехорошо использовать раскрытую приватную информацию. Рассказывают, кстати, вполне уважаемые люди из Google, LinkedIn и Apple. По итогам мастер-класс оставил очень положительное впечатление, слайды все доступны здесь.
Оказывается, уже достаточно давно существует концепция Differential Privacy, идея которой заключается в том, чтобы добавлять шум, затрудняющий установление истинных индивидуальных значений, но сохраняющий возможность восстановления общих распределений. Собственно, есть два параметра:
e — насколько сложно раскрыть данные, и d — насколько искажены ответы. В оригинале концепции предполагается, что между аналитиком и данными присутствует некое промежуточное звено — «Куратор», именно он обрабатывает все запросы и формирует ответы так, чтобы шум скрывал приватные данные. В реальности часто используется модель Local Differential Privacy, в рамках которой данные пользователя остаются на устройстве пользователя (например, мобильном телефоне или ПК), однако при ответе на запросы разработчика приложение с личного устройства отправляет такой пакет данных, который не позволяет выяснить, что же именно ответил данный конкретный пользователь. Хотя при объединении ответов от большого количества пользователей можно с высокой точностью восстановить общую картину.
Хороший пример: опрос «делали ли вы аборт». Если проводить опрос «в лоб», то правду никто не скажет. Но если организовать опрос следующим образом: «подкиньте монетку, если будет орел, то кидайте еще раз и на орла говорите «да», а на решку «нет», иначе ответьте правду», легко получается восстановить истинное распределение при сохранении индивидуальной приватности. Развитием этой идеи стала механика сбора чувствительной статистики Google RAPPOR (RAndomized Privacy-Preserving Ordinal Report), использовавшаяся для сбора данных об использовании Chrome и его форков.
Сразу после выхода Хрома в open source появилось достаточно большое количество желающих сделать собственный браузер с переопределенной домашней страницей, поисковым движком, собственными рекламными плашками и т.д. Естественно, пользователи и Google от этого были не в восторге. Дальнейшие действия в целом понятны: выяснить наиболее распространенные подмены и придавить административно, но вышел нежданчик… Политика приватности Chrome не позволяла Google взять и собрать информацию о настройке домашней страницы и поисковика пользователя :(
Чтобы преодолеть это ограничение и создали RAPPOR, который работает следующим образом:
- Данные по домашней странице записываются в небольшой, порядка 128 бит, bloom-фильтр.
- К этому bloom-фильтру добавляется перманентный белый шум. Перманентный = одинаковый для этого пользователя, без сохранения шума множественными запросами можно было бы раскрыть данные пользователя.
- Поверх постоянного шума накладывается индивидуальный шум, генерируемый для каждого запроса.
- Получившийся битовый вектор отсылается в Google, где начинается дешифровка общей картины.
- Сначала статистическими методами вычитаем из общей картины эффект от шума.
- Далее строим битовые векторы кандидатов (самые популярные сайты/поисковики в принципе).
- Используя полученные векторы в качестве базиса, строим линейную регрессию для восстановления картины.
- Комбинируем линейную регрессию с ЛАССО для подавления иррелевантных кандидатов.
Схематично построение фильтра выглядит так:

Опыт внедрения RAPPOR оказался очень положительным, и количество собранных с его помощью приватных статистик быстро увеличивается. Среди основных факторов успеха авторы выделили:
- Простоту и понятность модели.
- Открытость и документированность кода.
- Наличие на итоговых графиках границ ошибок.
Однако у такого подхода есть и существенное ограничение: необходимо иметь списки ответов-кандидатов для расшифровки (именно поэтому O — Ordinal). Когда Apple начать собирать статистику об используемых в текстовых сообщениях словах и эмоджи стало понятно, что этот подход не годится. В результате на конференции WDC-2016 одной из топовых новых заявленных фич в iOS стало добавление differential privacy. В качестве основы также была использована комбинация структуры-скетча с добавлением шума, однако пришлось решить много технических проблем:
- Клиент (телефон) должен иметь возможность за разумное время этот ответ построить и вместить в память.
- Далее этот ответ должен быть упакован в ограниченное по размеру сетевой сообщение.
- На стороне Apple всё это должно быть агрегируемо за разумное время.
В итоге пришли к схеме с использованием count-min-sketch для кодирования слов, далее случайным образом выбирался ответ только одной из хеш-функций (но с фиксацией выбора для пары пользователь/слово), вектор преобразовывался с помощью Hadamard transform и на сервер отправлялся только один значащий «бит» для выбранной хеш-функции.
Для восстановления результата на сервере также надо было просмотреть гипотезы-кандидаты. Но, выяснилось что при большом размере словаря это слишком сложно даже для кластера. Нужно было как-то эвристически выбирать наиболее перспективные направления поиска. Эксперимент с использование биграмм как начальных точек, из которых затем можно собрать мозаику, оказался неудачным — все биграммы были примерно одинаково популярны. Подход биграмма+хеш слова решал проблему, но вел к нарушению приватности. В итоге остановились на префиксных деревьях: статистика собиралась по начальным частям слова и далее по слову целиком.
Тем не менее, анализ исследовательским сообществом используемого Apple алгоритма приватности показал, что при долговременном сборе статистики приватность всё-таки может быть скомпрометирована.
В более сложной ситуации оказался LinkedIn с его исследованием распределения зарплат пользователей. Дело в том, что differential privacy хорошо работает, когда у нас есть очень большое количество измерений, иначе не удается надежно вычесть шум. В зарплатном же опросе количество отчетов ограничено, и LinkedIn решил пойти по другому пути: совместить технические инструменты криптографии и кибербезопасности с концепцией k-Anonymity: данные пользователя считаются достаточно замаскированы, если подавать их пачкой, где есть k ответов с одинаковыми входными атрибутами (например, местоположение и профессия), отличающиеся только целевой переменной (зарплата).
В итоге был построен комплексный конвейер, в котором разные сервисы передают друг другу куски данных, постоянно шифруя так, что раскрыть их целиком не может одна отдельно взятая машина. В итоге пользователи делятся по атрибутам на когорты, и по достижении когортой минимального размера её статистика уходит в HDFS для анализа.
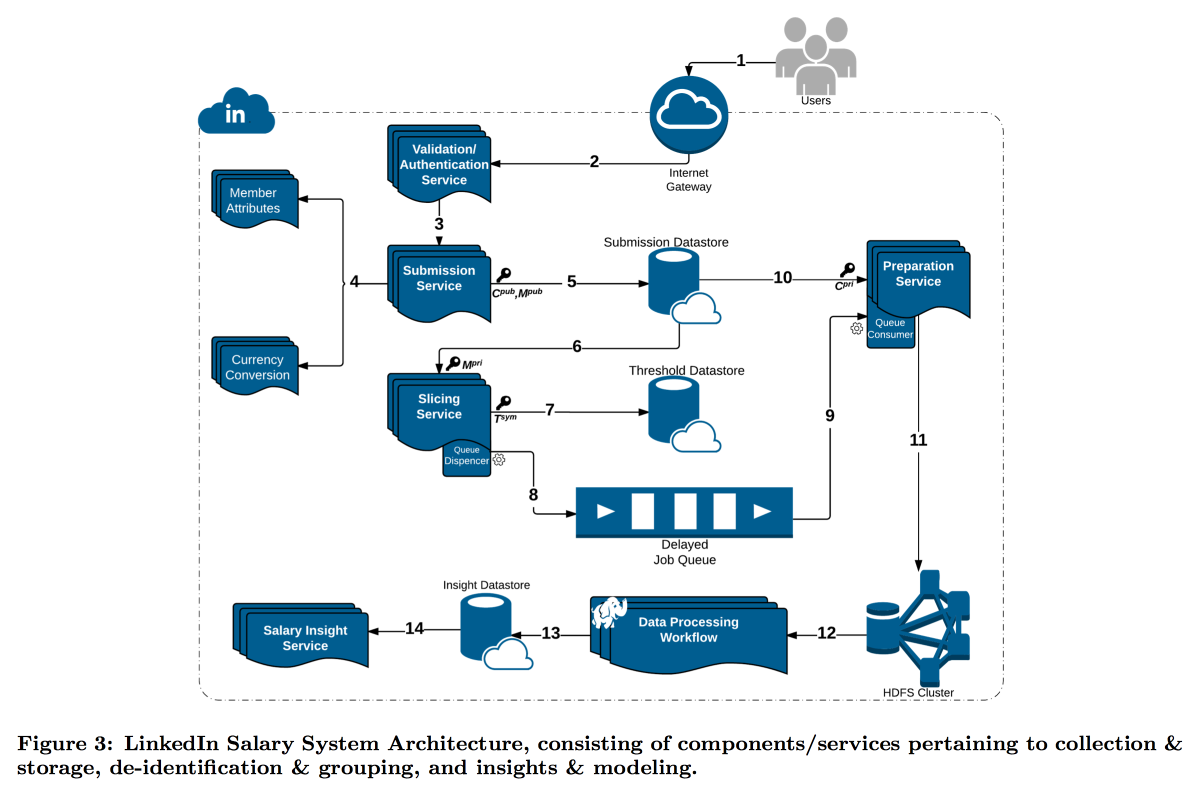
Отдельного внимания заслуживает таймстамп: его тоже необходимо анонимизировать, иначе по логу заходов можно выяснить, чей-же это ответ. Но целиком убирать время не хочется, ведь интересно следить за динамикой. В итоге решили добавить таймстамп к атрибутам, по которым строится когорта, и усреднять его значение в ней.
В результате получилась интересная премиум-фича и несколько интересных открытых вопросов:
GDPR предполагает, что по запросу мы должны уметь удалять все данные пользователя, но мы так постарались спрятать, что теперь не можем найти, чьи-же это данные. Имея данные по большому количеству разных срезов/когорт, можно вычленить соответствия и расширить список открытых атрибутов
Этот подход работает для данных большой размерности, но не работает с непрерывными данными. Практика показывает, что просто дискретизировать данные не очень хорошая идея, но Microsoft на NIPS2017 предложил решение, как с этим работать. К сожалению, подробности раскрыть уже не успели.
Анализ больших графов
Второй мастер-класс по анализу больших графов начался после обеда. Несмотря на то, что вели его тоже ребята из Google, и ожиданий от него было больше, понравился он гораздо меньше — рассказывали про свои закрытые технологии, то пускаясь в банальщину и общую философию, то погружаясь в дикие подробности, не успев даже сформулировать задачу. Тем не менее, некоторые интересные аспекты смог уловить. Слайды можно найти здесь.
Во первых, понравилась схема под названием ego-network clustering, думаю, на её основе можно построить интересные решения. Идея очень простая:
- Рассматриваем локальный граф с точки зрения конкретного пользователя, НО за вычетом его самого.
- Кластеризуем этот граф.
- Далее «клонируем» вершину нашего пользователя, добавляя по экземпляру на каждый кластер и не связывая их друг с другом ребрами.
В подобном преобразованном графе многие проблемы решаются проще и алгоритмы ранжирования работают чище. Например, гораздо проще такой граф сбалансированно партиционировать, а при ранжировании в рекомендации друзей узлы-мосты гораздо меньше шумят. Именно для задачи рекомендации друзей ENC и рассматривали/продвигали.
Но в целом ENC был только примером, в Google целый отдел занимается разработкой алгоритмов на графах и поставляет их другим отделам в качестве библиотеки. Заявленная функциональность библиотеки впечатляет: библиотека мечты для SNA, но всё закрыто. В лучшем случае отдельные блоки можно постараться воспроизвести по статьям. Утверждается, что у библиотеки сотни внедрений внутри Google, в том числе на графах с более чем триллионом рёбер.
Далее было примерно минут 20 рекламной акции модели MapReduce, будто мы сами не знаем, насколько она крутая. После чего ребята показали, что многие сложные задачи можно решить (приблизительно) по модели Randomized Composable Core Sets. Основная идея заключается в том, что данные о ребрах случайным образом раскидываются на N узлов, там втягиваются в память и задача решается локально, после чего результаты решения передаются на центральную машину и агрегируются. Утверждается, что таким образом можно задешево получить хорошие аппроксимации для многих проблем: компоненты связности, минимальный остовный лес, max matching, max coverage и т.д. В некоторых случаях, при этом, и на mapper, и в reduce решается одна и та же задача, но могут быть и немного разные. Наглядный пример того, как умно назвать простое решение, чтобы в него поверили.
Затем пошел разговор про то, ради чего я сюда и шел: про Balanced Graph Partitioning. Т.е. как порезать граф на N частей так, чтобы части были примерно равного размера, а количество связей внутри частей значительно превышало количество внешних связей. Если уметь хорошо решать такую задачу, то очень многие алгоритмы становятся проще, и даже А/Б-тесты можно запускать более качественно, с компенсацией вирусного эффекта. Но рассказ немного разочаровал, все выглядело как «гномий план»: присваиваем номера на базе иерархической аффинной кластеризации, двигаем, добавляем имбаланс. Без подробностей. Про это на KDD будет позже отдельный доклад от них же, попробую сходить. Плюс есть блогпост.
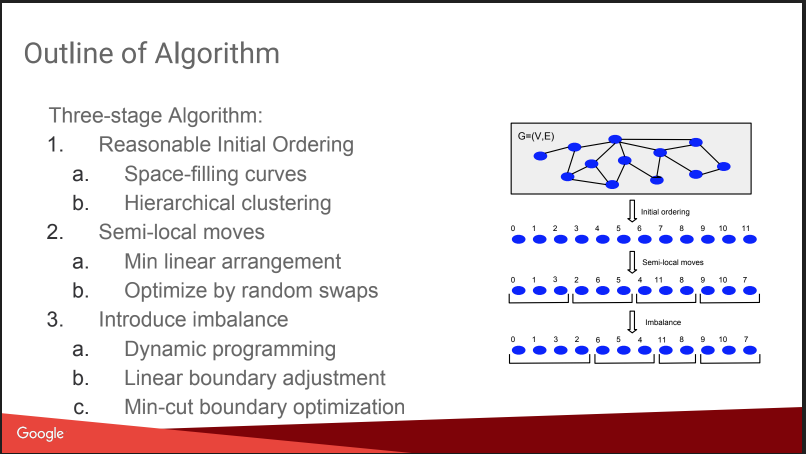
Тем не менее, дали сравнение с некоторыми конкурентами, часть из них открыта: Spinner, UB13 от FB, Fennel от Микрософта, Metis. Можно посмотреть и на них тоже.
Дальше немного рассказывали про технические подробности. У них используется несколько парадигм работы с графами:
- MapReduce поверх Flume. Не знал, что так можно — Flume ведь для сбора, а не для анализа данных, в интернете тоже не пишут особо. Думаю, что это внутригугловое извращение. UPD: Выяснил, что это действительно внутренний продукт Google, ничего общего с Apache Flume не имеющий, есть некий его эрзац в облаке под названием dataflow
- MapReduce + Distributed Hash Table. Говорят, что помогает значительно сократить количество раундов МР, но в инете про эту методику тоже не так много написано, например, тут
- Pregel — говорят, что скоро сдохнет.
- ASYnchronous Message Passing — самая крутая, быстрая и перспективная.
Идея ASYMP очень похожа на Pregel:
- узлы распределены, держат своё состояние и могу послать сообщение соседям;
- на машине строится очередь с приоритетами, что куда слать (порядок может отличаться от порядка добавления);
- получив сообщение, узел может поменять или не поменять состояние, при изменении шлём сообщение соседям;
- заканчиваем, когда все очереди пустые.
Например, при поиске компонентов связности инициализируем всем вершинам случайные веса U[0,1], после чего начинаем слать друг другу минимум по соседям. Соответственно, получив от соседей их минимумы, ищем минимум по ним и т.д., пока минимум не стабилизируется. Отмечают важный момент для оптимизации: схлопывать сообщения от одной ноды (для этого и очередь), оставляя только последнее. Также говорят про то, как легко делать восстановление после сбоев, сохраняя состояния нод.
Говорят, что без проблем строят очень быстрые алгоритмы, похоже на правду — концепт простой и рациональный. Есть публикации.
В итоге напрашивается вывод: ходить на рассказы про закрытые технологии грустно, но некоторые полезные биты удается ухватить.
