

Источник: unsplash.com
По словам Джеки Стюарта, трехкратного чемпиона мира по гонкам Формулы-1, понимание автомобиля помогло ему стать лучшим пилотом: «Гонщику не обязательно быть инженером, но нужен интерес к механике».
Мартин Томпсон (создатель LMAX Disruptor) применил эту концепцию к программированию. Если в двух словах, то понимание базового оборудования улучшит ваши навыки, когда речь заходит о разработке алгоритмов, структур данных и так далее.
Команда Mail.ru Cloud Solutions перевела статью, автор которой углубился в устройство процессора и рассмотрел, как понимание некоторых концепций CPU помогает принимать оптимальные решения.
Основы
Современные процессоры основаны на концепции симметричной многопроцессорности (SMP). Процессор сконструирован таким образом, что два или более ядра разделяют общую память (также называемую основной или оперативной памятью).
Кроме того, для ускорения доступа к памяти в процессоре несколько уровней кэша: L1, L2 и L3. Точная архитектура зависит от производителя, модели CPU и других факторов. Тем не менее чаще всего кэши L1 и L2 работают локально для каждого ядра, а L3 общий для всех ядер.

Архитектура SMP
Чем ближе кэш к ядру процессора, тем меньше задержка доступа и размер кэша:
| Кэш | Задержка | Циклы CPU | Размер |
| L1 | ~1,2 нс | ~4 | Между 32 и 512 КБ |
| L2 | ~3 нс | ~10 | Между 128 КБ и 24 МБ |
| L3 | ~12 нс | ~40 | Между 2 и 32 МБ |
Опять же, точные цифры зависят от модели процессора. Для приблизительной оценки: если доступ к основной памяти занимает 60 нс, доступ к L1 примерно в 50 раз быстрее.
В мире процессоров существует важное понятие локальности ссылок. Когда процессор обращается к определенной ячейке памяти, очень вероятно, что:
- Он обратится к той же ячейке памяти в ближайшем будущем — это принцип локальности по времени.
- Он обратится к ячейкам памяти, расположенным поблизости, — это принцип локальности по расстоянию.
Локальность по времени — одна из причин существования кэшей CPU. Но как использовать локальность по расстоянию? Решение — вместо копирования в кэши CPU одной ячейки памяти туда копируется строка кэша. Строка кэша — это непрерывный сегмент памяти.
Размер строки кэша зависит от уровня кэша (и опять же от модели процессора). Например, вот размер строки кэша L1 на моей машине:
$ sysctl -a | grep cacheline
hw.cachelinesize: 64
Вместо того, чтобы копировать в кэш L1 единственную переменную, процессор копирует туда непрерывный сегмент в 64 байта. Например, вместо копирования единственного элемента int64 среза Go, он cкопирует этот элемент плюс еще семь элементов int64.
Конкретное применение строк кэша в Go
Рассмотрим конкретный пример, который покажет преимущества процессорных кэшей. В следующем коде мы складываем две квадратные матрицы из элементов int64:
func BenchmarkMatrixCombination(b *testing.B) {
matrixA := createMatrix(matrixLength)
matrixB := createMatrix(matrixLength)
for n := 0; n < b.N; n++ {
for i := 0; i < matrixLength; i++ {
for j := 0; j < matrixLength; j++ {
matrixA[i][j] = matrixA[i][j] + matrixB[i][j]
}
}
}
}
Если
matrixLength равно 64k, это приводит к следующему результату:BenchmarkMatrixSimpleCombination-64000 8 130724158 ns/op
Теперь вместо
matrixB[i][j] мы добавим matrixB[j][i]:func BenchmarkMatrixReversedCombination(b *testing.B) {
matrixA := createMatrix(matrixLength)
matrixB := createMatrix(matrixLength)
for n := 0; n < b.N; n++ {
for i := 0; i < matrixLength; i++ {
for j := 0; j < matrixLength; j++ {
matrixA[i][j] = matrixA[i][j] + matrixB[j][i]
}
}
}
}
Повлияет ли это на результаты?
BenchmarkMatrixCombination-64000 8 130724158 ns/op
BenchmarkMatrixReversedCombination-64000 2 573121540 ns/op
Да, повлияло, и весьма радикально! Как это объяснить?
Попробуем нарисовать то, что происходит. Синий круг указывает на первую матрицу, а розовый — на вторую. Когда мы устанавливаем
matrixA[i][j] = matrixA[i][j] + matrixB[j][i], синий указатель находится в позиции (4,0), а розовый — в позиции (0,4):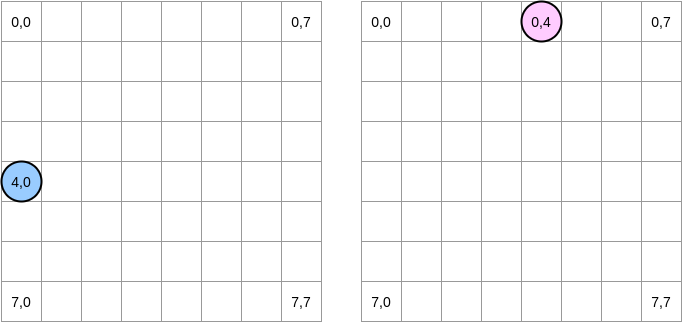
Примечание. На этой диаграмме матрицы представлены в математическом виде: с абсциссой и ординатой, а позиция (0,0) находится в левом верхнем квадрате. В памяти все строки матрицы располагаются последовательно. Однако для большей ясности давайте рассмотрим математическое представление. Более того, в следующих примерах размер матрицы кратен размеру строки кэша. Следовательно, строка кэша не будет «догоняться» на следующем ряду. Звучит сложно, но по примерам всё станет понятно.
Как будем перебирать матрицы? Синий указатель перемещается вправо, пока не достигнет последнего столбца, а затем переходит к следующей строке в позиции (5,0) и так далее. Наоборот, розовый указатель перемещается вниз, а затем переходит к следующему столбцу.
Когда розовый указатель достигает позиции (0,4), процессор кэширует всю строку (в нашем примере размер строки кэша равен четырем элементам). Поэтому, когда розовый указатель достигает положения (0,5), мы можем предположить, что переменная уже присутствует в L1, не так ли?
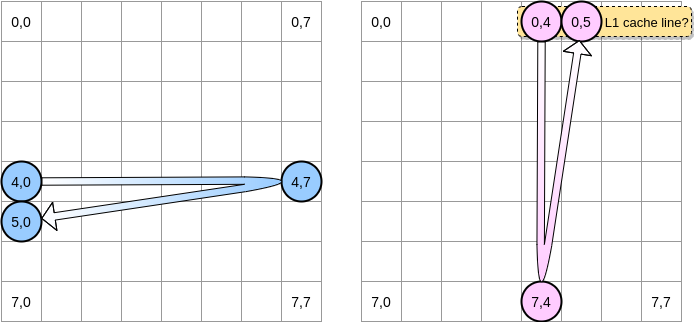
Ответ зависит от размера матрицы:
- Если матрица достаточно мала по сравнению с размером L1, то да, элемент (0,5) уже будет кэширован.
- В противном случае строка кэша будет удалена из L1 до того, как указатель достигнет позиции (0,5). Поэтому он будет генерировать промах кэша, и процессору придется обращаться к переменной по-другому, например через L2. Мы будем в таком состоянии:
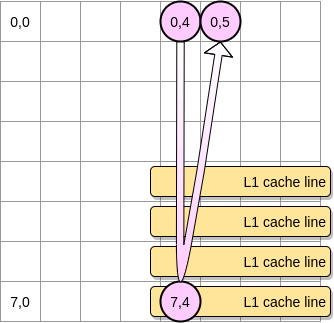
Насколько мала должна быть матрица, чтобы получить выгоду от L1? Давайте немного посчитаем. Во-первых, нужно знать размер кэша L1:
$ sysctl hw.l1dcachesize
hw.l1icachesize: 32768
На моей машине кэш L1 составляет 32 768 байт, тогда как строка кэша L1 — 64 байта. Таким образом, я могу хранить в L1 до 512 строк кэша. Что, если мы запустим тот же бенчмарк с матрицей из 512 элементов?
BenchmarkMatrixCombination-512 1404 718594 ns/op
BenchmarkMatrixReversedCombination-512 1363 850141 ns/opp
Хотя мы устранили разрыв (на матрице 64k разница была примерно в 4 раза), но всё еще можем заметить небольшую разницу. Что может быть не так? В бенчмарках мы работаем с двумя матрицами. Следовательно, процессор должен хранить строки кэша обоих. В идеальном мире (без других запущенных приложений и так далее), кэш L1 на 50% заполнен данными из первой матрицы и на 50% из второй. Что, если уменьшить размер матрицы вдвое, чтобы работать с 256 элементами:
BenchmarkMatrixCombination-256 5712 176415 ns/op
BenchmarkMatrixReversedCombination-256 6470 164720 ns/op
Наконец, мы достигли точки, где два результата (почти) эквивалентны.
Примечание. Почему второй бенчмарк немного быстрее первого? Разница выглядит довольно тонкой и связана с ассемблерным кодом, который создает Go. Во втором случае указатель на вторую матрицу управляется по-другому с помощью команды LEA (Load Effective Address). Когда процессору необходимо получить доступ к ячейке памяти, происходит перевод из виртуальной в физическую память. Использование LEA позволяет вычислить адрес памяти без необходимости проходить через этот перевод.
Например, если мы управляем фрагментом элементов int64 и у нас уже есть указатель на адрес первого элемента, мы можем использовать LEA для загрузки адреса второго элемента, просто сместив указатель на 8 байтов. В нашем примере это может быть потенциальной причиной того, что второй тест выполняется быстрее. Тем не менее я не эксперт по ассемблеру, так что не стесняйтесь оспаривать этот анализ. Если что, я выложил ассемблерный код первой и второй (обратной) функции.
Теперь — как ограничить влияние промахов кэша в случае более крупной матрицы? Существует метод, который называется оптимизация вложенных циклов (loop nest optimization). Чтобы извлечь максимальную выгоду из строк кэша, мы должны выполнять итерации только в пределах данного блока.
Давайте определим в нашем примере блок как квадрат из 4 элементов. В первой матрице мы перебираем от (4,0) до (4,3). Затем переходим к следующему ряду. Соответственно, мы перебираем вторую матрицу только от (0,4) до (3,4), прежде чем перейти к следующему столбцу.
Когда розовый указатель ходит по первому столбцу, процессор сохраняет соответствующую строку кэша. Таким образом, перебор по остальной части блока означает получение выгоды от L1:
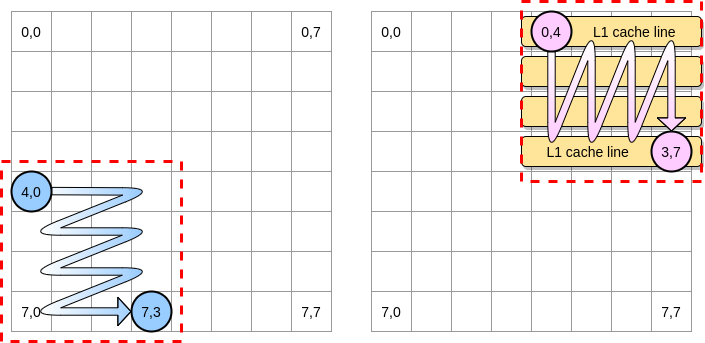
Напишем реализацию этого алгоритма на Go, но сначала мы должны тщательно выбрать размер блока. В предыдущем примере он был равен строке кэша. Он не должен быть меньше, иначе мы будем хранить элементы, к которым не будет доступа.
В нашем бенчмарке Go мы храним элементы int64 (по 8 байт). Строка кэша составляет 64 байта, поэтому она вмещает 8 элементов. Тогда значение размера блока должно быть не менее 8:
func BenchmarkMatrixReversedCombinationPerBlock(b *testing.B){
matrixA := createMatrix(matrixLength)
matrixB := createMatrix(matrixLength)
blockSize := 8
for n := 0; n < b.N; n++ {
for i := 0; i < matrixLength; i += blockSize {
for j := 0; j < matrixLength; j += blockSize {
for ii := i; ii < i+blockSize; ii++ {
for jj := j; jj < j+blockSize; jj++ {
matrixA[ii][jj] = matrixA[ii][jj] + matrixB[jj][ii]
}
}
}
}
}
}
Наша реализация теперь более чем на 67% быстрее, чем когда мы перебирали всю строку/столбец:
BenchmarkMatrixReversedCombination-64000 2 573121540 ns/op
BenchmarkMatrixReversedCombinationPerBlock-64000 6 185375690 ns/op
Это был первый пример, демонстрирующий, что понимание работы кэшей CPU может помочь в разработке более эффективных алгоритмов.
False sharing
Теперь мы понимаем, как процессор управляет внутренними кэшами. В качестве быстрого резюме:
- Принцип локальности по расстоянию заставляет процессор забирать не просто один адрес памяти, а строку кэша.
- Кэш L1 является локальным для одного ядра процессора.
Теперь обсудим пример с когерентностью кэша L1. В основной памяти хранятся две переменные
var1 и var2. Один поток на одном ядре обращается к var1, тогда как другой поток на другом ядре обращается к var2. Предполагая, что обе переменные непрерывны (или почти непрерывны), мы оказываемся в ситуации, когда var2присутствует в обоих кэшах.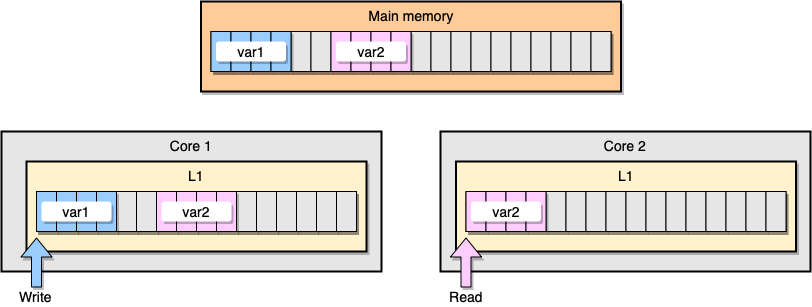
Пример кэша L1
Что произойдет, если первый поток обновит свою строку кэша? Потенциально он может обновить любое местоположение своей строки, включая
var2. Затем, когда второй поток считывает var2, значение может оказаться не согласованным.Как процессор сохраняет когерентность кэша? Если у двух строк кэша общие адреса, процессор помечает их как общие(shared). Если один поток изменяет общую строку, он помечает обе как измененные (modified). Чтобы гарантировать когерентность кэшей, требуется координация между ядрами, что может значительно снизить производительность приложения. Эта проблема называется false sharing (ложный обмен информацией).
Рассмотрим конкретное приложение на Go. В этом примере мы создаем две структуры одну за другой. Следовательно, эти структуры должны располагаться в памяти последовательно. Затем создаем две горутины, каждая из них обращается к своей структуре (M — это константа, равная миллиону):
type SimpleStruct struct {
n int
}
func BenchmarkStructureFalseSharing(b *testing.B) {
structA := SimpleStruct{}
structB := SimpleStruct{}
wg := sync.WaitGroup{}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(2)
go func() {
for j := 0; j < M; j++ {
structA.n += j
}
wg.Done()
}()
go func() {
for j := 0; j < M; j++ {
structB.n += j
}
wg.Done()
}()
wg.Wait()
}
}
В этом примере переменная n второй структуры доступна только второй горутине. Тем не менее поскольку структуры смежны в памяти, переменная будет присутствовать в обеих строках кэша (предполагая, что обе горутины запланированы на потоках на отдельных ядрах, что необязательно так). Вот результат бенчмарка:
BenchmarkStructureFalseSharing 514 2641990 ns/op
Как предотвратить ложный обмен информацией? Одним из решений является заполнение памяти (memory padding). Наша цель гарантировать, что между двумя переменными достаточно места, чтобы они принадлежали к разным строкам кэша.
Во-первых, создадим альтернативу предыдущей структуре, заполнив память после объявления переменной:
type PaddedStruct struct {
n int
_ CacheLinePad
}
type CacheLinePad struct {
_ [CacheLinePadSize]byte
}
const CacheLinePadSize = 64
Затем создаем экземпляры двух структур и продолжаем обращаться к этим двум переменным в отдельных горутинах:
func BenchmarkStructurePadding(b *testing.B) {
structA := PaddedStruct{}
structB := SimpleStruct{}
wg := sync.WaitGroup{}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(2)
go func() {
for j := 0; j < M; j++ {
structA.n += j
}
wg.Done()
}()
go func() {
for j := 0; j < M; j++ {
structB.n += j
}
wg.Done()
}()
wg.Wait()
}
}
С точки зрения памяти, этот пример должен выглядеть, словно две переменные являются частью разных строк кэша:
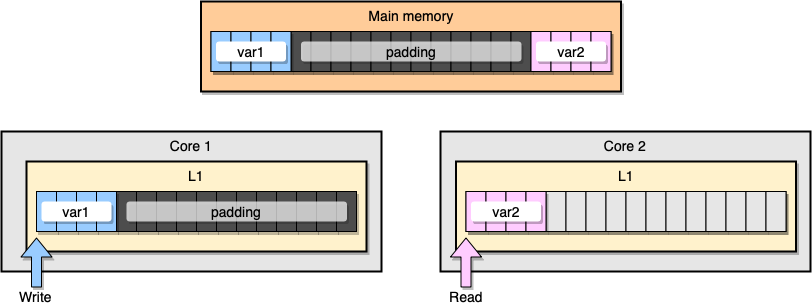
Заполнение памяти
Посмотрим на результаты:
BenchmarkStructureFalseSharing 514 2641990 ns/op
BenchmarkStructurePadding 735 1622886 ns/op
Второй пример с заполнением памяти примерно на 40% быстрее, чем наша первоначальная реализация. Но есть и обратная сторона. Метод ускоряет код, но требует большего объема памяти.
Симпатия к механике — важное понятие, когда речь заходит об оптимизации приложений. В этой статье мы видели примеры, как понимание работы CPU помогло нам повысить скорость программы.
Что еще почитать:
