

Привет, Хабр! Я работаю в команде Антиспама Почты Mail.ru. В этой статье я бы хотел рассказать про наш опыт запуска сервиса с пропускной способностью около 3 миллионов запросов в минуту на базе технологии gRPC. Это современная технология передачи данных по сети, которая реализует подход к удаленному вызову процедур. Разберу, с каким проблемами мы столкнулись при использовании этой технологии под высокой нагрузкой. Все описанное в статье касается реализации gRPC для языка С++.
Предисловие
Перед нашей командой стояла задача по написанию нового сервиса для запуска моделей машинного обучения. Про сами модели и как они работают рассказывать не буду, это тема отдельной статьи. Немного про требования, которые были выставлены к сервису: входной поток примерно 3 миллиона запросов в минуту, среднее время вычисления одной модели не должно превышать 10 миллисекунд, количество самих моделей около 10, но оно может меняться в процессе эксплуатации сервиса. Одним из вопросов, который встал перед нами — писать ли сетевое взаимодействие самим или использовать уже что-то готовое. Обычно все сетевое взаимодействие у нас строилось на базе Boost Asio — это отличная библиотека, для сетевого и низкоуровневого программирования ввода-вывода. Было несколько вариантов, в том числе написать что-то свое, но запуск сервиса мог бы затянуться. После сравнения всех «за» и «против» выбор пал на gRPC. Как видно из туториалов, библиотека проста в использовании и берет на себя все издержки по работе с сетью, что нам полностью подходило.
Помимо уже описанных требований, было еще одно: сервис должен запускаться в Kubernetes. Если кратко, сервис запускается в docker-контейнере на одной из машин кластера. Ему ограничивается потребление памяти и процессорного времени, чтобы железо могло утилизироваться другими проектами, на одной машине может работать много разных сервисов с разными запросами ресурсов. Чтобы было проще зашедулить сервис на ноду, надо выставлять более гранулярные значения для ресурсов, к примеру 4 ядра и 4 гигабайта оперативной памяти. Тогда у планировщика кластера появляется больше возможностей заселить сервис на ноду, если кластер заполнен.
После того как сервис был реализован и задеплоен, мы столкнулись со следующей проблемой: высокое потребление памяти процессом, в пиках значение доходило до 20 гигабайт. При этом все модели, которые загружал сервис, занимали около 2 гигабайт в памяти. Подобная аномалия нас не устраивала, поскольку на лицо было чрезмерно большое потребление памяти (сама логика вычисления моделей никак не могла требовать столько ресурсов). Помимо всего прочего, потребление памяти было не константно, оно увеличивалось с течением времени, что приводило к тому, что процесс убивался OOM-киллером. Далее расскажу, что нам удалось узнать, пока разбирались с этой проблемой.
Большое количество потоков у сервиса
Если хотите понять причину проблемы, надо ее воспроизвести. Желательно локально, чтобы можно было изменять код и сразу видеть результаты. Мы взяли код gRPC-клиента на python из примера в репозитории gRPC и адаптировали его под наши нужды. Далее запускали его и смотрели, что происходит с сервисом. У нас получилось воспроизвести проблему потребления памяти, но что сразу бросилось в глаза: большое количество потоков на стороне сервера. И мы начали более подробно изучать ее.
Она воспроизводилась только при наличии большого количества одновременных подключений (больше 1000), и сервис постоянно находился под нагрузкой. Вывод ps huH p <рid> | wc -l (сколько потоков в данный момент у процесса) показывал значения порядка 50 потоков, при этом большинство из них были заблокированы на gpr_cv_wait в ожидании какого-то события. Это показалось странным, и чтобы разобраться в ситуации, начали смотреть в код gRPC, чтобы понять, как устроен код сервера в gRPC C++. Так вот, сервер использует код из класса ThreadManager, вся основная работа происходит в функции MainWorkLoop. После создания потока, он начинает ожидать события на PollForWork, если раскрутить стек вызовов, то в самом низу будет вызов epoll_wait или другого мультиплексора в зависимости от системы и настроек gRPC.
Дальше мы поняли, что нам интересно выставление статуса WORK_FOUND. При выставлении данного статуса выполняется следующая работа: в самом начале проверяется, превысили ли мы лимит по потокам, которые ждут на PollForWork (декрементируется счетчик num_pollers_, потом идет проверка num_pollers_ < min_pollers_), далее проверка на квоту на создание потока-слушателя, если квота есть, то, перед тем как начать обработку запроса, будет создан новый поток-слушатель. Первая проверка проходит почти всегда, из-за декремента в самом начале и интенсивной нагрузки на сервис. Если не выставлять квоту при создании сервера через SetResourseQuota, то максимальное значение потоков будет равно INT_MAX, а значит и эта проверка пройдет. Получается, после того как была найдена новая задача на исполнение, почти всегда будет создан новый поток-слушатель, а тот поток, который занимался обработкой запроса, помещается в очередь на удаление и висит на том самом gpr_cv_wait. Мы подумали, что можно выставить квоту на использование потоков. В самом начале мы ограничили опцию MAX_POLLERS, которая выставляет квоту на потоки-слушатели, но потоков все равно было много. Это внесло путаницу, потому что ожидалось, что опция ограничит треды. Прочитав документацию, мы поняли, нужный нам функционал — это SetResourseQuota. Выставление квоты ограничит создание потоков в определенный момент времени, но не решит проблему постоянного их создания и удаления. А это довольно тяжелые операции, которые влекут за собой системные вызовы и утилизацию процессорного времени. При этом надо понимать, что у сервиса ограничено процессорное время через cgroups в Kubernetes, и лишний его расход не принесет ничего полезного.
Мы пробовали переписать сервис на асинхронное API, которое предоставляет gRPC, но проблема сохранилась. У сервиса все равно было много потоков, и все они были в режиме ожидания. Потом уже, после изучения самого кода библиотеки, мы поняли, почему ничего не изменилось: синхронное и асинхронное API используют один и тот же код для управления потоками сервера. Такой проблемы нет например в Go, где runtime-планировщик раскидывает горутины (задачи) по системным потокам, а само количество системных потоков выставляется через GOMAXPROCS. По итогу, мы лимитировали что-то, но это не давало ожидаемого улучшения, переписывание на асинхронную модель тоже не помогло. По факту получилось, что исходная конфигурация работает лучше всего, но вот с таким потреблением памяти мы подумывали поставить на gRPC крест.
Потребление памяти
После того как выяснили, что сервис создает много потоков, но с этим мы ничего сделать не можем без патча кода библиотеки, решили сосредоточиться на проблеме потребления памяти. Выше уже было сказано, что сервис имеет верхнее ограничение по потреблению памяти. В нашем случае оно равнялось 15 гигабайтам, но ничего не мешало ему выйти за эту границу. Мы начали разбираться, почему такое происходит и как это можно поправить.
Запустили сервис локально и попробовали дать на него нагрузку. В процессе поняли, что наш клиент на питоне не подходит для этих целей и решили попробовать использовать yandex-tank. Но есть один момент: по умолчанию он обстреливает через phantom, который реализует только HTTP-протокол. А у нас gRPC, нужно было как-то решать вопрос. После изучения документации было найдено решение: коллеги из Яндекса написали сменную пушку для танка под названием pandora. Ее преимущество в том, что пишется свой модуль на Go по примеру, далее собирается бинарник, который вызывается самим танком. Получается, что пушке указывается rps и максимальное количество клиентов, она обстреливает сервис и отдает данные танку, тот занимается построением статистики. Мы написали свой модуль по примеру и запустили его на нашей локальной машине, натравив на сервис, запущенный через valgrind --tool=massif, чтобы тот собрал статистику по потреблению памяти процессом. Получили такую вот картину:

Выше видно, что потребление памяти растет на gpr_malloc, если раскрутить стек вызовов, то увидим в самом низу системный вызов clone, который отвечает за создание нового потока в системе. Теперь нам стало понятно, что высокое потребление памяти — это следствие создания большого количества потоков при работе сервиса. Но непонятно почему оно было таким высоким. Чтобы понять, почему происходит подобная картина, пришлось углубится в теорию работы malloc в glibc (можно прочитать в этой статье). Основной проблемой оказалось то, что каждому потоку выделяется своя арена памяти, с которой он работает. При этом нет общей арены, куда бы складывалась неиспользуемая память после завершения работы потока. Мы начали думать, как это исправить. Примерно в это же время решили попробовать попрофилировать еще через gperftools, чтобы сравнить результаты. К нему надо, помимо libprofiler.so, подключать еще и libtcmalloc.so, чтобы снимать метрики по памяти и выводить их потом в формате callgrind. Загрузили все через LD_PRELOAD и натравили танк. Результат нас удивил:
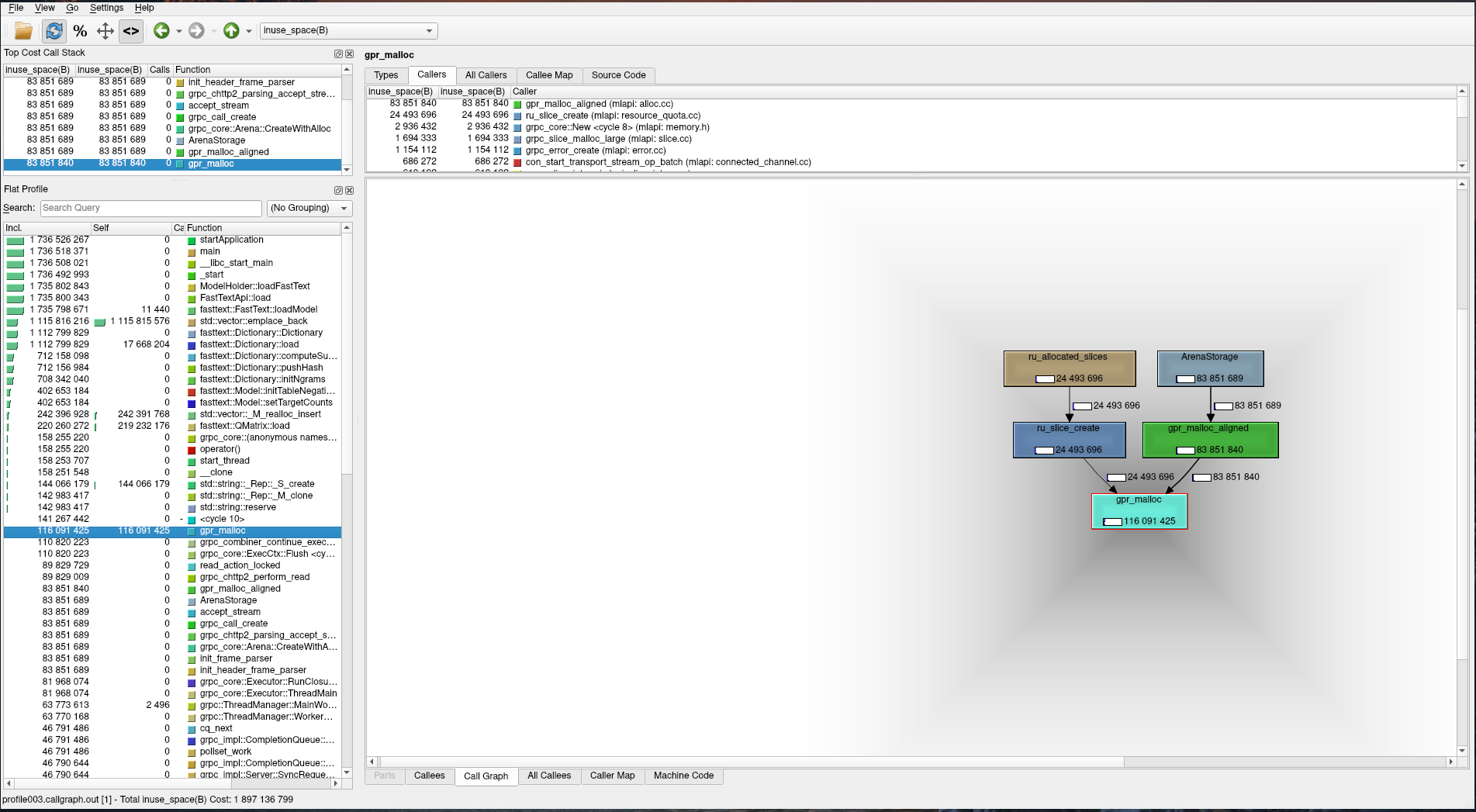
Видно, что общее количество используемой памяти равно примерно 2 гигабайта, а через gpr_malloc было выделено примерно 100 мегабайт против 5 гигабайт в glibc (по тесту выше, на самом деле потребление может расти). При этом в длительном тесте это значение оставалось практически неизменным, тогда как ранее память росла постоянно. Обратились к документации tcmalloc и разобрались, как он устроен внутри. Для каждого потока есть локальный кеш, который контролирует мелкие выделения памяти. Если в кеше ее недостаточно, то память выделяется из списка свободной памяти, который разделяется между всеми потоками. Если и в нем не оказалось достаточно памяти для выполнения запроса, то она запрашивается у системы. После завершения работы потока, вся доступная ему память складывается в общий список доступной памяти, таким образом остальные могут ее переиспользовать.
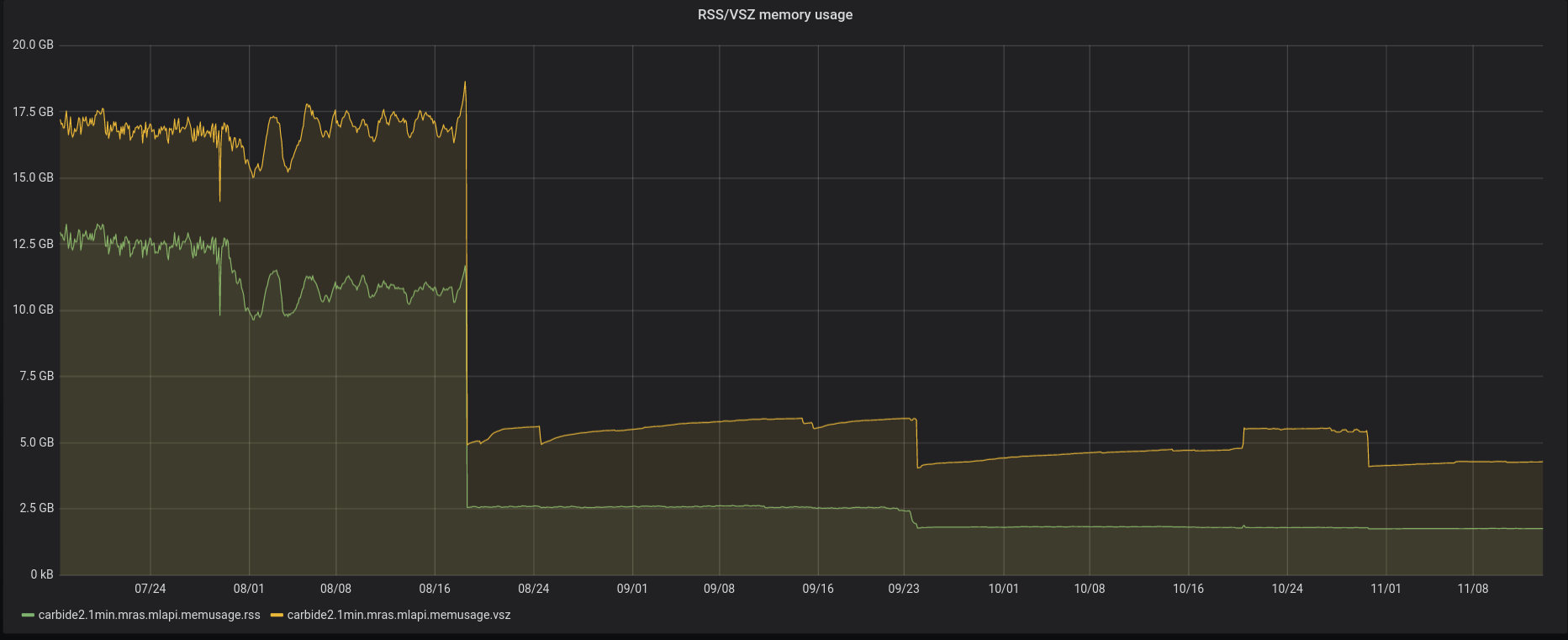
Мы решили попробовать запустить наш сервис с новым аллокатором. Но уже не локально, а на боевом окружении, чтобы увидеть, как поменяется значение потребления памяти. Результат не заставил себя долго ждать. Сразу после смены аллокатора мы получили потребление памяти в районе 2-2.5 гигабайт, которое остается постоянным на протяжении работы сервиса.
Опции keepalive
Есть еще один момент, о котором стоит упомянуть в этой статье. Он связан с тем, как gRPC поддерживает TCP-соединение. В какие-то моменты мы начали замечать, что наше клиентское приложение подвисает и у него подскакивает время обработки одного запроса. Такое происходило не всегда, а только в те моменты времени, когда перекатывался наш сервис для запуска моделей в Kubernetes.
Решили снять дамп памяти приложения через gcore, чтобы понять что оно делало в этот момент. Мы получили стек вызовов и epoll_wait в самом его верху. Сначала мы не поняли в чем дело и полезли разбираться. По стеку вызовов посмотрели кто и что вызывал и с какими параметрами. epoll_wait последним параметром принимает время, которое он ждет, прежде чем вернуть результат. На клиенте задается таймаут, после которого он либо идет в следующий инстанс, либо возвращает ошибку. У нас он равен 50 миллисекунд, но приложение могло висеть секунд 20, и значит дело было в чем-то другом.
Разобраться в проблеме помог вопрос на Stack Overflow, на который мы наткнулись случайно. Оказывается, в gRPC можно управлять опциями keep-alive, тем самым регулируя таймаут, период опроса и разрешения на отправку keepalive-сообщений без текущего вызова RPC-метода. Подробнее можно прочитать в документации.
Нас интересует параметр GRPC_ARG_KEEPALIVE_TIMEOUT_MS, по умолчанию он выставлен в 20 секунд, это как раз совпадало с временем зависания нашего клиента, и мы решили попробовать выставить нужные опции. Помогло выставление опций GRPC_ARG_KEEPALIVE_TIME_MS, GRPC_ARG_KEEPALIVE_TIMEOUT_MS, GRPC_ARG_KEEPALIVE_PERMIT_WITHOUT_CALLS. Как это сделать, можно подсмотреть в этом тесте. Но на этом все не закончилось, был один сервер, на котором все равно были проблемы, по этой же самой причине, зависания клиента. Оказалось, что выставление опций keepalive не работает на CentOS 6 (на этом одном сервере была она установлена): https://github.com/grpc/grpc/pull/16419/files, вот связанные issue: https://github.com/grpc/grpc/issues/15889, https://github.com/grpc/grpc/issues/14685.
Наши выводы
- gRPC — интересная технология, и отлично подходит, когда сервис не занимается тяжелой работой вроде подсчета моделей, но при этом не позволяет достаточно гибко контролировать поведение работы сервера что критично для высоконагруженных проектов;
- у gRPC достаточно много настроек, о которых написано в документации, но о них не узнаешь пока не сталкиваешься с реальными проблемами в бою, при этом из нее не всегда удается понять за что отвечает опция;
- достаточно много примеров и статей про то, как использовать и какой был опыт у людей, но нет информации про то, как оно работает изнутри. Сейчас мы все еще используем gRPC, но при внедрении более вычислительно сложных моделей. Мы не уверены, что оставим данную технологию в продакшене, так как видим риски в ее использовании.
