На рынке много продуктов, подходящих для игровой аналитики: Mixpanel, Localytics, Flurry, devtodev, deltaDNA, GameAnalytics. Но все же многие игровые студии строят свое решение.
Я работал и работаю со многими игровыми компаниями. Я заметил, что по мере роста проектов, в студиях появляется необходимость в продвинутых сценариях аналитики. После того, как несколько игровых компаний заинтересовались данным подходом, было решено задокументировать его в серии из двух статей.
Ответы на вопросы "Почему?", "Как это сделать?" и "Сколько это стоит?" вы найдете под катом.
Почему?
Универсальный комбайн хорош для выполнения простых задач. Но если нужно сделать что-то посложнее, его возможностей не хватает. Например, вышеупомянутые системы аналитики, в разной мере, обладают ограничениями в функционале:
- на количество параметров в событии
- на количество параметров в событиях воронки
- на частоту обновления данных
- на объем данных
- на период расчета данных
- на количество условий воронки
- и другие ограничения в таком же роде
Готовые решения не дают доступ к сырым данным. Например, если нужно провести более детальное исследование. Нельзя забывать и про машинное обучение и предиктивную аналитику. При значительном объеме аналитических данных, можно поиграться со сценариями машинного обучения: предсказание поведения пользователя, рекомендация покупок, персональные предложения и т.д.
Игровые студии часто строят собственные решения не на замену, а в дополнение к уже имеющимся.
Итак, как выглядит своя система аналитики?
Распространенный подход при построении аналитики — это лямбда архитектура, аналитика делится на "горячий" и "холодный" пути. По горячему пути идут данные, которые необходимо обработать с минимальной задержкой (количество игроков онлайн, платежи и т.д.).
По холодному пути идут данные, которые обрабатывают периодически (отчеты за день/месяц/год), а так же сырые данные для долгосрочного хранения.

Например, это полезно при запуске маркетинговых кампаний. Удобно видеть сколько юзеров пришло с кампаний, сколько из них совершили платеж. Это поможет отключить неэффективные каналы рекламы максимально быстро. Учитывая маркетинговые бюджеты игр — это может сэкономить много денег.
К холодному пути относится все остальное: периодические срезы, кастомные отчеты и т.д.
Недостаточная гибкость универсальной системы, как раз, и толкает к разработке собственного решения. По мере того, как игра развивается, необходимость в детальном анализе поведения пользователей возрастает. Ни одна универсальная система аналитики не сравнится с возможностью строить SQL запросы по данным.
Поэтому студии разрабатывают свои решения. Причем, решение, часто, затачивается под конкретный проект.
Студии, разработавшие свою систему, были недовольны тем, что ее приходилось постоянно поддерживать и оптимизировать. Ведь, если проектов много, или они очень большие, то количество собираемых данных растет очень быстро. Своя система начинает все больше тормозить и требовать значительных вкладов по оптимизации.
Как?
Технические риски
Разработка системы аналитики — задача не из простых.
Ниже — пример требований от студии, на которые я ориентировался.
- Хранение большого объема данных: > 3Tb
- Высокая нагрузка на сервис: от 1000 событий в секунду
- Поддержка языка запросов (предпочтительно SQL)
- Обеспечение приемлемой скорости обработки запросов: < 10 min
- Обеспечение отказоустойчивости инфраструктуры
- Обеспечение средств визуализации данных
- Аггрегирование регулярных отчетов
Это — далеко не полный список.
Когда я прикидывал как сделать решение, я руководствовался следующими приоритетами/хотелками:
- быстро
- дешево
- надежно
- поддержка SQL
- возможность горизонтального масштабирования
- эффективная работа с минимум 3Tb данных, опять же масштабирование
- возможность обрабатывать данные real time
Так как активность в играх имеет периодический характер, то решение должно, в идеале, адаптироваться к пикам нагрузки. Например, во время фичеринга, нагрузка возрастает многократно.
Возьмем, например, Playerunknown's Battleground. Мы увидим четко-выраженные пики в течение дня.

Источник: SteamDB
И если посмотреть на рост Daily Active Users (DAU) в течение года, то заметен довольно быстрый темп.

Источник: SteamDB
Не смотря на то, что игра — хит, похожие графики роста я видел и в обычных проектах. В течение месяца количество пользователей вырастало от 2 до 5 раз.
Нужно решение, которое легко масштабировать, но при этом не хочется платить за заранее зарезервированные мощности, а добавлять их, по мере роста нагрузки.
Решение на базе SQL
Решение в лоб — это взять какую-либо SQL БД, направлять туда все данные в сыром виде. Из коробки решает проблему языка запросов.
Напрямую данные с игровых клиентов нельзя направлять в хранилище, поэтому нужен отдельный сервис, который будет заниматься буферизацией событий от клиентов и пересылкой их в БД.
В данной схеме аналитики должны напрямую слать запросы в БД, что чревато. Если запрос тяжелый, БД может встать. Поэтому нужна реплика БД чисто для аналитиков.
Пример архитектуры ниже.

Такая архитектура обладает рядом недостатков:
- Про данные в реальном времени можно сразу забыть
- SQL — мощное средство, но данные ивентов часто не ложатся на реляционную схему, поэтому приходится выдумывать костыли, типа p0-p100500 параметров у событий
- Учитывая объем аналитических данных, собираемых в день, размер БД будет расти как на дрожжах, нужно партиционировать и т.д.
- Аналитик может родить запрос, который будет выполнятся несколько часов, а может даже день, тем самым заблокировав других юзеров. Не давать же каждому свою реплику БД?
- Если SQL on-prem, то нужно будет постоянно заботиться об отказоустойчивости, достаточном объеме свободного места и так далее. Если в облаке — может влететь в копеечку
Решение на базе Apache Stack
Тут стек довольно большой: Hadoop, Spark, Hive, NiFi, Kafka, Storm, и т.д.
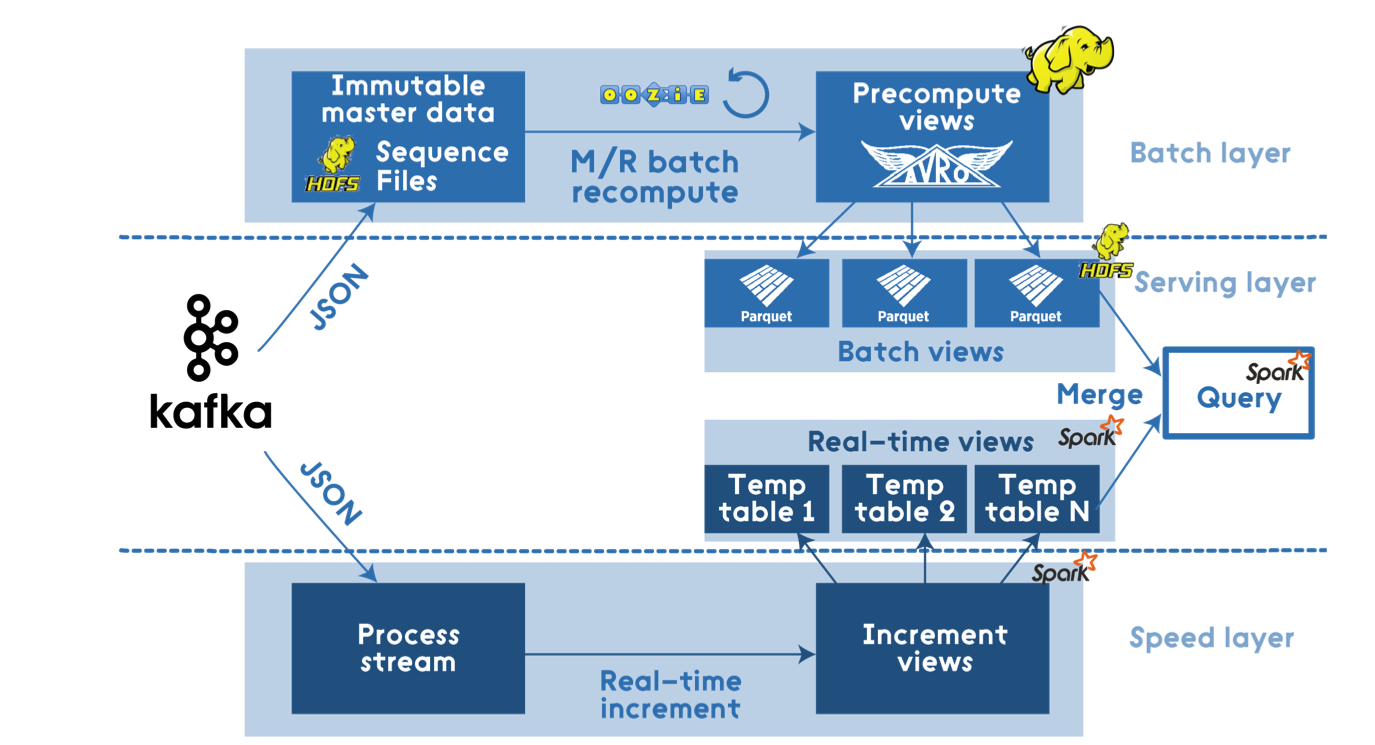
Источник: dzone.com
Такая архитектура точно справится с любыми нагрузками и будет максимально гибкой. Это полноценное решение, которое позволит обрабатывать данные и в реальном времени, и строить зубодробительные запросы по холодным данным.
Но, на самом деле, указанные в требованиях нагрузки сложно назвать BigData, их можно посчитать на единственной ноде. Поэтому Hadoop-based решения — это явный перебор.
Можно начать со Spark Standalone, это выйдет значительно проще и дешевле.
Для приема и предобработки событий, я бы предпочел Apache NiFi вместо Spark.
Управление кластером может значительно упростить Kubernetes на AKS.
Плюсы:
- Максимально гибкое решение, обработчики данных можно писать как чистым кодом, так и использовать Spark SQL
- Open Source стэк, большое коммьюнити
- Хорошая масштабируемость, всегда можно перекинуть все на Hadoop
Минусы:
- Администрирование и поддержка инфраструктуры вручную, хотя и могут быть упрощены с помощью AKS
- Биллинг за виртуалки, не очень выгодно, если большую часть времени они простаивают
- Обеспечение отказоустойчивости решения — нелегкая задача, которой так же нужно заниматься самому
- Так как запросы пишутся кодом — не всем подойдет, все привыкли к SQL, код могут не осилить
Решение на базе облачной платформы
Azure Event Hubs
Azure Event Hubs — простейший концентратор событий с высокой пропускной способностью. Из облачных платформ — наиболее подходящий вариант для приема больших объемов аналитики от клиентов.
Плюсы:
- Автомасштабирование
- Гарантированная надежность и отказоустойчивость
- Довольно низкая цена
Минусы:
- Скудные возможности по управлению событиями/очередями
- Нет встроенных механизмов отслеживания дубликатов сообщений
- Автомасштабирование только вверх
HDInsight
HDInsight — платформа, позволяющая разворачивать готовый к использованию Hadoop кластер, с определенными продуктами типа Spark. Можно откинуть сразу, так как он явный перебор для таких объемов данных, да и очень дорогой.
Azure Databricks
Azure Databricks — это такой Spark на стеройдах в облаке. Databricks — продукт от авторов Spark. Сравнение двух продуктов можно посмотреть здесь. Из плюшек, которые лично мне понравились:
- Поддержка нескольких версий Spark'a
- Комплексное решение, может работать и со стримом событий
- Быстрее, чем vanilla Spark, за счет различных оптимизаций (data skipping, auto caching)
- Приятный web-интерфейс, заточенный под командную работу
- Интерактивный блокноты с поддержкой SQL, Python, R, Scala
- Реал-тайм коллаборация
- Версионирование блокнотов, интеграция с github
- Публикация блокнотов в качестве интерактивных дашбордов
- Встроенная поддержка облачных сторэджей
- Все плюшки облака:
- Легкое масштабирование
- Биллинг за кластер, но с автоскейлингом и авто-терминейтом
- Система job'ов, создающая и убивающая кластер on-demand
Плюсы:
- Автомасштабирование
- Не нужно поддерживать инфраструктуру
- Удобные плюшки для аналитики в виде интерактивных Notebooks
- Гибкий поминутный биллинг за фактически используемое время вычислений
Минусы:
- Неудобный дебаг job'ов
- Отсутствие локального эмулятора для отладки job'ов
Azure Data Lake Analytics (ADLA)
Azure Data Lake Analytics — облачная платформа от Microsoft, которая во многом похожа на Databricks.
Биллинг примерно тот же, но немного более понятный, на мой взгляд. Здесь совсем нет понятия кластера, нет понятия ноды и ее размера. Есть абстрактный Analytics Unit (AU). Можно сказать, что 1 AU = часу работы одной абстрактной ноды.
Так как ADLA — продукт Microsoft, он лучше интегрирован в экосистему. Например, job'ы для ADLA можно писать как в портале Azure, так и в Visual Studio. Существует локальный эмулятор ADLA, можно отлаживать job'ы на своей машине перед запуском на больших данных. Поддерживается нормальный дебаг кастомного C# кода, с брейкпойнтами.
С параллелизации job'a подход немного другой, чем в databricks. Так как понятия кластера нет, при запуске job'a ты можешь указать количество выделенных AU. Таким образом ты сам можешь выбирать насколько job должен параллелиться.
Среди крутых фич — детальный план job'a. Показывает сколько и какие данные были обработаны, сколько заняла обработка на каждом этапе. Это мощный инструмент для оптимизации и отладки.
Основной язык job'ов — U-SQL. Что касается кастомного кода — тут выбора нет, только C#. Но многие видят в этом преимущество.
Плюсы:
- Масштабирование на уровне job'a
- Удобный U-SQL
- Хорошая интеграция с экосистемой Microsoft продуктов, включая сервисы Azure
- Удобная отладка job'ов на локальной машине
- Делатальные job планы
- Возможность работы через портал Azure
Минусы:
- Не может обрабатывать стрим событий, для этого нужно отдельное решение
- Нет инструментов интерактивной коллаборации, как в Azure Databricks
- Только один язык для кастомного кода
- Чтобы настроить процессинг данных по таймеру, нужны дополнительные инструменты
Azure Stream Analytics
Облачная платформа для обработки стрима событий. Довольно удобная штука. Из коробки имеет средства для отладки/тестирования прямо в портале. Разговаривает на диалекте T-SQL. Поддерживает разные виды окон для аггрегации. Умеет работать со многими источниками данных как на вход, так и на выход.
Не смотря на все плюсы вряд ли подойдет для чего-то сложного. Упретесь либо в производительность, либо в стоимость.
Функционал из-за которого его стоит рассмотреть — интеграция с PowerBI, что позволяет в пару кликов настроить real-time статистику.
Плюсы:
- Масштабирование
- Интеграция со всеми облачными сервисами из коробки
- Поддержка T-SQL
- Удобная отладка запросов
Минусы:
- Нельзя масштабировать без выключения job'a
- Отсутствуют средства для разведения job'a между prod / dev сценариями
- Высокая стоимость
- Плохая производительность при наличии тяжелых запросов вроде DISTINCT'a
Гибридное решение
Никто не запрещает комбинировать облачные платформы и OSS решения. Например, вместо Apache Kafka / NiFi можно использовать Azure Event Hubs, если нет какой-то дополнительной логики по трансформации событий.
Для всего остального можно оставить Apache Spark, например.
Конкретные цифры
С возможностями разобрались, теперь про цену. Ниже — пример расчета, который я делал для одной из студий.
Я использовал Azure Pricing Calculator для расчета стоимости.
Рассчитывал цены для работы с холодными данными в регионе West Europe.
Для простоты, я считал только Compute мощности. Я не учитывал хранилище, так как его размер сильно зависит от конкретного проекта.
На данном этапе я включил в таблицу цены для систем буфферизации только для сравнения. Там указаны цены для минимальных кластеров/размеров, с которых можно начать.
Стоимость Apache Stack на голых VM
| Решение | Цена |
|---|---|
| Spark | $204 |
| Kafka | $219 |
| Total | $433 |
Стоимость платформенного решения на базе ADLA
| Решение | Цена |
|---|---|
| Azure Data Lake Analytics | $108 |
| Azure Event Hubs | $11 |
| Total | $119 |
Стоимость платформенного решения на базе Azure Databricks
| Решение | Цена |
|---|---|
| Azure Databriks | $292 |
| Azure Event Hubs | $11 |
| Total | $303 |
Подробнее по расчетам
Kafka on Bare VMs
Для того, чтобы обеспечить более-менее надежное решение, нужно как минимум 3 ноды:
1 x Zookeeper (Standard A1) = $43.8 / month
2 x Kafka Nodes (Standard A2) = $175.2 / month
Total: $219
Справедливости ради стоит заметить, что такая конфигурация Kafka потянет значительно большую пропускную способность, чем нужна в требованиях. Поэтому Kafka может быть выгоднее, если нужна более высокая пропускная способность.
Spark on Bare VMs
Я думаю, минимальная конфигурация о которой стоит говорить: 4 vCPU, 14GB RAM.
Из самых дешевых VM я выбрал Standard D3v2.
1 x Standard D3v2 = $203.67 / month
Azure Databricks
У Databricks есть два типа кластеров: Standard и Serverless (beta).
Standard кластер в Azure Databricks включает как минимум 2 ноды:
- Driver — хостит блокноты и обрабатывает запросы, связанные с ними, а так же является Spark Master'ом и поддерживает SparkContext.
- Worker — собственно, воркер, который процессит все запросы
Честно говоря, не знаю, что здесь понимается под serverless, но вот что я заметил про этот тип:
- Все равно выбираешь тип воркер нод, их количество (от и до)
- Serverless создает ноды прямо в подписке, в отдельной ресурс группе
- Auto terminate фича отсутствует
- Поддерживает только R/Python/SQL запросы.
- Включает минимум 2 ноды
Так же Databricks включает два тира, Premium имеет несколько своих фишек, вроде разграничение доступа по блокнотам. Но я считал минимальный Standard.
Считая в калькуляторе, я наткнулся на один интересный момент — Driver нода там отсутствует. Так как минимальный размер любого кластера, в итоге, 2 ноды, стоимость в калькуляторе не полная. Поэтому я посчитал ручками.
Сам Databricks биллится за DBU — вычислительные мощности. Каждый тип ноды имеет свой коэффициент DBU в час.
Для воркера я взял минимальный DSv2 (\$0.272 / час), он соответствует 0.75 DBU.
Для драйвера я взял самый дешевый инстанс F4 (\$0.227 / час), он соответствует 0.5 DBU.
DSv2 = ($0.272 + $0.2 * 0.75 DBU на ноду) * 730 ч = $308.06
F4 = ($0.227 + $0.2 * 0.75 DBU на ноду) * 730 ч = $275.21
Total: $583.27Это расчет с учетом работы этого маленького кластера 24/7. Но на самом деле благодаря возможностям авто-терминейта, можно значительно снизить эту цифру. Минимальный idle-таймаут для кластера — 10 минут.
Если взять за аксиому, что с кластером работают 12 часов в день (полный рабочий день, с учетом плавающих часов), то стоимость уже будет $583 * 0.5 = $291.5.
Если же аналитики не утилизируют кластер 100% рабочего времени, то цифра может быть еще меньше.
Azure Data Lake Analytics
Цена в Европе \$2 за Analytics Unit в час.
Analytics Unit — по сути, одна нода. $2/час за ноду дороговато, но биллится это дело поминутно. Обычно Job занимает минимум минуту.
Если Job большой, то нужно больше AU чтобы его распараллелить.
Тут я понял, что пальцем в небо тыкать не очень хорошо. Поэтому предварительно провел небольшой тест. Я сгенерировал json файлы по 100 Мб, всего 1Гб, положил их в стор, запустил простой запрос в Azure Data Lake Analytics по аггрегации данных и посмотрел сколько времени займет обработка 1 Гб. У меня вышло 0.09 AU/h.
Теперь уже можно примерно посчитать сколько будет стоить обработка данных. Предположим, что в месяц у нас накапливается 600 Гб данных. Все эти данные мы должны как минимум 1 раз обработать.
600 Гб * 0.09AU * $2 = $108
Это довольно грубые расчеты минимальной конфигурации для аналитики.
Краткие итоги
Решение на базе SQL базы не обладает достаточной гибкостью и производительностью.
Решение на базе Apache Stack — очень сильное и гибкое, хотя дороговато для обозначенных требований. Плюс требует поддержки кластера ручками. Это Open Source, поэтому vendor lock'a можно не бояться. Плюс ко всему Apache Stack может покрыть сразу две задачи сразу — обработка холодных и горячих данных, а это плюс.
Если вам не страшны трудности администрирования, то это — идеальное решение.
Если вы постоянно работаете с аналитикой, с большими объемами, то иметь свой кластер может быть более выгодным решением.
Среди облачных платформ существует несколько решений.
Для буфферизации событий — EventHub. При небольших объемах получается подешевле Kafka.
Для обработки холодных данных — два подходящих варианта:
- Azure Databricks (Preview) — классный инструмент с интерактивными блокнотами и встроенным Spark. Может обрабатывать как горячие, так и холодные данные. Не очень дорого, поддержка многих языков, автоуправление кластером, и еще много плюшек.
- Azure Data Lake Analytics — не имеет кластера, параллелизация на уровне job'ов, хорошая интеграция с Visual Studio, удобные стредства для отладки, поминутный биллинг
Если нет ресурсов на поддержку инфраструктуры, а так же если нужен довольно дешевый старт, то эти варианты будут очень привлекательными.
Azure Databricks может быть более дешевым вариантом, если job'ы выполняются постоянно и в больших количествах.
Предложив обозначенные варианты нескольким студиям, многие заинтересовались платформенными решениями. Их можно довольно безболезненно интегрировать в существующие процессы и системы, без лишних трудозатрат по администрированию.
Ниже я рассматриваю подробный обзор по архитектуре на базе платформенного решения Azure Data Lake Analytics.
Игровая аналитика на Azure Event Hub / Azure Functions / Azure Data Factory / Azure Data Lake Analytics / Azure Stream Analytics / Power BI
Архитектура
Прикинув все за и против, я взялся за реализацию лямбда архитектуры на Azure. Она выглядит следующим образом:

Azure Event Hub — это очередь, буфер, который способен принимать огромное количество сообщений. Так же есть приятная фича записи сырых данных в хранилище. В данном случае — Azure Data Lake Storage (ADLS).
Azure Data Lake Store — хранилище, базирующееся на HDFS. Используется в связке с сервисом Azure Data Lake Analytics.
Azure Data Lake Analytics — сервис аналитики. Позволяет строить U-SQL запросы к данным, лежащим в разных источниках. Самый быстрый источник — ADLS. В особо сложных случаях, можно писать кастомный код для запросов, на C#. Есть удобный тулсет в Visual Studio, с подробным профайлингом запросов.
Azure Stream Analytics — сервис для обработки потока данных. В данном случае используется для аггрегации "горячих" данных и передачи их для визуализации в PowerB
Azure Functions — сервис для размещения serverless приложений. В данной архитектуре используется для "кастомной" обработки очереди событий.
Azure Data Factory — довольно спорный инструмент. Позволяет организовывать "пайплайны" данных. В данной конкретной архитектуре, используется для запуска "батчей". То есть запускает запросы в ADLA, вычисляя срезы за определенное время.
PowerBI — инструмент бизнес аналитики. Используется для организации всех дашбордов по игре. Умеет отображать реалтайм данные.
То же решение, но в другой перспективе.
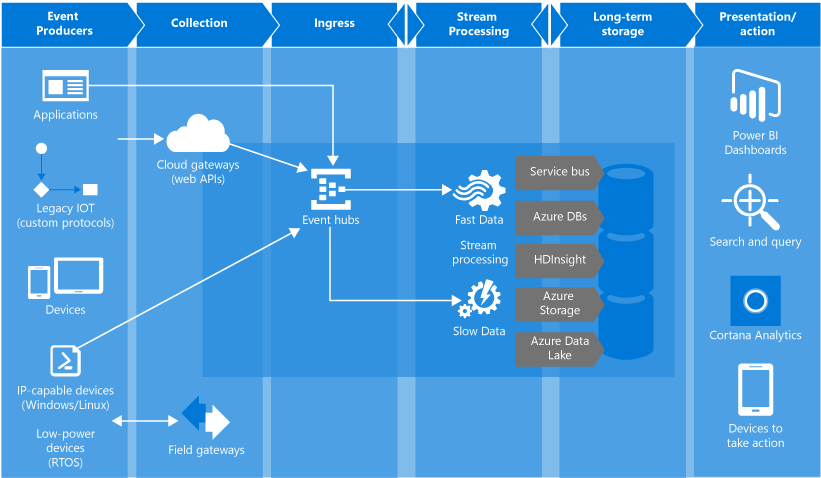
Здесь хорошо видно, что в Event Hubs клиенты могут как напрямую, так и через API Gateway. Аналогично, в Event Hubs можно кидать и серверную аналитику.
Обработка очереди событий
Холодные данные
После поступления в EventHub, события идут двумя путями: холодным и горячим. Холодный путь ведет в хранилище ADLS. Для сохранения событий есть несколько вариантов.
EventHub's Capture
Самый простой — использовать Capture фичу EventHub'a. Она позволяет автоматически сохранять сырые данные, поступающие в хаб, в одно из хранилищ: Azure Storage или ADLS. Фича позволяет настроить паттерн именования файлов, правда сильно ограниченный.
Хотя фича и полезная, подойдет она не во всех случаях. Например, мне она не подошла, так как время, используемое в паттерне для файлов, соответствует времени прибытия ивента в EventHub.
По факту, в играх, ивенты могут накапливаться клиентами, а затем посылаться пачкой. В таком случае, ивенты попадут в неправильный файл.
Организация данных в файловой структуре очень важна для эффективности ADLA. Накладные расходы на открытие/закрытие файла довольно велики, поэтому ADLA будет наиболее эффективным при работе с большими файлами. Опытным путем, я выяснил оптимальный размер — от 30 до 50 Мб. В зависимости от нагрузки, может понадобиться разбивать файлы по дням/часам.
Еще одна причина — отсутствтие возможности разложить ивенты по папкам, в зависимости от типа самого ивента. Когда дело дойдет до аналитики, запросы должны будут быть максимально эффективными. Самый оптимальный способ отфильтровать ненужные данные — не читать файлы совсем.
Если события будут смешаны внутри файла по типу (например, события авторизации и экономические события), то часть вычислительных мощностей аналитики будет тратиться на откидывание ненужных данных.
Плюсы:
- Быстро настроить
- Просто работает, без всяких заморочек
- Дешево
Минусы:
- Поддерживает только AVRO формат при сохранении событий в хранилище
- Обладает достаточно ограниченными возможностями по именованию файлов
Stream Analytics (Холодные данные)
Stream Analytics позволяет писать SQL-подобные запросы к потоку событий. Есть поддержка EventHub'a как источника данных и ADLS в качестве вывода. Благодаря этим запросам, в хранилище можно складывать уже трансформированные/агреггированные данные.
Аналогично, обладает скудными возможностями по именованию файлов.
Плюсы:
- Быстрая и простая настройка
- Поддерживает несколько форматов для ввода/вывода событий
Минусы:
- Обладает достаточно ограниченными возможностями по именованию файлов
- Высокая цена
- Отсутствие динамического масштабирования
Azure Functions (Холодные данные)
Наиболее гибкое решение. В Azure Functions есть binding для EventHub, и не надо заморачиваться с разбором очереди. Так же Azure Functions автоматически скалируются.
Именно на этом решении я остановился, так как смог размещать события в папках, соответствующих времени генерации события, а не его прибытия. Так же сами события удалось раскидать по папкам, согласно типу события.
Для биллинга есть две опции:
- Consumption Plan — трушный serverless, платите за используемую память в секунду. При больших нагрузках может быть дороговато
- App Service Plan — в данном варианте у Azure Functions есть сервер, его тип можно выбирать, вплоть до бесплатного, есть возможность автомасштабирования. Именно это опция в моем случае оказалась дешевле.
Плюсы:
- Гибкость в именовании файлов с сырыми данными
- Динамическое масштабирование
- Есть встроенная интеграция с EventHub
- Низкая стоимость решения, при правильно выбранном биллинге
Минусы:
- Необходимо писать кастомный код
Горячие данные
Stream Analytics (Горячие данные)
Опять же Stream Analytics самое простое решение для аггрегации горячих данных. Плюсы и минусы примерно те же, что и для холодного пути. Основным плюсом Stream Analytics является интеграция с PowerBI. Горячие данные можно отгружать в "реальном" времени.
Плюсы:
- Быстрая и простая настройка
- Имеет множество выводов, включая SQL, Blob Storage, PowerBI
Минусы:
- Поднможество T-SQL, используемое в Stream Analytics, все же имеет свои ограничения, при решении некоторых задач можно упереться в лимиты
- Цена
- Отсутствие динамического масштабирования
Azure Functions (Горячие данные)
Все то же самое, что и в холодных данных. Не буду подробно описывать.
Плюсы:
- Полностью кастомная логика
- Динамическое масштабирование
- Встроенная интеграция с EventHub
- Низкая стоимость решения, при правильно выбранном биллинге
Минусы:
- Необходимо писать кастомный код
- Так как функции stateless, необходимо отдельное хранилище состояния
Считаем цену полного решения
Итак, расчет для нагрузки 1000 событий в секунду.
| Решение | Цена |
|---|---|
| Azure EventHub | $10.95 |
| Azure Stream Analytics | $80.30 |
| Azure Functions | $73.00 |
| Azure Data Lake Store | $26.29 |
| Azure Data Lake Analytics | $108.00 |
В большинстве случаев Stream Analytics может не понадобится, поэтому итого будет от $217 до $297.
Теперь про то как я считал. Стоимость Azure Data Lake Analytics я взял из расчетов выше.
Расчет Azure Event Hub
Azure Event Hub — биллится за каждый миллион сообщений, а так же за пропускную способность в секунду.
Пропускная способность одного throughput unit (TU) 1000 событий / сек или 1МБ/сек, что наступит раньше.
Мы считаем для 1000 сообщений в сек, то есть необходимо 1 TUs. Цена за TU на момент написания статьи $0.015 за Basic тир. Принято считать, что в месяце 730 часов.
1 TU * $0.015 * 730 ч = $10.95
Считаем количество сообщений в месяц, с учетом одинаковой нагрузки в течение месяца (ха! такого не бывает):
1000 * 3600 сек * 730 ч = 2 628 000 000 событий
Считаем цену за количество входящих событий. Для Западной Европы, на момент написания статьи, цена была $0.028 за миллион событий:
2 628 000 000 / 1 000 000 * $0.028 = $73.584
Итого $10.95 + $73.584 = $84.534.
Что-то много выходит. Учитывая, что события обычно достаточно мелкие — это не выгодно.
Придется на клиенте написать алгоритм упаковки нескольких событий в одно (чаще всего так и делают). Это не только позволит уменьшить количество событий, но и сократить количество необходимых TUs при дальнейшем росте нагрузки.
Я взял выгрузку реальных ивентов из существующей системы и посчитал средний размер — 0.24KB. Максимально допустимый размер события в EventHub 256KB. Таким образом, мы можем упаковать приблизительно 1000 событий в одно.
Но тут есть тонкий момент: хоть максимальный размер события и 256KB, биллятся они кратно 64KB. То есть максимально упакованное сообщение будет посчитано как 4 события.
Пересчитаем с учетом этой оптимизации.
$73.584 / 1000 * 4 = $0.294
Вот это уже значительно лучше. Теперь посчитаем какая пропускная способность нам нужна.
1000 events per second / 1000 events in batch * 256KB = 256KB/s
Это вычисление показывает и другую важную особенность. Без батчинга ивентов нужно было бы 2.5MB/s, что потребовало бы 3TU. А мы ведь считали что нужен всего 1TU, ведь мы отправляем 1000 ивентов в секунду. Но лимит по пропускной способности наступил бы раньше.
В любом случае, мы можем уложиться в 1 TU вместо 3! И расчеты можно не менять.
Считаем цену для TU.
Итого получаем $10.95 + $0.294 = $11.244.
Сравним с ценой без учета упаковки ивентов: (1 - $11.244 / $84.534) * 100 = 86.7%.
На 86% выгоднее!
Упаковку событий нужно обязательно учесть при реализации этой архитектуры.
Расчет Azure Data Lake Store
Итак, давайте прикинем примерный порядок роста размера хранилища. Мы уже посчитали, что при нагрузке 1000 событий в секунду, мы получаем 256КБ/сек.
256КБ * 3600 сек * 730 ч = 657 000 MБ = 641 ГБ
Это довольно большая цифра. Скорее всего 1000 событий в секунду будут только часть времени суток, но тем не менее, стоит посчитать худший вариант.
641 ГБ * $0.04 = $25.64
Еще ADLS биллится за каждые 10000 транзакций с файлами. Транзакции — это любое действие с файлом: чтение, запись, удаление. К счастью удаление бесплатное =).
Давайте посчитаем чего нам стоит только запись данных. Воспользуемся предыдущими расчетами, мы собираем 2 628 000 000 событий в мес, но мы их упаковываем по 1000 в один ивент, поэтому 2 628 000 событий.
2 628 000 транзакций записи / 10000 транзакций * $0.05 = $13.14
Что-то не очень дорого, но можно уменьшить, если записывать батчами по 1000 событий. Упаковку нужно делать на уровне клиентского приложения, и батч записи на уровне обработки событий из EventHub.
$13.14 / 1000 = $0.0134
Вот это уже недурно. Но опять же, нужно учесть батчинг при разборе очереди EventHub.
Итого $26.28 + $0.0134 = $26.2934
Расчет Azure Functions
Использование Azure Functions возможно как для холодного, так и для горячего путей. Аналогично, их можно деплоить как одно приложение, так и отдельно.
Я посчитаю самый простой вариант, когда они крутятся как одно приложение.
Итак, у нас нагрузка 1000 событий в секунду. Это не очень много, но и не мало. Ранее я говорил, что Azure Functions могут обрабатывать события в батчах, причем это делают более эффективно, чем обработка событий по отдельности.
Если взять размер батча в 1000 событий, то нагрузка становится 1000 / 1000 = 1 реквест в секунду. Что совсем смешная цифра.
Посему можно деплоить все в одно приложение, и такую нагрузку потянет один минимальный инстанс S1. Его стоимость $73. Можно, конечно, взять и B1, он еще дешевле, но я бы перестраховался, и остановился на S1.
Расчет Stream Analytics
Stream Analytics нужен только для продвинутых реал-тайм сценариев, когда нужна механика скользящего окна. Это довольно редкий сценарий для игр, так как основная статистика рассчитывается на основе окна в день, и сбрасывается при наступлении следующего дня.
Если же вам нужен Stream Analytics, то гайдлайны рекомендуют начать с размера в 6 Streaming Units (SUs), что равно одной выделенной ноде. Далее нужно смотреть нагрузку работы, и скалировать SUs соответственно.
По моему опыту, если запросы не включают DISTINCT, или окно довольно маленькое (час), то достаточно одного SU.
1 SU * $0.110 * 730 hours = $80.3
Итоги
Существующие решения, предлагаемые на рынке, довольно мощные. Но их все равно недостаточно для продвинутых задач, они всегда имеют либо лимиты производительности, либо ограничения по кастомизации. И даже средние игры начинают довольно быстро в них упираться. Это побуждает на разработку собственного решения.
Встав перед выбором стека технологий, я прикинул цену. Мощняцкий Apache стек способен справиться с любыми задачами и нагрузками, но управлить им нужно вручную. Если вы не можете его легко масштабировать, то он обходится очень дорого, особенно если машины не загружены на 100% 24/7. Плюс, если вы не знакомы со стеком, для дешевого и быстрого старта такое решение не подойдет.
Если вкладываться в разработку и поддержку инфраструктуры не хочется, нужно смотреть в сторону облачных платформ. Игровая аналитика требует, в основном, периодических расчетов. Раз в день, например. Поэтому возможность платить только за то, что используешь — как раз в точку.
Самый дешевый и быстрый старт даст решение на базе ADLA. Более богатое и гибкое решение — Azure Databricks.
Так же могут быть и гибридные варианты.
Те студии, с которыми мы работали, предпочли облачные решения, как самый простой вариант для интеграции в существующие процессы и системы.
При использовании облачных сервисов нужно очень осторожно подходить к построению решения. Нужно изучать принципы формирования цены и учитывать необходимые оптимизации для снижения стоимости.
В итоге, расчеты показывают, что для 1000 запросов в секунду, что является средним показателем, кастомную систему аналитики можно получить за $300 в месяц. Что довольно дешево. При этом в разработку своего решения не нужно вкладывать ничего. Что интересно, вариант с ADLA, в отличие от других решений, при простое не потребляет денег совсем. Поэтому он очень интересен и для dev&test сценариев.
В следующих статьях я детально расскажу о технических аспектах реализации.
Там же расскажу о неприятных моментах. Например, Azure Stream Analytics для игровых сценариев показал себя не очень хорошо. Многие запросы завязаны на DAU, а его расчет требует расчета уников через DISTINCT. Это убивало производительность, и выливалось в копеечку. Решили проблему простым кодом на Azure Functions + Redis.
Мне нравится, хочу хочу хочу
Я — часть команды Microsoft, которая помогает партнерам строить интересные и эффективные решения. Мы сейчас ищем еще несколько игровых компаний, с которыми можно сделать подобный проект по аналитике, или придумать новые интересные сценарии. Мы будем рассказывать такие истории уже на примере реальных игр.
Мы не только за слово, но и за дело, поэтому мы готовы, вместе с вашими разработчиками и аналитиками, сесть рука об руку, и разработать такой проект или пилот. Мы поможем подготовить статьи для интересных проектов. Возможны и другие варианты плюшек с нашей стороны.
Если вы заинтересовались, пишите в личку, или по контактам в профиле.
