На GitHub представлено больше 300 языков программирования, начиная с общеизвестных языков, таких как Python, Java, и Javascript, и заканчивая эзотерическими языками, такими как Befunge, известными только малым группам людей.

Топ-10 языков программирования, размещенных на GitHub, по количеству репозиториев
Одна из проблем, с которой сталкивается GitHub — распознавание разных языков программирования. Когда какой-то код размещается в репозитории, очень важным является распознавание его типа. Это нужно из соображений поиска, оповещений об уязвимостях, подсветки синтаксиса, а также структурного представления контента репозитория пользователям.
На первый взгляд, распознавание языка является простой задачей, но это не совсем так. Linguist — это инструмент, который мы сейчас используем для определения языка программирования на GitHub. Linguist — это приложение на Ruby, использующее различные стратегии про распознаванию языка, в том числе данные о названиях и расширения файлов. Кроме того оно принимает во внимание модели Vim или Emacs, а также содержимое в верхней части файла (shebang). Linguist обрабатывает языковую неоднозначность эвристически и, если таким способом не получается, то использует наивный байесовский классификатор, обученный на небольшой выборке данных.
Хотя Linguist достаточно хорошо предсказывает на уровне файла (точность 84%), все ломается, когда файлы названы странно, а тем более, когда у файлов нет расширений. Это делает Linguist бесполезным для такого контента, как GitHub Gists или фрагментов кода в README, ошибках и pull requests.
С целью сделать определение языка более четким в долгосрочной перспективе мы разработали классификатор с машинным обучением, названный OctoLingua. Он создан на основе архитектуры Artificial Neural Network (ANN), которая может справиться с предсказанием языка в нетривиальных сценариях. Текущая версия модели может делать предсказания для топ-50 языков программирования на GitHub и превосходит Linguist по точности.
OctoLingua был написан с нуля на Python, Keras с бэкендом TensorFlow — он создавался, чтобы быть точным, надежным и простым в обслуживании. В данной части мы расскажем о наших источниках данных, архитектуре модели и тестах результативности OctoLingua. Мы также расскажем о процессе добавления возможности распознавания нового языка.
Текущая версия OctoLingua была обучена на файлах, полученных из Rosetta Code и из набора внутренних краудсорсовых репозиториев. Мы ограничили наш набор языков 50 самыми популярными на GitHub.
Rosetta Code был прекрасным стартовым набором данных, поскольку он содержал исходный код, написанный для выполнения одной и той же задачи, но на разных языках программирования. Например, код для генерирования чисел Фибоначчи был представлен на C, C++, CoffeeScript, D, Java, Julia и других. Однако покрытие языков было неоднородным: для каких-то языков программирования имелось всего лишь несколько файлов с кодом, для других же файлы содержали просто слишком мало кода. Поэтому было необходимо дополнить наш обучающий набор данных некоторыми дополнительными источниками и за счет этого существенно улучшить охват языков и результативность итоговой модели.
Наш процесс добавления нового языка не полностью автоматизирован. Мы программно собираем исходный код из общедоступных репозиториев в GitHub. Мы выбираем только те репозитории, которые отвечают минимальным квалификационным критериям, таким как наличие минимального количества форков, охватывающих целевой язык и охватывающих конкретные расширения файлов. На данном этапе сбора данных мы определяем основной язык репозитория, используя классификацию из Linguist.
Традиционно, для решения проблем текстовой классификации с помощью нейронных сетей используются основанные на памяти архитектуры, такие как Recurrent Neural Networks (RNN) и Long Short Term Memory Networks (LSTM). Однако различия языков программирования в лексике, расширениях файлов, структуре, стиле импортирования библиотек и других деталях, вынудили нас придумать другой подход, который использует всю эту информацию, извлекая некоторые признаки в табличной форме для обучения нашего классификатора. Признаки извлекаются следующим образом:
Мы используем вышеуказанные факторы в качестве входных данных для двухслойной нейросети, построенной с использованием Keras с бэкендом Tensorflow.
Диаграмма ниже показывает, что шаг извлечения признаков создает n-мерный табличный ввод для нашего классификатора. По мере того, как информация перемещается по слоям нашей сети, она упорядочивается с помощью отсева, и в итоге получается 51-мерный вывод, который представляет вероятность того, что данный код написан на каждом из топ-50 языков в GitHub. Также показывается вероятность того, что код не написан на каком-то языке из этих 50.

ANN-структура исходной модели (50 языков + 1 для “other”)
Мы использовали 90% нашей исходной базы данных для обучения. Также на шаге обучения модели была удалена часть расширений файлов, чтобы модель могла учиться именно на лексике файлов, а не на их расширениях, и так хорошо предсказывающих язык программирования.
В таблице ниже, мы показываем F1 Score (среднее гармоническое между точностью и полнотой) для OctoLingua и Linguist посчитан на одном и том же наборе тестов (10% от объема нашего изначального источника данных).
Здесь показано три теста. В первом тесте набор данных был не тронут совсем; во втором были удалены расширения файлов; в третьем же расширения файлов были перемешаны для того, чтобы запутать классификатор (например, файл Java мог иметь расширение “.txt”, а файл Python расширение “.java”.
Интуиция, стоящая за перемешиванием или удалением расширений файлов в нашем тестовом наборе, заключается в оценке надежности OctoLingua в классификации файлов, когда ключевой признак удален или вводит в заблуждение. Классификатор, который не сильно зависит от расширения, был бы чрезвычайно полезен для классификации логов и фрагментов кода, поскольку в этих случаях обычно люди не предоставляют точную информацию о расширении (например, многие связанные с кодом логи имеют расширение txt.)
В таблице ниже показано, как OctoLingua имеет хорошую результативность в различных условиях, когда мы предполагали, что модель учится в основном на лексике кода, а не на метаинформации (например, на расширении файла). В это же время Linguist определяет язык ошибочно, как только информация о правильном расширении файла отсутствовала.
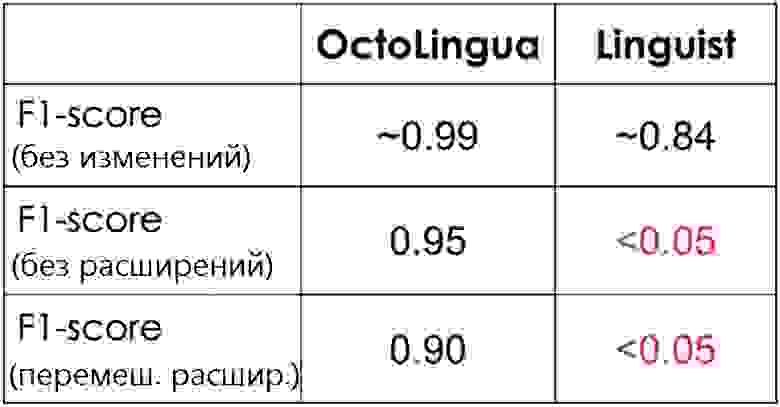 Результативность OctoLingua против Linguist на одном и том же наборе тестов
Результативность OctoLingua против Linguist на одном и том же наборе тестов
Как упоминалось ранее, во время обучения мы удалили некий процент расширений файлов из данных, чтобы заставить модель обучаться на лексике файлов. В таблице ниже показана результативность нашей модели с различными долями удаленных во время обучения расширений файлов.
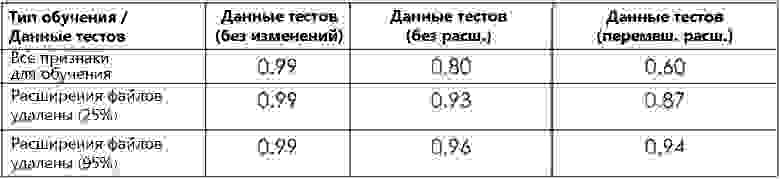
Результативность OctoLingua при разной доле удаленных расширений файлов
Обратите внимание, что модель, обученная на файлах с расширениями, значительно менее результативна на тестовых файлах без расширений или с перемешанными расширениями, чем на обычных тестовых данных. С другой стороны, когда модель обучается на наборе данных, в котором удалена часть расширений файлов, результативность модели не сильно снижается на модифицированном наборе тестов. Это подтверждает, что удаление расширений из части файлов во время обучения побуждает наш классификатор учиться больше на лексике кода. Это также показывает, что расширение файла имело тенденцию доминировать и препятствовал приданию большего веса признакам содержимого.
Добавление нового языка в OctoLingua — это довольно простой процесс. Он начинается с поисков и получения большого количества файлов на новом языке (мы можем сделать это программно, как описано в пункте «Источники данных»). Эти файлы делятся на обучающие и тестовые наборы, а затем проходят через наши препроцессор и экстрактор признаков. Новый набор данных добавляется в существующий пул. Набор для тестирования позволяет нам убедиться, что точность нашей модели остается приемлемой.

Добавление нового языка в OctoLingua
На данный момент OctoLingua находится на «продвинутой стадии прототипирования». Наш механизм классификации языков уже надежен, но еще не поддерживает все языки программирования, доступные на GitHub. Помимо расширения языковой поддержки, что не так сложно, мы стремимся обеспечить обнаружение языка с различными уровнями детализации кода. Наша текущая реализация уже позволяет нам, с небольшой модификацией нашего механизма машинного обучения, классифицировать фрагменты кода. Также не кажется чем-то сложным выведение модели на этап, на котором она сможет надежно обнаруживать и классифицировать встроенные языки.
Мы также рассматриваем возможность публикации исходного кода нашей модели, но нужен запрос от сообщества.
Наша цель при разработке OctoLingua — создать сервис, обеспечивающий надежное определение языка по исходному коду на разных уровнях детализации: от уровня файлов или фрагментов кода до потенциально определения и классификации языка на уровне строк. Вся наша работа над данным сервисом нацелена на поддержку разработчиков в их повседневной работе по разработке, а также на создание условий для написания качественного кода.
Если вы заинтересованы в содействии нашей работе, пожалуйста, не стесняйтесь связываться с нами в Twitter @github!

Топ-10 языков программирования, размещенных на GitHub, по количеству репозиториев
Одна из проблем, с которой сталкивается GitHub — распознавание разных языков программирования. Когда какой-то код размещается в репозитории, очень важным является распознавание его типа. Это нужно из соображений поиска, оповещений об уязвимостях, подсветки синтаксиса, а также структурного представления контента репозитория пользователям.
На первый взгляд, распознавание языка является простой задачей, но это не совсем так. Linguist — это инструмент, который мы сейчас используем для определения языка программирования на GitHub. Linguist — это приложение на Ruby, использующее различные стратегии про распознаванию языка, в том числе данные о названиях и расширения файлов. Кроме того оно принимает во внимание модели Vim или Emacs, а также содержимое в верхней части файла (shebang). Linguist обрабатывает языковую неоднозначность эвристически и, если таким способом не получается, то использует наивный байесовский классификатор, обученный на небольшой выборке данных.
Хотя Linguist достаточно хорошо предсказывает на уровне файла (точность 84%), все ломается, когда файлы названы странно, а тем более, когда у файлов нет расширений. Это делает Linguist бесполезным для такого контента, как GitHub Gists или фрагментов кода в README, ошибках и pull requests.
С целью сделать определение языка более четким в долгосрочной перспективе мы разработали классификатор с машинным обучением, названный OctoLingua. Он создан на основе архитектуры Artificial Neural Network (ANN), которая может справиться с предсказанием языка в нетривиальных сценариях. Текущая версия модели может делать предсказания для топ-50 языков программирования на GitHub и превосходит Linguist по точности.
Более детально об OctoLingua
OctoLingua был написан с нуля на Python, Keras с бэкендом TensorFlow — он создавался, чтобы быть точным, надежным и простым в обслуживании. В данной части мы расскажем о наших источниках данных, архитектуре модели и тестах результативности OctoLingua. Мы также расскажем о процессе добавления возможности распознавания нового языка.
Источники данных
Текущая версия OctoLingua была обучена на файлах, полученных из Rosetta Code и из набора внутренних краудсорсовых репозиториев. Мы ограничили наш набор языков 50 самыми популярными на GitHub.
Rosetta Code был прекрасным стартовым набором данных, поскольку он содержал исходный код, написанный для выполнения одной и той же задачи, но на разных языках программирования. Например, код для генерирования чисел Фибоначчи был представлен на C, C++, CoffeeScript, D, Java, Julia и других. Однако покрытие языков было неоднородным: для каких-то языков программирования имелось всего лишь несколько файлов с кодом, для других же файлы содержали просто слишком мало кода. Поэтому было необходимо дополнить наш обучающий набор данных некоторыми дополнительными источниками и за счет этого существенно улучшить охват языков и результативность итоговой модели.
Наш процесс добавления нового языка не полностью автоматизирован. Мы программно собираем исходный код из общедоступных репозиториев в GitHub. Мы выбираем только те репозитории, которые отвечают минимальным квалификационным критериям, таким как наличие минимального количества форков, охватывающих целевой язык и охватывающих конкретные расширения файлов. На данном этапе сбора данных мы определяем основной язык репозитория, используя классификацию из Linguist.
Признаки: основываясь на предыдущем знании
Традиционно, для решения проблем текстовой классификации с помощью нейронных сетей используются основанные на памяти архитектуры, такие как Recurrent Neural Networks (RNN) и Long Short Term Memory Networks (LSTM). Однако различия языков программирования в лексике, расширениях файлов, структуре, стиле импортирования библиотек и других деталях, вынудили нас придумать другой подход, который использует всю эту информацию, извлекая некоторые признаки в табличной форме для обучения нашего классификатора. Признаки извлекаются следующим образом:
- Топ-5 специальных символов в файле
- Топ-20 знаков в файле
- Расширение файла
- Наличие конкретных специальных символов, которые используются в исходном коде файлов, таких как двоеточие, фигурные скобки, точка с запятой
Модель Artificial Neural Network (ANN)
Мы используем вышеуказанные факторы в качестве входных данных для двухслойной нейросети, построенной с использованием Keras с бэкендом Tensorflow.
Диаграмма ниже показывает, что шаг извлечения признаков создает n-мерный табличный ввод для нашего классификатора. По мере того, как информация перемещается по слоям нашей сети, она упорядочивается с помощью отсева, и в итоге получается 51-мерный вывод, который представляет вероятность того, что данный код написан на каждом из топ-50 языков в GitHub. Также показывается вероятность того, что код не написан на каком-то языке из этих 50.

ANN-структура исходной модели (50 языков + 1 для “other”)
Мы использовали 90% нашей исходной базы данных для обучения. Также на шаге обучения модели была удалена часть расширений файлов, чтобы модель могла учиться именно на лексике файлов, а не на их расширениях, и так хорошо предсказывающих язык программирования.
Тест результативности
OctoLingua против Linguist
В таблице ниже, мы показываем F1 Score (среднее гармоническое между точностью и полнотой) для OctoLingua и Linguist посчитан на одном и том же наборе тестов (10% от объема нашего изначального источника данных).
Здесь показано три теста. В первом тесте набор данных был не тронут совсем; во втором были удалены расширения файлов; в третьем же расширения файлов были перемешаны для того, чтобы запутать классификатор (например, файл Java мог иметь расширение “.txt”, а файл Python расширение “.java”.
Интуиция, стоящая за перемешиванием или удалением расширений файлов в нашем тестовом наборе, заключается в оценке надежности OctoLingua в классификации файлов, когда ключевой признак удален или вводит в заблуждение. Классификатор, который не сильно зависит от расширения, был бы чрезвычайно полезен для классификации логов и фрагментов кода, поскольку в этих случаях обычно люди не предоставляют точную информацию о расширении (например, многие связанные с кодом логи имеют расширение txt.)
В таблице ниже показано, как OctoLingua имеет хорошую результативность в различных условиях, когда мы предполагали, что модель учится в основном на лексике кода, а не на метаинформации (например, на расширении файла). В это же время Linguist определяет язык ошибочно, как только информация о правильном расширении файла отсутствовала.

Эффект от удаления расширений файлов при обучении модели
Как упоминалось ранее, во время обучения мы удалили некий процент расширений файлов из данных, чтобы заставить модель обучаться на лексике файлов. В таблице ниже показана результативность нашей модели с различными долями удаленных во время обучения расширений файлов.

Результативность OctoLingua при разной доле удаленных расширений файлов
Обратите внимание, что модель, обученная на файлах с расширениями, значительно менее результативна на тестовых файлах без расширений или с перемешанными расширениями, чем на обычных тестовых данных. С другой стороны, когда модель обучается на наборе данных, в котором удалена часть расширений файлов, результативность модели не сильно снижается на модифицированном наборе тестов. Это подтверждает, что удаление расширений из части файлов во время обучения побуждает наш классификатор учиться больше на лексике кода. Это также показывает, что расширение файла имело тенденцию доминировать и препятствовал приданию большего веса признакам содержимого.
Поддержка нового языка
Добавление нового языка в OctoLingua — это довольно простой процесс. Он начинается с поисков и получения большого количества файлов на новом языке (мы можем сделать это программно, как описано в пункте «Источники данных»). Эти файлы делятся на обучающие и тестовые наборы, а затем проходят через наши препроцессор и экстрактор признаков. Новый набор данных добавляется в существующий пул. Набор для тестирования позволяет нам убедиться, что точность нашей модели остается приемлемой.

Добавление нового языка в OctoLingua
Наши планы
На данный момент OctoLingua находится на «продвинутой стадии прототипирования». Наш механизм классификации языков уже надежен, но еще не поддерживает все языки программирования, доступные на GitHub. Помимо расширения языковой поддержки, что не так сложно, мы стремимся обеспечить обнаружение языка с различными уровнями детализации кода. Наша текущая реализация уже позволяет нам, с небольшой модификацией нашего механизма машинного обучения, классифицировать фрагменты кода. Также не кажется чем-то сложным выведение модели на этап, на котором она сможет надежно обнаруживать и классифицировать встроенные языки.
Мы также рассматриваем возможность публикации исходного кода нашей модели, но нужен запрос от сообщества.
Заключение
Наша цель при разработке OctoLingua — создать сервис, обеспечивающий надежное определение языка по исходному коду на разных уровнях детализации: от уровня файлов или фрагментов кода до потенциально определения и классификации языка на уровне строк. Вся наша работа над данным сервисом нацелена на поддержку разработчиков в их повседневной работе по разработке, а также на создание условий для написания качественного кода.
Если вы заинтересованы в содействии нашей работе, пожалуйста, не стесняйтесь связываться с нами в Twitter @github!
