За почти четырнадцатилетнюю историю использования Jira и Confluence на Московской бирже в них накоплен огромный объем данных: у нас более 350 проектов в Jira и более 200 пространств в Confluence. Не будет преувеличением сказать, что в этих продуктах сейчас работает вся Биржа, а не только айтишники. Оперблок ведет в Confluence чеклисты регламентных операций, бизнес и аналитики пишут и согласовывают функциональные задания. В Jira недавно перевели проектный портал, которым заведует Проектный офис. Фактически продукты Atlassian у нас используются в режиме, приближенном к 24*7. Поэтому вопросы резервного копирования, восстановления в случае сбоя и времени вынужденного простоя уже давно стояли для нас весьма остро. В прошлом году мы сделали теплый резерв Jira и Confluence буквально на коленке, о чем и расскажем в этой статье. Ничего уникального, но тем выше шанс, что наш подход принесет пользу кому-то еще – увы, Atlassian уже начала отзывать лицензии, и неизвестно, что будет дальше.
Как было
На рисунке ниже представлена прошлая архитектура развертывания и механизмы резервирования и восстановления:
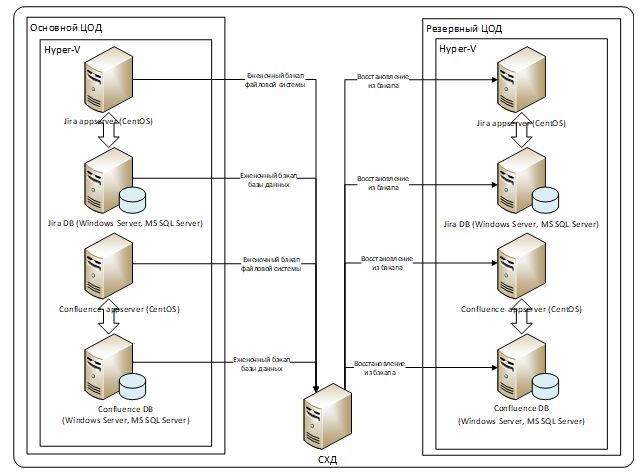
Как известно, Jira и Confluence хранят пользовательские данные в СУБД и на файловой системе. В случае проблем с основным ЦОДом для запуска Jira или Confluence в резервном ЦОДе нужно было скопировать базу данных и архив с данными на файловой системе на соответствующие сервера в резервном ЦОДе, развернуть базу, распаковать архив, запустить сервис. У такого решения есть недочеты. Первый – можно потерять боевые данные за сутки, если сбой в основном ЦОДе произойдет непосредственно перед снятием копий с базы и/или файловой системы Jira или Confluence. Второй недочет – в случае необходимости восстановления сервиса в резервном ЦОДе счет времени неработоспособности сервиса идет на часы, так как резервная копия базы данных Confluence у нас более 100 ГБ, а архивы данных на файловых системах Jira и Confluence – под 50 ГБ, только копирование и распаковка архивов занимает 2-3 часа. То есть нужно было как-то решить проблему оперативной доставки обновлений данных в резервный ЦОД.
Как стало
На следующем рисунке представлена текущая архитектура развертывания и механизмы резервирования и репликации:
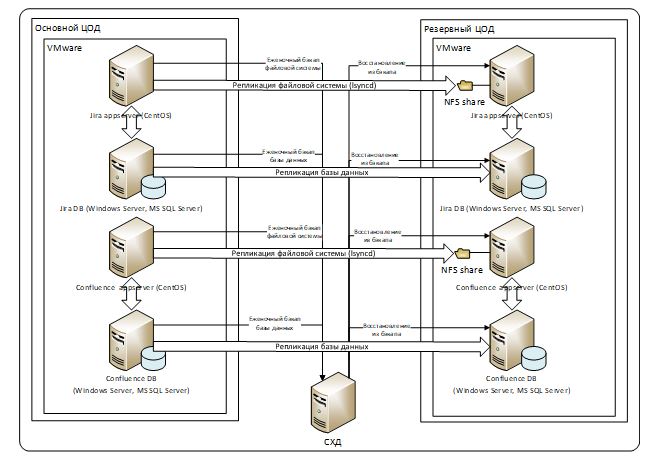
Репликация данных, хранящихся в СУБД, сделана стандартными средствами MS SQL Server (см. например). Для репликации файловых систем была выбрана утилита lsyncd – демон, который следит за изменениями файлов в дереве локальной директории, и раз в какое-то настраиваемое время отправляет изменения в удаленную примонтированную локально директорию. В настройках lsyncd можно указать, какие поддиректории игнорировать (например, логи нет смысла копировать). Про lsyncd можно почитать тут. В части репликации файловых систем мы пошли немного дальше и реплицируем не только директории с данными (аттачменты и т. п.), но и директории, в которые установлены сами Jira и Confluence. Таким образом, обновление на новую версию продукта достаточно сделать только в основном ЦОДе, в резервный все скопируется автоматически. Старые механизмы резервного копирования раз в сутки также работают, этими резервными копиями мы пользуемся при необходимости обновить данные на тестовом контуре. В результате применения данной схемы данные реплицируются в резервный ЦОД в пределах минуты. Подъем сервиса в резервном ЦОДе занимает 5-10 минут, в чем мы убедились во время проведения DR-тестирований в июле 2021 года и в январе 2022 года. Сценарий запуска сервиса в резервном ЦОДе на примере Confluence следующий.
Cредствами MS SQL Server на сервере БД в резервном ЦОДе останавливаем репликацию данных.
На сервере приложения в резервном ЦОДе прекращаем сетевой доступ к отшаренной папке, где установлен Confluence.
Убеждаемся, что в файле confluence.cfg.xml на сервере в резервном ЦОДе указан IP-адрес сервера БД в резервном ЦОДе.
Запускаем Confluence.
В DNS переключаемся на Confluence в резервном ЦОДе и идем смотреть, что там приключилось в основном ЦОДе.
В итоге мы получили возможность перевода сервисов Jira и Confluence в резервный ЦОД в случае проблем в основном ЦОДе за 5-10 минут практически без потери данных. Решение не потребовало материальных вложений на закупку специализированного ПО или железа, все было сделано имеющимися средствами. Теперь нам предстоит решить вопрос с импортозамещением обоих продуктов. С учетом того, что таких проработанных продуктов в реестрах отечественного ПО нет, задача выглядит непростой. Будем делиться изысканиями и успехами на этом пути.
