 Как было понятно из прошлой статьи “Четыре порока обслуживания”, мы активно внедряем ITSM подходы в нашей компании. Сегодня хотелось бы поговорить о том, с чего обычно начинается внедрение ITSM в компании — о каталоге услуг.
Как было понятно из прошлой статьи “Четыре порока обслуживания”, мы активно внедряем ITSM подходы в нашей компании. Сегодня хотелось бы поговорить о том, с чего обычно начинается внедрение ITSM в компании — о каталоге услуг.Выделение услуг оказалось не совсем простой задачей и мы столкнулись с массой сложностей:
- Можно принимать за ИТ-услугу программный комплекс или нет?
- Как выделить единого ответственного, если услуга составная и поддерживается двумя программными комплексами?
- Как определять по какой услуге зарегистрировать инцидент, если рухнула ИТ-инфраструктура в целом и почти все услуги не предоставляются.
Вот каких принципов мы придерживаемся при выделении любой услуги:
- Любая услуга должна иметь единого ответственного, который полностью отвечает за ее качество (своевременное устранение инцидентов, доступность и т.д.)
- Название и описание услуги должны быть понятны конечному потребителю (внутреннему клиенту) и при этом услуга должна предоставлять понятную ценность.
- Действующая услуга должна поддерживать как минимум один бизнес-процесс.
Давайте разберем эти принципы немного подробнее и поймем, как они помогут нам правильно выделять услуги. Да! Сразу хочу предупредить, что это наши принципы и мы не настаиваем на их применимости во всех организациях. Я лично видел несколько каталогов услуг, которые не подчиняются данным принципам.
Любая услуга должна иметь единого ответственного, который полностью отвечает за ее качество
Логически вроде все понятно. Если не будет единого ответственного, то не исключена проблема потери ответственности и последующий пинг-понг в устранении инцидентов, про который я писал в прошлой статье.
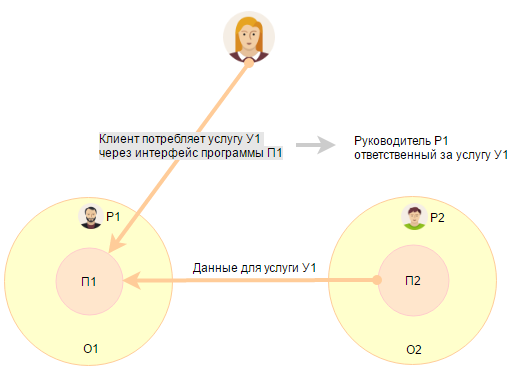
Но как определить ответственного за составную услугу. Например, есть услуга У1, суть которой в предоставлении интерфейса к определенному набору данных. Есть программное обеспечение П1, которое разрабатывает отдел О1. Программное обеспечение П1 только отображает данные, предоставляемые в рамках услуги У1, для всех сотрудников компании. Все данные для программного обеспечения П1 предоставляет программное обеспечение П2, которое разрабатывает отдел О2.
Кто является единым ответственным за услугу У1?
Мы для себя решили, что у нас действует интерфейсный принцип определения ответственности.
Что это значит?
Интерфейсный принцип определения ответственности
Ответственный за услугу = ответственному за приложение, в котором внутренний клиент потребляет услугу.
Почему? Потому что для клиента не должна быть понятна внутренняя архитектура услуги. Клиент потребляет услугу У1, используя интерфейс программы П1 и если с услугой что-то не так, то будет страдать имидж сотрудника, ответственного за программу П1 (имидж программы П1). И тут уже не важно, что 80% проблем с данными в программе П1 связаны с тем, что программа П2 плохо выгружает данные.
Ответственность за услугу на том, кто отвечает за конечное представление данных и его задача наладить взаимодействие с ответственным за приложение П2 так, чтобы воспринимаемое качество его услуги не страдало.
Название услуги должно быть понятно конечному потребителю и отражать понятную клиенту ценность
С первой частью все должно быть понятно. С клиентом нужно общаться на понятном ему языке, в общем. А в частности, называть услуги так, как они будут понятны клиенту.
Не надо использовать в названиях услуг имена протоколов передачи данных и тому подобные технические термины.
Например, вместо услуги “Передача сообщений по протоколу XMPP ” лучше использовать “Сервис передачи мгновенных сообщений”
Однажды я открыл методичку по физическому практикуму и во втором абзаце прочел следующее:
“Инжектированные в базу дырки должны диффундировать в направлении коллектора”
Надо быть проще и тогда будет понятнее.
Из названия услуги клиенту должна быть понятна ценность. Например, услуга “Автоматизация кассовых операций” несет понятную клиенту ценность. А услуга “Сеть передачи данных” нет. Не понятно в чем ценность такой услуги для обычного рядового пользователя. Зачем ему передавать данные !? Какую ценность он получит !?
ITIL достаточно строго определяет понятие ценности:
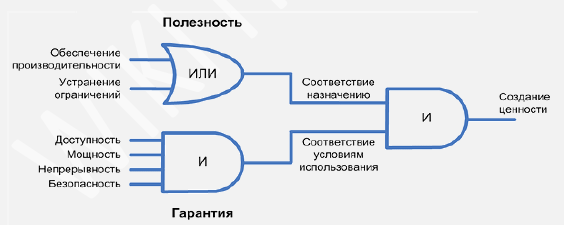
Услуга “Автоматизация кассовых операций” обеспечивает производительность, услуга “Прием заявок на сайте” устраняет ограничения (необходимость физически присутствовать в торговой точке). Услуга “Сеть передачи данных” не понятна рядовому пользователю и поэтому ценности для него не несет. Но несет ценность для ИТ-специалиста, который эту ценность понимает.
Данный принцип уберегает нас от внесения в каталог услуг того, что там быть не должно: внутренних услуг (таких, например, как ЛВС, виртуальные сервера и т.п.)
Недавно зашел на сайт nalog.ru и увидел, что чтобы получить налоговый вычет нужно потребить услугу “Заполнить справку 3НДФЛ” такая услуга не несет ценность. Во-первых 3НДФЛ термин бухгалтерский и непонятный, во-вторых совершенно неясно в чем ценность услуги. А вот услуга “Вернуть 13% от суммы медицинских расходов” несла бы ценность.
Действующая услуга должна поддерживать как минимум один бизнес-процесс
Опять же, все логично. Если услуга не поддерживает бизнес-процесс, то она бизнесу не нужна. И в каталоге услуг ей не место.
Именно этот принцип навел нас на мысль о том, что программный комплекс в самом общем случае нельзя принимать за ИТ-услугу. Программный комплекс может быть заменен другим программным комплексом, при этом услуга остается неизменной. Например, услуга “Телефония” поддерживает бизнес-процессы в call-центре. При замене одного программно-аппаратного комплекса ip-телефонии другим, услуга не должна меняться. Поэтому, услуги “IP-телефония Oktell” у нас нет.
Этот же принцип помогает нам понять, когда в одном и том же программном обеспечении следует выделить различные ИТ-услуги.
Если различные логические модули одного приложения поддерживают различные бизнес-процессы, то и услуги должны быть разными.
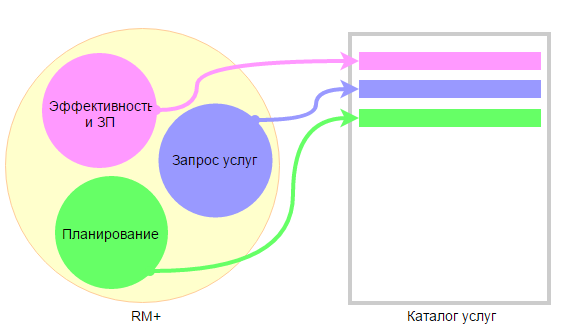
Например, есть приложение RM+, которое реализует различные аспекты управления компанией: Расчет эффективности и начисление ЗП, Планирование, Запрос услуг (Service Desk) и т.д.
Различные модули приложения RM+ поддерживают разные бизнес-процессы компании. Поэтому и услуги разные.
С другой стороны, есть сервис электронной почты, который тоже поддерживает самые различные бизнес-процессы компании, но при этом в сервисе нельзя выделить логические модули, которые бы поддерживали различные бизнес-процессы. Всем бизнес-процессом нужна одна и та же функциональность отправки электронных писем.
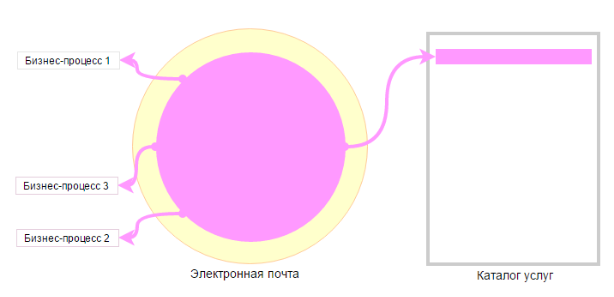
Поэтому в данном случае, услуга у нас одна — “Электронная почта”.
Есть еще один 4-ый принцип, про который явно не написал в начале статьи.
Если рухнул кусок инфраструктуры, то инциденты нужно заводить по тем услугам, которые клиент не может потребить в текущий момент.
Разберем на примере, что это значит.
Допустим клиент потребляет три услуги: Услуга 1, Услуга 2, Услуга 3. Все три услуги напрямую зависят от внутренней услуги: “Сеть передача данных” (данной услуги нет в каталоге услуг пользователя).
Допустим, что-то происходит с корневым свитчом. Внутренняя услуга “Сеть передачи данных” перестает предоставляться. Вслед за ней перестают предоставляться услуги из каталога услуг: Услуга 1, Услуга 2, Услуга 3.
Конечные клиенты ничего не знают об Услуге “Сеть передачи данных”. Все три услуги из каталога услуг в текущий момент не работают. По какой услуге Service Desk должен завести инцидент от конечного клиента, по какой услуге должны примениться SLA-нормы устранения инцидента и т.д.?
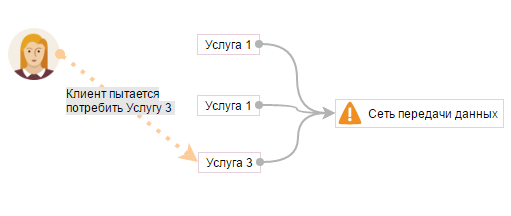
Наш ответ: По той, которую прямо сейчас хочет, но не может потребить клиент и по внутренней, про которую клиент ничего не знает. В данном случае по услугам: “Услуга 3” и внутренней услуге “Сеть передачи данных”. Если остальные услуги клиента не работают, но он и не пытается их использовать, то по ним инциденты можно не заводить.
Это все, чем хотелось бы поделиться в рамках данной статьи. Надеюсь, вам понравилось. Спасибо!
Немного подарков

Скидка в 20% на плагин Service Desk, который поможет оказывать услуги согласно ITSM-подходу в вашей компании, а также реализует много других полезных вещей.
Скидка действует в течение 3 недель.
Наши плагины для Redmine используются по всему миру и славятся своей гибкостью и низкой стоимостью.
