Технологическая инфраструктура «Группы М.Видео-Эльдорадо» сегодня – это значительно больше, чем гигантская цепочка контрольно-кассовых аппаратов в более чем 1000 магазинах по всей стране. Под капотом у нас онлайн-платформа, обеспечивающая взаимодействие с клиентами, машинное обучение, алгоритмы умного поиска, чат-боты, система рекомендаций, автоматизация ключевых бизнес-процессов и электронный документооборот. Под катом обстоятельный рассказ о том, что же подтолкнуло нас в сторону разбиения монолита на микросервисы.
Преданья старины глубокой
Для того, чтобы все это работало как часы, нам необходимо следить за развитием технологий и оперативно реагировать на запросы бизнеса. К сожалению, далеко не всегда базовая функциональность глобальных ERP-систем способна быстро реагировать на возникшие потребности внутренних клиентов. В 2016 году это стало одним из аргументов в пользу нашего перехода на микросервисную архитектуру.
Перед компанией стояла достаточно сложная задача, реализовать единую бизнес-логику работы с различными промо-механиками в процессе оформления клиентами заказов во всех каналах продаж и точках контакта (на тот момент: сайт, мобильное приложение, кассы и терминалы в магазинах и операторы в колл-центре).
При этом внутри ИТ-ландшафта у нас были большие монолитные системы вида Oracle ATG E-commerce platform, SAP CRM и другие. Повторение логики в каждой из них или реализация в одной и переиспользование в другой необходимой функциональности по нашим расчетам выливалось в годы времени и десятки миллионов инвестиций.
Поэтому мы собрали небольшую команду разработчиков и технически грамотных людей, которые были на тот момент в нашем распоряжении, и подумали, как нам сделать отдельный для наших нужд сервис. В процессе проработки мы поняли, что нам на самом деле нужен не один, а три-четыре рабочих инструмента. Так мы подошли к концепции микросервисной архитектуры первый раз.
Кодить решили на Java, так как в этом у нас был необходимый опыт. Выбрали Spring версии 3.2. В итоге получился некий распределенный микромонолит в три-четыре сервиса, тесно взаимосвязанных между собой. Несмотря на то, что разрабатывались они независимо, работать могли только все вместе.
Тем не менее, это был большой скачок в плане развития собственных технологий. Мы перешли с Java 6 на Java 8, начали осваивать Spring 3, плавно перейдя на Spring 4. Конечно же, это была определенная проба пера.
Мы успешно сократили сроки реализации проекта с туманных «месяцы на разработку», реализовав нужную нам кросс-канальную бизнес-логику фактически за два месяца.
Технологическая эволюция
В 2017-18 годах мы начали глобальный рефакторинг микромонолита. Концепция развития микросервисов понравилась, как и IT-специалистам так и бизнесу. Поток рабочих задач начал нарастать. Кроме того, мы продолжили выделять из корпоративного ИТ-ландшафта нужные разным потребителям функциональные блоки и переводить их на рельсы микросервисов.
Мы попытались идти в ногу со временем и скакнуть на Java 9, но успехом это не увенчалось. К сожалению, осязаемой выгоды мы от этого упражнения не получили, поэтому остались на Java 8.
Сервисов становилось все больше, ими надо было централизовано управлять, стандартизировать работу с ними. Тут мы впервые попробовали контейнеризацию. Docker-контейнеры тогда были большие и тяжелые по несколько сотен мегабайт.
Позже нам пришлось решать вопросы с балансировкой трафика и нагрузки на сервисы. В качестве решений мы выбрали Consul для внешних клиентов и Eureka для внутренних. Пробовали разные инструменты межсервисного взаимодействия gRPC, RMI. Так мы жили почти год, и как нам казалось, научились успешно создавать микросервисы и строить микросервисную архитектуру.
Пристегните ремни, мы тонем!
В 2019 году количество наших микросервисов увеличилось в разы, перевалив за отметку в 100+. Мы применяли новые решения для межсервисного взаимодействия, где это было возможно, старались внедрять event based подходы.
Между тем, все острее вставали вопросы оркестрации и управления зависимостями. Но самая большая перемена, которая коснулась нас уже в начале 2019 года, относилась к смене политики компании в отношении использования Java.
Перед нами был выбор, что делать дальше: остаться с Oracle и платить им много денег, инвестировать в собственную сборку open jdk или же попытаться найти какие-то реальные альтернативы.
Мы выбрали третий вариант и вместе с компанией BellSoft, которая входит в пятерку мировых лидеров, участвующих в разработке проекта OpenJDK, после ряда встреч и обсуждений, сформировали план перехода и пилотирования новой версии Java, причем совместив это с переходом сразу на Java 11. Процесс был непростой, но на всех тестовых испытаниях, мы не ощутили серьезных и неразрешимых проблем.
Следующим шагом для нас стало внедрение управления контейнерами под Kubernetes. Благодаря этому на некоторое время нам показалось, что все хорошо и мы достигли серьезного успеха. Но тут появились очередные проблемы с инфраструктурой. Она попросту не справлялась с постоянным ростом нагрузки.
Мы элементарно не успевали масштабироваться. Стала очевидной необходимость очередных кардинальных технических преобразований. Так мы начали смотреть в сторону облачных технологий и стремиться примерить их на себя.
Поднимись над облаками
Начало 2020 года обещало нам большой шаг в развитии наших внутренних технологий, понимании и совершенствовании нашей микросервисной архитектуры. Впереди виднелся большой шаг в облака. Увы, корректировать планы пришлось корректировать, как говорится, прямо по ходу пьесы.
Из-за пандемии COVID-19, вместо постепенной миграции и изучения возможностей облачных сервисов, нам пришлось всей компанией искать новые инструменты для удовлетворения изменившихся в связи с пандемией потребностей наших клиентов. Мы фактически писали очередные микросервисы, параллельно внедряя новые технологии и все же переходя на облачную инфраструктуру.
Для нас стал критичным размер контейнеров по двум простым причинам: это деньги за потребляемые облачные вычислительные мощности и время, которое тратит разработчик, а значит и вся компания на подъем контейнеров, их синхронизацию и конфигурирование, прогоны автотестов и так далее. И здесь мы в полной мере ощутили преимущество и полезность наших компактных контейнеров с рантаймом Liberica JDK.
Несмотря на разгар пандемии, мы за несколько месяцев реализовали и успешно запустили в продуктивную эксплуатацию два десятка микросервисов, полностью на базе облачной инфраструктуры.
В конце 2020 года мы сосредоточились на процессных вещах: много времени и сил инвестировали в построение продуктового подхода, в разработку микросервисов, в выделение и формирование отдельных команд со своими метриками и KPI вокруг различных направлений бизнес-подразделений.
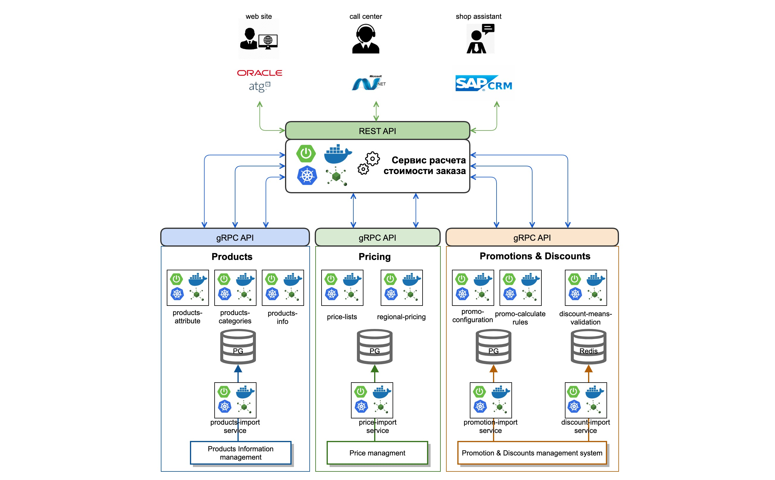
Распиливаем монолит на микросервисы на примере сервиса расчета заказа
Для того, чтобы не испытывать ваше терпение, хочется продемонстрировать конкретные примеры и логику работы с микросервисной инфраструктурой. Возьмем типичный расчет заказа в условиях стандартной информационной среды.
Мы столкнулись с целым набором вызовов. Наши мастер-данные находились глубоко в системах в бэк-офисе. Каждая ИТ-система – это классический монолит: база данных, сервер приложений. Интеграция мастер-систем с другими участниками ИТ-ландшафта выполнялась, как «точка-точка», то есть каждая ИТ-система интегрировалась сама, по-своему и каждый раз заново.
Интеграции были в основном двух типов: репликация на уровне баз данных, файловая передача данных. Логика расчета повторялась в каждой ИТ-системе отдельно, а именно на разных языках разработки, нет возможности переиспользовать даже код соседней команды.
Крайне затратно и почти нереально было синхронизировать логику расчета одновременно во всех системах, ввиду разных роудмапов и ресурсных затрат различных ИТ-систем.
Кроме того, в случае работы с жалобами клиентов нам было крайне сложно определить почему не была предоставлена корректная цена или та или иная скидка.
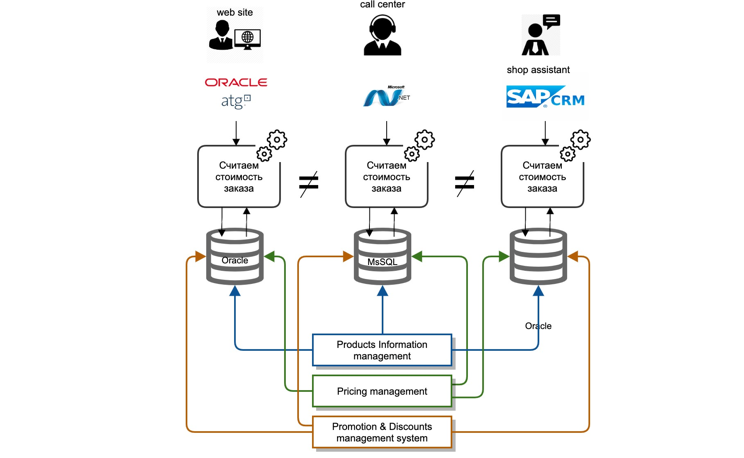
Что мы сделали? Провели анализ и определили контекст, который необходим для корректного расчета стоимости заказа. Далее, выделили бизнес домены и разделили их внутри на отдельные микросервисы. Так, например, выделили данные по товарам, которые было необходимо учитывать в процессе расчета стоимости заказа.
Мы реализовали сервис импорта данных из мастер-систем в режиме онлайн, используя очереди (Kafka). Поверх данных реализовали атомарные микросервисы, которые оперируют категориями товаров и их атрибутами (products-attribute-service, products-categories-service). Аналогично поступили с доменами в контексте Price и Promotion.
Отдельно вынесли логику и порядок расчета цен заказа в отдельный order-calculation-engine, реализовав единую унифицированную логику расчета цен и стоимости, применения скидочных средств и акционных карт.
Мы реализовали и стандартизированный REST API для всех клиентов, которые реализуют логику расчета заказа. Для межсервисного взаимодействия выбрали протокол gRPC с описание на protobuf3.
В результате стандартный микросервис сегодня выглядит примерно так: это spring boot application, который собирается в docker container при помощи GitLab CI и деплоится в Kubernetes cluster.
Что в итоге?
На пути нашей технической эволюции, во-первых, мы пересмотрели подход к процессу разработки самих сервисов и формированию команд. Мы сфокусировались на продуктовом подходе, укомплектовали команды исходя из максимальных принципов автономности.
При этом, чтобы команды соответствовали конкретным бизнес доменам и направлениям и, соответственно, могли на ряду с руководителями бизнес-функций участвовать в развитии того или иного направления бизнеса.
В плане технического развития, мы выбрали для себя, как один из инструментов межсервисного взаимодействия ─ асинхронное коннективити с использованием Kafka, в том числе и Kafka streams. Это позволило командам стать практически независимыми от других. Мы также активно используем и практикуем реактивные практики разработке, на примере проекта reactor. По-прежнему очень хотим попробовать project Loom.
Для ускорения разработки, мы сфокусировались на развитии нескольких технических и организационных факторов, которые позволили нам существенно влиять на сроки.
Технологический аспект — переход на облачные технологии, обеспечивший оптимальную скорость автоматизации процессов CI\CD. Скорость и длительность прогона полного регресса и деплоймента того или иного микросервиса здесь критична.
Для примера сегодня полный прогон (со всеми видами тестирования юнитов, контрактные, интеграционные) CI\CD Pipeline для работающего продуктивного бизнес-приложения ─ а это около 12-15 микросервисов связанных между собой) составляет около 31 минуты что на 7-8 минут меньше показателей начала 2020 года.
Таким образом, мы примерно на 17-18 % меньше времени тратим ожидания результата. Эта экономия позволяет нам заниматься другими продуктовыми задачами. Во многом это связано с тем, что мы используем компактные контейнеры на основе Alpine Linux, которые с каждым часом становятся все быстрее и легче.
Мы стали эффективнее в плане разработке микросервисов в целом. И это положительным образом сказывается на пользовательском опыте наших клиентов. Одной из ключевых метрик наших онлайн продуктов (сайт и мобильные приложения) сейчас является скорость, и Liberica JDK также позволяет нам добиваться этого прироста, по производительности который мы конвертируем в позитивный опыт наших покупателей.
Кроме того, правильный подход к разработке микросервисов позволил нам существенно ускорить время запуска нашего продукта на рынок. Мы научились выводить в продакшен отдельные сервисы, используя при этом различные стратегии деплоймент A\B, cannery и другие по мере необходимости. Это дает возможность быстро получать обратную связь о работе микросервисов.
Мы за два месяца разработали и внедрили пару новых сервисов в покупательском опыте. Речь про так называемую быструю доставку товаров в течение 2 часов (используем различные агрегаторы такси и доставки) и выдачу наших заказов в самых неожиданных местах (в магазинах «Пятерочка» или отделениях «Почты России», даже на парковках больших бизнес-центров).
У части клиентов Группы «М.Видео-Эльдорадо» благодаря нашим микросервисам, появилась возможность уехать на такси со своим товаром прямиком из магазина домой.
Творческие планы
В наших планах на 2021 год активное развитие облачной инфраструктуры и переход полностью на концепцию Infrastructure as a code («Инфраструктура как код»).
Мы планируем уделять большое внимание построению прозрачных решений для контроля и взаимодействия микросервисов в виде Service Mesh-решения на базе Istio и Admiral. Нас ждет связанная с этим большая работа по доведению до ума и улучшениям всего стека Observability, мониторинг трассировки запросов и логирования сообщений.
Также в наших планах попробовать применять технологии serverless в том числе есть желание попробовать это в java. Кроме того, есть такая пока далекая но не кажущаяся нереальной идея построить multi-Cloud инфраструктуру и экосистему.
Если интересно потрогать наш технологический стек руками, не стесняйтесь, работы хватит на всех. Запись в добровольцы осуществляется 24/7: здесь. Добро пожаловать.
Польза, лайфхаки, личный опыт

Дмитрий Чуйко, старший архитектор по производительности BellSoft, о секретах крошечных Docker-контейнеров для микросервисов Java:
─ Скорость сегодня прямо влияет на прибыль организации. Чем меньше время трансфера и деплоя софта, тем больше обрабатывается данных и скорее запускаются сервисы. Отсюда тренд на компактные образы Docker-контейнеров. Быстрые и полнофункциональны, они экономят драгоценное время во всех средах: разработка приложений, тестирование и эксплуатация.
Поэтому для микросервисной архитектуры (и не только) стоит рассмотреть контейнер в разрезе двух компонентов, которые всегда влияют на объем занимаемой памяти. Это базовый образ Linux и JDK. Если ваш проект недавно перешел на микросервисы, об этой архитектуре я подробно рассказываю в блоге, а здесь опишу два способа уменьшить контейнер.
1. Переключаемся на образ легкой ОС
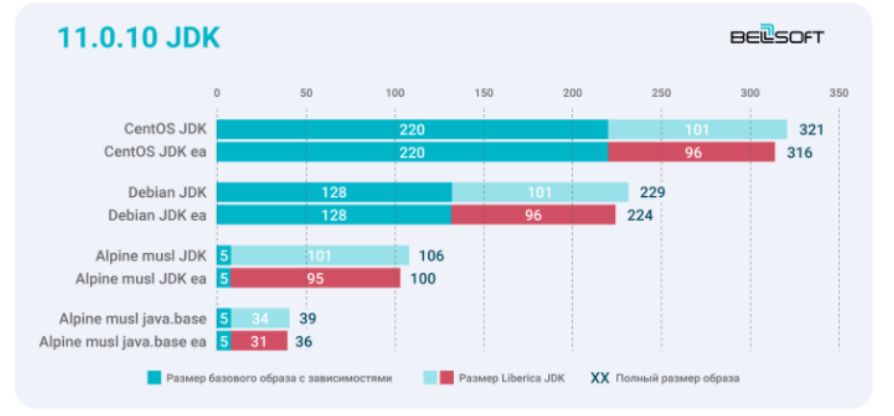
С тяжелой полной версии CentOS перейдите на CentOS slim. Недостаточно? Переключитесь на Debian. Или рассмотрите Alpine musl. В BellSoft мы берем Alpine Linux, поскольку его базовый образ — самый легкий в семействе Linux. Сравните на графике размеры контейнеров с образами Liberica JDK 11.0.10 + 11.0.10 в раннем доступе для трех дистрибутивов Linux.
Бинари Liberica EA меньше на дополнительные 3–6 МБ и это 14,7 % для образа Alpine musl java.base. А в среднем улучшение составляет 7,6 %. Если не требуется компилировать приложения внутри Docker-образа, можно использовать JRE или java.base. Для Liberica JRE EA наблюдается аналогичная положительная динамика — в среднем аж на 16 %.
В микроконтейнерах мы используем вариант поставки Liberica Lite для облачных инстансов и экономии ресурсов. Если интересно, влияет ли сокращение объема занимаемой памяти в статике на функциональность, ответ — нет. Уменьшенные бинарные файлы по-прежнему соответствуют спецификации Java SE и обеспечивают все функции JVM, доступные в варианте Standart, включая все JIT-компиляторы (C1, C2, Graal JIT Compiler), сборщики мусора (Serial, Parallel, CMS, G1, Shenandoah, ZGC) и компоненты serviceability, если они нужны.
2. Помогаем JDK сбросить лишний вес
Второй способ уменьшить контейнер — это минимизировать рантайм за счет исключения ненужных модулей с помощью jdeps и jlink. Код внутри этого файла — небольшое приложение, которое поможет. Запустите инструмент анализа зависимостей Java (jdeps). Он обрабатывает байт-код Java, т. е. файлы классов или JAR, которые их содержат, и проверяет статически объявленные зависимости между классами. Но jdeps можно применить и для составления списка модулей JDK, от которых зависит Java-приложение. Оставьте только те, которые нужны в нативном образе, и избавьтесь от остальных.
Благодаря анализу с помощью jdeps мы видим, что код использует только java.base. В случае крупного приложения с большим числом зависимостей и библиотек для уменьшения рантайма стоит использовать jlink. К счастью, в BellSoft уже есть Docker-образ с java.base. Вот образ на DockerHub, подготовленный с помощью этого приложения.
Запустим его с docker run –rm bellsoft/liberica – openjdk -demos- asciiduke.
Для большинства CLI-like приложений с интерфейсом командной строки достаточно одного модуля java.base. И весь образ с рантаймом Liberica JDK Lite и Alpine Linux musl на борту будет занимать всего 40,4 МБ вместе с приложением.
После упаковки и запуска этот крошечный образ и дает нам самый маленький контейнер из существующих в мире.
Enjoy!