Или как с помощью умного анализа потребностей клиентов сформировать идеальный ассортимент в магазине электроники.

Вы когда-нибудь задумывались, почему на полках любых магазинов — от гипермаркетов электроники до гастрономов — стоят именно эти товары и именно в такой последовательности? А Категорийные Менеджеры (и дата-сайентисты, кстати) думают об этом постоянно. Сегодня мы расскажем, как в М.Видео-Эльдорадо использовали искусственный интеллект для заполнения полок и изучили потребности клиентов при управлении ассортиментом.
Традиционно планирование категории основывалось на исторических продажах, экспертной оценки динамики рынка, косвенных источниках данных, в совокупности с прогнозом будущих продаж.
Начнем с проблемы. Категорийные менеджеры (КМ) в любом ритейле решают, какой товар будет стоять на полке или будет доступен в интернет магазине, а также определяют его цену и применяемые скидки. Как же принять решение, что именно ставить на полку?
Разумеется, на полку хочется поставить тот товар, который будет лучше всего продаваться в штуках, а также приносить максимальную прибыль в деньгах. Получается, что для каждого товара необходимо сделать прогноз штучных продаж, умножить его на маржинальность одной штуки и получить ожидаемую прибыль.
Далее, можно отсортировать все товары по значению этой прибыли и выставить на полку те, у которых она максимальная. Размер полки ограничен (в случае с физическим магазином), размер склада тоже (в случае с интернет-магазином), поэтому приходится выбирать.
Клиенты не просто покупают товары, они покупками закрывают определенные потребности. Это можно учитывать для повышения эффективности
Какие недостатки у подхода выше? Первый и главный в том, что товары с точки зрения клиента не являются независимыми. Что имеется в виду. Давайте представим, что по историческим данным у нас хорошо продаются две модели телевизоров. У них одинаковая диагональ, одинаковый по качеству экран и сопоставимый набор опций. Оба телевизоре влезают на полку магазина. Обратите внимание, что речь идет именно о полке, то есть о том, куда можно выложить товар, чтобы клиент его увидел. Сколько телевизоров на складе мы не рассматриваем.
Давайте еще представим, что есть третья модель телевизоров, которая продается несколько хуже, чем первые две. Причем не обязательно хуже в штуках, например, маржинальность ниже. Логика, описанная выше говорит о том, что такая модель не будет поставлена на полку, если полка вмещает только два телевизора.
Однако, этот третий телевизор очень нравится одному умному категорийному менеджеру - он во что бы то ни стало хочет поставить его на полку и задается таким вопросом: А что если первые два телевизора хоть и хорошо продаются, но продаются внутри одной и той же группы клиентов для одних и тех же целей. Другими словами, они закрывают всего одну популярную потребность. То есть, клиент, купивший телевизор 1 с такой же готовностью купил бы и телевизор 2 и наоборот. Случайные факторы, сравнимые с подбрасыванием монетки, влияют на то, что один клиент покупает телевизор 1, а другой - телевизор 2 (мы, конечно, сильно упрощаем).
И,если это так, то на полке можно оставить только один из этих двух телевизоров (самый маржинальный, например, или самый продающийся в штуках), а рядом поставить тот третий. Экономический эффект от продажи первых двух телевизоров не уменьшится (при условии, что мы обеспечим запасы модели на складе). При этом, суммарный результат от продажи всех телевизоров в целом значительно вырастет, так как к продажам первых двух моделей мы добавляем продажи третьей модели, которые появятся за счет новых клиентов, увидевших и купивших третью модель.
Понять, что потребности есть - одно, научиться их выделять и использовать в работе - другое
Как же проверить, что товары закрывают одну и ту же потребность? Как автоматизировать расчет таких потребностей? Как интегрировать такой подход в процесс работы категорийного менеджера?

Основной инструмент выявления потребностей клиента - построение дерева клиентских предпочтений
Начнем с того, что нам важны не столько сами потребности, сколько отнесение наших товаров к ним. Другими словами, наш образ результата это таблица, где для каждого товара проставлена потребность, которую он закрывает.
Говоря математически, какую именно задачу мы решаем? Есть два варианта: задачу классификации или задачу кластеризации. Задача классификации означает, что у нас есть список потребностей, сформированный каким-то образом, есть какое-то подмножество товаров, для которых отнесение товара к потребности уже проставлено и нам необходимо отнести оставшиеся товары к потребностям.
Здесь возникает вопрос, как нам сформировать первоначальный список потребностей и отнести к ним товары, ведь мы заранее не знаем, какие потребности существуют. Собственно товары и их продажи - наш путь, чтобы это узнать.
Соответственно, напрашивается задача кластеризации. То есть, все товары необходимо разбить на набор кластеров, которые и были бы потребностями. Интерпретация же самих потребностей дело вторичное, нам важно знать, относится какая-то пара товаров к одной и той же или к разным потребностям, что это за потребности - менее важно.
Первый вопрос, по какому параметру товара будем делать кластеризацию так, чтобы она отразила то, что нам нужно, а именно потребности. Параметра, отражающего потребность, у товара нет и быть не может, иначе задача была бы решена. Такой параметр нам нужно было ввести. В силу того, что товары, закрывающие одинаковую потребность должны быть близки друг к другу, мы ввели меру близости для каждой пары товаров, отражающей принадлежность к одинаковой потребности.
Чтобы сделать кластеризацию по потребностям нам нужно определить меру близости товаров (мера, в которой два товара закрывают одну потребность)
Соответственно, получив меру близости мы могли бы рассчитать матрицу расстояний между каждой парой товаров и на основе этой матрицы сделать кластеризацию. Осталось придумать, как считать расстояния.
Мы рассмотрели три подхода:
На основе покупок. Если клиент за какой-то период покупает разные товары из одной и той же категории, то, наверное, эти товары для него равнозначны. Если похожее поведение мы найдем у большого количества клиентов, то такие товары и будут закрывать единую потребность;
На основе свойств самих товаров. Телевизоры с одинаковой диагональю с одинаковым типом матрицы и в одинаковом ценовом сегменте, наверное, закрывают близкие потребности. Добавим сюда еще какие-то свойства, например, цвет корпуса, тип подставки и, кажется, вот оно полное описание товара. Все свойства можно закодировать, из этих чисел сделать вектора (координаты в пространстве свойств), и расстояние между товарами просится само - Евклидово расстояние между векторами свойств;
На основе совместных просмотров продуктов на сайте М-Видео или Эльдорадо. Не ожидали? А почему нет? Здесь мы исходим из гипотезы, если клиент просматривает несколько товаров из одной и той же категории в рамках одной сессии, то, наверное, эти товары для него похожи. Если же многие клиенты делают тоже самое, то видимо, между этими товарами точно есть что-то общее.
Давайте по очереди рассмотрим каждый из подходов.
Мера близости на основе покупок. Наверное, это самая точная и справедливая, так как, если человек в течение определенного времени покупает разные товары из одной и той же категории, то с большой вероятностью эти товары для него заменяют друг друга.
К сожалению, такой подход трудно применим в ритейлере электроники, так как клиенты не делают покупки каждый день, для некоторых категорий каждый месяц или даже не каждый год. Мы не покупаем новый холодильник каждый месяц или новый телевизор. Даже телефоны мы обычно меняем максимум раз в год. По этой причине мера близости на основе покупок хорошо бы подошла продуктовому ритейлеру, а для электроники не очень.
Мера близости на основе свойств товаров. Это довольно очевидная мера близости. Возьмем чайник, например. Они, чайники, бывают стеклянные, металлические и пластиковые, бывают чайники, а бывают термопоты. Чайники также бывают премиальные (сильно отличающиеся по цене от других), разноцветные, с различными функциями касательно поддержания температуры, подогрева вместо кипячения и так далее.
Далее напрашивается следующее заключение: если два чайника похожи по свойствам, то они закрывают одну и ту же потребность. Это очень логичный и простой вывод: если у меня два чайника, которые оба металлические, одинакового размера, с одинаковым функционалом и примерно равной ценой и один маржинальнее второго, то мы можем поставить на полку один вместо двух и не ошибемся. Реальность однако показывает, что ошибемся.
Существует расхожее мнение, что чем большее разных товаров выставишь на полку (если полка позволяет), тем больше будут продажи. Люди покупают глазами. Чайники, даже очень похожие по свойствам могут отличаться внешне. Соответственно, вот этот чайник может нравится, а вот этот - нет.
Кроме этого, в некоторых категориях товаров существует сильная рекламная поддержка от производителей и товары, даже сильно схожие по свойствам, в голове покупателей могут отличаться как небо и земля.
Также немаловажно и то, что свойства товара в системах заполняются людьми, которым как и прежде свойственно ошибаться. Другими словами, мера близости на основе свойств товара тоже не идеальна. Вопрос, однако, насколько она плоха. Наверное, главный ее недостаток состоит в том, что точно померить это мы не можем, но вот приблизительно можем оценить. Как - опишем чуть ниже.
Мера близости на основе просмотров с сайта аналогична мере на основе покупок, но основывается на просмотрах. Преимуществом данной меры является то, что она очевидно коррелирует с поведением клиента в отличие от меры на основе свойств. Со свойствами мы только предполагаем, что для клиента товары со схожими свойствами закрывают схожие потребности. В данном случае мы это объективно наблюдаем.
Какие же минусы у данной меры? Самым очевидным минусом является то, что просмотры коррелируют с выдачей на сайте. От чего зависит выдача? От популярности товара (по продажам), от промо. Все это, конечно, дает смещение. Однако, промо влияет на предпочтения клиентов в любом случае.
Для оценки близости на основе просмотров с сайта необходимо построить метрику между парами товаров, которая описывает логику «чем больше совместных просмотров, тем меньше расстояние между товарами». То есть, в данном случае мы работаем со множествами. На ум приходят метрики расстояний Жаккара и Юле, мы попробовали обе и остановились на Жаккаре по причине простоты и распространенности метрики. Плюс, с ним получились более понятные бизнес-результаты.

Мы обещали рассказать про то, как оценить, насколько плоха метрика на основе свойств. Так вот, мы понимаем, что метрика на основе просмотров не идеальна, но тем не менее она коррелирует с потребностями клиентов. Таким образом, если метрика на основе свойств имела бы право на жизнь, то она хотя бы частично коррелировала бы с мерой на основе просмотров. Давайте эту корреляцию и посмотрим.

Как вы видите, корреляция на уровне белого шума. Отсюда делаем вывод, что мера по свойствам нам точно не подходит, хотя сами свойства нам еще пригодятся (к этому вернемся позже).
Итак, мы определили меру близости для каждой пары товаров, что позволяет нам построить матрицу расстояний, где по каждой из осей товары, а на пересечении расстояние между ними на основе меры по просмотрам. Осталось сделать кластеризацию.
Пример матрицы расстояний:

Обратите внимание, что матрица расстояний достаточно разрежена, так как для каждого конкретного товара есть лишь небольшое количество «заменителей».
Определив меру близости, пора сделать кластеризацию по потребностям. Вот для чего нужно наше дерево
Как будем делать кластеризацию? Классическая кластеризация нам здесь не подойдет, так как, во-первых, мы не знаем заранее, сколько будет кластеров, а во-вторых, совсем не факт, что все товары аккуратно группируются вокруг нескольких центров.
Более вероятно, что одни товары похожи на другие, те другие еще на какие-то и так далее. То есть, похожесть выстраивается через «посредников», а не напрямую. Здесь больше подходит иерархическая кластеризация. Нам нужно построить дерево близких товаров, и крупные ветки этого дерева назвать потребностями. Вот мы и пришли к дереву клиентских предпочтений (потребностей).
Присвоим каждому товару свой кластер. Далее будем собирать товары по парам, минимизируя выбранную выше метрику (расстояние Жаккара). После первой итерации в каждом кластере у нас будет по два товара, как теперь собирать пары товаров в более высокоуровневый кластер?
Есть много способов (минимальное расстояние, среднее расстояние, общее расстояние, метод Ward и другие), но, учитывая саму метрику, которая не является евклидовой и смысл иерархии, предполагающий, что каждый товар в кластере должен репрезентировать определенную потребность покупателя, мы остановились на методе «average».
Кластера собираются вместе тогда, когда среднее расстояние между всеми их товарами минимальное среди всех возможных пар кластеров. Такой алгоритм продолжает выполнятся, пока у нас не останется 1 большой кластер со всеми товарами, в процессе построив дерево разбиений товаров на предпочтения покупателя (мини-кластера).
А что, ваша кластеризация у вас сразу получается? А как же перебор параметров алгоритма? А как же интерпретация (разметка) результата?
Итак, что же нужно, чтобы построить законченное дерево? Как и в любой кластеризации необходимо перебирать параметры, чтобы получить оптимальное дерево. Давайте рассмотрим несколько деревьев на примере одной категории и поймем, чем они отличаются.
Вот такое дерево получилось, например, после первого расчета подкатегории Холодильники.
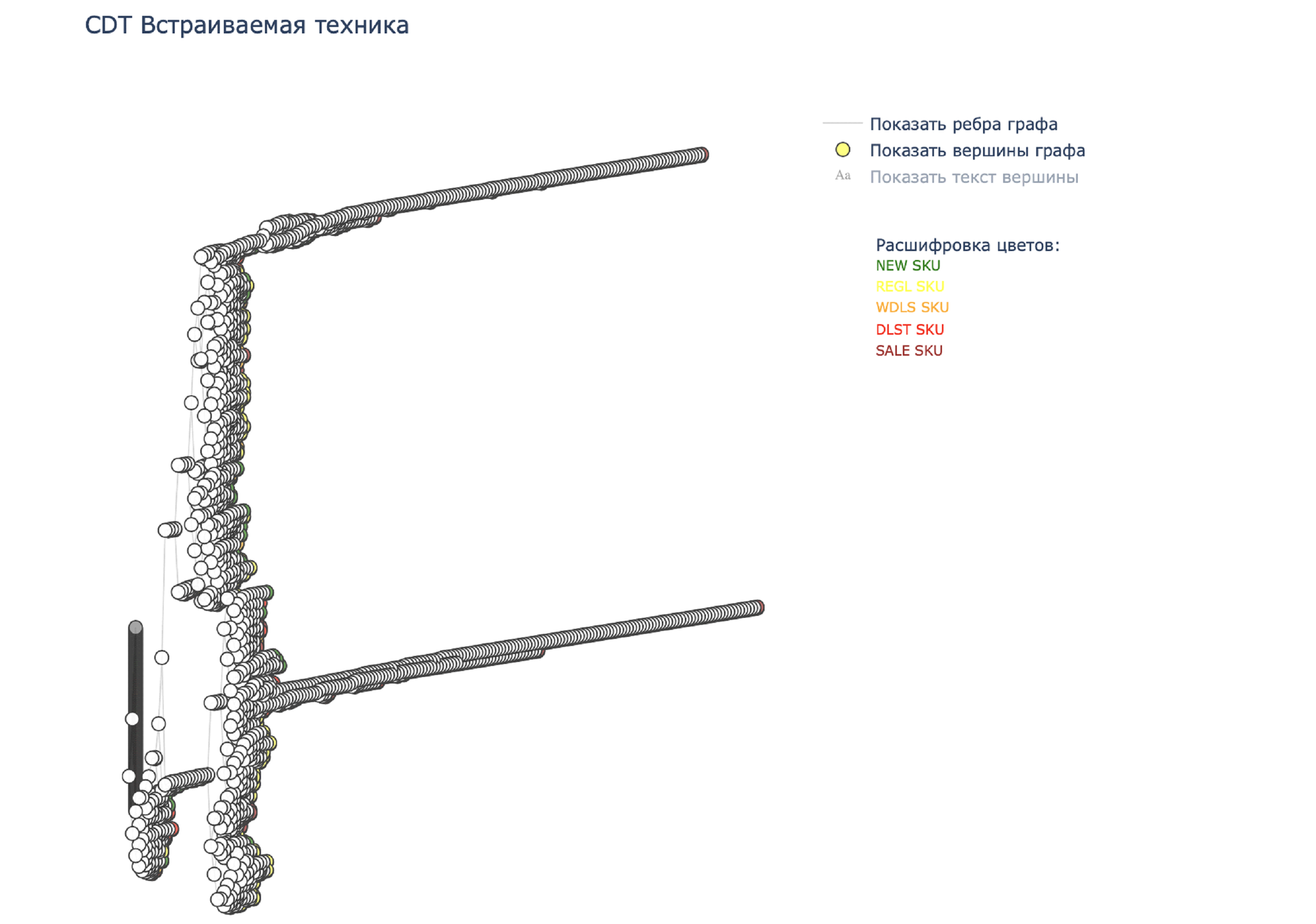
Выбрав изначальные параметры видим, что несколько веток слишком «размазаны» по горизонтали (скорее всего в них входят SKU с низкими просмотрами и другими показателями продаж), продолжим перебирать параметры для схлопывания их в один кластер. Посчитаем еще раз.

Дерево стало заметно лучше, но все еще есть сильно разбросанные ветки. Давайте еще раз.

Важно не только сделать кластеризацию, но и сделать грамотную бизнес-интерпретацию результата. Никто лучше Категорийного менеджера это не сделает, и нам пришлось создать целый визуальный инструмент для такой разметки
Давайте посмотрим, как выглядит разметка дерева клиентских предпочтений с точки зрения категорийного менеджера на примере полученного нами дерева по холодильникам.
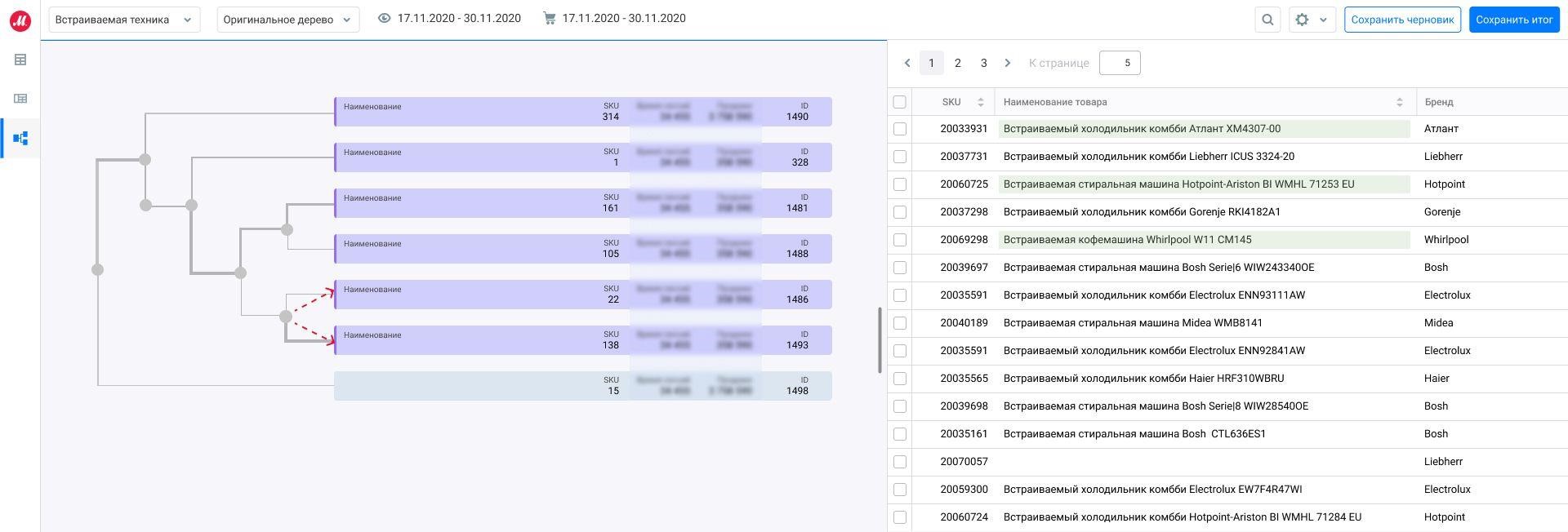
При разметке дерева КМ движется слева направо, последовательно раскрывая кластеры. Далее все рисунки и описания соответствуют нашему примеру «Встраиваемая техника».
Пользователь перемещается по дереву. Справа в таблице видны товары, которые есть в выделенном кластере. На рисунке выбранный (от которого идут стрелки) содержит в себе разные группы товаров. Необходимо исследовать оба дочерних кластера.
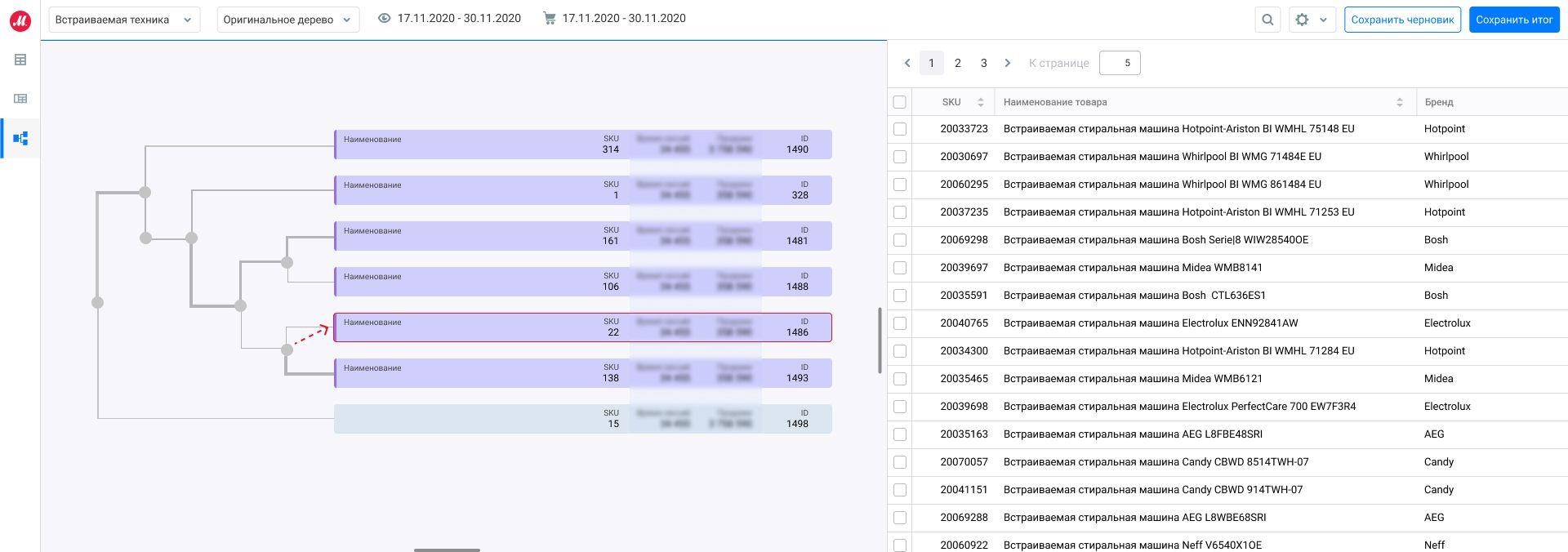
При просмотре выяснилось, что верхний дочерний кластер содержит только «Встроенные стиральные машины» (таблица справа).
Далее при движении по дереву был найден кластер из четырех товаров со схожими характеристиками в одной ценовой категории.

Этот кластер подходит для создания потребности. После создания дерево выглядит так:
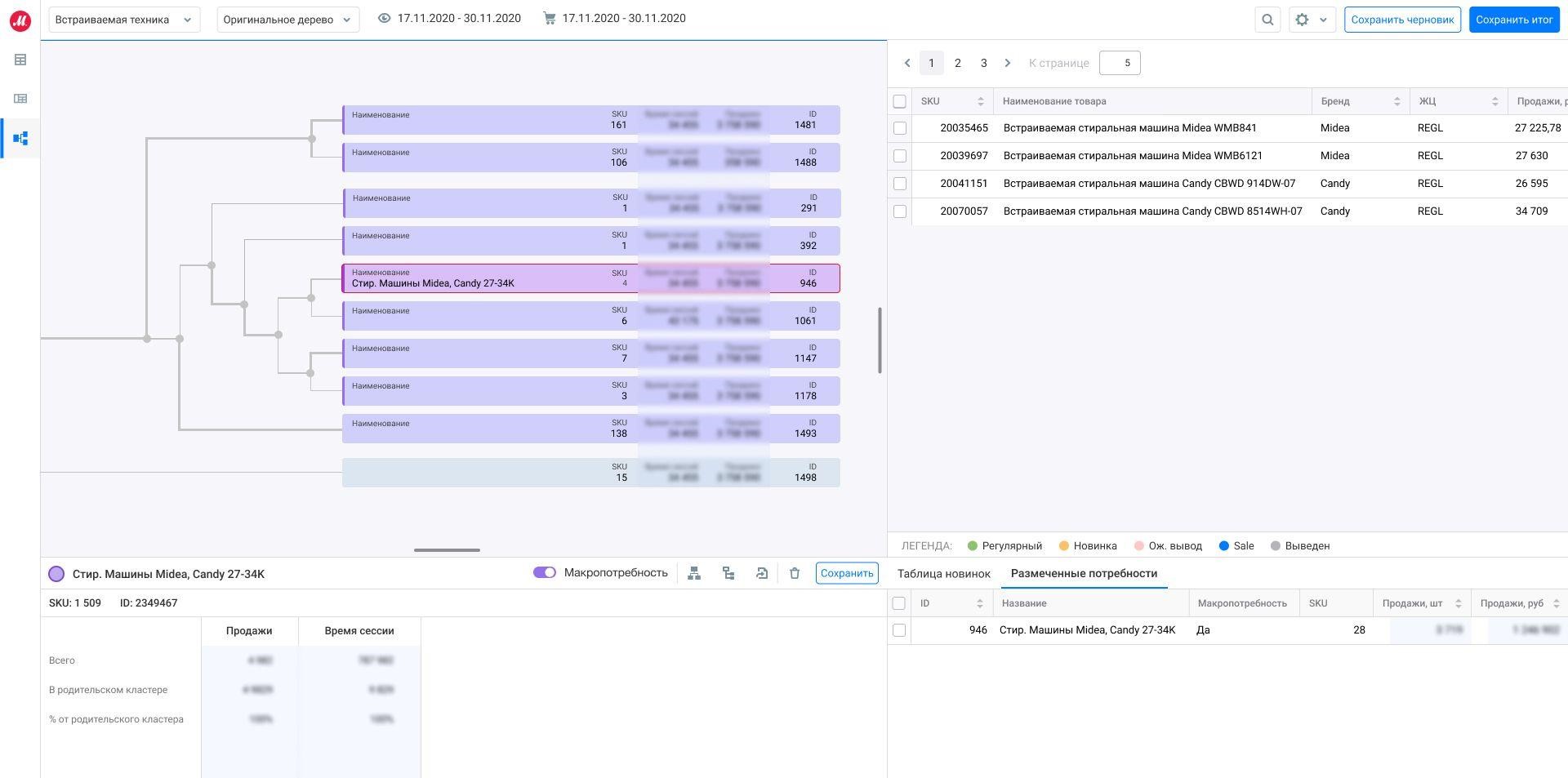
Итак, мы получили размеченные потребности клиента по группе «Холодильники» и далее будем использовать это дерево для оптимизации ассортимента в магазинах, как в физических, так и в интернет. О том, как мы это делаем, читайте в следующих публикациях. Пока давайте еще коротко остановимся на новой роли категорийного менеджера с учетом изложенных изменений в подходе.
Новая роль категорийного менеджера
Построение CDT (Customer Decision Tree) значительно облегчает работу КМ, потому что на базе уже созданной разметки и кластеризации он может выделить отдельные группы товаров и формировать ассортимент, опираясь на актуальные потребности покупателей.
Основанная на реальных данных аналитика помогает быстрее принимать решения, а также избежать ошибок интерпретации косвенных данных о клиентах и избавиться от перебойности и искаженности метрик получаемых в опросах Например, после внедрения системы мы сразу же убедились, что корреляции по свойствам продуктов может и не быть. То есть люди не рассматривают чайники одного и того же объема и бренда — покупатели всегда исходят из каких-то своих отправных точек, и CDT помогает их найти.
Конечно, ассортимент управляется в рамках определенной номенклатуры (товары для кухни, цифровые товары и так далее). Но для ее выстраивания необходима иерархия товаров — экспертная и даже техническая. И сегодня речь идет о том, чтобы категорийные менеджеры получали уже структурированную информацию “на лету”.
Например, CDT может показать, что определенная клиентская потребность угасает. Месяц назад пользователи хотели покупать компьютерные мыши с подсветкой, а сегодня — уже нет. В результате менеджер может ее деприоритизировать в рамках логики построения ассортимента. Мы как раз работаем над тем, чтобы добавить автоматизацию принятия таких решений в систему и сократить объем логики, которую КМ нужно держать в голове, тем самым освобождая бесценный человеческий ресурс на более сложные и творческие задачи, которые крайне актуальны в условиях современного ритейла.
