Здравствуйте, уважаемые Хабраюзеры!
Так сложилось, что это третий пост в блоге нашей компании, и, как и первые два, он посвящен вопросам многопоточного программирования и проблемам, которые при этом возникают. Получилось так неслучайно, ведь мы на собственной «шкуре» испытали, что ситуации, возникающие при написании многопоточных программ, невероятно сложны для отладки, так как во многом определяются динамикой работы программы на конкретной аппаратной платформе. Уверен, что большинство программистов сталкивались с ситуацией, когда программа, которая прекрасно работает на одном компьютере, на другом совершенно неожиданно начинает дедлочиться практически «на ровном месте».
При написании своих предыдущих постов мы совершили непростительную ошибку, начав рассматривать взаимные блокировки со сложных, но, как нам казалось, наиболее интересных случаев. Этого уважаемая аудитория Хабра, к сожалению, не оценила. Спешим исправиться, и, пусть не с первого раза, но все-таки подойти к рассмотрению проблемы блокировок с самого начала. Однако мы все же рассчитываем, что вы знаете, зачем нужны и какие бывают средства синхронизации при написании многопоточных программ.
Рецепты, описанные в этом посте весьма просты, но далеко не все даже профессиональные программисты используют осознанно, руководствуясь скорее ощущениями «почему-то кажется, что не стоит захватывать тот мьютекс из под захваченного этого». Так жили и мы долгие-долгие годы, когда в один ужасно ответственный момент не обнаружили, что на «железке», которую нужно срочно отправить заказчику, наш любимый софт не может и часа прожить без дедлока. Убив на решение этой задачи несколько дней работы своих ведущих программистов, мы приняли решение, которое изменило нашу жизнь – мы занялись суровой формализацией ситуаций взаимных блокировок, включающей строгие математические доказательства того, почему так можно делать, а так нельзя. Надо сказать, что исследование наше выродилось в кандидатскую диссертацию одного из сотрудников, но я не уверен, что использованный там формат изложения будет интересен здесь…
Итак, о блокировках с самого начала…
Не будем вдаваться в сложные математически выверенные определения ситуаций взаимных блокировок и скажем просто: взаимная блокировка – это такое состояние системы, в котором один поток ожидает наступления чего-то, а это что-то не может произойти потому, что другой поток ожидает наступления чего-то от первого потока.
Традиционно принято считать, что причиной блокировок всегда являются мьютексы (mutex), однако это не совсем точно. Причиной блокировок могут являться любые средства и механизмы синхронизации, которые предполагают ожидание чего-либо одного потока со стороны другого, например, ожидание сигнала на переменной кондиции (condition variable) или, что значительно менее очевидно, ожидание завершение другого потока (wait/join thread). В теории, на самом деле, второй случай является тем же самым «ожиданием сигнала», однако ввиду неявности этой операции синхронизации, при поиске дедлоков о ней просто забывают, как о потенциальном источнике угрозы и часто не замечают в коде.
Прежде, чем перейти к рассмотрению конкретных ситуаций простейших взаимных блокировок хочется сказать несколько слов о модели, которую мы используем для описания многопоточных программ и возникающих в них ситуаций.
Мы назвали эту модель – «моделью переходов» и представляет она собой совокупность ориентированных графов, где каждый граф представляет собой поток (субъект). Каждый граф имеет одну начальную вершину, соответствующую состоянию, когда ни одно средство синхронизации еще не задействовано, и имеет одну конечную вершину, соответствующую состоянию, когда ни одно средство синхронизации уже не задействовано. Предполагается, что при достижении конечной вершины поток автоматически начинается сначала. Все другие вершины графов представляют собой операцию в отношении того или иного средства синхронизации, например, L (lock) – захват мьютекса, U (unlock) – отпускание мьютекса и т.д. Для доказательств утверждений важно, что модель игнорирует время между выполнениями отдельных операций в отношении средств синхронизации, расширяя тем самым возможный диапазон динамик до бесконечности. Если аудитории Хабра интересна математическая и физическая суть модели, то я готов написать отдельный пост на эту тему, а здесь… всего лишь начало долгой, но интересной истории о многопоточном программировании.
Пример модели, состоящей из одного потока (субъекта):
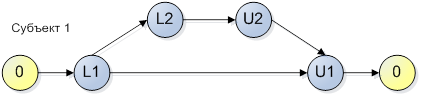
Рисунок 1.
В соответствии с данным рисунком, субъект может пройти по двум веткам: 0, L1, U1, 0 или 0, L1, L2, U2, U1, 0. Эта схема может рассматриваться, как конечный автомат, грамматика которого включает две фразы {0, L1, U1, 0} и {0, L1, L2, U2, U1, 0}. Будем считать, что время перехода между действиями в отношении средств синхронизации конечно, т.е. алгоритмически корректно. Не будем считать ошибкой синхронизации захват и удержание мьютекса в течение ожидания какого-либо действия пользователя, которое потенциально может никогда не наступить.
Для исследования программы на потенциальную возможность возникновения ситуации взаимной блокировки необходимо составить цепочки выполнения всех возможных субъектов в программе.
Пусть в нашей программе помимо потока (субъекта), приведенного на рисунке 1, есть еще один:

Рисунок 2.
Смею утверждать, что наша программа имеет потенциальный deadlock и даже, если ваши тестировщики утверждают, что все прекрасно работает, то вы не застрахованы от ситуации, что на другом «железе» ваша программа поведет себя вот так:

Рисунок 3.
Ничего не мешает нашим двух независимым потокам выполниться так: поток 1 успел захватить мьютекс 1, затем планировщик переключил выполнение на поток 2, который захватил мьютекс 2, и после этого оба наших потока пытаются захватить мьютексы, которые уже захвачены – deadlock!
Назовем систему потоков (субъектов) несовместимой, если существуют хотя бы один вариант наложения цепочек их выполнения, при котором наступает ситуация взаимной блокировки. Соответственно, совместимой является такая система субъектов, для которой не существует динамики, при которой возможно возникновение ситуации взаимной блокировки.
Рассмотренные два субъекта являются несовместимыми, т.к. существует вариант наложения, приведенный на рисунке 3, при котором возникает ситуация взаимной блокировки. Отметим, что такие субъекты не обязательно будут приводить к блокировке (зависанию) программы. Динамика конкретной работы (время переходов между обращениями к средствам синхронизации) может быть такова, что найденный вариант наложения никогда не проявится в реальности. В любом случае, программный код, описываемый такой моделью, является потенциально опасным и блокировки могут проявиться при портировании на другую программную или аппаратную платформу, а также просто при изменении условий функционирования.

Рисунок 4
Важно помнить, что потоки могут быть попарно совместимы между собой, но не совместимы в большей комбинации. На рисунке 5 показана модель программы, где все субъекты попарно совместимы между собой, но все вместе приводят к ситуации взаимной блокировки.
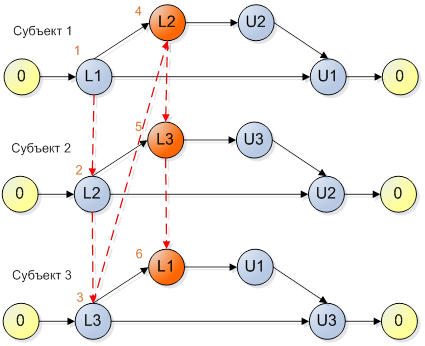
Рисунок 5
На рисунке 6 показан другой вариант совмещения цепочек выполнения для модели, представленной на рисунке 5, при котором возникает взаимная блокировка.

Рисунок 6
Прямо так и хочется сказать: Как страшно жить!
И это было бы действительно так, если бы не было двух очень простых правил, которым интуитивно следуют профессиональные программисты, зачастую даже не задумываясь, почему они так делают.
Всегда отпускайте захваченные мьютексы в обратном захвату порядке, т.е. руководствуйтесь логикой «первый захвачен – последний отпущен».
Всегда соблюдайте один и тот же порядок захвата мьютексов.
Если вы в одном потоке захватываете мьютекс 1, а затем мьютекс 2, то недопустимо захватывать их в ином порядке в другом потоке.
На самом деле, правило не так просто, как кажется на первый взгляд. Еще раз посмотрим внимательно на Рисунок 6. Там это правило нарушено, но это несколько неочевидно. Глядя на первый поток, мы фиксируем, что мьютекс 2 мы захватываем после мьютекса 1. Глядя на второй поток, мы фиксируем, что мьютекс 3 мы захватываем после мьютекса 2. Объединение этих наблюдений означает, что мьютекс 3 мы захватываем после мьютекса 1, что не выполняется в потоке 3. Результатом этого невыполнения является deadlock, который и показан на рисунке.
Несмотря на всю простоту данных правил, смею утверждать, что если ваша программа в качестве средств синхронизации использует только мьютексы и вы соблюли эти правила, то взаимные блокировки вам не страшны! Мы, конечно, не берем в расчет ситуацию попытки двойного захвата нерекурсивного мьютекса одним потоком, но это скорее глупость, чем deadlock.
В заключение хотелось бы задать вопрос: интересна ли эта тема аудитории Хабра? Если да, то есть желание и возможность рассказать о чуть более интересных ситуациях, возникающих при использовании сигнальных переменных и, может быть, немного глубже окунуться в доказательную базу – это уже для искушенных программистов многопоточных приложений.
Надеюсь, этот пост был полезен.
Читайте продолжение — Рецепты против взаимных блокировок на сигнальных переменных.
Так сложилось, что это третий пост в блоге нашей компании, и, как и первые два, он посвящен вопросам многопоточного программирования и проблемам, которые при этом возникают. Получилось так неслучайно, ведь мы на собственной «шкуре» испытали, что ситуации, возникающие при написании многопоточных программ, невероятно сложны для отладки, так как во многом определяются динамикой работы программы на конкретной аппаратной платформе. Уверен, что большинство программистов сталкивались с ситуацией, когда программа, которая прекрасно работает на одном компьютере, на другом совершенно неожиданно начинает дедлочиться практически «на ровном месте».
При написании своих предыдущих постов мы совершили непростительную ошибку, начав рассматривать взаимные блокировки со сложных, но, как нам казалось, наиболее интересных случаев. Этого уважаемая аудитория Хабра, к сожалению, не оценила. Спешим исправиться, и, пусть не с первого раза, но все-таки подойти к рассмотрению проблемы блокировок с самого начала. Однако мы все же рассчитываем, что вы знаете, зачем нужны и какие бывают средства синхронизации при написании многопоточных программ.
Рецепты, описанные в этом посте весьма просты, но далеко не все даже профессиональные программисты используют осознанно, руководствуясь скорее ощущениями «почему-то кажется, что не стоит захватывать тот мьютекс из под захваченного этого». Так жили и мы долгие-долгие годы, когда в один ужасно ответственный момент не обнаружили, что на «железке», которую нужно срочно отправить заказчику, наш любимый софт не может и часа прожить без дедлока. Убив на решение этой задачи несколько дней работы своих ведущих программистов, мы приняли решение, которое изменило нашу жизнь – мы занялись суровой формализацией ситуаций взаимных блокировок, включающей строгие математические доказательства того, почему так можно делать, а так нельзя. Надо сказать, что исследование наше выродилось в кандидатскую диссертацию одного из сотрудников, но я не уверен, что использованный там формат изложения будет интересен здесь…
Итак, о блокировках с самого начала…
Природа взаимных блокировок
Не будем вдаваться в сложные математически выверенные определения ситуаций взаимных блокировок и скажем просто: взаимная блокировка – это такое состояние системы, в котором один поток ожидает наступления чего-то, а это что-то не может произойти потому, что другой поток ожидает наступления чего-то от первого потока.
Традиционно принято считать, что причиной блокировок всегда являются мьютексы (mutex), однако это не совсем точно. Причиной блокировок могут являться любые средства и механизмы синхронизации, которые предполагают ожидание чего-либо одного потока со стороны другого, например, ожидание сигнала на переменной кондиции (condition variable) или, что значительно менее очевидно, ожидание завершение другого потока (wait/join thread). В теории, на самом деле, второй случай является тем же самым «ожиданием сигнала», однако ввиду неявности этой операции синхронизации, при поиске дедлоков о ней просто забывают, как о потенциальном источнике угрозы и часто не замечают в коде.
Прежде, чем перейти к рассмотрению конкретных ситуаций простейших взаимных блокировок хочется сказать несколько слов о модели, которую мы используем для описания многопоточных программ и возникающих в них ситуаций.
Несколько слов о модели многопоточных программ
Мы назвали эту модель – «моделью переходов» и представляет она собой совокупность ориентированных графов, где каждый граф представляет собой поток (субъект). Каждый граф имеет одну начальную вершину, соответствующую состоянию, когда ни одно средство синхронизации еще не задействовано, и имеет одну конечную вершину, соответствующую состоянию, когда ни одно средство синхронизации уже не задействовано. Предполагается, что при достижении конечной вершины поток автоматически начинается сначала. Все другие вершины графов представляют собой операцию в отношении того или иного средства синхронизации, например, L (lock) – захват мьютекса, U (unlock) – отпускание мьютекса и т.д. Для доказательств утверждений важно, что модель игнорирует время между выполнениями отдельных операций в отношении средств синхронизации, расширяя тем самым возможный диапазон динамик до бесконечности. Если аудитории Хабра интересна математическая и физическая суть модели, то я готов написать отдельный пост на эту тему, а здесь… всего лишь начало долгой, но интересной истории о многопоточном программировании.
Пример модели, состоящей из одного потока (субъекта):
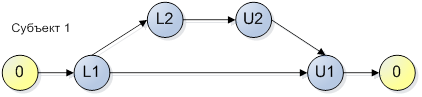
Рисунок 1.
В соответствии с данным рисунком, субъект может пройти по двум веткам: 0, L1, U1, 0 или 0, L1, L2, U2, U1, 0. Эта схема может рассматриваться, как конечный автомат, грамматика которого включает две фразы {0, L1, U1, 0} и {0, L1, L2, U2, U1, 0}. Будем считать, что время перехода между действиями в отношении средств синхронизации конечно, т.е. алгоритмически корректно. Не будем считать ошибкой синхронизации захват и удержание мьютекса в течение ожидания какого-либо действия пользователя, которое потенциально может никогда не наступить.
Для исследования программы на потенциальную возможность возникновения ситуации взаимной блокировки необходимо составить цепочки выполнения всех возможных субъектов в программе.
Простейшая взаимная блокировка с участием мьютексов
Пусть в нашей программе помимо потока (субъекта), приведенного на рисунке 1, есть еще один:
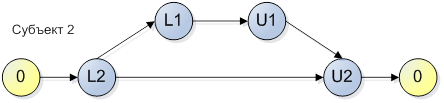
Рисунок 2.
Смею утверждать, что наша программа имеет потенциальный deadlock и даже, если ваши тестировщики утверждают, что все прекрасно работает, то вы не застрахованы от ситуации, что на другом «железе» ваша программа поведет себя вот так:
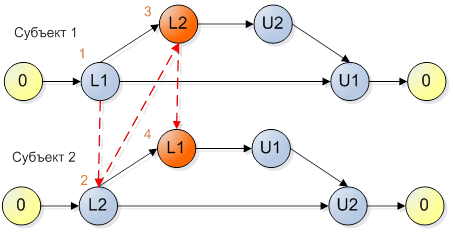
Рисунок 3.
Ничего не мешает нашим двух независимым потокам выполниться так: поток 1 успел захватить мьютекс 1, затем планировщик переключил выполнение на поток 2, который захватил мьютекс 2, и после этого оба наших потока пытаются захватить мьютексы, которые уже захвачены – deadlock!
Назовем систему потоков (субъектов) несовместимой, если существуют хотя бы один вариант наложения цепочек их выполнения, при котором наступает ситуация взаимной блокировки. Соответственно, совместимой является такая система субъектов, для которой не существует динамики, при которой возможно возникновение ситуации взаимной блокировки.
Рассмотренные два субъекта являются несовместимыми, т.к. существует вариант наложения, приведенный на рисунке 3, при котором возникает ситуация взаимной блокировки. Отметим, что такие субъекты не обязательно будут приводить к блокировке (зависанию) программы. Динамика конкретной работы (время переходов между обращениями к средствам синхронизации) может быть такова, что найденный вариант наложения никогда не проявится в реальности. В любом случае, программный код, описываемый такой моделью, является потенциально опасным и блокировки могут проявиться при портировании на другую программную или аппаратную платформу, а также просто при изменении условий функционирования.

Рисунок 4
Важно помнить, что потоки могут быть попарно совместимы между собой, но не совместимы в большей комбинации. На рисунке 5 показана модель программы, где все субъекты попарно совместимы между собой, но все вместе приводят к ситуации взаимной блокировки.
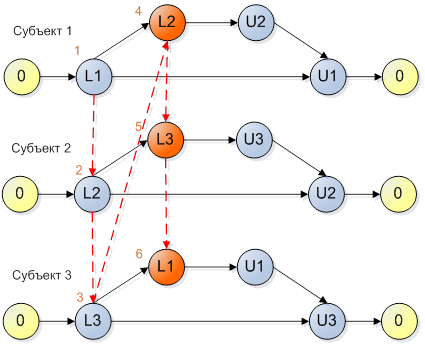
Рисунок 5
На рисунке 6 показан другой вариант совмещения цепочек выполнения для модели, представленной на рисунке 5, при котором возникает взаимная блокировка.

Рисунок 6
Прямо так и хочется сказать: Как страшно жить!
И это было бы действительно так, если бы не было двух очень простых правил, которым интуитивно следуют профессиональные программисты, зачастую даже не задумываясь, почему они так делают.
Первое правило
Всегда отпускайте захваченные мьютексы в обратном захвату порядке, т.е. руководствуйтесь логикой «первый захвачен – последний отпущен».
Второе правило
Всегда соблюдайте один и тот же порядок захвата мьютексов.
Если вы в одном потоке захватываете мьютекс 1, а затем мьютекс 2, то недопустимо захватывать их в ином порядке в другом потоке.
На самом деле, правило не так просто, как кажется на первый взгляд. Еще раз посмотрим внимательно на Рисунок 6. Там это правило нарушено, но это несколько неочевидно. Глядя на первый поток, мы фиксируем, что мьютекс 2 мы захватываем после мьютекса 1. Глядя на второй поток, мы фиксируем, что мьютекс 3 мы захватываем после мьютекса 2. Объединение этих наблюдений означает, что мьютекс 3 мы захватываем после мьютекса 1, что не выполняется в потоке 3. Результатом этого невыполнения является deadlock, который и показан на рисунке.
Несмотря на всю простоту данных правил, смею утверждать, что если ваша программа в качестве средств синхронизации использует только мьютексы и вы соблюли эти правила, то взаимные блокировки вам не страшны! Мы, конечно, не берем в расчет ситуацию попытки двойного захвата нерекурсивного мьютекса одним потоком, но это скорее глупость, чем deadlock.
В заключение хотелось бы задать вопрос: интересна ли эта тема аудитории Хабра? Если да, то есть желание и возможность рассказать о чуть более интересных ситуациях, возникающих при использовании сигнальных переменных и, может быть, немного глубже окунуться в доказательную базу – это уже для искушенных программистов многопоточных приложений.
Надеюсь, этот пост был полезен.
Читайте продолжение — Рецепты против взаимных блокировок на сигнальных переменных.
