Уважаемые Хабрапользователи!
 Продолжая начатую недавно традицию публикации проектов стандартов, разрабатываемых нашей компанией в рамках деятельности технического комитета по стандартизации ТК-234 «Системы тревожной сигнализации и противокриминальной защиты», представляем вашему вниманию стандарт «Системы охранные телевизионные. Компрессия оцифрованных аудиоданных. Общие технические требования и методы оценки алгоритмов».
Продолжая начатую недавно традицию публикации проектов стандартов, разрабатываемых нашей компанией в рамках деятельности технического комитета по стандартизации ТК-234 «Системы тревожной сигнализации и противокриминальной защиты», представляем вашему вниманию стандарт «Системы охранные телевизионные. Компрессия оцифрованных аудиоданных. Общие технические требования и методы оценки алгоритмов».
Будем крайне признательны за конструктивную критику проекта, а все ценные замечания и пожелания будут внесены в очередную редакцию стандарта. Текст стандарта под катом.
Для лучшего понимания структуры данного стандарта и общего подхода рекомендуем предварительно ознакомиться с уже принятым стандартом по компрессии оцифрованных видеоданных, разработанным нами еще 2011 году.
НАЦИОНАЛЬНЫЙ СТАНДАРТ РОССИЙСКОЙ ФЕДЕРАЦИИ
Введение
Активное применение в системах охранных телевизионных (СОТ) методов компрессии оцифрованных аудиоданных, заимствованных из мультимедийных применений телевидения, привело к невозможности осуществления следственных мероприятий, а также оперативных функций, с использованием большинства существующих СОТ.
Важной отличительной особенностью методов компрессии оцифрованных аудиоданных для СОТ является необходимость обеспечения высокого качества звука в восстановленных аудиоданных. Данный стандарт позволяет упорядочить существующие и разрабатываемые методы компрессии оцифрованных аудиоданных, предназначенные для применения в составе систем противокриминальной защиты.
В качестве критерия для классификации алгоритмов компрессии оцифрованных аудиоданных настоящий стандарт устанавливает значения метрик качества, характеризующих степень отклонения исходных и соответствующих им восстановленных оцифрованных аудиоданных.
Настоящий стандарт следует применять совместно с ГОСТ Р 51558-2008 «Средства и системы охранные телевизионные. Классификация. Общие технические требования. Методы испытаний».
1 Область применения
Настоящий стандарт распространяется на цифровые системы охранные телевизионные (далее ЦСОТ) и устанавливает общие технические требования и методы оценки алгоритмов компрессии оцифрованных аудиоданных в ЦСОТ.
Настоящий стандарт применяют к алгоритмам компрессии (декомпрессии), независимо от их реализации на аппаратном уровне.
Настоящий стандарт устанавливает классификацию алгоритмов компрессии (декомпрессии) оцифрованных аудиоданных.
Настоящий стандарт устанавливает методику сравнения различных алгоритмов компрессии и декомпрессии оцифрованных аудиоданных.
Настоящий стандарт применяют совместно со стандартами ГОСТ Р МЭК 60065, ГОСТ Р 51558, ГОСТ 13699, ГОСТ 15971, ГОСТ Р 52633.5-2011
2 Нормативные ссылки
В настоящем стандарте использованы нормативные ссылки на следующие стандарты:
ГОСТ Р 51558-2008 Средства и системы охранные телевизионные. Общие технические требования и методы испытаний
ГОСТ Р МЭК 60065-2009 Аудио-, видео- и аналогичная электронная аппаратура. Требования безопасности
ГОСТ 13699-91 Запись и воспроизведение информации. Термины и определения
ГОСТ 15971-90 Системы обработки информации. Термины и определения
ГОСТ Р 52633.5-2011 Защита информации. Техника защиты информации. Автоматическое обучение нейросетевых преобразователей биометрия-код доступа
3 Термины и определения
В настоящем стандарте применены термины по ГОСТ 15971-90, ГОСТ 13699, ГОСТ Р 51558, ГОСТ Р 52633.5-2011, ГОСТ Р МЭК 60065-2009, а также следующие термины с соответствующими определениями:
1. аудиоданные (audio data), аудиосигнал (audio signal), моноканальный аудиосигнал (monophonic audio): аналоговый сигнал, несущий информацию об изменении во времени амплитуды звука.
2. многоканальный аудиосигнал (multi-channel audio): аудиосигнал, состоящий из объединения определенного количества аудиосигналов (каналов), которые несут информацию об одном и том же звуке; предназначен для более качественной передачи звука с учетом пространственной ориентации.
3. стереофонический двухканальный аудиосигнал (stereophonic audio signal), стерео аудиосигнал (stereo audio signal), двухканальный аудиосигнал (stereo audio signal): многоканальный аудиосигнал, состоящий из двух моноканальных аудиосигналов.
4. оцифрованные аудиоданные (digitized audio data): данные, полученные путем аналого-цифрового преобразования аудиоданных, представляющие собой последовательность байтов в некотором формате (WAV или др.).
5. аналого-цифровой преобразователь, АЦП (Analog-to-digital converter, ADC): устройство, преобразующее входной аналоговый аудиосигнал в оцифрованные аудиоданные.
6. частота дискретизации (Sample rate): частота взятия отсчетов непрерывного во времени сигнала при его аналого-цифровом преобразовании в оцифрованные аудиоданные.
7. разрядность АЦП (resolution of ADC): количество бит, которым кодируется каждый отсчет сигнала в процессе АЦП.
8. фрейм (frame): фрагмент звукового сигнала с заданным количеством значений (длиной фрейма).
9. формат оцифрованных аудиоданных (digitized audio data format): представление оцифрованных аудиоданных, обеспечивающее их обработку цифровыми вычислительными средствами.
10. компрессия (сжатие) оцифрованных аудиоданных (audio compression): обработка оцифрованных аудиоданных, предназначенная для уменьшения их объема.
11. сжатые аудиоданные (compressed audio data): данные, полученные путем компрессии оцифрованных аудиоданных.
12. компрессия оцифрованных аудиоданных с потерями (lossy audio compression): компрессия оцифрованных аудиоданных, при которой происходит потеря информации, и вследствие этого восстановленные (в результате выполнения декомпрессии) оцифрованные аудиоданные отличаются от исходных оцифрованных аудиоданных.
13. компрессия оцифрованных аудиоданных без потерь (lossless audio compression): компрессия оцифрованных аудиоданных, при которой не происходит потери информации, и вследствие этого восстановленные (в результате выполнения декомпрессии) оцифрованные аудиоданные не отличаются от исходных оцифрованных аудиоданных.
14. декомпрессия сжатых аудиоданных (audio decompression): восстановление оцифрованных данных из сжатых аудиоданных.
15. восстановленные аудиоданные (decoded audio data): данные, полученные из сжатых аудиоданных после их декомпрессии.
16. аудиокодер (audio encoder): программные, аппаратные или аппаратно-программные средства, с помощью которых осуществляется компрессия оцифрованных аудиоданных.
17. аудиодекодер (audio decoder): программные, аппаратные или аппаратно-программные средства, с помощью которых осуществляется декомпрессия сжатых аудиоданных.
18. кодек аудиоданных (audio codec): программный, аппаратный или аппаратно-программный модуль, способный выполнять как компрессию, так и декомпрессию аудиоданных.
19. степень сжатия (compression ratio): коэффициент сокращения объема оцифрованных аудиоданных в результате компрессии.
20. битрейт (bit rate): выраженная в битах оценка количества сжатых аудиоданных, определенная для некоторого временного интервала и отнесенная к длительности выбранного временного интервала в секундах.
21. качество восстановленных аудиоданных (decoded audio data quality): объективная оценка соответствия восстановленных аудиоданных исходным оцифрованным аудиоданным на основе рассчитанных метрик качества.
22. метрика качества (quality metric): аналитически определяемые параметры, характеризующие степень отклонения восстановленных аудиоданных от исходных оцифрованных аудиоданных.
23. метод оценки алгоритма компрессии(method of evaluating compression algorithm): метод аналитического определения значений метрик качества на соответствие требованиям, предъявляемым к алгоритмам компрессии аудиоданных.
24. алгоритм компрессии (compression algorithm): точный набор инструкций и пра-вил, описывающий последовательность действий, согласно которым исходные аудиоданные преобразуются в сжатые, реализуемый при помощи аудиокодера.
25. алгоритм декомпрессии (decompression algorithm): точный набор инструкций и пра-вил, описывающий последовательность действий, согласно которым сжатые аудиоданные преобразуются в восстановленные, реализуемый при помощи аудиодекодера.
26. частотно-временная метрика (time-frequency metric): метрика качества, основанная на сравнении спектрограмм оцифрованных и восстановленных аудиоданных.
27. амплитудно-временная метрика (time-amplitude metric): метрика качества, основанная на сравнении оцифрованных и восстановленных аудиоданных по форме волны.
28. передискретизация (resampling) аудиосигнала: изменение частоты дискретизации аудиосигнала.
29. психоакустическая модель (psychoacoustics model): модель для сжатия аудиоданных с потерями, использующая особенности восприятия звука человеческим ухом.
30. психоакустическое маскирование (psychoacoustics masking): скрытие при определенных условиях одного звука другим звуком из-за особенностей восприятия звука человеческим ухом.
31. порог маскирования (masking threshold): пороговый уровень сигнала, не различаемого человеком из-за эффекта психоакустического маскирования.
32. шум (noise): совокупность апериодических звуков различной интенсивности и частоты, не несущая полезной информации.
33. спектр сигнала (frequency spectrum): результат разложения сигнала на простые синусоидальные функции (гармоники).
34. дискретное преобразование Фурье, ДПФ (discrete Fourier transform, DFT): преобразование, ставящее в соответствие N отсчетам дискретного сигнала N отсчетов дискретного спектра сигнала
35. алгоритм быстрого преобразования Фурье (fast Fourier transform, FFT): алгоритм быстрого вычисления дискретного преобразования Фурье.
36. спектрограмма (spectrogram): характеристика плотности мощности сигнала в частотно-временном пространстве.
37. окно (window function): весовая функция, которая используется для управления эффектами, обусловленными наличием боковых лепестков в спектральных оценках (растеканием спектра). Имеющуюся конечную запись данных или имеющуюся конечную корреляционную последовательность удобно рассматривать как некоторую часть соответствующей бесконечной последовательности, видимую через применяемое окно.
38. оконное преобразование Ханна (short-time Fourier transform with Hann window): ДПФ с весовой функцией – окном Ханна.
39. искусственная нейронная сеть (artificial neural network, ANN): математическая модель, а также ее программные или аппаратные реализации, построенная в некотором смысле по образу и подобию сетей нервных клеток живого организма и используемая для аппроксимации непрерывных функций. Искусственная нейронная сеть состоит из входного слоя с нейронами и выходного слоя с нейронами. Между этим слоями находится один или более промежуточных, скрытых, слоев с нейронами.
40. искаженный фрейм (distorted frame): фрейм, для которого максимальное отношение шума к порогу маскирования превышает 1,5 дБ.
41. пиковое отношение сигнал/шум (peak-to-peak signal-to-noise ratio): соотношение между максимумом возможного значения сигнала и мощностью шума.
42. дифференциация (от латинского differentia — различие) — выделение частного из общей совокупности по некоторым признакам.
4 Общие технические требования
Требования, предъявляемые к компрессии оцифрованных аудиоданных, направлены на оценку качества восстановленных аудиоданных, которая определяется качеством каждого отдельного звукового фрагмента восстановленных аудиоданных. Размер звукового фрагмента определяется в секундах, либо количеством оцифрованных значений внутри фрагмента.
Качество звукового фрагмента восстановленных аудиоданных определяется значениями метрик качества, характеризующих степень искажения восстановленных после сжатия аудиоданных по сравнению с исходными оцифрованными аудиоданными. Порядок расчета метрик приведен в главе 6 настоящего документа.
По значениям метрик качества восстановленных аудиоданных алгоритмы компрессии оцифрованных аудиоданных принадлежат к одному из трех классов (см. главу 5 настоящего доку-мента).
Принадлежность алгоритма компрессии оцифрованных данных к определенному классу определяется по рассчитанным для него значениям метрик качества и таблице 1, приведенной в главе 5.
5 Классификация алгоритмов компрессии
5.1 Для оценки качества восстановленных аудиоданных и классификации алгоритмов компрессии используются следующие метрики качества: пиковое отношение сигнал/шум (peak signal-to-noise ratio, PSNR); коэффициент различия форм сигналов; метрика на основе объективной оценки аудиоданных с точки зрения восприятия их человеком (perceptual evaluation of audio quality, PEAQ).
5.2 Классификация алгоритмов компрессии оцифрованных аудиоданных осуществляется на основе значений метрик качества, которые отражают те аспекты изменения оцифрованных аудиоданных после их обработки алгоритмами компрессии и декомпрессии, которые могут оказать критическое влияние на возможность использования восстановленных аудиоданных для установления наличия звуковых сигналов, дифференциации звуков и речи.
5.3 В зависимости от значений метрик качества, вычисленных в ходе проведения оценки, алгоритмы компрессии оцифрованных аудиоданных могут быть отнесены к одному из следующих классов (см. Табл. 1):

Таблица 1 — Классификация алгоритмов компрессии
5.4 Значения метрик качества определяются для каждого звукового фрагмента (длиной в пять секунд) оцифрованных аудиоданных, а в качестве результирующей оценки выбирается: наименьшее значение для метрик PSNR и PEAQ; наибольшее значение для коэффициента различия форм сигналов.
Для расчета метрик PSNR и коэффициента различия форм сигналов исходные и восстановленные цифровые аудиоданные должны быть представлены с частотой дискретизации 44100 Гц, 16 битами памяти на одно дискретное значение выборки и с одним звуковым каналом. Длина звукового фрагмента в пять секунд в этом случае составляет 220500 оцифрованных значений.
Для расчета метрики PEAQ исходные и восстановленные цифровые аудиоданные должны быть представлены с частотой дискретизации 48000 Гц, 16 битами памяти на одно дискретное значение выборки и с одним или с двумя звуковыми каналами. Длина звукового фрагмента в пять секунд в этом случае составляет 240000 оцифрованных значений для каждого канала.
Для сигналов с частотой, отличной от требуемой, необходимо предварительно выполнить передискретизацию аудиосигнала.
6.1 Общее описание методов оценки
Общая схема работы ЦСОТ с точки зрения использования алгоритмов компрессии и декомпрессии представлена на рисунке 1.
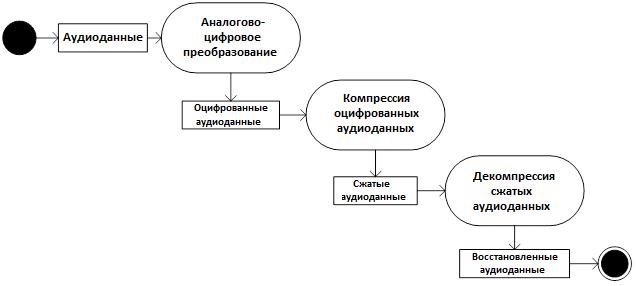
Рисунок 1 — Общая схема работы ЦСОТ
Аналоговые аудиоданные подвергаются аналогово-цифровому преобразованию, в результате которого получаются оцифрованные аудиоданные с определенной частотой дискретизации и количеством битов на одно дискретное оцифрованное значение. На компьютере оцифрованные аудиоданные должны храниться в одном из форматов хранения оцифрованных аудиоданных.
Оцифрованные аудиоданные подвергаются компрессии, в результате которой формируются сжатые аудиоданные.
Сжатые аудиоданные используются для хранения архива или для передачи по сети, после чего они подвергаются декомпрессии. В результате декомпрессии сжатых аудиоданных образуются восстановленные аудиоданные, которые используются для воспроизведения оператору и подаются на вход программным модулям анализа аудиоданных.
В соответствии с представленной общей схемой работы ЦСОТ, классификация алгоритмов компрессии оцифрованных аудиоданных выполняется путем оценки метрик качества восстановленных аудиоданных от исходных оцифрованных аудиоданных. В зависимости от особенностей технической реализации конкретной ЦСОТ существует два метода оценки:
— на основе разделения оцифрованных аудиоданных;
— на основе разделения аудиоданных.
Перед оценкой значений метрик качества оба аудиосигнала (исходные и восстановленный) должны быть преобразованы в сигналы с частотой дискретизации 44100 Гц и 48000 Гц. Для обеих частот (44100 Гц и 48000 Гц) количество бит, приходящееся на одно дискретное оцифрованное значение, должно быть равным 16.
6.1.1 Метод оценки алгоритма на основе разделения оцифрованных аудиоданных
Для применения данного метода техническая реализация ЦСОТ должна позволять получить оцифрованные аудиоданные до их обработки алгоритмами компрессии и декомпрессии.
Общая схема реализации метода оценки на основе разделения оцифрованных аудиоданных представлена на рисунке 2.
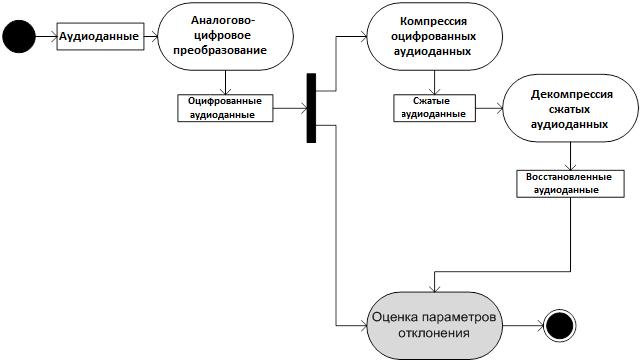
Рисунок 2 — Общая схема реализации метода оценки на основе разделения оцифрованных аудиоданных
Алгоритм осуществления оценки выполняется следующей последовательностью действий:
— на вход испытываемой ЦСОТ подают последовательность аудиоданных;
— с использованием возможностей ЦСОТ оцифрованные и восстановленные аудиоданные сохраняют на устройствах хранения;
— выполняют расчет значений метрик качества и осуществляют классификацию алгоритма компрессии по Таблице 1.
— выполняется расчет значений метрик качества и осуществляется классификацию алгоритма компрессии по Таблице 1.
6.1.2 Метод оценки алгоритма на основе разделения аудиоданных
Метод оценки на основе разделения аудиоданных следует применять только в случае, если техническая реализация ЦСОТ не позволяет применять метод оценки на основе разделения оцифрованных аудиоданных. Применение данного метода требует наличия дополнительной ЦСОТ в составе испытательного стенда, которая предназначена для сохранения оцифрованных аудиоданных.
Общая схема реализации метода оценки на основе разделения аудиоданных представлена на рисунке 3.
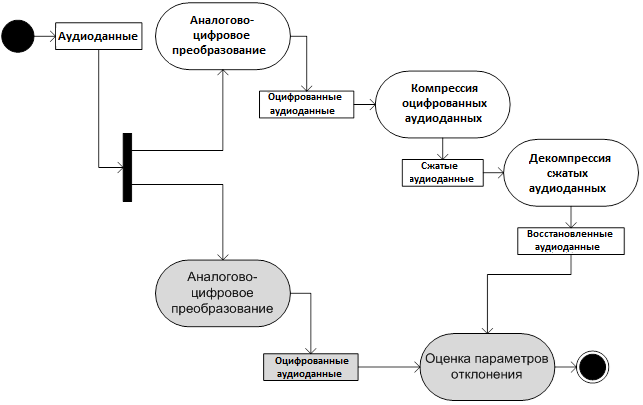
Рисунок 3 — Общая схема реализации метода оценки на основе
Алгоритм осуществления оценки по данному методу предполагает выполнение следующих действий:
— на вход испытываемой ЦСОТ подают последовательные аудиоданные, которые дублируются на другую ЦСОТ посредством делителя аудиосигнала (из состава испытательного стенда);
— с использованием возможностей ЦСОТ восстановленные аудиоданные сохраняют на устройствах хранения;
— с использованием возможностей ЦСОТ из состава испытательного стенда оцифрованные аудиоданные сохраняют на устройствах хранения;
— выполняют расчет значений метрик качества и осуществляют классификацию алгоритма компрессии по Таблице 1.
7 Методы сравнения алгоритмов компрессии оцифрованных аудиоданных
7.1 Два и более алгоритмов компрессии сравнимы друг с другом, если они принадлежат од-ному и тому же классу в соответствии с Таблицей 1
7.2 Из двух и более сравнимых алгоритмов компрессии лучшим признается алгоритм, обеспечивающий лучшие значения хотя бы двух из трех метрик, приведенных в Таблице 1. Лучшим значением метрики признается большее значение — для метрик PSNR и PEAQ, и меньшее значение — для метрики «коэффициент различия форм сигналов».
Ссылки:
1. P.Kabal, An Examinationa and Intrpretation of ITU-R BS.1387 Perceptual Evaluation of Audio Quality
2. PQevalAudio
 Продолжая начатую недавно традицию публикации проектов стандартов, разрабатываемых нашей компанией в рамках деятельности технического комитета по стандартизации ТК-234 «Системы тревожной сигнализации и противокриминальной защиты», представляем вашему вниманию стандарт «Системы охранные телевизионные. Компрессия оцифрованных аудиоданных. Общие технические требования и методы оценки алгоритмов».
Продолжая начатую недавно традицию публикации проектов стандартов, разрабатываемых нашей компанией в рамках деятельности технического комитета по стандартизации ТК-234 «Системы тревожной сигнализации и противокриминальной защиты», представляем вашему вниманию стандарт «Системы охранные телевизионные. Компрессия оцифрованных аудиоданных. Общие технические требования и методы оценки алгоритмов».Будем крайне признательны за конструктивную критику проекта, а все ценные замечания и пожелания будут внесены в очередную редакцию стандарта. Текст стандарта под катом.
Для лучшего понимания структуры данного стандарта и общего подхода рекомендуем предварительно ознакомиться с уже принятым стандартом по компрессии оцифрованных видеоданных, разработанным нами еще 2011 году.
НАЦИОНАЛЬНЫЙ СТАНДАРТ РОССИЙСКОЙ ФЕДЕРАЦИИ
Системы охранные телевизионные. Компрессия оцифрованных аудиоданных.
Классификация. Общие технические требования и методы оценки алгоритмов
Введение
Активное применение в системах охранных телевизионных (СОТ) методов компрессии оцифрованных аудиоданных, заимствованных из мультимедийных применений телевидения, привело к невозможности осуществления следственных мероприятий, а также оперативных функций, с использованием большинства существующих СОТ.
Важной отличительной особенностью методов компрессии оцифрованных аудиоданных для СОТ является необходимость обеспечения высокого качества звука в восстановленных аудиоданных. Данный стандарт позволяет упорядочить существующие и разрабатываемые методы компрессии оцифрованных аудиоданных, предназначенные для применения в составе систем противокриминальной защиты.
В качестве критерия для классификации алгоритмов компрессии оцифрованных аудиоданных настоящий стандарт устанавливает значения метрик качества, характеризующих степень отклонения исходных и соответствующих им восстановленных оцифрованных аудиоданных.
Настоящий стандарт следует применять совместно с ГОСТ Р 51558-2008 «Средства и системы охранные телевизионные. Классификация. Общие технические требования. Методы испытаний».
1 Область применения
Настоящий стандарт распространяется на цифровые системы охранные телевизионные (далее ЦСОТ) и устанавливает общие технические требования и методы оценки алгоритмов компрессии оцифрованных аудиоданных в ЦСОТ.
Настоящий стандарт применяют к алгоритмам компрессии (декомпрессии), независимо от их реализации на аппаратном уровне.
Настоящий стандарт устанавливает классификацию алгоритмов компрессии (декомпрессии) оцифрованных аудиоданных.
Настоящий стандарт устанавливает методику сравнения различных алгоритмов компрессии и декомпрессии оцифрованных аудиоданных.
Настоящий стандарт применяют совместно со стандартами ГОСТ Р МЭК 60065, ГОСТ Р 51558, ГОСТ 13699, ГОСТ 15971, ГОСТ Р 52633.5-2011
2 Нормативные ссылки
В настоящем стандарте использованы нормативные ссылки на следующие стандарты:
ГОСТ Р 51558-2008 Средства и системы охранные телевизионные. Общие технические требования и методы испытаний
ГОСТ Р МЭК 60065-2009 Аудио-, видео- и аналогичная электронная аппаратура. Требования безопасности
ГОСТ 13699-91 Запись и воспроизведение информации. Термины и определения
ГОСТ 15971-90 Системы обработки информации. Термины и определения
ГОСТ Р 52633.5-2011 Защита информации. Техника защиты информации. Автоматическое обучение нейросетевых преобразователей биометрия-код доступа
3 Термины и определения
В настоящем стандарте применены термины по ГОСТ 15971-90, ГОСТ 13699, ГОСТ Р 51558, ГОСТ Р 52633.5-2011, ГОСТ Р МЭК 60065-2009, а также следующие термины с соответствующими определениями:
1. аудиоданные (audio data), аудиосигнал (audio signal), моноканальный аудиосигнал (monophonic audio): аналоговый сигнал, несущий информацию об изменении во времени амплитуды звука.
2. многоканальный аудиосигнал (multi-channel audio): аудиосигнал, состоящий из объединения определенного количества аудиосигналов (каналов), которые несут информацию об одном и том же звуке; предназначен для более качественной передачи звука с учетом пространственной ориентации.
3. стереофонический двухканальный аудиосигнал (stereophonic audio signal), стерео аудиосигнал (stereo audio signal), двухканальный аудиосигнал (stereo audio signal): многоканальный аудиосигнал, состоящий из двух моноканальных аудиосигналов.
4. оцифрованные аудиоданные (digitized audio data): данные, полученные путем аналого-цифрового преобразования аудиоданных, представляющие собой последовательность байтов в некотором формате (WAV или др.).
5. аналого-цифровой преобразователь, АЦП (Analog-to-digital converter, ADC): устройство, преобразующее входной аналоговый аудиосигнал в оцифрованные аудиоданные.
6. частота дискретизации (Sample rate): частота взятия отсчетов непрерывного во времени сигнала при его аналого-цифровом преобразовании в оцифрованные аудиоданные.
7. разрядность АЦП (resolution of ADC): количество бит, которым кодируется каждый отсчет сигнала в процессе АЦП.
8. фрейм (frame): фрагмент звукового сигнала с заданным количеством значений (длиной фрейма).
9. формат оцифрованных аудиоданных (digitized audio data format): представление оцифрованных аудиоданных, обеспечивающее их обработку цифровыми вычислительными средствами.
10. компрессия (сжатие) оцифрованных аудиоданных (audio compression): обработка оцифрованных аудиоданных, предназначенная для уменьшения их объема.
11. сжатые аудиоданные (compressed audio data): данные, полученные путем компрессии оцифрованных аудиоданных.
12. компрессия оцифрованных аудиоданных с потерями (lossy audio compression): компрессия оцифрованных аудиоданных, при которой происходит потеря информации, и вследствие этого восстановленные (в результате выполнения декомпрессии) оцифрованные аудиоданные отличаются от исходных оцифрованных аудиоданных.
13. компрессия оцифрованных аудиоданных без потерь (lossless audio compression): компрессия оцифрованных аудиоданных, при которой не происходит потери информации, и вследствие этого восстановленные (в результате выполнения декомпрессии) оцифрованные аудиоданные не отличаются от исходных оцифрованных аудиоданных.
14. декомпрессия сжатых аудиоданных (audio decompression): восстановление оцифрованных данных из сжатых аудиоданных.
15. восстановленные аудиоданные (decoded audio data): данные, полученные из сжатых аудиоданных после их декомпрессии.
16. аудиокодер (audio encoder): программные, аппаратные или аппаратно-программные средства, с помощью которых осуществляется компрессия оцифрованных аудиоданных.
17. аудиодекодер (audio decoder): программные, аппаратные или аппаратно-программные средства, с помощью которых осуществляется декомпрессия сжатых аудиоданных.
18. кодек аудиоданных (audio codec): программный, аппаратный или аппаратно-программный модуль, способный выполнять как компрессию, так и декомпрессию аудиоданных.
19. степень сжатия (compression ratio): коэффициент сокращения объема оцифрованных аудиоданных в результате компрессии.
20. битрейт (bit rate): выраженная в битах оценка количества сжатых аудиоданных, определенная для некоторого временного интервала и отнесенная к длительности выбранного временного интервала в секундах.
21. качество восстановленных аудиоданных (decoded audio data quality): объективная оценка соответствия восстановленных аудиоданных исходным оцифрованным аудиоданным на основе рассчитанных метрик качества.
22. метрика качества (quality metric): аналитически определяемые параметры, характеризующие степень отклонения восстановленных аудиоданных от исходных оцифрованных аудиоданных.
23. метод оценки алгоритма компрессии(method of evaluating compression algorithm): метод аналитического определения значений метрик качества на соответствие требованиям, предъявляемым к алгоритмам компрессии аудиоданных.
24. алгоритм компрессии (compression algorithm): точный набор инструкций и пра-вил, описывающий последовательность действий, согласно которым исходные аудиоданные преобразуются в сжатые, реализуемый при помощи аудиокодера.
25. алгоритм декомпрессии (decompression algorithm): точный набор инструкций и пра-вил, описывающий последовательность действий, согласно которым сжатые аудиоданные преобразуются в восстановленные, реализуемый при помощи аудиодекодера.
26. частотно-временная метрика (time-frequency metric): метрика качества, основанная на сравнении спектрограмм оцифрованных и восстановленных аудиоданных.
27. амплитудно-временная метрика (time-amplitude metric): метрика качества, основанная на сравнении оцифрованных и восстановленных аудиоданных по форме волны.
28. передискретизация (resampling) аудиосигнала: изменение частоты дискретизации аудиосигнала.
29. психоакустическая модель (psychoacoustics model): модель для сжатия аудиоданных с потерями, использующая особенности восприятия звука человеческим ухом.
30. психоакустическое маскирование (psychoacoustics masking): скрытие при определенных условиях одного звука другим звуком из-за особенностей восприятия звука человеческим ухом.
31. порог маскирования (masking threshold): пороговый уровень сигнала, не различаемого человеком из-за эффекта психоакустического маскирования.
32. шум (noise): совокупность апериодических звуков различной интенсивности и частоты, не несущая полезной информации.
33. спектр сигнала (frequency spectrum): результат разложения сигнала на простые синусоидальные функции (гармоники).
34. дискретное преобразование Фурье, ДПФ (discrete Fourier transform, DFT): преобразование, ставящее в соответствие N отсчетам дискретного сигнала N отсчетов дискретного спектра сигнала
35. алгоритм быстрого преобразования Фурье (fast Fourier transform, FFT): алгоритм быстрого вычисления дискретного преобразования Фурье.
36. спектрограмма (spectrogram): характеристика плотности мощности сигнала в частотно-временном пространстве.
37. окно (window function): весовая функция, которая используется для управления эффектами, обусловленными наличием боковых лепестков в спектральных оценках (растеканием спектра). Имеющуюся конечную запись данных или имеющуюся конечную корреляционную последовательность удобно рассматривать как некоторую часть соответствующей бесконечной последовательности, видимую через применяемое окно.
38. оконное преобразование Ханна (short-time Fourier transform with Hann window): ДПФ с весовой функцией – окном Ханна.
39. искусственная нейронная сеть (artificial neural network, ANN): математическая модель, а также ее программные или аппаратные реализации, построенная в некотором смысле по образу и подобию сетей нервных клеток живого организма и используемая для аппроксимации непрерывных функций. Искусственная нейронная сеть состоит из входного слоя с нейронами и выходного слоя с нейронами. Между этим слоями находится один или более промежуточных, скрытых, слоев с нейронами.
40. искаженный фрейм (distorted frame): фрейм, для которого максимальное отношение шума к порогу маскирования превышает 1,5 дБ.
41. пиковое отношение сигнал/шум (peak-to-peak signal-to-noise ratio): соотношение между максимумом возможного значения сигнала и мощностью шума.
42. дифференциация (от латинского differentia — различие) — выделение частного из общей совокупности по некоторым признакам.
4 Общие технические требования
Требования, предъявляемые к компрессии оцифрованных аудиоданных, направлены на оценку качества восстановленных аудиоданных, которая определяется качеством каждого отдельного звукового фрагмента восстановленных аудиоданных. Размер звукового фрагмента определяется в секундах, либо количеством оцифрованных значений внутри фрагмента.
Качество звукового фрагмента восстановленных аудиоданных определяется значениями метрик качества, характеризующих степень искажения восстановленных после сжатия аудиоданных по сравнению с исходными оцифрованными аудиоданными. Порядок расчета метрик приведен в главе 6 настоящего документа.
По значениям метрик качества восстановленных аудиоданных алгоритмы компрессии оцифрованных аудиоданных принадлежат к одному из трех классов (см. главу 5 настоящего доку-мента).
Принадлежность алгоритма компрессии оцифрованных данных к определенному классу определяется по рассчитанным для него значениям метрик качества и таблице 1, приведенной в главе 5.
5 Классификация алгоритмов компрессии
5.1 Для оценки качества восстановленных аудиоданных и классификации алгоритмов компрессии используются следующие метрики качества: пиковое отношение сигнал/шум (peak signal-to-noise ratio, PSNR); коэффициент различия форм сигналов; метрика на основе объективной оценки аудиоданных с точки зрения восприятия их человеком (perceptual evaluation of audio quality, PEAQ).
5.2 Классификация алгоритмов компрессии оцифрованных аудиоданных осуществляется на основе значений метрик качества, которые отражают те аспекты изменения оцифрованных аудиоданных после их обработки алгоритмами компрессии и декомпрессии, которые могут оказать критическое влияние на возможность использования восстановленных аудиоданных для установления наличия звуковых сигналов, дифференциации звуков и речи.
5.3 В зависимости от значений метрик качества, вычисленных в ходе проведения оценки, алгоритмы компрессии оцифрованных аудиоданных могут быть отнесены к одному из следующих классов (см. Табл. 1):
- класс I — полнофункциональные алгоритмы компрессии, обеспечивающие качество восстановленных аудиоданных неотличимое от качества исходных аудиоданных;
- класс II — алгоритмы компрессии, обеспечивающие качество восстановленных аудиоданных, достаточное для установления наличия звуковых сигналов, дифференциации звуков, речи и не уступающее в этом качеству исходных аудиоданных, но отличимое от качества исходных аудиоданных;
- класс III — алгоритмы компрессии, обеспечивающие качество восстановленных аудиоданных, достаточное для установления наличия звуковых сигналов и не уступающее в этом качеству исходных аудиоданных, но создающее помехи при дифференциации звуков, понимании речи.

Таблица 1 — Классификация алгоритмов компрессии
5.4 Значения метрик качества определяются для каждого звукового фрагмента (длиной в пять секунд) оцифрованных аудиоданных, а в качестве результирующей оценки выбирается: наименьшее значение для метрик PSNR и PEAQ; наибольшее значение для коэффициента различия форм сигналов.
Для расчета метрик PSNR и коэффициента различия форм сигналов исходные и восстановленные цифровые аудиоданные должны быть представлены с частотой дискретизации 44100 Гц, 16 битами памяти на одно дискретное значение выборки и с одним звуковым каналом. Длина звукового фрагмента в пять секунд в этом случае составляет 220500 оцифрованных значений.
Для расчета метрики PEAQ исходные и восстановленные цифровые аудиоданные должны быть представлены с частотой дискретизации 48000 Гц, 16 битами памяти на одно дискретное значение выборки и с одним или с двумя звуковыми каналами. Длина звукового фрагмента в пять секунд в этом случае составляет 240000 оцифрованных значений для каждого канала.
Для сигналов с частотой, отличной от требуемой, необходимо предварительно выполнить передискретизацию аудиосигнала.
Методы оценки алгоритмов компрессии
6.1 Общее описание методов оценки
Общая схема работы ЦСОТ с точки зрения использования алгоритмов компрессии и декомпрессии представлена на рисунке 1.

Рисунок 1 — Общая схема работы ЦСОТ
Аналоговые аудиоданные подвергаются аналогово-цифровому преобразованию, в результате которого получаются оцифрованные аудиоданные с определенной частотой дискретизации и количеством битов на одно дискретное оцифрованное значение. На компьютере оцифрованные аудиоданные должны храниться в одном из форматов хранения оцифрованных аудиоданных.
Оцифрованные аудиоданные подвергаются компрессии, в результате которой формируются сжатые аудиоданные.
Сжатые аудиоданные используются для хранения архива или для передачи по сети, после чего они подвергаются декомпрессии. В результате декомпрессии сжатых аудиоданных образуются восстановленные аудиоданные, которые используются для воспроизведения оператору и подаются на вход программным модулям анализа аудиоданных.
В соответствии с представленной общей схемой работы ЦСОТ, классификация алгоритмов компрессии оцифрованных аудиоданных выполняется путем оценки метрик качества восстановленных аудиоданных от исходных оцифрованных аудиоданных. В зависимости от особенностей технической реализации конкретной ЦСОТ существует два метода оценки:
— на основе разделения оцифрованных аудиоданных;
— на основе разделения аудиоданных.
Перед оценкой значений метрик качества оба аудиосигнала (исходные и восстановленный) должны быть преобразованы в сигналы с частотой дискретизации 44100 Гц и 48000 Гц. Для обеих частот (44100 Гц и 48000 Гц) количество бит, приходящееся на одно дискретное оцифрованное значение, должно быть равным 16.
6.1.1 Метод оценки алгоритма на основе разделения оцифрованных аудиоданных
Для применения данного метода техническая реализация ЦСОТ должна позволять получить оцифрованные аудиоданные до их обработки алгоритмами компрессии и декомпрессии.
Общая схема реализации метода оценки на основе разделения оцифрованных аудиоданных представлена на рисунке 2.

Рисунок 2 — Общая схема реализации метода оценки на основе разделения оцифрованных аудиоданных
Алгоритм осуществления оценки выполняется следующей последовательностью действий:
— на вход испытываемой ЦСОТ подают последовательность аудиоданных;
— с использованием возможностей ЦСОТ оцифрованные и восстановленные аудиоданные сохраняют на устройствах хранения;
— выполняют расчет значений метрик качества и осуществляют классификацию алгоритма компрессии по Таблице 1.
— выполняется расчет значений метрик качества и осуществляется классификацию алгоритма компрессии по Таблице 1.
6.1.2 Метод оценки алгоритма на основе разделения аудиоданных
Метод оценки на основе разделения аудиоданных следует применять только в случае, если техническая реализация ЦСОТ не позволяет применять метод оценки на основе разделения оцифрованных аудиоданных. Применение данного метода требует наличия дополнительной ЦСОТ в составе испытательного стенда, которая предназначена для сохранения оцифрованных аудиоданных.
Общая схема реализации метода оценки на основе разделения аудиоданных представлена на рисунке 3.

Рисунок 3 — Общая схема реализации метода оценки на основе
Алгоритм осуществления оценки по данному методу предполагает выполнение следующих действий:
— на вход испытываемой ЦСОТ подают последовательные аудиоданные, которые дублируются на другую ЦСОТ посредством делителя аудиосигнала (из состава испытательного стенда);
— с использованием возможностей ЦСОТ восстановленные аудиоданные сохраняют на устройствах хранения;
— с использованием возможностей ЦСОТ из состава испытательного стенда оцифрованные аудиоданные сохраняют на устройствах хранения;
— выполняют расчет значений метрик качества и осуществляют классификацию алгоритма компрессии по Таблице 1.
6.2. Алгоритм вычисления PEAQ
Данная метрика предназначена для оценки качества обработанного сигнала относительно исходного с учетом слуховых особенностей человека (психоакустической модели). Данная метрика оценки качества аудиосигнала рекомендована стандартом ITU-R BS 1387.1.
Требования к входным аудиосигналам:
• оба аудиосигнала (исходный и восстановленный) для расчета метрики PEAQ должны иметь частоту дискретизации равную 48 кГЦ. Для сигналов с отличной от 48 кГц частотой необходимо предварительно выполнить передискретизацию аудиосигнала;
• оба аудиосигнала должны иметь одинаковую длину (состоять из одного и того же количества оцифрованных значений).
>Обозначения
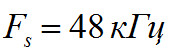 — частота дискретизации сигналов;
— частота дискретизации сигналов;
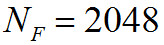 — количество оцифрованных значений сигнала, определяющих длину звукового фрагмента (размер фрейма);
— количество оцифрованных значений сигнала, определяющих длину звукового фрагмента (размер фрейма);
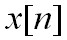 — оцифрованные данные фрейма,
— оцифрованные данные фрейма, 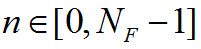
Покадровый шаг вперед: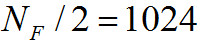 , таким образом, перекрытие фреймов составляет 50%;
, таким образом, перекрытие фреймов составляет 50%;
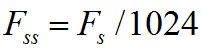 — частота выборки кадров с учетом покадрового шага;
— частота выборки кадров с учетом покадрового шага;
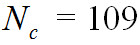 — количество частотных полос фильтрации.
— количество частотных полос фильтрации.
Требования к входным аудиосигналам:
• оба аудиосигнала (исходный и восстановленный) для расчета метрики PEAQ должны иметь частоту дискретизации равную 48 кГЦ. Для сигналов с отличной от 48 кГц частотой необходимо предварительно выполнить передискретизацию аудиосигнала;
• оба аудиосигнала должны иметь одинаковую длину (состоять из одного и того же количества оцифрованных значений).
>Обозначения
 — частота дискретизации сигналов;
— частота дискретизации сигналов; — количество оцифрованных значений сигнала, определяющих длину звукового фрагмента (размер фрейма);
— количество оцифрованных значений сигнала, определяющих длину звукового фрагмента (размер фрейма); — оцифрованные данные фрейма,
— оцифрованные данные фрейма, 
Покадровый шаг вперед:
 , таким образом, перекрытие фреймов составляет 50%;
, таким образом, перекрытие фреймов составляет 50%; — частота выборки кадров с учетом покадрового шага;
— частота выборки кадров с учетом покадрового шага; — количество частотных полос фильтрации.
— количество частотных полос фильтрации.Расчет метрики должен состоять из 5 этапов.
I Предварительная обработка сигналов
Применение оконного преобразованияИсходные оцифрованные данные разбиваются на фреймы. Оцифрованные данные каждого фрейма подвергаются масштабированному оконному преобразованию Ханна по формуле (2). Оконная функция Ханна имеет вид:
 (1)
(1)
Масштабированная версия оконной функции Ханна:
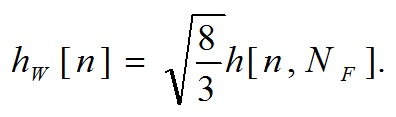 (2)
(2)
Переход в частотную область осуществляется путем применения дискретного преобразования Фурье (ДПФ):
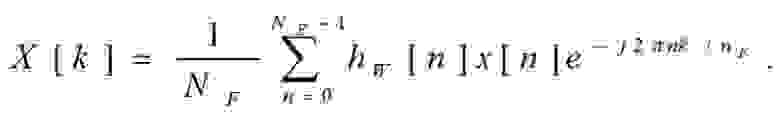 (3)
(3)
Модель наружного и среднего уха
Частотная характеристика наружного и среднего уха должна вычисляться по следующей формуле:
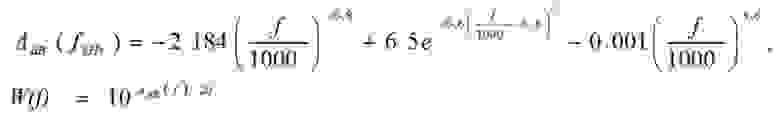 (4)
(4)
По формулам (4) вектор весовых коэффициентов вычисляется следующим образом:
 (5)
(5)
Используя эти веса (5), вычисляется взвешенная энергия ДПФ:
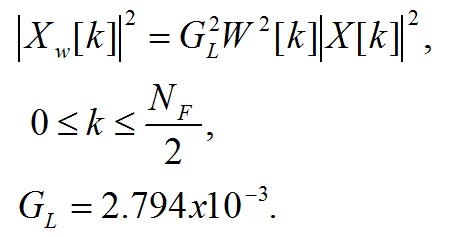 (6)
(6)
Разложение критической полосы слуха
Ниже приведены формулы, необходимые для преобразования в шкалу Барка (7) и обратного преобразования (8):
 (7)
(7)
где z измеряется в Барках.
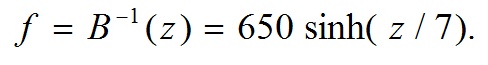 (8)
(8)
Полосы частот
Полосы частот определяются заданием нижней, центральной и верхней частот каждой полосы. Эти значения в шкале Барка задаются так:
 (9)
(9)
Обратное преобразование выполняется по следующим формулам:
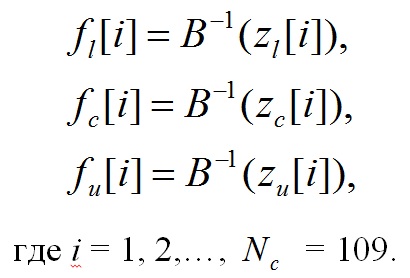 (10)
(10)
Значение i = 1, 2,…,.
Энергия полосы частот
Для i-ой полосы частот вклад энергии от k-ой основной частоты ДПФ вычисляется по следующей формуле:
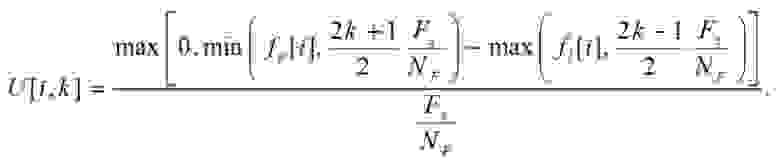 (11)
(11)
Тогда энергия i-ой полосы частот равна:
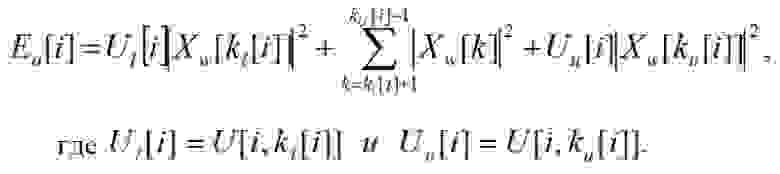 (12)
(12)
Ниже приведена конечная формула для энергии i-ой полосы частот:
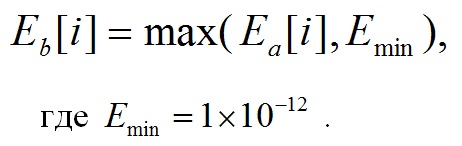 (13)
(13)
Внутренний шум уха
Чтобы компенсировать внутренние шумы в самом ухе, введем надбавочное значение для энергии каждой полосы частот:
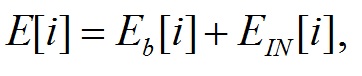 (14)
(14)
где внутренний шум моделируется следующим образом:
 (15)
(15)
Энергии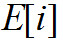 будем называть в дальнейшем образами высоты.
будем называть в дальнейшем образами высоты.
Энергия распространения в пределах одного фрейма
Характеристика энергии распространения в шкале Барка рассчитывается так:
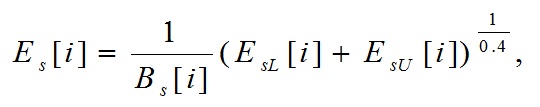 (16)
(16)
где
 (17)
(17)
Функция S (i, l, E) имеет следующий вид:
 (18)
(18)
где
 (19)
(19)
Ниже приводятся формулы для вычисления слагаемых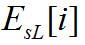 и
и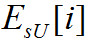 :
:
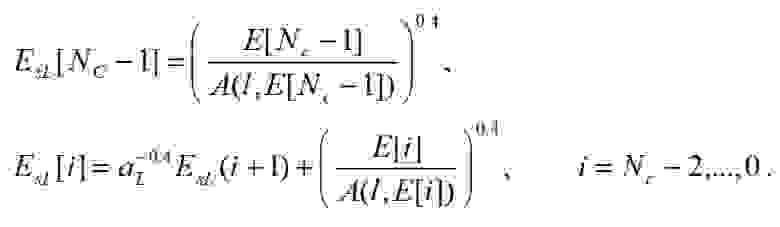 (20)
(20)
и
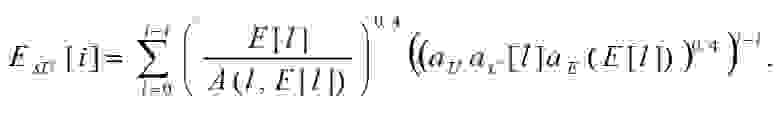 (21)
(21)
Энергии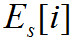 — образами нераспространенных возбуждений.
— образами нераспространенных возбуждений.
Фильтрация энергии
Пусть n — индекс фрейма (фреймы проиндексированы, начиная с n = 0). Тогда энергия n-го фрейма соответствующая формуле (16) обозначается так:Фильтрация энергии выполняется в соответствии со следующей формулой:
 (22)
(22)
где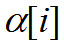 — постоянная времени для угасающей энергии. Начальное условие для фильтрации:
— постоянная времени для угасающей энергии. Начальное условие для фильтрации: 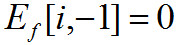
Конечные значения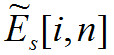 — образы возбуждений.
— образы возбуждений.
Постоянные времени
Постоянная времени для фильтрации i-ой полосы вычисляется следующим образом:
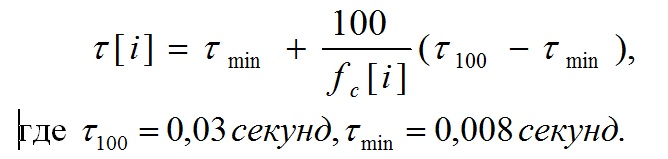 (23)
(23)
можно вычислить так:
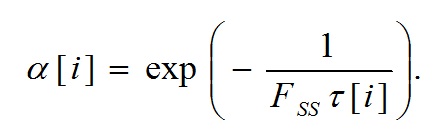 (24)
(24)
II. Обработка образов
Ниже на рисунке 4 приведена схема предварительных вычислений, описанных в предыдущей главе.

Рисунок 4 Схема предварительной обработки сигналов
Индексы R и T обозначают исходный и восстановленный аудиосигналы соответственно. Индекс k обозначает индекс полосы частот (всего полос частот — 109), а индекс n — номер фрейма. Для рекуррентных формул на этом и следующем этапе (этапе III) всегда выбираются нулевые начальные условия.
Обработка образов возбуждений
Входными данными для этой стадии вычислений являются образы возбуждений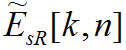 и
и 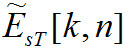 , рассчитываемые по формуле (22) для исходного и тестируемого аудиосигналов соответственно.
, рассчитываемые по формуле (22) для исходного и тестируемого аудиосигналов соответственно.
Коррекция образов возбуждений
Сначала осуществляется фильтрация для обоих аудиосигналов по формуле:
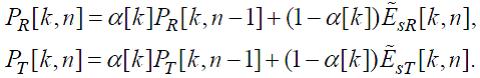 (25)
(25)
Постоянная времени рассчитывается по формулам (23) и (24), но при 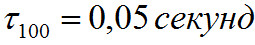 ,
,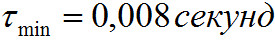 . Начальное условие для фильтрации выбирается равным 0.
. Начальное условие для фильтрации выбирается равным 0.
Далее вычисляется коэффициент коррекции:
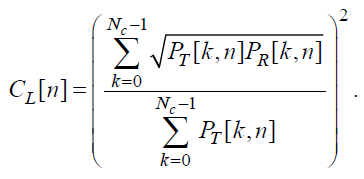 (26)
(26)
Образы возбуждений корректируются следующим образом:
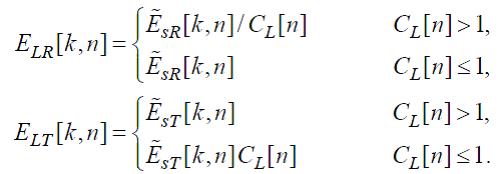 (27)
(27)
Адаптация образов возбуждений
Используя те же постоянные времени и начальные условия, что и при коррекции образов возбуждений, выходные сигналы, рассчитанные по формуле (27), сглаживаются в соответствии со следующими формулами:
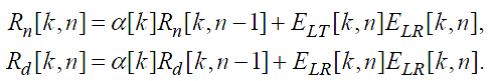 (28)
(28)
На основе соотношения между рассчитанными в (28) значениями, вычисляется пара вспомогательных сигналов:
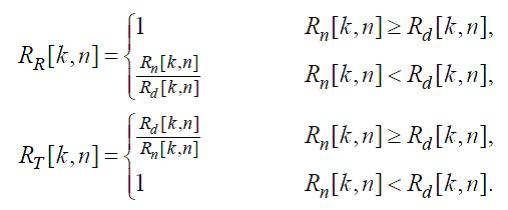 (29)
(29)
Если в предыдущей формуле (29) числитель и знаменатель равны нулю, то необходимо вы-полнить следующие действия: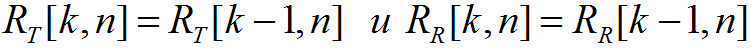 .
.
Если же k = 0, то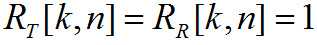
Для формирования множителей для коррекции образов, вспомогательные сигналы подвергаются фильтрации, с использованием тех же постоянных времени и начального условия, что и в (25):
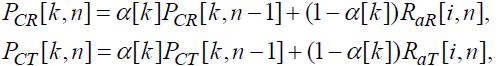 (30)
(30)
где
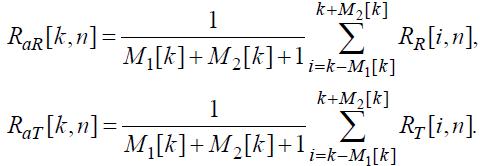 (31)
(31)
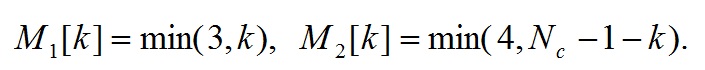 (32)
(32)
Как конечный результат этой стадии обработки, на основе формулы (30) получаются спектрально адаптированные образы:
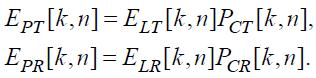 (33)
(33)
Обработка образов модуляции
Входными данными для этой стадии вычислений являются образы нераспространенных возбуждений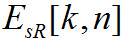 и
и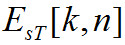 , рассчитываемые по формуле (16) для исходного и тестируемого аудиосигналов соответственно. Цель этого раздела вы-числить меры модуляций огибающих спектра.
, рассчитываемые по формуле (16) для исходного и тестируемого аудиосигналов соответственно. Цель этого раздела вы-числить меры модуляций огибающих спектра.
Сначала вычисляется средняя громкость:
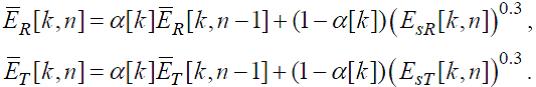 (34)
(34)
Далее необходимо вычислить следующие разности:
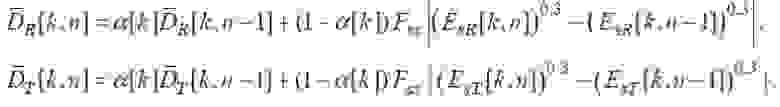 (35)
(35)
Постоянные времени и начальные условия используются те же самые, что и в предыдущей секции.
Меры модуляции огибающих спектра вычисляются следующим образом:
 (36)
(36)
Вычисление громкости
Образы громкости вычисляются в соответствии со следующими формулами:
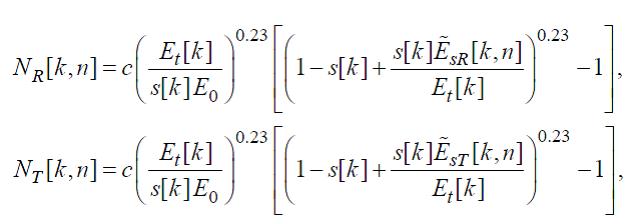 (37)
(37)
где
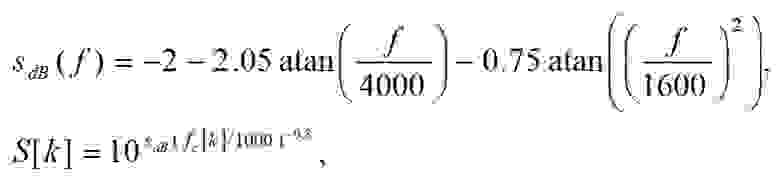 (38)
(38)
и
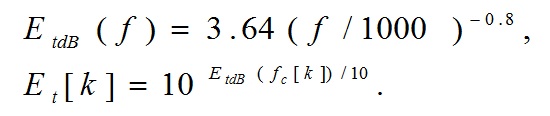 (39)
(39)
Параметр c = 1,07664.
Общие громкости для обоих сигналов вычисляются так:
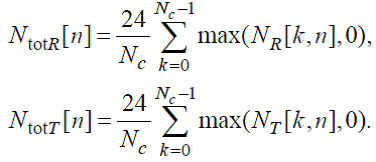 (40)
(40)
III. Расчет выходных значений психоакустической модели
Выходные характеристики из главы I используются для вычисления выходных характеристик главы II в соответствии со схемой, приведенной ниже (см. рисунок 5).
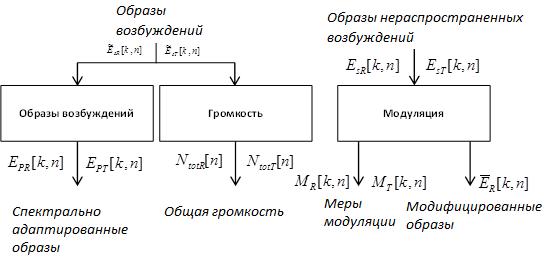
Рисунок 5 Схема обработки образов
В свою очередь, значения предыдущей главы (II) используются вычисления выходных значений переменных психоакустической модели (см. таблицу 1 и рисунок 6).
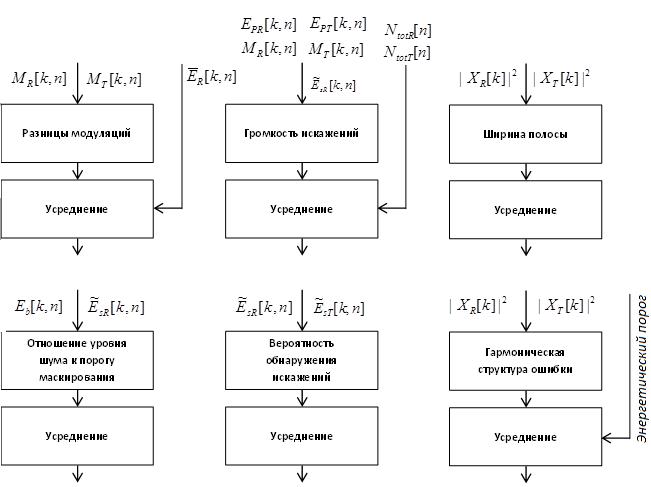
Рисунок 6 Схема вычисления значений выходных переменных психоакустической модели
В общей сложности, рассчитываются значения 11 переменных психоакустической модели. Они перечислены в Таблице 2.
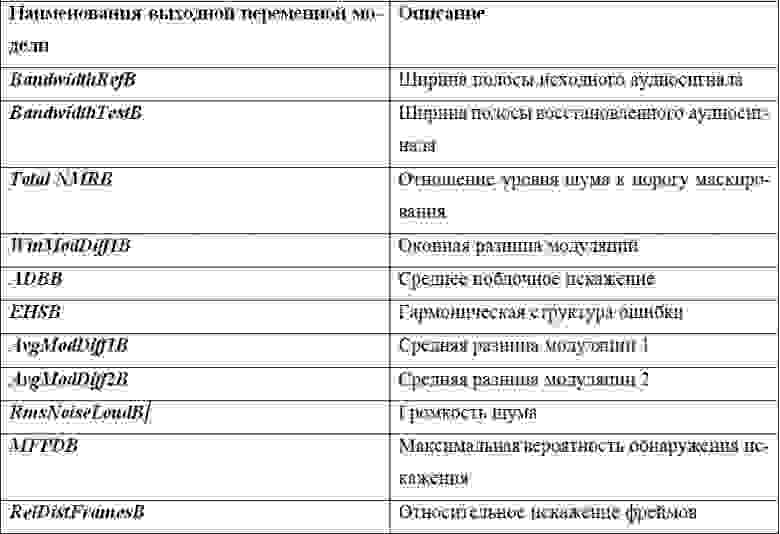
Таблица 2. Выходные переменные психоакустической модели
Для двухканальных аудиосигналов значения переменных для каждого канала рас-считываются отдельно, а потом усредняются. Значения всех переменных (кроме значений переменных ADBB и MFPDB) для каждого канала сигнала рассчитываются независимо от второго канала.
Общее описание процесса расчета параметров
Все значения выходных переменных модели получены путем усреднения по всем фреймам функций времени и частоты, полученных на предыдущем шаге (в результате — скалярное значение).
Значения, которые будут усредняться, должны лежать в границах, определяемых следующим условием: начало или конец данных, которые будут подвергаться усреднению, определяются как первая позиция с начала или с конца последовательности значений амплитуд аудиосигнала, для которой сумма пяти последовательных абсолютных значений амплитуд превышает 200 в любом из аудио кана-лов. Фреймы, которые лежат вне этих границ — должны игнорироваться при усреднении. Значение порога 200 используется в случае, если амплитуды входных аудиосигналов нормализованы в диапазоне от -32768 до+32767. В противном случае, значение порога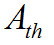 вычисляется следующим образом:
вычисляется следующим образом:
(41)
где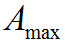 — максимальное значение амплитуды аудиосигнала.
— максимальное значение амплитуды аудиосигнала.
В дальнейшем, индекс фрейма n: начинается с нуля для первого фрейма, удовлетворяющего условиям проверки границ с порогом и отсчитывает число фрей-мов N вплоть до последнего фрейма, удовлетворяющего выше упоминаемому условию.
Оконная разница модуляций 1 (WinModDiff1B)
Ниже приведена формула для вычисления мгновенной разницы модуляций:
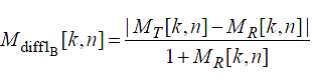 (42)
(42)
Значение мгновенной разницы модуляций усредняется по всем полосам частот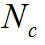 в соответствии со следующей формулой:
в соответствии со следующей формулой:
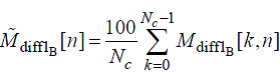 (43)
(43)
Конечное значение выходной переменной получается усреднением формулы 43 со скользящим окном L = 4 (85 мс, т.к. каждый шаг равен 1024 оцифрованных значений):
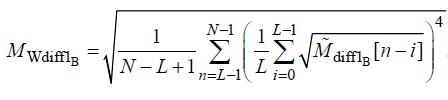 (44)
(44)
При этом применяется так называемое усреднение с задержкой — первые 0,5 секунд сигнала не участвуют в вычислениях. Количество пропускаемых фреймов составляет: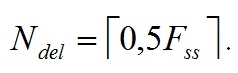 (45)
(45)
В формуле 45 операция обозначает отбрасывание дробной части.
Таким образом, в формуле 44 индекс фреймов включает только фреймы, которые идут после задержки величиной в 0,5 секунд.
Средняя разница модуляций 1 (WinModDiff1B)
Значение данной выходной переменной психоакустической модели вычисляется по следующей формуле:
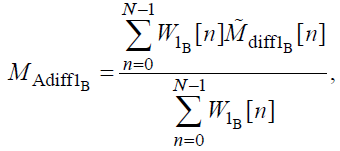 (46)
(46)
где
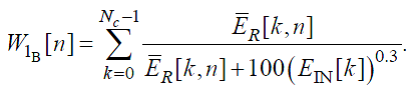 (47)
(47)
Для вычисления этого значения также применяется усреднение с задержкой.
Средняя разница модуляций 2 (WinModDiff2B)
Сначала вычисляется значение мгновенной разницы модуляций по формуле:
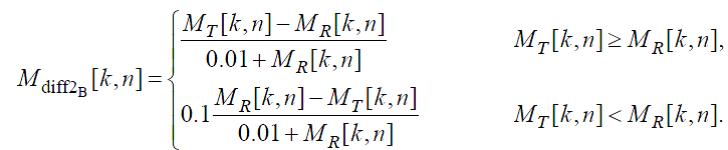 (48)
(48)
Затем вычисляется усредненное по полосам частот значение разности модуляций:
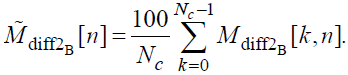 (49)
(49)
Конечное значение переменной психоакустической модели вычисляется следующим образом:
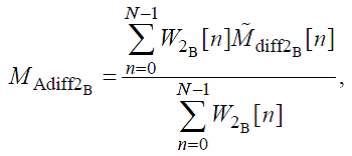 (50)
(50)
где
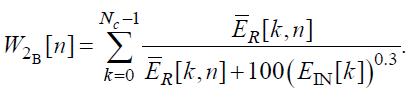 (51)
(51)
Для вычисления этого значения также применяется усреднение с задержкой.
Громкость шума (RmsNoiseLoudB)
Ниже приведена формула для нахождения значений мгновенной громкости шума:
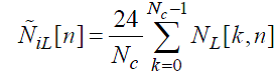 (52)
(52)
где
 (53)
(53)
где:
 (54)
(54)
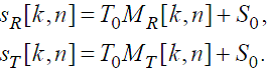 (55)
(55)
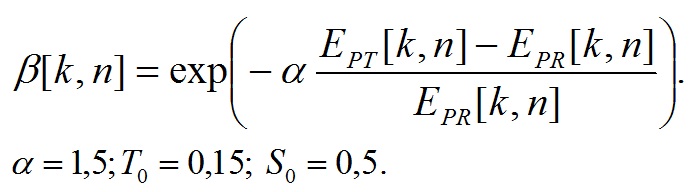 (56)
(56)
а
Далее, если мгновенная громкость меньше 0, то она устанавливается равной 0:
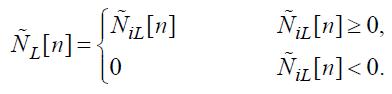 (57)
(57)
Значение конечной выходной переменной психоакустической модели находится усреднени-ем мгновенной громкости:
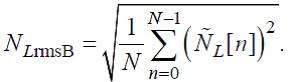 (58)
(58)
Для вычисления этого значения применяется усреднение с задержкой. Совместно с усреднением с задержкой используется порог громкости, для нахождения значения мгновенной громкости шума, начиная с которого выполняется процесс усреднение. Таким образом, усреднение начинается с первого значения, определяемого условием превышения порога громкости, но не позднее 0,5 секунд с начала сигнала (в соответствии с усреднением с задержкой).
Условие превышения порога громкости
Значения мгновенной громкости шума в начале обоих сигналов (исходного и тестируемого) игнорируются до тех пор, пока не пройдет 50 мс после того, как значение общей громкости превысит в обоих каналах одного из сигналов значение порога, равное 0,1.
Условие превышения порога можно представить в виде:
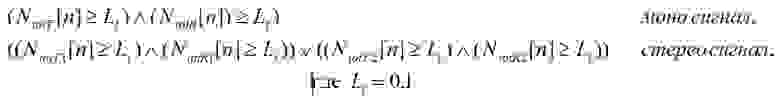 (59)
(59)
Ниже приведенная формула предназначена для расчета количества пропускаемых после превышения порога фреймов:
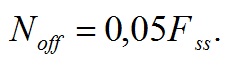 (60)
(60)
Ширина полос исходного и восстановленного аудиосигналов (BandwidthRefB и BandwidthTestB)
Операции вычислений ширины полос исходного и восстановленного аудиосигналов описываются в терминах операций на выходных значениях ДПФ, выраженных в децибелах (дБ). Прежде всего, для каждого фрейма выполняются следующие операции:
• Для восстановленного сигнала: находится самая большая компонента после частоты 21,6 кГц. Это значение называется уровнем порога.
• Для исходного сигнала: выполняя поиск вниз, начиная с частоты 21,6 кГц, находится пер-вое значение, которое превышает значение уровня порога на 10 дБ. Соответствующая это-му значению частота называется шириной полосы для исходного сигнала.
• Для восстановленного сигнала: выполняя поиск вниз, начиная со значения ширины полосы исходного сигнала, находится первое значение, которое превышает значение уровня порога на 5 дБ. Обозначим соответствующую этому значению частоту как ширину полосы для восстановленного сигнала.
Если найденные частоты для исходного сигнала не превосходят 8,1 кГц, то ширина полосы для этого фрейма игнорируется.
Значения ширин полос для всех фреймов называются основными частотами ДПФ.
Основная частота ДПФ для n-го фрейма обозначается как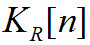 для исходного сигнала и как—
для исходного сигнала и как—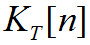 для восстановленного сигнала. Для вычисления конечных значений переменных психоакустической модели, значений ширин полос исходного и восстановленного сигналов, необходимо выполнять по следующим формулам соответственно:
для восстановленного сигнала. Для вычисления конечных значений переменных психоакустической модели, значений ширин полос исходного и восстановленного сигналов, необходимо выполнять по следующим формулам соответственно:
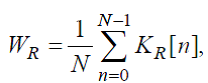 (61)
(61)
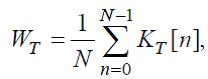 (62)
(62)
где суммирование ведется только для тех фреймов, в которых основная частота ДПФ превышает 8,1 кГц.
Отношение уровня шума к порогу маскирования (Total NMRB)
Порог маскирования вычисляется по следующей формуле:
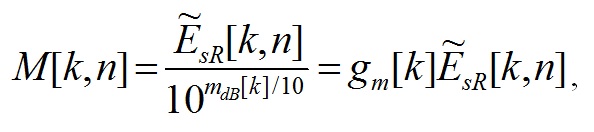 (63)
(63)
где
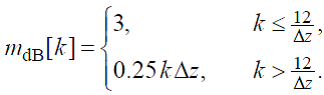 (64)
(64)
Уровень шума вычисляется так:
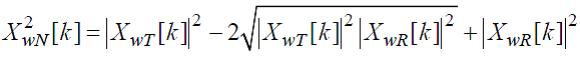 (65)
(65)
где k обозначает индекс основной частоты ДПФ.
Отношение уровня шума к порогу маскирования в k-ой полосе частот выражается следующей формулой:
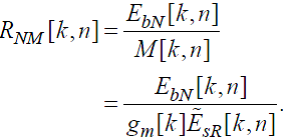 (66)
(66)
Конечное отношение уровня шума к порогу маскирования (в децибелах) вычисляется так:
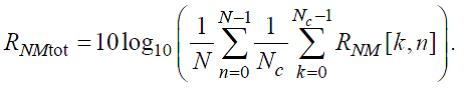 (67)
(67)
Относительное искажение фреймов (RelDistFramesB)
Максимальное отношение шума к порогу маскирования фрейма вычисляется так:
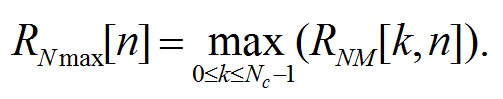 (68)
(68)
Искаженным считается тот фрейм, в котором максимальное отношение шума к порогу маскирования превышает 1,5 дБ.
Конечное значение выходной переменной психоакустической модели представляет собой отношения количества искаженных фреймов к общему количеству фреймов.
Максимальная вероятность обнаружения искажения (MFPDB)
Прежде всего, вычислим асимметричное возбуждение:
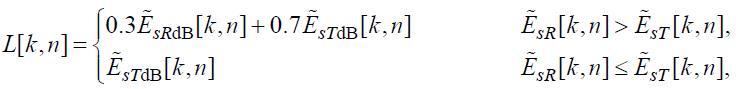 (69)
(69)
где
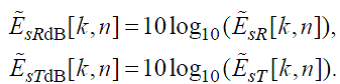 (70)
(70)
Далее вычисляется шаг для обнаружения искажения:
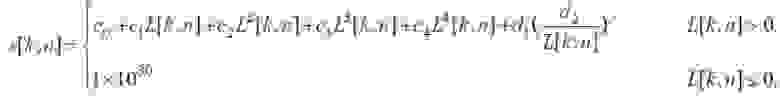 (71)
(71)
где
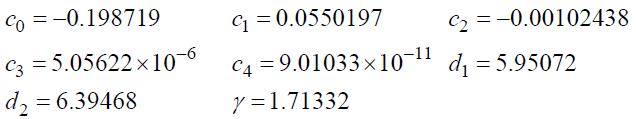 (72)
(72)
Вероятность обнаружения вычисляется так:
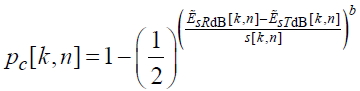 (73)
(73)
где b вычисляется так:
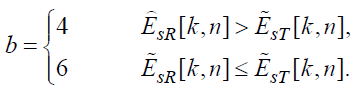 (74)
(74)
Вычислим количество шагов сверх порога вероятности обнаружения:
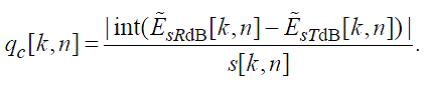 (75)
(75)
Характеристики (73) и (75) вычисляются для каждого канала сигнала. Для каждой частоты и времени, полная вероятность обнаружение и полное число шагов сверх порога выбираются как большее значение из всех каналов:
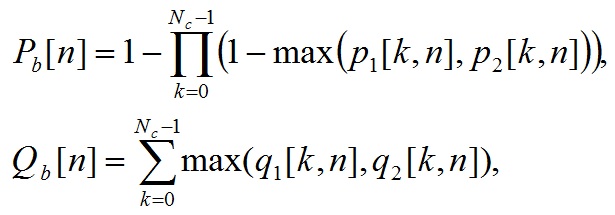 (76)
(76)
где индексы 1 и 2 обозначают номер канала.
Для одноканальных сигналов выше приведенные значения вычисляются так:
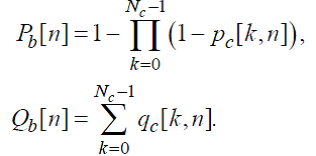 (77)
(77)
Выполняется следующая вычислительная процедура:
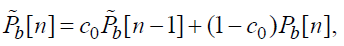 (78)
(78)
где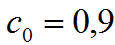 и начальное условие — нулевое.
и начальное условие — нулевое.
Максимальная вероятность обнаружения искажения вычисляется по рекуррентной формуле:
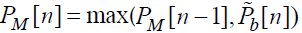 (79)
(79)
Конечное значение выходной переменной психоакустической модели рассчитывается так:
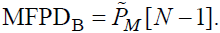 (80)
(80)
Среднее поблочное искажение (ADBB)
Сначала вычисляется сумма общего числа шагов сверх порога обнаружения:
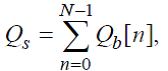 (81)
(81)
Причем суммирование ведется для всех значений, для которых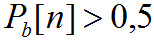
Конечная характеристика имеет вид:
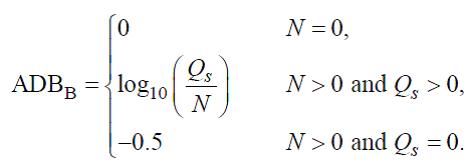 (82)
(82)
Гармоническая структура ошибки (EHSB)
Выходы ДПФ для исходного и восстановленного сигналов обозначаются как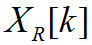 и
и  соответственно.
соответственно.
Вычисляется характеристика:
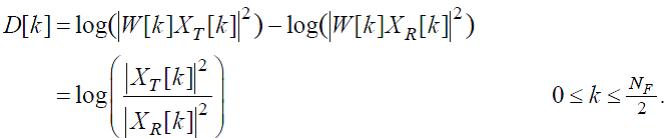 (83)
(83)
Формируется вектор длины M из значений D[k]:
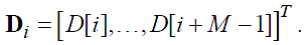 (84)
(84)
Нормализованная автокорреляция вычисляется по формуле:
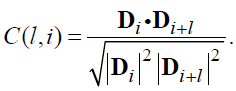 (85)
(85)
где
Пусть —C[l]=C[l,0]. Далее необходимо вычислить:
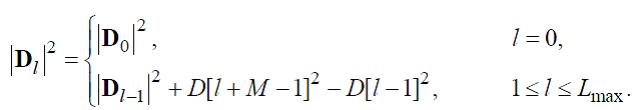 (86)
(86)
При вычислении (85) в случае, если сигналы равны, необходимо установить нормализованную автокорреляцию равной единице, чтобы избежать деления на 0.
Вводится оконная функцию следующего вида:
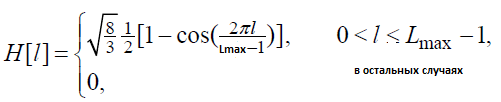 (87)
(87)
Применяется оконное преобразование (87) к нормализованной автокорреляции:
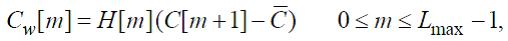 (88)
(88)
где
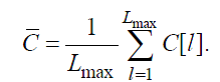 (89)
(89)
Спектр мощности вычисляется по формуле:
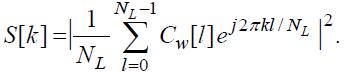 (90)
(90)
Поиск максимального пика спектра мощности начинается с k = 1 и заканчивается при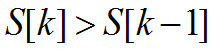 или
или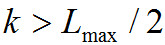 Найденное значение максимального пика обозначается как
Найденное значение максимального пика обозначается как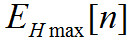 Тогда конечное значение выходной переменной психоакустической модели рассчитывается по следующей формуле:
Тогда конечное значение выходной переменной психоакустической модели рассчитывается по следующей формуле:
 (91)
(91)
При вычислении этого значения, исключаются фреймы с низкой энергией. Для определения фреймов с низкой энергией, вводится пороговое значение:
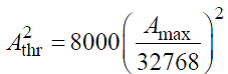 (92)
(92)
где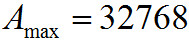 для амплитуд, хранимых в виде 16 битного целого числа.
для амплитуд, хранимых в виде 16 битного целого числа.
Энергия фрейма оценивается по следующей формуле:
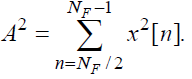 (93)
(93)
При вычислении гармонической структуры ошибки фрейм игнорируется, если:
 (94)
(94)
IV. Нормирование значений выходных переменных психоакустической модели
Нормирование полученных на предыдущем шаге значений выходных переменных психоакустической модели выполняется в соответствии со следующей формулой:
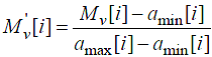 (95)
(95)
где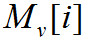 — значение i-ой выходной переменной психоакустической модели, значения
— значение i-ой выходной переменной психоакустической модели, значения 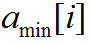 и
и 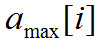 приведены в Таблице 3 ниже.
приведены в Таблице 3 ниже.
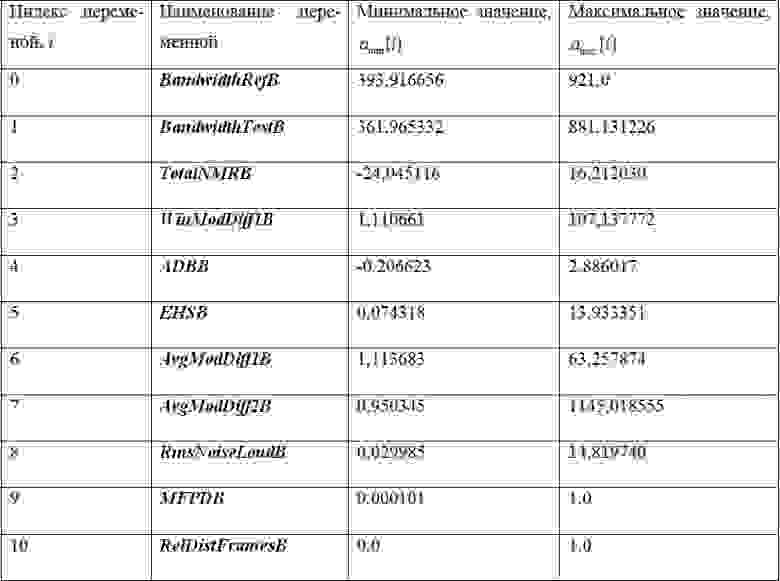
Таблица 3. Константы для нормирования значений выходных переменных психоакустической модели
V. Оценка качества восстановленного сигнала с помощью искусственной нейронной сети
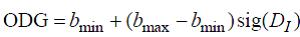 (96)
(96)
где bmin = −3,98 и bmax = 0,22, а функция sig(x) — ассиметричная сигмоида:
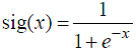 (97)
(97)
Значение вычисляется следующим образом:
вычисляется следующим образом:
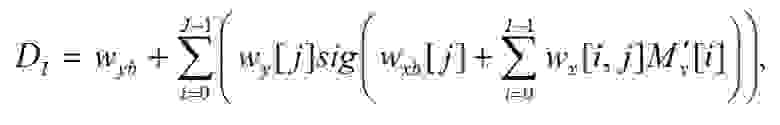 (98)
(98)
где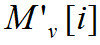 — нормализованное значение i-ой выходной переменной, I — количество выходных пе-ременных (равное 11), J — количество нейронов в скрытом слое (равное 3),
— нормализованное значение i-ой выходной переменной, I — количество выходных пе-ременных (равное 11), J — количество нейронов в скрытом слое (равное 3), 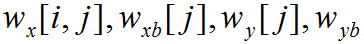 — значения весов и смещений нейронной сети, приведенные в Таблицах 4-6 ниже.
— значения весов и смещений нейронной сети, приведенные в Таблицах 4-6 ниже.
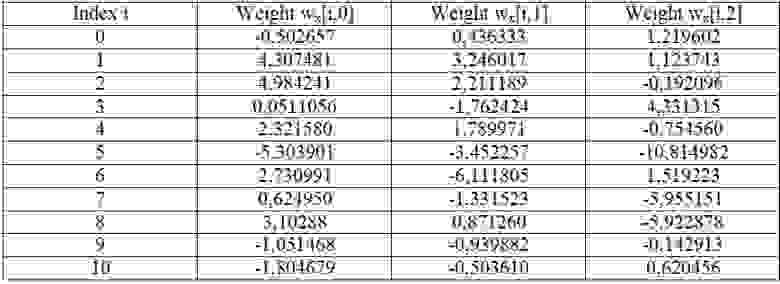
Таблица 4 Веса нейронной сети
<
Таблица 5 Смещения нейронной сети

Таблица 6 Веса и смещения нейронной сети
Это значение метрики (PEAQ) представляет собой вещественное число, принадлежащее отрезку [-3,98; 0,22].
Применение оконного преобразованияИсходные оцифрованные данные разбиваются на фреймы. Оцифрованные данные каждого фрейма подвергаются масштабированному оконному преобразованию Ханна по формуле (2). Оконная функция Ханна имеет вид:
 (1)
(1)Масштабированная версия оконной функции Ханна:
 (2)
(2)Переход в частотную область осуществляется путем применения дискретного преобразования Фурье (ДПФ):
 (3)
(3)Модель наружного и среднего уха
Частотная характеристика наружного и среднего уха должна вычисляться по следующей формуле:
 (4)
(4) По формулам (4) вектор весовых коэффициентов вычисляется следующим образом:
 (5)
(5)Используя эти веса (5), вычисляется взвешенная энергия ДПФ:
 (6)
(6)Разложение критической полосы слуха
Ниже приведены формулы, необходимые для преобразования в шкалу Барка (7) и обратного преобразования (8):
 (7)
(7)где z измеряется в Барках.
 (8)
(8)Полосы частот
Полосы частот определяются заданием нижней, центральной и верхней частот каждой полосы. Эти значения в шкале Барка задаются так:
 (9)
(9)Обратное преобразование выполняется по следующим формулам:
 (10)
(10)Значение i = 1, 2,…,
.Энергия полосы частот
Для i-ой полосы частот вклад энергии от k-ой основной частоты ДПФ вычисляется по следующей формуле:
 (11)
(11)Тогда энергия i-ой полосы частот равна:
 (12)
(12)Ниже приведена конечная формула для энергии i-ой полосы частот:
 (13)
(13)Внутренний шум уха
Чтобы компенсировать внутренние шумы в самом ухе, введем надбавочное значение для энергии каждой полосы частот:
 (14)
(14)где внутренний шум моделируется следующим образом:
 (15)
(15)Энергии
 будем называть в дальнейшем образами высоты.
будем называть в дальнейшем образами высоты.Энергия распространения в пределах одного фрейма
Характеристика энергии распространения в шкале Барка рассчитывается так:
 (16)
(16)где
 (17)
(17)Функция S (i, l, E) имеет следующий вид:
 (18)
(18) где
 (19)
(19) Ниже приводятся формулы для вычисления слагаемых
 и
и :
: (20)
(20)и
 (21)
(21)Энергии
 — образами нераспространенных возбуждений.
— образами нераспространенных возбуждений.Фильтрация энергии
Пусть n — индекс фрейма (фреймы проиндексированы, начиная с n = 0). Тогда энергия n-го фрейма соответствующая формуле (16) обозначается так:
Фильтрация энергии выполняется в соответствии со следующей формулой: (22)
(22) где
 — постоянная времени для угасающей энергии. Начальное условие для фильтрации:
— постоянная времени для угасающей энергии. Начальное условие для фильтрации: 
Конечные значения
 — образы возбуждений.
— образы возбуждений.Постоянные времени
Постоянная времени для фильтрации i-ой полосы вычисляется следующим образом:
 (23)можно вычислить так:
(23)можно вычислить так: (24)
(24)II. Обработка образов
Ниже на рисунке 4 приведена схема предварительных вычислений, описанных в предыдущей главе.

Рисунок 4 Схема предварительной обработки сигналов
Индексы R и T обозначают исходный и восстановленный аудиосигналы соответственно. Индекс k обозначает индекс полосы частот (всего полос частот — 109), а индекс n — номер фрейма. Для рекуррентных формул на этом и следующем этапе (этапе III) всегда выбираются нулевые начальные условия.
Обработка образов возбуждений
Входными данными для этой стадии вычислений являются образы возбуждений
 и
и  , рассчитываемые по формуле (22) для исходного и тестируемого аудиосигналов соответственно.
, рассчитываемые по формуле (22) для исходного и тестируемого аудиосигналов соответственно.Коррекция образов возбуждений
Сначала осуществляется фильтрация для обоих аудиосигналов по формуле:
 (25)
(25)Постоянная времени
рассчитывается по формулам (23) и (24), но при  ,
, . Начальное условие для фильтрации выбирается равным 0.
. Начальное условие для фильтрации выбирается равным 0.Далее вычисляется коэффициент коррекции:
 (26)
(26)Образы возбуждений корректируются следующим образом:
 (27)
(27)Адаптация образов возбуждений
Используя те же постоянные времени и начальные условия, что и при коррекции образов возбуждений, выходные сигналы, рассчитанные по формуле (27), сглаживаются в соответствии со следующими формулами:
 (28)
(28)На основе соотношения между рассчитанными в (28) значениями, вычисляется пара вспомогательных сигналов:
 (29)
(29)Если в предыдущей формуле (29) числитель и знаменатель равны нулю, то необходимо вы-полнить следующие действия:
 .
. Если же k = 0, то

Для формирования множителей для коррекции образов, вспомогательные сигналы подвергаются фильтрации, с использованием тех же постоянных времени и начального условия, что и в (25):
 (30)
(30)где
 (31)
(31) (32)
(32)Как конечный результат этой стадии обработки, на основе формулы (30) получаются спектрально адаптированные образы:
 (33)
(33)Обработка образов модуляции
Входными данными для этой стадии вычислений являются образы нераспространенных возбуждений
 и
и , рассчитываемые по формуле (16) для исходного и тестируемого аудиосигналов соответственно. Цель этого раздела вы-числить меры модуляций огибающих спектра.
, рассчитываемые по формуле (16) для исходного и тестируемого аудиосигналов соответственно. Цель этого раздела вы-числить меры модуляций огибающих спектра. Сначала вычисляется средняя громкость:
 (34)
(34)Далее необходимо вычислить следующие разности:
 (35)
(35)Постоянные времени и начальные условия используются те же самые, что и в предыдущей секции.
Меры модуляции огибающих спектра вычисляются следующим образом:
 (36)
(36)Вычисление громкости
Образы громкости вычисляются в соответствии со следующими формулами:
 (37)
(37)где
 (38)
(38)и
 (39)
(39)Параметр c = 1,07664.
Общие громкости для обоих сигналов вычисляются так:
 (40)
(40)III. Расчет выходных значений психоакустической модели
Выходные характеристики из главы I используются для вычисления выходных характеристик главы II в соответствии со схемой, приведенной ниже (см. рисунок 5).

Рисунок 5 Схема обработки образов
В свою очередь, значения предыдущей главы (II) используются вычисления выходных значений переменных психоакустической модели (см. таблицу 1 и рисунок 6).

Рисунок 6 Схема вычисления значений выходных переменных психоакустической модели
В общей сложности, рассчитываются значения 11 переменных психоакустической модели. Они перечислены в Таблице 2.

Таблица 2. Выходные переменные психоакустической модели
Для двухканальных аудиосигналов значения переменных для каждого канала рас-считываются отдельно, а потом усредняются. Значения всех переменных (кроме значений переменных ADBB и MFPDB) для каждого канала сигнала рассчитываются независимо от второго канала.
Общее описание процесса расчета параметров
Все значения выходных переменных модели получены путем усреднения по всем фреймам функций времени и частоты, полученных на предыдущем шаге (в результате — скалярное значение).
Значения, которые будут усредняться, должны лежать в границах, определяемых следующим условием: начало или конец данных, которые будут подвергаться усреднению, определяются как первая позиция с начала или с конца последовательности значений амплитуд аудиосигнала, для которой сумма пяти последовательных абсолютных значений амплитуд превышает 200 в любом из аудио кана-лов. Фреймы, которые лежат вне этих границ — должны игнорироваться при усреднении. Значение порога 200 используется в случае, если амплитуды входных аудиосигналов нормализованы в диапазоне от -32768 до+32767. В противном случае, значение порога
 вычисляется следующим образом:
вычисляется следующим образом:(41)
где
 — максимальное значение амплитуды аудиосигнала.
— максимальное значение амплитуды аудиосигнала. В дальнейшем, индекс фрейма n: начинается с нуля для первого фрейма, удовлетворяющего условиям проверки границ с порогом
и отсчитывает число фрей-мов N вплоть до последнего фрейма, удовлетворяющего выше упоминаемому условию.Оконная разница модуляций 1 (WinModDiff1B)
Ниже приведена формула для вычисления мгновенной разницы модуляций:
 (42)
(42)Значение мгновенной разницы модуляций усредняется по всем полосам частот
 в соответствии со следующей формулой:
в соответствии со следующей формулой: (43)
(43)Конечное значение выходной переменной получается усреднением формулы 43 со скользящим окном L = 4 (85 мс, т.к. каждый шаг равен 1024 оцифрованных значений):
 (44)
(44)При этом применяется так называемое усреднение с задержкой — первые 0,5 секунд сигнала не участвуют в вычислениях. Количество пропускаемых фреймов составляет:
 (45)
(45)В формуле 45 операция обозначает отбрасывание дробной части.
Таким образом, в формуле 44 индекс фреймов включает только фреймы, которые идут после задержки величиной в 0,5 секунд.
Средняя разница модуляций 1 (WinModDiff1B)
Значение данной выходной переменной психоакустической модели вычисляется по следующей формуле:
 (46)
(46)где
 (47)
(47)Для вычисления этого значения также применяется усреднение с задержкой.
Средняя разница модуляций 2 (WinModDiff2B)
Сначала вычисляется значение мгновенной разницы модуляций по формуле:
 (48)
(48)Затем вычисляется усредненное по полосам частот значение разности модуляций:
 (49)
(49)Конечное значение переменной психоакустической модели вычисляется следующим образом:
 (50)
(50)где
 (51)
(51)Для вычисления этого значения также применяется усреднение с задержкой.
Громкость шума (RmsNoiseLoudB)
Ниже приведена формула для нахождения значений мгновенной громкости шума:
 (52)
(52)где
 (53)
(53)где:
 (54)
(54) (55)
(55) (56)
(56)а
Далее, если мгновенная громкость меньше 0, то она устанавливается равной 0:
 (57)
(57)Значение конечной выходной переменной психоакустической модели находится усреднени-ем мгновенной громкости:
 (58)
(58)Для вычисления этого значения применяется усреднение с задержкой. Совместно с усреднением с задержкой используется порог громкости, для нахождения значения мгновенной громкости шума, начиная с которого выполняется процесс усреднение. Таким образом, усреднение начинается с первого значения, определяемого условием превышения порога громкости, но не позднее 0,5 секунд с начала сигнала (в соответствии с усреднением с задержкой).
Условие превышения порога громкости
Значения мгновенной громкости шума в начале обоих сигналов (исходного и тестируемого) игнорируются до тех пор, пока не пройдет 50 мс после того, как значение общей громкости превысит в обоих каналах одного из сигналов значение порога, равное 0,1.
Условие превышения порога можно представить в виде:
 (59)
(59)Ниже приведенная формула предназначена для расчета количества пропускаемых после превышения порога фреймов:
 (60)
(60)Ширина полос исходного и восстановленного аудиосигналов (BandwidthRefB и BandwidthTestB)
Операции вычислений ширины полос исходного и восстановленного аудиосигналов описываются в терминах операций на выходных значениях ДПФ, выраженных в децибелах (дБ). Прежде всего, для каждого фрейма выполняются следующие операции:
• Для восстановленного сигнала: находится самая большая компонента после частоты 21,6 кГц. Это значение называется уровнем порога.
• Для исходного сигнала: выполняя поиск вниз, начиная с частоты 21,6 кГц, находится пер-вое значение, которое превышает значение уровня порога на 10 дБ. Соответствующая это-му значению частота называется шириной полосы для исходного сигнала.
• Для восстановленного сигнала: выполняя поиск вниз, начиная со значения ширины полосы исходного сигнала, находится первое значение, которое превышает значение уровня порога на 5 дБ. Обозначим соответствующую этому значению частоту как ширину полосы для восстановленного сигнала.
Если найденные частоты для исходного сигнала не превосходят 8,1 кГц, то ширина полосы для этого фрейма игнорируется.
Значения ширин полос для всех фреймов называются основными частотами ДПФ.
Основная частота ДПФ для n-го фрейма обозначается как
 для исходного сигнала и как—
для исходного сигнала и как— для восстановленного сигнала. Для вычисления конечных значений переменных психоакустической модели, значений ширин полос исходного и восстановленного сигналов, необходимо выполнять по следующим формулам соответственно:
для восстановленного сигнала. Для вычисления конечных значений переменных психоакустической модели, значений ширин полос исходного и восстановленного сигналов, необходимо выполнять по следующим формулам соответственно: (61)
(61) (62)
(62)где суммирование ведется только для тех фреймов, в которых основная частота ДПФ превышает 8,1 кГц.
Отношение уровня шума к порогу маскирования (Total NMRB)
Порог маскирования вычисляется по следующей формуле:
 (63)
(63)где
 (64)
(64)Уровень шума вычисляется так:
 (65)
(65)где k обозначает индекс основной частоты ДПФ.
Отношение уровня шума к порогу маскирования в k-ой полосе частот выражается следующей формулой:
 (66)
(66)Конечное отношение уровня шума к порогу маскирования (в децибелах) вычисляется так:
 (67)
(67)Относительное искажение фреймов (RelDistFramesB)
Максимальное отношение шума к порогу маскирования фрейма вычисляется так:
 (68)
(68)Искаженным считается тот фрейм, в котором максимальное отношение шума к порогу маскирования превышает 1,5 дБ.
Конечное значение выходной переменной психоакустической модели представляет собой отношения количества искаженных фреймов к общему количеству фреймов.
Максимальная вероятность обнаружения искажения (MFPDB)
Прежде всего, вычислим асимметричное возбуждение:
 (69)
(69)где
 (70)
(70)Далее вычисляется шаг для обнаружения искажения:
 (71)
(71)где
 (72)
(72)Вероятность обнаружения вычисляется так:
 (73)
(73)где b вычисляется так:
 (74)
(74)Вычислим количество шагов сверх порога вероятности обнаружения:
 (75)
(75)Характеристики (73) и (75) вычисляются для каждого канала сигнала. Для каждой частоты и времени, полная вероятность обнаружение и полное число шагов сверх порога выбираются как большее значение из всех каналов:
 (76)
(76)где индексы 1 и 2 обозначают номер канала.
Для одноканальных сигналов выше приведенные значения вычисляются так:
 (77)
(77)Выполняется следующая вычислительная процедура:
 (78)
(78)где
 и начальное условие — нулевое.
и начальное условие — нулевое.Максимальная вероятность обнаружения искажения вычисляется по рекуррентной формуле:
 (79)
(79)Конечное значение выходной переменной психоакустической модели рассчитывается так:
 (80)
(80)Среднее поблочное искажение (ADBB)
Сначала вычисляется сумма общего числа шагов сверх порога обнаружения:
 (81)
(81)Причем суммирование ведется для всех значений, для которых

Конечная характеристика имеет вид:
 (82)
(82)Гармоническая структура ошибки (EHSB)
Выходы ДПФ для исходного и восстановленного сигналов обозначаются как
 и
и  соответственно.
соответственно. Вычисляется характеристика:
 (83)
(83)Формируется вектор длины M из значений D[k]:
 (84)
(84) Нормализованная автокорреляция вычисляется по формуле:
 (85)
(85)где
Пусть —C[l]=C[l,0]. Далее необходимо вычислить:
 (86)
(86)При вычислении (85) в случае, если сигналы равны, необходимо установить нормализованную автокорреляцию равной единице, чтобы избежать деления на 0.
Вводится оконная функцию следующего вида:
 (87)
(87)Применяется оконное преобразование (87) к нормализованной автокорреляции:
 (88)
(88)где
 (89)
(89)Спектр мощности вычисляется по формуле:
 (90)
(90)Поиск максимального пика спектра мощности начинается с k = 1 и заканчивается при
 или
или Найденное значение максимального пика обозначается как
Найденное значение максимального пика обозначается как Тогда конечное значение выходной переменной психоакустической модели рассчитывается по следующей формуле:
Тогда конечное значение выходной переменной психоакустической модели рассчитывается по следующей формуле: (91)
(91)При вычислении этого значения, исключаются фреймы с низкой энергией. Для определения фреймов с низкой энергией, вводится пороговое значение:
 (92)
(92)где
 для амплитуд, хранимых в виде 16 битного целого числа.
для амплитуд, хранимых в виде 16 битного целого числа.Энергия фрейма оценивается по следующей формуле:
 (93)
(93)При вычислении гармонической структуры ошибки фрейм игнорируется, если:
 (94)
(94)IV. Нормирование значений выходных переменных психоакустической модели
Нормирование полученных на предыдущем шаге значений выходных переменных психоакустической модели выполняется в соответствии со следующей формулой:
 (95)
(95)где
 — значение i-ой выходной переменной психоакустической модели, значения
— значение i-ой выходной переменной психоакустической модели, значения  и
и  приведены в Таблице 3 ниже.
приведены в Таблице 3 ниже.
Таблица 3. Константы для нормирования значений выходных переменных психоакустической модели
V. Оценка качества восстановленного сигнала с помощью искусственной нейронной сети
 (96)
(96)где bmin = −3,98 и bmax = 0,22, а функция sig(x) — ассиметричная сигмоида:
 (97)
(97)Значение
 вычисляется следующим образом:
вычисляется следующим образом: (98)
(98)где
 — нормализованное значение i-ой выходной переменной, I — количество выходных пе-ременных (равное 11), J — количество нейронов в скрытом слое (равное 3),
— нормализованное значение i-ой выходной переменной, I — количество выходных пе-ременных (равное 11), J — количество нейронов в скрытом слое (равное 3),  — значения весов и смещений нейронной сети, приведенные в Таблицах 4-6 ниже.
— значения весов и смещений нейронной сети, приведенные в Таблицах 4-6 ниже.
Таблица 4 Веса нейронной сети
<

Таблица 5 Смещения нейронной сети

Таблица 6 Веса и смещения нейронной сети
Это значение метрики (PEAQ) представляет собой вещественное число, принадлежащее отрезку [-3,98; 0,22].
6.3 Алгоритм вычисления PSNR
Пиковое отношение сигнал/шум между исходным аудиосигналом  и восстановленным
и восстановленным  рассчитывается по формулам:
рассчитывается по формулам:
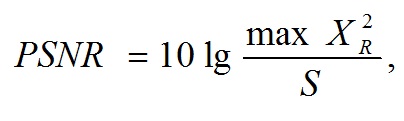 (99)
(99)
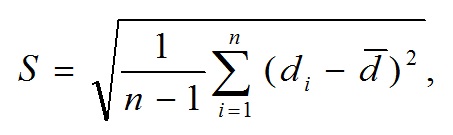 (100)
(100)
где, в свою очередь:
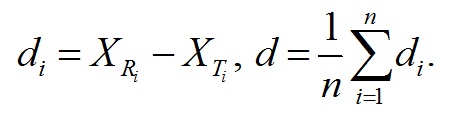 (101)
(101)
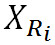 и
и 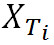 — i-ые оцифрованные значения исходного и восстановленного аудиосигналов соответственно, i = 1, 2,….,n, а
— i-ые оцифрованные значения исходного и восстановленного аудиосигналов соответственно, i = 1, 2,….,n, а 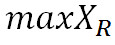 — максимальное значение среди оцифрованных значений исходного аудиосигнала.
— максимальное значение среди оцифрованных значений исходного аудиосигнала.
 и восстановленным
и восстановленным  рассчитывается по формулам:
рассчитывается по формулам: (99)
(99)  (100)
(100) где, в свою очередь:
 (101)
(101) и
и  — i-ые оцифрованные значения исходного и восстановленного аудиосигналов соответственно, i = 1, 2,….,n, а
— i-ые оцифрованные значения исходного и восстановленного аудиосигналов соответственно, i = 1, 2,….,n, а  — максимальное значение среди оцифрованных значений исходного аудиосигнала.
— максимальное значение среди оцифрованных значений исходного аудиосигнала.6.4 Алгоритм вычисления метрики «коэффициент различия форм сигналов»
Пусть 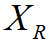 — исходный моноканальный аудиосигнал (либо один канал исходного многоканального аудиосигнала). Аналогично,
— исходный моноканальный аудиосигнал (либо один канал исходного многоканального аудиосигнала). Аналогично, 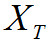 — восстановленный моноканальный аудиосигнал (либо один канал восстановленного многоканального аудиосигнала). Оба сигнала состоят из одинакового количества значений N.
— восстановленный моноканальный аудиосигнал (либо один канал восстановленного многоканального аудиосигнала). Оба сигнала состоят из одинакового количества значений N.
Массивы значений амплитуд сигналовипредставляются в виде относительного изменения значений амплитуд сигнала: 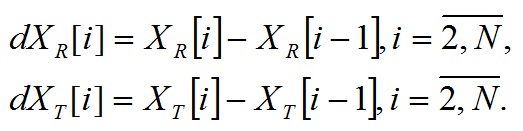 (102)
(102)
Значение метрики «коэффициент различия форм сигналов» K вычисляется как среднеквадратическое отклонение массивов значений амплитуд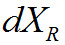 и
и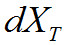 :
:
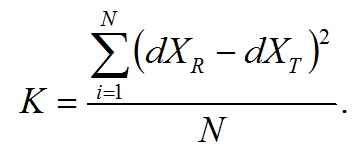 (103)
(103)
 — исходный моноканальный аудиосигнал (либо один канал исходного многоканального аудиосигнала). Аналогично,
— исходный моноканальный аудиосигнал (либо один канал исходного многоканального аудиосигнала). Аналогично,  — восстановленный моноканальный аудиосигнал (либо один канал восстановленного многоканального аудиосигнала). Оба сигнала состоят из одинакового количества значений N.
— восстановленный моноканальный аудиосигнал (либо один канал восстановленного многоканального аудиосигнала). Оба сигнала состоят из одинакового количества значений N.Массивы значений амплитуд сигналов
ипредставляются в виде относительного изменения значений амплитуд сигнала:  (102)
(102)Значение метрики «коэффициент различия форм сигналов» K вычисляется как среднеквадратическое отклонение массивов значений амплитуд
 и
и :
: (103)
(103)7 Методы сравнения алгоритмов компрессии оцифрованных аудиоданных
7.1 Два и более алгоритмов компрессии сравнимы друг с другом, если они принадлежат од-ному и тому же классу в соответствии с Таблицей 1
7.2 Из двух и более сравнимых алгоритмов компрессии лучшим признается алгоритм, обеспечивающий лучшие значения хотя бы двух из трех метрик, приведенных в Таблице 1. Лучшим значением метрики признается большее значение — для метрик PSNR и PEAQ, и меньшее значение — для метрики «коэффициент различия форм сигналов».
Ссылки:
1. P.Kabal, An Examinationa and Intrpretation of ITU-R BS.1387 Perceptual Evaluation of Audio Quality
2. PQevalAudio
