
Всем привет, меня зовут Михаил Марюфич. Я занимаюсь машинным обучением в команде антиспама в Одноклассниках. И сегодня я расскажу про то, как и зачем мы сделали свою технологию распознавания текстовых символов с изображения OCR (Optical character recognition).
Наша команда работает с крупными сервисами Mail.ru: Одноклассники, Юла, Ситимобил, myTarget, ICQ, Игры@mail.ru. Каждый сервис подвергается воздействию спамеров, мошенников, которые хотят навредить обычным пользователям. Для противодействия нам приходится решать различные ML-задачи, и OCR — как раз одна из таких задач.
 Сервисы, с которыми работает команда Антиспама
Сервисы, с которыми работает команда АнтиспамаРаспространение текстового спама началось еще с эры почтовых рассылок. Наши антиспам-фильтры научились оперативно его обнаруживать и удалять. Однако, чем лучше работает антиспам, тем находчивее становятся спамеры.

Примеры спама с текстом на фото
Очередным витком в этой борьбе щита и меча стало нанесение спам-текста на картинку. В тот момент, когда такой спам появился, в Одноклассниках еще не было нейронных сетей, подходящих для того, чтобы своевременно обнаружить и удалить подобные изображения. Приходилось находить их по косвенным признакам с последующей проверкой через ручную модерацию. Это долго и неудобно. А для автоматизации борьбы с таким контентом необходимо уметь распознавать текст на картинке. Но как это сделать?
Распознавание текста или голоса — задача, с одной стороны, трудоёмкая, но с другой, не уникальная: такие задачи уже решали наши коллеги из других компаний. Логично, что стоит начать с анализа готовых решений на рынке и попробовать применить их.
Мы выбрали несколько вариантов распознавания текста от компаний, предоставляющих OCR как сервис: Google, Яндекс, Microsoft. В итоге нам не подошел ни один из вариантов. И вот почему.
Первое. Это стоимость. Сколько стоит распознать текст с одной картинки? В Google — это 10 копеек, в Яндексе — 12 копеек, в Microsoft — 5 копеек. Кажется, не так уж дорого.

Стоимость облачных решений
Но что, если нужно распознать не одну картинку, а, скажем, десятки миллионов? При наших объемах, а это около 50 млн загружаемых изображений в день, нам бы приходилось тратить от 2.5 млн рублей ежедневно. За год получается 1-2 млрд рублей. За такие деньги экономически эффективнее уже сделать самим.
Второе. Все облачные решения изначально создаются для задач распознавания текстов документов. Такой текст не сопротивляется, когда его распознают. А спамерский может выглядеть примерно так.

Спамерский текст с модификациями
Согласитесь, большая разница между распознаванием обычного текста и спамерского?
Спамеры не очень заинтересованы, чтобы их находили, поэтому постоянно модифицируют свои фотографии. Тут, например, почти рукописный шрифт.

Спамерский текст, написанный от руки
Готовые облачные решения не всегда могут правильно распознать такой текст. А постоянно дорабатывать под наши запросы модели, увы, никто не будет.
Третье. Допустим, мы смогли убедить подрядчиков и они начали переобучать свои модели под запросы ОК. Как быстро это будет происходить? Наша практика показывает, что после выхода новой модели в продакшен, спустя сутки (а то и раньше) спамеры уже находят варианты обхода модели. Постоянное дообучение моделей в сторонних сервисах приведет к дополнительному росту денежных затрат, что опять нас возвращает к мысли о том, что дешевле сделать свое.
Все же готовое решение
Но разрабатывать решение полностью с 0 сложно, поэтому мы решили начать с анализа бесплатных готовых решений, которые можно взять и переиспользовать. Рассмотрим одно из них— всем известный Tesseract, «движок» для распознавания текста от Hewlett-Packard, впоследствии выкупленный компанией Google. В первую очередь, он предназначен для распознавания документов, но для обычных картинок его тоже можно применить. Возьмём пример с сайта Tesseract. Справа — распознанный текст, слева — фотография. Видно, что Tesseract распознал корректно.

Пример распознанного текста с помощью Tesseract
Пытаемся распознать изображение, которое содержит спам-фразу «Срочно требуются сотрудники в интернет-магазин». В распознанном тексте также есть нужная фраза. Распозналось все верно.

Результат распознавания простого спам-текста с помощью Tesseract
Идём дальше. На следующем примере текст расположен уже не на всей фотографии, а в углу. Появляется слишком много шума, хотя в целом видно, что необходимый нам текст распознался: «Работа онлайн без вложений. Ставь плюс».

Результат распознавания спам-текста с помощью Tesseract
Неплохо, но шум заставляет задуматься: может, Tesseract не так уж хорош для этой задачи?
Финальный тест — подаем более сложный спам. Картинка почти ничем не отличается, только текст немного повернут.

Результат распознавания сложного спам-текста с помощью Tesseract
Видно, что Tesseract выдает текст, с которым дальше невозможно работать. Спамер может легко обойти такую систему, всего лишь немного поворачивая на изображении баннеры с текстом.
Окей, можно ли теперь решить, что есть инструмент, который отлично обрабатывает прямоугольные баннеры с текстом? Если это так, то никаких проблем. Всё-таки большинство текстов прямоугольные, для них можно использовать Tesseract. На самом деле, не совсем так. В следующем примере в обычном меме Tesseract смог распознать только первую строчку.

Результат распознавания мема с помощью Tesseract
Люди, которые знакомы с этим сервисом, говорят: «Вы его не тюнили, изображение нужно нормализовывать, чтобы текст более чётко отделялся от фона». Да, мы знаем об этом. Но проблема в том, что универсального преобразования нет, нужно подбирать его под каждое фото.
В итоге Tesseract не очень подходит для нашей задачи. Изначально он проектировался только для сканов документов, что и подтвердили наши тесты.
Стали ли мы тащить Tesseract в продакшен? — Да
С учетом вводных, это немного неочевидно. Почему мы так сделали?
В статье “Hidden Technical Debt in Machine Learning Systems” от группы авторов из Google есть отличная иллюстрация на эту тему. При разработке ML решения не нужно забывать о сопутствующие инфраструктуре, необходимой для работы системы в продакшене. Зачастую, её разработка не менее сложная и интересная задача.
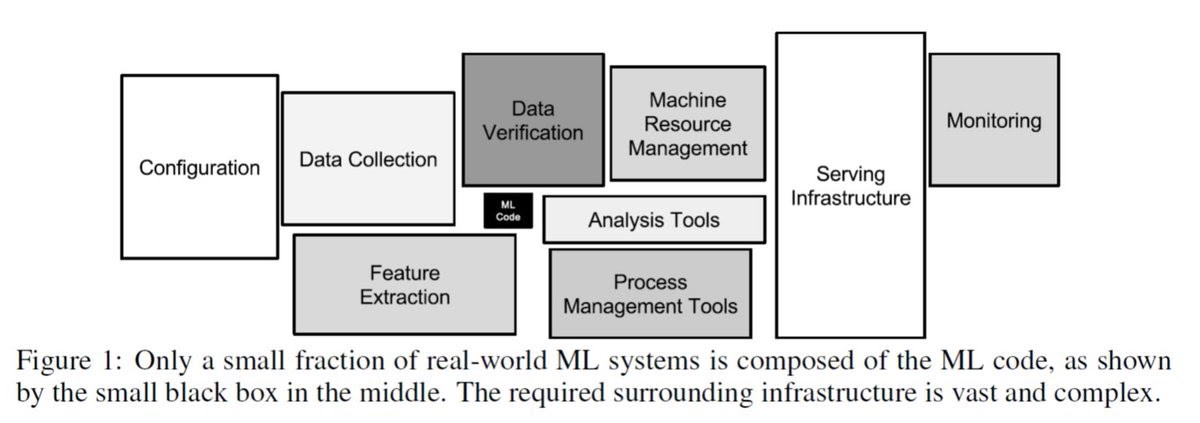
Изображение из статьи “Hidden Technical Debt in Machine Learning Systems”
Поэтому, параллельно с разработкой более совершенной ML-системы мы начали разрабатывать инфраструктуру для её внедрения, чтобы в будущем просто заменить Tesseract в уже работающей системе, приносящей пользу.
Как и ожидалось, в процессе внедрения всплыли некоторые аспекты, о которых изначально не подумали.
Производительность
Основной камень преткновения для использования OCR на большом объеме данных — производительность. OCR обходится недешево. Для инференса нейронных сетей обычно используются видеокарты, но Tesseract работает на CPU и делает это довольно эффективно.
Но оказалось, что для того, чтобы прогонять через Tesseract весь входящий поток, нам бы потребовалось N процессоров(где N это достаточно большое число, которое неприятно было бы выделять на эту задачу) чтобы быстро обрабатывать весь входящий поток изображений.
Кроме того, для нейронной сети, которая делает простую классификацию, мы обычно использовали изображения в небольшом разрешении. Однако, для хорошей работы OCR достаточно критично использовать высокое разрешение. А это дополнительная нагрузка на сеть и CPU.
С помощью пары трюков мы смогли решить эту проблему.
Трюк 1
Помните, мы говорили про 50 млн фото в день? Оказалось, что в общем потоке ежедневных изображений, только каждое четвертое фото содержит текст. Поэтому мы решили предварительно классифицировать изображения на две категории: с текстом и без текста.

Типичное соотношения картинок с текстом к обычным картинкам в ежедневном трафике
Мы сделали это с помощью обычного классификатора, такого же, как для распознавания картинок из датасета ImageNet. У него может быть любая архитектура, мы используем EfficientNet. Важно то, что он работает как фильтр: на вход подается картинка, на выходе имеем вероятность нахождения текста на изображении. Если текст есть, картинка отдается на дальнейшее распознавание.
Пропускная способность всей системы сильно улучшается при условии, что классификатор хорошо определяет картинки с текстом. Мы добились того, что классификатор работает с большим охватом и хорошей точностью (recall 0.95, precision 0.99). Так мы повысили пропускную способность всей системы OCR в четыре раза и теперь нам нужно N/4 процессоров.
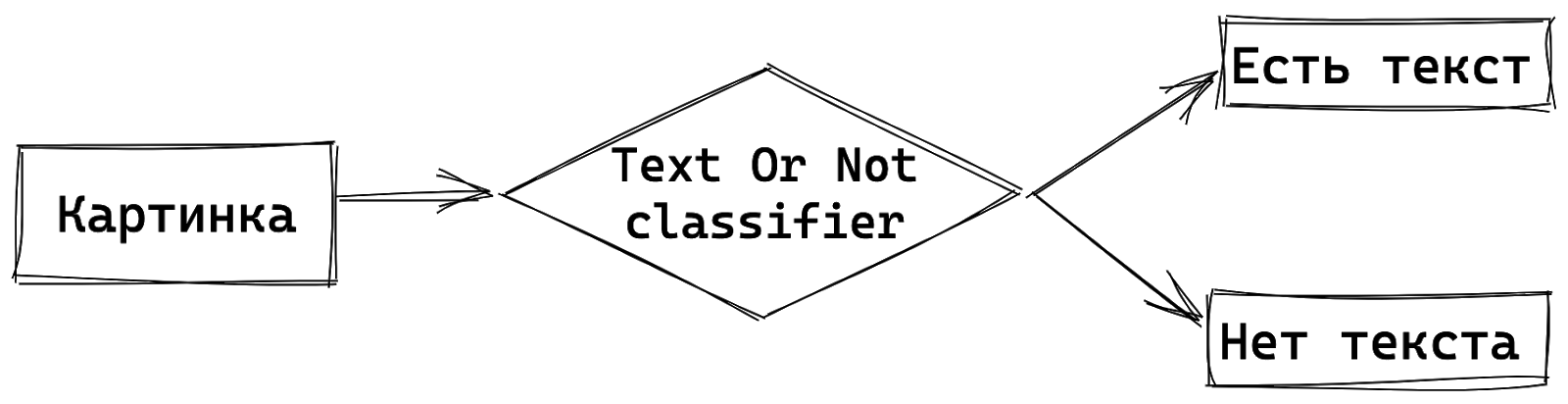
Простая структура с классификатором изображения по наличию текста
Трюк 2
Ниже пример из 5 одинаковых картинок — они тоже передают примерную статистику распределения ежедневного трафика на продакшене ОК. Люди часто грузят неуникальный контент: много раз заливают одно и то же фото в ленту, в сообщества, в комментарии. Только каждая 5-я картинка — уникальна. И если раньше мы уже извлекали из подобной картинки текст и запомнили, что на ней написано «спасибо прадеду за деда», то зачем снова делать то же самое?

Примеры одинаковых изображений в ежедневном трафике
В этой ситуации нам помогли кэши. Каждая картинка подается на классификатор Text Or Not. Если текст есть, то мы распознаем его, если нет — ничего не делаем. Все результаты кладём в кэш, в качестве ключа выступает md5 или phash. Если по какой-то из картинок раньше уже был результат, то не пересчитываем. То есть с использованием этой техники, мы можем снизить кол-во используемых процессоров до N/5.
Итого, комбинируя эти 2 техники, удалось снизить требования по количеству процессоров до N/20, что для нас оказалось приемлемо. Конечно, кэши и обработка всех фотографий еще одной нейронной сетью не бесплатны, но выигрыш по ресурсам оказался существеннее.
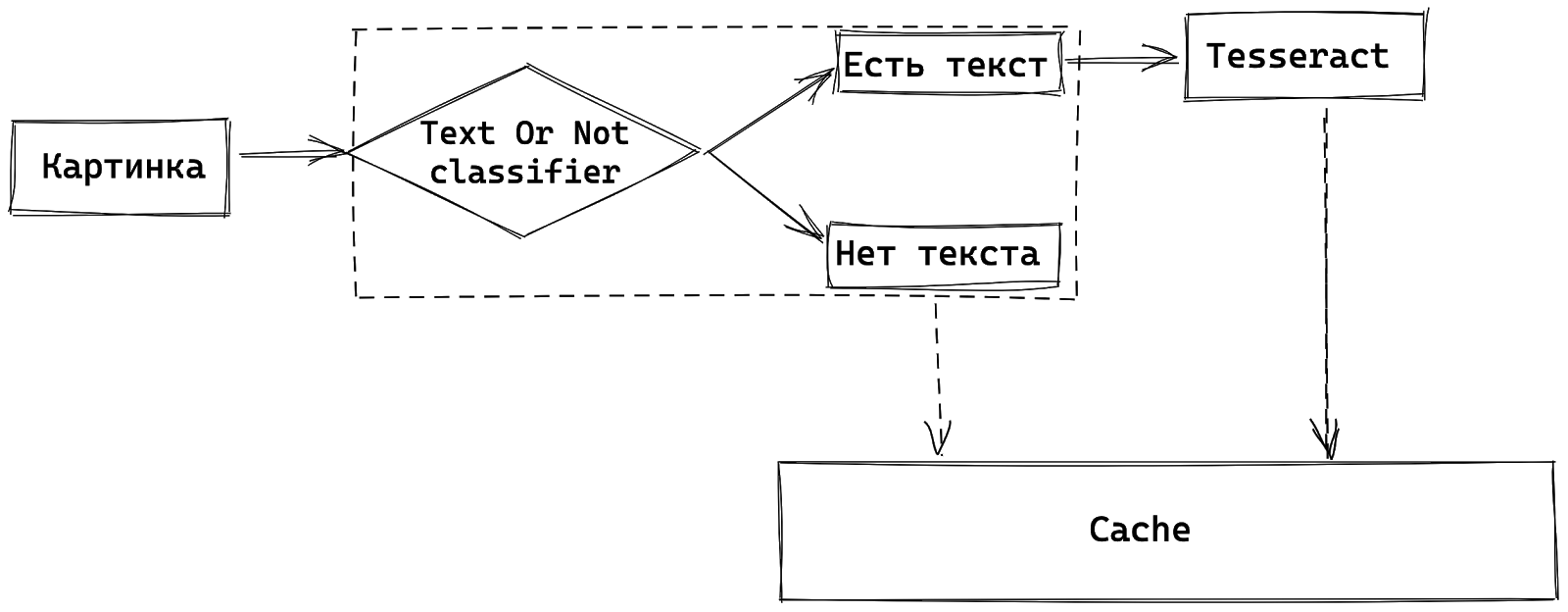
Структура обработки изображения с учетом дедубликации одинаковых картинок
Напомним, что конечная цель классификации — увидеть в изображении спам. Для этого мы используем наши готовые антиспам системы — текстовые классификаторы. Распознанный текст подается на текстовые классификаторы, которые выдают вероятность наличия спама в тексте.
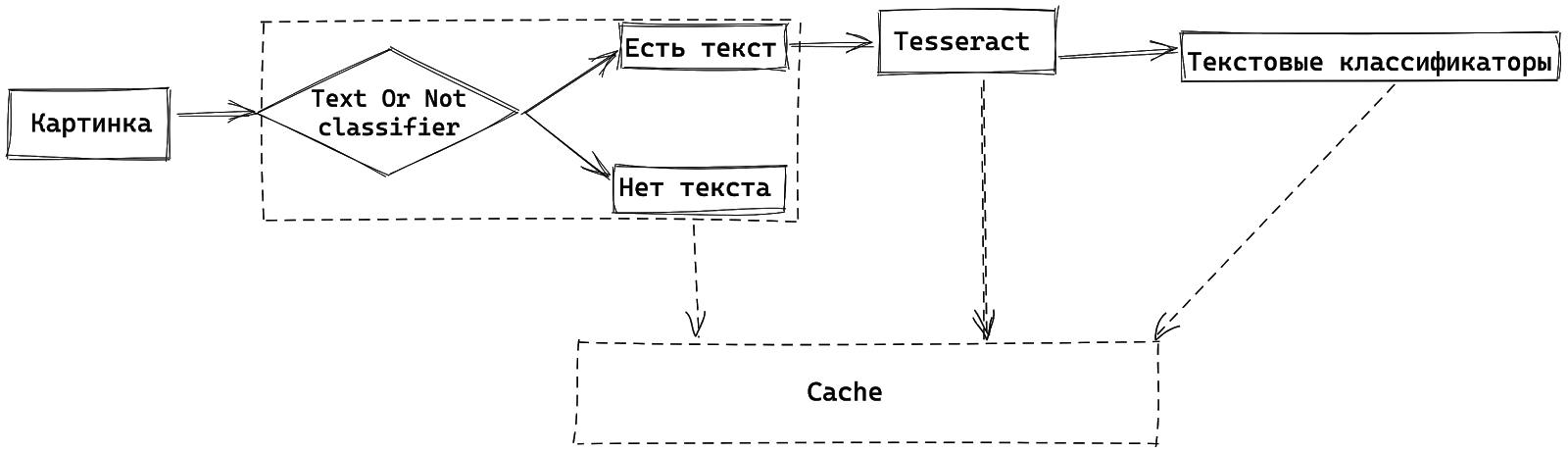
Структура обработки изображения с учетом текстовых классификаторов
Текстовые классификаторы также помогают нам даже определять, что на картинке выделено текстом: анекдот или новости. Но это тема другой статьи.
Хотя наша система теперь достаточно производительна, чтобы обработать все фотографии, она делает это не слишком хорошо(вспоминаем примеры выше). Поэтому, наша следующая цель, это заменить Tesseract на собственную разработку.
Как вообще работает OCR?

Мы ждем от OCR следующего: есть изображение, нужно извлечь из него все слова и по каждому слову распознать, что написано. Для этого обычно выделяют отдельные модели: одна находит и выделяет области, где есть текст. Мы не знаем, что написано, но знаем, где. Другая — распознаёт, что написано в каждой текстовой области.
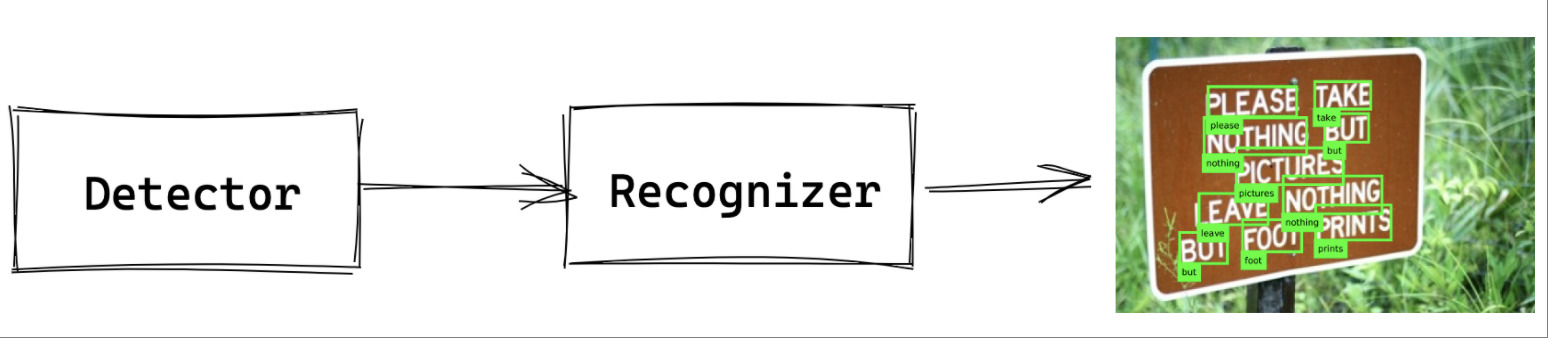
Типовая структура работы OCR-движка
На чем это учить?
ML-модели, как мы знаем, нуждаются в наборе данных для обучения. Для задачи классификации нужны очень простые метки (1 — если представитель этого класса найден, 0 — если нет). А вот для распознавания текста требуется разметка посложнее: множество таких изображений, где для каждого слова выделена область, координаты и есть расшифровка написанного.
Почти ни у кого нет таких данных, особенно на русском. Есть несколько академических наборов, но они небольшие и, преимущественно, на английском (coco-text, focused scene text, incidental scene text). К счастью, в этой области хорошо работает обучение на синтетике. Мы можем действовать по принципу спамеров — брать различные фоны и помещать на них текст, варьируя размеры, шрифты, межбуквенные расстояния, по разному поворачивая текст и т.д.
Так как мы сами генерируем картинки, то мы знаем точные координаты текстовых областей и что в них написано и можем использовать их для обучения ML-моделей.

Простая генерация спам-картинки

Генерация спам-картинки с модификацией букв

Сложная спам-картинка с тонами, фоном и поворотами слов
Так же мы используем более продвинутый метод генерации синтетики — SynthText. В нём применяется ещё одна нейронная сеть, которая предсказывает карту глубины для картинки. Потом некий алгоритм встраивает картинку прямо в изображение лучше, чем мы сами, когда используем более простой код. В итоге у встроенного текста появляется объем.

Всмотрись в картинку и увидишь “Егор года!” :)
Детектор
Итак, у нас уже есть датасет для обучения моделей. Осталось понять, какие модели мы будем учить.
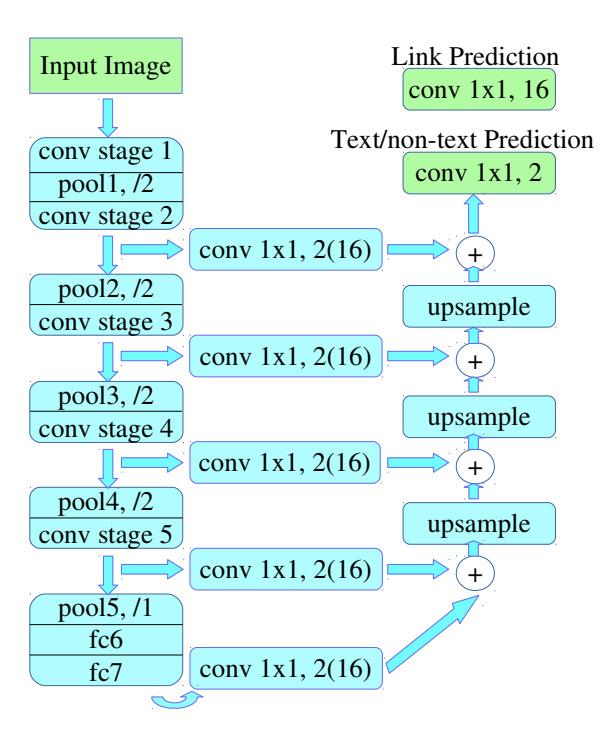
Архитектура PixelLink
Мы выбрали архитектуру PixelLink — представителя сегментационных нейронных сетей, который предсказывает наличие текста для каждого пикселя изображения. Видно, что архитектура очень похожа на обычный Unet. Главное отличие состоит в том, что для каждого пикселя, помимо вероятности “текст или нет”, возвращается вероятность для каждого из его 8/16 (в зависимости от конфигурации) соседей принадлежать к одной текстовой области с ним.
Зачем это нужно? Таким образом решается проблема сливающихся слов. Если нейронная сеть будет предсказывать только один класс, то на этапе постпроцессинга их будет очень сложно отличить друг от друга. В PixelLink мы можем с помощью алгоритма поиска компонент связности на изображении выделить отдельные слова и присвоить им цвет.
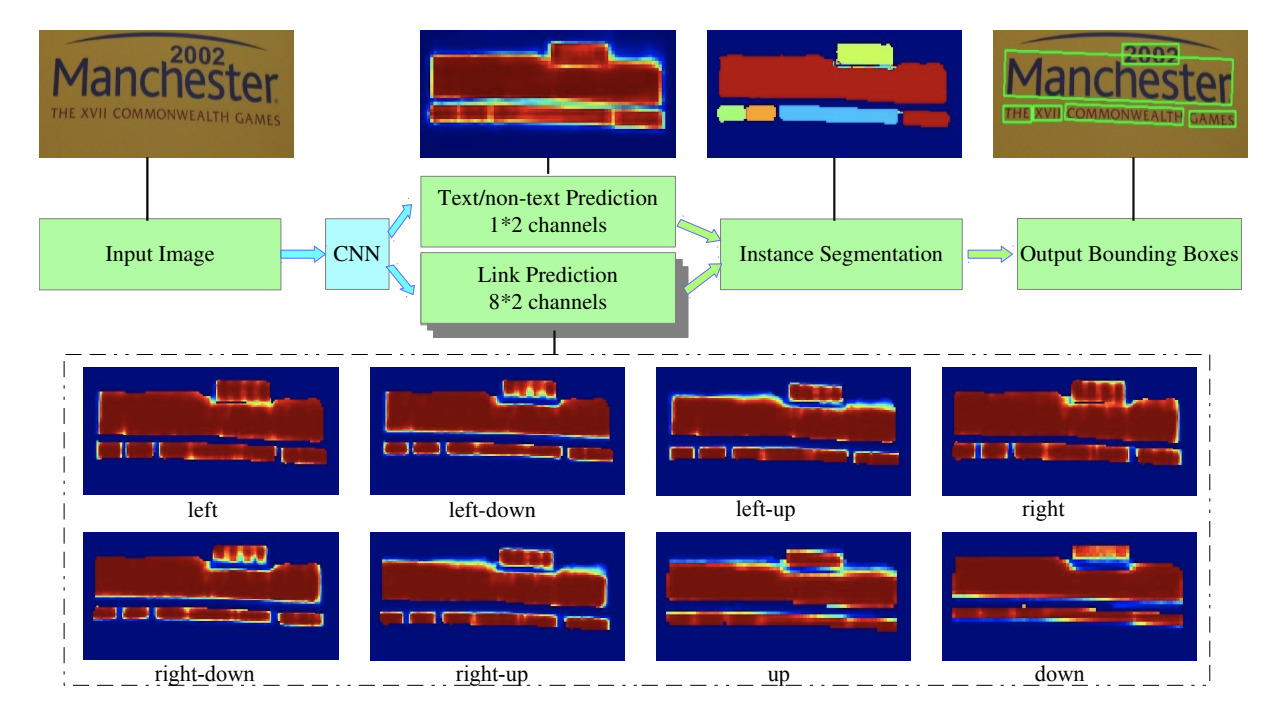
Демонстрация работы PixelLink
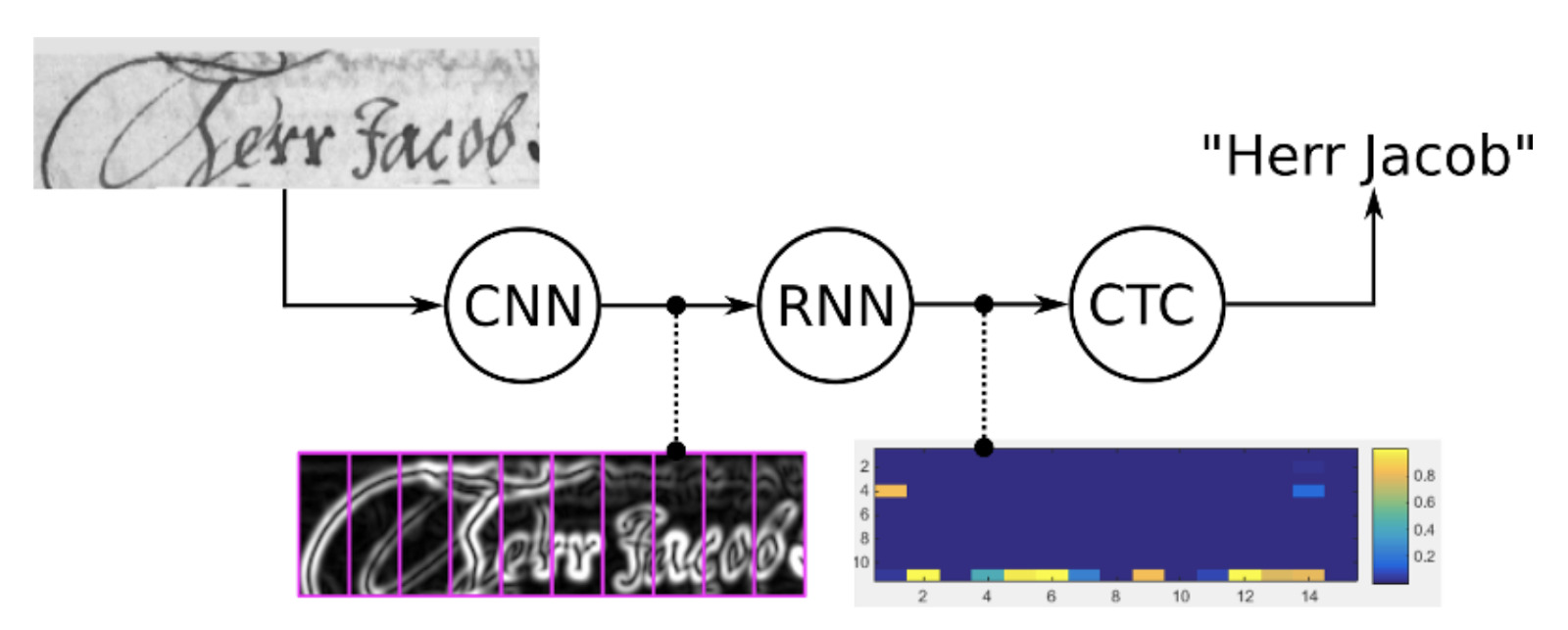
Распознаватель
Сейчас популярным решением является CTC-loss, работающий по принципу End-to-End. Математику, стоящую за этим методом, можно изучить в оригинальной статье. Для обучения достаточно подготовить кроп картинки, содержащий только текст (желательно одно-два слова) и расшифровку к ней, а далее обучать нейросеть, оптимизируя эту (ctc) функцию потерь.
При использовании уже обученной нейросети тоже нужно подавать текстовые области. А на выходе, применив небольшой препроцессинг (Beam Search Decoding in CTC-trained Neural Networks), получаем текст.
Получилась нейронная сеть. Синтетику она распознаёт прилично, точность — 95%.
Теперь нужно вспомнить, что Tesseract уже какое-то время работает в продакшене, и нужно доказать, что его можно безболезненно заменить.
Оценка качества
Мы протестировали работу детектора Tesseract и детектор PixelLink на паре тысяч тестовых примеров. Как мы и подозревали в начале, оказалось, что Tesseract плохо выделяет текстовые области на реальных пользовательских данных, а PixelLink дает высокий MAP и DICE.
Для оценки качества распознавателя и сравнения его с Tesseract мы применили следующий подход:
На сайте Одноклассников есть система для разметки, которая называется «Модератор Одноклассников». Она работает по принципу краудсорса — пользователи соцсети размечают данные и могут выделять текст на фото.
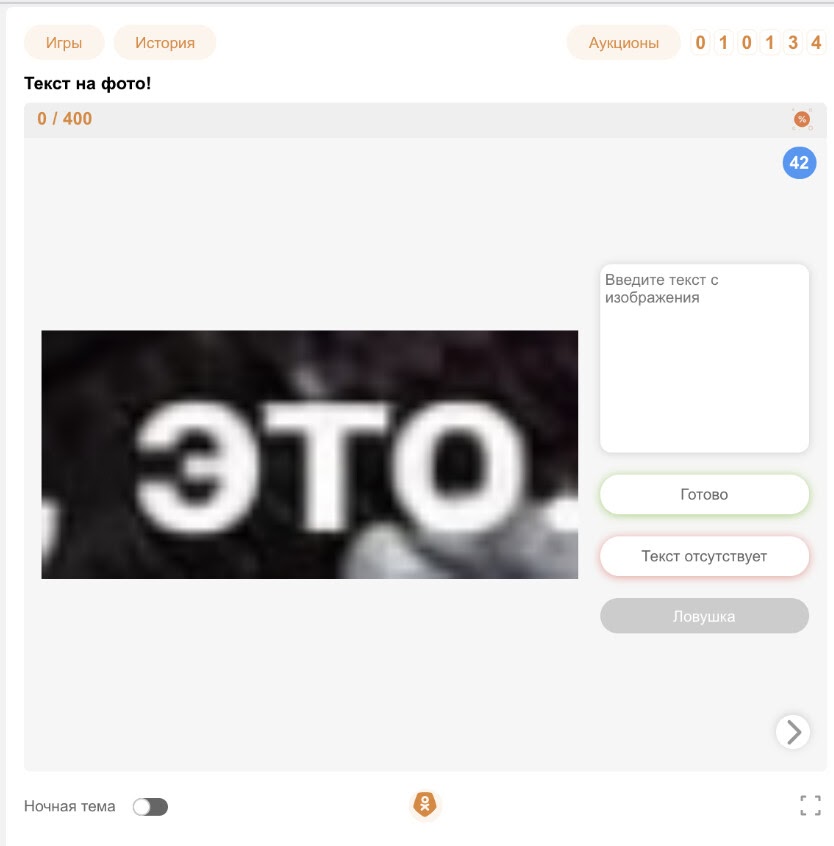
Пример задания “Выдели текст на фото”
Мы выделили очень много кропов (текстовых фрагментов) из продакшен-данных и попросили людей написать, что здесь написано. Получилось собрать много данных, которые потом подавались на вход нашему распознавателю и Tesseract.
Хотя мы использовали самую последнюю версию Tesseract (на момент замера TESSERACT 4.0) с LSTM внутри, он работает для 50% слов, а наша система — 90% слов. Превосходство нашего OCR доказано и значительно, что позволило нам заменить им Tesseract в проде.
Также интересно, что для синтетики качество распознавания составило 95%. Этот показатель говорит нам, что качество на синтетических данных (95%) и реальных (90%) — близко.
Performance is back
Итак, у нас есть решение, которое работает намного лучше и оно состоит из двух компонент: детектор и распознаватель. Но теперь мы сталкиваемся с проблемой быстродействия. Tesseract тратит на обработку 1 изображения около 200 ms на одном cpu ядре и на детектирование и распознавание. PixelLink же только детектирований производит 10 в секунду на целой видеокарте, что гораздо медленнее.
Чтобы запустить это решение в продакшен, нам нужно потратить не сильно больше ресурсов, чем при использовании Tesseract.

Сравнение времени работы детектора и распознавателя в зависимости от типа вычислительного устройства
В задаче ускорения детектора нам помогла обработка данных на CPU с помощью фреймворка от Intel — OpenVINO. Через него мы оптимизировали работу модели нейронной сети, в результате чего детектор стал обрабатывать три картинки в секунду на одном ядре CPU. Процессоров у нас гораздо больше чем видеокарт, поэтому мы запустили детекцию на CPU.
Вариант от Intel
Кстати, у Intel есть готовая реализация PixelLink для детекции текстов, уже сконвертированная под OpenVino. И это стало для нас одной из причин выбрать именно эту архитектуру в качестве основы. Мы обучали ее на своих данных и самостоятельно конвертировали под OpenVINO.
Вторая часть нашей системы — распознаватель. Казалось бы, если мы уже запустили детектор на CPU, то, может, и распознаватель тоже на CPU запустить? Прямо на той же машине, где и детектор. Было бы очень удобно.
Мы применили OpenVINO к распознавателю, получилось примерно 7 картинок в секунду, причём даже не полноценных картинок, а именно кропов. Без OpenVINO работало ещё в десять раз медленнее, но такой вариант нас всё равно не устраивает.
К счастью, постпроцессинг там не такой тяжёлый. Поэтому мы запустили распознаватель на видеокарте с использованием технологии TensorRT. Это инструмент от Nvidia, который оптимизирует наши нейронные сети для видеокарт от Nvidia. Это ускорило распознавание до 700 кропов в секунду.
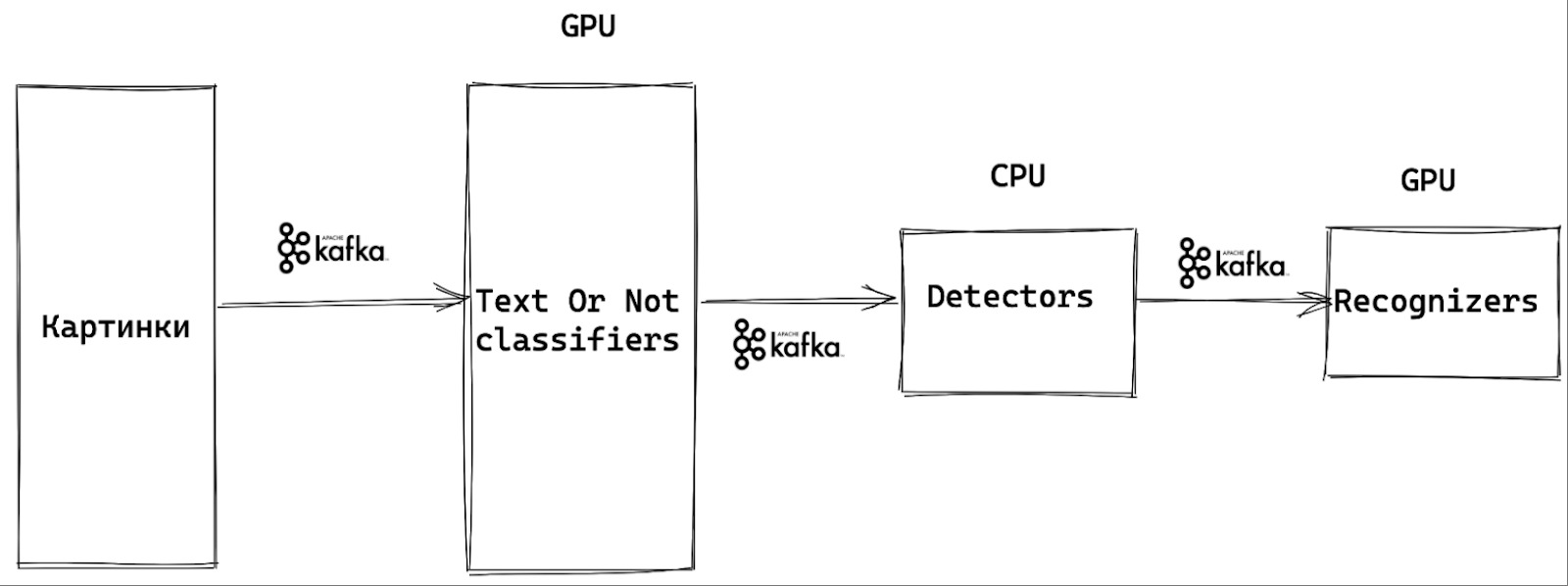
Высокоуровневая архитектура системы распознавания текста с картинки
В итоге, высокоуровневая архитектура всей системы выглядит так. Мы отправляем картинки через Kafka в классификатор Text Or Not. Если классификатор говорит, что текст есть, изображение передается на детекторы, которые определяют, где текст расположен. Причём детекторы запущены на серверах, где есть только CPU.
Дальше отправляем результат на сервера с GPU, где работают распознаватели. Полученные данные и пропускаем через текстовые классификаторы.
Одну картинку мы обрабатываем медленнее, потому что часть времени тратится на передачу по Kafka. Но зато миллион картинок мы обрабатываем гораздо быстрее (throughput vs latency). Также мы можем масштабировать каждый компонент этой системы по отдельности для повышения производительности.
Примеры распознавания
Посмотрим на примеры работы распознавателя.
Начнем с мема, с которым Tesseract не справился. Теперь мы с ним справляемся и умеем распознавать юмор.
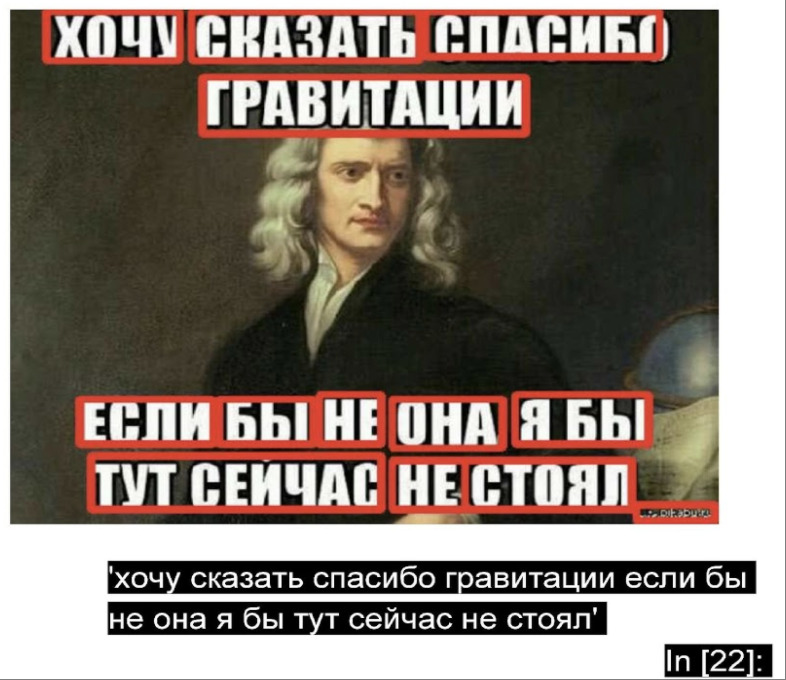
Результат распознавания текста с мема
Хоть Новый год и прошел, узнать рецепт праздничного салата пользователей Одноклассников нам всё равно удастся.

Результат распознавание рецепта с картинки
Умеем распознавать даже более сложные картинки, где фотография целиком повёрнута.

Результат распознавания текста с картинки книги
Теперь спамерский текст. Тоже распознаём. Замечательный эффект. Мы начали бороться со спамерами, и они вынуждены делать всё более сложные картинки, которые уже и людям нелегко читать. А чем сложнее прочесть их креативы, тем меньше у спамеров профита.

Результат распознавания текста со спамерской картинки
Применение OCR в других сервисах
Но OCR нашёл применение не только в Одноклассниках.
В «Ситимобил»: для осуществления задачи по фотоконтролю такси — распознаем госномер автомобиля на фото. Распознанные данные сравниваются с данными в карточке водителя. Таким образом мы определяем правильная машина пришла на контроль или нет.

Результат распознавания ГОС номера. Автомобиль Вина Дизеля из фильма “Вавилон Н.Э.”
В сервисе для объявлений «Юла»: с помощью OCR мы находим лекарственные препараты, которые запрещены к продаже на Юле. Для этого распознанный текст сравнивается со справочником лекарственных средств. Кроме того, мы определяем номера телефонов, ссылки на сторонние сайты, ник Инстаграма и т. д.

Примеры товаров Юлы, автоматически категоризируемых с помощью OCR
Для рекламной платформы myTarget: мы группируем рекламные баннеры по наличию одинакового текста на изображении. Это позволяет сократить количество ручной модерации, а также использовать текстовые классификаторы для определения рекламы низкого качества.

Что в итоге
Мы справились с поставленной задачей. Что получилось:
- Полноценный масштабируемый сервис не только для распознавания текста, но и с возможностью последующей автоматической обработки того, что мы распознали.
- Архитектура решения позволяет быстро обучаться на новые типы/форматы/модификации текста.
- Сервис можно использовать не только в наших целях борьбы со спамом, но и в любых продуктовых задачах, где нужен текст с картинки (например, рекомендации).
- Экономически, разработка своего решения обошлась нам в сотни раз дешевле, чем если бы купили готовый вариант на рынке.
Какие проблемы остались:
- Модель тренировалась только на русском и английском языках. Для других текстов необходимо отдельное обучение;
- Рукописный текст сложен для распознавания. Для работы с ним необходимо использовать дополнительные трюки и дообучать модель.
