 Чтобы сделать мониторинг полезным, нам приходится прорабатывать разные сценарии вероятных проблем и проектировать дашборды и триггеры таким образом, чтобы по ним сразу была понятна причина инцидента.
Чтобы сделать мониторинг полезным, нам приходится прорабатывать разные сценарии вероятных проблем и проектировать дашборды и триггеры таким образом, чтобы по ним сразу была понятна причина инцидента.
В некоторых случаях мы хорошо понимаем, как работает тот или иной компонент инфраструктуры, и тогда заранее известно какие метрики будут полезны. А иногда мы снимаем практически все возможные метрики с максимальной детализацией и потом смотрим, как на них видны те или иные проблемы.
Сегодня будем смотреть как и почему может распухать Write-Ahead Log (WAL) постгреса. Как обычно — примеры из реальной жизни в картинках.
Немного теории WAL в postgresql
Любое изменение в базе данных в первую очередь фиксируется в WAL, и только после этого изменяются данные в странице в buffer cache и она помечается как dirtied — нуждающаяся в сохранении на диск. Кроме того периодически запускается процесс CHECKPOINT, который сохраняет на диск все dirtied страницы и сохраняет номер сегмента WAL, вплоть до которого все измененные страницы уже записаны на диск.
Если вдруг postgresql по какой-то причине аварийно завершится и запустится снова, в процессе восстановления будут проигрываться все сегменты WAL с момента последнего checkpoint.
Сегменты WAL предшествующие чекпоинту нам уже не пригодятся для поставарийного восстановления БД, но в постгресе WAL также участвует в процессе репликации, а еще может быть настроено резервное копирование всех сегментов для целей Point In Time Recovery — PITR.
Опытный инженер уже наверное всё понял, как оно ломается в реальной жизни:)
Давайте смотреть графики!
WAL распух #1
Наш мониторинговый агент для каждого найденного инстанса постгреса вычисляет путь на диске до директории с wal и снимает как суммарный размер, так и количество файлов (сегментов):
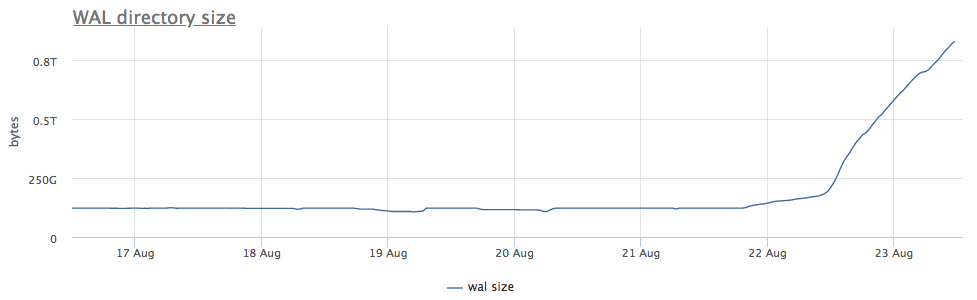
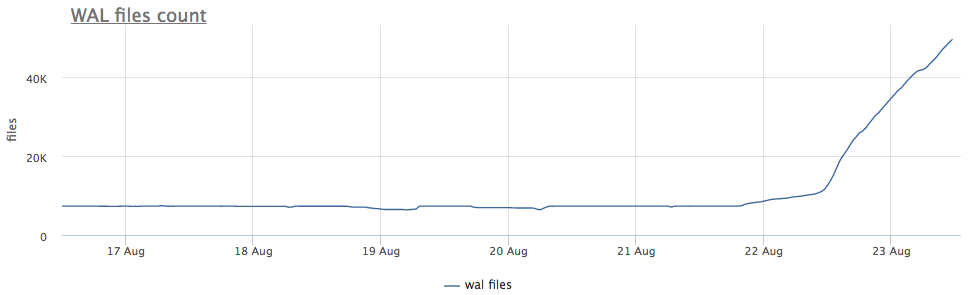
Первым делом смотрим, как давно у нас запускался CHECKPOINT.
Метрики берем из pg_stat_bgwriter:
- checkpoints_timed — счетчик запусков чекпоинтера, произошедших по условию превышения времени с последнего чекпоинта более чем на pg_settings.checkpoint_timeout
- checkpoints_req — счетчик запусков чекпоинтера по условию превышения размера wal с последнего чекпоинта
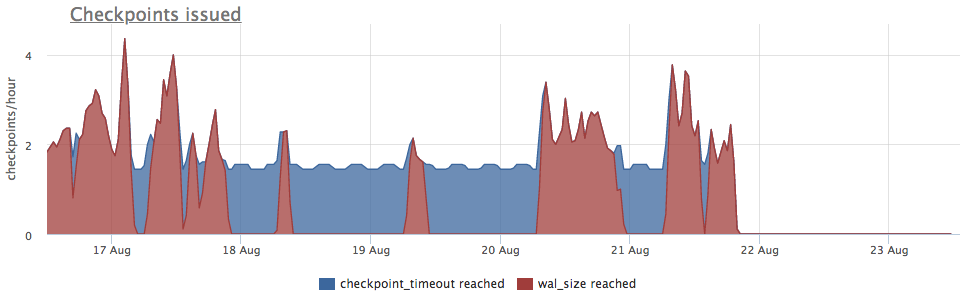
Видим, что checkpoint давненько не запускался. В данном случае напрямую понять причину НЕзапуска это процесса невозможно (а было бы круто конечно), но мы то знаем, что в постгресе очень много проблем возникает из-за длинных транзакций!
Проверяем:

Дальше понятно, что делать:
- убивать транзакцию
- разбираться с причинами, почему она долгая
- ждать, но проверить, что места хватит
Еще один важный момент: на репликах, подключенных к данному серверу, wal так же распух!
WAL archiver
По случаю напоминаю: репликация не бэкап!
Хороший бэкап должен позволять восстановиться на любой момент времени. Например, если кто-то "случайно" выполнил
DELETE FROM very_important_tbl;То у нас должна быть возможность восстановить базу на состояние ровно перед этой транзакцией. Это называется PITR (point-in-time recovery) и реализуется в postgresql периодическими полными бэкапами базы + сохранением всех сегментов WAL после дампа.
За резервное копирование wal отвечает настройка archive_command, постгрес просто запускает заданную вами команду, и если она завершается без ошибки, сегмент считается успешно скопированным. Если получилась ошибка — будет пробовать до победного, сегмент при этом будет лежать на диске.
Ну и в качестве иллюстрации — графики сломанной архивации wal:
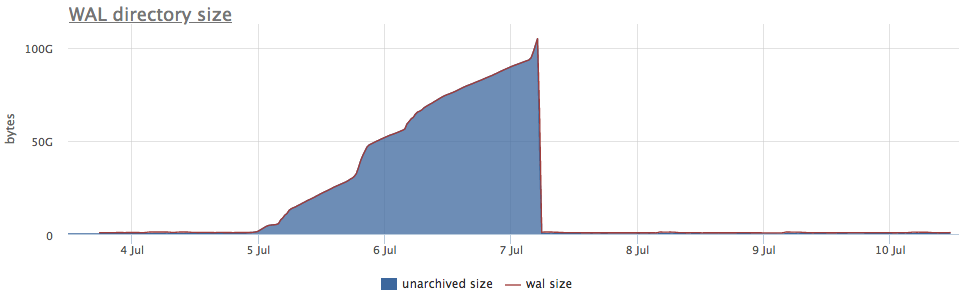
Здесь помимо самого размера всех сегментов wal, есть unarchived size — это размер сегментов, которые еще не считаются успешно сохраненными.
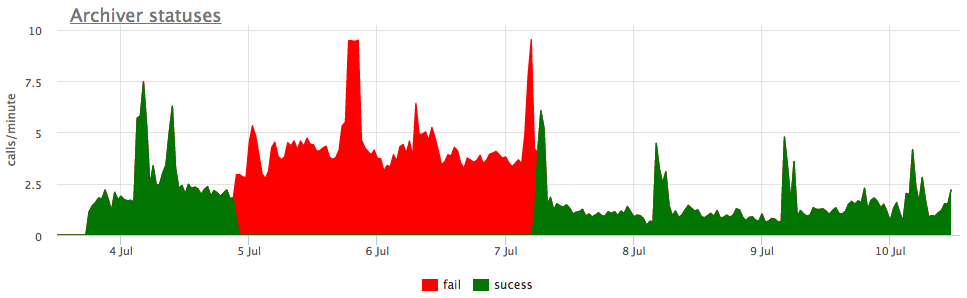
Статусы считаем по счетчикам из pg_stat_archiver. На количество фэйлов мы сделали автотриггер для всех клиентов, так как оно достаточно часто ломается, особенно когда в качестве места назначения используется какое-то облачное хранилище (S3 к примеру).
Replication lag
Streaming replication в посгтресе работает через передачу и проигрывания wal на репликах. Если по каким-то причинам реплика отстала и не проиграла какое-то количество сегментов, мастер будет хранить для нее pg_settings.wal_keep_segments сегментов. Если реплика отстанет на бОльшее количество сегментов, она больше не сможет подключиться к мастеру (придется наливать заново).
Для того, чтобы гарантировать сохранение любого нужного количества сегментов, в 9.4 появился функционал слотов репликации, о котором речь пойдет дальше.
Replication slots
Если репликация настроена с использованием replication slot и к слоту было хотя бы одно успешное подключение реплики, то в случае, если реплика пропадает, постгрес будет хранить все новые сегменты wal до тех пор, пока не кончится место.
То есть забытый слот репликации может быть причиной распухания wal. Но к счастью мы можем мониторить состояние слотов через pg_replication_slots.
Вот как это выглядит на живом примере:
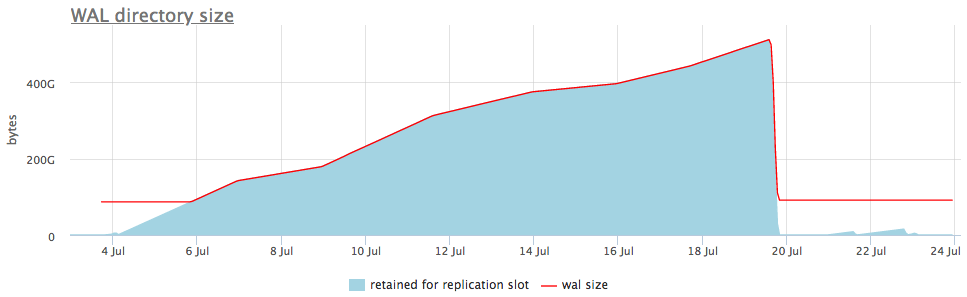

На верхнем графике мы рядом с размером wal всегда отображаем либо слот с максимальным количеством накопленных сегментов, но так же есть детальный график, который покажет какой именно слот распух.
После того, как мы поняли, что за слот копит данные, мы либо можем починить связанные с ним реплики, либо просто его удалить.
Я привел самые распространенные случаи распухания wal, но уверен есть и другие кейсы (баги в постгресе тоже иногда встречаются). Поэтому важно мониторить размер wal и реагировать на проблемы раньше, чем кончится место на диске и база перестанет обслуживать запросы.
Наш сервис мониторинга уже всё это умеет собирать, правильно визуализировать и алертить. А еще у нас есть on-premises вариант поставки для тех, кому облако не подходит.
