
Сергей Пузырёв (Mail.Ru Group)
Меня зовут Сергей Пузырев, я системный администратор в Mail.ru, я занимаюсь проектом «Поиск». Да, на удивление, у Mail.ru есть поиск. Я люблю сервисы, которые не требуют внимания. Я системный администратор, и я не люблю работать системным администратором очень много, я люблю делать так, чтобы работы было меньше, поэтому одно из решений, которое мы пытаемся использовать в своей работе, я вам опишу.
Сначала я скажу пару слов о том, что такое сервис-ориентированная архитектура.

Достаточно большие веб-приложения можно строить с помощью комбинаций из большого количества небольших, достаточно простых по своей сути сервисов, которые общаются друг с другом. Это немного похоже на Unix, только это не в пределах одного компьютера, это в пределах приложения. И принципы здесь почти что те же самые, т.е. приложения должны делать мало вещей, но должны делать их хорошо. Они не должны быть сильно связаны друг с другом, они должны использовать более-менее стандартные процедуры связи друг с другом.
Приложения не должны знать, кто ими пользуется. Соответственно, если мы используем storage статики, то storage’у статики не важно, что в нем лежит – видео, картинки, что угодно, его задача просто хранить блобы и отдавать блобы, больше он не делает ничего, и слишком умным он быть не пытается.
Точно так же, как в Unix, клиенты не должны ничего знать о сервисах, о том, как сервисы устроены. Опять же, если мы используем сервис storage’а статики, то мы просто в него заливаем. Storage статики – это вещь сложная, но клиента это не волнует, клиент хочет положить блоб и хочет забрать блоб, где оно там ляжет, сколько там будет факторов репликаций, как это будет – синхронно, асинхронно между дата-центрами, как оно будет восстанавливаться в случае аварии, – их, вообще, это не волнует, они хотят просто ни о чем не думать. Разработчики тоже не хотят ни о чем думать, т.е. концепт слабосвязанных сервисов позволяет не беспокоиться о внутреннем устройстве других компонентов и из-за этого разработчику проще. И разработчики тоже такие же люди, как мы, они тоже не хотят думать слишком много.
Возможно, четвертый пункт кажется немного очевидным, но слабосвязанные сервисы, тем не менее, друг с другом взаимодействуют и пользуются друг другом.
Давайте посмотрим на то, что такое сервис.

Когда я употребляю слово «сервис», я имею в виду более-менее изолированное приложение, у которого есть три обязательные части. Ну, обязательных частей у него две, третья – опциональная.
- Во-первых, должен существовать протокол общения с сервисом, т.е. то, какой сервис он оказывает. Это ключевой момент, сам сервис характеризуется протоколом, а не тем, как он внутри устроен.
- В нашем случае, конкретно в нашем проекте так исторически сложилось, что все сервисы, по большей части, сетевые сервисы работают поверх TCP протокола, не поверх каких-то вышележащих протоколов (так получилось, что у нас есть самописные вышележащие протоколы, но в контексте рассматриваемого доклада это не очень существенно). Соответственно, у каждого сервиса есть точка входа. В нашем случае это всегда пара IP+port. В общем случае у сервиса, сейчас это особенно модно со всякими архитектурами наподобие REST, это чаще всего http точки входа, но не ими едиными, потому что сервис – это совсем не обязательно http-сервис.
- И сервисы могут пользоваться друг другом. Здесь мы приходим к самому важному элементу, о чем собственно весь доклад, – когда один сервис хочет воспользоваться другим сервисом, этот сервис должен знать, где другой сервис найти, и эту информацию необходимо ему как-то сообщить.
Какие у нас есть простые сервисы?
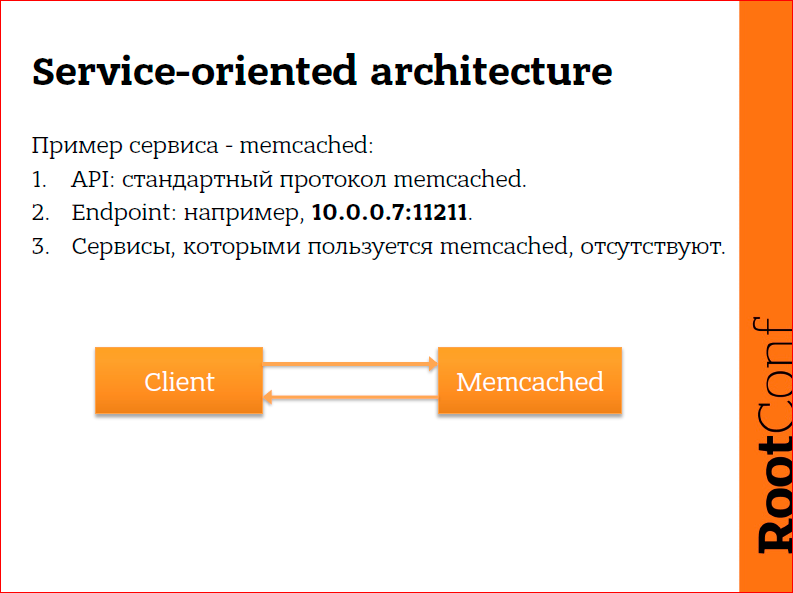
Например, у нас есть совершенно тупучий сервис – memcached. Я думаю, им пользовались все. Он работает по протоколу memcached, у него всегда есть IP-адрес и порт, и сам он ничем не пользуется, он просто запустился, слушает порт и работает, больше он ни о чем не думает. Клиент с ним общается, клиенту нужно просто знать, куда постучаться по TCP или по UDP. Memcached, кстати, работает по UDP, иногда это может быть удобно. И ничего сложного.
Сервис чуть-чуть посложнее.
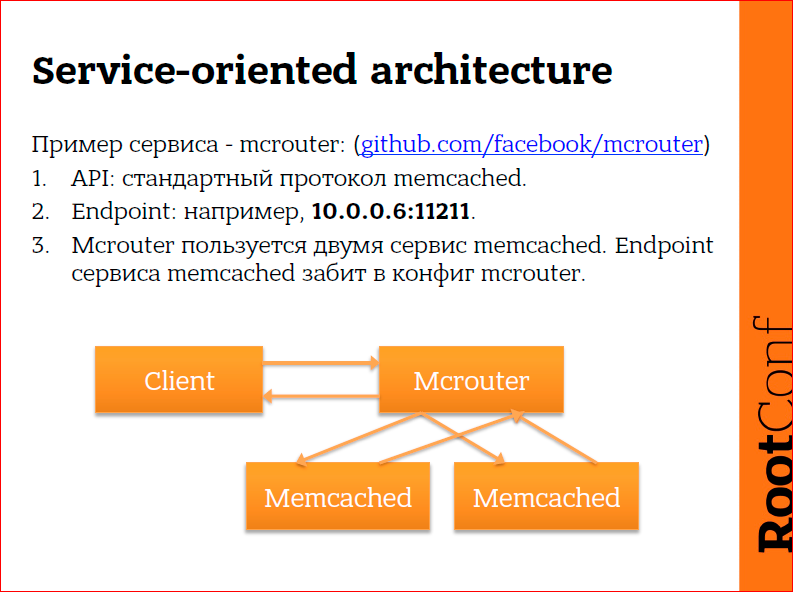
Клиент хочет отказоустойчивый memcached. Существует такая штука как mcrouter, ее разработала копания Facebook. Mcrouter позволяет, например, реплицировать записи, которые идут в mcrouter в два разных бэкенда memcached. Клиент в этом случае общается с mcrouter по протоколу memcached и, опять же, он ничего не знает о том, как mcrouter устроен дальше, его не волнует, сколько там memcached, он просто хочет общаться с memcached сервисом, который будет отказоустойчивым. Mcrouter, в свою очередь, знает, где у него есть два бэкенда memcached, и он реплицирует туда данные. Клиент ничего не знает о memcached, а mcrouter должен знать о memcached, но при этом клиент должен знать, где находится mcrouter, а mcrouter должен знать, где находятся memcached. Т.е. здесь у нас уже три места, которые необходимо сконфигурировать:
- клиент должен найти mcrouter,
- mcrouter должен найти первый memcached ,
- mcrouter должен найти второй memcached .
Пойдем дальше.

Такая архитектура, на самом деле ничего особенного, это любой средний php сайт. Nginx, несколько php нод, storage статики, часто он внешний, MySQL master, MySQL slave, под mcrouter (просто я люблю mcrouter, поэтому так с ним получилось), часто используется один memcached сервер и балансировка изнутри php. Но, тем не менее, в таком на самом деле несложном сервисе, который состоит из пары-тройки серверов физических, у нас наблюдаются уже 16 мест, которые необходимо сконфигурировать – nginx должен знать о php, он должен знать о том, где находится memcached вместе с mcrouter, nginx должен знать, где находится static storage… Я дальше не буду читать картинку, мы можем посчитать количество связей между сервисами и посмотреть, сколько мест необходимо сконфигурировать, и убедиться, что их здесь 16. А у нас всего лишь простой php сайт.
Что же мы будем делать, когда у нас будет сложное приложение?

Эта картинка не моя. У меня есть OpenStack в работе, мы его используем, и он действительно достаточно сложный. Картинка гуглится по запросу «OpenStack diagram», можете сами посчитать, сколько здесь мест необходимо сконфигурировать. На самом деле, тут есть небольшие читы, потому что подходы, которые я рассказываю в этом докладе используются в OpenStack, но, тем не менее, там сильно нетривиально и со временем конфигурировать утомляет. Делать-то что? Я не знаю.
Сначала мы хватались за головы, потом мы начали думать, как решать эту проблему. Как сервисам рассказывать, как им общаться друг с другом.

Самый простой путь – мы просто берем конфиги и записываем в них, где находятся сервисы, которыми хочет пользоваться наш сервис. Т.е. в примере с mcrouter, мы забиваем в конфиг mcrouter’а адреса memcached. Очень быстро, очень легко, вообще ничего не нужно. Т.е. пошли, наконфигурили, рестартнули, работает. Нам больше ни о чем не надо думать. Пока у нас два физических сервера, у нас все хорошо. Даже когда у нас 30 физических серверов, нам почти нормально, они у нас вылетают раз в два месяца, и ничего у нас не происходит. Когда у нас 3000, у нас начинаются проблемы, потому что они никогда не работают все вместе. Все время несколько штук лежит, все время они какие-то сломанные, где-то стойка упала по сети, где-то сервер выломался, где-то какой-то сервер надо выломать и т.п., и начинается паника. Это момент №1.
Момент №2 – из-за того, что у нас в конфигах куча IP-адресов и непонятных портов, все время непонятно. Ты заходишь в конфиг и смотришь: что за фигня? А там цифры и ничего не понятно. Приходиться держать документацию, а документация имеет свойство отставать от реальности. И посреди ночи у тебя сломалось приложение, ты идешь, пытаешься понять, что за фигня, ничего не находишь, материшься, потом кое-как чинишь, плачешь… Есть некоторые проблемы.
Третий момент – когда у вас есть сервис, которым пользуются 1000 других сервисов, и он внезапно меняет, например, свой endpoint (точку входа), вам необходимо переконфигурить аж 1000 сервисов, чтобы они теперь ходили в другое место. И это больно, потому что больно переконфигурить 1000 мест. Это тяжело, в принципе, хоть какую архитектуру вы будете использовать.
Поэтому тривиальное решение – давайте вместо IP-адресов использовать DNS.

Очень легко. Тут особой разницы нет, просто место, которое мы исправляем, место, в которое мы будем вносить изменения, пытаемся переместить из конфига демона, которым мы пользуемся, в DNS-зону.
Мы, как бы, часть проблемы решаем, а часть проблемы мы таким путем создаем. Потому что все равно требуется документация, которая будет отставать от реальности. У нас это будет лучше работать, чем IP-адреса в большом проекте, но незначительно лучше, потому что никакой связи с реальностью, с тем, что сейчас работает, а что не работает, в конфигах самостоятельно появляться не будет. У вас так же будут падать стойки, и вам необходимо будет идти и исправлять где-то вручную, если софт не приспособлен с этим жить. А софт часто не приспособлен с этим жить, особенно, когда софту 10 лет. Например, в случае с mcrouter и несколькими memcached, бэкендами, особенно тяжело добавлять новые инстансы memcached. Или, например, вы хотите уже репликацию не два, а три, и вы никак не можете только правкой DNS’ов исправить ситуацию. Вам все равно надо идти и править конфиг и, возможно, не в одном месте, а потом еще где-нибудь править конфиг. И те же самые проблемы. Когда серверов мало, никаких проблем нет, когда много, тогда проблемы есть.
В-четвертых, DNS – это из коробки, он априори асинхронный, он никогда не может быть синхронным, мы не можем внести изменения в DNS и получить по щелчку, чтобы нам стало хорошо. Нет, даже при TTL=60 сек. у нас может быть доплыв этой информации до демонов несколько минут. Поэтому DNS нам тоже не очень подходит. У нас еще и такая проблема есть. Потому что на сотни сервисов нормально DNS работает, на тысячи – уже плохо.

Мы все говорим, что используем системы управления конфигурацией, это модно. Но часто, к сожалению, видно, что они не используются. Казалось бы, нас спасет, но не все так хорошо, потому что система управления конфигурацией, опять же, на большом проекте решает проблемы, но проблема, о которой я говорил, это не та проблема, которая решается системой управления конфигурацией, т.к. раскатка системы и конфигурация на тысячи машин занимает много времени. Константин из Mail.ru докладывал о том, как у них работает Puppet, можете поинтересоваться, сколько у них занимает раскатка на все. Это даже не минуты, это скорее часы, и поэтому мы опять не можем быстро реагировать на изменения в инфраструктуре. Это момент №1.
Момент №2. Учитывая, что система управления конфигурацией – это часто куча шаблонов и куча структурированной информации, при неправильно организации шаблонов заранее вы можете получить проблемы при расширении. Т.е. для того, чтобы вам какое-то, кажется, банальное место изменить, которое при хардкоде endpoint’ов в конфигах вы смогли бы исправить очень быстро, вам придется переписывать шаблоны, тестировать шаблоны, тестировать это в dev-окружении, потом выкатывать в продакшн. И вы на простую процедуру увеличения количества бэкендов с двух до пяти потратите полдня работы. Поэтому, к сожалению, системы управления конфигурацией тоже не полностью решают эту задачу.

Мне кажется, что основная проблема здесь в том, что ко всей этой штуке привлечен человек, который коммитит, который конфигурирует. Это все неправильно. Фактически у нас роботы ломаются, роботы друг друга эксплуатируют. Мне кажется, мы там лишние. Давайте посмотрим, что мы можем сделать.

Существуют системы обнаружения сервисов, они характеризуются несколькими вещами. Во-первых, мы вводим две концепции – сервис может регистрироваться в системе обнаружения сервисов, в этом случае он стартует и регистрируется. После этого другой сервис, который хочет попользоваться сервисом, который у нас только что зарегистрировался, идет в систему обнаружения сервисов и спрашивает: «А есть ли у тебя такой сервис, и где он, если он у тебя есть?». Система обнаружения сервисов ему говорит: «Смотри, у меня есть вот такой», и сервис, который хотел узнать, куда ему сходить, узнал и пошел, куда ему нужно. Или не пошел, если не смог.
Это очень похоже на DNS, но это не совсем DNS, скорее, это совсем не DNS. Так получилось, что исторически система обнаружения сервисов (их достаточно много, снизу список из нескольких штук, которые в принципе существуют) также часто работают как средства распределенной блокировки, и использовать их, соответственно, необходимо с учетом этого.
Я немного расскажу конкретно о том стеке софта, о котором пойдет дальше речь. Что такое Etcd? Etcd – это специальное хранилище данных, которое строго консистентное, транзакции в нем выполняются только на всем кластере сразу, точнее, на кворуме кластера, и поэтому они строго сериализованы. Нельзя внести изменения в кластер, когда у нас нет кворума ни в одной половине, это невозможно. Etcd работает по алгоритму Raft. Алгоритм Raft – это взгляд на Паксос, если кто-нибудь слушал про Паксос, и попытка сделать Паксос более простым. К сожалению, Raft все равно остался достаточно сложным, поэтому я оставлю его описание за пределами этой конференции, это просто слишком долго. Но, тем не менее, как работает etcd? На каждом сервере у нас запущен etcd -демон, который связывается с остальными etcd-демонами с помощью первичного входа. Т.е. мы на каждом сервере запускаем etcd, и мы должны указать хотя бы один уже находящийся в кластере etcd, дальше они сами друг друга найдут. Эта вся магия зашита в etcd. И в следующий раз они уже будут знать, как им стартовать. И когда нам будет необходимо пообщаться с системой обнаружения сервисов, а именно etcd, мы всегда будем общаться с локальной петлей. Т.е. etcd всегда сложит локальную петлю на любом сервере, который у нас, в принципе, есть.

Следующий кусочек мозаики – это Confd. Confd – это слушалка etcd, т.е. etcd хранит ключи и позволяет эти ключи изменять. Confd позволяет подцепиться к ключу и отслеживать изменения в etcd. Делается это через http long polling, т.е. сonfd фактически представляет собой http-клиент, а etcd – это http-сервер. Confd спрашивает у etcd: «Смотри, есть такой ключ, я хочу за ним следить», и вешается в long polling. Как только в etcd кто-то другой этот ключ записал или изменил, или удалил, апдейтнул, что угодно – etcd обрывает соединение и дает ответ. Поэтому реакция происходит очень быстро. Т.е. если происходит транзакция, то подключенный confd сразу же об этом узнает. Т.о. etcd используется как шина сообщений.
Confd умеет реагировать на изменения в etcd и что-либо запускать. Изначально он был приспособлен для того, чтобы брать данные из etcd, шаблонизировать, подкладывать конфиг и рестартить демон. Но по факту, он может просто дергать какой-то скрипт, который будет делать более сложную логику, если то, что можно запихать в confd, само по себе не работает. И учитывая, что etcd – это просто http, с ним вполне можно жить, общаясь fget’ом или любым другим вашим любимым http-клиентом, на Python’е, на чем угодно. Можно писать эти маленькие скрипты на чем угодно, не использовать confd, если его логика вам не подходит. Просто мы его использовали, так получилось.
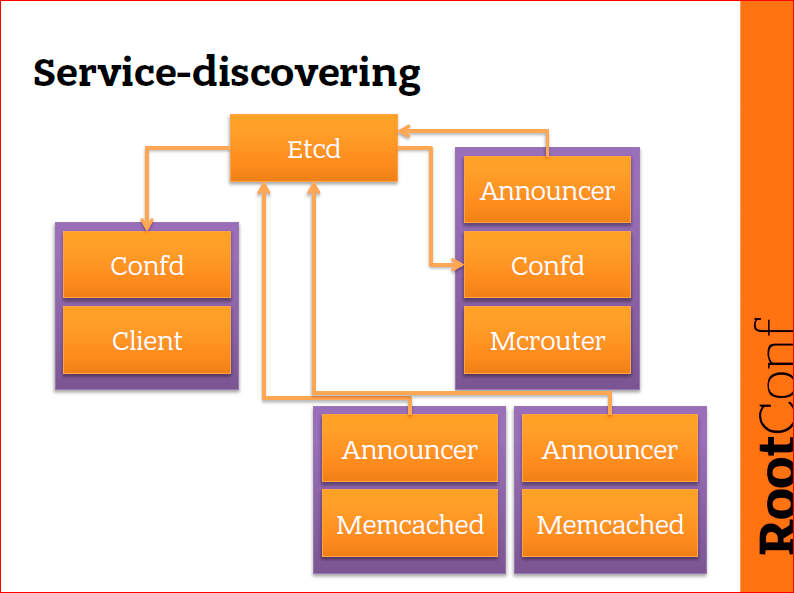
Как это примерно работает? Здесь есть та самая схема с клиентом, mcrouter’ом и memcached‘ами. Что происходит? Я нарисовал etcd отдельно, потому что рисовать его в каждое место не нужно, а etcd присутствует на всех машинах. На каждой машине, которая у нас есть, есть etcd. И каждый раз, когда мы общаемся с etcd, мы общаемся с петлей. Это важно. На некоторых машинах присутствует confd. Confd не присутствует у нас на memcached, confd занимается тем, что он читает в etcd данные и конфигурирует демон, сконфигурированный на локальной машине. Т.е. машины – это фиолетовые прямоугольники, а оранжевые прямоугольники – это демоны, которые запущены на машинах. Клиент – это какой-то абстрактный клиент, это может быть сервис, это может быть какое-нибудь наше приложение, но оно хочет попользоваться mcrouter’ом. Mcrouter, в свою очередь, – это клиент к memcached. Т.о. у нас есть разные типы: у нас есть клиент, у нас есть mcrouter, memcached и, помимо этого, у нас есть общие компоненты – confd и announcer.
Что происходит дальше? Когда у нас стартует memcached, рядом с ним запускается маленький bash’евый скриптик и пытается определить endpoint, по которому доступен memcached. Он берет эту строку, т.е. endpoint этого memcached (announcer-то знает, где запущен memcached) и пишет в etcd: «Привет, я memcached, я доступен здесь». Второй memcached делает точно так же и пишет: «Привет, я тоже memcached, и я доступен вот здесь». И теперь в etcd есть две записи про доступные memcached: memcached 1 и memcached 2, и у них разные IP-адреса, потому что это разные машины, и в etcd об этом информация уже есть. После этого у нас старутет mcrouter. На mcrouter точно так же есть announcer, который рассказывает, где доступен mcrouter. Etcd – это не одна машина, это кластерный сервис, инстанс которого находится на каждой машине. Confd читает из etcd то, что туда написали announcer’ы memcached. После этого confd узнает, что memcahed доступны по этим двум адресам и конфигурирует mcrouter, чтобы mcrouter ходил именно в эти memcached. Дальше, если один из этих memcahed упадет, в etcd через несколько секунд проэкспайрится ключ, и эта запись исчезнет. Confd, который следит за ключами в etcd, об этом узнает и переконфигурирует mcrouter так, чтобы mcrouter перестал использовать мертвый memcahed. Если появится третий memcahed, то confd, опять же, об этом узнает, потому что confd на mcrouter отслеживает в etcd изменения всех ключей, ну, условно, memcahed*. Т.е. как только там появляется хоть какой-то memcahed, confd на mcrouter об этом узнает и переконфигурирует mcrouter. Для клиента вся эта штука происходит прозрачно, он просто общается с mcrouter, и клиент в свою очередь узнает, как пообщаться с mcrouter с помощью все того же etcd. Работает оно примерно так. На достаточно простом кейсе.

Из плюсов здесь – оно работает по-настоящему быстро. Т.е. это происходит мгновенно. В случае с memcahed и mcrouter это будет происходить меньше секунды, потому что все эти демоны очень быстро перезапускаются. И если у нас нет проблем со связанностью, кластер не разорван, и все у нас нормально, то нам, вообще, не требуется помнить о том, где находятся эти memcahed, мы их неважно где стартуем, и они сразу же появляются в кластере, туда сразу же идет нагрузка. И я как админ становлюсь от этого счастливый, радостный, мне хочется прыгать и бегать от счастья.
Кроме того, мне не надо даже думать о документации, потому что мне не нужно записывать, что у меня и где работает. У меня всегда уже записано, что где работает. Я всегда это вижу, потому что документация появляется от того, что где запущено, а не наоборот. Т.е. первичен запуск, а не документация. А в случае, когда мы работаем с хардкодом, сначала мы хардкодим, а потом мы запускаем.
Есть, конечно, несколько минусов, они написаны, я думаю, их даже комментировать не стоит, потому что система действительно усложняется и действительно становится страшно, что делать, если оно все разваливается, и у нас с дата-центром приходит кошмар.
Здесь есть два момента. Первый пункт – сложность. Сложность не так страшна, особенно учитывая, что у нас очень много сервисов. Сложность с хардкодом, сложность с DNS значительно выше, потому что здесь один раз настроили, а после этого рутинные операции по перемещению сервисов к стопу сервисов, к старту сервисов, добавлению, изменению – они становятся почти бесплатными, и мы не правим постоянно DNS-зоны, мы не правим конфиги, мы не боимся копипастить циферки из одного места в другое, оно все само работает. Поэтому оно с одной стороны сложно, но с другой стороны, оно на самом деле проще, потому что время экономит знатно.
Во-вторых, страшность. Конечно, страшно, вдруг вся эта штука исчезнет и придет ей кирдык. Здесь нас спасает в etcd такое счастье, что даже в случае, если происходит полный краш всего, что можно предположить, etcd остается доступным на чтение. Писать в разломанный кластер нельзя, читать из разломанного кластера последние изменения, которые в разломанную часть кластера прилетели, можно. Каждая нода etcd всегда хранит полный дамп всех данных, которые у нас есть. Etcd не шардит данные и, даже если у машины опушены все сетевые интерфейсы, то что она получила в etcd, пока была в кластере, на ней остается. Если у вас отвалился дата-центр, то у вас все равно останется кворум в кластере в части дата-центров, которые у вас остались все вместе, и туда, если вам повезет, даже можно будет писать. Ну, как минимум, оттуда можно будет читать. Несмотря на то, что изменения происходят часто, они, тем не менее, происходят не каждые две секунды, поэтому, даже если у нас все развалится, нам все равно более-менее нормально.
И есть еще один минус, это третий пункт – что демонам необходимо в хорошем случае уметь с etcd работать нативно. Так обычно происходит лучше, потому что многие демоны не любят релоад, потому что мы можем ошибиться в шаблонах, с помощью которых confd будет конфигурировать наши демоны, мы можем ошибиться где-нибудь еще. Если это будет код, который вшит прямо в наши сервисы, это будет работать стабильнее и лучше. Это желательно, потому что если бы было необходимо, то такие штуки как confd и скриптики announcer не появлялись бы.

Мы пытались решить несколько проблем, и на самом деле система service-discovering в таком виде, в котором я описал, полностью наши проблемы решить не могут. Есть несколько моментов.
Наше приложение в поиске стартует, читает 40-200 Гбайт в оперативную память, лочит это в памяти, и потом, наконец-то, начинает слушать порт, и начинает с этим работать. И так оно живет долго. Записи у нас мало, у нас очень много чтения. Это поисковая система, понятно, что поиск почти ничего не узнает о том, когда с ним работают клиенты. Но, к сожалению, из-за такого типа жизни демон у нас стартует пять минут. Соответственно, если у меня будет изменяться какая-то мелкая штука, я не могу позволить себе пять минут простоя сервиса, ну никак, потому что они все одновременно рестартнутся – я ж специально добился того, что они все быстрые, а теперь они все быстро сами рестартятся, я так жить-то не могу. Это первая проблема. Ситуация с confd и постоянным рестартом демонов плохая, мы не можем ее себе позволить.
Вторая проблема, как в любом достаточно долго живущем проекте, а Поиск в Mail.ru существует с 2008 года, есть достаточное количество кода, в который никто не хочет влазить. Разработчики уволились и др. И, соответственно, мы никак не можем научить некоторые наши демоны работать с etcd. Некоторые можем, которые в горячей разработке.
Это из тех двух проблем, которые мы не можем решить сами.
Третий пункт – это задача, которую мы хотели решить, чтобы нам не было необходимости переконфигурировать тысячи мест.
Нам, вроде бы, становится лучше, но у нас есть первый пункт, по которому мы не можем перезапускать ничего.
И еще один момент, это общее требование к любой системе – нам не должно стать хуже с момента, как мы ее внедрим. Если у нас сейчас используется хардкод и DNS, то если мы внедряем систему обнаружения сервисов, мы не должны получить деградацию в надежности, по сравнению с тем, что у нас есть. Поэтому мы пошли дальше и начали внедрять новые хорошие костыли.

Мы начали думать и решили сделать немножко хитрозакрученный сервис, такой чтобы приложения или наши сервисы, клиенты не имели необходимости вообще менять тип связи с какими-то другими сервисами, серверами. В разных контекстах один и тот же сервис может быть как клиент, так и сервер.

Эту схему вы уже видели. Вот так вот оно у нас живет в нормальном режиме, и в этом случае confd конфигурит нашего клиента. Клиент – это то приложение, которое я не хочу ребутать.
И поэтому мы решили сделать вот так:

Мы добавляем HAproxy между клиентом и mcrouter. Опять же, клиент и mcrouter – это абстрактные какие-то примеры, можно засунуть сюда фактически что угодно.
Какой мы получаем от этого profit? Клиент общается с HAproxy. HAproxy слушает петлю, в конфиг клиента у нас забито, что memcached доступен по 127.001:11.211. Всегда, везде, на любом сервере, который захочет воспользоваться mcrouter. У нас запущен HAproxy, который слушает петлю, и в конфиге всегда забита петля. Confd, в свою очередь, конфигурит уже не клиент, confd конфигурит HAproxy, HAproxy слушает петлю и проксирует эти обращения в настоящий mcrouter. Где находится настоящий mcrouter, HAproxy узнает из confd, confd, в свою очередь, – из etcd.
Здесь, мне кажется, ничего сильно сложнее не становится. Сразу вопрос: почему на mcrouter нет HAproxy для того, чтобы с помощью HAproxy общаться с memcached? На самом деле, ее можно туда вставить, но mcrouter умный и работает выше, чем по протоколу TCP, он влезает в протокол memcached, и поэтому mcrouter, к сожалению, приходится конфигурить вручную. Но mcrouter почти не хранит состояния, поэтому ему рестарт не страшен. Демоны, которые не хранят состояния, мы можем легко ребутать, и они быстро стартуют. Демоны, которые хранят состояния, мы не можем ребутать, потому что они стартуют долго. И вообще это больно. Поэтому мы к ним вонзаем костыль в виде HAproxy.

Почему мы делали именно так? Потому что мы не могли ничего ребутать. Теперь мы можем не ребутать и можем ребутать только HAproxy, это бесплатно. Это условно бесплатно, но намного более бесплатно, чем пять минут простоя демона из-за изменения где-то какого-то маленького конфижика.
Во-вторых, учитывая, что сервисов много и кода разного много, конфигурировать нужно много, и эти шаблоны писать в confd тоже утомляет. Один раз написать все шаблоны для HAproxy сильно проще, и мы потом ни о чем не думаем, просто везде забиваем петлю. Для memcached это будет порт 11.211, для MySQL это будет порт 33.06, но все приложения всегда общаются с петлей. Они, вообще, ни о чем не думают. Нам даже переконфигурировать ничего никогда нигде не нужно.
В-третьих, у HAproxy есть чудные репорты, с которых можно снимать статистику, которую часто из приложения достать трудно, это досталось нам бесплатно, это не было целью, но это внезапно можно использовать, и это помогает.
В-четвертых, HAproxy – это не просто proxy, это еще и балансировщик. Если у нас есть простые демоны, которые требуют балансировки, которая имеет возможность быть реализованной с помощью HAproxy, мы можем ее бесплатно получить.
И дополнительные плюшки – таймаутинг на коннекты, дополнительные активные чеки соединений до бэкендов. Это все в HAproxy есть, и нам нет необходимости встраивать это в демоны, которые общаются по нестандартным протоколам, которые вовсе даже не http.
Но есть проблема, HAproxy не умеет в UDP, а UDP демоны существуют. Константин рассказывал про Graphite, Graphite работает по UDP, он умеет по TCP, но когда метрик много, TCP – это сильный оверхед здесь, а HAproxy в UDP не умеет принципиально. Поэтому мы используем DNAT.

DNAT имеет тот же функционал, при необходимости он может условно заменить HAproxy в этом кейсе, но у него нет никаких дополнительных плюшек HAproxy. Поэтому с ним можно жить и ограниченно использовать. Если у нас реально проблема с производительностью HAproxy, например, то мы можем вставить DNAT вместо HAproxy и для TCP, но в этом случае все проблемы TCP, коннектов, таймаутов и всего такого, о чем я говорил, должны быть все-таки решены клиентом, если мы используем в TCP-режиме. Здесь показан пример со statsd и Carbon’ом для Graphite, когда одно с другим общается по UDP. И здесь много компонентов не указано наподобие annauncer’ов, просто потому что они не влезают в эту схему, экран маленький, а руки большие.

К чему мы все это делали? Нам стало почти безболезненно двигать сервисы между разными местами. Сети Mail.ru обладают интересной особенностью – если необходимо, условно, сервер вытащить из одной стойки и поставить в другую, то мне нужно переконфигурировать ему сеть. Я не могу сделать по-другому. Поэтому у меня эти процедуры болезненные. Даже просто взять опустить один memcached на одном сервере, поднять его на другом и так, чтобы заменить, мне все равно необходимо переконфигурировать сеть. Вот так у нас сеть устроена. Эту задачу мы решали с помощью этого инструмента, и в целом она становится сильно проще, потому что нам нет необходимости идти и править 25 сетевых конфигов и потом еще 1000 конфигов и демонов.
Второй момент – это, когда у нас есть mcrouter или какой-то другой демон похожей роли, под ним есть несколько memcached и memcahed внезапно нужно сделать больше. Эти штуки с помощью DNS не решаются, в принципе, а с помощью etcd они решаются, потому что мы можем написать правильные шаблоны и правильно разложить данные в etcd при старте демонов, так чтобы пулы расширялись и броды наши были шелковистыми.
Третий момент – это дополнительный момент, который нам достался бесплатно. Демонов очень много, что-то запущено 35 лет назад, и мы об этом не знаем, оно не в мониторинге, документации на это нет, обнаруживаем только, когда падает. Если у нас все засунуто в etcd, то мы всегда видим, кто с кем общается. Во-вторых, если у нас есть HAproxy мы еще и видим, сколько общается. Мы получаем все метрики бесплатно. В-третьих, у нас в этом случае отделен момент конфигурирования демона, который работает, и конфигурирование клиентского демона. Нет, они как раз совмещены, в обычном кейсе они объединены, из-за этого мы можем просто взять опечататься в порте, когда мы конфигурируем клиентский демон, и получить проблему.
Это не выдуманный кейс. Я с этим кейсом столкнулся два дня назад. У меня админ просто ошибся и внес другой порт. На 10-ти серверах это выкатилась, сервис начал деградировать, и мы начали грустить. Происходит это, потому что люди не совершенны, так бывает. Но если мы используем роботов, то роботы при правильной эксплуатации сильно более совершены, чем люди, если за ними правильно следить. И когда у нас появляется новый сервис, только в этом случае нам необходимо конфигурировать что-то вручную. Если мы переконфигурируем старые сервисы, у нас все происходит автоматически, и у нас нет необходимости постоянно коммитить, что-то вручную, рестартовать, жестко мониторить и все такое.
Контакты
» s.puzirev@corp.mail.ru
» Блог компании Mail.Ru Group
Этот доклад — расшифровка одного из лучших выступлений на конференции по эксплуатации и devops RootConf.
Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Ну и главная новость — мы начали подготовку весеннего фестиваля "Российские интернет-технологии", в который входит восемь конференций, включая RootConf. Набираем докладчиков!
