Классы, которые люди самостоятельно пишут, а потом копируют из одного проекта в другой, хотя они уже есть в стандартных библиотеках, в простонародье называются велосипедами. Первый вопрос, который возникает при встрече с таким «велосипедом» — зачем люди переписывают что-то заново? Вариантов может быть несколько.
Сегодня мы не будем говорить о том, что велосипеды — это плохо, это не обязательно так. Мы поговорим о том, что действительно плохо:
А также затронем «вредные» советы, обсудим новейшие практики программирования (C++ 11 и позднее), подумаем, что делать с «идеальным» велосипедом.
О спикере: Антон Полухин (@antoshkka) сотрудник компании Яндекс, активный разработчик библиотек Boost, автор TypeIndex, DLL, Stacktrace, Maintainer Boost Any, Conversion, LexicalСast, Variant, сопредседатель Национальной рабочей группы по стандартизации С++. Всё это вместе значит, что Антон ежедневно видит очень много кода, как опенсорсного, так и коммерческого, и очень хорошо знает, как часто разработчики изобретают велосипеды.
Итак, тема — велосипеды. С какого класса начнем? Правильно — со строки.
Представьте себе, что на дворе глубокое средневековье, люди в латах скачут на лошадях. Вы — разработчик стандартной библиотеки, и единственный стандарт, который есть, это С++ 98. Вам надо написать свою строчку.
Вы начнете писать что-то очень простое без всяких шаблонов. У вас будет указатель на динамический проаллоцированный кусок памяти (data), переменная size, которая хранит количество символов в проаллоцированном куске памяти, и переменная capacity, которая задает размер этого динамического куска памяти.
Для вашего класса строки вы напишите конструктор копирования и конструктор от массива символов. Оба они будут динамически аллоцировать кусок памяти, перемещать туда символы. Здесь написано new + memmove, но на самом деле там могут быть быть небольшие вариации типа malloc, memcpy, смысл остается тем же.
Так как вы — хороший разработчик стандартной библиотеки, вас интересует, насколько хорошо такой класс строки будет работать. Вы открываете пользовательский код, смотрите популярные рецепты и находите что-то наподобие примера ниже, где создается map от строки и int, и туда вставляется пара.
И тут вы понимаете, что дела плохи — медленно, очень медленно.
У вас есть знакомый Вася, который тоже разрабатывает стандартную библиотеку и у него класс строки работает быстрее. Где именно теряется производительность:
Получается весьма печальная картина — 3 вызова new, 3 вызова memmove, пара вызовов delete, и все это жутко медленно. Вас раздражает, что у Васи быстрее, и вы начинаете думать, как сделать лучше.
Тут вы либо сами придумываете, либо где-то читаете о технологии Copy-On-Write (COW). Она позволяет эффективнее работать с временными объектами. Большая часть потерь была за счет того, что создаются временные объекты, которые никак не модифицируются: их просто создали, что-то из них скопировали и тут же уничтожили.
По технологии Copy-On-Write вместо того, чтобы строка уникально владела динамическим объектом, который создан в куче, можно сделать так, чтобы несколько строк одновременно ссылались на динамический объект. Тогда в этом динамическом объекте будет счетчик ссылок — сколько одновременно строчек работает с ним. Код будет выглядеть так:
Вы напишете class string_impl (можно написать его получше) и добавите use_count, т. е. счетчик ссылок — сколько строчек ссылается одновременно на динамический объект. Еще вы поменяете конструктор копирования, теперь он будет брать указатель на динамический объект от входной строки и увеличивать счетчик ссылок.
Немного придется повозиться с неконстантными функциями, которые потенциально меняют строчку. Если две строки владеют динамическим объектом, и одна из них начнет менять его, то другая увидит изменения. Это побочный эффект, которым пользователи будут недовольны, ведь они сначала работали с одной строчкой, а потом она внезапно поменялась.
Нужно добавить проверку: если мы уникально владеем динамическим объектом, то есть счетчик ссылок равен 1, то мы можем делать с ним все, что угодно. Если счетчик ссылок не равен 1, мы должны вызвать new и memmove, создать еще один динамический объект и скопировать туда данные из старого объекта.
Деструктор тоже изменится. Он будет уменьшать счетчик ссылок и смотреть: если мы — последний владелец динамического объекта, тогда его нужно удалить.
В конструкторе от массива символов ничего лучше не стало, по-прежнему new и memmove. Зато дальше вызовется конструктор копирования строки при создании пары, который теперь не вызывает ни new, ни memmove. Когда пара будет вставляться в map, опять будет вызван конструктор копирования строки, который опять-таки не вызывает new и memmove.
Все деструкторы временных объектов тоже не вызовут delete — красота!
Итого, COW более чем в 2 раза ускоряет код в C++98.
Если сейчас мне кто-то скажет, что знает технологию, которая увеличивает производительность моего кода в 2-3 раза, я буду использовать ее везде.
В 90-е года многие библиотеки так делали. Например, есть библиотека QT, где COW присутствует практически во всех базовых классах.
Но технологии не стоят на месте. Наступают 2000-е года, появляются процессоры с Hyper-threading и многоядерные процессоры, причем не только серверные, но и пользовательские:
Теперь у каждого пользователя может быть более, чем 1 ядро. И наша строка уже плохо работает, потому что у нас общий счетчик ссылок.
Например, есть два потока, в них по строке, которые ссылаются на общий динамический объект. Если потоки работают со строками и одновременно решают их удалить, получается, что мы из двух потоков будем пытаться одновременно менять динамический счетчик ссылок use_count. Это приведет к тому, что либо возникнет утечка памяти, либо приложение аварийно завершится.
Чтобы это исправить, вводим атомарную переменную — сделаем вид, что в C++ 98 есть std::atomic. Теперь наш класс выглядит так:
Все работает — замечательно! Почти…
Теперь у нас и конструктор копирования, и деструктор имеет в себе атомарную инструкцию , что не очень хорошо. Неконстантные методы превращаются в жуткое безобразие, потому что появляются граничные условия, которые редко возникают, но которые мы обязаны обрабатывать.
Например, два потока владеют строчками. Эти строчки ссылаются на один и тот же динамический объект. Один поток решает поменять строку. Строка смотрит, что она неуникально владеет динамическим объектом и начинает объект клонировать. В этот момент второй поток говорит, что строчка ему больше не нужна и вызывает ее деструктор.
А первый поток все еще клонирует, вызывает new, memmove. Он закончил свои дела и вдруг понимает, что у него две строки, а нужна ему одна.
Придется еще предусмотреть логику и на такое, а это дополнительные проверки, возможно, дополнительный лишний вызов new и memmove, и опять много атомарных операций, что плохо.
На X86 не атомарный инкремент — простое увеличение integer на единицу занимает один такт процессора [1]. Если сделать эту операцию атомарной, то она будет занимать от 5 до 20 тактов, если только одно ядро делает атомарную инструкцию и если это ядро последнее меняло атомарную переменную [2]. Если ядро не последним меняло атомарную переменную, то в районе 40 тактов.
Итого, такое решение в 5-40 раз медленнее только за счет того, что использована атомарная переменная. Дальше хуже.

Если несколько ядер одновременно работают с атомарной переменной, например, три ядра одновременно хотят сделать инкремент атомарной переменной, у нас будет ядро-счастливчик, которое начнет делать атомарный инкремент, остальные два ядра будут ждать от 5 до 40 тактов, пока ядро не закончит все свои действия.
Тут появляется второе ядро-счастливчик, которое начинает делать атомарную операцию, т. к. не оно последнее меняло атомарную переменную, это займет 40 тактов. Третье ядро все еще ждет. Чем больше ядер одновременно пытаются сделать атомарную операцию над одной и той же переменной, тем дольше последнее ядро будет ждать.
Так выглядит график ожидания последнего ядра:
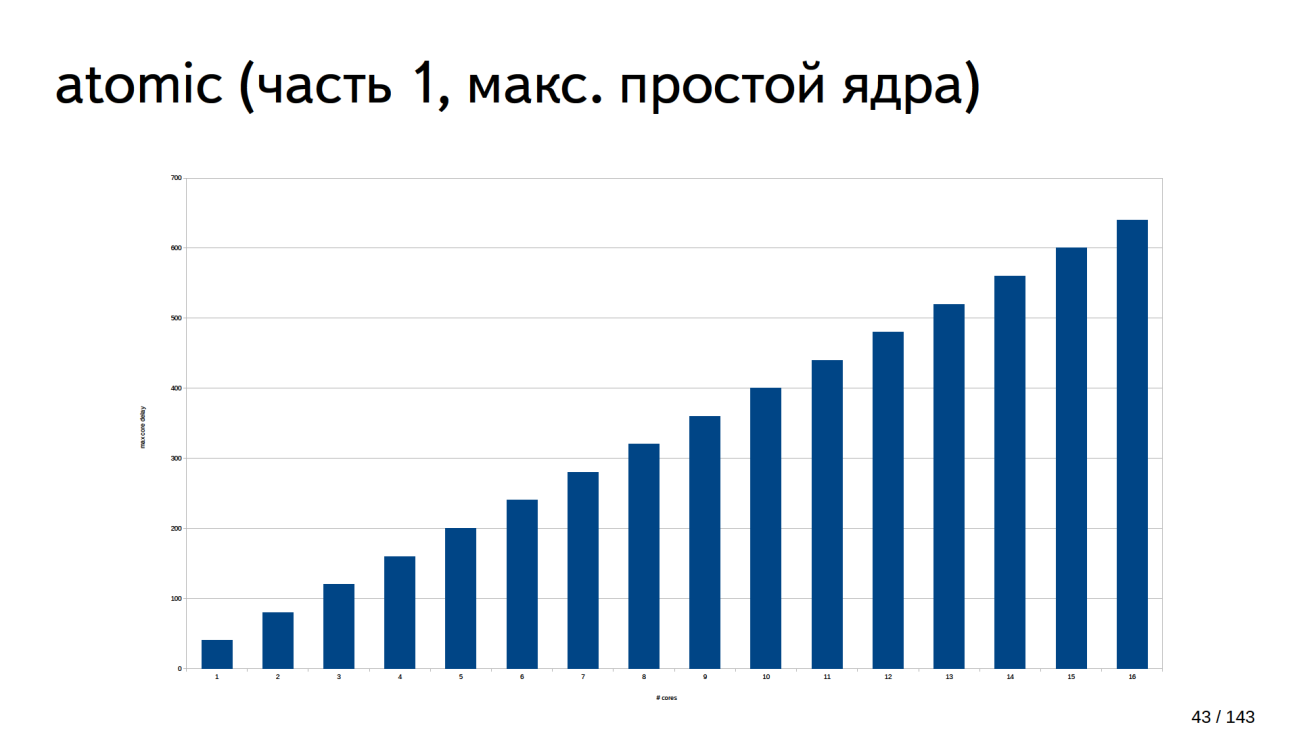
В этом примере 16 ядер и последнее ядро ждет в районе 600 тактов. Это простой самого несчастливого ядра. Если просуммировать простои, то получится картина простоя получится квадратичная.
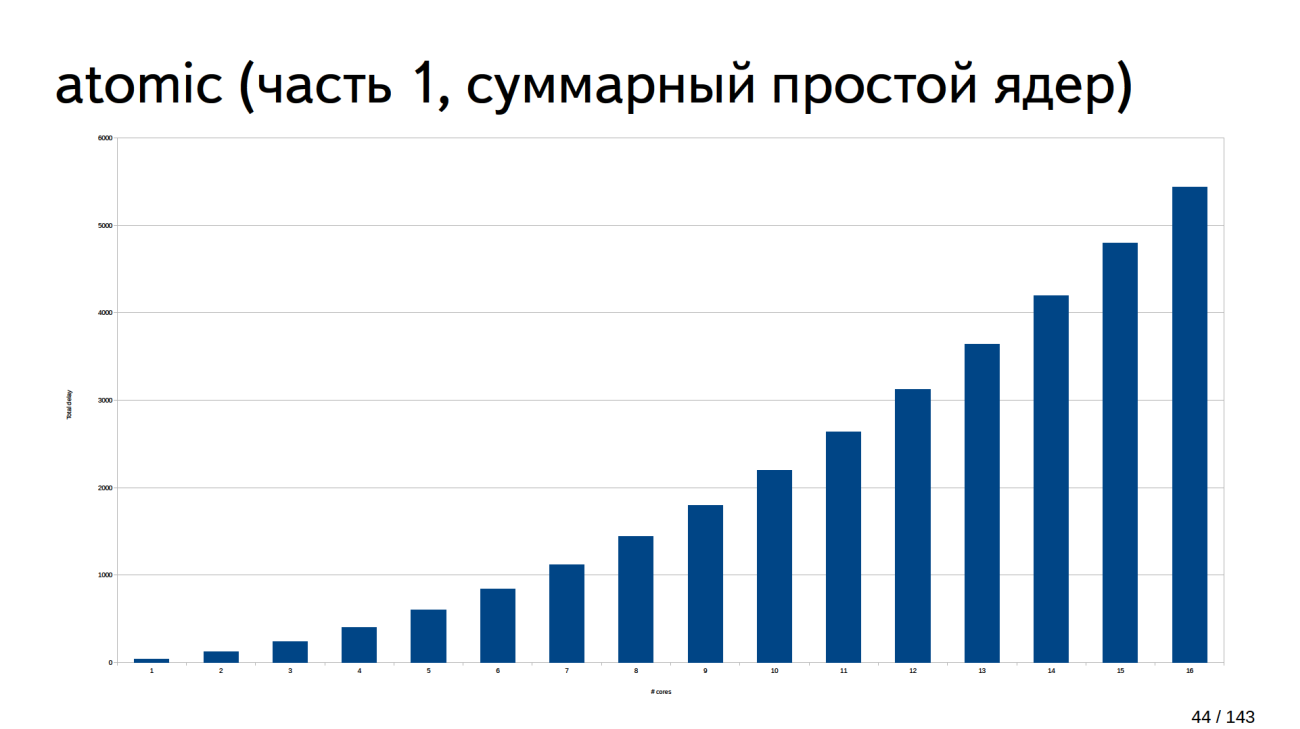
На 16 ядрах примерно 6000 тактов ушло в никуда.
Существуют системы, содержащие более 90 ядер, и если все они 90 ядер решат одновременно работать с одной и той же атомарной переменной, все будет очень печально.
COWболее чем в 2 раза ускоряет код в C++98. Все равно Copy-On-Write быстрее и все тут.
В C++11 появляются rvalue reference, что позволяет писать специальные классы и специальные методы, которые работают с временными объектами.
Например, move-конструктор для строки одинаково хорошо работает, если строка COW и если строка самая обычная базовая из средневековья, где динамически аллоцируется объект, и только одна строка им владеет.
Что здесь происходит? На вход приходит объект s. Он временный, мы знаем, что компиллятор его скоро удалит, что больше им никто пользоваться не будет, и мы можем забрать у него ресурсы. С ним можно делать вообще все, что угодно, — главное, чтобы для него потом можно было вызвать деструктор.
Забрали ресурсы. Мы — пустая строка, нам пришла строка с результатом, делаем swap. Теперь мы строка с результатом, а временная строка без всяких ресурсов — пустая.
Посмотрим, как это работает на нашем примере, если у нас строка без COW.
Создается строка от массива символов «Hello». Тут new и memmove — так же, как с COW.
Дальше — лучше. При копировании строки в пару у нас вызовется move-конструктор строки (
При вставке пары в map, map видит, что пара у нас тоже временный объект (
Без new и memmove строка перекочует внутрь map: 1 вызов new и 1 вызов memmove — так же, как с COW, но без атомарных операций.
Хорошо, а если мы хотим копировать строчку? Мы все разумные люди, и хотим копировать строчку, как правило, если мы хотим ее менять.
Без COW мы скопировали строчку, сразу вызывался new и memmove. Мы можем менять строчку и делать все, что угодно.
Если у нас COW строка:
Результат тот же, что и без COW, но, как минимум, пара лишних атомарных операций появляется.
Неконстантные методы по-прежнему ужасны. Если мы хотим пройтись по нашей строке (первым десяти символам в строке), используя индексы, с COW строкой — это 10 атомарных операций над одной и той же атомарной переменной. Если два потока одновременно проходятся по одной и той же строке — большая беда.

В итоге COW-конструктор имеет атомарные операторы, деструктор, скорее всего, будет вызывать атомарные инструкции — везде много атомарных инструкций, которые нам не нужны. Мы их не просили, и это против правил C++. Мы платим за то, чем не пользуемся.
Начиная с C++11 COW строчки запрещены в стандарте. Там наложены специальные условия на строчку, что COW реализовать невозможно. Все современные имплементации стандартных библиотек не имеют COW строк.
COW устарел, осторожнее с его использованием.
Аккуратнее используйте COW в новых проектах. Не доверяйте статьям, которым больше 10 лет, перепроверяйте их. COW не показывает таких хороших результатов, как 20 лет назад.
Если вы имели COW строчку и всем своим пользователям говорили: «У нас COW строка — она идеально все копирует, у нас все замечательно, у нас везде COW», пользователи могли заточиться под это, и писать код с учетом того, что ваши классы используют COW.
Например, пользователь мог написать класс bimap — это класс, который умеет искать как по ключу, так и по значению.
Он мог написать его через два std::map, каждая из которых имеет строчку. Здесь строчка COW, пользователь об этом знает, как и то, что в map две копии строки. Пользователь знает, что они динамически будут ссылаться на один и тот же объект памяти, и что это эффективно по памяти. Если здесь COW строчку поменять на обычную, затраты по памяти увеличатся вдвое.
В C++17 это можно поправить, например, как в примере выше, заменив одну из строчек на string_view. По памяти получится точно также, но уберутся атомарные операции и код станет немного быстрее.
Получается, что к той древней строчке 98 года, которая уникально владела динамическим объектом, мы добавили move-конструктор, и все — это идеальная строка? Ничего лучше сделать нельзя?
Вот что придумали люди. Они посмотрели на один из первых наших примеров, где создается map от строки и int, и туда вставляется пара, долго качали головой и говорили, как все плохо:
Люди придумали, как можно, не меняя размер строки — переменной std::string — хранить в ней символы, не аллоцируя динамически память. Они посмотрели на самый первый класс строки:
Теперь внутри строки в примере выше находится union. Первая часть — это указатель на data и переменная size_t. Вторая часть union — структура — содержит data (маленький буфер размером с char* и size_t). В него влезает примерно 16 байт.
Если сapacity = 0 — это значит, что мы память динамически не аллоцировали и нам надо идти в impl small_buffer_t, и в data будет лежать наша строчка без динамической аллокации.
Если сapacity ≠ 0, значит, мы динамически где-то проаллоцировали память, и нужно идти в impl no_small_buffer_t. Там есть указатель на динамически проаллоцированный кусок памяти и переменная size.
Конечно, в примере немного упрощенный вариант. Некоторые стандартные библиотеки, например Boost, умеют хранить 22 символа и вдобавок терминирующий 0 без динамических аллокаций, не увеличивая размер строки. Все современные стандартные библиотеки используют этот трюк. Это называется Small String Optimization.
Эта штука хороша, во-первых, на пустых строчках. Они теперь гарантированно не аллоцируют память, и гарантированно вызов метода c_str() теперь не будет аллоцировать память.
Я знаю компании, которые переписывали std::string, потому что у них пустая строка динамически аллоцировала память. Не надо этого больше делать.
Во-вторых, например, наш «Hello!» влезет без динамической аллокации. Если в строчках хранятся логины пользователей, их имена и фамилии отдельно от имен, какие-то идентификаторы, города, страны, названия валют — как правило, все влезет в строчку без динамических аллокаций.
Но люди посмотрели и опять подумали, что медленно. Начиная с C++17, компилятор умеет оптимизировать memmove, его альтернативу — ту, которая находится в строке, на этапе компиляции. Но и этого показалось мало. В C++17 есть Guaranteed copy elision, который гарантирует, что в ряде случаев вообще никаких копирований и memmove не будет. Просто в map каким-то чудом образуется эта строчка без промежуточных переменных.
На примере std::variant рассмотрим, что бывает, если люди пытаются велосипедостроительствовать, не заглядывая в чужие решения.
В C++17 принят класс std::variant — это умный union, который помнит, что он хранит. Мы можем написать std::variant<std::string, std::vector<int>>. Это значит, что вариант может хранить в себе либо строку, либо вектор. Если мы запишем в такой вариант слово «Hello», variant запомнит индекс шаблонного параметра в переменной t_index (что он содержит в себе строчку), по месту проаллоцирует строчку и будет ее хранить.
Если теперь попытаться записать туда вектор, std::variant посмотрит, что он хранит в себе строчку в данный момент, а не вектор, вызовет delete для строки, на месте строки сконструирует вектор и в какой-то момент обновит t_index.
Класс приняли в C++17, и люди по всему миру сразу кинулись его писать заново, переписывать, велосипедостроительствовать.
Выше — реальный код из опенсорсного проекта, видите в нем ошибку? Здесь вместо union получился struct.
Ниже — код из коммерческого проекта:
Здесь ошибка гораздо хуже и во многих имплементациях variant она присутствует. Здесь будут большие проблемы с исключениями.
Например, у нас variant, который хранит в себе std::string и мы пытаемся записать в него вектор. В строчке destroy вызовется delete для строки. С этого момента variant пустой, он ничего не хранит.
Потом на месте строки мы пытаемся создать вектор. Вектор передался по константной ссылке и мы вынуждены его копировать. Вызываем placement new и пытаемся скопировать вектор. Вектор — класс большой, в нем могут храниться пользовательские данные, которые при копировании могут кидать исключения. Допустим, мы кинули исключение. Оно выйдет из текущего блока, вызывая деструкторы всех локальных переменных, и выйдет в блок выше. Там исключение тоже вызовет деструкторы всех локальных переменных. Дойдет до того блока, где был объявлен сам variant и вызовет деструктор варианта.
Деструктор варианта смотрит, что у него записано в переменной index, которая еще не обновлена. В ней записано std::string, т. е. variant думает, что у него есть строка, которую надо удалить. А на самом деле на этом месте уже ничего нет, строка уже удалена. В этот момент вся ваша программа аварийно завершится.
Чтобы этого избежать, достаточно открыть интерфейс стандартной библиотеки и посмотреть, что std::variant имеет функцию valueless_by_exception, удивиться, что это такое, и посмотреть, зачем оно нужно. Можно открыть исходники Boost — там 2/3 кода посвящено этой проблеме.
Я говорю это все к тому, чтобы вы и все ваши подчиненные смотрели, как написаны велосипеды у других людей, во избежание таких печальных последствий. Это очень популярная ошибка. Она везде проскакивает.
Я привожу пример только variant, но в многих других классах есть подобное. Люди переписывают, думают, что что-то лишнее, не заглядывают в чужой код, и это приводит к катастрофическим последствиям.
Самое время попрыгать по больным мозолям.
Можно найти проекты, где все методы помечены как FORCE_INLINE — буквально весь проект вдоль и поперек на гигабайты кода. У людей спрашиваешь:
И с этого момента с людьми очень сложно спорить, потому что у них есть бенчмарк, а ты написать такой бенчмарк не можешь.
Современные процессоры — очень сложные устройства. Никто не знает до конца, как они устроены, даже разработчики процессоров.
Современный процессор не может выполнять вашу программу прямо с диска или прямо с оперативной памяти. Прежде, чем он начнет выполнять программу, он должен подтянуть ее в кеш инструкции. Только оттуда процессор может выполнять инструкции.
Некоторые процессоры имеют хитрый кеш инструкций, который делает дополнительную обработку команд, которые в него попадают. Но кеш инструкций — маленький, в него помещается мало кода. Если вы используете компилятор, который действительно делает FORCE_INLINE, когда вы его просите сделать FORCE_INLINE, у вас увеличивается объем вашего бинарного кода.

Представьте, что на рисунке выше ваша программа. Зеленым отмечено то, что поместилось в кеш. Это еще дополнительно ваш hot path — то место, где ваша программа тратит основное количество времени. Сейчас оно все поместилось в кеш процессора, в кеше инструкций простоя не будет.
Если вы добавите FORCE_INLINE, по бенчмаркам все будет замечательно, но код перестанет помещаться в кеш инструкций.

Когда вы дойдете до красной строчки, процессор скажет: «У меня нет инструкций новых, я должен подождать, пока они подтянутся из памяти». Если это где-то в цикле, он будет постоянно перещелкивать какие-то инструкции, подтягивать их себе из памяти в кеш. Это медленно.
Чтобы ваш бенчмарк правильно отражал реальное положение дел, он должен учитывать все 3 кеша — данных, инструкций и адресов. Для этого бенчмарк должен:
Другими словами, написать такой бенчмарк невозможно. Можно протестировать только ваш production код.
Если вы добавили FORCE_INLINE и ваш production код не стал лучше — лучше убрать FORCE_INLINE. Современные компиляторы умеют инлайнить. 10 лет назад они не умели этого делать хорошо, и FORCE_INLINE действительно в некоторых случаях помогал, например, на GCC. Сейчас нет.
Я говорю, что FORCE_INLINE — плохо, стоит отказаться от него в большинстве случаев, хотя иногда он может быть полезен.
Однако, разработчики компиляторов умные люди. Они видят, что пользователи пишут везде FORCE_INLINE и программы становится медленнее. Поэтому современные компиляторы имеют разные эвристики на игнорирование FORCE_INLINE. Некоторые компиляторы просто считают строчки внутри функции — если ваша функция длиннее трех строчек кода, FORCE_INLINE будет проигнорирован.
Ходит легенда, что есть компилятор, где люди очень сильно озаботились FORCE_INLINE, он их так достал, что они придумали следующую эвристику:
Если вы вдруг написали программу, добавили туда десяток FORCE_INLINE и все стало замечательно быстрее, возможно, что вы пользуетесь этим компилятором. Смотрите ассемблерный код, если вам действительно нужно, чтобы что-то встраивалось, чтобы FORCE_INLINE в этом месте действительно был. Я сам удивлялся тому, что в ряде случаев компиляторы тихо игнорируют FORCE_INLINE.
И наоборот, компилятор может тихо игнорировать ваше «не инлайнить». Он подумает: «Ты не знаешь, что делаешь, написал не инлайнить, но я лучше знаю — я заинлайню».
Я знаю очень умного программиста, который писал имплементацию B-Tree. Все было сделано на С++, на шаблонах, везде perfect forwarding, без всяких динамический аллокаций — просто идеально. Когда этот код стали проверять на одном из Performance Analyze, выяснилось, что исполнение не достаточно быстрое из-за того, что большую часть времени занимает ожидание инструкций в кеше инструкций.
Программист подумал, чуть упростил B-tree, убрал perfect forwarding, заменил его везде на константные ссылки, потому что B-tree никак не менял данные, которые ему приходили, убрал пару шаблонов, сделал код чуть компактнее, добавил noexcept, что тоже уменьшает объем бинарного кода.
В итоге код стал работать в 2 раза быстрее. Алгоритм не меняли — все то же самое, но код стал работать быстрее.
Если не верите мне, что FORCE_INLINE плохо, то рекомендую посмотреть лекции (1, 2) разработчика Clang Чендлера Каррута. Он говорит о том же, что и я, но короче, быстрее и на английском.

От «вредных» бенчмарков переходим к «вредным» советам.
Редко, когда разработка идет под одну платформу. Чаще бывает, что когда-то давным-давно разрабатывали под одну платформу, а теперь — под несколько.
Обычно, если компания начинается, как маленький стартап, она может выбрать себе одну платформу, под которую у нее уже есть заказчики. Постепенно компания растет, код становится популярнее, и приходит мысль портировать его на другие платформы.
Но в момент, когда люди начинают портировать на GCC, программа перестает работать: все компилируется, но тесты не проходят, программа выдает какой-то неадекватный вывод. Люди лезут на Stack Overflow или на другие ресурсы, посвященные программированию, задают этот вопрос и получают ответ:
И действительно — все начинает работать.
Объясню на примере, что делает эта опция (с именем функции я здесь не заморачивался).
Функция qwe принимает в себя две переменные: foo по ссылке, bar по константной ссылке. Это два разных типа данных. Внутри тела функции к f прибавляется значение b и выводится квадрат от b.
Ниже немного ассемблерного псевдокода, который скомпилирует компилятор, если подсунуть опцию -fno-strict-aliasing.
Компилятор:
Тут большинство людей задаются вопросом, зачем мы второй раз подгружали b в регистр, она же уже в регистре.
А потому, что добавили опцию -fno-strict-aliasing. Она говорит компилятору о том, что два типа данных, абсолютно разных, никак друг с другом не пересекающихся, все равно могут находиться в одной и той же ячейке памяти. Исходя из этого компилятор начинает генерировать код.
Когда вы делаете f += b, компилятор думает, что возможно f и b находятся в одной и той же ячейке памяти, и запись в f меняет значение b. И это во всем вашем проекте — добавили опцию, во всем проекте код стал генерироваться хуже.
По разным замерам (например, этому и этому), в зависимости от кода и оптимизации, это дает от 5% до 30% просадки производительности. Все очень зависит от вашего кода. Если у вас просто системные вызовы и работа с сетью, возможно, ничего не изменится для вас с -fno-strict-aliasing. Но просто ее писать при сборке вашего проекта не совсем правильно.
Правильнее включить предупреждение компилятора (GCC умеет предупреждать, когда нарушается strict-aliasing) и исправить в этом месте нарушение strict-aliasing. Как правило, это нарушение происходит, когда вы используете reinterpret_cast для двух несвязанных друг с другом типов.
Вместо reinterpret_cast лучше использовать memcopy или memmove. Компиляторы GCC умеют их оптимизировать. Просадки производительности в том месте, где вы делаете memcpy вместо reinterpret_cast, быть не должно.
От лютой теории переходим к советам, которыми можно пользоваться в повседневной практике.
Скорее всего, вы все это знаете, и, скорее всего, не используете.
Ниже пример функции foo, в которой создается вектор от shared_ptr. Мы знаем, shared_ptr — ровно тысяча. Они вставляются в вектор, и он возвращается.
Первый недочет: если мы знаем, сколько элементов будет хранить наш вектор, стоит вызвать res. reserve(1000). Это заранее проаллоцирует нужное количество памяти, и вектор при вставке в него не будет пытаться угадать, сколько памяти нужно. Без reserve в C++11 и раньше вектор сначала примет значение под 2 элемента, потом под 4 элемента, 8, 16 и т. д. Все это время при изменении размера он будет вызывать new, delete, копирование либо move вашего типа данных, что медленно.
Если же вызвать res. reserve(1000), то вектор точно знает, что это 1000 элементов, никаких дополнительных move, new, delete не будет.
Начиная с C++14 компиляторам разрешено оптимизировать вызовы new. Некоторые компиляторы умеют это делать, но им должно повезти — не во всех случаях это получается. Если вы хотите быть уверены, что компилятор сгенерирует оптимальный код, лучше вставить reserve — хуже не будет.
Другое проблемное место в этом примере компилятор соптимизировать не сможет. Это вызов std::shared_ptr<int>. В этой строчке происходит две динамические аллокации:
Причем в памяти они находятся в разных местах. Если ваше приложение не использует weak pointers, или использует их не сильно, вместо строчки std::shared_ptr<int>(new int) имеет смысл написатьstd::make_shared<int>().
Make_shared сразу проаллоцирует кусок памяти, где может хранить и int, и счетчик ссылок. За счет того, что эти две переменные будут находиться рядом, это более кеш-дружелюбно. Работа с shared_ptr станет чуть быстрее, динамических аллокаций будет не две, а одна.
Итого, код в первом примере мы ускорили чуть более, чем в два раза,просто добавив reserve и заменив конструктор shared_ptr на make_shared.
Код в примере, представленном выше, ужасен. Давайте его улучшать постепенно, причем, скорее всего, не с того места, которое вы заметили.
V здесь копия элемента из вектора. За пределами цикла, и после итераций цикла она нам особо не нужна. Мы можем сказать компилятору, что переменная v больше не используется, заменив v на std::move(v), превратить ее в rvalue, и тогда вставка в результирующий контейнер res произойдет по rvalue ссылке. Ресурсы из v будут просто перекинуты внутрь контейнера, что быстрее.
Массив vector data больше никак не используется, все, что в нем содержится, будет уничтожено при выходе из функции. Вместо того, чтобы копировать v, мы можем написать for (auto&& v: data), т. е. сделать ссылку на v (&& — здесь это тоже ссылка).
В итоге получится следующее: v — ссылка на элемент внутри data. Когда мы к этой ссылке применим std::move, ресурс заберется уже из вектора data — прямо из вектора строка перетянется внутрь контейнера res. Никаких динамических аллокаций в итоге не будет. По сравнению с изначальным кодом стало в 100500 раз быстрее.
Ситуация, как в примере выше, возникает чаще — то же самое, но из вектора мы запоминаем последний элемент, а потом этот последний элемент извлекаем.
Также можно соптимизировать: мы говорим std::string res = std::move(data. back()). После этого в res — значение последнего элемента (мы перетащили ресурсы из вектора в переменную res). Теперь back внутри вектора — это пустая строка, data.pop_back() просто изменит одну из внутренних переменных вектора. Никаких динамических аллокаций, никаких вызовов delete — все быстрее.
В парсерах и протоколах зачастую есть массивы заранее известных строк. Люди часто пишут их так:
Кажется, что это лишь немного не оптимально, но, в принципе, не так страшно. Это произойдет один раз при запуске вашей программы либо при подгрузке DLL.
Но когда проект очень большой, то в разных его частях может накопиться большое количество таких кусков кода — 10, 100, 1000. Инициализация переменной CONSTANTS происходит при запуске программы либо при подгрузке динамической библиотеки. В этот момент этот однопоточный код будет вызывать new, аллокации, инициализировать вектор строк и это может замедлить старт вашей программы либо подгрузку динамической библиотеки.
Для тех, кто пишет realtime приложения и приложения, которые должны быстро рестартовать, если они упали, это может быть критично. Если у вас тысячи и миллионы таких объектов, это замедлит старт программы.
Если вам массив констант нужен, и вы обращаетесь к нему только по индексу или используете его только в range-based for, вы можете заменить вектор на обычный массив. То есть вместо std::vector<std::string> CONSTANTS можно написать std::string_viewCONSTANTS[].
В итоге старт вашего приложения не будет делать дополнительных операций, вызывать new, дополнительно фрагментировать память.
Если вам нужна строгая гарантия, что это выполнится еще до того, как ваша программа запустится, вы можете
Выше базовый класс base, в нем метод act —ничего интересного. Интересно, когда мы от этого base наследуемся. Представьте себе, что вы разработчик в компании и вам сказали разобраться в чужом коде, причем вы видите только то, что идет ниже.
Вы видите только это, вы еще не заглядывали в описание base и вас интересует, что это за метод act, объявлен ли он в базовом классе, перегружаем ли мы его, и вообще, что здесь происходит.
Вы можете сделать код более читабельным, просто добавив слово override:
Он будет не только более читабельный, но и более безопасный. Новый человек, когда будет читать ваш код, увидит override и подумает: «Ага, значит, этот метод объявлен в базовом классе, мы его перегружаем, все в порядке».
Придет новый человек и будет рефакторить базовый класс, поменяет там сигнатуру метода act, добавит туда integer и на этапе компиляции словит ошибку, что в классе-наследнике мы пытаемся заоверрайдить класс, который уже не объявлен в базовом, которого нет.
В итоге он не поломает ваш код. Без override все скомпилируется, как-то будет работать, но будет ошибка на рантайме. На ее отлавливание может уйти много времени. С override сломается на компайлтайме. Человек, который будет делать рефакторинг, это заметит и поправит и здесь метод act.
Еще можно добавить final в первую строку:
Компилятор видит, что класс final. Когда он видит some_implementation и переменную этого класса, и у этой переменной вызывается act, компилятор понимает, что от этого класса больше никто не наследуется, и в нем есть act. Он будет вызывать act без прохода по виртуальным таблицам, не будет различных динамических вещей — будет вызов act, как будто он не виртуальный.
Можно еще чуть-чуть улучшить, запихнув все в анонимный namespace:
Анонимный namespace — это как бы static на стероидах. Можно объявить переменную или функцию статиком, тогда она не будет видна наружу. Все, что вы объявите внутри анонимного пространства имен, будет видно только в этой единице трансляции.
Это хорошо тем, что развязывает руки оптимизатору. Он может делать больше оптимизаций, основываясь на том, что этот класс больше снаружи никто не использует. Оптимизатор также может подумать, что раз этот класс снаружи никто не использует, то его не надо экспортировать, что увеличит скорость загрузки и линковки приложения на рантайме.
Например, в OpenOffice была проблема, что этап динамической загрузки библиотек и линкер, который соединял все зависимости друг с другом, занимали 10 секунд, потому что много символов торчало наружу. Если использовать анонимный namespace, эта проблема станет меньше.
Ниже move constructors для класса my_data_struct. В нем только вектор data.
Только move забыли. И еще noexcept. Давайте перепишем:
Ряд стандартных контейнеров, например, vector, делают сложные подсчеты на этапе компиляции на основе того, помечены ли move-конструкторы как noexcept или нет. Если ваши move-конструкторы не помечены как noexcept, вектор может дополнительно аллоцировать память, когда он будет расширяться, и копировать элементы, вместо того, чтобы их перемещать. Это безобразие, потому что очень медленно.
Чтобы было быстрее, добавляем noexcept.
Эта запись не нравится большинству людей. Здесь непонятно, что написано, и нужно знать:
Куча каких-то деталей, которые нам не нужны.
Надо все лишь написать вот так и все это станет заботой компилятора:
Теперь компилятор сам расставит noexcept, constexpr, если сможет. Код из стандартной библиотеки будет работать быстрее — вам легче.
Хочу рассказать об одной штуке, на которую я недавно натолкнулся, и которая меня удивила.
Люди закешировали деление единицы на число. Они создали extern массив на 256 элементов, в котором запомнили:
Далее работают с этим массивом везде, где нужна часть от 1.
Как вы думаете, так будет быстрее или медленнее? Давайте выясним.

Залезаем в талмуды, где описано, сколько тактов занимают инструкции, и обнаруживаем, что доступ к элементу массива, который находится в L1 кеше, занимает 5 тактов, а деление — 22-29 тактов. Итого такое кеширование может быть в 2-4 раза быстрее, но…
1. Оптимизатор не видит значения
Это серьезное негативное влияние на производительность.
При этом компилятор даже не поверит вам, если вы везде напишите const, потому что он не оптимизирует, основываясь на const. Если вы где-то написали const, компилятор проигнорирует это, потому что где-то в другом месте вы могли написать const_cast.
2. Мы потратили кучу времени на обсуждение этого...
То, что мы потратили кучу времени на его обсуждение, тоже плохо в этом примере. Когда вы увидите его в чужом коде, вы тоже потратите кучу времени, чтобы разобраться, что это за безобразие.
3. Мы потратили 1Kb L1 кеша из 16/32Kb
Люди, которые разрабатывают компиляторы, пишут книги на эту тему и защищают сложные теории, говорят, что в современном мире производительность системы ограничена не скоростью процессора, а зачастую работой с памятью:
Мы потратили 1Kb кеша 1-го уровня на то, чтобы сохранить массив, и другие полезные данные теперь туда не поместятся.
Разработчик стандартной библиотеки C под Linux Ульрих Дреппер написал труд «What Every Programmer Should Know About Memory», то есть о том, что каждый программист должен знать о памяти. В нем намешана серьезная теория и физика, но есть замечательный простой пример важности кеша. На куске кода с переумножением матриц, не меняя практически алгоритм и ассемблерные инструкции, Ульрих Дреппер ускорил производительность в 10 раз просто за счет более эффективной работы с кешом данных.
Станет ли быстрее с таким кешированием единиц или нет — непонятно:
Но люди написали кучу кода, а мы потратили кучу времени на его разбор. Когда вы его встретите в чужом продакшн-коде, вы тоже потратите кучу времени на разбор, ваша производительность упадет. Работодатель будет недоволен.
Мы уже поговорили о «вредном», перейдем к хорошему.
Как написать свой идеальный велосипед, свою идеальную программу, я вам не скажу. На это есть куча книг, часть из них правильная, часть — не очень. Но, если вы написали программу, библиотеку, которая:
добро пожаловать в рабочую группу РГ21, мы:
С первого раза сделать proposal не просто, потому что есть специальные термины, которых надо остерегаться, и определенные формальности, которые надо соблюдать. Если вы просто напишете proposal и отправите его в Комитет, скорее всего, дальше ничего не произойдет, если вы (или доверенный человек) не прибудете в Комитет и не защитите вашу идею перед международным собранием. Приходит много предложений, и в первую очередь приоритет отдается тем, которые лично представляют и защищают.
Заходите на сайт рабочей группы https://stdcpp.ru/, там можно предложить свою идею, посмотреть, что предлагают другие, а самые интересные предложения мы обсудим вместе.
Узнать о других докладах Антона, посмотреть его презентации, публикации и множество другой полезной информации можно здесь — http://apolukhin.github.io/
- Некоторые делают это для самообучения: берут класс стандартной библиотеки, пишут его сами с нуля, сравнивают то, что получилось, с тем, что есть в стандартной библиотеке — в процессе узнают для себя что-то новое.
- Некоторые проекты имеют особое требования к коду. В embedded-разработке принято работать без RTTI и без exception, поэтому части стандартной библиотеки, которые используют RTTI и exception, необходимо переписать без них.
- Редко, но бывает, когда велосипед пишут, потому что могут написать лучше, чем в стандартной библиотеке. Как правило, такие нововведения рано или поздно попадают в стандартную библиотеку.
- Другим только кажется, что они могут написать лучше, и таких людей больше. Но в процессе они обучаются, выясняют для себя что-то новое и что-то интересное открывают.
- Могут быть другие причины.
Сегодня мы не будем говорить о том, что велосипеды — это плохо, это не обязательно так. Мы поговорим о том, что действительно плохо:
- бездумно переносить устаревшие технологии 20-30-летней давности в современные проекты;
- пользоваться «вредными» бенчмарками и оптимизациями.
А также затронем «вредные» советы, обсудим новейшие практики программирования (C++ 11 и позднее), подумаем, что делать с «идеальным» велосипедом.
О спикере: Антон Полухин (@antoshkka) сотрудник компании Яндекс, активный разработчик библиотек Boost, автор TypeIndex, DLL, Stacktrace, Maintainer Boost Any, Conversion, LexicalСast, Variant, сопредседатель Национальной рабочей группы по стандартизации С++. Всё это вместе значит, что Антон ежедневно видит очень много кода, как опенсорсного, так и коммерческого, и очень хорошо знает, как часто разработчики изобретают велосипеды.
Итак, тема — велосипеды. С какого класса начнем? Правильно — со строки.
std::string
string: C++98
Представьте себе, что на дворе глубокое средневековье, люди в латах скачут на лошадях. Вы — разработчик стандартной библиотеки, и единственный стандарт, который есть, это С++ 98. Вам надо написать свою строчку.
class string {
char* data;
size_t size;
size_t capacity;
// ...
};
Вы начнете писать что-то очень простое без всяких шаблонов. У вас будет указатель на динамический проаллоцированный кусок памяти (data), переменная size, которая хранит количество символов в проаллоцированном куске памяти, и переменная capacity, которая задает размер этого динамического куска памяти.
class string {
char* data;
// ...
public:
string(const string& s)
:data(s. clone()) // new + memmove
{}
// ...
string(const char* s); // new + memmove
};
Для вашего класса строки вы напишите конструктор копирования и конструктор от массива символов. Оба они будут динамически аллоцировать кусок памяти, перемещать туда символы. Здесь написано new + memmove, но на самом деле там могут быть быть небольшие вариации типа malloc, memcpy, смысл остается тем же.
Так как вы — хороший разработчик стандартной библиотеки, вас интересует, насколько хорошо такой класс строки будет работать. Вы открываете пользовательский код, смотрите популярные рецепты и находите что-то наподобие примера ниже, где создается map от строки и int, и туда вставляется пара.
std::map<string, int> m;
m.insert(
std::pair<string, int>("Hello!", 1)
);
И тут вы понимаете, что дела плохи — медленно, очень медленно.
У вас есть знакомый Вася, который тоже разрабатывает стандартную библиотеку и у него класс строки работает быстрее. Где именно теряется производительность:
- Cначала вызывается конструктор строки от массива символов — это вызов new и memmove (
string("Hello!")). - Потом вызывается конструктор пары, т. е. будет вызван copy-конструктор строки. Это еще один вызов new и еще один вызов memmove (
make_pair(string("Hello!"), 1)). - Потом эта пара вставляется в map. Копируется пара и ее содержимое — еще один вызов new и memmove (
m.insert(make_pair(string("Hello!"), 1))). - После этого временный объект пары и временный объект строки будут удалены.
Получается весьма печальная картина — 3 вызова new, 3 вызова memmove, пара вызовов delete, и все это жутко медленно. Вас раздражает, что у Васи быстрее, и вы начинаете думать, как сделать лучше.
string: COW
Тут вы либо сами придумываете, либо где-то читаете о технологии Copy-On-Write (COW). Она позволяет эффективнее работать с временными объектами. Большая часть потерь была за счет того, что создаются временные объекты, которые никак не модифицируются: их просто создали, что-то из них скопировали и тут же уничтожили.
std::map<string, int> m;
m.insert(
std::pair<string, int>("Hello!", 1) // копии которые не надо копировать
); // копии которые не надо копировать
По технологии Copy-On-Write вместо того, чтобы строка уникально владела динамическим объектом, который создан в куче, можно сделать так, чтобы несколько строк одновременно ссылались на динамический объект. Тогда в этом динамическом объекте будет счетчик ссылок — сколько одновременно строчек работает с ним. Код будет выглядеть так:
class string_impl {
char* data;
size_t size;
size_t capacity;
size_t use_count; // <===
// ...
};
Вы напишете class string_impl (можно написать его получше) и добавите use_count, т. е. счетчик ссылок — сколько строчек ссылается одновременно на динамический объект. Еще вы поменяете конструктор копирования, теперь он будет брать указатель на динамический объект от входной строки и увеличивать счетчик ссылок.
class string {
string_impl*impl;
public:
string(const string& s)
:impl(s.impl)
{
++impl->use_count;
}
};
Немного придется повозиться с неконстантными функциями, которые потенциально меняют строчку. Если две строки владеют динамическим объектом, и одна из них начнет менять его, то другая увидит изменения. Это побочный эффект, которым пользователи будут недовольны, ведь они сначала работали с одной строчкой, а потом она внезапно поменялась.
Нужно добавить проверку: если мы уникально владеем динамическим объектом, то есть счетчик ссылок равен 1, то мы можем делать с ним все, что угодно. Если счетчик ссылок не равен 1, мы должны вызвать new и memmove, создать еще один динамический объект и скопировать туда данные из старого объекта.
class string {
string_impl*impl;
public:
char& operator[](size_t i) {
if (impl->use_count > 1)
*this = clone();
}
return impl->data[i];
}
};
Деструктор тоже изменится. Он будет уменьшать счетчик ссылок и смотреть: если мы — последний владелец динамического объекта, тогда его нужно удалить.
class string {
string_impl*impl;
public:
~string() {
--impl->use_count;
if (!impl->use_count) {
delete impl;
}
}
};
Производительность вставки в std::map
В конструкторе от массива символов ничего лучше не стало, по-прежнему new и memmove. Зато дальше вызовется конструктор копирования строки при создании пары, который теперь не вызывает ни new, ни memmove. Когда пара будет вставляться в map, опять будет вызван конструктор копирования строки, который опять-таки не вызывает new и memmove.
Все деструкторы временных объектов тоже не вызовут delete — красота!
Итого, COW более чем в 2 раза ускоряет код в C++98.
Если сейчас мне кто-то скажет, что знает технологию, которая увеличивает производительность моего кода в 2-3 раза, я буду использовать ее везде.
В 90-е года многие библиотеки так делали. Например, есть библиотека QT, где COW присутствует практически во всех базовых классах.
Но технологии не стоят на месте. Наступают 2000-е года, появляются процессоры с Hyper-threading и многоядерные процессоры, причем не только серверные, но и пользовательские:
- Hyper-threading в процессорах Pentium 4.
- 2-ядерный процессор Opteron архитектуры AMD64, предназначенный для серверов.
- Pentium D x86-64 — первый 2-ядерный процессором для персональных компьютеров.
Теперь у каждого пользователя может быть более, чем 1 ядро. И наша строка уже плохо работает, потому что у нас общий счетчик ссылок.
Например, есть два потока, в них по строке, которые ссылаются на общий динамический объект. Если потоки работают со строками и одновременно решают их удалить, получается, что мы из двух потоков будем пытаться одновременно менять динамический счетчик ссылок use_count. Это приведет к тому, что либо возникнет утечка памяти, либо приложение аварийно завершится.
string: COW MT fixes
Чтобы это исправить, вводим атомарную переменную — сделаем вид, что в C++ 98 есть std::atomic. Теперь наш класс выглядит так:
class string_impl {
char* data;
size_t size;
size_t capacity;
atomic<size_t> use_count; //<=== Fixed
// ...
};
Все работает — замечательно! Почти…
Теперь у нас и конструктор копирования, и деструктор имеет в себе атомарную инструкцию , что не очень хорошо. Неконстантные методы превращаются в жуткое безобразие, потому что появляются граничные условия, которые редко возникают, но которые мы обязаны обрабатывать.
class string {
string_impl*impl;
public:
char& operator[](size_t i) {
if (impl->use_count > 1) { // atomic
string cloned = clone(); // new + memmove + atomic —
swap(*this, cloned);
// atomic in ~string for cloned; delete in ~string if other thread released the string
} // ...
}
};
Например, два потока владеют строчками. Эти строчки ссылаются на один и тот же динамический объект. Один поток решает поменять строку. Строка смотрит, что она неуникально владеет динамическим объектом и начинает объект клонировать. В этот момент второй поток говорит, что строчка ему больше не нужна и вызывает ее деструктор.
А первый поток все еще клонирует, вызывает new, memmove. Он закончил свои дела и вдруг понимает, что у него две строки, а нужна ему одна.
Придется еще предусмотреть логику и на такое, а это дополнительные проверки, возможно, дополнительный лишний вызов new и memmove, и опять много атомарных операций, что плохо.
Atomic
На X86 не атомарный инкремент — простое увеличение integer на единицу занимает один такт процессора [1]. Если сделать эту операцию атомарной, то она будет занимать от 5 до 20 тактов, если только одно ядро делает атомарную инструкцию и если это ядро последнее меняло атомарную переменную [2]. Если ядро не последним меняло атомарную переменную, то в районе 40 тактов.
Итого, такое решение в 5-40 раз медленнее только за счет того, что использована атомарная переменная. Дальше хуже.

Если несколько ядер одновременно работают с атомарной переменной, например, три ядра одновременно хотят сделать инкремент атомарной переменной, у нас будет ядро-счастливчик, которое начнет делать атомарный инкремент, остальные два ядра будут ждать от 5 до 40 тактов, пока ядро не закончит все свои действия.
Тут появляется второе ядро-счастливчик, которое начинает делать атомарную операцию, т. к. не оно последнее меняло атомарную переменную, это займет 40 тактов. Третье ядро все еще ждет. Чем больше ядер одновременно пытаются сделать атомарную операцию над одной и той же переменной, тем дольше последнее ядро будет ждать.
Так выглядит график ожидания последнего ядра:

В этом примере 16 ядер и последнее ядро ждет в районе 600 тактов. Это простой самого несчастливого ядра. Если просуммировать простои, то получится картина простоя получится квадратичная.

На 16 ядрах примерно 6000 тактов ушло в никуда.
Существуют системы, содержащие более 90 ядер, и если все они 90 ядер решат одновременно работать с одной и той же атомарной переменной, все будет очень печально.
COW
С++11
В C++11 появляются rvalue reference, что позволяет писать специальные классы и специальные методы, которые работают с временными объектами.
Например, move-конструктор для строки одинаково хорошо работает, если строка COW и если строка самая обычная базовая из средневековья, где динамически аллоцируется объект, и только одна строка им владеет.
string::string(string&& s) {
swap(*this, s);
}
Что здесь происходит? На вход приходит объект s. Он временный, мы знаем, что компиллятор его скоро удалит, что больше им никто пользоваться не будет, и мы можем забрать у него ресурсы. С ним можно делать вообще все, что угодно, — главное, чтобы для него потом можно было вызвать деструктор.
Забрали ресурсы. Мы — пустая строка, нам пришла строка с результатом, делаем swap. Теперь мы строка с результатом, а временная строка без всяких ресурсов — пустая.
Посмотрим, как это работает на нашем примере, если у нас строка без COW.
std::map<string, int> m;
m.insert(
std::pair<string, int>("Hello!", 1) // string("Hello!")
);
Создается строка от массива символов «Hello». Тут new и memmove — так же, как с COW.
Дальше — лучше. При копировании строки в пару у нас вызовется move-конструктор строки (
pair(string&&, int)). Пара видит, что строка временная, и забирает ресурсы из временного объекта. New и memmove не будет.При вставке пары в map, map видит, что пара у нас тоже временный объект (
m.insert(pair&&)). Map вызовет move-конструктор для пары, пара вызовет move-конструктор для своего содержимого, move-конструктор для строки.Без new и memmove строка перекочует внутрь map: 1 вызов new и 1 вызов memmove — так же, как с COW, но без атомарных операций.
Хорошо, а если мы хотим копировать строчку? Мы все разумные люди, и хотим копировать строчку, как правило, если мы хотим ее менять.
Без COW мы скопировали строчку, сразу вызывался new и memmove. Мы можем менять строчку и делать все, что угодно.
Если у нас COW строка:
- создаем новый объект строки с атомарным инкрементом общего счетчика ссылок;
- одну из этих строчек начинаем менять;
- строчка атомарно посмотрит, что мы не уникально владеем строкой, вызовет new, memmove, проведет дополнительные проверки, чтобы внезапно второй поток не уничтожил эту строчку, что у нас нужное количество строчек и т. д.
Результат тот же, что и без COW, но, как минимум, пара лишних атомарных операций появляется.
char& operator[](size_t i) {
if (impl->use_count > 1) { // atomic
string cloned = clone(); // atomic—
swap(*this, cloned); // atomic in ~string for cloned
}
return impl->data[i];
}
Неконстантные методы по-прежнему ужасны. Если мы хотим пройтись по нашей строке (первым десяти символам в строке), используя индексы, с COW строкой — это 10 атомарных операций над одной и той же атомарной переменной. Если два потока одновременно проходятся по одной и той же строке — большая беда.

В итоге COW-конструктор имеет атомарные операторы, деструктор, скорее всего, будет вызывать атомарные инструкции — везде много атомарных инструкций, которые нам не нужны. Мы их не просили, и это против правил C++. Мы платим за то, чем не пользуемся.
Начиная с C++11 COW строчки запрещены в стандарте. Там наложены специальные условия на строчку, что COW реализовать невозможно. Все современные имплементации стандартных библиотек не имеют COW строк.
COW устарел, осторожнее с его использованием.
Аккуратнее используйте COW в новых проектах. Не доверяйте статьям, которым больше 10 лет, перепроверяйте их. COW не показывает таких хороших результатов, как 20 лет назад.
Случаи, где COW все еще жжет
Если вы имели COW строчку и всем своим пользователям говорили: «У нас COW строка — она идеально все копирует, у нас все замечательно, у нас везде COW», пользователи могли заточиться под это, и писать код с учетом того, что ваши классы используют COW.
Например, пользователь мог написать класс bimap — это класс, который умеет искать как по ключу, так и по значению.
// COW legacy
class bimap {
std::map<string, int> str_to_int;
std::map<int, string> int_to_str;
public:
void insert(string s, int i) {
str_to_int.insert(make_pair(s, i));
int_to_str.insert(make_pair(i, std::move(s)));
}
Он мог написать его через два std::map, каждая из которых имеет строчку. Здесь строчка COW, пользователь об этом знает, как и то, что в map две копии строки. Пользователь знает, что они динамически будут ссылаться на один и тот же объект памяти, и что это эффективно по памяти. Если здесь COW строчку поменять на обычную, затраты по памяти увеличатся вдвое.
// COW legacy fix
class bimap {
std::map<string, int> str_to_int;
std::map<int, string_view> int_to_str;
public:
void insert(string s, int i) {
auto it = str_to_int.insert(make_pair(std::move(s), i));
int_to_str.insert(make_pair(i, *it.first)));
}
В C++17 это можно поправить, например, как в примере выше, заменив одну из строчек на string_view. По памяти получится точно также, но уберутся атомарные операции и код станет немного быстрее.
Одна оптимизация для string
Получается, что к той древней строчке 98 года, которая уникально владела динамическим объектом, мы добавили move-конструктор, и все — это идеальная строка? Ничего лучше сделать нельзя?
Вот что придумали люди. Они посмотрели на один из первых наших примеров, где создается map от строки и int, и туда вставляется пара, долго качали головой и говорили, как все плохо:
— Тут вызывается new и memmove. За new может стоять системный вызов и атомарные операции, а у нас еще нет C++14, где компилятор умеет оптимизировать new. Все очень плохо — давайте сделаем что-нибудь получше!
Люди придумали, как можно, не меняя размер строки — переменной std::string — хранить в ней символы, не аллоцируя динамически память. Они посмотрели на самый первый класс строки:
—У нас здесь указатель на 64-битной платформе — это 8 байт, у нас size тоже на 64-битной платформе — это опять 8 байт. Это 16 байт — в них можно сохранить 15 символов! Что, если пользоваться этими двумя переменными не как переменной-указателем и переменной size, а прямо поверх них располагать данные.
class string {
size_t capacity;
union {
struct no_small_buffer_t {
char* data;
size_t size;
} no_small_buffer;
struct small_buffer_t {
char data[sizeof(no_small_buffer_t)];
}small_buffer;
}impl;
}
Теперь внутри строки в примере выше находится union. Первая часть — это указатель на data и переменная size_t. Вторая часть union — структура — содержит data (маленький буфер размером с char* и size_t). В него влезает примерно 16 байт.
Если сapacity = 0 — это значит, что мы память динамически не аллоцировали и нам надо идти в impl small_buffer_t, и в data будет лежать наша строчка без динамической аллокации.
Если сapacity ≠ 0, значит, мы динамически где-то проаллоцировали память, и нужно идти в impl no_small_buffer_t. Там есть указатель на динамически проаллоцированный кусок памяти и переменная size.
Конечно, в примере немного упрощенный вариант. Некоторые стандартные библиотеки, например Boost, умеют хранить 22 символа и вдобавок терминирующий 0 без динамических аллокаций, не увеличивая размер строки. Все современные стандартные библиотеки используют этот трюк. Это называется Small String Optimization.
Эта штука хороша, во-первых, на пустых строчках. Они теперь гарантированно не аллоцируют память, и гарантированно вызов метода c_str() теперь не будет аллоцировать память.
Я знаю компании, которые переписывали std::string, потому что у них пустая строка динамически аллоцировала память. Не надо этого больше делать.
Во-вторых, например, наш «Hello!» влезет без динамической аллокации. Если в строчках хранятся логины пользователей, их имена и фамилии отдельно от имен, какие-то идентификаторы, города, страны, названия валют — как правило, все влезет в строчку без динамических аллокаций.
Но люди посмотрели и опять подумали, что медленно. Начиная с C++17, компилятор умеет оптимизировать memmove, его альтернативу — ту, которая находится в строке, на этапе компиляции. Но и этого показалось мало. В C++17 есть Guaranteed copy elision, который гарантирует, что в ряде случаев вообще никаких копирований и memmove не будет. Просто в map каким-то чудом образуется эта строчка без промежуточных переменных.
Со строкой разобрались, но ответы на некоторые уточняющие вопросы из зала здесь
— Больше-то не нужно!
— У меня реальный случай из практики. Замена COW-строки на строку со Small String Optimization ускорила проект на 7-15%, потому что большую часть времени мы работаем почему-то с маленькими строчками, которые в std::string влезают. Поэтому становится быстрее.
Можно ли использовать строчку, которая будет динамически в памяти хранить size и capacity? Можно. Тут подключатся проблемы с оптимизатором. Видя, что у нас указатель на какой-то участок памяти, он не сможет лучше оптимизировать эти переменные. Оптимизатор не сможет делать эвристики, основанные на size и capacity. Если же size и capacity расположены на стеке и оптимизатор видит это, он сможет делать на этом эвристики и лучше оптимизировать код.
— Да, хуже. Но количество байтов, которое есть в small_buffer, все то же.
— Пока все выглядит как реклама велосипедов на самом деле. Например, COW в GCC был до 2015 года, до выхода 5.1. Значит, нужно было писать велосипеды?
— Больше-то не нужно!
— Как? Например, все говорят, что классная штука Small String Optimization. Но, допустим, когда строка выделяется динамически, size и capacity можно засунуть в тот же самый буфер, в котором лежит строка. Тогда строка будет всего 8 байт. И если у меня в объекте много строк, это будет выгоднее?
— У меня реальный случай из практики. Замена COW-строки на строку со Small String Optimization ускорила проект на 7-15%, потому что большую часть времени мы работаем почему-то с маленькими строчками, которые в std::string влезают. Поэтому становится быстрее.
Можно ли использовать строчку, которая будет динамически в памяти хранить size и capacity? Можно. Тут подключатся проблемы с оптимизатором. Видя, что у нас указатель на какой-то участок памяти, он не сможет лучше оптимизировать эти переменные. Оптимизатор не сможет делать эвристики, основанные на size и capacity. Если же size и capacity расположены на стеке и оптимизатор видит это, он сможет делать на этом эвристики и лучше оптимизировать код.
— С широкими юникодными строками эта оптимизация хуже работает?
— Да, хуже. Но количество байтов, которое есть в small_buffer, все то же.
Разработка без оглядки на готовые решения. std::variant
На примере std::variant рассмотрим, что бывает, если люди пытаются велосипедостроительствовать, не заглядывая в чужие решения.
В C++17 принят класс std::variant — это умный union, который помнит, что он хранит. Мы можем написать std::variant<std::string, std::vector<int>>. Это значит, что вариант может хранить в себе либо строку, либо вектор. Если мы запишем в такой вариант слово «Hello», variant запомнит индекс шаблонного параметра в переменной t_index (что он содержит в себе строчку), по месту проаллоцирует строчку и будет ее хранить.
union {
T0 v0;
T1 v1;
T2 v2;
// ...
};
int t_index;
Если теперь попытаться записать туда вектор, std::variant посмотрит, что он хранит в себе строчку в данный момент, а не вектор, вызовет delete для строки, на месте строки сконструирует вектор и в какой-то момент обновит t_index.
Класс приняли в C++17, и люди по всему миру сразу кинулись его писать заново, переписывать, велосипедостроительствовать.
template <class... T>
class variant {
// ...
std::tuple<T...> data;
};
Выше — реальный код из опенсорсного проекта, видите в нем ошибку? Здесь вместо union получился struct.
Ниже — код из коммерческого проекта:
variant<T...>& operator=(const U& value) {
if (&value == this) {
return *this;
}
destroy(); // data->~Ti()
construct_value(value); // new (data) Tj(value);
t_index = get_index_from_type<U>(); // t_index = j;
return *this;
}
Здесь ошибка гораздо хуже и во многих имплементациях variant она присутствует. Здесь будут большие проблемы с исключениями.
Например, у нас variant, который хранит в себе std::string и мы пытаемся записать в него вектор. В строчке destroy вызовется delete для строки. С этого момента variant пустой, он ничего не хранит.
Потом на месте строки мы пытаемся создать вектор. Вектор передался по константной ссылке и мы вынуждены его копировать. Вызываем placement new и пытаемся скопировать вектор. Вектор — класс большой, в нем могут храниться пользовательские данные, которые при копировании могут кидать исключения. Допустим, мы кинули исключение. Оно выйдет из текущего блока, вызывая деструкторы всех локальных переменных, и выйдет в блок выше. Там исключение тоже вызовет деструкторы всех локальных переменных. Дойдет до того блока, где был объявлен сам variant и вызовет деструктор варианта.
variant<T...>& operator=(const U& value) {
if (&value == this) {
return *this;
}
destroy(); // data->~Ti()
construct_value(value); // throw; ...
// ...
// ~variant() {
// data->~Ti() // Oops!!!
Деструктор варианта смотрит, что у него записано в переменной index, которая еще не обновлена. В ней записано std::string, т. е. variant думает, что у него есть строка, которую надо удалить. А на самом деле на этом месте уже ничего нет, строка уже удалена. В этот момент вся ваша программа аварийно завершится.
Чтобы этого избежать, достаточно открыть интерфейс стандартной библиотеки и посмотреть, что std::variant имеет функцию valueless_by_exception, удивиться, что это такое, и посмотреть, зачем оно нужно. Можно открыть исходники Boost — там 2/3 кода посвящено этой проблеме.
Я говорю это все к тому, чтобы вы и все ваши подчиненные смотрели, как написаны велосипеды у других людей, во избежание таких печальных последствий. Это очень популярная ошибка. Она везде проскакивает.
Я привожу пример только variant, но в многих других классах есть подобное. Люди переписывают, думают, что что-то лишнее, не заглядывают в чужой код, и это приводит к катастрофическим последствиям.
Пожалуйста, смотрите в код, который вы переписываете или придумываете
заново. Такой подход значительно упростит вашу жизнь.
FORCE_INLINE
Самое время попрыгать по больным мозолям.
Можно найти проекты, где все методы помечены как FORCE_INLINE — буквально весь проект вдоль и поперек на гигабайты кода. У людей спрашиваешь:
— Зачем вы все пометили FORCE_INLINE?
— Мы написали маленький бенчмарк, проверили — с FORCE_INLINE быстрее. Мы написали и здесь маленький бенчмарк — проверили, с FORCE_INLINE быстрее. Мы протестировали все маленькими бенчмарками и везде с FORCE_INLINE быстрее — мы FORCE_INLINE запихнули во весь проект.
— Вы неправильно делали бенчмарк.
И с этого момента с людьми очень сложно спорить, потому что у них есть бенчмарк, а ты написать такой бенчмарк не можешь.
У процессора есть не только кеш данных
Современные процессоры — очень сложные устройства. Никто не знает до конца, как они устроены, даже разработчики процессоров.
"Большинство современных микропроцессоров для компьютеров и серверов имеют как минимум три независимых кеша: кеш инструкций для ускорения загрузки машинного кода, кеш данных для ускорения чтения и записи данных и буфер ассоциативной трансляции (TLB) для ускорения трансляции виртуальных (логических) адресов в физические, как для инструкций, так и для данных" [1].
Современный процессор не может выполнять вашу программу прямо с диска или прямо с оперативной памяти. Прежде, чем он начнет выполнять программу, он должен подтянуть ее в кеш инструкции. Только оттуда процессор может выполнять инструкции.
Некоторые процессоры имеют хитрый кеш инструкций, который делает дополнительную обработку команд, которые в него попадают. Но кеш инструкций — маленький, в него помещается мало кода. Если вы используете компилятор, который действительно делает FORCE_INLINE, когда вы его просите сделать FORCE_INLINE, у вас увеличивается объем вашего бинарного кода.

Представьте, что на рисунке выше ваша программа. Зеленым отмечено то, что поместилось в кеш. Это еще дополнительно ваш hot path — то место, где ваша программа тратит основное количество времени. Сейчас оно все поместилось в кеш процессора, в кеше инструкций простоя не будет.
Если вы добавите FORCE_INLINE, по бенчмаркам все будет замечательно, но код перестанет помещаться в кеш инструкций.

Когда вы дойдете до красной строчки, процессор скажет: «У меня нет инструкций новых, я должен подождать, пока они подтянутся из памяти». Если это где-то в цикле, он будет постоянно перещелкивать какие-то инструкции, подтягивать их себе из памяти в кеш. Это медленно.
Чтобы ваш бенчмарк правильно отражал реальное положение дел, он должен учитывать все 3 кеша — данных, инструкций и адресов. Для этого бенчмарк должен:
- в бинарном виде занимать столько же, сколько ваш production код;
- иметь приблизительно такое же количество функций и переходов, как ваш production код;
- вызывать методы так же, как ваш production код.
Другими словами, написать такой бенчмарк невозможно. Можно протестировать только ваш production код.
Если вы добавили FORCE_INLINE и ваш production код не стал лучше — лучше убрать FORCE_INLINE. Современные компиляторы умеют инлайнить. 10 лет назад они не умели этого делать хорошо, и FORCE_INLINE действительно в некоторых случаях помогал, например, на GCC. Сейчас нет.
Я говорю, что FORCE_INLINE — плохо, стоит отказаться от него в большинстве случаев, хотя иногда он может быть полезен.
Однако, разработчики компиляторов умные люди. Они видят, что пользователи пишут везде FORCE_INLINE и программы становится медленнее. Поэтому современные компиляторы имеют разные эвристики на игнорирование FORCE_INLINE. Некоторые компиляторы просто считают строчки внутри функции — если ваша функция длиннее трех строчек кода, FORCE_INLINE будет проигнорирован.
Ходит легенда, что есть компилятор, где люди очень сильно озаботились FORCE_INLINE, он их так достал, что они придумали следующую эвристику:
Если пользователь помечает FORCE_INLINE функцию, которую гарантированно не надо делать FORCE_INLINE, компилятор это запоминает и считает, сколько раз такое произошло. Если превышено некое пороговое значение, компилятор у себя выставляет галочку: «Пользователь не знает, что такое FORCE_INLINE и использует его не там, где нужно — игнорировать все FORCE_INLINE от пользователя».
Если вы вдруг написали программу, добавили туда десяток FORCE_INLINE и все стало замечательно быстрее, возможно, что вы пользуетесь этим компилятором. Смотрите ассемблерный код, если вам действительно нужно, чтобы что-то встраивалось, чтобы FORCE_INLINE в этом месте действительно был. Я сам удивлялся тому, что в ряде случаев компиляторы тихо игнорируют FORCE_INLINE.
И наоборот, компилятор может тихо игнорировать ваше «не инлайнить». Он подумает: «Ты не знаешь, что делаешь, написал не инлайнить, но я лучше знаю — я заинлайню».
Cлучай из практики
Я знаю очень умного программиста, который писал имплементацию B-Tree. Все было сделано на С++, на шаблонах, везде perfect forwarding, без всяких динамический аллокаций — просто идеально. Когда этот код стали проверять на одном из Performance Analyze, выяснилось, что исполнение не достаточно быстрое из-за того, что большую часть времени занимает ожидание инструкций в кеше инструкций.
Программист подумал, чуть упростил B-tree, убрал perfect forwarding, заменил его везде на константные ссылки, потому что B-tree никак не менял данные, которые ему приходили, убрал пару шаблонов, сделал код чуть компактнее, добавил noexcept, что тоже уменьшает объем бинарного кода.
В итоге код стал работать в 2 раза быстрее. Алгоритм не меняли — все то же самое, но код стал работать быстрее.
Если не верите мне, что FORCE_INLINE плохо, то рекомендую посмотреть лекции (1, 2) разработчика Clang Чендлера Каррута. Он говорит о том же, что и я, но короче, быстрее и на английском.

От «вредных» бенчмарков переходим к «вредным» советам.
Aliasing
Редко, когда разработка идет под одну платформу. Чаще бывает, что когда-то давным-давно разрабатывали под одну платформу, а теперь — под несколько.
Обычно, если компания начинается, как маленький стартап, она может выбрать себе одну платформу, под которую у нее уже есть заказчики. Постепенно компания растет, код становится популярнее, и приходит мысль портировать его на другие платформы.
Но в момент, когда люди начинают портировать на GCC, программа перестает работать: все компилируется, но тесты не проходят, программа выдает какой-то неадекватный вывод. Люди лезут на Stack Overflow или на другие ресурсы, посвященные программированию, задают этот вопрос и получают ответ:
— Добавьте волшебную опцию компилятора -fno-strict-aliasing и у вас все заработает.
И действительно — все начинает работать.
Объясню на примере, что делает эта опция (с именем функции я здесь не заморачивался).
bar qwe(foo& f, const bar& b) {
f += b;
return b * b;
}
Функция qwe принимает в себя две переменные: foo по ссылке, bar по константной ссылке. Это два разных типа данных. Внутри тела функции к f прибавляется значение b и выводится квадрат от b.
Ниже немного ассемблерного псевдокода, который скомпилирует компилятор, если подсунуть опцию -fno-strict-aliasing.
bar qwe(foo& f, const bar& b) {
// load b
// load f
f += b;
// load b
return b * b;
}
Компилятор:
- подгрузит в регистр значение переменной b,
- подгрузит в регистр значение переменной f,
- произведет операцию f += b,
- запишет значение f в память,
- подгрузит значение b опять в память,
- выполнит b2.
Тут большинство людей задаются вопросом, зачем мы второй раз подгружали b в регистр, она же уже в регистре.
А потому, что добавили опцию -fno-strict-aliasing. Она говорит компилятору о том, что два типа данных, абсолютно разных, никак друг с другом не пересекающихся, все равно могут находиться в одной и той же ячейке памяти. Исходя из этого компилятор начинает генерировать код.
Когда вы делаете f += b, компилятор думает, что возможно f и b находятся в одной и той же ячейке памяти, и запись в f меняет значение b. И это во всем вашем проекте — добавили опцию, во всем проекте код стал генерироваться хуже.
По разным замерам (например, этому и этому), в зависимости от кода и оптимизации, это дает от 5% до 30% просадки производительности. Все очень зависит от вашего кода. Если у вас просто системные вызовы и работа с сетью, возможно, ничего не изменится для вас с -fno-strict-aliasing. Но просто ее писать при сборке вашего проекта не совсем правильно.
Правильнее включить предупреждение компилятора (GCC умеет предупреждать, когда нарушается strict-aliasing) и исправить в этом месте нарушение strict-aliasing. Как правило, это нарушение происходит, когда вы используете reinterpret_cast для двух несвязанных друг с другом типов.
Вместо reinterpret_cast лучше использовать memcopy или memmove. Компиляторы GCC умеют их оптимизировать. Просадки производительности в том месте, где вы делаете memcpy вместо reinterpret_cast, быть не должно.
От лютой теории переходим к советам, которыми можно пользоваться в повседневной практике.
Советы на каждый день
Скорее всего, вы все это знаете, и, скорее всего, не используете.
Пример #1, vector
Ниже пример функции foo, в которой создается вектор от shared_ptr. Мы знаем, shared_ptr — ровно тысяча. Они вставляются в вектор, и он возвращается.
auto foo() {
std::vector< std::shared_ptr<int> > res;
for (unsigned i = 0; i < 1000; ++i)
res.push_back(
std::shared_ptr<int>(new int)
);
return res;
}
Первый недочет: если мы знаем, сколько элементов будет хранить наш вектор, стоит вызвать res. reserve(1000). Это заранее проаллоцирует нужное количество памяти, и вектор при вставке в него не будет пытаться угадать, сколько памяти нужно. Без reserve в C++11 и раньше вектор сначала примет значение под 2 элемента, потом под 4 элемента, 8, 16 и т. д. Все это время при изменении размера он будет вызывать new, delete, копирование либо move вашего типа данных, что медленно.
Если же вызвать res. reserve(1000), то вектор точно знает, что это 1000 элементов, никаких дополнительных move, new, delete не будет.
Начиная с C++14 компиляторам разрешено оптимизировать вызовы new. Некоторые компиляторы умеют это делать, но им должно повезти — не во всех случаях это получается. Если вы хотите быть уверены, что компилятор сгенерирует оптимальный код, лучше вставить reserve — хуже не будет.
Другое проблемное место в этом примере компилятор соптимизировать не сможет. Это вызов std::shared_ptr<int>. В этой строчке происходит две динамические аллокации:
- Первая — new int.
- Вторая скрыта внутри конструктора shared_ptr. Ему нужен счетчик ссылок, который он динамически аллоцирует где-то в куче.
Причем в памяти они находятся в разных местах. Если ваше приложение не использует weak pointers, или использует их не сильно, вместо строчки std::shared_ptr<int>(new int) имеет смысл написатьstd::make_shared<int>().
Make_shared сразу проаллоцирует кусок памяти, где может хранить и int, и счетчик ссылок. За счет того, что эти две переменные будут находиться рядом, это более кеш-дружелюбно. Работа с shared_ptr станет чуть быстрее, динамических аллокаций будет не две, а одна.
Итого, код в первом примере мы ускорили чуть более, чем в два раза,просто добавив reserve и заменив конструктор shared_ptr на make_shared.
Пример #2, for (auto v: data)
auto foo() {
std::vector<std::string> data = get_data();
// ...
for (auto v: data)
res. insert(
v
);
return res;
}
Код в примере, представленном выше, ужасен. Давайте его улучшать постепенно, причем, скорее всего, не с того места, которое вы заметили.
V здесь копия элемента из вектора. За пределами цикла, и после итераций цикла она нам особо не нужна. Мы можем сказать компилятору, что переменная v больше не используется, заменив v на std::move(v), превратить ее в rvalue, и тогда вставка в результирующий контейнер res произойдет по rvalue ссылке. Ресурсы из v будут просто перекинуты внутрь контейнера, что быстрее.
Массив vector data больше никак не используется, все, что в нем содержится, будет уничтожено при выходе из функции. Вместо того, чтобы копировать v, мы можем написать for (auto&& v: data), т. е. сделать ссылку на v (&& — здесь это тоже ссылка).
В итоге получится следующее: v — ссылка на элемент внутри data. Когда мы к этой ссылке применим std::move, ресурс заберется уже из вектора data — прямо из вектора строка перетянется внутрь контейнера res. Никаких динамических аллокаций в итоге не будет. По сравнению с изначальным кодом стало в 100500 раз быстрее.
Пример #3, vector
auto foo() {
std::vector<std::string> data = get_data();
// ...
std::string res = data.back();
data.pop_back();
// ...
return res;
}
Ситуация, как в примере выше, возникает чаще — то же самое, но из вектора мы запоминаем последний элемент, а потом этот последний элемент извлекаем.
Также можно соптимизировать: мы говорим std::string res = std::move(data. back()). После этого в res — значение последнего элемента (мы перетащили ресурсы из вектора в переменную res). Теперь back внутри вектора — это пустая строка, data.pop_back() просто изменит одну из внутренних переменных вектора. Никаких динамических аллокаций, никаких вызовов delete — все быстрее.
Пример #4, глобальные константы
В парсерах и протоколах зачастую есть массивы заранее известных строк. Люди часто пишут их так:
#include <vector>
#include <string>
static const std::vector<std::string> CONSTANTS = {
"Hello",
"Word",
"!"
};
Кажется, что это лишь немного не оптимально, но, в принципе, не так страшно. Это произойдет один раз при запуске вашей программы либо при подгрузке DLL.
Но когда проект очень большой, то в разных его частях может накопиться большое количество таких кусков кода — 10, 100, 1000. Инициализация переменной CONSTANTS происходит при запуске программы либо при подгрузке динамической библиотеки. В этот момент этот однопоточный код будет вызывать new, аллокации, инициализировать вектор строк и это может замедлить старт вашей программы либо подгрузку динамической библиотеки.
Для тех, кто пишет realtime приложения и приложения, которые должны быстро рестартовать, если они упали, это может быть критично. Если у вас тысячи и миллионы таких объектов, это замедлит старт программы.
Если вам массив констант нужен, и вы обращаетесь к нему только по индексу или используете его только в range-based for, вы можете заменить вектор на обычный массив. То есть вместо std::vector<std::string> CONSTANTS можно написать std::string_viewCONSTANTS[].
В итоге старт вашего приложения не будет делать дополнительных операций, вызывать new, дополнительно фрагментировать память.
Если вам нужна строгая гарантия, что это выполнится еще до того, как ваша программа запустится, вы можете
static const заменить на constexpr. Это будет обязывать ваш компилятор выполнить этот кусок кода до рантайма.Пример #5, наследование
// base. hpp
struct base {
// ...
virtual void act() = 0;
virtual ~base(){}
};
Выше базовый класс base, в нем метод act —ничего интересного. Интересно, когда мы от этого base наследуемся. Представьте себе, что вы разработчик в компании и вам сказали разобраться в чужом коде, причем вы видите только то, что идет ниже.
// something. cpp
struct some_implementation: base {
// ...
void act() { /* ... */ }
};
Вы видите только это, вы еще не заглядывали в описание base и вас интересует, что это за метод act, объявлен ли он в базовом классе, перегружаем ли мы его, и вообще, что здесь происходит.
Вы можете сделать код более читабельным, просто добавив слово override:
// something. cpp
struct some_implementation: base {
// ...
void act() override { /* ... */ } // <======
};
Он будет не только более читабельный, но и более безопасный. Новый человек, когда будет читать ваш код, увидит override и подумает: «Ага, значит, этот метод объявлен в базовом классе, мы его перегружаем, все в порядке».
Придет новый человек и будет рефакторить базовый класс, поменяет там сигнатуру метода act, добавит туда integer и на этапе компиляции словит ошибку, что в классе-наследнике мы пытаемся заоверрайдить класс, который уже не объявлен в базовом, которого нет.
В итоге он не поломает ваш код. Без override все скомпилируется, как-то будет работать, но будет ошибка на рантайме. На ее отлавливание может уйти много времени. С override сломается на компайлтайме. Человек, который будет делать рефакторинг, это заметит и поправит и здесь метод act.
Еще можно добавить final в первую строку:
struct some_implementation final: base. Это значит, что этот класс финальный, больше от него никто не наследуется. Нам от этого не очень жарко и не очень холодно, но от этого веселее компилятору.Компилятор видит, что класс final. Когда он видит some_implementation и переменную этого класса, и у этой переменной вызывается act, компилятор понимает, что от этого класса больше никто не наследуется, и в нем есть act. Он будет вызывать act без прохода по виртуальным таблицам, не будет различных динамических вещей — будет вызов act, как будто он не виртуальный.
Можно еще чуть-чуть улучшить, запихнув все в анонимный namespace:
// something. cpp
namespace { // <======
struct some_implementation final: base {
// ...
void act() override { /* ... */ }
};
} // anonymous namespace</strong>
Анонимный namespace — это как бы static на стероидах. Можно объявить переменную или функцию статиком, тогда она не будет видна наружу. Все, что вы объявите внутри анонимного пространства имен, будет видно только в этой единице трансляции.
Это хорошо тем, что развязывает руки оптимизатору. Он может делать больше оптимизаций, основываясь на том, что этот класс больше снаружи никто не использует. Оптимизатор также может подумать, что раз этот класс снаружи никто не использует, то его не надо экспортировать, что увеличит скорость загрузки и линковки приложения на рантайме.
Например, в OpenOffice была проблема, что этап динамической загрузки библиотек и линкер, который соединял все зависимости друг с другом, занимали 10 секунд, потому что много символов торчало наружу. Если использовать анонимный namespace, эта проблема станет меньше.
Пример #5, move constructors
Ниже move constructors для класса my_data_struct. В нем только вектор data.
class my_data_struct {
std::vector<int> data_;
public:
// ...
my_data_struct(my_data_struct&& other)
:data_(other.data_)
{}
};
Только move забыли. И еще noexcept. Давайте перепишем:
class my_data_struct {
std::vector<int> data_;
public:
// ...
my_data_struct(my_data_struct&& other) noexcept // <======
:data_(std::move(other.data_))
{}
};
Ряд стандартных контейнеров, например, vector, делают сложные подсчеты на этапе компиляции на основе того, помечены ли move-конструкторы как noexcept или нет. Если ваши move-конструкторы не помечены как noexcept, вектор может дополнительно аллоцировать память, когда он будет расширяться, и копировать элементы, вместо того, чтобы их перемещать. Это безобразие, потому что очень медленно.
Чтобы было быстрее, добавляем noexcept.
Эта запись не нравится большинству людей. Здесь непонятно, что написано, и нужно знать:
- как устроен std::vector;
- кидает ли он exception при move-конструировании;
- будет ли он кидать exception, если туда подставить необычный аллокатор;
- можно ли этот move-конструктор пометить noexcept;
- обзательно ли его нужно помечать noexcept.
Куча каких-то деталей, которые нам не нужны.
Надо все лишь написать вот так и все это станет заботой компилятора:
class my_data_struct {
std::vector<int> data_;
public:
// ...
my_data_struct(my_data_struct&& ) = default; // <======
};
Теперь компилятор сам расставит noexcept, constexpr, если сможет. Код из стандартной библиотеки будет работать быстрее — вам легче.
Caching divs
Хочу рассказать об одной штуке, на которую я недавно натолкнулся, и которая меня удивила.
// .h
extern const double fractions[256];
// .cpp
const double fractions[256] = { 1.0 / i, ... };
Люди закешировали деление единицы на число. Они создали extern массив на 256 элементов, в котором запомнили:
- первое число — это 1/0 (сделали 0).
- второе число по индексу 1 — это 1/1.
- число по индексу 100 — это 1/100 и т. д.
Далее работают с этим массивом везде, где нужна часть от 1.
Как вы думаете, так будет быстрее или медленнее? Давайте выясним.

Залезаем в талмуды, где описано, сколько тактов занимают инструкции, и обнаруживаем, что доступ к элементу массива, который находится в L1 кеше, занимает 5 тактов, а деление — 22-29 тактов. Итого такое кеширование может быть в 2-4 раза быстрее, но…
Недостатки cashing divs:
1. Оптимизатор не видит значения
- Нет возможности оптимизировать ближайшие инструкции. Массив объявлен в другой единице трансляции. Если у вас нет Link-time -оптимизации, или link-time-optimizer недостаточно продвинутый, он не будет видеть значения и не сможет оптимизировать, основываясь на значениях. Если у вас будет обращение к 1/100, а потом умножение на 100, то, если бы оптимизатор видел значение, сразу получилось бы 1 (плюс-минус). Но если оптимизатор не видит значение, он не сможет это соптимизировать и умножение на 100 останется.
- Нет возможности использовать этот массив в constexpr выражениях, шаблонах.
- Другая проблема — aliasing. Ссылка на double может указывать на ту же ячейку памяти, как в примере с -fno-strict-aliasing при изменении этого double компилятор будет перечитывать значение из памяти для этой переменной.
Это серьезное негативное влияние на производительность.
При этом компилятор даже не поверит вам, если вы везде напишите const, потому что он не оптимизирует, основываясь на const. Если вы где-то написали const, компилятор проигнорирует это, потому что где-то в другом месте вы могли написать const_cast.
2. Мы потратили кучу времени на обсуждение этого...
То, что мы потратили кучу времени на его обсуждение, тоже плохо в этом примере. Когда вы увидите его в чужом коде, вы тоже потратите кучу времени, чтобы разобраться, что это за безобразие.
3. Мы потратили 1Kb L1 кеша из 16/32Kb
Люди, которые разрабатывают компиляторы, пишут книги на эту тему и защищают сложные теории, говорят, что в современном мире производительность системы ограничена не скоростью процессора, а зачастую работой с памятью:
«В то время, как традиционно компиляторы уделяли большее внимание оптимизации работы процессора, сегодня больший упор следует делать на более эффективное использование иерархии памяти».
Ахо, Сети, Ульман. Компиляторы. Принципы, технологии, инструменты. 2ed.2008
Мы потратили 1Kb кеша 1-го уровня на то, чтобы сохранить массив, и другие полезные данные теперь туда не поместятся.
Разработчик стандартной библиотеки C под Linux Ульрих Дреппер написал труд «What Every Programmer Should Know About Memory», то есть о том, что каждый программист должен знать о памяти. В нем намешана серьезная теория и физика, но есть замечательный простой пример важности кеша. На куске кода с переумножением матриц, не меняя практически алгоритм и ассемблерные инструкции, Ульрих Дреппер ускорил производительность в 10 раз просто за счет более эффективной работы с кешом данных.
Кеш данных очень важен. Не надо туда писать то, чем вы редко
пользуетесь.
Станет ли быстрее с таким кешированием единиц или нет — непонятно:
- Если у вас критически важный кусок памяти, где вы часто делаете эти операции, где их особо нельзя соптимизировать — да, может стать лучше.
- Если у вас обобщенный код, где вы много работаете с другими данными, и это одно-единственное вычисление — вы тратите лишний кеш. Скорее всего, станет хуже.
Но люди написали кучу кода, а мы потратили кучу времени на его разбор. Когда вы его встретите в чужом продакшн-коде, вы тоже потратите кучу времени на разбор, ваша производительность упадет. Работодатель будет недоволен.
Мы уже поговорили о «вредном», перейдем к хорошему.
Идеальный велосипед
Как написать свой идеальный велосипед, свою идеальную программу, я вам не скажу. На это есть куча книг, часть из них правильная, часть — не очень. Но, если вы написали программу, библиотеку, которая:
- кроссплатформенная;
- быстрая;
- полезная;
- функциональная
- пригодится большому количеству людей,
добро пожаловать в рабочую группу РГ21, мы:
- Поможем с формальностями.
- Поможем с принятием в Boost.
- Поможем с написанием proposal.
- Защитим ваши интересы на международном заседнии при ISO, передадим отзывы на ваше предложение.
С первого раза сделать proposal не просто, потому что есть специальные термины, которых надо остерегаться, и определенные формальности, которые надо соблюдать. Если вы просто напишете proposal и отправите его в Комитет, скорее всего, дальше ничего не произойдет, если вы (или доверенный человек) не прибудете в Комитет и не защитите вашу идею перед международным собранием. Приходит много предложений, и в первую очередь приоритет отдается тем, которые лично представляют и защищают.
Идеи в разработке РГ21:
- P0539R0: wide_int by Игорь Клеванец, чтобы можно было писать int256, int512, int4000000;
- P0275R1: Dynamic library load;
- ConcurrentHashMap by Сергей Мурылев, Антон Малахов — пока очень ранний этап;
- Constexpr: «D0202R2: Constexpr algorithm», std::array — добавление везде, где только можно;
- Улучшение поддержки динамических библиотек в стандартной библиотеке (?dlsym?);
- Stacktrace в стандартной библиотеке, чтобы можно было иметь класс Stacktrace, который в поток можно вывести и посмотреть Stacktrace, например, что происходило до этого, почему мы здесь упали.
- Множество мелочей, которые делают все в ISO WG21 — это исправление мелких недочетов стандарта, стенографирование заседаний и куча других дел.
Заходите на сайт рабочей группы https://stdcpp.ru/, там можно предложить свою идею, посмотреть, что предлагают другие, а самые интересные предложения мы обсудим вместе.
Узнать о других докладах Антона, посмотреть его презентации, публикации и множество другой полезной информации можно здесь — http://apolukhin.github.io/
Эта статья — расшифровка одного из лучших докладов наших друзей C++ Russia 2017, ближайшая их конференция в этом году пройдет уже в апреле с 19 по 21 число.
Открывать конференцию в этом году будет Jon Kalb, разработчик с 25-летним стажем
В течении этого времени успел поработать в Amazon, Microsoft, Netscape,
Yahoo и других компаниях. Jon — организатор конференции CppCon. Автор книги
C++ Today: The Beast is Back.
А мы пока активно работаем над программой фестиваля конференций Российские интернет-технологии (РИТ++), до 9 апреля еще можно успеть подать заявку на доклад, и выходим на финишную прямую. Обещаем, что серверный блок будет представлен очень хорошо, хотя и про другие можно сказать то же самое.
