Если вы слышали о законе Беттериджа, то уже догадываетесь, как обстоят дела с безопасностью контейнеров. Но односложного ответа в любом случае недостаточно, поэтому рассмотрим, какие существуют решения для создания изолированных контейнеров и защиты вашей инфраструктуры от вредоносных действий изнутри контейнеров и чего они на самом деле позволяют добиться.
Готовых рецептов будет немного, зато поймете, от чего отталкиваться в собственных исследованиях безопасности контейнеров.
О спикере: Александр Хаёров (allexx) 10 лет занимается разработкой, в основном веб-проектами, связанными с инфраструктурой, а сейчас руководит разработкой в Chainstack. В этой должности приходится примерять на себя самые разные роли и заниматься всем: от классической разработки до принятия технических решений и управления людьми. Это позволяет исследовать разные темы, в том числе ту, о которой пойдет речь в статье — далее от первого лица.
Я не разработчик ядра Linux, не специалист по информационной безопасности или DevSecOps. Я потребитель технологий контейнеризации. Команда Chainstack предоставляет multi-cloud платформу для блокчейна и строит инфраструктуру на основе контейнеров, а именно Kubernetes. Поэтому исследовать безопасность контейнеров будем с точки зрения потребителя технологии, а не разработчика самой технологии или специалиста по поиску уязвимостей.
Темы безопасности и контейнеров очень обширны, не претендуя на общность, расскажу только о том, с чем столкнулся на практике.
Когда говорят о безопасности кластеров, чаще всего подразумевают стойкость к атакам извне.

Когда хакер пытается проникнуть в кластер, он делает это с помощью нагрузки на кластер, использует доступные снаружи ресурсы или атакует инфраструктурные элементы. В этой статье мы это как раз обсуждать не будем.
Поговорим о том, что будет, если в кластере есть «плохой» контейнер — контейнер, который позволяет атаковать вашу инфраструктуру изнутри. Он может поражать как другие контейнеры, так и всю инфраструктуру целиком.
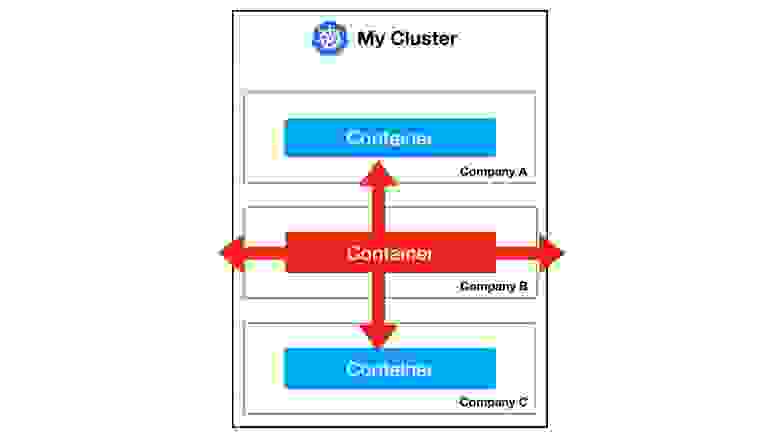
Объясню, почему важно защититься от этого в нашей компании. У нас много пользователей, поэтому мы работаем в режиме multi tenancy (мультиарендности) — на один кластер попадает нагрузка от различных компаний. Мы делаем managed-инфраструктуру, и приложения нескольких компаний-клиентов работают на одном кластере.
Схематично: есть Pod, иными словами запущенный runtime, и некое хранилище. Вся наша нагрузка — это вычислительные узлы, нам никак не обойтись без сохранения состояния.
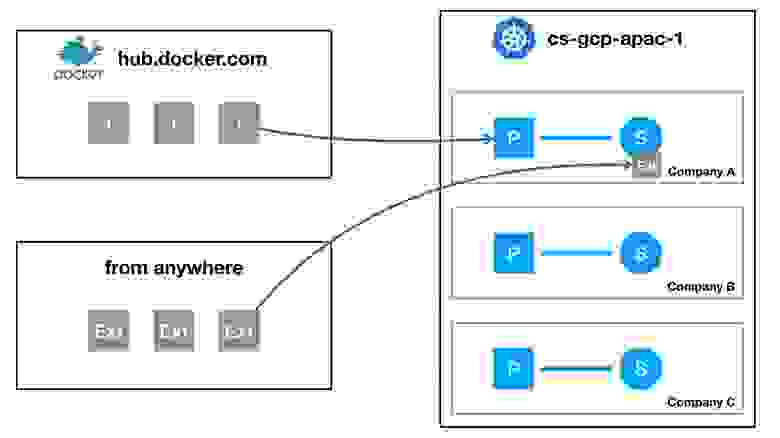
Мы используем Docker Hub для поиска нужных docker-образов для runtime. К счастью, многие из них являются официальными: вендоры решений, которые мы запускаем и делаем управляемыми (managed), уже научились их паковать и отправлять в Docker Hub. Мы запускаем их в нашем кластере, чтобы получить runtime. Однако у нас есть такое понятие, как расширение — это может быть, например, дополнительное стороннее приложение, написанное на Java для блокчейн-платформы Corda.
Мы можем скачать официальный образ Corda от компании R3, который верифицирован, и скорее всего ему можно доверять. Если мы запустим этот образ в нашем кластере, все будет хорошо. Но наши пользователи могут устанавливать расширения, и это в принципе основной сценарий использования платформы Corda, когда вы делаете смарт-контракты. А так как это Java-приложения, в принципе может произойти всё что угодно.
Мы думаем над тем, чтобы проводить аудит таких приложений, но это отдельная сложная задача. Пока исходим из того, что не знаем, что там в этом приложении. Загружая приложение в persistence или state, мы перезагружаем runtime и фактически даем возможность выполнять различные действия прямо в runtime. Тем самым потенциально воздействовать на кластер изнутри. Это было главной причиной для исследования вопроса безопасности контейнеров.
Рассматривая типовой сценарий, который возникает во многих инфраструктурах, попытаемся понять, где могут быть проблемы. Но сначала зайдем с другой стороны, и посмотрим, какие вообще могут быть проблемы, вдруг это все надуманное и такой сценарий в принципе невозможен.
Так как безопасность или DevSecOps не моя специальность, я не слежу за каждой новостью о найденных уязвимостях. Я просто посмотрел, что происходило в 2019 году, и моё внимание привлекло две уязвимости.
2019-02-11 CVE-2019-5736 — Breaking out of Docker via runC (Score 9.3). Подробности уязвимости хорошо описаны в этой статье, а нас как потребителей больше всего интересует следующая часть описания:
2019-08-28 CVE-2019-11245 — Containers attempt to run as uid 0 (Score 7.8). Менее страшная, но зато более свежая уязвимость заключается в том, что runAsUser в Kubernetes всегда может иметь root-доступ.
Это только малая часть, но и она заставляет задуматься о том, что угроза безопасности изнутри контейнеров существует и может быть серьезной.
В нашей жизни огромное количество абстракций: мы оперируем Kubernetes, кто-то использует Istio, а кто-то запускает базы данных в контейнерах. Поэтому молодые, да и опытные разработчики тоже не всегда представляют себе, как работают эти технологии. А это важно для понимания сути проблем и поиска возможных способов их решения.
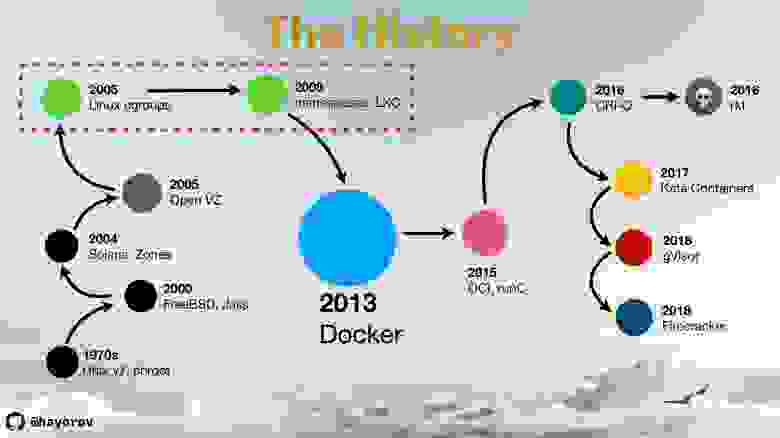
Базовые достижения на пути к контейнеризации удобно представить в виде roadmap.

В 1970-х появился chroot в Unix, и он до сих пор существует. Потом появился FreeBSD Jail, Zones в ОС Solaris. 2005-й — важная лично для меня веха — Open VZ. Я работал в Parallels и был причастен к поздним этапам разработки, для меня это было открытие контейнеров как таковых.
На карте я выделил Linux cgroups и namaspaces с LXC, потому что это очень важные вехи во всей истории развития технологий контейнеризации.
А уже потом, в 2013 году появился Docker, и в принципе можно было бы рассматривать технологии только с этого момента, но дальше я покажу, почему предыдущие этапы тоже нужно иметь в виду.
Добавим немного деталей в представление docker-стека. Наверху находится демон, который позволяет все запускать, а внизу облачное или физическое железо. Не забудем о containerd, вспомним, что такое shim и что это за runtime, который называется runC.
Тем не менее, все четыре прямоугольника из правого верхнего угла схемы, включая doсkerd, можно так или иначе поменять. А вот слой Linux Kernel и базовые модули ядра никогда не меняется.

cgroups и namespaces — это два кита, на которых стоит контейнеризация в целом. На чем бы мы ни работали, мы всегда их используем.
О модулях, выделенных на схеме голубым цветом, помнят скорее всего только системные администраторы. AppArmor (или SeLinux — нет принципиальной разницы между этими инструментами), seccomp, capabilities отвечают за то, чтобы изоляцию сделать действительно изолированной, чтобы научиться управлять ресурсами и фильтровать процессы.
Linux Kernel и эти модули — это базис любого контейнерного решения: старого, современного, улучшенного, модифицированного. Все, что находится выше по стеку, будет так или иначе использовать функциональность Linux-ядра.
Вернемся к истории и посмотрим, что же происходило после знакового 2013-го.
Docker внес существенный вклад в развитие многих аспектов технологий, но, на мой взгляд, важнейший — это OCI (Open Container Initiative). В том же 2015 году появился runC, который мы все используем.
В 2016 появились CRI-O и rkt. Позже Red Hat приобрел CoreOS, в том числе runtime Rocket и сосредоточил все усилия на том, чтобы делать CRI-O, а rkt в 2019 закрыли.
Ветвь, которая на схеме начинается с Kata Containers, не является логическим продолжением runtime, но имеет большое значение. В частности мы попробовали gVisor для того, чтобы изменить состояние безопасности изоляции в контейнерах, и о результатах этого эксперимента дальше пойдет речь.
Firecracker от AWS не имеет прямого отношения к контейнерам, но кажется мне важной вехой в развитии той проблематики, которую мы обсуждаем. Начать знакомство с тем, как устроены эти микровиртуалки и как позволяют добиться multi tenancy, можно начать с доклада архитектора AWS.
Для полноты картины исторического базиса напомню различия контейнеров и виртуальных машин.
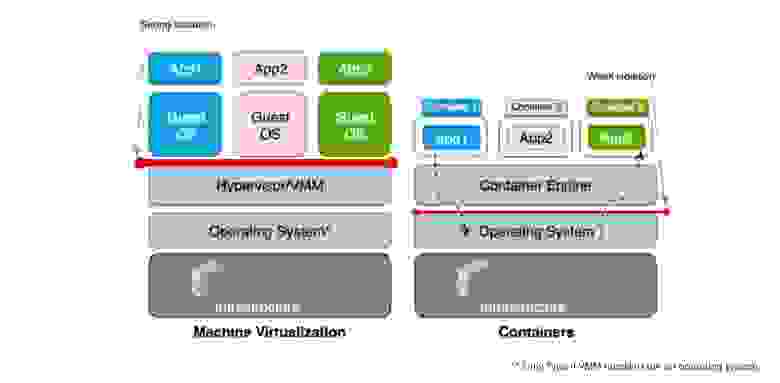
Основное отличие в том, где мы проводим черту изоляции и что находится между железом, инфраструктурой и приложением. В случае виртуализации есть гостевая операционная система, в контейнере её нет — есть одна операционная система, в которой все это магическим образом работает. Тут и кроется наша проблема, проблема в слабой изоляции.
Покажу подробнее, что плохого в слабой изоляции: есть контейнер, который работает на нашей машине, есть одно-единственное ядро машины и может произойти то, что называется «Escape».

В архитектуре контейнерной инфраструктуры нет никаких барьеров. Есть изоляция, можно запускать разную нагрузку на одном ядре, чтобы она не мешала друг другу, но это не означает, что процесс живет в «security sandbox».
Изучив историю, мы поняли, что раз уж архитектура такова, что всё работает на одном ядре, надо повышать безопасность этого ядра.
Мы определили три главных для нас требования к решению: безопасность, zero config или очень простая конфигурация, легковесность. То есть мы хотим, чтобы запускаемые контейнеры были безопасны для инфраструктуры, и мы не хотим их конфигурировать, либо конфигурирование должно быть минимальным. Это требование появилось из опыта наших системных администраторов, которые активно настраивали и конфигурировали SELinux и AppArmor и знали, что всё связанное с безопасностью непременно нужно тщательно конфигурировать. А легковесность — это собственно то, за что все любят контейнеры. Все бы и дальше использовали виртуальные машины, если бы не быстрый и удобный запуск и старт контейнеров.
Мы стали искать, какие уже доступны решения, как можно в текущей парадигме и состоянии развития инструментов, а это было в конце 2018-го, обезопасить контейнеры.
Мы решили использовать gVisor не потому что провели масштабное исследование, а просто как раз в это время прошла конференция Google Cloud и gVisor был выпущен в open source. Было много информационного шума, на который мы попались.
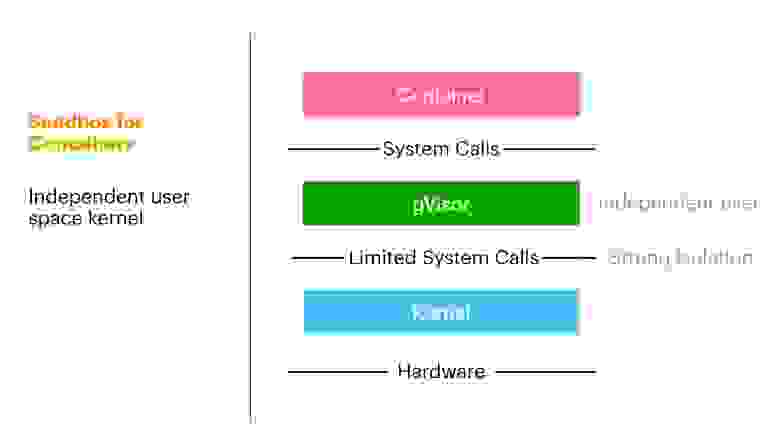
Суть в том, что запускается все тот же контейнер, с точки зрения интерфейсов ничего не меняется. Системные вызовы остаются, но теперь между ними и контейнером есть gVisor, который не дает случиться тому «Escape», потому что работает в user space, а в userspace по определению права ограничены. Таким образом добавляется промежуточный компонент и получается своего рода прокси в виде gVisor, что и дает изоляцию.
Архитектура gVisor несколько раз обновлялась. Постепенно разработчики адаптировали её для OCI-совместимости. Это практичнее промежуточных решений, потому что не требует изменений в конфигурации.
Все начинается с того, что клиент (в нашем случае docker-кластер) обращается к OCI-совместимой системе. Runtime называется runsc от «secure» и является имплементацией OCI runtime.
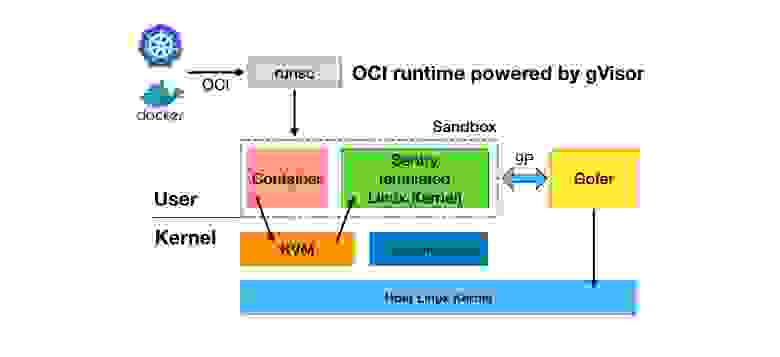
А дальше происходит интересное: runsc создает контейнер и рядом с ним деплоит еще один сервис — Sentry, который эмулирует Linux Kernel (то самое ядро, которое находится в user space). Связку контейнера и эмулированного ядра можно назвать песочницей.
На уровне ядра находится всё тоже самое, что там и было — настоящий Linux Kernel.
gVisor развивался эволюционно, и сначала выполнял простую функцию: перехватывал системные вызовы из контейнера с помощью Sentry, чтобы выполнить их в user space. Самым простым способом перехвата системных вызовов является ptrace. Он удобен тем, что работает практически везде и не требует виртуализации. На ранних этапах это был основной режим работы gVisor, а позже появился более продвинутый вариант, который предлагает использование KVM, то есть виртуализации. В большой части наших экспериментов использовался вариант с ptrace.
Таким образом на уровне ядра находится KVM или классическая связка namespaces и seccomp, которая позволяет фильтровать системные вызовы ядра.
Дополнительный компонент Gofer (неизвестно, как он связан с Golang) обрабатывает все системные вызовы к файловой системе, а все вызовы не связанные с диском обрабатывает Sentry.
9P между Sentry и Gofer — это Plan 9 — интерфейс взаимодействия через файловую систему между разными частями системы. Сама операционная система не взлетела, но некоторые её части оказались очень полезны и стали использоваться 40 лет спустя.
Пройдя все нудные аспекты архитектуры, давайте наконец-то поговорим, как это все запустить.
Я пользователь macOS, порядок действий там достаточно нетривиальный, поэтому делюсь инструкцией.
Во-первых, не пробуйте собирать runsc на macOS локально. Runsc для этого не предназначен и вообще не должен запускаться на macOS. Но это и не нужно, на macOS у вас есть Docker, который естественно работает под Linux. Поэтому вам нужен собранный бинарь runsc на Linux. Возьмите и скачайте его (да, мы все еще говорим о безопасности):
Дальше нужно найти настройку docker-демона в macOS. Сложный способ — через UI в настройках найти «Daemon», выбрать «Advanced» и т.д. Прочитать JSON мне кажется легче:
В этот файл нужно дописать следующее:
То есть создать новый runtime и указать путь до бинарного файла. Для macOS важно смонтировать папку с бинарником в docker. Как ни странно, docker без проблем допускает еще один runtime.
В итоге получается такая связка: вы пробрасываете бинарный файл runsc с macOS в docker, который работает на Linux, и прописываете это в конфигурации. Docker перезапускается, можно использовать это:
Обратите внимание, что runsc не runtime по умолчанию.
Это как будто, простой способ, но есть еще и вариант для продвинутых пользователей. На самом деле он не такой и сложный, потому что технологии довольно дружелюбные: GKE — Google Kubernetes Engine — дружелюбный для запуска gVisor (кто бы, конечно, мог подумать, но это стало так только осенью 2019).
Нужно создать новый node pool:
К сожалению, без этого в managed Kubernetes это запустить никак не получится. Создавая новый node pool, нужно указать параметр sandbox с типом gVisor.
Проверить новый node pool можно так:
Всё работает, можно создавать свои приложения или модифицировать имеющиеся манифесты.
В спецификации появился новый параметр
Казалось бы, этого достаточно, чтобы все заработало. Но, например, у нас не работала сеть, потому что мы использовали разные серверы, а по умолчанию поддержка сети выключена. Чтобы взаимодействовать с портами, вспоминаем Linux-модуль capabilities:
Модуль
Проверим теперь работоспособность этого решения, а главное, узнаем, что теряем на его запуске.
В первую очередь, мы фильтруем системные вызовы, то есть запускаем их внутри userspace и заново реализовываем. gVisor — это по сути новый Linux, написанный на Go, который на сегодняшний день реализует большую часть системных вызовов — 251 из 347. Однако это ничего не говорит о работоспособности приложений, которые вы используете. В список поддерживаемых приложений входят, например: Elasticsearch, Jenkins, MariaDB, Memcached, MongoDB, Node, PHP, PostgreSQL, Prometheus.
Мы выделили те приложения, которые посчитали востребованными для наиболее широкого круга разработчиков: Golang, Java8, Python, nginx. Все они отлично работают с точки зрения совместимости. Мы не использовали какие-нибудь эзотерические способы, но, например, Python веб-сервер на Django или iohttp не доставили проблем — можете пробовать и локально, и на кластере.
С точки зрения производительности нас интересует цена нестандартного runtime, ptrace, перехвата и запуска. Любые метрики и бенчмарки можно бесконечно критиковать, поэтому я в своей оценке буду основываться на разнице показателей без gVisor и с его использованием.
Таким образом, главная проблема в большом количестве I/O операций, которые превращаются в системные вызовы и поэтому работают медленно. Например, если в вашем приложении есть Redis, который умеет хитро оптимизировать работу с диском и использовать другие системные вызовы, чем обычно используются при работе iohttp-сервера, то производительность просядет не так сильно.
В нашем случае все приложения на Django, flask, iohttp показали примерно 50% снижение производительности — что, прямо скажем, ужасно.
Авторы этой научной статьи подошли к вопросу сравнения производительности гораздо серьезнее, собрали большое число данных и сравнили варианты с ptrace и KVM — результаты с KVM чуть лучше.
Вообще в конце 2019 появилось много материалов, с которыми стоит познакомиться, если вам интересна безопасная работа контейнеров. В частности, теперь есть официальный мануал по запуску gVisor в Google Cloud Platform, а когда мы начинали работу с gVisor, со всем приходилось разбираться самостоятельно.
Отдельно отмечу, что таким образом невозможно получить прямой доступ к железу, поэтому использовать GPU не получится.
Несмотря на все аспекты обеспечения безопасности контейнеров, которые мы рассмотрели в этой статье, ответ на заглавный вопрос — однозначно нет.
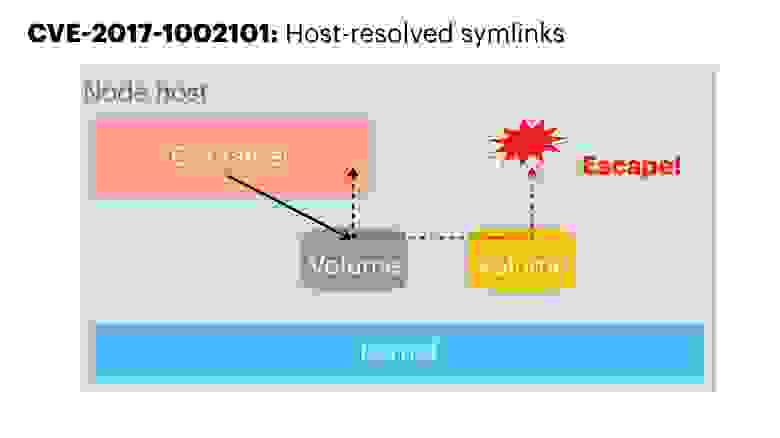
Мы рассмотрели только runtime-уровень, но можно обратиться к почти любой другой уязвимости, например, вспомнить, что у нас есть файловая система, которую можно монтировать, или symlinks, которые легко могут породить тот же самый Escape.
Тема комплексная, и мы далеки от того, чтобы сделать контейнеры полностью безопасными. Тем не менее есть некоторые варианты, что делать:
Наш опыт с gVisor говорит о том, что известные проблемы и уязвимости можно закрыть другими средствами не теряя в производительности. А получить полноценную изоляцию в контейнерах пока всё равно невозможно. Именно поэтому в моих советах нет использования gVisor :(
Контакты спикера Александра Хаёрова и все выступления на конференциях: https://hayorov.me (бонусом велосипедная активность в Strava :)
Готовых рецептов будет немного, зато поймете, от чего отталкиваться в собственных исследованиях безопасности контейнеров.
О спикере: Александр Хаёров (allexx) 10 лет занимается разработкой, в основном веб-проектами, связанными с инфраструктурой, а сейчас руководит разработкой в Chainstack. В этой должности приходится примерять на себя самые разные роли и заниматься всем: от классической разработки до принятия технических решений и управления людьми. Это позволяет исследовать разные темы, в том числе ту, о которой пойдет речь в статье — далее от первого лица.
Я не разработчик ядра Linux, не специалист по информационной безопасности или DevSecOps. Я потребитель технологий контейнеризации. Команда Chainstack предоставляет multi-cloud платформу для блокчейна и строит инфраструктуру на основе контейнеров, а именно Kubernetes. Поэтому исследовать безопасность контейнеров будем с точки зрения потребителя технологии, а не разработчика самой технологии или специалиста по поиску уязвимостей.
Темы безопасности и контейнеров очень обширны, не претендуя на общность, расскажу только о том, с чем столкнулся на практике.
Безопасность кластера
Когда говорят о безопасности кластеров, чаще всего подразумевают стойкость к атакам извне.

Когда хакер пытается проникнуть в кластер, он делает это с помощью нагрузки на кластер, использует доступные снаружи ресурсы или атакует инфраструктурные элементы. В этой статье мы это как раз обсуждать не будем.
Поговорим о том, что будет, если в кластере есть «плохой» контейнер — контейнер, который позволяет атаковать вашу инфраструктуру изнутри. Он может поражать как другие контейнеры, так и всю инфраструктуру целиком.

Объясню, почему важно защититься от этого в нашей компании. У нас много пользователей, поэтому мы работаем в режиме multi tenancy (мультиарендности) — на один кластер попадает нагрузка от различных компаний. Мы делаем managed-инфраструктуру, и приложения нескольких компаний-клиентов работают на одном кластере.
Схематично: есть Pod, иными словами запущенный runtime, и некое хранилище. Вся наша нагрузка — это вычислительные узлы, нам никак не обойтись без сохранения состояния.

Мы используем Docker Hub для поиска нужных docker-образов для runtime. К счастью, многие из них являются официальными: вендоры решений, которые мы запускаем и делаем управляемыми (managed), уже научились их паковать и отправлять в Docker Hub. Мы запускаем их в нашем кластере, чтобы получить runtime. Однако у нас есть такое понятие, как расширение — это может быть, например, дополнительное стороннее приложение, написанное на Java для блокчейн-платформы Corda.
Мы можем скачать официальный образ Corda от компании R3, который верифицирован, и скорее всего ему можно доверять. Если мы запустим этот образ в нашем кластере, все будет хорошо. Но наши пользователи могут устанавливать расширения, и это в принципе основной сценарий использования платформы Corda, когда вы делаете смарт-контракты. А так как это Java-приложения, в принципе может произойти всё что угодно.
Мы думаем над тем, чтобы проводить аудит таких приложений, но это отдельная сложная задача. Пока исходим из того, что не знаем, что там в этом приложении. Загружая приложение в persistence или state, мы перезагружаем runtime и фактически даем возможность выполнять различные действия прямо в runtime. Тем самым потенциально воздействовать на кластер изнутри. Это было главной причиной для исследования вопроса безопасности контейнеров.
Рассматривая типовой сценарий, который возникает во многих инфраструктурах, попытаемся понять, где могут быть проблемы. Но сначала зайдем с другой стороны, и посмотрим, какие вообще могут быть проблемы, вдруг это все надуманное и такой сценарий в принципе невозможен.
Уязвимости и угрозы безопасности
Так как безопасность или DevSecOps не моя специальность, я не слежу за каждой новостью о найденных уязвимостях. Я просто посмотрел, что происходило в 2019 году, и моё внимание привлекло две уязвимости.
2019-02-11 CVE-2019-5736 — Breaking out of Docker via runC (Score 9.3). Подробности уязвимости хорошо описаны в этой статье, а нас как потребителей больше всего интересует следующая часть описания:
«… allows a malicious container to (with minimal user interaction) overwrite the host runc binary and thus gain root-level code execution on the host. The level of user interaction is being able to run any command… as root ...».То есть то, что, проделав несколько нехитрых операций, можно получить root-доступ до host-машины. Причем уязвимости были подвержены многие системы: Debian, Docker, Red Hat, Ubuntu, AWS, GCP, Azure и т.д. В результате практически все вендоры, ОС, облачные провайдеры выпустили свои бюллетени и внесли определенные изменения.
2019-08-28 CVE-2019-11245 — Containers attempt to run as uid 0 (Score 7.8). Менее страшная, но зато более свежая уязвимость заключается в том, что runAsUser в Kubernetes всегда может иметь root-доступ.
Независимо от настроек «...for pods that do not specify an explicit runAsUser attempt to run as uid 0 (root) on container restart, or if the image was previously pulled to the node. If the pod specified mustRunAsNonRoot: true, the kubelet will refuse to start the container as root. If the pod did not specify mustRunAsNonRoot: true, the kubelet will run the container as uid 0».К счастью, уязвимости CVE-2019-11245 подвержены только отдельные версии Kubernetes v1.13.6 и v1.14.2.
Это только малая часть, но и она заставляет задуматься о том, что угроза безопасности изнутри контейнеров существует и может быть серьезной.
История развития технологий контейнеризации
В нашей жизни огромное количество абстракций: мы оперируем Kubernetes, кто-то использует Istio, а кто-то запускает базы данных в контейнерах. Поэтому молодые, да и опытные разработчики тоже не всегда представляют себе, как работают эти технологии. А это важно для понимания сути проблем и поиска возможных способов их решения.
Базовые достижения на пути к контейнеризации удобно представить в виде roadmap.

В 1970-х появился chroot в Unix, и он до сих пор существует. Потом появился FreeBSD Jail, Zones в ОС Solaris. 2005-й — важная лично для меня веха — Open VZ. Я работал в Parallels и был причастен к поздним этапам разработки, для меня это было открытие контейнеров как таковых.
На карте я выделил Linux cgroups и namaspaces с LXC, потому что это очень важные вехи во всей истории развития технологий контейнеризации.
А уже потом, в 2013 году появился Docker, и в принципе можно было бы рассматривать технологии только с этого момента, но дальше я покажу, почему предыдущие этапы тоже нужно иметь в виду.
Docker-стек
Добавим немного деталей в представление docker-стека. Наверху находится демон, который позволяет все запускать, а внизу облачное или физическое железо. Не забудем о containerd, вспомним, что такое shim и что это за runtime, который называется runC.
Тем не менее, все четыре прямоугольника из правого верхнего угла схемы, включая doсkerd, можно так или иначе поменять. А вот слой Linux Kernel и базовые модули ядра никогда не меняется.

cgroups и namespaces — это два кита, на которых стоит контейнеризация в целом. На чем бы мы ни работали, мы всегда их используем.
- namespaces предоставляют изоляцию, то есть возможность запускать на одном ядре разные процессы, изменять hostname, управлять файловыми системами, проводить межпроцессные коммуникации.
- cgroups отвечают за ресурсы и позволяют распределить между процессами почти все виды ресурсов: память, CPU, диски.
О модулях, выделенных на схеме голубым цветом, помнят скорее всего только системные администраторы. AppArmor (или SeLinux — нет принципиальной разницы между этими инструментами), seccomp, capabilities отвечают за то, чтобы изоляцию сделать действительно изолированной, чтобы научиться управлять ресурсами и фильтровать процессы.
Linux Kernel и эти модули — это базис любого контейнерного решения: старого, современного, улучшенного, модифицированного. Все, что находится выше по стеку, будет так или иначе использовать функциональность Linux-ядра.
Новейшая история
Вернемся к истории и посмотрим, что же происходило после знакового 2013-го.
Docker внес существенный вклад в развитие многих аспектов технологий, но, на мой взгляд, важнейший — это OCI (Open Container Initiative). В том же 2015 году появился runC, который мы все используем.
В 2016 появились CRI-O и rkt. Позже Red Hat приобрел CoreOS, в том числе runtime Rocket и сосредоточил все усилия на том, чтобы делать CRI-O, а rkt в 2019 закрыли.

Ветвь, которая на схеме начинается с Kata Containers, не является логическим продолжением runtime, но имеет большое значение. В частности мы попробовали gVisor для того, чтобы изменить состояние безопасности изоляции в контейнерах, и о результатах этого эксперимента дальше пойдет речь.
Firecracker от AWS не имеет прямого отношения к контейнерам, но кажется мне важной вехой в развитии той проблематики, которую мы обсуждаем. Начать знакомство с тем, как устроены эти микровиртуалки и как позволяют добиться multi tenancy, можно начать с доклада архитектора AWS.
Для полноты картины исторического базиса напомню различия контейнеров и виртуальных машин.

Основное отличие в том, где мы проводим черту изоляции и что находится между железом, инфраструктурой и приложением. В случае виртуализации есть гостевая операционная система, в контейнере её нет — есть одна операционная система, в которой все это магическим образом работает. Тут и кроется наша проблема, проблема в слабой изоляции.
Покажу подробнее, что плохого в слабой изоляции: есть контейнер, который работает на нашей машине, есть одно-единственное ядро машины и может произойти то, что называется «Escape».

В архитектуре контейнерной инфраструктуры нет никаких барьеров. Есть изоляция, можно запускать разную нагрузку на одном ядре, чтобы она не мешала друг другу, но это не означает, что процесс живет в «security sandbox».
На прошлых этапах развития технологий контейнеризации, будь то cgroups или namespaces, не ставилась задача получить песочницы — защищенные изолированные среды.Если проанализировать историю создания этих компонентов, то увидим, что они стали заложниками длинной истории развития независимых модулей, которые как LEGO складывались в единую систему, чтобы мы теперь могли легко пользоваться контейнерами. На мой взгляд, огромная заслуга runC и OCI в том, что разные модули соединяются вместе и позволяют нам получать те самые контейнеры.
Как повысить безопасность в контейнерах
Изучив историю, мы поняли, что раз уж архитектура такова, что всё работает на одном ядре, надо повышать безопасность этого ядра.
Мы определили три главных для нас требования к решению: безопасность, zero config или очень простая конфигурация, легковесность. То есть мы хотим, чтобы запускаемые контейнеры были безопасны для инфраструктуры, и мы не хотим их конфигурировать, либо конфигурирование должно быть минимальным. Это требование появилось из опыта наших системных администраторов, которые активно настраивали и конфигурировали SELinux и AppArmor и знали, что всё связанное с безопасностью непременно нужно тщательно конфигурировать. А легковесность — это собственно то, за что все любят контейнеры. Все бы и дальше использовали виртуальные машины, если бы не быстрый и удобный запуск и старт контейнеров.
Мы стали искать, какие уже доступны решения, как можно в текущей парадигме и состоянии развития инструментов, а это было в конце 2018-го, обезопасить контейнеры.
gVisor
Мы решили использовать gVisor не потому что провели масштабное исследование, а просто как раз в это время прошла конференция Google Cloud и gVisor был выпущен в open source. Было много информационного шума, на который мы попались.
В маркетинговом описании gVisor значится: «Предоставляем sandbox для контейнеров».Это именно то, чего мы и хотели. Казалось, что изменения, которые привносит gVisor, — независимое ядро в userspace — позволяет оставаться в парадигме контейнеров и реализовывать как минимум близкое к песочнице окружение.

Суть в том, что запускается все тот же контейнер, с точки зрения интерфейсов ничего не меняется. Системные вызовы остаются, но теперь между ними и контейнером есть gVisor, который не дает случиться тому «Escape», потому что работает в user space, а в userspace по определению права ограничены. Таким образом добавляется промежуточный компонент и получается своего рода прокси в виде gVisor, что и дает изоляцию.
Архитектура gVisor
Архитектура gVisor несколько раз обновлялась. Постепенно разработчики адаптировали её для OCI-совместимости. Это практичнее промежуточных решений, потому что не требует изменений в конфигурации.
Все начинается с того, что клиент (в нашем случае docker-кластер) обращается к OCI-совместимой системе. Runtime называется runsc от «secure» и является имплементацией OCI runtime.

А дальше происходит интересное: runsc создает контейнер и рядом с ним деплоит еще один сервис — Sentry, который эмулирует Linux Kernel (то самое ядро, которое находится в user space). Связку контейнера и эмулированного ядра можно назвать песочницей.
На уровне ядра находится всё тоже самое, что там и было — настоящий Linux Kernel.
gVisor развивался эволюционно, и сначала выполнял простую функцию: перехватывал системные вызовы из контейнера с помощью Sentry, чтобы выполнить их в user space. Самым простым способом перехвата системных вызовов является ptrace. Он удобен тем, что работает практически везде и не требует виртуализации. На ранних этапах это был основной режим работы gVisor, а позже появился более продвинутый вариант, который предлагает использование KVM, то есть виртуализации. В большой части наших экспериментов использовался вариант с ptrace.
Таким образом на уровне ядра находится KVM или классическая связка namespaces и seccomp, которая позволяет фильтровать системные вызовы ядра.
Дополнительный компонент Gofer (неизвестно, как он связан с Golang) обрабатывает все системные вызовы к файловой системе, а все вызовы не связанные с диском обрабатывает Sentry.
9P между Sentry и Gofer — это Plan 9 — интерфейс взаимодействия через файловую систему между разными частями системы. Сама операционная система не взлетела, но некоторые её части оказались очень полезны и стали использоваться 40 лет спустя.
Как начать
Пройдя все нудные аспекты архитектуры, давайте наконец-то поговорим, как это все запустить.
Я пользователь macOS, порядок действий там достаточно нетривиальный, поэтому делюсь инструкцией.
Во-первых, не пробуйте собирать runsc на macOS локально. Runsc для этого не предназначен и вообще не должен запускаться на macOS. Но это и не нужно, на macOS у вас есть Docker, который естественно работает под Linux. Поэтому вам нужен собранный бинарь runsc на Linux. Возьмите и скачайте его (да, мы все еще говорим о безопасности):
$ wget https://storage.googleapis.com/gvisor/releases/nightly/latest/runsc.Дальше нужно найти настройку docker-демона в macOS. Сложный способ — через UI в настройках найти «Daemon», выбрать «Advanced» и т.д. Прочитать JSON мне кажется легче:
$ cat ~/.docker/daemon.json (taskbar > Preferences > Daemon > Advanced.В этот файл нужно дописать следующее:
"default-runtime": "runc",
"runtimes": {
"runsc": {
"path": "/usr/allexx/foo/runsc"
}
}То есть создать новый runtime и указать путь до бинарного файла. Для macOS важно смонтировать папку с бинарником в docker. Как ни странно, docker без проблем допускает еще один runtime.
В итоге получается такая связка: вы пробрасываете бинарный файл runsc с macOS в docker, который работает на Linux, и прописываете это в конфигурации. Docker перезапускается, можно использовать это:
$ docker run --rm --runtime=runsc -it alpine.Обратите внимание, что runsc не runtime по умолчанию.
Это как будто, простой способ, но есть еще и вариант для продвинутых пользователей. На самом деле он не такой и сложный, потому что технологии довольно дружелюбные: GKE — Google Kubernetes Engine — дружелюбный для запуска gVisor (кто бы, конечно, мог подумать, но это стало так только осенью 2019).
Нужно создать новый node pool:
gcloud beta container node-pools create [NODE_POOL_NAME] \
--cluster=[CLUSTER_NAME] \
--node-version=[NODE_VERSION] \
--image-type=cos_containerd \
--sandbox type=gvisor \К сожалению, без этого в managed Kubernetes это запустить никак не получится. Создавая новый node pool, нужно указать параметр sandbox с типом gVisor.
Проверить новый node pool можно так:
$ kubectl get runtimeclasses
NAME AGE
gvisor 19s
Всё работает, можно создавать свои приложения или модифицировать имеющиеся манифесты.
kind: Deployment
metadata:
name: httpd
spec:
replicas: 1
selector:
matchLabels:
app: httpd
template:
metadata:
labels:
app: httpd
spec:
runtimeClassName: gvisor
containers:
- name: httpd
image: httpd
В спецификации появился новый параметр
runtimeClassName, который как раз позволяет указать gVisor. Подробнее о том, как использовать GKE Sandbox написано в документации Google Cloud.Казалось бы, этого достаточно, чтобы все заработало. Но, например, у нас не работала сеть, потому что мы использовали разные серверы, а по умолчанию поддержка сети выключена. Чтобы взаимодействовать с портами, вспоминаем Linux-модуль capabilities:
spec:
containers:
- name: my-container
securityContext:
capabilities:
add: ["NET_RAW"]
Модуль
capabilities можно настроить через securityContext, он позволяет фильтровать параметры системных вызовов, а в данном случае обеспечит поддержку сети.Применимость и производительность
Проверим теперь работоспособность этого решения, а главное, узнаем, что теряем на его запуске.
В первую очередь, мы фильтруем системные вызовы, то есть запускаем их внутри userspace и заново реализовываем. gVisor — это по сути новый Linux, написанный на Go, который на сегодняшний день реализует большую часть системных вызовов — 251 из 347. Однако это ничего не говорит о работоспособности приложений, которые вы используете. В список поддерживаемых приложений входят, например: Elasticsearch, Jenkins, MariaDB, Memcached, MongoDB, Node, PHP, PostgreSQL, Prometheus.
Мы выделили те приложения, которые посчитали востребованными для наиболее широкого круга разработчиков: Golang, Java8, Python, nginx. Все они отлично работают с точки зрения совместимости. Мы не использовали какие-нибудь эзотерические способы, но, например, Python веб-сервер на Django или iohttp не доставили проблем — можете пробовать и локально, и на кластере.
С точки зрения производительности нас интересует цена нестандартного runtime, ptrace, перехвата и запуска. Любые метрики и бенчмарки можно бесконечно критиковать, поэтому я в своей оценке буду основываться на разнице показателей без gVisor и с его использованием.
- CPU. В нагрузке на процессор (измеряли число событий в секунду) различия в рамках погрешности.
- Оперативная память. Сам контейнер не модифицируется и занимает столько же памяти, что и без gVisor, но дополнительно требуется Sentry и Gofer, то есть 35 Мбайт дополнительной памяти — это немного.
- Время старта контейнера не поменялось. Стандартный или модифицированный runtime не оказывают влияние на итоговое время старта, прослойки docker тут вносят гораздо более существенный вклад (тестирование проводилось локально).
- Сеть. RPS в iohttp-приложении получилось в 2 раза меньше с gVisor, чем без него. Причем на любых объемах и видах нагрузки (загрузка файлов или запросы по API).
Таким образом, главная проблема в большом количестве I/O операций, которые превращаются в системные вызовы и поэтому работают медленно. Например, если в вашем приложении есть Redis, который умеет хитро оптимизировать работу с диском и использовать другие системные вызовы, чем обычно используются при работе iohttp-сервера, то производительность просядет не так сильно.
В нашем случае все приложения на Django, flask, iohttp показали примерно 50% снижение производительности — что, прямо скажем, ужасно.
Авторы этой научной статьи подошли к вопросу сравнения производительности гораздо серьезнее, собрали большое число данных и сравнили варианты с ptrace и KVM — результаты с KVM чуть лучше.
Вообще в конце 2019 появилось много материалов, с которыми стоит познакомиться, если вам интересна безопасная работа контейнеров. В частности, теперь есть официальный мануал по запуску gVisor в Google Cloud Platform, а когда мы начинали работу с gVisor, со всем приходилось разбираться самостоятельно.
Отдельно отмечу, что таким образом невозможно получить прямой доступ к железу, поэтому использовать GPU не получится.
Могут ли контейнеры быть безопасными?
Несмотря на все аспекты обеспечения безопасности контейнеров, которые мы рассмотрели в этой статье, ответ на заглавный вопрос — однозначно нет.
Мы рассмотрели только runtime-уровень, но можно обратиться к почти любой другой уязвимости, например, вспомнить, что у нас есть файловая система, которую можно монтировать, или symlinks, которые легко могут породить тот же самый Escape.

Тема комплексная, и мы далеки от того, чтобы сделать контейнеры полностью безопасными. Тем не менее есть некоторые варианты, что делать:
- Познакомиться поближе с securityContext и его конфигурацией: runAsUser, allowPrivilegeEscalation, readOnlyRootFilesystem.
- Держать весь свой софт а актуальном состоянии: ОС, runtime, Kubernetes.
- Присмотреться к Falco — инструменту для мониторинга нагрузки, который совместим с managed Kubernetes, например, GKE.
- Настроить продвинутые политики безопасности: seccomp, AppArmor, SELinux.
- Посмотреть на альтернативы: Kata Containers и микровиртуалки Firecracker.
- Если вам нужны настоящие песочницы — использовать полноценные виртуальные машины или железные серверы, вместо модных контейнеров.
Наш опыт с gVisor говорит о том, что известные проблемы и уязвимости можно закрыть другими средствами не теряя в производительности. А получить полноценную изоляцию в контейнерах пока всё равно невозможно. Именно поэтому в моих советах нет использования gVisor :(
Контакты спикера Александра Хаёрова и все выступления на конференциях: https://hayorov.me (бонусом велосипедная активность в Strava :)
25 и 26 мая Онтико организует онлайн-фестиваль для тех, кто делает Интернет. Новый РИТ++ стирает границы между разными специальностями: профессионалы в одной области сделают доклады для профессионалов смежных областей. Приходите, чтобы быстро узнать срез индустрии и понять, как использовать наработки соседей в своей работе. Или подавайте доклад, если наоборот хотите помочь коллегам не бояться смотреть шире.
А глубоко погружаться в DevOps будем уже осенью — 7 и 8 сентября на DevOpsConf в Москве. Сейчас формируем повестку и принимаем доклады.
