Comments 179
Эльбрус устроен сложнее традиционных процессоров, поэтому большинство вирусов в нем не работают.
А абзацем позже выясняется, что по факту
На сегодня сделать ядро Linux для защищенного режима пока не удалось.
А вообще отличная статья, спасибо большое!
большинство вирусов в нем не работают.
наверное просто нет смысла писать вирусы для Эльбруса?
Ок, я переформулирую. Множество известных сценариев взлома кода на Эльбрусе нереализуемо.
Что касается смысла - stuxnet был написан для поражения одного конкретного противника.
На Э2К работает, в частности, одна из ключевых федеральных систем РФ - паспорта. Я бы не счёл нулевой вероятность появления заказчика на её взлом.
Только вот взлом можно делать не только посредством взлома на уровне кода. Гораздо эффективнее, подчас, взламывать людей. Нужен всего-то системный администратор, который выполнит нужную последовательность действий — и защита на уровне процессора от этого не защитит. Что не означает, конечно, что такой защиты быть не должно.
блокчейн спасет отца русской демократии от взлома паспортов
Эльбрус устроен сложнее традиционных процессоров, поэтому большинство вирусов в нем не работаютЭто грубое коверканье терминологии бросается глаза.
Ведь что такое традиционный вирус? Программа, которая ищет на диске исполняемые файлы и «заражает» их — дописывает свой код, корректируя служебные структуры. Как тут может помешать защита Эльбруса? Да никак.
В бытовом значении сейчас вирусами называют бэкдоры и боты: вредоносное ПО, работающее без разрешения владельца системы. И тут защита Эльбруса тоже никак не помогает. Это чаще всего отдельный исполняемый модуль, скомпилированный по всем правилам, как любая другая программа.
Что хотел сказать автор? Защита есть от некоторых эксплойтов, а именно направленных на разрушение памяти. Но это лишь небольшая часть всех эксплойтов, т.к. есть ещё SQL (и прочие) инъекции, дыры в конфигурировании доступа, баги на уровне логики приложения. Это всё будет работать, как и в любой другой архитектуре.
Или может автор буквально хотел сказать «большинство вирусов», как скомпилированных под другую архитектуру, а значит имел ввиду эффект «неуловимого джо»?
Извините. Это причёсанный транскрипт выступления, он неидеален, я согласен.
Вы правы.
Разве тут есть противоречие?
Особенно интересует, есть ли разница в том, как происходит защита в нативных приложениях и в транслированных.
Вариант есть же работы вируса нативным кодом внутри транслируемой в х86 ОС?
МЦСТ же хвалится тем, что под трансляцией целиком может запускать x86 ОС, такие как Windows.
Не соглашусь, не увидел никаких признаков того что вопрос тут расматривается только однобоко с точки зрения транслятора для Linux, а не включает в себя RTC.
2. Трансляторы, которые существуют, из-под какой ОС запускаются?
Покупайте, потом расскажете зачем купили :)
Что, в комплекте с платой идет форма допуска к гостайне и вы уже все подписали?
А другие идут, увы, в комплекте
Брелок, подставка под фикус...
А если по серьезке чутка — да, мощность не оч, какой бы там потенциал не был. Цена как крыло от самолета.
Но IDE есть? есть. Наше? наше. Может не лучшее, но там и не интел с амд бабло вбухивал десятилетиями. Куда-то в системы класса 1 вполне подойдет, своя ниша с МСВС и Астрой будет, лет через пяток может и дойдут до чего-то совсем красивого. Почему бы и не задонить?
Почему бы и не задонить?
Потому что документацию и исходники вы все равно в полном объеме не получите, как раз из-за военных применений, а что получите - скорее всего под NDA.И довольно быстро вы обнаружите, что тащить этот воз без документации и с непонятно какого качества поддержкой (скорее всего с никакой) как то сложно. И отправится комп как раз туда, куда я написал, - работать дорогой подставкой под фикус.
как раз из-за военных примененийда нет у E2K никаких военных применений, вы о чем вообще?
да нет у E2K никаких военных применений, вы о чем вообще?
Э, а зачем он тогда вообще нужен?
Атомогозовонефтеконторы уже вовсю тестируют железки на Э для внедрения куда им надо. Естественно это не пользовательский и даже не прикладной серверный сегмент, а конкретные специфичные вещи, завязанные на промбезопасность.
Ой, не напоминайте мне об МСВС, за сотни нефти. И о том как наши разрабы с ней мучались. Единственная мякотка там, это кнопочки «Есть!» и «Отставить!» в гуях. ;-)
img-fotki.yandex.ru/get/31082/114185435.e/0_12aec2_a2043c06_orig
Я-б лучше купил что-нибудь из рапторов. Всё таки иметь «маленький кусочек суперкомпьютера», из первой пятёрки TOP500, это... Ну вообщем интересно... Да и архитектура открытая. Кстати, кто напомнит, почему интел отказался от итаниум, который тоже VLIW?
Кстати, кто напомнит, почему интел отказался от итаниум, который тоже VLIW?
Как чего, AMD все планы испортила с 64 битной архитектурой и Athlon'ами 64.
У Итаниума была плохая совместимость с x86 - код работал медленно, а ведь даже на AMD64 уже начали массово переходить только в десятых годах.
Кстати, суперкомпьютер строить на «Эльбрусе» — хорошая затея. Потому что программу для суперкомпьютера будут заведомо вылизывать, а благодаря архитектуре, на «Эльбрусах» при таком вылизывании можно потенциально задействовать все аппаратные возможности по максимуму, поскольку аппаратура практически полностью открыта для программиста.
Можно получить бесплатный ssh доступ к серверу на процессоре Эльбрус. Писать админам YouTube канала Elbrus PC Test: https://www.youtube.com/c/ElbrusPCTest
Используется ли какой то аналог БИОСа или u-boot, для настройки аппаратной конфигурации, памяти, периферии и пр.? Возможно ли обновление микрокода ?
да, правда оно cli и довольно скудное, но вас же как профессионала это не напугает. и да микрокод можно обновлять.
что плохо так это то что на данный момент на эльбрусе невозможно загрузиться с raid ни с программного ни с аппаратного..
》встраивания ядра Linux+initrd в микрокод загрузчика.
Да, в эмбеддед сегменте достаточно востребованное решение. Под заказ.
Проблема в том что достичь сопоставимых с конкурентами скоростей без рантаймового переопределения порядка не получается, в Эльбрус 32 они все таки вставят этот блок и уберут эту простоту
А пока получается что несмотря на весь потенциал Эльбрус сливает Core i7 сделанному на аналогичном техпроцессе (
в Эльбрус 32 они все таки вставят этот блок и уберут эту простоту
Ничего подобного они не собираются городить. Рантайм оптимизациями будет заниматься компилятор, а процессор будет собирать и выдавать ему статистику. Эта фича заявлена уже для Эльбрус-16С
В Эльбрус-32С хотят добавить предсказатель переходов, но не такой предсказатель как у суперскаляров если коротко это будет предсказатель подготовленных переходов и 7 управляющих регистров (сейчас только 3).
Надеюсь что они учтут так же подготовку предсказания вызовов, потому что текущая реализация не позволяет подготовить заранее два-три вызова и поочереди их дергать.
Ничего подобного они не собираются городить. Рантайм оптимизациями будет заниматься компилятор, а процессор будет собирать и выдавать ему статистику
То, что не будут ничего такого городить - это хорошо и правильно. Другой разговор, что никакие рантайм оптимизации фундаментально не решат проблему отсутствия аппаратного ОоО.
В Эльбрус-32С хотят добавить предсказатель переходов, но не такой предсказатель как у суперскаляров если коротко это будет предсказатель подготовленных переходов и 7 управляющих регистров (сейчас только 3)
Я надеюсь что сейчас вы выступаете в роли Рабиновича, наигрывающего Моцарта. Потому что звучит вышенаписанное как лютая хрень.
Процессоры без ОоО существовали и работали раньше и существуют и работают до сих пор. Никакой такой фундаментальной необходимости в ОоО нет, это чисто приблуда для повышения однопоточной производительности на сегодня уже исчерпавшая свой потенциал, не только из-за того что производительность уже не растет, но и из за дыр которые оно в итоге имплементирует.
Не надо всем его толкать как панацею, его уже довели до совершенства лидеры рынка, нам их не догнать. Сейчас они еще тонны денег в ресерчь вольют, прикроют свои дыры и пропиарят так что от процессоров без этих затычек будут шарахаться как от прокаженных. Рантайм профилирование и взаимодействие с компилятором в динамике это очень интересное и перспективное направление, для рантайм-языков так точно. Предложить то чего у других нет - вот ключ к успеху, а лепить свою формулу-1 и тащить на гонку с определившимися фаворитами на черт знает каком кругу, даже если допустят, бесперспективно.
Я надеюсь что сейчас вы выступаете в роли Рабиновича, наигрывающего Моцарта. Потому что звучит вышенаписанное как лютая хрень.
Хорошо, приведу цитату:Архитектура «Эльбрус» предполагает наличие
в программном коде команд разной длины, поэтому
выдача предсказания для подкачки кода необходима
до выполнения его декодирования и определения
размеров и типа команд. В архитектуре «Эльбрус»
введены два типа операций перехода — подготов-
ленные и непосредственные, причем количество
непосредственных переходов в коде очень неве-
лико, для них весьма редко реализуется условие
перехода, т. е. в основном они обречены на промах,
в данном случае неизвестен заранее адрес пере-
хода. С учетом этих факторов было принято реше-
ние при проектировании устройства не рассматри-
вать операции непосредственного перехода.
То есть переходы по командам ibranch предсказываться не будут, что логично в виду наличия в системе команд кучу инструкций для вычисления адреса перехода, плюс ошибки предсказания проще проглатываются:Интересно отметить, что отсутствие неупорядо-
ченного исполнения команд и раннее вычисление ус-
ловия перехода в микропроцессорах с архитектурой
«Эльбрус» позволяют упростить реализацию услов-
ной отмены команд — вся деятельность при ошибоч-
ном предсказании ограничена устройством управ-
ления и кэш-памятью команд, а в исполнительные
устройства попадают команды только из правильной
ветви перехода.
Главное чтоб можно было делать:
{ disp %ctpr1, malloc }
{ disp %ctpr2, my_funct }
...
{ call %ctpr1, wbs = 0x4 }
{ call %ctpr2, wbs = 0x4 }а не как сейчас. Судя по описанию реализации все для этого есть.
Предложить то чего у других нет — вот ключ к успеху, а лепить свою формулу-1 и тащить на гонку с определившимися фаворитами на черт знает каком кругу, даже если допустят, бесперспективноВсё так, но тогда надо предлагать принципиально другие подходы к вычислениям, к рантайму, к ОС, организации алгоритмов. А то получается, берём «принципиально новый» процессор, и натягиваем его, как сову на глобус, на столетний C/C++ код (linux kernel и миллионы строк кода прикладных программ). Под это легаси игроки рынка десятилетиями оптимизировали свои мейнстрим процессоры, и на этом поле их не догнать.
Никакой такой фундаментальной необходимости в ОоО нет, это чисто приблуда для повышения однопоточной производительности
Это просто вишенка на торт к тому потоку дичайшего бреда, который вы написали в первых двух абзацах.
Хорошо, приведу цитату:
Это цитата из ресерч статьи, а в жизни всё может поменяться. Вы результаты видели там? минус 2 процента перфа. И ничего не сказано про главное - return из функции. В общем, это опять не нормальный бранч-предиктор, а очередной костыль, который пытаются впихнуть в реалии Эльбруса.
Вы результаты видели там? минус 2 процента перфа.
Естественно, потому что бранчпредиктор не дает бесплатных переходов. В отличии от доп. конвеера с уже заранее подкаченными инструкциями бранча, у него один пайплайн и ему нужно угадать какими инструкциями из какого бранча в следующем такте его начать забивать вслед за инструкцией условного перехода для которой еще даже аргументы не сосчитались. Потому что если этого не сделать переход будет дорогим на всю длинну стадий конвеера.
Сам по себе это и есть костыль для пайплайновых процессоров дабы удешевить переходы, и ошибки предсказания (штатная ситуация для бранчпредикторов) дорого обходятся, так как в этом случае приходится сбрасывать конвейер.
Однако эльбрусовские классические подготовки как назло стоят там где бранчпредиктор вполне себе хорошо справляются и наоборот, плюс первый стоит дорого по оборудованию и не масштабируется, второй же более менее можно допиливать и расширять, вангую в итоге придут к урезаной версии конвеера подготовки и общему бранчпредиктору. Возможно что уже прешли, все таки дока выше 2016г и его в таком виде так и не имплементировали.
И ничего не сказано про главное - return из функции.
Бранчпредиктору все равно возврат, переход,, вызов, прыжок в начало цыкла или что то еще, он не исполняет инструкции он их выдает конвейеру по заранее предсказанному адресу.
*** Бранчпредиктору все равно возврат, переход,, вызов, прыжок в начало цыкла или что то еще, он не исполняет инструкции он их выдает конвейеру по заранее предсказанному адресу. ***
Ничего подобного. Я работал в MIPS и у нас был отдельный бранчпредиктор для возвратов из функции, другой чем главный бранчпредиктор
Это написано и в википедии:
https://en.wikipedia.org/wiki/Branch_predictor#Prediction_of_function_returns
Many microprocessors have a separate prediction mechanism for return instructions. This mechanism is based on a so-called return stack buffer, which is a local mirror of the call stack. The size of the return stack buffer is typically 4–16 entries.[8]
Оппонент выше написал, что предиктор можно заменить на инструкции disp, которые будут принудительно подкачивать код. Адрес, который надо подкачать, известен перед входом в функцию, но незадолго перед return такую команду разместить нельзя, потому что статически адрес возврата неизвестен. Поэтому динамическое предказание работает на возвратах, а статическое не работает.
К вопросу о костылях, согласно текущим реалиям, фронт процессоров (по сути на текущий момент они все RISC) последовательный, а бэк, соответственно, параллельный. Тогда вопрос, как вы будете организовывать параллельные вычисления на уровне какого-либо языка программирования?
Не согласны? Приведите пример, где ручной шедулинг настолько нужен, что автоматика точно не справится.
Конечно нет, потому что, в итоге, скажем так, вы получите идеологический перекос и он начнет усугубляться, в будущем, в излишках железа и кода. Уже проверено и перепроверено. В итоге вам все равно придется переходить на "прямую" идеологию.
Простой пример. Есть у вас проц с параллельным бэком, вам из ЯП нужно организовать параллельное вычисление (не важно чего), тогда к текущим инструкциям камня пишете еще сет, на основе его пишите интерефейс и в виде библиотек подключаете его к ЯП, а потом уже в контексте процедур и функций этой библиотеки делаете свои параллельные дела. Ничего не напоминает?
Можно сделать по другому. Например, для такого кода:
Параллельно
Нач
х1 = 1;
х2 = 2;
х3 = 3;
Конец;
просто пишите "параллельный" компилятор и фронт камня делаете параллельным. Такой подход как раз дает равномерность при загрузке программера, компилятора и проца - каждый играет свою роль без переоборов или недоборов.
И опять же, компилятор должен тут что-то неявно параллелить. Например выражение типа
v = (a+b)*(c+d) вы будете заставлять человека вручную разбивать на широкие команды?Реально полезного примера вы не предоставили. То есть, сейчас вам на таком языке ничего не хочется написать. Значит, идея ещё не готова к применению на практике.
Например, для такого кода: <...> просто пишите «параллельный» компилятор и фронт камня делаете параллельнымНа самом деле, не просто.
«Просто» я напишу:
Параллельно
x1 = System.File.IO.ReadFloat(file1);
x2 = gcd(z1, z2); // алгоритм Евклида
x3 = sin(e);
Конец;Тут вызов ф-ции ОС, вызов длинного алгоритма и совсем простое — что-то посчитать на FPU (который возможно будет занят первой инструкцией). Формально я буду прав — это можно всё делать параллельно. Как компилятор должен это положить в код — потоками, VLIW или ещё как — задача на данный момент не имеет решения, компилятор не имеет достаточной информации о том, что происходит, чтобы принять оптимальное решение.
Усугубляю. Какой алгоритм решения той или иной задачи эффективнее, последовательный или параллельный (точнее будет сказать последовательно-параллельный, он же ППА)? Ответ по-моему очевиден. Тогда следующий вопрос - по "мотивам" ППА какой должен быть код на коком-либо ЯП? И опять все на поверхности, т.е. последовательно-параллельным ( ЯП тогда должен по-сути своей называться явно параллельным языком программирования - ЯПЯП)! Тогда для ЯПЯП каким должен быть компилятор и фронт процессора?
... и (как говорят в Одессе и Израиле)) вы будете утверждать, что ему никогда не присвоят почетного звания генерала Пурпозы)))?
Погодите, но ведь profile-guided оптимизация в gcc была еще хз с каких времен и ничего дополнительного в процессоре точно не требовалось? Не совсем понятно что именно нужно добавить в Эльбрус чтобы это заработало.
Несколько ремарок:
Это позволяет экономить на jmp потому, что некоторые простые условные операции можно закодировать в одной инструкции
Главная идея предикатов не в экономии jmp, а в том, чтобы убрать ветвления и создать максимально длинные последовательные участки кода. Иначе невозможно эффективно заполнить ШК,
Команда перехода (jmp) сбивает работу конвейера и обходятся процессору как десяток других команд
Это не так при наличии блока предсказателя переходов. А данный блок существует в любом мало-мальски приличном CPU уже лет 20 как.
Эльбрус может избежать этой проблемы не только с помощью предикатов, но и за счёт по другому устроенной команды переходов
Это уже было обсуждено в серии последних статей про Эльбрус - механизм подготовки переходов является одной из главных проблем архитектуры e2k, он катастрофически плохо работает. Именно поэтому МЦСТ в последних публичных заявлениях (неофициальных, правда) декларирует отказ от текущего мехнизма и переход к классическому предсказателю переходов
Если вы закодируете эту операцию обычным циклом (часть кода, jmp на начало, снова та же часть кода, который исполняется в цикле), то на каждой итерации будет обращение к памяти, на котором процессор зависнет, пока не получит данные из памяти
Опять-таки, это неверно, т.к. аппартный блок префетча заранее подкачает код в кэши и процессор записать не будет
В традиционном процессоре, jmp не позволит исполнять следующую итерацию до окончания предыдущей, поэтому код будет исполняться строго до последней инструкции
Конечно же нет. ОоО легко перемешивает инструкции из разных итераций цикла. Более того, это как раз одно из тех мест, где современный ОоО RISC процессор фундаментально проще и быстрее исполняет код, по сравнению с VLIW со статическим планированием. Т.е. каждый цикл в ОоО RISC автоматически и максимально эффективно накручивается (если хватает внутренних буферов, конечно же)
Бинарный транслятор сделан в виде набора из трёх трансляторов и состоит из трех уровней кодогенерации
Всё же из 4-х, там есть ещё интерпретатор (хотя это не транслятор, но тем не менее)
Быстрый регионный, который берет уже не одну инструкцию, а линейный фрагмент и компилирует его, учитывая взаимосвязи между инструкциями
Быстрый регионный транслятор оперирует регионами (т.е. произвольными CFG-графами), а не линейными фрагментами. Что собственно даже из его названия проистекает. Даже шаблонный транслятор оперирует трассами (хотя транслирует код "шаблонно" по одной x86-инструкции)
Это тяжелый оптимизирующий компилятор, который выжимает из бинарной трансляции все, что возможно, и синтезирует эффективный код. По быстродействию он мало уступает прямому исполнению на родном Интел
Тогда тут надо уточнить, что родной Интел должен быть года этак из 2005-го (это если мы говорим про Эльбрус-16С). Плюс/минус, конечно же.
То что эмулируемый на эльбрусе интел такой же как интел из 2005 года — это в смысле по поддерживаемым наборам инструкций (SSE, AVX и т.п.) и/или по производительности?
доп:
Если по скорости, то это не так — в эмуле даже на 8с удается запускать достаточно тяжелый Final Fantasy XV
А вот с cyberpank были проблемы, мб каких-нибудь avx не хватает?
По производительности, конечно же.
Если по скорости, то это не так — в эмуле даже на 8с удается запускать достаточно тяжелый Final Fantasy XV
Если верить вашему чатику в неизвестном разрешении на Low графике игра показывает 16-20 фпс, строго говоря чтобы корректно сравнивать нужно было гонять бенчмарки, как делали в 18 году все обзорщики, но легко найти в интернете видео связки i3-2120+rx550 которые показывают в Low стабильные 36 фпс в той же сцене. Так конечно на Intel'ах 2005 года ее никто не пробовал запускать, но разница производительности на ядро между Core 2 Duo и i3-2120 - далеко не в два раза.
А вот с cyberpank были проблемы, мб каких-нибудь avx не хватает?
Cyberpunk без фанатских патчей требует AVX, но на первые патчи была фанатская модификация, которая позволяла его запускать если AVX нет, но есть SSE 4.2 (но разработчики впрочем потом это включили в хотфикс)
Если по скорости, то это не так
Согласитесь, достаточно странно спорить о производительности Lintel с человеком, который производительностью Lintel и занимался.
Производительность вообще надо уметь корректно мерять. Что касается вашего примера - измерять перф процессора на играх достаточно плохая затея, т.к. там скорее важнее перф видеокарты. Ну т.е. если вы запустили Final Fantasy XV с какой-то приемлемой производительностью, то это скорее всего заслуга видеокарты. Уж как минимум, надо детально разбираться, что там происходит.
Что касается вашего примера - измерять перф процессора на играх достаточно плохая затея, т.к. там скорее важнее перф видеокарты. Ну т.е. если вы запустили Final Fantasy XV с какой-то приемлемой производительностью, то это скорее всего заслуга видеокарты. Уж как минимум, надо детально разбираться, что там происходит.
В среднем да, но конкретно в этом случаи игра уперлась в процессор (если открыть их чатик и почитать, там челвоек показывает 100% загрузку цпу и отдыхающий половину времени GPU на графиках).
Вообще игры могут упираться в процессор, притом в разные части - все таки каждый фрейм это render call и его надо как-то обработать, а еще кроме самого рендера кадров нужно рассчитывать AI, скрипты и прочее, то есть процессор в современных играх тоже важен до какого-то момента. Тут еще проблема в том, что сложно найти тесты игр на множестве разных процессоров и видеокарт. Например на i3-2120 игра не упирается в процессор в 1080p. Но разрешение в котором игру тестировали в чатике том - неизвестно, известно что загрузка цпу была 100% на их 16 фпс, то есть можно прикинуть что резульаты Эльбруса примерно в 4 раза хуже чем i3-2120 для игр.
А про правильные бенчмарки - надо собирать много статистики и, по возможности, использовать воспроизводимые бенчмарки (например встроенные средства или уже написанные другими людьми, как в случаи с FF XV). Если смотришь на реальный геймплей, то выбирается сейв где делается очень предсказуемый набор действий, и в это время записывается много статистики, в духе загрузки CPU, загрузки GPU, времени рендера каждого кадра (чтобы потом можно было посчитать FPS и различные перцентили, например оценить наличие просадок), тогда можно предметнее говорить о бенчмарках в играх. И кстати, в некоторых играх когда процессор не может раскачать карту - будут заметны просадки именно в 99-99.9 перцентилях времени рендера, а для игрока это будет выглядеть как периодические фризы (или фризы в каких-то ситуациях), например во время боя или взаимодействия с предметами в случаи action'ов.
В среднем да, но конкретно в этом случаи игра уперлась в процессорВ этом-то и ирония. Если игра на интеле жрёт 25% процессора и выдаёт 60 fps, а на Эльбрусе жрёт 100% и выдаёт 20 fps, разница не в 3 раза, разница в 12 раз.
В этом-то и ирония. Если игра на интеле жрёт 25% процессора и выдаёт 60 fps, а на Эльбрусе жрёт 100% и выдаёт 20 fps, разница не в 3 раза, разница в 12 раз.
Я не нашел адекватных тестов на очень старых интелах, в каком-то случайном видео на youtube'е загрузка была 50%, поэтому я округленно посчитал что 32/16 = 2 раза чистой производительности и скорее всего имея еще половину цпу свободным - еще 2 раза, так что 4. Но не принципиально.
Я видел еще тесты на каком-то сомнительном сайте где игра на i3-2100 давала 60 с чем-то FPS в 1080p@Low на RX 550 и 125 фпс если заменить видеокарту на rx570, но я не смог найти информацию про методику тестирования и это был буквально первый раз когда я видел этот сайт в глдаза, поэтому не стал его приводить (но думал об этом). Потому что по хорошему в рамках тестов надо фиксировать используемые версии и все доступные настройки, а этого эльбрусовцами сделано не было.
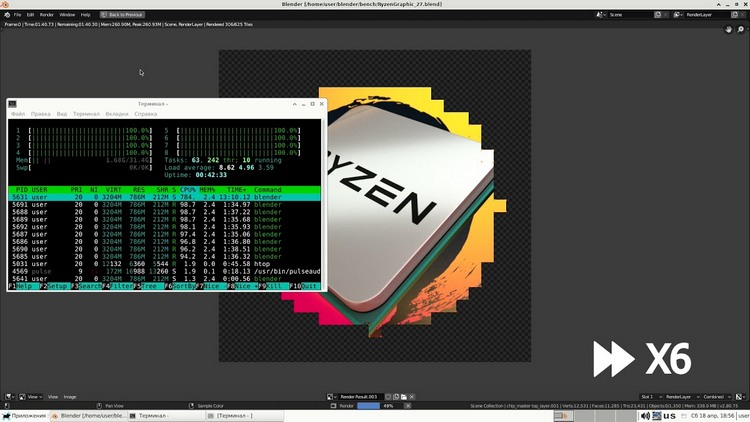
Все потому, что в Эльбрусе нет предсказателя, а статическая оптимизация (оптимизация на уровне компилятора) на деле оказалась полным фуфлом. Если Вашу игрушку перекомпилять с иcпользованием SIMD оптимизации, то она покажет те же 60 fsp при близкой к интеллу нагрузке. Недавно такой фокус проделали с Blender-ом и получили интересные результаты. Но засада в том, что сделать это в подавляющем большинстве случаев либо невозможно, либо сильно затруднительно.
Ссылка некорректная. Посмотрите на результат в ней и на картинку, которая была ранее (скриншот из статьи на которую они же ссылаются). Пока картинки не будут попиксельно идентичными, скорость сравнивать в принципе некорректно (например поломанные источники освещения могли привести к ускорению рендера, а не оптимизации).
{kind=link}
{kind=link}
Если Вашу игрушку перекомпилять с иcпользованием SIMD оптимизации, то она покажет те же 60 fsp при близкой к интеллу нагрузке.
Только при условии, если игра использует операции, которые хорошо векторизуются (что само по себе не факт), а также не стоит забывать про другие особенности Эльбруса типа нелюбви к ветвлениям (по понятным причинам, о которых в том числе вы сказали), но которые активно используются в играх.
Вы полностью правы. Все это говорит от том, что Эльбрус - процессор специализированного назначения (хорошая цифродробилка) и в тесте с Blender-ом он был задействован по своему прямому назначению, хоть тест и не совсем правильный. Желание МЦСТ навялить Эльбрус нашему государству как процессор общего назначения сталкивается в профессиональном обществе с резонным вопросом - "нахрена козе баян".
Лично моё мнение - на Эльбрусах можно и нужно делать видеоускорители, нейроускорители и прочие DSP. Но только те, где НЕ требуется многозадачность. Иначе длинный регистровый файл похоронит и эту нишу.
Лично моё мнение - на Эльбрусах можно и нужно делать видеоускорители, нейроускорители и прочие DSP. Но только те, где НЕ требуется многозадачность. Иначе длинный регистровый файл похоронит и эту нишу.
При позиционировании как числодробилки напрашивается будут уже другие сравнения. Там тоже интересный вопрос, как будет выглядеть результат.
Я уверен, криптомайнеры были бы счастливы помайнить на Эльбрусах - была бы цена доступной. ;-)
Совсем не факт, что им бы удалось эффективно загрузить эльбрус (там же очень много ограничений на то что с чем может сочетаться из операций). Хотя это скорее зависит от алгоритма.
криптомайнеры были бы счастливы помайнить на ЭльбрусахБессмысленно. 8704 CUDA-ядер у RTX 3080, на которых параллельно выполняется 8704 потоков вычислений невозможно догнать никаким 8 или даже 16-ядерным CPU.
Шигорин там ошибся. Использовался не тот рендер.
Согласен
Зачем все эти потуги, может лучше было бы клонировать арм?
Я бы проголосовал за RISC-V. Ну просто потому что мне кажется эта архитектура довольно перспективной. Да и лицензионная чистота как бы тоже гуд.
А что будет, когда выйдет новая версия (условно, ARMv11), а продавать лицензию не захотят?
У Байкала архитектурная лицензия на ARM?Нет, не архитектурная. Она не имеет смысла для подавляющего большинства компаний, а Байкал не относится к той небольшой подгруппе, которая получает конкурентные преимущества за счет микроархитектуры.
А что будет, когда выйдет новая версия (условно, ARMv11), а продавать лицензию не захотят?А что будет, когда выйдет нова версия ARM, а продавать ее Apple и Qualcomm они не захотят?
Если же вы переживаете насчет каких-то новых санкций, то побеспокойтесь лучше о том, как производить процессоры на 180 нм, если отключат не лицензию на ARM, а доступ к TSMC.
Если же вы переживаете насчет каких-то новых санкций, то побеспокойтесь лучше о том, как производить процессоры на 180 нм, если отключат не лицензию на ARM, а доступ к TSMC.
Кстати, а сопутствующие материалы, типа тех же пластин, для тех фабов в рф вообще делают? А то что то мне подсказывает, что там зависимостей несколько больше.
Кстати, а сопутствующие материалы, типа тех же пластин, для тех фабов в рф вообще делают? А то что то мне подсказывает, что там зависимостей несколько больше.Правильно подсказывает. Пластины импортные, фотошаблоны — импортные, даже у полностью отечественных чипов, большая часть химии импортная, все производственное оборудование, запчасти и поддержка к нему — импортные.
А что будет, когда выйдет нова версия ARM, а продавать ее Apple и Qualcomm они не захотят?То есть, RISC-V это минус один риск.
побеспокойтесь лучше о том, как производить процессоры на 180 нм, если отключат не лицензию на ARM, а доступ к TSMCЧисто теоретически, материковые китайцы лет через 5 смогут выполнять заказы на более-менее актуальные нанометры.
Чисто теоретически, материковые китайцы лет через 5 смогут выполнять заказы на более-менее актуальные нанометры.А чем именно технологическая зависимость от КНР лучше зависимости от США и Тайваня?
То есть, RISC-V это минус один риск.Я очень слабо представляю себе ситуацию, когда ARM запретят, а иностранные фабы — нет. Эти риски почти наверняка придут вместе, поэтому надо избавляться или от обоих сразу, или ни от одного.
И САПР для проектирования еще — третий риск в комплекте.
Я очень слабо представляю себе ситуацию, когда ARM запретят, а иностранные фабы — нетРазница в том, что абстрактных иностранных фабов теоретически может быть несколько, не все сразу запретят. А лицензиар конкретной архитектуры — ровно один.
Когда Хуавею запретили доступ к TSMC, они даже не стали пробовать договариваться с Samsung, потому что понимали, что ничего не выйдет.
Чисто теоретически, материковые китайцы лет через 5 смогут выполнять заказы на более-менее актуальные нанометры.
Если смогут освоить производство оборудования в достаточной мере, чтобы быть свободными от экспортных ограничений. И если сами захотят портить отношения с другими ради помощи соседу. И если этот сосед с ними не поругаться раньше. В общем очень ую много если.
Спасибо за статью. Читается на одном дыхании, многих аспектов не знал, хотя за Эльбрусами посматриваю довольно давно.
P.S. Если кто пугается текущих цен на модули, то скажу, что раньше модулей или не было, или они были дороже. С массовостью цены неизбежно будут ниже, хотя, конечно, до Интел или АМД вряд ли опустятся - масштабы производства сильно отличаются всё-таки.
Спасибо за статью. Было интересно читать.
Эх, я все жду когда выпустят маленькие модулю с выводами под usb, sata отдельными, чтобы можно было это дело в кастомное шасси ноута вставить и попробовать это дело все потыкать.
В Эльбрусе команды push и pop не используются. Процессор содержит пул из 256 84-разрядных регистров. Не все они видны программе: каждая функция «заказывает» у процессора нужное количество и процессор выделяет ей часть пула, в которой она будет жить.
Вот этот момент явно отличается от всего что сделано раньше, и даже сейчас. В связи с чем вопрос - каким образом функция может вернуть больше одного регистра, например структуру.
В нормальных цпу перед вызовом подпрограммы выделяется место на стеке. В сильно оптимизированном виде пространство данных может быть выделено прямо в регистрах. Но как выяснилось, у эльбруса два стека на поток: откачка лишнего из раздутого "кеша" регистрового поля, и стек заточенный под сохранение данных. Лично мне как пользователю ARM - данный прикол кажется дикой дикостью. Это-ж сколько нужно дополнительной индексной информации параллельно обслуживать, чтобы вытащить нужное из глубины стека.
И дополнительно, сообщите плиз уровень вашей боли при переключении контекста.
Не вижу проблемы. Вы точно так же можете оставить место в окне параметров под структуру, или передать параметр с адресом.
Но как выяснилось, у эльбруса два стека на поток: откачка лишнего из раздутого «кеша» регистрового поля, и стек заточенный под сохранение данных. Лично мне как пользователю ARM — данный прикол кажется дикой дикостью. Это-ж сколько нужно дополнительной индексной информации параллельно обслуживать, чтобы вытащить нужноеКак по мне, это плюс: железо может два, а то и три стека обслуживать параллельно. И между ними не будет зависимостей по данным (т.е. условный call/ret никак не пересекается с push/pop).
з.ы. пишу интерпретатор стековой машины и разнёс стеки числовых и ссылочных значений (строк) в разные структуры. Никаких проблем от этого, только касты исчезли между uint64 и void*
Вот этот момент явно отличается от всего что сделано раньше, и даже сейчас.
Это Register Stack Engine (RSE), как в Itanium. Подобное было в SPARC-е и в каком-то Hobbit-е.
Накладные расходы (конструктивные) на регистровые файлы намного меньше, чем на конвейеризацию. Это прямо - бинго в плане размена, на что тратить логические ячейки. Однако "обычные" процессоры давным давно изобрели кэш третьего уровня, работающий на частоте ядра.
Меня вот смущает реализация многопоточности. Одно дело, когда компилятор собирает код единственного потока - тут можно оптимизировать сколько угодно. И регистровый файл тут в масть.
Но совсем другое дело - жонглирование большим количеством потоков. Явно, что переключаться туда-сюда нельзя будет, поскольку одно дело, хранить для каждого потока один указатель на вершину его собственного стека, и совсем другое - где-то брать уникальную копию регистрового файла в самом железе процессора.
Ведь нет никакой гарантии, что к моменту переключения потоков (завершения кванта, выделенного потоку) стек будет хотя бы приблизительно в том же месте, где при входе в этот самый квант.
Накладные расходы (конструктивные) на регистровые файлы намного меньше, чем на конвейеризацию. Это прямо — бинго в плане размена, на что тратить логические ячейки. Однако «обычные» процессоры давным давно изобрели кэш третьего уровня, работающий на частоте ядра.
Вы сплели 3 несвязанные между собой вещи в один абзац. Не ясно что вы хотели этим сказать.
Все современные процессоры конвейеризированы (и Эльбрус). А уж имеют ли они вращающиеся регистры или кэш L3, то это вообще тут не причём.
где-то брать уникальную копию регистрового файла в самом железе процессора.
Никакой копии там нет (в Эльбрусе). Стеки сохраняются в память.
Например на Sparc может быть до 32 окон по 16 регистров (512+8) в теории. Смена задач или любое нарушение порядка вызовов может вызывать сброс регистров в память.
В процессорах типа Niagara (Ultrasparc T1+) есть 4-way SMT, что несколько улучшает положение.
В любом случае идея с вращающимися регистрам ущербна сама по себе для процессора общего назначения.
Она годится только для вычислений в однозадачной среде.
icps.u-strasbg.fr/people/loechner/public_html/enseignement/SPARC/sparcstack.html
That was the idea, anyway. The drawback is that upon interactions with the system the registers need to be flushed to the stack, necessitating a long sequence of writes to memory of data that is often mostly garbage. Register windows was a bad idea that was caused by simulation studies that considered only programs in isolation, as opposed to multitasking workloads, and by considering compilers with poor optimization. It also caused considerable problems in implementing high-end Sparc processors such as the SuperSparc, although more recent implementations have dealt effectively with the obstacles. Register windows is now part of the compatibility legacy and not easily removed from the architecture.
Спасибо!
Разработчики молодцы! Не смотря ни на что.
Но хотелось бы побольше фоток железок и желательно с чистой мета-датой. Также, интересно было бы узнать, а проходят ли аудит другие комплектующие? Ну и увидеть бы код биос и/или его производную.
Очень красиво написано, но почему бенчмарков нет? Нужно убедительное сравнение со "всякими интелами".
Мне, как не профи в этом вопросе - каждый раз, разумеется, любопытно читать статьи, которые то восхваляют Эльбрусы, то выбивают из них последний дух. Особенно доставляет прочтение комментариев.
Но такой вопрос, просто, чтобы разобраться:
Если Эльбрус плох, то зачем и на что существует разработчик?
Если Эльбрус так хорош, то почему его распространение НАСТОЛЬКО ограничено даже при всех тех попытках, которые осуществляет государство для его проталкивания в жизнь?
Процессоры дешевеют при массовом производстве. Для массового производства нужен массовый заказ. Для массового заказа процессор должен быть дешёвым.
Для массового заказа процессор ещё должен быть востребован массовым заказчиком, эффективно удовлетворяя его потребности в пересчёте на единицу стоимости и потребляемый Ватт. И удобен во всех смыслах разработчикам массово используемого ПО. Так то и Broadcom BCM2711, и какой-нибудь EPYC – оба массовые.
распространенние никто не ограничивает, по моему опыту софт всегда отстает от железа, малое количество софта и отсутствие программистов в данном сегменте ограничивает применимость архитектуры и процессора.
считаю, что по мере наработки софта, под эту архитектуру станет проще разрабатывать, потребителей станет больше, появится спрос на программистов, повысится их зп и престиж, но альтернативный вариант, признать Эльбрус неперспективным и использовать всем только х86, так как это проще (нет).
Если Эльбрус плох, то зачем и на что существует разработчик?Разработчик существует на выделяемые из бюджета деньги. В Минпромторге считают, что стране нужна собственная архитектура. Ее коммерческая успешность Минпромторг волнует в меньшей степени, чем независимость.
А чем обусловлена необходимость именно своей архитектуры? Чем плохи другие в том числе и открытые?
Есть ещё OpenRISC и OpenSPARC. Ну и не стоит забывать хоть и про лицензируемую, но довольно распространенную архитектуру MIPS. Всё же на ARM свет клином не сошелся.
Кроме того у МЦСТ есть опыт в работе со SPARC, что могло бы помочь.
В чем выигрыш открытых решений? В их открытости. Я думаю это не надо объяснять. Помимо этого, под выше перечисленные архитектуры есть рабочие сборки linux.
МЦСТ не спешить открывать документацию на Эльбрус. Без этого можно довериться только их уровню компетенции в адаптации ОС и компиляторов под их же архитектуру.
Лично мне кажется, что открытая архитектура была бы предпочтительнее, чем закрытая хотя бы в той части, что больше разработчиков могло бы её изучать и адаптировать софт. А ещё более предпочтительно не только открытая, но и так которая уже использовалась.
Вот вы всё упираете на производительность и архитектурные ошибки. Но насколько мне не изменяется память за исключением каких то экзотических и экспериментальных архитектур всё что дожило до наших дней и делалось в кремнии вполне себе не хуже. У каждой архитектуры есть достоинства и недостатки. При условии, что не надо тянуть за собой груз обратной совместимости производительность будет +- одна. Всё упирается уже в техпроцесс и хитрые оптимизации в виде дополнительных расширенных инструкций, мощного блока предсказания ветвлений, конвейеров.
Тот же ARM очень долгое время оставался нишевым процессором не выделяющимся особой производительностью на фоне x86-64 в абсолютных выражениях. Но как только появилась потребность и деньги, так его быстро подтянули до нужных высот.
С другой стороны x86-64 и ARM в своих недрах не так уж и различны. А вот VLIW это совсем другой подход и судя по тому что я читал есть серьезные трудности с наращиванием его производительности в обычных задачах.
Я не понимаю почему вы так упираете в то что MIPS свернули? Это не проблема архитектуры, как таковой, а проблема экономической обоснованности.
Вообще, чтобы говорит о том сколько нужно денег для создания сравнимого с x86-64 по производительности процессора на другой архитектуре необходимо понимание почему у них эта самая производительность разная. Лично я не берусь вот так лихо на глаз сказать, что нужно Х мил. долларов.
Я высказываю предположение, что RISC архитектура в любой конечной реализации в силу своей близости к x86-64 проще довести до нужной производительности, чем VLIW у которого довольно сильные отличия именно в базе. К тому же есть опыт Intel в этом направлении и опыт неудачный. А уж кто, как не Intel понимали в чем причина производительности x86.
В чем выигрыш открытых решений? В их открытости.Вы же понимаете, что говоря об «открытых» RISC-V, OpenPOWER или иже с ними, мы по факту имеем в виду проприетарные реализации открытой системы команд?
То есть, если вам по каким-то причинам была бы нужна архитектурная лицензия на ARM, то RISC-V — это экономия. А если нужно конкретное ядро, то разницы между ARM и RISC-V никакой нет.
А что нужно РФ? В статьях о Эльбрусах, как один из плюсов это то что в процессоре своя архитектура без вражеских закладок. Но открытая архитектура в этом плане ничем не хуже.
что нужно РФ?Если бы на поставленный таким образом вопрос существовал короткий прямой ответ, он был бы публичным достоянием.
Но в реальности это вопрос из серии «за все хорошее против всего плохого». Не существует никакого «нужно РФ». Есть люди, боящиеся «вражеских закладок». Есть люди, не верящие в существование «вражеских закладок». Есть люди, считающие импортозамещение жизненной необходимостью, есть люди, считающие его одним большим распилом.
Есть люди, считающие опенсорс единственным выходом, есть люди, считающие, что опенсорс в конечном итоге подконтролен США.
От длинных регистровых файлов отказались сразу, как только их придумали и испытали в 80х. Основная причина - потеря производитеьлности при переключении контекста в многозадачных ОС, которые уже в то время начали доминировать. Более подробно об этом можно прочесть в статьях Д.Паттерсона и Дж. Хеннесси в сборнике "Электроника СБИС. Проектирование микроструктур", Мир, 1989. В сборнике есть много интересной статистики по исполнению различного кода, от компляторов и ОС, до числодробилок.
Насколько я понял, в эльбрусе не просто большой регистровый файл, а Register Stack Engine (RSE), как в Itanium. Если RSE в фоновом режиме сохраняет в основную память участок не на вершине стека, то производительность будет не хуже любого процессора.
Да и сохранение большого регистрового файла можно оптимизировать, если помечать, какие регистры были изменены, и сохранять только их.
Большой регистровый файл хуже маленького, только если маленькая доля регистров используется. Если используется весь большой регистровый файл, тогда процессор с маленьким регистровым файлом будет обращаться не к регистрам, а к кеш-памяти, то есть работать быстрее не будет.
Если RSE в фоновом режиме сохраняет в основную память участок не на вершине стека, то производительность будет не хуже любого процессораА что произойдёт в момент переключения контекста? Всё несохранённое на текущем потоке надо сохранить в память, вершину стека нового потока загрузить в кеш. Это нельзя делать «в фоновом режиме», т.к. выполнение второго потока на первой же инструкции обратится к регистру из регистрового файла, а там ещё ничего нет.
Да и сохранение большого регистрового файла можно оптимизировать, если помечать, какие регистры были изменены, и сохранять только их.Только память DDR сейчас работает длинными передачами. Выгоднее отправить одну транзакцию на 256 байт, чем 7 транзакций по 8 байт.
процессор с маленьким регистровым файлом будет обращаться не к регистрам, а к кеш-памяти, то есть работать быстрее не будетТут же вопрос переключения контекста. Кеш L1 не надо сбрасывать при его переключении. Пришло прерывание от таймера — процессор увеличил 1 переменную (все регистры вообще не надо сохранять), вернулся к программе.
Только память DDR сейчас работает длинными передачами. Выгоднее отправить одну транзакцию на 256 байт, чем 7 транзакций по 8 байт.
Ну и используйте регистры длинными блоками.
А что произойдёт в момент переключения контекста? Всё несохранённое на текущем потоке надо сохранить в память
Всё несохранённое надо сохранять в любом процессоре. Надо сравнивать процессор и другой процессор, а не процессор и чудесное устройство, которое не пользуется кэш-памятью вообще. Размер несохранённого в процессоре с обычным регистровым файлом задано электронной схемой процессора (размер регистрового файла), а в процессоре с RSE задаётся динамически, как размер области стека, к которой программа часто обращается.
Всё несохранённое надо сохранять в любом процессореЯ же привёл пример: обработчик прерывания от железки может сохранить только пару регистров (которые он использует), всякие SSE-FPU вообще не трогать, увеличить какую-то переменную или поставить какой-то флажок и вернуть управление программе, которая была прервана. Кеш L1, играющий роль регистрового файла, останется нетронутым.
а в процессоре с RSE задаётся динамическиОчень интересно. Какой минимальный размер я могу запросить? Могу запросить 4 или 8 регистров? А если опкод обратится к 10-му, что будет?
А чем вам комдив в таком случае не нравится?
Ну или спарки от мцст, что то там у модуля, элвис ещё и прочие?
А еще можно взять пару вёдер логики серии K155 и построить процессор на ней - вполне доступное, полностью отечественное решение. На чем там Эльбрус 3 был собран ? ;-)
Для того, что бы процессор был сделан в России, в России нужно сначала построить фабрику по выпеканию кристаллов по современным тех процессам. Но для этого, во-первых нет такого количества денег (около $10 млрд на саму фабрику и еще столько же на заводики обеспечения размером поменьше), во-вторых, нет технологий - все оборудование импортное и под жестким контролем американцев, приобрести его не представляется возможным. Перед тем как построить фабрику, нужно еще решить вопрос с поставкой расходных материалов и программным обеспечением, все это тоже находится в руках наших западных партнёров. А еще перед этим нужно вырастить специалистов в этой области и сделать так, что бы они не сбежали на Запад до того, как фабрика будет построена и не умерли от старости. Иными словами, про процессор "сделанный в России" в ближайшие лет 30 можно смело забыть.
России нужно налаживать отношения с Западом и включаться в общий поток развития технологий, брать на себя какой-то небольшой участок этого необьятного процесса, двигать его вперед и коммитить результаты в общий котёл. Одной из таких тем, я считают, может быть разработка архитектуры и микроархитектуры RISC-V и высокопроизводительных процессоров на ней. Другой такой темой может быть разработка новых методов литографии (с использованием рентгена) и наладка серийного производства станков. В обеих темах у нас есть все шансы быть в авангарде и заслужить признание мировой общественности. Что в свою очередь приведет к более тесной интеграции и невозможности отрезать нас от мировых производителей и технологий производства. Нужно интегрироваться в мировое сообщество, а не отгораживаться от него со словами "сейчас мы наш православный процессор построим и тогда ух...".
про процессор «сделанный в России» в ближайшие лет 30 можно смело забыть.Не «тридцать лет», а навсегда забыть. Микроэлектроника — глобализованная отрасль, что бы по этому поводу ни думали правительства России, США или Китая.
Другой такой темой может быть разработка новых методов литографии (с использованием рентгена)В смысле, заново изобрести EUV?
В смысле, заново изобрести EUV?
EUV это "недорентген" (l=13.5нм). Сейчас идут дебаты по поводу использования более высоких частот с длиной волны до 6нм, что позволит производить структуры в несколько атомов. Там есть масса нерешенных задач, за которые можно взяться имея под собой хорошую финансовую опору и материальную базу. И даже в EUV тоже есть чем заниматься - тут недавно была статья про многослойные зеркала от некого корейца который на самом деле украинец работающий в китае.
Вот нашел статью в Nature, новая потенциальная технология называется Beyond-EUV (BEUV).
EUV это «недорентген» (l=13.5нм).Рентген — это все, что имеет длину волны ниже 100 нм, а не ниже 10. EUV называют иначе в силу сложившихся исторических причин, а именно громкого провала ранних попыток создания рентгеновской литографии, подмочивших репутацию и уверенность инвесторов. Тем не менее, EUV — вполне себе рентгеновское излучение.
новая потенциальная технология называется Beyond-EUV (BEUV).BEUV — это не новая технология, а логическое развитие EUV, и нет никаких причин, по которым какие-то российские компании смогут внезапно преодолеть многолетнее отставание и опередить ASML или даже китайцев. В отличие от условий уважаемого koreec, никакими «неограниченными бюджетами» на такие исследования в России и не пахнет.
А, вот и пришли пользователи, которые заявляют, что если абсолютно всё не было сделано в одно рыло, то и нечего вообще делать продукт.
А человек такого нигде не заявлял. Это очень креативное искажение его слов.
А это как Суд обязал «Т-платформы» вернуть Минпромторгу 3,26 млрд руб. субсидий за провал при разработке систем на чипах «Байкал»А это так что Опанасенко сначала посадили, потом, чтобы выпустить, вынудили отдать «Байкал» кому надо, а потом еще три миллиарда долга на него повесили, чтобы не скучал после выхода на свободу.
А упомянутый провал в разработке систем был вызван как раз тем, что владелец компании сел в тюрьму.
Это все конечно классно, супер, вы молодцы! Но где тестовые платы за адекватные деньги для того, чтобы потестить?
И я не про продакшн варианты, а про образцы ну не за 100к как с остальными эльбрусами... Для обычных людей :)
статья хорошая, решения описываются интересные.
но я так и остаюсь при своём мнении: vliw не нужен.
Архитектура и особенности процессора Эльбрус 2000