Как и многие языки, Go часто использует магию под названием хип (heap). Обычно, когда мы пишем наши джейсоно-гонятели, мы просто не задумываемся об этом, хоть и знаем, что это «где-то есть». Давайте попробуем заглянуть в кроличью нору поглубже и увидеть не только то, какими методами аллокатор Go старается облегчить программисту жизнь, но и то, из чего он состоит в целом.
Меня зовут Антон Киреев, я бэкенд-разработчик с опытом работы больше 11 лет. В настоящее время работаю техлидом в Авито. В жизни мне нравятся две вещи: приносить пользу своей работой и проводить свободное время с семьёй. Именно поэтому я люблю делать что-то быстро, но качественно, а потом отдыхать. Для этого я постоянно учусь и пытаюсь докапываться до сути вещей. Сегодня поговорим, как наша любимая Гошечка работает с памятью.

Стек
Каждый из вас знает базовые концепции работы стека (stack). Поэтому давайте опустим теорию и представим его работу в виде кода.

Здесь в левой части мы видим код, который будет исполняться нами как компилятором. В правой части — представление стека. Запускаем программу, выполняем, смотрим:
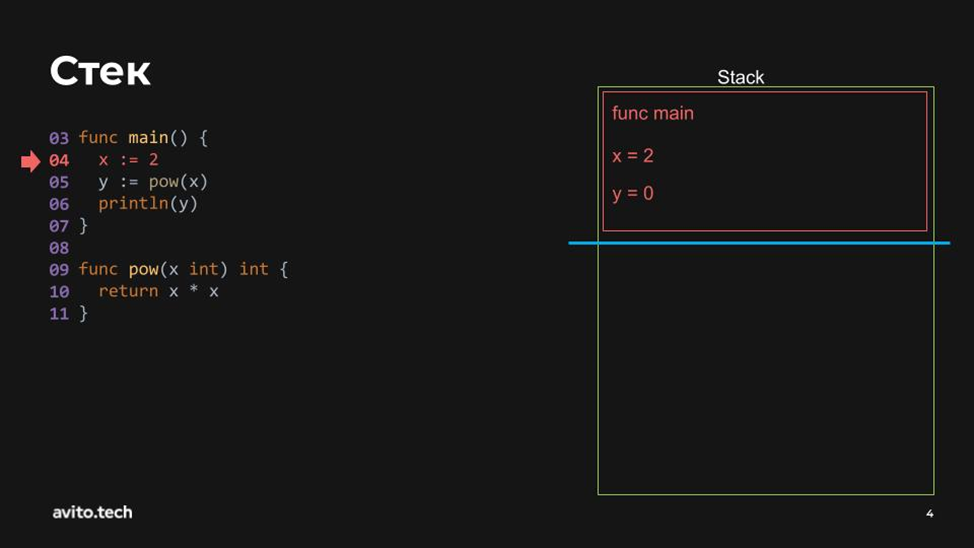
Вначале инициализируются переменные. Видим, что x=2, а y=0, потому что мы пока ещё не знаем, что вернет функция, которая получает значение и возводит его в квадрат.
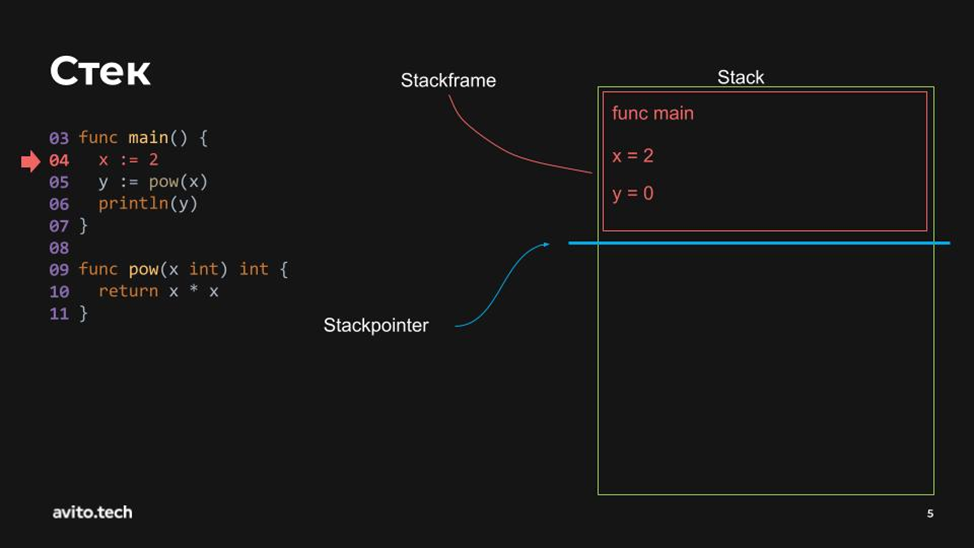
Здесь красный прямоугольник — это представление стек-фрейма, а синяя линия — это стек-пойнтер. Пока всё по канонам, всё по книгам: создался стек-фрейм, а стек-пойнтер сдвинулся вниз.
Идём дальше.

Встретили функцию возведения в степень 2. Переменная x заходит в неё и умножается на саму себя, назад возвращается y=4.
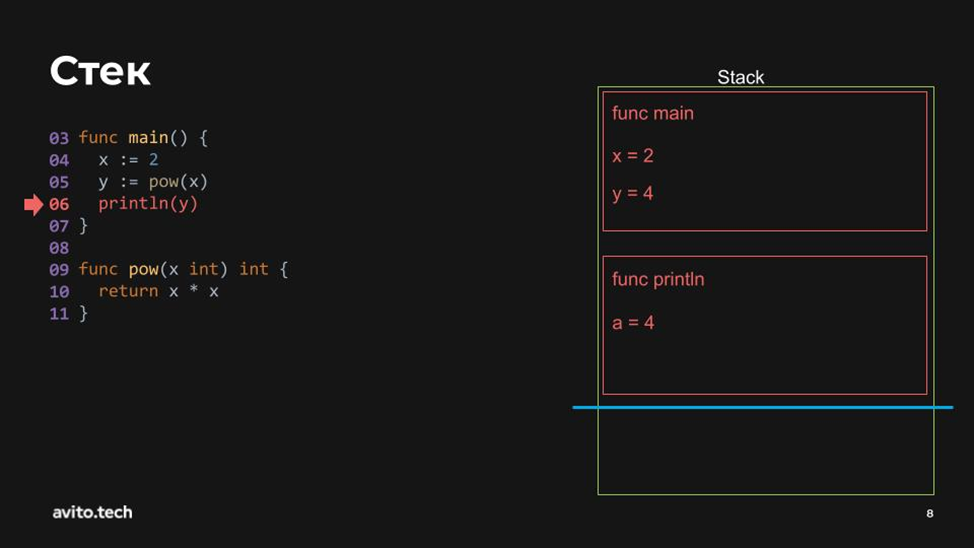
Передаём результат в println. Все замечательно и вроде бы просто.
Проверим байку: «если в вашем коде есть ссылка или указатель, то это хранится где угодно, но только не на стеке».
Для этого переделаем программу:

Теперь у нас есть функция inc, которая получает значение по ссылке, и увеличивает ее на 1. Запускаем, смотрим:

Итак, инициализируется x=2. Это понятно. Но здесь ещё появился некоторый адрес. Пусть он будет просто 0xc000040842. Идём дальше. Встречаем функцию inc и передаём туда адрес переменной x.

Теперь этот адрес хранится по другому адресу, 0xc000040742, который находится в другом стек-фрейме. Тоже все понятно. Дальше мы увеличиваем значение по адресу 0xc000040842 на 1 и возвращаемся назад. Получаем x=3.
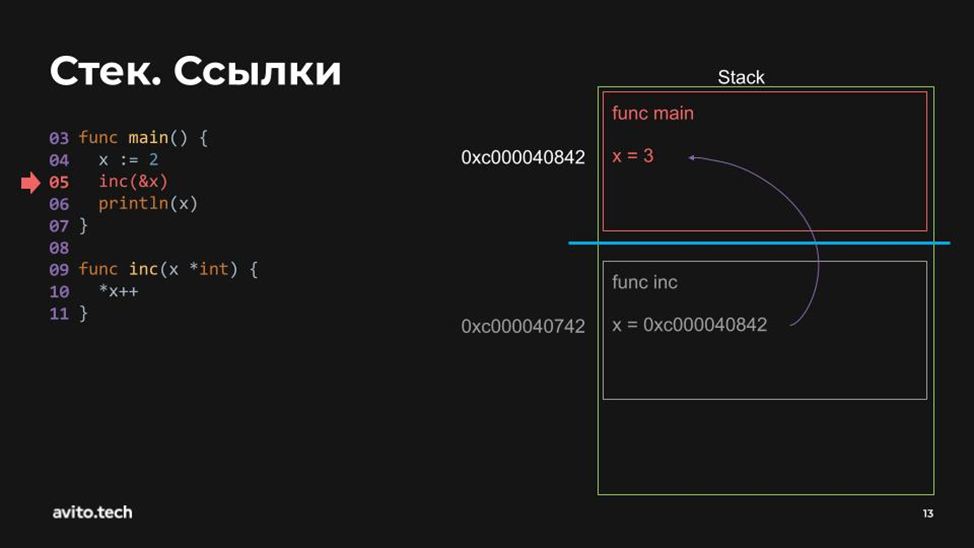
Передаём в println:

Итак, байка неверна. Переменная осталась на стеке.
Проблема висячего указателя
Хорошо, давайте ещё чуть усложним!
Теперь значение будем получать из некой функции — и не просто значение, а ссылку на него.

Глянем, что будет происходить.

Мы проинициализировали x равный nil, потому что мы пока не знаем, что вернет функция getValue.

Затем мы зашли в getValue, инициализировали x=4 по адресу 0xc000040742. Заметьте, что этот адрес находится в следующем стек-фрейме.
Потом мы этот адрес из второго стек-фрейма, который остаётся на месте, хотя стек-пойнтер сдвинулся вверх, передали в адрес 0xc000040842. Что произойдёт дальше?
А дальше идёт функция println, которая создаст новый стек-фрейм на предыдущем, и возникает «dangling pointer» (висячий указатель).
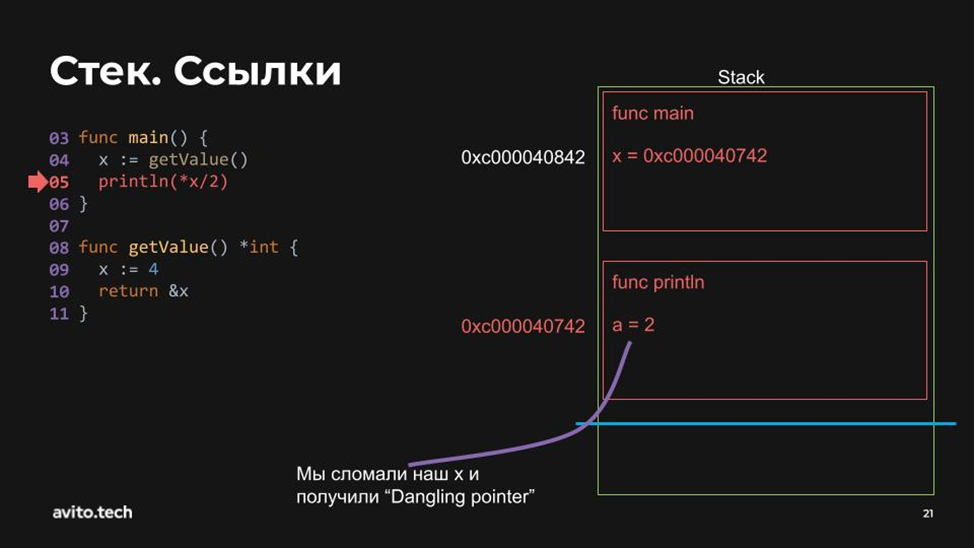
Мы поломали наше приложение. Теперь адрес 0xc000040742 больше не отсылает к x, так как x была стёрта в другом стеке. Как это можно починить?
А что, если хранить не в стеке?
Представим, что помимо стека есть ещё другое место, где можно сохранять переменные. Мы уже знаем, что адрес переменной x будет передан вовне функции. Поэтому повторим наши последние действия, но заведём значение x в некоем другом месте и вернём адрес оттуда.
Таким образом, когда мы потом перейдём в функцию println, то мы ничего не сотрём, и наша программа корректно отработает: x=4 останется в памяти по заданному адресу.
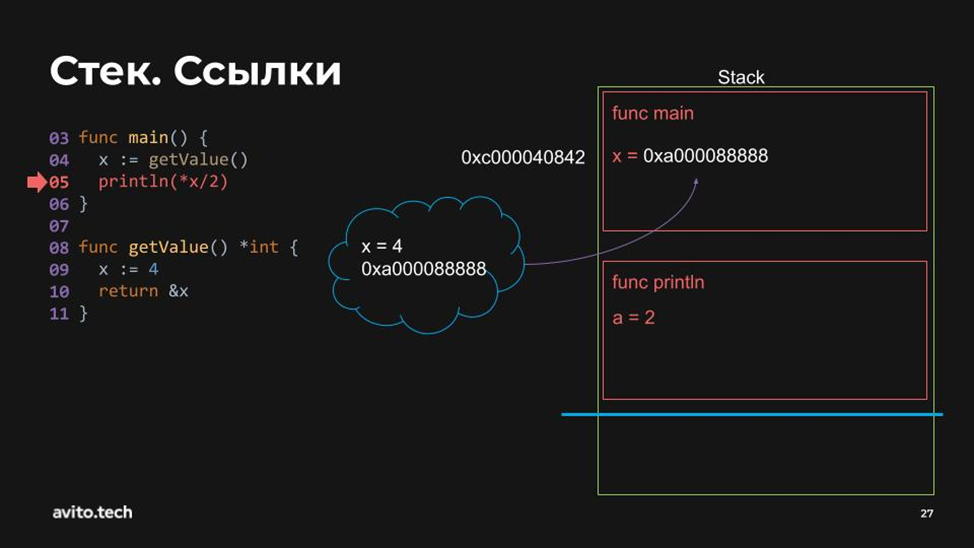
Это стало возможно благодаря хип (heap) — тому самому другому месту вне стека.
Как я могу знать, где Golang выделяет память под переменные — в хип или в стек?
Посмотреть, где у вас выделяются значения — на хипе или на стеке — можно путем команды: go build -gcflags=«-m». Причём, чем больше букв m, тем более подробно будет выведена информация.
Тем не менее разработчики языка гарантируют, что Golang всегда будет стараться выделить значение переменных на стеке, кроме некоторых исключительных ситуаций. Чтобы выяснить их, рассмотрим Escape Analysis. Escape Analysis — это механизм, который решает, будет ли храниться значение на стеке или на хипе.
Устройство escape analysis
Сначала нужно заклонить source код Golang и зайти в пакет gc. В файле /go/src/cmd/compile/internal/gc/main.go находится entry point для escape analysis. Там вы увидите огромную функцию Main:

И где-то посередине есть вызов функции escape.Funcs. С этого момента начинается escape analysis.
Давайте посмотрим, что Funcs содержит внутри. Это обычная маленькая функция в одну строку:

По сути, она не очень интересная. Здесь интересен callback Batch. Разберём примерно его алгоритм.
В начале строится направленный граф весов. Что такое граф весов? Представим, что у нас есть структура T struct с полем Value, и есть некая функция tryToEscape, у которой 4 переменные. Причем l3 отдается по ссылке. Тогда по алгоритму будет построен граф:

Видим, что появилась переменная r1 — это так называемая псевдопеременная. В этом графе нодой являются сами переменные, ребра — это присваивание, а веса (0, -1, 1, -1) — это типы этих присваиваний:
0 проставляется в случае, если это обычное присваивание, как в случае l1 = a;
-1 проставляется, если мы берем ссылку от переменной;
1 — если идет разыменование.
Сам алгоритм, который решает должно ли значение уходить в heap или нет, находится в файле solve.go в пакете escape:
// file: cmd/compile/internal/escape/solve.go
Зная этот алгоритм, мы можем посмотреть на функцию Batch. Сама функция Batch тоже огромная:

Если разбивать это кусок кода на 3 части, то это будет выглядеть так:
1. Вначале строится граф
2. Потом происходит проверка на размер переменных. Дело в том, что у каждого типа переменной есть свой лимит на размер.
3. Наконец, обход графа (walkAll) и выдвижение решения того, уходит ли в хип переменная или нет.
Примерно так работает эскейп анализ. Теперь, понимая, как примерно устроен escape analysis в golang, мы можем посмотреть на устройство аллокатора heap.
Heap allocator и проблема фрагментации
Аллокатор хип основан на TCMalloc (Thread-Caching Allocator). Главная идея заключается в «слоистом» представлении памяти и в отдельных блоках памяти для каждого треда, в которые он обращается без lock.
Рассмотрим это более детально, но уже в языке Go. Представим, что у нас есть какое-то приложение и где-то есть виртуальная память для него. Мы говорим: «Дай нам, пожалуйста, кусочек памяти», и ОС его дает. Все замечательно. Но что произойдет, если мы внезапно захотим много кусочков памяти? В этом случае у нас произойдёт падение производительности.
Как с этим борются в Golang? Очень просто. Они просят не маленький кусочек памяти, а сразу огромный кусок, а потом решают, что с ним делать. Этот кусок памяти в аллокаторе называется ареной. Когда арена заканчивается, запрашивается ещё арена, и ещё арена, и ещё арена.

Размер этой арены рассчитывается по такой «маленькой» формуле:
logHeapArenaBytes=(6+20)(_64bit(1-goos.IsWindows)(1-goarch.IsWasm)(1-goos.IsIos*goarch.IsArm64))+(2+20)(_64bit*goos.IsWindows)+(2+20)(1-_64bit)+(2+20)*goarch.IsWasm+(2+20)*goos.IsIos*goarch.IsArm64
Чтобы не утруждать вас чтением этой формулы, есть табличка с размерами арен для каждой из платформ:

Здесь указано, на какой платформе какой размер арены. Например, если у вас лаптоп на Linux 64 bit, то у вас арена будет весить 64Mb.
Важно подчеркнуть, что арена — это не просто кусок памяти. Как только мы получаем арену, например, в 64мб, то она сразу будет поделена на 8kb странички.
Арены и странички (arena и pages) не имеют никакой метаинформации о них. Это просто вшитые константы, которые вычисляются на момент компиляции. Всем этим свором (аренами и страничками) управляет «мама»-структура — heap arena или mheap в самом аллокаторе.

Теперь представим, что есть некий фрагмент арены.

Пусть каждый маленький синий блок будет 1b. Мы говорим: «Хотим 4 байта!» — «Пожалуйста!»
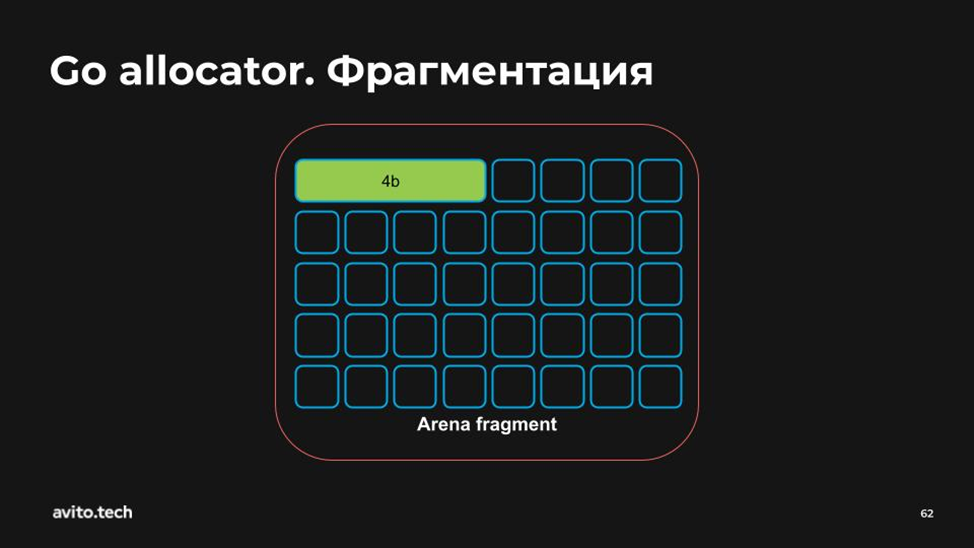
«Хотим 1 байт!» — «Пожалуйста!»
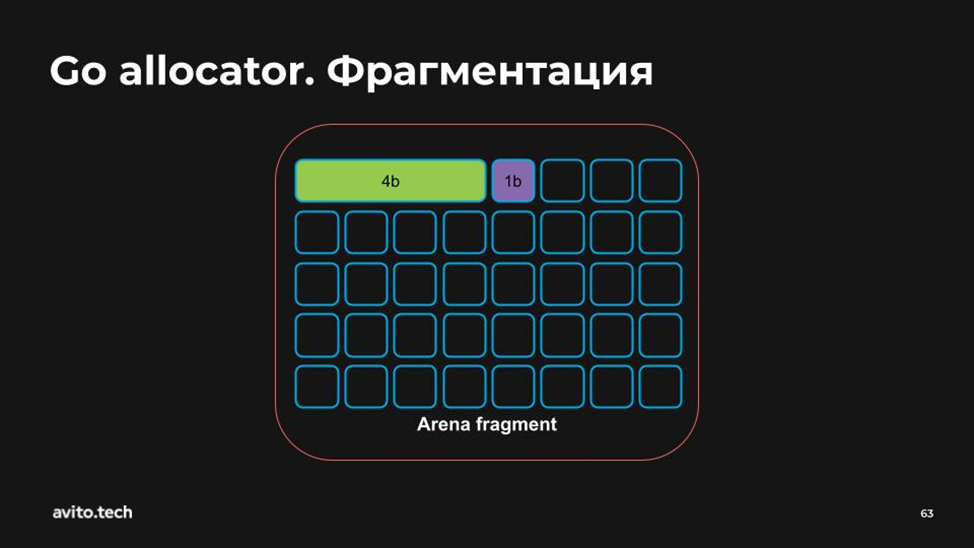
«Много байт!» — «Пожалуйста!»
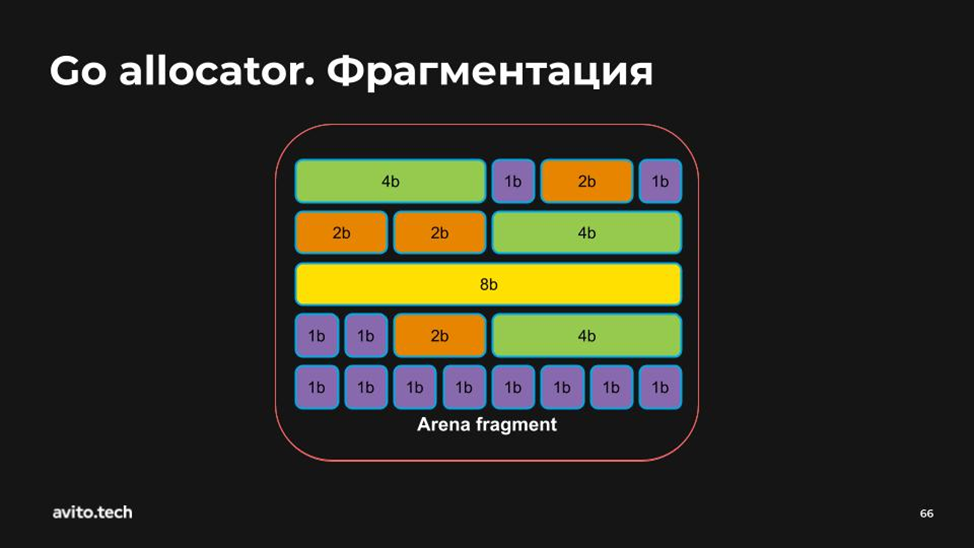
После того как мы поигрались, мы говорим, что не хотим вот эти и эти два байта — «Замечательно, я их удаляю!».

И мы радуемся, что у нас есть теперь 4 свободных байта, куда можно запихать переменную размером в 4b… А вот фигушки! Потому что эта пара по 2b находятся в разных местах. Мы получили так называемую внешнюю фрагментацию.
Как с ней борются в Golang? Разработчики начали думать. Так, есть программисты и есть использование разных размеров переменных. Давайте выясним, какого размера переменные часто используют программисты и создадим для этих размеров пулы.
Pool объектов
У нас есть арена. На этой арене выделим пулы для разных размеров переменных. То есть, если есть переменные в 16b, сразу выделим пул в 16b. Если есть переменная в 32b, сразу выделим пул в 32b, и т.д. Такой пул называется в аллокаторе mspan.
mspan — это минимальный юнит в аллокаторе, который уже имеет метаинформацию о переменных. У mspan есть поле spanClass, которое хранит тип класса для данного пула. Класс определяет для какого размера создан этот пул. Mspan 1-го класса означает, что он создан для переменных 8b, а если 3-го класса, то для переменных 24b.
Вы можете сами посмотреть какие есть классы так как разработчиками сгенерирована табличка со всеми этим классами и информацией по ним. Она находится в пакете runtime/sizeclasses.go
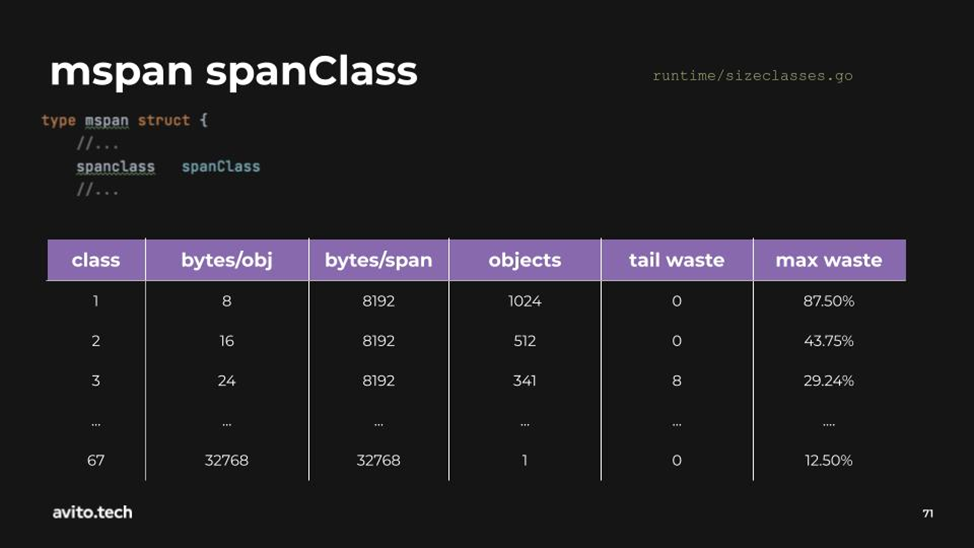
Третий столбец говорит о том, сколько страниц тратится на данный пул. Видно, что для mspan класса 1 тратится 1 страница, потому что в этом третьем столбце написано 8192 байта. В Golang всего 67 классов. Для 67-го класса тратится 4 страницы.
Четвертый столбец (objects) говорит, сколько, максимум, объектов помещается в этот пул. Посчитать это очень легко: возьмем первую строчку из таблицы, возьмем размер пула 8192 поделим на размер объекта в этом пуле 8 и получим количество этих объектов 1024.
Давайте теперь обратим внимание на последние два столбца: tail waste и max waste.
О чем говорит tail waste? Он говорит о том, что, используя пул с размером блока в 48 байт, к примеру, мы всегда гарантированно будем терять 32b потому, что пул состоит из одной страницы размером в 8192b. Пытаемся поделить её на 48 и понимаем, что никак на цело не делится. Получается, что у нас всегда будет пустовать 32b(как остаток от деления).
О чем говорит max waste? Он говорит о том, что в худшем случае для данного класса пула мы будем терять 31% памяти. Это так называемая внутренняя фрагментация.
Худший случай для класса 5 (пул 48b) — 33b, потому что это минимальный размер переменной, которое можно туда поместить, и мы всегда будем терять 15b. Они всегда будут пустовать в этом блоке. Об это нам и говорят разработчики.
Естественно, эти пулы заканчиваются, и когда это происходит, создаётся ещё один пул (ещё один mspan). Все эти mspan соединены друг с другом в двусторонний связанный список.
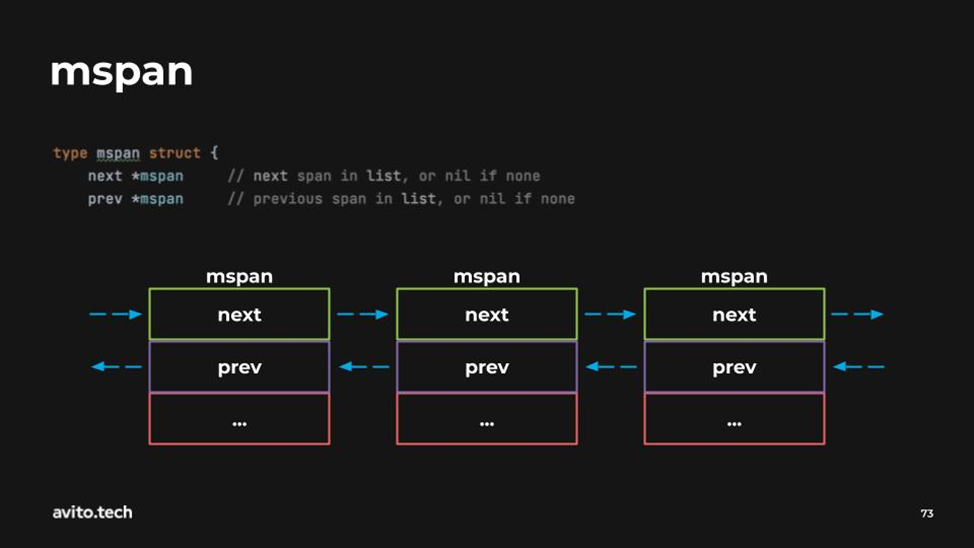
Поля next и prev указывают на следующее и предыдущее mspan.
Также из интересного — поле startAddr, которое говорит, где именно на арене начинается данный пул.
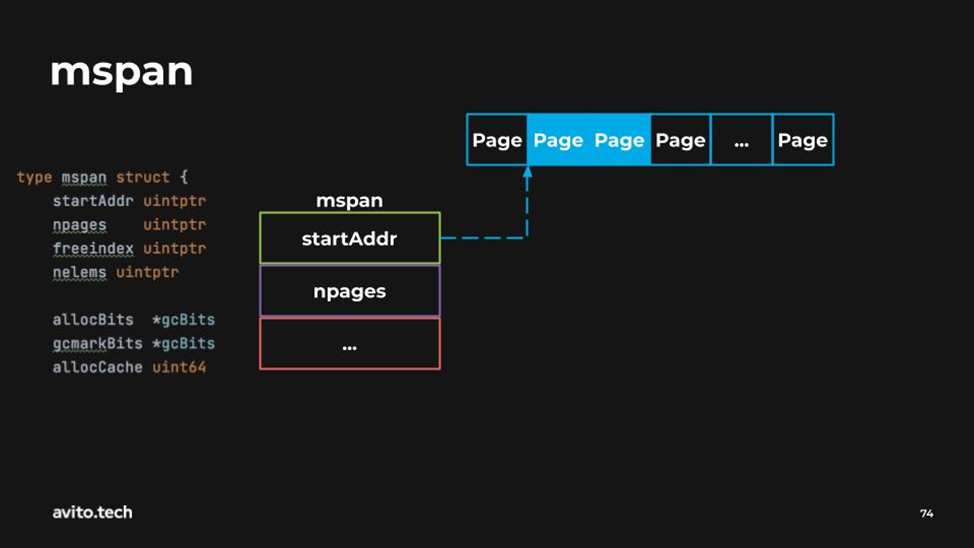
Кроме этого здесь есть:
1) Поле npages. Оно показывает из какого количества страниц состоит данный пул.
2) Поле freeindex. Оно нужно для того, чтобы моментально находить свободный блок в данном пуле.
3) Поле nelems. Оно говорит о том, сколько всего элементов в данном пуле
4) Также есть интересное поле allocBits. Оно показывает свободные ячейки в данном пуле. Нужно для поиска и для garbage collector.
Если mspan связывается в двусторонний список, то должна быть какая-то структура, которая управляет этим списком. За это отвечает структура mcentral. Один mcentral закрепляется за одним классом. Соответственно, всего будет 67 mcentral, так как всего 67 классов.

Отсюда, у mcentral есть поле spanclass, которое говорит, что данный mcentral принадлежит такому-то классу, и в нем содержаться mspan такого-то класса. Также у mcentral есть два списка:
· nonempty. В нем содержится список mspan, в которых уже есть какая-то информация.
· еmpty, в котором содержатся пустые mspan
С течением runtime эти списки друг с другом тусуются. Если где-то освобождается информация, то mspan переходит в empty. Если где-то информация занимает место, то mspan переходит в nonempty.
Go Concurrency model. Работа с несколькими тредами
Что, если у нас несколько тредов и один блок памяти? Если треды начнут запрашивать память, мы получим race condition. Как с этим можно бороться?
Мы знаем , что в ситуации c race condition нас точно спасет lock. Если первый тред запрашивает память, то мы ставим lock, выделяем и записываем память. Если второй, то пусть ждет, пока первый доделает свои дела.

Всё просто, но мы получаем падение производительности. Пока кто-то чего-то дождётся, только потеряем время.
Разработчики Golang борются с этим очень просто — вводом кэша.
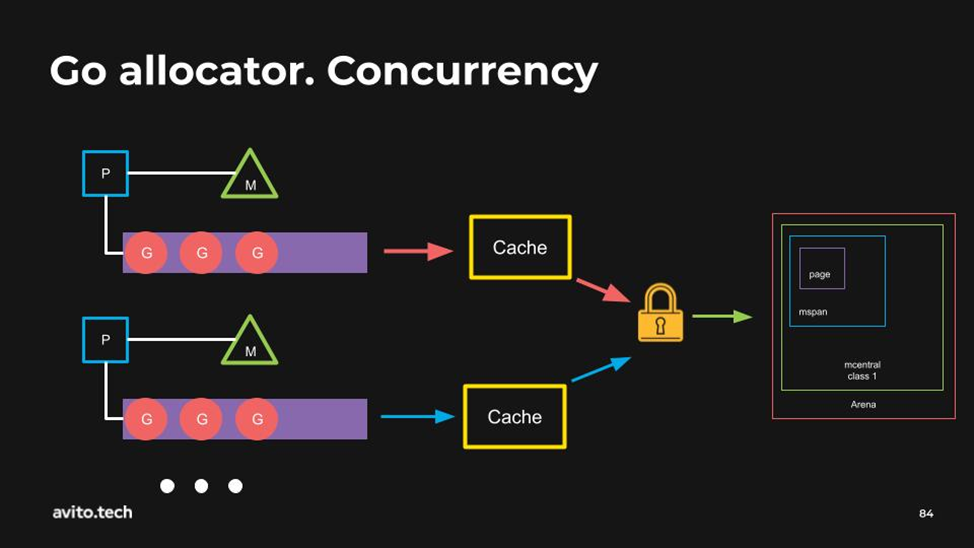
На каждый тред есть сразу отдельный блок памяти с выделенным для него mspan. Каждый тред работает со своим определённым кешем. За этот кеш отвечает структура mcache.

Из интересного - mcache имеет поле alloc. Это массив, состоящий всего лишь из 2 элементов с индексом 0 и 1. По индексу 0 лежит двусвязный список mspan, который содержит в себе переменные, указатели на другие указатели. По индексу 1 лежат переменные, которые не содержат указатели. Это некая оптимизация для garbage collector, чтобы он лишний раз не делал traverse.
Подводя итоги
Есть три неизменяемых правила выделения памяти от версии к версии Golang. У вас 100% выделится значение на хипе, если:
Возврат результата происходит по ссылке;
Значение передается в аргумент типа interface{} — аргумент fmt.Println;
Размер значения переменной превышает лимиты стека.
Почему так? Мы выяснили это, разобрав устройство аллокатора Go.
Что мы узнали:
01. Как работает стек;
02. Как устроен escape analysis;
03. Как устроен heap;
Главный вопрос — а зачем нам это?
В случае, когда мы просто программируем, всё хорошо. Но как только случается какая-то сложная ситуация, мы просто уходим туда с головой. Она может быть очень нудной! И мы не знаем, как ее решить. Но владея этой информацией, мы можем ее быстро решить, сказать боссу, что это было очень трудно, а в это время просто сидеть и читать Медиум или Хабр.
Покажу пример:

Вроде, код очень простой. Есть цикл, и в нем определяется структура X. Заметьте, что она определяется два раза по-разному:
Создается ссылка на нее, и в ней сразу инициализируется поле p.
Сначала создается структура, и только потом уже записывается поле p.
Казалось бы, это должно работать одинаково. Применим полученные знания и запустим escape analysis.

Переменная i2 ушла в хип. Почему так и на что это может повлиять ?
Вот на что. Так выглядит benchmark куска кода, когда мы сразу инициализируем поле p:

Видно, что потратилось 0,2 ns.
А так выглядит кусок кода, когда мы после инициализации самой структуры инициализируем какое-то поле:

Приглашаем вас на Saint Highload++ 2022 - конференцию разработчиков высоконагруженных систем, которая пройдет 22-23 сентября в Санкт-Петербурге. Расписание опубликовано. Билеты можно бронировать здесь.
