В предыдущих статьях мы уже показывали на реальных событиях, что термин Big Data, «засаленный и потертый», переходит в фазу «разочарования»:
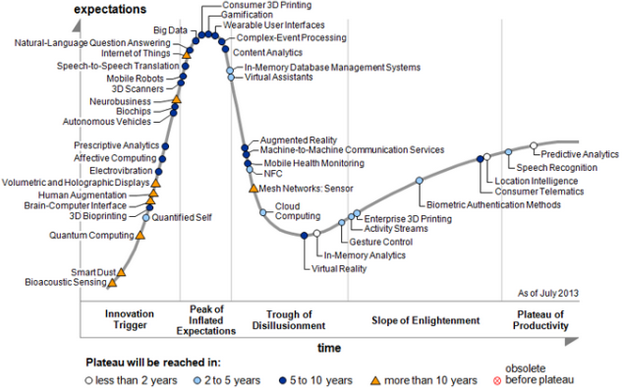
В качестве еще одного гвоздика в крышку приводим перевод одной из ряда статей очередного разочарования. Так ли все плохо и в чем Big Error такого подхода к Big Data — после статьи. Материал в любом случае полезен для ознакомления, поскольку содержит несколько важных ссылок на индустриальные исследования и наборы данных.
Big Data — осознание: Мы находимся в переходном этапе
Недавно читал публикацию от Али Сайеда, озаглавленную как «Европейцы не верят в эффективность Big Data».
Это исследование проводилось по заказу Института Общества и Коммуникаций Vodafone исследователями рынка из TNS Infratest. В нём участвовало более 8,000 человек из 8 европейских государств и на его примере можно увидить отношение людей как к Big Data, так и к аналитике в целом.
Всё ещё есть люди, которые не верят в тот факт, что мы живём в эпоху Big Data. Другими словами, они считают, что что вопрос Big Data просто сильно переоценен, и вся шумиха вокруг него скоро утихнет.
Для меня понятие Big Data отнюдь не ново. Мы лишь постепенно получаем навыки для большего и лучшего их анализа. И это есть лишь начало, и чем дальше этот процесс будет идти, тем больше простой человек уверует в Big Data.
Помню, как на одной конференции, посвящённой Big Data в марте 2013 года, профессор статистики спорил с остальными её участниками, говоря, что такого понятия, как Big Data попросту не существует, поскольку для того, чтобы данные можно было анализировать и извлекать из них статистику, то их нужно уменьшить в количестве и разбить на небольшие группы.
Встреча с Big Data неизбежна для каждого. Одна из возможных причин недоверия людей к Big Data может быть в том, что они попросту не имеют к ним доступа. Как говорится, лучше один раз увидеть. Компании, работающие с Big Data постепенно публикуют свои ранее секретные инструменты и массивные наборы данных, чтобы мировая общественность сделала наконец этот шаг вперёд и прочувствовала Big Data.
В ноябре 2015 года Google выпустил TensorFlow – алгоритм глубокого анализа, использующий Big Data, а затем, в январе 2016 года Yahoo выпустили "Самый большой набор данных для машинного анализа" — аж 13.5 терабайт неархивированных данных.
По словам главы проекта из Yahoo Labs: “У многих исследователей и аналитиков данных нет доступа к реально большим массивам и наборам данных, так как это, как правило, является привилегией очень крупных компаний. Мы обнародовали наш набор данных потому, что мы ценим открытое и взаимовыгодное сотрудничество с нашими коллегами и всегда стремимся продвигать технологии машинного анализа.”
Мы живём в переходном периоде времени, и пока что не существует того, что можно назвать абсолютными Big Data, а точные объёмы восприятия «большизны» разнятся от человека к человеку. Для кого-то и гигабайт уже Big Data, а кому то мало и петабайта, и это зависит от ёмкости хранилища и вычислительных мощностей.
Объёмы данных всё продолжают и продолжают расти, но напрашивается очевидный вопрос: А достигнем ли мы когда-нибудь максимально возможный объём данных, который мы сможем хранить и использовать? Я считаю, что да, это возможно, поскольку о таком объёме данных нам когда то говорил великий учёный Лаплас.
В Демоне Лапласа утверждается: «Мы можем рассматривать настоящее состояние Вселенной как следствие его прошлого и причину его будущего. Разум, которому в каждый определённый момент времени были бы известны все силы, приводящие природу в движение, и положение всех тел, из которых она состоит, будь он также достаточно обширен, чтобы подвергнуть эти данные анализу, смог бы объять единым законом движение величайших тел Вселенной и мельчайшего атома; для такого разума ничего не было бы неясного и будущее существовало бы в его глазах точно так же, как прошлое..» — Пьер-Симон-Лаплас, Философское эссе о вероятностях.
Та же самая концепция была перефразирована и Стивеном Хокингом: "По сути своей, он сказал то, что если бы в какой то конкретный момент мы бы знали положения и скорости всех частиц во вселенной, то мы бы смогли рассчитать их поведение в любой момент времени, как в прошлом, так и в будущем". Большим препятствием на пути к гипотезе Лапласа является принцип неопределённости Гейзенберга, но всё тот же Стивен Хокинг писал, что "И всё равно, предсказать комбинацию положения и скорости было бы возможно".
Если в один прекрасный день мы и сможем создать такой набор данных, то никто не останется неубеждённым ;)
Подводя итоги можно сказать, что мы живём во время переходного периода, когда люди начинают понимать, что возможные объёмы наборов данных всё растут и традиционные средства обработки данных не справятся с этой новой нагрузкой.
===========================================
Если применить законы диалектики, то в статье видна Big Error, о которой философы и ученые предупреждали еще в XIX веке: механистический подход не применим к усложняющимся структурам. Как физика не может объяснить законы молекулярной химии, как химия не может объяснить структуру мышления социума, так и «просто наборы данных» не являются Big Data.
Но, в любом случае, следует признать, что термин Big Data переживает этап спада (за исключением индустрии накопителей и хостинга), а взамен исследователи используют термины «более умные большие данные» — Smart/Clever (Big) Data.
P.S. Пока «ученые» считают и подсчитывают атомы во Вселенной и терабайты однотипных чеков из магазинов, индустрия движется быстрыми темпами вперед — ждем и участвуем в (про)движении! :-)
В качестве еще одного гвоздика в крышку приводим перевод одной из ряда статей очередного разочарования. Так ли все плохо и в чем Big Error такого подхода к Big Data — после статьи. Материал в любом случае полезен для ознакомления, поскольку содержит несколько важных ссылок на индустриальные исследования и наборы данных.
Big Data — осознание: Мы находимся в переходном этапе
Недавно читал публикацию от Али Сайеда, озаглавленную как «Европейцы не верят в эффективность Big Data».
Это исследование проводилось по заказу Института Общества и Коммуникаций Vodafone исследователями рынка из TNS Infratest. В нём участвовало более 8,000 человек из 8 европейских государств и на его примере можно увидить отношение людей как к Big Data, так и к аналитике в целом.
Всё ещё есть люди, которые не верят в тот факт, что мы живём в эпоху Big Data. Другими словами, они считают, что что вопрос Big Data просто сильно переоценен, и вся шумиха вокруг него скоро утихнет.
Для меня понятие Big Data отнюдь не ново. Мы лишь постепенно получаем навыки для большего и лучшего их анализа. И это есть лишь начало, и чем дальше этот процесс будет идти, тем больше простой человек уверует в Big Data.
Помню, как на одной конференции, посвящённой Big Data в марте 2013 года, профессор статистики спорил с остальными её участниками, говоря, что такого понятия, как Big Data попросту не существует, поскольку для того, чтобы данные можно было анализировать и извлекать из них статистику, то их нужно уменьшить в количестве и разбить на небольшие группы.
Встреча с Big Data неизбежна для каждого. Одна из возможных причин недоверия людей к Big Data может быть в том, что они попросту не имеют к ним доступа. Как говорится, лучше один раз увидеть. Компании, работающие с Big Data постепенно публикуют свои ранее секретные инструменты и массивные наборы данных, чтобы мировая общественность сделала наконец этот шаг вперёд и прочувствовала Big Data.
В ноябре 2015 года Google выпустил TensorFlow – алгоритм глубокого анализа, использующий Big Data, а затем, в январе 2016 года Yahoo выпустили "Самый большой набор данных для машинного анализа" — аж 13.5 терабайт неархивированных данных.
По словам главы проекта из Yahoo Labs: “У многих исследователей и аналитиков данных нет доступа к реально большим массивам и наборам данных, так как это, как правило, является привилегией очень крупных компаний. Мы обнародовали наш набор данных потому, что мы ценим открытое и взаимовыгодное сотрудничество с нашими коллегами и всегда стремимся продвигать технологии машинного анализа.”
Мы живём в переходном периоде времени, и пока что не существует того, что можно назвать абсолютными Big Data, а точные объёмы восприятия «большизны» разнятся от человека к человеку. Для кого-то и гигабайт уже Big Data, а кому то мало и петабайта, и это зависит от ёмкости хранилища и вычислительных мощностей.
Объёмы данных всё продолжают и продолжают расти, но напрашивается очевидный вопрос: А достигнем ли мы когда-нибудь максимально возможный объём данных, который мы сможем хранить и использовать? Я считаю, что да, это возможно, поскольку о таком объёме данных нам когда то говорил великий учёный Лаплас.
В Демоне Лапласа утверждается: «Мы можем рассматривать настоящее состояние Вселенной как следствие его прошлого и причину его будущего. Разум, которому в каждый определённый момент времени были бы известны все силы, приводящие природу в движение, и положение всех тел, из которых она состоит, будь он также достаточно обширен, чтобы подвергнуть эти данные анализу, смог бы объять единым законом движение величайших тел Вселенной и мельчайшего атома; для такого разума ничего не было бы неясного и будущее существовало бы в его глазах точно так же, как прошлое..» — Пьер-Симон-Лаплас, Философское эссе о вероятностях.
Та же самая концепция была перефразирована и Стивеном Хокингом: "По сути своей, он сказал то, что если бы в какой то конкретный момент мы бы знали положения и скорости всех частиц во вселенной, то мы бы смогли рассчитать их поведение в любой момент времени, как в прошлом, так и в будущем". Большим препятствием на пути к гипотезе Лапласа является принцип неопределённости Гейзенберга, но всё тот же Стивен Хокинг писал, что "И всё равно, предсказать комбинацию положения и скорости было бы возможно".
Если в один прекрасный день мы и сможем создать такой набор данных, то никто не останется неубеждённым ;)
Подводя итоги можно сказать, что мы живём во время переходного периода, когда люди начинают понимать, что возможные объёмы наборов данных всё растут и традиционные средства обработки данных не справятся с этой новой нагрузкой.
===========================================
Если применить законы диалектики, то в статье видна Big Error, о которой философы и ученые предупреждали еще в XIX веке: механистический подход не применим к усложняющимся структурам. Как физика не может объяснить законы молекулярной химии, как химия не может объяснить структуру мышления социума, так и «просто наборы данных» не являются Big Data.
Но, в любом случае, следует признать, что термин Big Data переживает этап спада (за исключением индустрии накопителей и хостинга), а взамен исследователи используют термины «более умные большие данные» — Smart/Clever (Big) Data.
P.S. Пока «ученые» считают и подсчитывают атомы во Вселенной и терабайты однотипных чеков из магазинов, индустрия движется быстрыми темпами вперед — ждем и участвуем в (про)движении! :-)
