Привет, Хабр!
Напоминаем, что у нас вышла очередная чрезвычайно интересная и полезная книга о паттернах Kubernetes. Начиналось все еще с "Паттернов" Брендана Бернса, и, впрочем, работа в этом сегменте у нас кипит. Сегодня же мы предлагаем вам почитать статью из блога MinIO, кратко излагающую тенденции и специфику паттернов хранения данных в Kubernetes.
Kubernetes фундаментальным образом изменил традиционные паттерны разработки и развертывания приложений. Теперь у команды могут уходить считанные дни на разработку, тестирование и развертывание приложения – в разных окружениях, и все это в пределах кластеров Kubernetes. Такая работа с технологиями предыдущих поколений обычно занимала целые недели, если не месяцы.
Такое ускорение стало возможно благодаря абстракции, обеспечиваемой Kubernetes — то есть, благодаря тому, что Kubernetes сам осуществляет взаимодействие с низкоуровневыми деталями физических или виртуальных машин, позволяя пользователям объявлять среди прочих параметров нужный процессор, нужный объем памяти, количество экземпляров контейнеров. Поскольку поддержкой Kubernetes занято огромное сообщество, а масштабы применения Kubernetes постоянно расширяются, он с большим отрывом лидирует среди всех платформ оркестрации контейнеров.
По мере расширения использования Kubernetes растет и путаница по поводу применяемых в нем паттернов хранения данных.
При всеобщей конкуренции за кусок пирога Kubernetes (то есть, за хранилище данных), когда заходит разговор о хранении данных, сигнал здесь тонет в сильном шуме.
Kubernetes воплощает современную модель разработки и развертывания приложений, а также управления ими. Такая современная модель открепляет хранение данных от вычислений. Чтобы полностью понять такое открепление в контексте Kubernetes, также нужно понять, что такое приложения, работающие с сохранением состояния и без сохранения состояния, а также как с этим сочетается хранение данных. Именно здесь REST API подход, применяемый S3, обладает явными преимуществами по сравнению с подходом POSIX/CSI, характерным для других решений.
В этой статье мы поговорим о паттернах хранения данных в Kubernetes и отдельно коснемся спора о приложениях, работающих с сохранением и без сохранения состояния, чтобы как следует понять, в чем же заключается разница между ними, и почему она важна. Далее в тексте будут рассмотрены приложения и применяемые в них паттерны хранения данных в свете наилучших практик работы с контейнерами и Kubernetes.
Контейнеры без сохранения состояния
Контейнеры по природе своей легковесны и эфемерны. Их можно без труда останавливать, удалять или развертывать на другом узле – на все это уходят считанные секунды. В большой системе оркестрации контейнеров такие операции происходят постоянно, и пользователи даже не замечают таких перемен. Однако, перемещения возможны, только если у контейнера нет никаких зависимостей от узла, на котором он расположен. О таких контейнерах говорят, что они работают без сохранения состояния.
Контейнеры с сохранением состояния
Если контейнер хранит данные на локально подключенных устройствах (или на блочном устройстве), то хранилище данных, на котором он расположен, придется перемещать на новый узел вместе с самим контейнером — в случае отказа. Это важно, поскольку в противном случае приложение, запущенное в контейнере, не сможет правильно функционировать, так как ему необходимо обращаться к данным, сохраненным на локальных носителях. О таких контейнерах говорят, что они работают с сохранением состояния.
С чисто технической точки зрения, контейнеры с сохранением состояния также можно перемещать на другие узлы. Обычно это обеспечивается при помощи распределенных файловых систем или блочных сетевых хранилищ данных, прикрепленных ко всем узлам, на которых работают контейнеры. Таким образом, контейнеры получают доступ к томам для персистентного хранения данных, и информация хранится на дисках, находящихся по всей сети. Такой метод я назову «контейнерным подходом с сохранением состояния», и в оставшейся части статьи так и буду именовать его ради единообразия.

При типичном контейнерном подходе с сохранением состояния все поды приложений прикрепляются к одной распределенной файловой системе – получается своего рода разделяемое хранилище, где обретаются все данные приложений. Притом, что возможны некоторые вариации, это высокоуровневый подход.
Теперь же давайте разберемся, почему контейнерный подход с сохранением состояния в облачно-ориентированном мире является антипаттерном.
Облачно-ориентированное проектирование приложений
Традиционно приложения использовали базы данных для структурированного хранения информации и локальные диски или распределенные файловые системы, куда сбрасывались все неструктурированные или даже полуструктурированные данные. По мере того, как объемы неструктурированных данных росли, разработчики осознали, что POSIX чересчур «болтлив», сопряжен со значительными издержками и, в конечном итоге, мешает работе приложения при переходе к действительно большим масштабам.
Это в основном и поспособствовало появлению нового стандарта хранения данных, то есть, облачно-ориентированных хранилищ, работающих преимущественно на основе REST API и освобождающих приложение от обременительного обслуживания локального хранилища данных. В таком случае приложение фактически переходит в режим работы без сохранения состояния (поскольку состояние находится в удаленном хранилище). Современные приложения возводятся с нуля уже с учетом этого фактора. Как правило, любое современное приложение, обрабатывающее данные того или иного рода (логи, метаданные, блобы и т.д.) построено по облачно-ориентированной парадигме, где состояние переносится в специально выделенную для его хранения софтверную систему.
Контейнерный подход с сохранением состояния заставляет всю эту парадигму откатиться ровно к тому, с чего она начиналась!
При использовании интерфейсов POSIX для хранения данных приложения работают в том же духе, как если бы они сохраняли состояние, и из-за этого отступают от наиболее важных постулатов облачно-ориентированного проектирования, то есть, от возможности варьировать размеры рабочих потоков приложения в зависимости от входящей нагрузки, перемещаться на новый узел, как только актуальный узел откажет, и так далее.
Присмотревшись к этой ситуации внимательнее, обнаруживаем, что при выборе хранилища данных мы вновь и вновь сталкиваемся с дилеммой «POSIX против REST API», НО с дополнительным усугублением проблем POSIX, обусловленным распределенной природой окружений Kubernetes. В частности,
- POSIX болтлив: семантика POSIX требует ассоциировать с каждой операцией метаданные и дескрипторы файлов, которые помогают поддерживать состояние операции. Это приводит к значительным издержкам, не имеющим никакой реальной ценности. API для хранения объектов, в частности, S3 API, избавились от этих требований, позволяя приложению сработать, а затем «забыть» о вызове. Отклик системы хранения данных указывает, успешно было выполнено данное действие или нет. В случае неудачи приложение может выполнить повторную попытку.
- Сетевые ограничения: В распределенной системе подразумевается, что может существовать множество приложений, пытающихся записать данные на один и тот же прикрепленный носитель. Поэтому, мало того, что приложения будут конкурировать друг с другом за полосу передачи данных (чтобы отправить данные на носитель), сама система хранения данных будет конкурировать за эту полосу, рассылая данные по физическим дискам. Из-за словоохотливости POSIX количество сетевых вызовов вырастает в несколько раз. С другой стороны, S3 API обеспечивает четкое разграничение сетевых вызовов между теми, что поступают с клиента на сервер, и теми, что происходят в пределах сервера.
- Безопасность: Модель безопасности POSIX рассчитана на активное участие человека: администраторы конфигурируют конкретные уровни доступа для каждого пользователя или группы. Такая парадигма сложно адаптируется под облачно-ориентированный мир. Современные приложения зависят от моделей безопасности, завязанных на API, где права доступа определяются как набор политик, выделяются сервисные аккаунты, временные учетные данные и т.д.
- Управляемость: Контейнеры с сохранением состояния влекут определенные издержки, связанные с управлением. Речь о синхронизации параллельного доступа к данным, об обеспечении согласованности данных, все это требует внимательно взвесить, какие паттерны доступа к данным использовать. Приходится устанавливать, контролировать и конфигурировать дополнительные программы, не говоря уже о дополнительных усилиях, затрачиваемых на разработку.
Контейнерный интерфейс хранилища данных
Тогда как интерфейс контейнерного хранилища данных (CSI) отлично помог с распространением уровня томов Kubernetes, частично передав его сторонним вендорам хранилищ данных, но также случайно поспособствовал убеждению, что контейнерный подход с сохранением состояния является рекомендуемым методом хранения данных в Kubernetes.
CSI был разработан как стандарт предоставления произвольных систем блочного и файлового хранения данных унаследованным приложениям при работе с Kubernetes. И, как было показано в этой статье, единственная ситуация, в которой целесообразен контейнерный подход с сохранением состояния (и CSI в его нынешней форме) – когда само приложение является унаследованной системой, в которой невозможно добавить поддержку API объектного хранилища данных.
Важно понимать, что, используя CSI в его нынешней форме, то есть, монтируя тома при работе с современными приложениями, мы столкнемся примерно с такими же проблемами, что возникали и в системах, где хранение данных организовано в стиле POSIX.
Более качественный подход
В данном случае важно понимать, что большинство приложений по сути своей не заточены именно под работу с сохранением состояния или без сохранения состояния. Такое поведение зависит от общей архитектуры системы и от конкретных вариантов, выбранных при проектировании. Поговорим немного о приложениях, сохраняющих состояние.
В принципе, все данные приложений можно распределить на несколько обширных типов:
- Данные логов
- Данные меток времени
- Данные транзакций
- Метаданные
- Образы контейнеров
- Данные блобов (больших двоичных объектов)
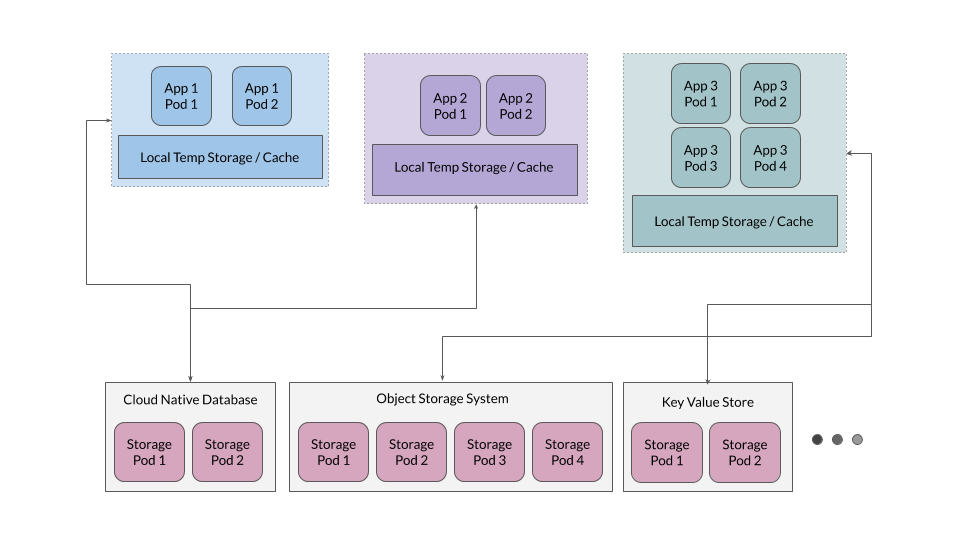
Все эти типы данных очень хорошо поддерживаются на современных платформах хранения данных, и существует несколько облачно-ориентированных платформ, приспособленных для поставки данных в каждом из этих конкретных форматов. Например, данные транзакций и метаданные могут находиться в современной облачно-ориентированной базе данных, такой как CockroachDB, YugaByte и т.д. Образы контейнеров или данные блобов могут храниться в реестре docker, основанном на MinIO. Данные временных меток могут храниться в базе данных временных рядов, например, InfluxDB и т.д. Не будем здесь вдаваться в детали каждого типа данных и соответствующих приложений, но общая идея в том, чтобы избежать персистентного хранения данных, основанного на локальном монтировании дисков.

Кроме того, зачастую оказывается эффективно предоставить уровень временного кэширования, служащий для приложений своеобразным хранилищем временных файлов, но приложения не должны зависеть от этого уровня как от источника истины.
Хранилище для приложений с сохранением состояния
Тогда как в большинстве случаев полезно держать приложения без сохранения состояния, те приложения, что предназначены для хранения данных – например, базы данных, объектные хранилища, хранилища ключей и значений – должны сохранять состояние. Давайте разберемся, почему эти приложения разворачивают на Kubernetes. В качестве примера возьмем MinIO, но подобные принципы применимы и к любым другим крупным облачно-ориентированным системам хранения данных.
Облачно-ориентированные приложения проектируются с расчетом на максимально эффективное использование гибкости, свойственной контейнерам. Это означает, что в них не делается никаких допущений относительно той среды, в которой они будут развертываться. Например, в MinIO используется внутренний механизм избыточного кодирования (erasure coding), обеспечивающий системе достаточную устойчивость, чтобы она оставалась работоспособной даже при отказе половины дисков. Также MinIO управляет целостностью и безопасностью данных, используя собственное хеширование и шифрование на стороне сервера.
Для таких облачно-ориентированных приложений в качестве резервного хранилища наиболее удобны локальные персистентные тома (PV). Локальный PV предоставляет возможность хранения сырых данных, тогда как приложения, работающие поверх этих PV, самостоятельно собирают информацию, позволяющую масштабировать данные и управлять растущими требованиями к данным.
Этот подход гораздо проще и значительно лучше масштабируется по сравнению с PV на основе CSI, которые привносят в систему собственные уровни управления данными и избыточности; дело в том, что эти уровни обычно конфликтуют с приложениями, спроектированными по принципу сохранения состояния.
Уверенное движение к откреплению данных от вычислений
В этой статье мы поговорили о том, как приложения переориентируются на работу без сохранения состояния, либо, иным словами, хранение данных отграничивается от вычислений над ними. В заключение рассмотрим несколько реальных примеров такого тренда.
Spark, знаменитая платформа для анализа данных, традиционно использовалась с сохранением состояния и с развертыванием в файловой системе HDFS. Однако, по мере перехода Spark а облачно-ориентированный мир, эта платформа все активнее используется без сохранения состояния с использованием `s3a`. Spark применяет s3a для передачи состояния в другие системы, тогда как сами контейнеры Spark работают целиком без сохранения состояния. Другие крупные enterprise-игроки в области аналитики больших данных, в частности, Vertica, Teradata, Greenplum также переходят к работе с разделением хранения данных и вычислений над ними.
Подобные паттерны также прослеживаются на других крупных аналитических платформах, среди которых Presto, Tensorflow to R, Jupyter. Выгружая состояние в удаленные облачные системы хранения данных, становится гораздо проще управлять вашим приложением и масштабировать его. Кроме того, это способствует портируемости приложения в разнообразные окружения.
