Всем привет! В июне в Новосибирске прошла конференция по разработке высоконагруженных приложений HighLoad++ Siberia 2019. Ранее в статьях на Хабре мы упоминали, что мы в компании Plesk проводим ретроспективу конференций и докладов, которые посещаем, чтобы не потерять полученные знания и впоследствии применить их. Мы расскажем, какие доклады для себя отметили, а также поделимся с вами рецептом ретроспективы. Организаторы постепенно выкладывают видео сюда: youtube-канал. Часть из того, что мы описываем, уже можно посмотреть.
Это обзорный доклад об успешной миграции Redis → PostgreSQL → Pgbouncer + PostgreSQL → Patroni Consul + Pgbouncer + PostgreSQL. Автор приводит схемы, типовые подводные камни очевидных решений, рассказывает об альтернативных решениях и почему они не подошли. Из интересного:
Полезно посмотреть тем, кто использует или собирается использовать PostgreSQL, и у кого растёт количество данных.
В качестве вводной докладчик провёл краткое сравнение некоторых особенностей Kafka и RabbitMQ. Коротко: Kafka — простая очередь, сложный получатель; RabbitMQ — сложная очередь, простой получатель. Также автор рассказал про виды гарантий доставки сообщения из очереди. Важное замечание: ни одна очередь не может обеспечить доставку сообщения ровно 1 раз без поддержки на отправителе и получателе.
Доклад посвящён YandexMQ. YandexMQ (YMQ) — совместимая по API с Amazon SQS очередь. Основой YandexMQ является Yandex Database (YDB). Василий показал, в чём преимущество YandexMQ, как достигают строгой консистентности и безотказности, и сделал обзор архитектуры YMQ. YMQ реализует паттерн «Competing consumers» — одно сообщение одному потребителю. Фишка YMQ: когда consumer просит сообщение, то в очереди оно скрывается, чтобы больше никто его не взял в обработку. Если при обработке возникли проблемы, то после VisibilityTimeout сообщение снова становится видимым в очереди. Докладчик утверждает, что у Apache Kafka есть проблема потери данных при внезапном уничтожении процесса, Yandex MessageQueue устойчив к этому.

Доклад рекомендован всем, кто хочет разобраться в принципиальных особенностях очередей.
Доклад о том, как хранить и обрабатывать в PostgreSQL time series данные.
TimescaleDB позволяет хранить большие объёмы за счёт хитрого партицирования, а PipelineDB предоставляет работу со стримами прямо в PostgreSQL (а также интеграцию с очередями).
TimescaleDB:
Основная мысль: TimescaleDB нужна в первую очередь для хранения данных.
PipelineDB:
Основная мысль: PipelineDB нужна в первую очередь для обработки данных.

Для задач, где одновременно необходима реляционная СУБД, NoSQL и time series, данный вариант может быть довольно удобен.
Хороший обзорный доклад про PostgreSQL, наследование таблиц и Tips&Tricks производительности PostgreSQL 10, 11, 12+. Секционирование через наследование, шардинг. Полезно посмотреть всем, кто использует PostgreSQL и хочет сделать его чуть быстрее.
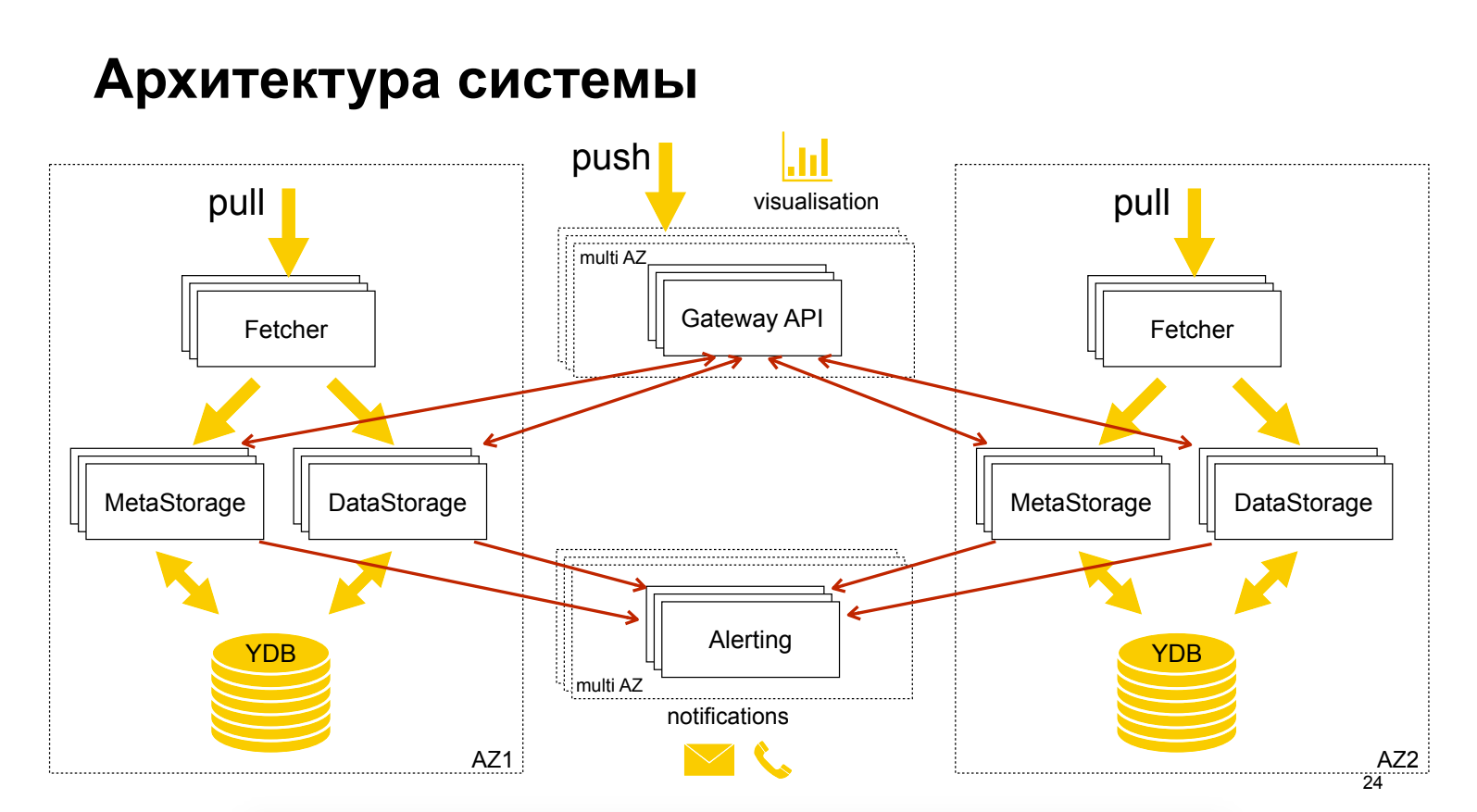
Об облачном продукте Yandex Monitoring, который пока в стадии «Preview» — бесплатный. Довольно подробно рассказано об архитектуре. Показан интересный приём — отделение метаданных от данных, которое даёт возможность независимого масштабирования и оптимизации. В качестве GUI используется Grafana, при этом оповещения свои, не в Grafana.

Опыт коммерческого системного администрирования множества серверов PostgreSQL. Рассказывается о том, какие параметры серверов автоматически отслеживаются, как расставляются приоритеты задач.
В Data Egret используют обобщенный опыт в Wiki с рецептами, чек-листами — это является основой для будущих статей и докладов. Используют базу инцидентов с описанием проблем и решений — это существенно экономит ресурсы. Выпустили ряд утилит для работы с PostgreSQL, приводят ссылки на них.

Доклад об архитектуре сложного, высокодоступного, распределённого приложения Яндекс.Маркет и о процессах и инструментах его разработки, тестирования, обновления, мониторинга. Из интересного:

Доклад о том, чем хорош ClickHouse, и как его готовить в связке с Grafana. Основное интересное:
В заключение обзора докладов хочется отметить, что нам также очень понравился доклад «Видеозвонки: от миллионов в сутки до 100 участников в одной конференции» (Александр Тоболь / Одноклассники), который вошёл в число лучших докладов конференции по результатам голосования. Это отличный обзор того, как работают видеоконференции на группу участников. Доклад отличается понятным системным изложением. Если вдруг придётся делать видеозвонки, можно посмотреть доклад, чтобы быстро вникнуть в предметную область.
А теперь, на десерт, о том, как же мы пишем ретроспективу внутри компании. В первую очередь, мы стараемся написать ретро в первую неделю после посещения конференции, пока ещё свежи воспоминания. Кстати, материал ретроспективы может служить потом основой для статьи, как можно догадаться;)
Цель написания ретроспективы — это не только закрепить знания, но также и поделиться ими с теми, кто не был на конференции, но хочет быть в курсе последних трендов, интересных решений. Готовый список помогает сократить время на поиск интересных докладов для просмотра. Мы выписываем уроки, которые для себя вынесли, отмечаем конкретных людей с пометкой, почему нужно посмотреть доклад и подумать над идеями и решениями других. Выписанные уроки помогают сфокусироваться и не потерять, что мы хотели сделать. Посмотрев на записи через 3-6 месяцев мы поймём, не забыли ли мы о чём-то важном.
Документацию в компании мы храним в Confluence, для конференций у нас есть отдельное дерево страниц, кусочек дерева:
Как видно со скриншота, материалы мы раскладываем по годам для удобства навигации.
Внутри страницы, посвящённой конкретной конференции, мы храним следующие секции: общий обзор (overview) с ссылками на сайт события, расписание, видео и презентации, список участников (лично и на трансляции), общее впечатление (overall impression) и детальный обзор (detailed overview). Кстати, страницу для ретро мы генерим из шаблона, в котором вся структура уже есть. Также мы составляем содержание из заголовков, чтобы можно было очень быстро просмотреть список докладов и перейти к нужному.
В разделе Overall impression дается краткая оценка конференции, приводятся впечатления участников. Если участники были на конференции в прошлые годы, они могут сравнить их уровни и в целом понять для себя полезность посещения мероприятия.
Раздел Detailed overview содержит таблицу:

Пример заполнения таблицы:

Нам было бы интересно узнать о том, какие доклады понравились вам на Highload Siberia 2019, а также о вашем опыте проведения ретроспектив.
Обзор докладов
Отказоустойчивый кластер PostgreSQL + Patroni. Реальный опыт внедрения
Виктор Еремченко (Miro)Это обзорный доклад об успешной миграции Redis → PostgreSQL → Pgbouncer + PostgreSQL → Patroni Consul + Pgbouncer + PostgreSQL. Автор приводит схемы, типовые подводные камни очевидных решений, рассказывает об альтернативных решениях и почему они не подошли. Из интересного:
- Инженеры Miro собрали своё решение, чтобы не платить за Amazon RDS, и это решение пока их устраивает.
- Ликбез по менеджерам соединений для PostgreSQL.
- Рассказано про процесс обновления узлов кластера без остановки приложения.
- Показан приём для быстрого обновления PostgreSQL.
Полезно посмотреть тем, кто использует или собирается использовать PostgreSQL, и у кого растёт количество данных.
Реализация геораспределённой персистентной очереди сообщений на примере Yandex Message Queue
Василий Богонатов (Яндекс)В качестве вводной докладчик провёл краткое сравнение некоторых особенностей Kafka и RabbitMQ. Коротко: Kafka — простая очередь, сложный получатель; RabbitMQ — сложная очередь, простой получатель. Также автор рассказал про виды гарантий доставки сообщения из очереди. Важное замечание: ни одна очередь не может обеспечить доставку сообщения ровно 1 раз без поддержки на отправителе и получателе.
Доклад посвящён YandexMQ. YandexMQ (YMQ) — совместимая по API с Amazon SQS очередь. Основой YandexMQ является Yandex Database (YDB). Василий показал, в чём преимущество YandexMQ, как достигают строгой консистентности и безотказности, и сделал обзор архитектуры YMQ. YMQ реализует паттерн «Competing consumers» — одно сообщение одному потребителю. Фишка YMQ: когда consumer просит сообщение, то в очереди оно скрывается, чтобы больше никто его не взял в обработку. Если при обработке возникли проблемы, то после VisibilityTimeout сообщение снова становится видимым в очереди. Докладчик утверждает, что у Apache Kafka есть проблема потери данных при внезапном уничтожении процесса, Yandex MessageQueue устойчив к этому.

Доклад рекомендован всем, кто хочет разобраться в принципиальных особенностях очередей.
Time series данные в реляционной СУБД. Расширения TimescaleDB и PipelineDB для PostgreSQL
Иван Муратов (Первая Мониторинговая Компания)Доклад о том, как хранить и обрабатывать в PostgreSQL time series данные.
TimescaleDB позволяет хранить большие объёмы за счёт хитрого партицирования, а PipelineDB предоставляет работу со стримами прямо в PostgreSQL (а также интеграцию с очередями).
TimescaleDB:
- Имеет очень устойчивую скорость записи при росте объема базы под большими нагрузками и при увеличении количества партиций, измеряемого тысячами.
- Позволяет использовать стандартные возможности PostgreSQL, такие как SQL, репликация, резервное копирование, восстановление и др.
- Заявлен неплохой набор интеграций, к примеру, с Prometheus, Telegraf, Grafana, Zabbix, Kubernetes.
- Есть бесплатная версия с открытым кодом.
Основная мысль: TimescaleDB нужна в первую очередь для хранения данных.
PipelineDB:
- Позволяет непрерывно обрабатывать поступающие данные c помощью SQL и складывать результат в таблицу.
- Имеет SQL интерфейс.
- Есть выполнение хранимых процедур по условиям.
- Возможны интеграции с Apache Kafka и Amazon Kinesis.
- Есть бесплатная версия с открытым кодом.
- Разработка PipelineDB заморожена на версии 1.0, и сейчас выходят только багфиксы.
Основная мысль: PipelineDB нужна в первую очередь для обработки данных.
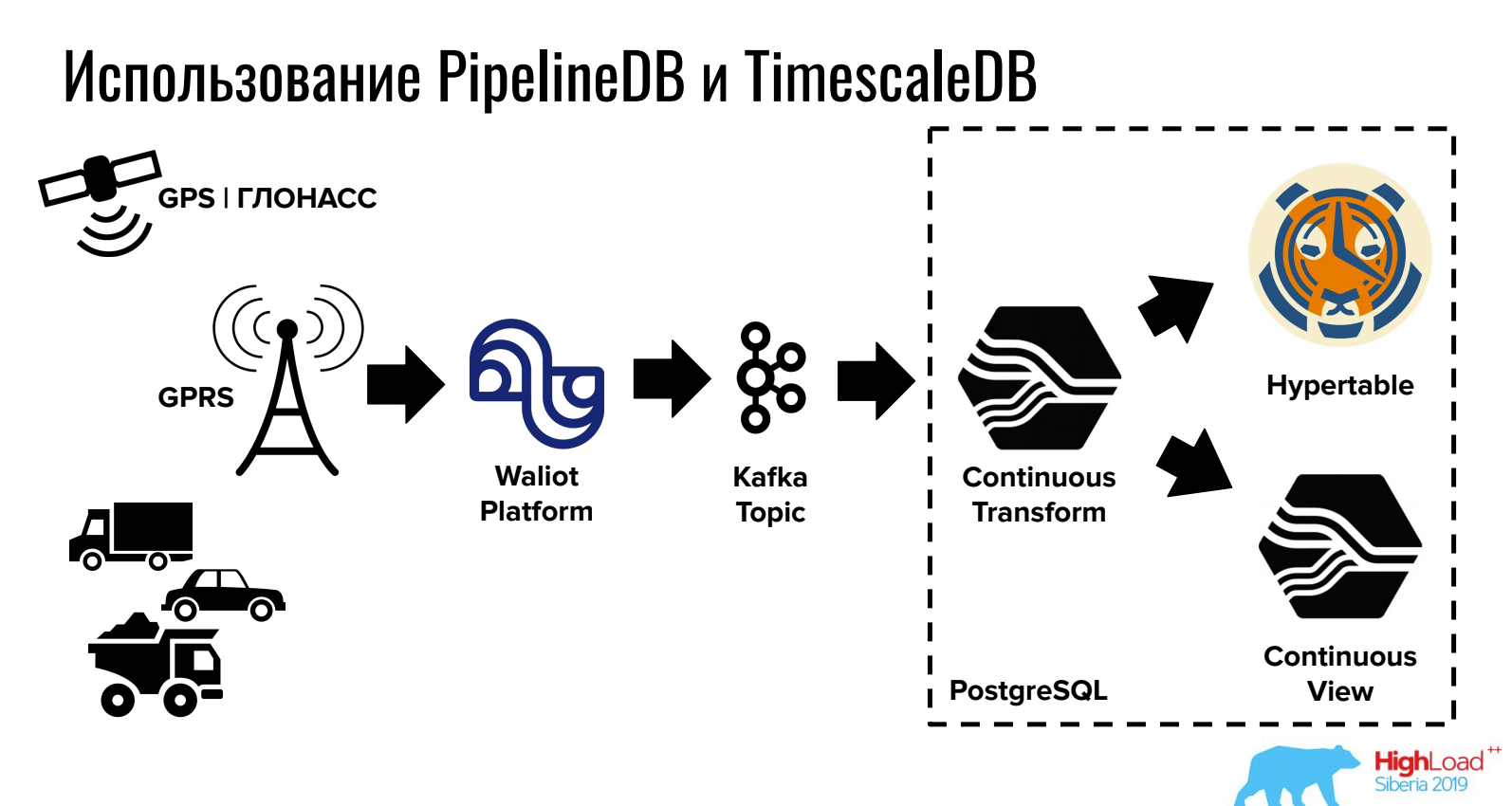
Для задач, где одновременно необходима реляционная СУБД, NoSQL и time series, данный вариант может быть довольно удобен.
Не очень большие данные
Павел Лузанов (Постгрес Профессиональный)Хороший обзорный доклад про PostgreSQL, наследование таблиц и Tips&Tricks производительности PostgreSQL 10, 11, 12+. Секционирование через наследование, шардинг. Полезно посмотреть всем, кто использует PostgreSQL и хочет сделать его чуть быстрее.
Архитектура высокопроизводительной и высокодоступной системы мониторинга в Яндексе
Сергей Половко (Яндекс)Об облачном продукте Yandex Monitoring, который пока в стадии «Preview» — бесплатный. Довольно подробно рассказано об архитектуре. Показан интересный приём — отделение метаданных от данных, которое даёт возможность независимого масштабирования и оптимизации. В качестве GUI используется Grafana, при этом оповещения свои, не в Grafana.
Рутина администратора баз данных
Андрей Сальников (Data Egret)Опыт коммерческого системного администрирования множества серверов PostgreSQL. Рассказывается о том, какие параметры серверов автоматически отслеживаются, как расставляются приоритеты задач.
В Data Egret используют обобщенный опыт в Wiki с рецептами, чек-листами — это является основой для будущих статей и докладов. Используют базу инцидентов с описанием проблем и решений — это существенно экономит ресурсы. Выпустили ряд утилит для работы с PostgreSQL, приводят ссылки на них.

Инфраструктура поиска Яндекс.Маркета
Евгений Соколов (Яндекс.Маркет)Доклад об архитектуре сложного, высокодоступного, распределённого приложения Яндекс.Маркет и о процессах и инструментах его разработки, тестирования, обновления, мониторинга. Из интересного:
- «Стоп-кран» — своё решение для быстрого применения и отката конфигурации, помогает тестировать новый функционал.
- Трафик перенаправляется из текущего датацентра балансировщиком в другой датацентр в случае проблем.
- Для мониторинга используются Graphite и Grafana.
- Имеется дублирующий базовый мониторинг на другом стеке технологий.
- Используется Shadow-кластер для разработчиков, на который дублируется часть пользовательского трафика. Пользователи при этом не видят ответов Shadow-кластера.
- Производится автоматический подсчёт качества при A/B тестировании.

ClickHouse и тысяча графиков
Антон Алексеев (2ГИС)Доклад о том, чем хорош ClickHouse, и как его готовить в связке с Grafana. Основное интересное:
- Если не хватает скорости, стоит использовать семплирование (утверждается, что точности данных после семплирования хватает). Семплирование в ClickHouse — частичная выборка данных с агрегированием с сохранением соотношения разнообразных значений в ключе таблицы, позволяет в разы ускорить агрегирование и при этом иметь результат, очень близкий к реальному.
- ClickHouse можно использовать для быстрого исследования инцидентов (в докладе интересный пример).
- Для ускорения выборки в ClickHouse также есть MaterializedView.
- Описан HTTP интерфейс ClickHouse для выполнения запросов и загрузки данных.
В заключение обзора докладов хочется отметить, что нам также очень понравился доклад «Видеозвонки: от миллионов в сутки до 100 участников в одной конференции» (Александр Тоболь / Одноклассники), который вошёл в число лучших докладов конференции по результатам голосования. Это отличный обзор того, как работают видеоконференции на группу участников. Доклад отличается понятным системным изложением. Если вдруг придётся делать видеозвонки, можно посмотреть доклад, чтобы быстро вникнуть в предметную область.
Структура ретроспектив конференций в Plesk
А теперь, на десерт, о том, как же мы пишем ретроспективу внутри компании. В первую очередь, мы стараемся написать ретро в первую неделю после посещения конференции, пока ещё свежи воспоминания. Кстати, материал ретроспективы может служить потом основой для статьи, как можно догадаться;)
Цель написания ретроспективы — это не только закрепить знания, но также и поделиться ими с теми, кто не был на конференции, но хочет быть в курсе последних трендов, интересных решений. Готовый список помогает сократить время на поиск интересных докладов для просмотра. Мы выписываем уроки, которые для себя вынесли, отмечаем конкретных людей с пометкой, почему нужно посмотреть доклад и подумать над идеями и решениями других. Выписанные уроки помогают сфокусироваться и не потерять, что мы хотели сделать. Посмотрев на записи через 3-6 месяцев мы поймём, не забыли ли мы о чём-то важном.
Документацию в компании мы храним в Confluence, для конференций у нас есть отдельное дерево страниц, кусочек дерева:
Как видно со скриншота, материалы мы раскладываем по годам для удобства навигации.
Внутри страницы, посвящённой конкретной конференции, мы храним следующие секции: общий обзор (overview) с ссылками на сайт события, расписание, видео и презентации, список участников (лично и на трансляции), общее впечатление (overall impression) и детальный обзор (detailed overview). Кстати, страницу для ретро мы генерим из шаблона, в котором вся структура уже есть. Также мы составляем содержание из заголовков, чтобы можно было очень быстро просмотреть список докладов и перейти к нужному.
В разделе Overall impression дается краткая оценка конференции, приводятся впечатления участников. Если участники были на конференции в прошлые годы, они могут сравнить их уровни и в целом понять для себя полезность посещения мероприятия.
Раздел Detailed overview содержит таблицу:

Пример заполнения таблицы:

Нам было бы интересно узнать о том, какие доклады понравились вам на Highload Siberia 2019, а также о вашем опыте проведения ретроспектив.
