В прошлый раз мы познакомились с устройством одного из важных объектов разделяемой памяти, буферного кеша. Возможность потери информации из оперативной памяти — основная причина необходимости средств восстановления после сбоя. Сегодня мы поговорим про эти средства.
Увы, чудес не бывает: чтобы пережить потерю информации в оперативной памяти, все необходимое должно быть своевременно записано на диск (или другое энергонезависимое устройство).
Поэтому сделано вот что. Вместе с изменением данных ведется еще и журнал этих изменений. Когда мы что-то меняем на странице в буферном кеше, мы создаем в журнале запись об этом изменении. Запись содержит минимальную информацию, достаточную для того, чтобы при необходимости изменение можно было повторить.
Чтобы это работало, журнальная запись в обязательном порядке должна попасть на диск до того, как туда попадет измененная страница. Отсюда и название: журнал предзаписи (write-ahead log).
Если происходит сбой, данные на диске оказываются в рассогласованном состоянии: какие-то страницы были записаны раньше, какие-то — позже. Но остается и журнал, который можно прочитать и выполнить повторно те операции, которые уже были выполнены до сбоя, но результат которых не успел дойти до диска.
Журналировать нужно все операции, при выполнении которых есть риск получить несогласованность на диске в случае сбоя. В частности, в журнал записываются следующие действия:
В журнал не записываются:
До версии PostgreSQL 10 не журналировались хеш-индексы (они служили только для сопоставления функций хеширования различным типам данных), но сейчас это исправлено.
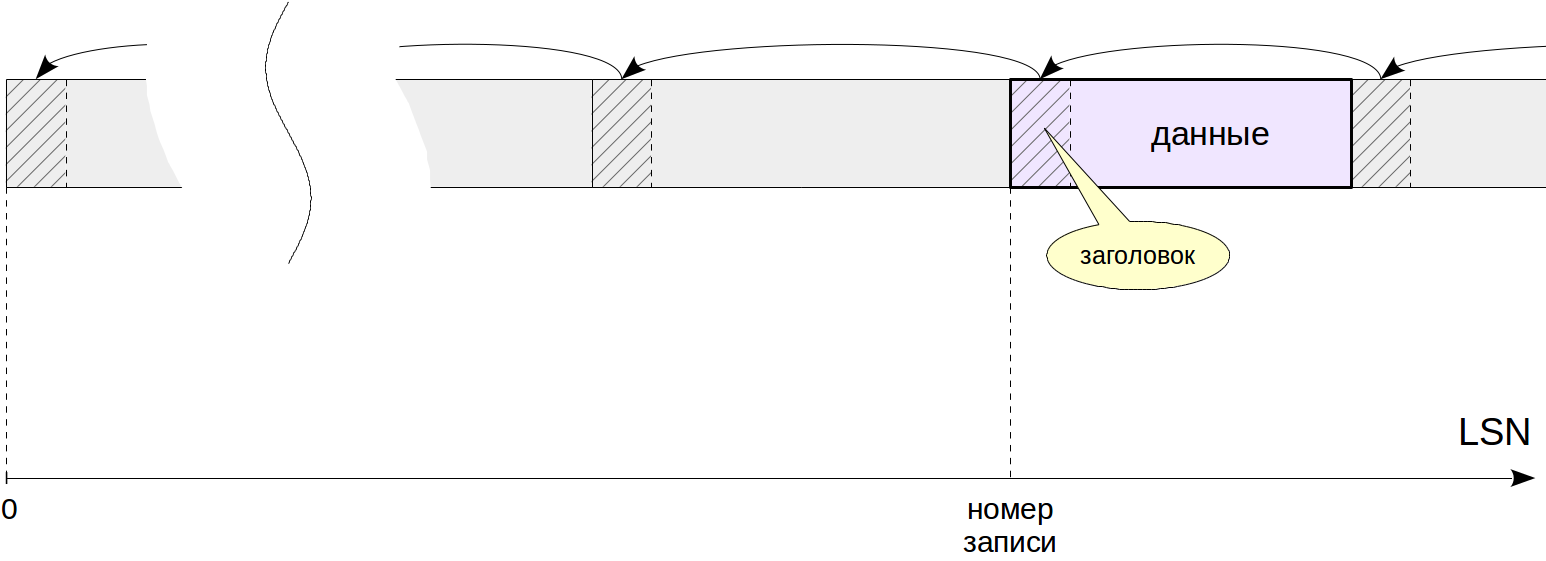
Логически журнал можно представить себе как последовательность записей различной длины. Каждая запись содержит данные о некоторой операции, предваренные стандартным заголовком. В заголовке, в числе прочего, указаны:
Сами данные имеют разный формат и смысл. Например, они могут представлять собой некоторый фрагмент страницы, который надо записать поверх ее содержимого с определенным смещением. Указанный менеджер ресурсов «понимает», как интерпретировать данные в своей записи. Есть отдельные менеджеры для таблиц, для каждого типа индекса, для статуса транзакций и т. п. Полный их список можно при желании получить командой
На диске журнал хранится в виде файлов в каталоге $PGDATA/pg_wal. Каждый файл по умолчанию занимает 16 Мб. Размер можно увеличить, чтобы избежать большого числа файлов в одном каталоге. До версии PostgreSQL 11 это можно было сделать только при компиляции исходных кодов, но теперь размер можно указать при инициализации кластера (ключ
Журнальные записи попадают в текущий использующийся файл; когда он заканчивается — начинает использоваться следующий.
В разделяемой памяти сервера для журнала выделены специальные буферы. Размер журнального кеша задается параметром wal_buffers (значение по умолчанию подразумевает автоматическую настройку: выделяется 1/32 часть буферного кеша).
Журнальный кеш устроен наподобие буферного кеша, но работает преимущественно в режиме кольцевого буфера: записи добавляются в «голову», а записываются на диск с «хвоста».
Позиции записи («хвоста») и вставки («головы») показывают функции pg_current_wal_lsn и pg_current_wal_insert_lsn соответственно:
Для того, чтобы сослаться на определенную запись, используется тип данных pg_lsn (LSN = log sequence number) — это 64-битное число, представляющее собой байтовое смещение до записи относительно начала журнала. LSN выводится как два 32-битных числа в шестнадцатеричной системе через косую черту.
Можно узнать, в каком файле мы найдем нужную позицию, и с каким смещением от начала файла:
Имя файла состоит из двух частей. Старшие 8 шестнадцатеричных разрядов показывают номер ветви времени (она используется при восстановлении из резервной копии), остаток соответствует старшим разрядам LSN (а оставшиеся младшие разряды LSN показывают смещение).
Журнальные файлы можно посмотреть в файловой системе в каталоге $PGDATA/pg_wal/, но начиная с PostgreSQL 10 их также можно увидеть специальной функцией:
Посмотрим, как происходит журналирование и как обеспечивается упреждающая запись. Создадим таблицу:
Мы будем заглядывать в заголовок табличной страницы. Для этого нам понадобится уже хорошо знакомое расширение:
Начнем транзакцию и запомним позицию вставки в журнал:
Теперь выполним какую-нибудь операцию, например, обновим строку:
Это изменение было записано и в журнал, позиция вставки изменилась:
Чтобы гарантировать, что измененная страница данных не будет вытеснена на диск раньше, чем журнальная запись, в заголовке страницы сохраняется номер LSN последней журнальной записи, относящейся к этой странице:
Надо учитывать, что журнал общий для всего кластера, и в него все время попадают новые записи. Поэтому LSN на странице может оказаться меньше, чем значение, которое только что вернула функция pg_current_wal_insert_lsn. Но в нашей системе ничего не происходит, поэтому цифры совпадают.
Теперь завершим транзакцию.
Запись о фиксации также попадает в журнал, и позиция снова меняется:
Фиксация меняет статус транзакции в структуре, называемой XACT (мы уже говорили про нее). Статусы хранятся в файлах, но для них тоже используется свой кеш, который занимает в разделяемой памяти 128 страниц. Поэтому и для страниц XACT приходится отслеживать номер LSN последней журнальной записи. Но эта информация хранится не в самой странице, а в оперативной памяти.
В какой-то момент созданные журнальные записи будут записаны на диск. В какой именно — мы поговорим в другой раз, но в нашем случае это уже произошло:
После этого момента страницы данных и XACT могут быть вытеснены из кеша. А вот если бы потребовалось вытеснить их раньше, это было бы обнаружено и журнальные записи были бы принудительно записаны первыми.
Зная две позиции LSN, можно получить размер журнальных записей между ними (в байтах) простым вычитанием одной позиции из другой. Надо только привести позиции к типу pg_lsn:
В данном случае обновление строки и фиксация потребовали 108 байтов в журнале.
Таким же способом можно оценить, какой объем журнальных записей генерируется сервером за единицу времени при определенной нагрузке. Это важная информация, которая потребуется при настройке (о чем мы поговорим в следующий раз).
Теперь воспользуемся утилитой pg_waldump, чтобы посмотреть на созданные журнальные записи.
Утилита может работать и с диапазоном LSN (как в этом примере), и выбрать записи для указанной транзакции. Запускать ее следует от имени пользователя ОС postgres, так как ей требуется доступ к журнальным файлам на диске.
Здесь мы видим заголовки двух записей.
Первая — операция HOT_UPDATE, относящаяся к менеджеру ресурсов Heap. Имя файла и номер страницы указаны в поле blkref и совпадают с обновленной табличной страницей:
Вторая запись — COMMIT, относящаяся к менеджеру ресурсов Transaction.
Не самый удобочитаемый формат, но при необходимости разобраться можно.
Когда мы стартуем сервер, первым делом запускается процесс postmaster, а он, в свою очередь, запускает процесс startup, задача которого — обеспечить восстановление, если произошел сбой.
Чтобы определить, требуется ли восстановление, startup заглядывает в специальный управляющий файл $PGDATA/global/pg_control и смотрит на статус кластера. Мы можем и сами проверить статус с помощью утилиты pg_controldata:
У аккуратно остановленного сервера статус будет «shut down». Если сервер не работает, а статус остался «in production», это означает, что СУБД упала и тогда автоматически будет выполнено восстановление.
Для восстановления процесс startup будет последовательно читать журнал и применять записи к страницам, если в этом есть необходимость. Необходимость можно проверить, сравнив LSN страницы на диске с LSN журнальной записи. Если LSN страницы оказался больше, то запись применять не нужно. А на самом деле — даже и нельзя, потому что записи рассчитаны на строго последовательное применение.
Изменение страниц при восстановлении происходит в буферном кеше, как при обычной работе — для этого postmaster запускает необходимые фоновые процессы.
Аналогично журнальные записи применяются и к файлам: например, если запись говорит о том, что файл должен существовать, а его нет — файл создается.
Ну и в самом конце процесса восстановления все нежурналируемые таблицы перезаписываются «пустышками» из своих init-слоев.
Это сильно упрощенное изложение алгоритма. В частности, мы пока ничего не говорили о том, с какого места надо начинать чтение журнальных записей (этот разговор придется отложить до рассмотрения контрольной точки).
И последнее уточнение. «По классике» процесс восстановления состоит из двух фаз. На первой фазе (roll forward) накатываются журнальные записи, при этом сервер повторяет всю потерянную при сбое работу. На второй (roll back) — откатываются транзакции, которые не были зафиксированы на момент сбоя. Но PostgreSQL не нуждается во второй фазе. Как мы рассматривали ранее, благодаря особенностям реализации многоверсионности транзакции не надо откатывать физически; достаточно того, что в XACT не будет установлен бит фиксации.
Продолжение.
Журнал
Увы, чудес не бывает: чтобы пережить потерю информации в оперативной памяти, все необходимое должно быть своевременно записано на диск (или другое энергонезависимое устройство).
Поэтому сделано вот что. Вместе с изменением данных ведется еще и журнал этих изменений. Когда мы что-то меняем на странице в буферном кеше, мы создаем в журнале запись об этом изменении. Запись содержит минимальную информацию, достаточную для того, чтобы при необходимости изменение можно было повторить.
Чтобы это работало, журнальная запись в обязательном порядке должна попасть на диск до того, как туда попадет измененная страница. Отсюда и название: журнал предзаписи (write-ahead log).
Если происходит сбой, данные на диске оказываются в рассогласованном состоянии: какие-то страницы были записаны раньше, какие-то — позже. Но остается и журнал, который можно прочитать и выполнить повторно те операции, которые уже были выполнены до сбоя, но результат которых не успел дойти до диска.
Почему принудительно не записывать на диск сами страницы с данными, зачем вместо этого выполнять двойную работу? Оказывается, так эффективнее.
Во-первых, журнал — это последовательный поток данных на запись. С последовательной записью даже HDD-диски справляются неплохо. А вот запись самих данных — случайная, потому что страницы разбросаны по диску более или менее хаотично.
Во-вторых, журнальная запись может быть гораздо меньше, чем страница.
В-третьих, при записи можно не заботиться о том, чтобы в каждый произвольный момент времени данные на диске оставались согласованными (такое требование сильно усложняет жизнь).
Ну и в-четвертых, как мы потом увидим, журнал (раз уж он есть) можно использовать не только для восстановления, но и для резервного копирования и репликации.
Журналировать нужно все операции, при выполнении которых есть риск получить несогласованность на диске в случае сбоя. В частности, в журнал записываются следующие действия:
- изменение страниц в буферном кеше (как правило, это страницы таблиц и индексов) — так как измененная страница попадает на диск не сразу;
- фиксация и отмена транзакций — изменение статуса происходит в буферах XACT и тоже попадает на диск не сразу;
- файловые операции (создание и удаление файлов и каталогов, например, создание файлов при создании таблицы) — так как эти операции должны происходить синхронно с изменением данных.
В журнал не записываются:
- операции с нежурналируемыми (unlogged) таблицами — их название говорит само за себя;
- операции с временными таблицами — нет смысла, поскольку время жизни таких таблиц не превышает времени жизни создавшего их сеанса.
До версии PostgreSQL 10 не журналировались хеш-индексы (они служили только для сопоставления функций хеширования различным типам данных), но сейчас это исправлено.
Логическое устройство

Логически журнал можно представить себе как последовательность записей различной длины. Каждая запись содержит данные о некоторой операции, предваренные стандартным заголовком. В заголовке, в числе прочего, указаны:
- номер транзакции, к которой относится запись;
- менеджер ресурсов — компонент системы, ответственный за запись;
- контрольная сумма (CRC) — позволяет определить повреждение данных;
- длина записи и ссылка на предыдущую запись.
Сами данные имеют разный формат и смысл. Например, они могут представлять собой некоторый фрагмент страницы, который надо записать поверх ее содержимого с определенным смещением. Указанный менеджер ресурсов «понимает», как интерпретировать данные в своей записи. Есть отдельные менеджеры для таблиц, для каждого типа индекса, для статуса транзакций и т. п. Полный их список можно при желании получить командой
pg_waldump -r list
Физическое устройство
На диске журнал хранится в виде файлов в каталоге $PGDATA/pg_wal. Каждый файл по умолчанию занимает 16 Мб. Размер можно увеличить, чтобы избежать большого числа файлов в одном каталоге. До версии PostgreSQL 11 это можно было сделать только при компиляции исходных кодов, но теперь размер можно указать при инициализации кластера (ключ
--wal-segsize).Журнальные записи попадают в текущий использующийся файл; когда он заканчивается — начинает использоваться следующий.
В разделяемой памяти сервера для журнала выделены специальные буферы. Размер журнального кеша задается параметром wal_buffers (значение по умолчанию подразумевает автоматическую настройку: выделяется 1/32 часть буферного кеша).
Журнальный кеш устроен наподобие буферного кеша, но работает преимущественно в режиме кольцевого буфера: записи добавляются в «голову», а записываются на диск с «хвоста».
Позиции записи («хвоста») и вставки («головы») показывают функции pg_current_wal_lsn и pg_current_wal_insert_lsn соответственно:
=> SELECT pg_current_wal_lsn(), pg_current_wal_insert_lsn();
pg_current_wal_lsn | pg_current_wal_insert_lsn
--------------------+---------------------------
0/331E4E64 | 0/331E4EA0
(1 row)
Для того, чтобы сослаться на определенную запись, используется тип данных pg_lsn (LSN = log sequence number) — это 64-битное число, представляющее собой байтовое смещение до записи относительно начала журнала. LSN выводится как два 32-битных числа в шестнадцатеричной системе через косую черту.
Можно узнать, в каком файле мы найдем нужную позицию, и с каким смещением от начала файла:
=> SELECT file_name, upper(to_hex(file_offset)) file_offset
FROM pg_walfile_name_offset('0/331E4E64');
file_name | file_offset
--------------------------+-------------
000000010000000000000033 | 1E4E64
\ /\ /
ветвь 0/331E4E64
времени
Имя файла состоит из двух частей. Старшие 8 шестнадцатеричных разрядов показывают номер ветви времени (она используется при восстановлении из резервной копии), остаток соответствует старшим разрядам LSN (а оставшиеся младшие разряды LSN показывают смещение).
Журнальные файлы можно посмотреть в файловой системе в каталоге $PGDATA/pg_wal/, но начиная с PostgreSQL 10 их также можно увидеть специальной функцией:
=> SELECT * FROM pg_ls_waldir() WHERE name = '000000010000000000000033';
name | size | modification
--------------------------+----------+------------------------
000000010000000000000033 | 16777216 | 2019-07-08 20:24:13+03
(1 row)
Упреждающая запись
Посмотрим, как происходит журналирование и как обеспечивается упреждающая запись. Создадим таблицу:
=> CREATE TABLE wal(id integer);
=> INSERT INTO wal VALUES (1);
Мы будем заглядывать в заголовок табличной страницы. Для этого нам понадобится уже хорошо знакомое расширение:
=> CREATE EXTENSION pageinspect;
Начнем транзакцию и запомним позицию вставки в журнал:
=> BEGIN;
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn
---------------------------
0/331F377C
(1 row)
Теперь выполним какую-нибудь операцию, например, обновим строку:
=> UPDATE wal set id = id + 1;
Это изменение было записано и в журнал, позиция вставки изменилась:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn
---------------------------
0/331F37C4
(1 row)
Чтобы гарантировать, что измененная страница данных не будет вытеснена на диск раньше, чем журнальная запись, в заголовке страницы сохраняется номер LSN последней журнальной записи, относящейся к этой странице:
=> SELECT lsn FROM page_header(get_raw_page('wal',0));
lsn
------------
0/331F37C4
(1 row)
Надо учитывать, что журнал общий для всего кластера, и в него все время попадают новые записи. Поэтому LSN на странице может оказаться меньше, чем значение, которое только что вернула функция pg_current_wal_insert_lsn. Но в нашей системе ничего не происходит, поэтому цифры совпадают.
Теперь завершим транзакцию.
=> COMMIT;
Запись о фиксации также попадает в журнал, и позиция снова меняется:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn
---------------------------
0/331F37E8
(1 row)
Фиксация меняет статус транзакции в структуре, называемой XACT (мы уже говорили про нее). Статусы хранятся в файлах, но для них тоже используется свой кеш, который занимает в разделяемой памяти 128 страниц. Поэтому и для страниц XACT приходится отслеживать номер LSN последней журнальной записи. Но эта информация хранится не в самой странице, а в оперативной памяти.
В какой-то момент созданные журнальные записи будут записаны на диск. В какой именно — мы поговорим в другой раз, но в нашем случае это уже произошло:
=> SELECT pg_current_wal_lsn(), pg_current_wal_insert_lsn();
pg_current_wal_lsn | pg_current_wal_insert_lsn
--------------------+---------------------------
0/331F37E8 | 0/331F37E8
(1 row)
После этого момента страницы данных и XACT могут быть вытеснены из кеша. А вот если бы потребовалось вытеснить их раньше, это было бы обнаружено и журнальные записи были бы принудительно записаны первыми.
Зная две позиции LSN, можно получить размер журнальных записей между ними (в байтах) простым вычитанием одной позиции из другой. Надо только привести позиции к типу pg_lsn:
=> SELECT '0/331F37E8'::pg_lsn - '0/331F377C'::pg_lsn;
?column?
----------
108
(1 row)
В данном случае обновление строки и фиксация потребовали 108 байтов в журнале.
Таким же способом можно оценить, какой объем журнальных записей генерируется сервером за единицу времени при определенной нагрузке. Это важная информация, которая потребуется при настройке (о чем мы поговорим в следующий раз).
Теперь воспользуемся утилитой pg_waldump, чтобы посмотреть на созданные журнальные записи.
Утилита может работать и с диапазоном LSN (как в этом примере), и выбрать записи для указанной транзакции. Запускать ее следует от имени пользователя ОС postgres, так как ей требуется доступ к журнальным файлам на диске.
postgres$ /usr/lib/postgresql/11/bin/pg_waldump -p /var/lib/postgresql/11/main/pg_wal -s 0/331F377C -e 0/331F37E8 000000010000000000000033
rmgr: Heap len (rec/tot): 69/ 69, tx: 101085, lsn: 0/331F377C, prev 0/331F3014, desc: HOT_UPDATE off 1 xmax 101085 ; new off 2 xmax 0, blkref #0: rel 1663/16386/33081 blk 0
rmgr: Transaction len (rec/tot): 34/ 34, tx: 101085, lsn: 0/331F37C4, prev 0/331F377C, desc: COMMIT 2019-07-08 20:24:13.945435 MSK
Здесь мы видим заголовки двух записей.
Первая — операция HOT_UPDATE, относящаяся к менеджеру ресурсов Heap. Имя файла и номер страницы указаны в поле blkref и совпадают с обновленной табличной страницей:
=> SELECT pg_relation_filepath('wal');
pg_relation_filepath
----------------------
base/16386/33081
(1 row)
Вторая запись — COMMIT, относящаяся к менеджеру ресурсов Transaction.
Не самый удобочитаемый формат, но при необходимости разобраться можно.
Восстановление
Когда мы стартуем сервер, первым делом запускается процесс postmaster, а он, в свою очередь, запускает процесс startup, задача которого — обеспечить восстановление, если произошел сбой.
Чтобы определить, требуется ли восстановление, startup заглядывает в специальный управляющий файл $PGDATA/global/pg_control и смотрит на статус кластера. Мы можем и сами проверить статус с помощью утилиты pg_controldata:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | grep state
Database cluster state: in production
У аккуратно остановленного сервера статус будет «shut down». Если сервер не работает, а статус остался «in production», это означает, что СУБД упала и тогда автоматически будет выполнено восстановление.
Для восстановления процесс startup будет последовательно читать журнал и применять записи к страницам, если в этом есть необходимость. Необходимость можно проверить, сравнив LSN страницы на диске с LSN журнальной записи. Если LSN страницы оказался больше, то запись применять не нужно. А на самом деле — даже и нельзя, потому что записи рассчитаны на строго последовательное применение.
Есть исключения. Часть записей формируются как полный образ страницы (FPI, full page image), и понятно, что такой образ можно применить к странице в любом состоянии — он все равно сотрет все, что там было. Еще изменение статуса транзакции можно применять к любой версии страницы XACT — поэтому внутри таких страниц нет необходимости хранить LSN.
Изменение страниц при восстановлении происходит в буферном кеше, как при обычной работе — для этого postmaster запускает необходимые фоновые процессы.
Аналогично журнальные записи применяются и к файлам: например, если запись говорит о том, что файл должен существовать, а его нет — файл создается.
Ну и в самом конце процесса восстановления все нежурналируемые таблицы перезаписываются «пустышками» из своих init-слоев.
Это сильно упрощенное изложение алгоритма. В частности, мы пока ничего не говорили о том, с какого места надо начинать чтение журнальных записей (этот разговор придется отложить до рассмотрения контрольной точки).
И последнее уточнение. «По классике» процесс восстановления состоит из двух фаз. На первой фазе (roll forward) накатываются журнальные записи, при этом сервер повторяет всю потерянную при сбое работу. На второй (roll back) — откатываются транзакции, которые не были зафиксированы на момент сбоя. Но PostgreSQL не нуждается во второй фазе. Как мы рассматривали ранее, благодаря особенностям реализации многоверсионности транзакции не надо откатывать физически; достаточно того, что в XACT не будет установлен бит фиксации.
Продолжение.
