Автор — Игорь Косенков, инженер Postgres Professional
Привет всем! Сегодня речь пойдет о кластере. Да, снова об отказоустойчивом кластере на базе Corosync/Pacemaker. Только настраивать мы его будем не как обычно — с помощью утилиты pcs, а с помощью мало используемой утилиты crm.
С точки зрения использования этих утилит (pcs и crm) весь мир Unix-like операционок делится на два вида:
crm — cluster resource manager — специальная утилита, которая используется для создания и управления отказоустойчивым кластером. Она включена в пакет crmsh, который обычно не входит в состав самых распространенных дистрибутивов Linux.
Идея написать статью об этой утилите пришла однажды, когда я спросил у поисковика: «Как настроить отказоустойчивый кластер с помощью crm». В ответ не получил ничего нужного и полезного, т.к. поисковик мне предложил много вариантов, никак не связанных с crm.
В то же время, если спросить у поисковика про утилиту настройки кластера pcs, которая является по функционалу такой же утилитой, как и
Утилита crm такая же мощная и гибкая, как и pcs, но незаслуженно обделена вниманием.
Решено было исправить этот пробел и написать статью.
Причины, по которым те или иные разработчики дистрибутивов предпочитают кто crm, а кто pcs, мне неизвестны. Могу предположить, что все дело в зависимостях. Например, если сравнить количество зависимостей у pcs и crm, то получается такая картина:
Сторонники минимализма, скорей всего, предпочтут crmsh. А если еще учесть, что pcs «тянет» за собой ruby, openssl, pam и python, а crmsh только python, то выбор в некоторых случаях будет однозначно на стороне crm. В каких случаях? Ну, например, при сертификации ОС есть некоторые трудности с пакетом ruby. Также известны случаи, когда в банковских структурах служба безопасности не разрешает установку нерегламентированного ПО.
У утилиты crm есть как сходства, так и различия с известной всем утилитой pcs.
Сходства утилит приведены в таблице 1:

На этом сходства заканчиваются и дальше идут различия, которых много, поэтому привожу лишь некоторые из них (таблица 2):

Различия начинаются с самого начала — с момента инициализации кластера. Инициализировать кластер с помощью crm можно одной командой, а у pcs это происходит в два этапа — авторизация и инициализация.
Удалить кластер («разобрать») у pcs можно одной командой сразу, а у crm необходимо удалять по одному узлу до тех пор, пока их не останется в кластере.
Чтобы изменить параметры ресурса, который мы уже создали в кластере, у pcs есть опция update. У crm такой опции нет, но есть команда configure edit, которая позволяет менять любые настройки кластера налету и мгновенно. Даже больше — мы можем за один прием отредактировать любое количество параметров и ресурсов, и в конце редактирования применить все изменения сразу. Удобно? Думаю, да.
Еще различие – у pcs есть веб-интерфейс, с помощью которого можно выполнить различные действия – запустить, остановить, создать какой-нибудь ресурс с помощью любого браузера.
У crm в стандартной поставке нет веб-инструмента, но зато он есть в коммерческой версии SUSE — HAWK.
Лучший способ узнать и познакомиться с crm — это настроить отказоустойчивый кластер.
Чем мы сейчас и займемся. Для примера возьмем ОС CentOS 7.9.
Для создания отказоустойчивого кластера PostgreSQL нам понадобится стенд, состоящий из 3-х узлов — node1, node2, node3. На каждом узле установлена ОС CentOS 7.9 и пакеты corosync, pacemaker, fence-agents* (агенты фенсинга).
В качестве СУБД будем использовать Postgres Pro Standard v.11, но вы можете с таким же успехом использовать «ванильную» версию PostgreSQL. В нашей системе установлены необходимые пакеты — postgrespro-std-11-server, postgrespro-std-11-libs, postgrespro-std-11-contrib, postgrespro-std-11-client.
Настройки СУБД (postgresql.conf) и доступа к ней (pg_hba.conf) не рассматриваются в данной статье, информации об этом достаточно в интернете. На одном из узлов (например, node1) необходимо инициализировать базу данных с помощью initdb, а на двух других узлах с помощью pg_basebackup скопировать базу данных с node1.
Кроме того, в будущем кластере должны быть настроены синхронизация времени на узлах и разрешение имен узлов в кластере с помощью файла /etc/hosts.
ПРИМЕЧАНИЕ:
В этом разделе все команды необходимо выполнить на всех узлах кластера.
Поскольку пакет crmsh не входит в состав дистрибутива ОС, то необходимо подключить репозиторий Extra OKay Packages for Enterprise Linux с этим пакетом.
Нам также понадобится репозитарий EPEL:
Устанавливаем пакет crmsh:
При установке и настройке кластера нам также понадобится пакет
Разработчики
ОТСТУПЛЕНИЕ:
Сервис csync2 может использоваться не только для создания отказоустойчивого кластера Corosync/Pacemaker. Например, если есть несколько серверов, у которых меняются конфигурационные файлы и эти файлы периодически нужно синхронизировать по критерию «самый свежий файл».
Итак, устанавливаем
Тут нас поджидает подводный камень.
Поскольку csync2 и crmsh не являются «родными» для CentOS, то без дополнительных «танцев» сразу после установки они не заработают. Вызов crm влечет вызов утилиты csync2, которой в свою очередь не хватает парочки systemd-юнитов. Почему этих файлов нет в пакете csync2 для CentOS — мне неизвестно. Замечу, что в коммерческом дистрибутиве SLES (crmsh там «родной») все необходимые файлы есть, все работает из коробки сразу после установки пакетов.
Итак, создадим и добавим недостающие systemd-юниты.
Первый называется
Второй называется
Оба файла нужно разместить в стандартной папке systemd — /usr/lib/systemd/system.
Юнит, относящийся к сокету, нужно активировать и установить в автозапуск при загрузке ОС:
Примечание. Все настройки выполнялись для ОС CentOS, но есть подозрение, что эти действия также понадобятся и для других систем, например, для Debian или Ubuntu.
Теперь у нас все готово к началу работ по настройке кластера.
Настройка кластера производится в 2 этапа — инициализация, затем создание и добавление ресурсов. Инициализация кластера с настроенным сервисом синхронизации конфигураций csync2 производится на одном узле.
Если по каким-то причинам вам не удалось «победить» этот сервис, то это не беда, в конце статьи я расскажу, как обойтись без csync2.
На всякий случай сначала удалим кластер (на всех узлах) с помощью такого набора команд:
Далее надо выполнить команду инициализации кластера:
где demo-cluster — название нашего кластера.
По этой команде создаются необходимые файлы в папке /etc/corosync: corosync.conf, ключ авторизации authkey, а также прописываются ssh-ключи для беспарольной авторизации и выполнения команд в кластере с привилегиями суперпользователя root (на всех трех узлах кластера).
По умолчанию инициализация кластера выполняется в режиме multicast. Но есть также возможность проинициализировать кластер в режиме unicast:
Кластер проинициализирован и запущен.
Проверить работоспособность можно с помощью консольного монитора состояния кластера crm_mon:
Далее можно приступать к созданию ресурсов в кластере.
Для начала поменяем некоторые значению по умолчанию. Например, порог миграции ресурсов migration-threshold по умолчанию равен 0. Меняем на 1, чтобы после первого сбоя ресурсы мигрировали на другой узел.
По умолчанию кластер запускается в симметричном режиме.
Чем отличается симметричный кластер от несимметричного? В симметричном кластере любой созданный ресурс будет запускаться на любом узле, если не установлены дополнительные правила размещения или старта.
В несимметричном — наоборот, ресурс не будет запущен ни на одном узле, пока явно не будет указано, где и в какой последовательности его запускать.
Зачем это нужно? Ну, например, в ситуации, когда в кластере ресурсы запускаются не на всех узлах, т.е. узлы неравноценны по ресурсам и назначению.
Если, вдруг, вам когда-то понадобится изменить режим кластера с симметричного на несимметричный, то достаточно ввести команду:
Мы оставим этот параметр без изменения.
Включаем механизм stonith:
Создадим и добавим ресурс «виртуальный IP адрес»:
где <virtual IP> — виртуальный IP-адрес в кластере.
С помощью монитора состояния кластера crm_mon можно убедиться в том, что ресурс успешно создан и запущен на первом попавшемся узле:
Создадим ресурс postgresql и назовем его pg:
ПРИМЕЧАНИЕ:
В данном примере пути расположения бинарников и БД указаны по умолчанию для версии Postgres Pro Std 11. Также для упрощения указан пользователь для репликации «postgres». Но ничто не мешает вам изменить «умолчательные» пути и пользователя репликации на свои.
Хочу обратить внимание на параметр rep_mode: он задан «sync». Это означает, что в отказоустойчивом кластере хотя бы одна реплика будет синхронной. Синхронность реплики в кластере обеспечивает RPO=0 (кластер без потерь данных в случае сбоя).
Зададим тип ресурса Master-Standby (ms):
Нам нужно, чтобы ресурсы vip-master и mspg в режиме «мастер» запускались на одном узле:
Указываем порядок запуска ресурсов – сначала СУБД в режиме «мастер», потом виртуальный IP:
Таким образом, мы создали 2 необходимых ресурса — виртуальный IP адрес и ресурс postgresql.
Теперь можно переходить к настройке фенсинга в отказоустойчивом кластере.
Про фенсинг в кластере — что это и зачем он нужен — есть много информации в интернете, не хочется повторяться. Добавлю только одно — он необходим в любом кластере. А это значит, что мы его сейчас настроим.
Для начала можно ознакомиться со списком всех агентов фенсинга:
На моем стенде node1, node2, node3 — это виртуальные машины, которые запущены и управляются с помощью гипервизора KVM. Соответственно, ресурс-агент фенсинга для KVM называется fence_virsh.
Вывести полную информацию о fence_virsh:
Прежде чем создавать ресурс фенсинга, рекомендую проверить работоспособность всей цепочки от ОС виртуалки до гипервизора.
Проверка работоспособности фенсинга для узла node1 выглядит так:
где username & password — учетная запись на хосте гипервизора.
Фенсинг для node1 настраивается так:
ПРИМЕЧАНИЕ:
Ресурсы фенсинга не должны запускаться на «своих» узлах, иначе фенсинг может не сработать.
Следующее правило расположения запретит ресурсу фенсинга для узла node1 располагаться на этом узле:
Для node2:
Для node3:
Можно написать скрипт, который будет содержать все команды сразу, останется только его выполнить. Но сегодня наша цель не автоматизация создания кластера, а изучение crm.
Как обещал выше, расскажу про вариант инициализации кластера без установки и настройки csync2 (если по каким-то причинам вам не удалось его настроить).
Сначала вариант с использованием multicast.
Все команды выполняются на одном узле, например, на node1.
По этой команде создаются необходимые файлы в папке /etc/corosync: corosync.conf, ключ авторизации authkey.
Далее нужно скопировать авторизационный файл authkey и corosync.conf на узлы node2 и node3:
На остальных узлах (на node1 кластер уже запущен) запустить кластер:
С помощью монитора crm_mon можно убедиться, что кластер проинициализирован и запущен:
В случае настройки кластера с использованием unicast действия и команды будут отличаться.
Все команды выполняются на одном узле, например, на node1.
Открываем файл /etc/corosync/corosync.conf и добавляем строки в секцию nodelist:
В секции quorum меняем число голосов:
expected_votes: 3
Далее необходим рестарт сервиса corosync на первом узле:
Затем нужно скопировать файл authkey и отредактированный corosync.conf на узлы node2 и node3:
На остальных узлах (на node1 кластер уже запущен) запустить кластер:
С помощью монитора crm_mon можно убедиться, что кластер проинициализирован и запущен:
На этом инициализация кластера без csync2 закончена.
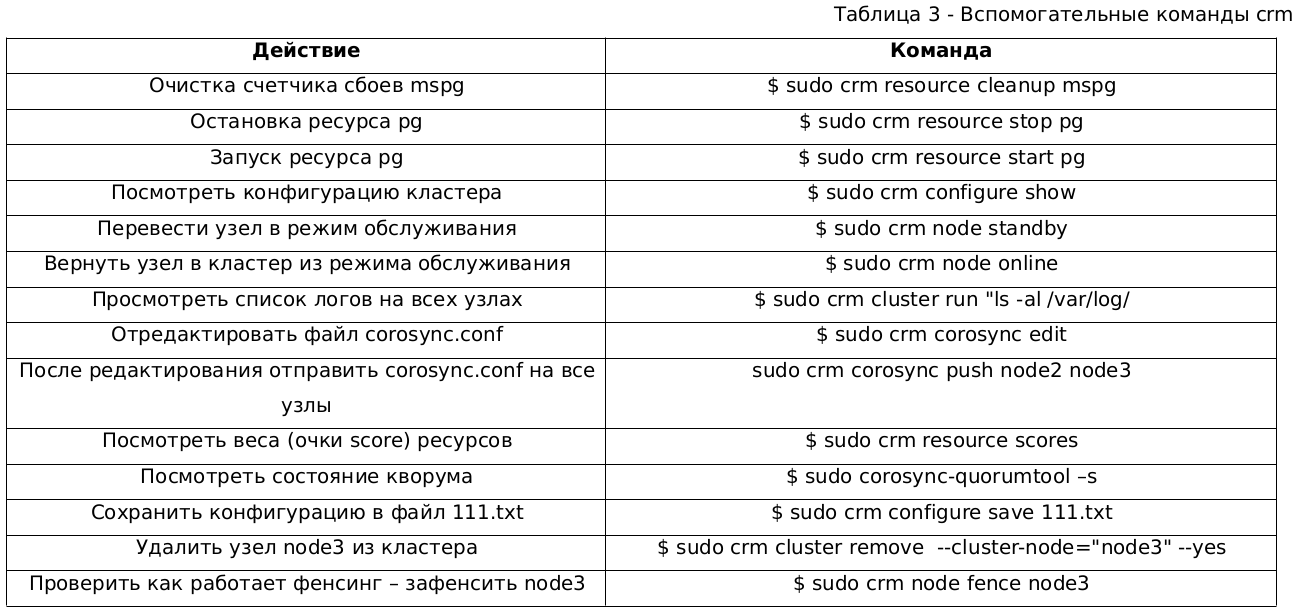
При работе с кластером могут пригодиться некоторые crm-команды.
Для удобства команды и пояснения сведены в таблицу 3:
На этом все. Буду рад, если статья поможет кому-то в создании и настройке отказоустойчивого кластера с помощью утилиты crm.
Привет всем! Сегодня речь пойдет о кластере. Да, снова об отказоустойчивом кластере на базе Corosync/Pacemaker. Только настраивать мы его будем не как обычно — с помощью утилиты pcs, а с помощью мало используемой утилиты crm.
С точки зрения использования этих утилит (pcs и crm) весь мир Unix-like операционок делится на два вида:
- содержит пакеты утилиты pcs (RHEL, CentOS, Debian, Ubuntu);
- содержит пакеты утилиты crm (SLES, Opensuse, Elbrus, Leningrad и т.д.).
crm — cluster resource manager — специальная утилита, которая используется для создания и управления отказоустойчивым кластером. Она включена в пакет crmsh, который обычно не входит в состав самых распространенных дистрибутивов Linux.
Идея написать статью об этой утилите пришла однажды, когда я спросил у поисковика: «Как настроить отказоустойчивый кластер с помощью crm». В ответ не получил ничего нужного и полезного, т.к. поисковик мне предложил много вариантов, никак не связанных с crm.
В то же время, если спросить у поисковика про утилиту настройки кластера pcs, которая является по функционалу такой же утилитой, как и
crm, то информации будет много. Есть даже несколько статей на Хабре (в том числе и моя статья Кластер pacemaker/corosync без валидола).Утилита crm такая же мощная и гибкая, как и pcs, но незаслуженно обделена вниманием.
Решено было исправить этот пробел и написать статью.
Причины, по которым те или иные разработчики дистрибутивов предпочитают кто crm, а кто pcs, мне неизвестны. Могу предположить, что все дело в зависимостях. Например, если сравнить количество зависимостей у pcs и crm, то получается такая картина:
$ sudo rpm -qpR crmsh-3.0.1-1.el7.centos.noarch.rpm | wc -l
19
$ sudo rpm -qpR pcs-0.9.169-3.el7.centos.x86_64.rpm | wc -l
50Сторонники минимализма, скорей всего, предпочтут crmsh. А если еще учесть, что pcs «тянет» за собой ruby, openssl, pam и python, а crmsh только python, то выбор в некоторых случаях будет однозначно на стороне crm. В каких случаях? Ну, например, при сертификации ОС есть некоторые трудности с пакетом ruby. Также известны случаи, когда в банковских структурах служба безопасности не разрешает установку нерегламентированного ПО.
Сходства и различия
У утилиты crm есть как сходства, так и различия с известной всем утилитой pcs.
Сходства утилит приведены в таблице 1:

На этом сходства заканчиваются и дальше идут различия, которых много, поэтому привожу лишь некоторые из них (таблица 2):

Различия начинаются с самого начала — с момента инициализации кластера. Инициализировать кластер с помощью crm можно одной командой, а у pcs это происходит в два этапа — авторизация и инициализация.
Удалить кластер («разобрать») у pcs можно одной командой сразу, а у crm необходимо удалять по одному узлу до тех пор, пока их не останется в кластере.
Чтобы изменить параметры ресурса, который мы уже создали в кластере, у pcs есть опция update. У crm такой опции нет, но есть команда configure edit, которая позволяет менять любые настройки кластера налету и мгновенно. Даже больше — мы можем за один прием отредактировать любое количество параметров и ресурсов, и в конце редактирования применить все изменения сразу. Удобно? Думаю, да.
Еще различие – у pcs есть веб-интерфейс, с помощью которого можно выполнить различные действия – запустить, остановить, создать какой-нибудь ресурс с помощью любого браузера.
У crm в стандартной поставке нет веб-инструмента, но зато он есть в коммерческой версии SUSE — HAWK.
Подготовка к настройке отказоустойчивого кластера
Лучший способ узнать и познакомиться с crm — это настроить отказоустойчивый кластер.
Чем мы сейчас и займемся. Для примера возьмем ОС CentOS 7.9.
Для создания отказоустойчивого кластера PostgreSQL нам понадобится стенд, состоящий из 3-х узлов — node1, node2, node3. На каждом узле установлена ОС CentOS 7.9 и пакеты corosync, pacemaker, fence-agents* (агенты фенсинга).
В качестве СУБД будем использовать Postgres Pro Standard v.11, но вы можете с таким же успехом использовать «ванильную» версию PostgreSQL. В нашей системе установлены необходимые пакеты — postgrespro-std-11-server, postgrespro-std-11-libs, postgrespro-std-11-contrib, postgrespro-std-11-client.
Настройки СУБД (postgresql.conf) и доступа к ней (pg_hba.conf) не рассматриваются в данной статье, информации об этом достаточно в интернете. На одном из узлов (например, node1) необходимо инициализировать базу данных с помощью initdb, а на двух других узлах с помощью pg_basebackup скопировать базу данных с node1.
Кроме того, в будущем кластере должны быть настроены синхронизация времени на узлах и разрешение имен узлов в кластере с помощью файла /etc/hosts.
ПРИМЕЧАНИЕ:
В этом разделе все команды необходимо выполнить на всех узлах кластера.
Поскольку пакет crmsh не входит в состав дистрибутива ОС, то необходимо подключить репозиторий Extra OKay Packages for Enterprise Linux с этим пакетом.
node1,2,3$ sudo rpm -ivh http://repo.okay.com.mx/centos/7/x86_64/release/okay-release-1-5.el7.noarch.rpmНам также понадобится репозитарий EPEL:
node1,2,3$ sudo yum install epel-release
node1,2,3$ sudo yum updateУстанавливаем пакет crmsh:
node1,2,3$ sudo yum install crmshПри установке и настройке кластера нам также понадобится пакет
csync2. Это пакет синхронизации конфигураций, созданный специально для кластеров.Разработчики
crmsh вставили код вызова этой кластерной утилиты для удобства настройки. Можно, конечно, обойтись и без csync2, но в таком случае будет больше ручной работы с конфигурационными файлами на каждом узле.ОТСТУПЛЕНИЕ:
Сервис csync2 может использоваться не только для создания отказоустойчивого кластера Corosync/Pacemaker. Например, если есть несколько серверов, у которых меняются конфигурационные файлы и эти файлы периодически нужно синхронизировать по критерию «самый свежий файл».
Итак, устанавливаем
csync2 и простейшую базу данных для хранения мета-данных (sqlite).$ sudo yum install csync2 libsqlite3x-develТут нас поджидает подводный камень.
Поскольку csync2 и crmsh не являются «родными» для CentOS, то без дополнительных «танцев» сразу после установки они не заработают. Вызов crm влечет вызов утилиты csync2, которой в свою очередь не хватает парочки systemd-юнитов. Почему этих файлов нет в пакете csync2 для CentOS — мне неизвестно. Замечу, что в коммерческом дистрибутиве SLES (crmsh там «родной») все необходимые файлы есть, все работает из коробки сразу после установки пакетов.
Итак, создадим и добавим недостающие systemd-юниты.
Первый называется
csync2.socket и содержит:[Socket]
ListenStream=30865
Accept=yes
[Install]
WantedBy=sockets.targetВторой называется
csync2@.service с таким содержимым:[Unit]
Description=csync2 connection handler
After=syslog.target
[Service]
ExecStart=-/usr/sbin/csync2 -i -v
StandardInput=socket
StandardOutput=socketОба файла нужно разместить в стандартной папке systemd — /usr/lib/systemd/system.
Юнит, относящийся к сокету, нужно активировать и установить в автозапуск при загрузке ОС:
node1,2,3$ sudo systemctl enable --now csync2.socketПримечание. Все настройки выполнялись для ОС CentOS, но есть подозрение, что эти действия также понадобятся и для других систем, например, для Debian или Ubuntu.
Теперь у нас все готово к началу работ по настройке кластера.
Настройка кластера с помощью crm
Настройка кластера производится в 2 этапа — инициализация, затем создание и добавление ресурсов. Инициализация кластера с настроенным сервисом синхронизации конфигураций csync2 производится на одном узле.
Если по каким-то причинам вам не удалось «победить» этот сервис, то это не беда, в конце статьи я расскажу, как обойтись без csync2.
На всякий случай сначала удалим кластер (на всех узлах) с помощью такого набора команд:
node1,2,3$ sudo systemctl stop corosync;sudo find /var/lib/pacemaker/cib/ -type f -delete; sudo find -f /etc/corosync/ -type f -deleteДалее надо выполнить команду инициализации кластера:
node1$ sudo crm cluster init --name demo-cluster --nodes "node1 node2 node3" --yesгде demo-cluster — название нашего кластера.
По этой команде создаются необходимые файлы в папке /etc/corosync: corosync.conf, ключ авторизации authkey, а также прописываются ssh-ключи для беспарольной авторизации и выполнения команд в кластере с привилегиями суперпользователя root (на всех трех узлах кластера).
По умолчанию инициализация кластера выполняется в режиме multicast. Но есть также возможность проинициализировать кластер в режиме unicast:
node1$ sudo crm cluster init --unicast --name demo-cluster --nodes "node1 node2 node3" --yesКластер проинициализирован и запущен.
Проверить работоспособность можно с помощью консольного монитора состояния кластера crm_mon:
node1$ sudo crm_mon -AfrДалее можно приступать к созданию ресурсов в кластере.
Создание ресурсов в кластере
Для начала поменяем некоторые значению по умолчанию. Например, порог миграции ресурсов migration-threshold по умолчанию равен 0. Меняем на 1, чтобы после первого сбоя ресурсы мигрировали на другой узел.
node1$ sudo crm configure rsc_defaults rsc-options: migration-threshold=1 resource-stickiness=INFINITYПо умолчанию кластер запускается в симметричном режиме.
Чем отличается симметричный кластер от несимметричного? В симметричном кластере любой созданный ресурс будет запускаться на любом узле, если не установлены дополнительные правила размещения или старта.
В несимметричном — наоборот, ресурс не будет запущен ни на одном узле, пока явно не будет указано, где и в какой последовательности его запускать.
Зачем это нужно? Ну, например, в ситуации, когда в кластере ресурсы запускаются не на всех узлах, т.е. узлы неравноценны по ресурсам и назначению.
Если, вдруг, вам когда-то понадобится изменить режим кластера с симметричного на несимметричный, то достаточно ввести команду:
node1$ sudo crm configure property symmetric-cluster=falseМы оставим этот параметр без изменения.
Включаем механизм stonith:
node1$ sudo crm configure property stonith-enabled=yesСоздадим и добавим ресурс «виртуальный IP адрес»:
node1$ sudo crm configure primitive master-vip IPaddr2 op start timeout=20s interval=0 op stop timeout=20s interval=0 op monitor timeout=20s interval=10s params ip=<virtual IP> nic=eth0где <virtual IP> — виртуальный IP-адрес в кластере.
С помощью монитора состояния кластера crm_mon можно убедиться в том, что ресурс успешно создан и запущен на первом попавшемся узле:
node1$ sudo crm_mon -AfrСоздадим ресурс postgresql и назовем его pg:
node1$ sudo crm configure primitive pg pgsql op start interval=0 timeout=120s op stop interval=0 timeout=120s op monitor interval=30s timeout=30s op monitor interval=29s role=Master timeout=30s params pgctl="/opt/pgpro/std-11/bin/pg_ctl" psql="/opt/pgpro/std-11/bin/psql" pgdata="/var/lib/pgpro/std-11/data" pgport="5432" repuser=postgres master_ip=<virtual IP> rep_mode=sync node_list="node1 node2 node3"ПРИМЕЧАНИЕ:
В данном примере пути расположения бинарников и БД указаны по умолчанию для версии Postgres Pro Std 11. Также для упрощения указан пользователь для репликации «postgres». Но ничто не мешает вам изменить «умолчательные» пути и пользователя репликации на свои.
Хочу обратить внимание на параметр rep_mode: он задан «sync». Это означает, что в отказоустойчивом кластере хотя бы одна реплика будет синхронной. Синхронность реплики в кластере обеспечивает RPO=0 (кластер без потерь данных в случае сбоя).
Зададим тип ресурса Master-Standby (ms):
node1$ sudo crm configure ms mspg pg meta target-role=Master clone-max="3"Нам нужно, чтобы ресурсы vip-master и mspg в режиме «мастер» запускались на одном узле:
node1$ sudo crm configure colocation pgsql-colocation inf: master-vip:Started mspg:MasterУказываем порядок запуска ресурсов – сначала СУБД в режиме «мастер», потом виртуальный IP:
node1$ sudo crm configure order order-promote-pgsql Mandatory: mspg:promote master-vip:startТаким образом, мы создали 2 необходимых ресурса — виртуальный IP адрес и ресурс postgresql.
Теперь можно переходить к настройке фенсинга в отказоустойчивом кластере.
Фенсинг узлов
Про фенсинг в кластере — что это и зачем он нужен — есть много информации в интернете, не хочется повторяться. Добавлю только одно — он необходим в любом кластере. А это значит, что мы его сейчас настроим.
Для начала можно ознакомиться со списком всех агентов фенсинга:
node1$ sudo crm ra list stonithНа моем стенде node1, node2, node3 — это виртуальные машины, которые запущены и управляются с помощью гипервизора KVM. Соответственно, ресурс-агент фенсинга для KVM называется fence_virsh.
Вывести полную информацию о fence_virsh:
node1$ sudo crm ra info stonith:fence_virshПрежде чем создавать ресурс фенсинга, рекомендую проверить работоспособность всей цепочки от ОС виртуалки до гипервизора.
Проверка работоспособности фенсинга для узла node1 выглядит так:
node1$ fence_virsh -a <hypervisor IP> -l <username>-p <password> -n node1 -x --use-sudo -o statusгде username & password — учетная запись на хосте гипервизора.
Фенсинг для node1 настраивается так:
node1$ sudo crm configure primitive fence-node1 stonith:fence_virsh params ipaddr=<hypervisor IP> ip=<hypervisor IP> login=<username> username=<username> passwd=<password> pcmk_host_list=node1 sudo=1 op monitor interval=60sПРИМЕЧАНИЕ:
Ресурсы фенсинга не должны запускаться на «своих» узлах, иначе фенсинг может не сработать.
Следующее правило расположения запретит ресурсу фенсинга для узла node1 располагаться на этом узле:
node1$ sudo crm configure location l_fence_node1 fence-node1 -inf: node1Для node2:
node2$ sudo crm configure primitive fence-node2 stonith:fence_virsh params ipaddr=<hypervisor IP> ip=<hypervisor IP> login=<username> username=<username> passwd=<password> pcmk_host_list=node2 sudo=1 op monitor interval=60s
node2$ sudo crm configure location l_fence_node2 fence-node2 -inf: node2Для node3:
node3$ sudo crm configure primitive fence-node3 stonith:fence_virsh params ipaddr=<hypervisor IP> ip=<hypervisor IP> login=<username> username=<username> passwd=<password> pcmk_host_list=node3 sudo=1 op monitor interval=60s
node3$ sudo crm configure location l_fence_node3 fence-node3 -inf: node3Можно написать скрипт, который будет содержать все команды сразу, останется только его выполнить. Но сегодня наша цель не автоматизация создания кластера, а изучение crm.
Инициализация кластера с помощью crm без csync2
Как обещал выше, расскажу про вариант инициализации кластера без установки и настройки csync2 (если по каким-то причинам вам не удалось его настроить).
Сначала вариант с использованием multicast.
Все команды выполняются на одном узле, например, на node1.
node1$ sudo crm cluster init --name demo-cluster --nodes "node1" --yesПо этой команде создаются необходимые файлы в папке /etc/corosync: corosync.conf, ключ авторизации authkey.
Далее нужно скопировать авторизационный файл authkey и corosync.conf на узлы node2 и node3:
node1$ sudo scp /etc/corosync/{authkey,corosync.conf} node2:/etc/corosync/
node1$ sudo scp /etc/corosync/{authkey,corosync.conf} node3:/etc/corosync/На остальных узлах (на node1 кластер уже запущен) запустить кластер:
node2,3$ sudo crm cluster startС помощью монитора crm_mon можно убедиться, что кластер проинициализирован и запущен:
node1$ sudo crm_mon -AfrВ случае настройки кластера с использованием unicast действия и команды будут отличаться.
Все команды выполняются на одном узле, например, на node1.
node1$ sudo crm cluster init --unicast --name demo-cluster --nodes "node1" --yesОткрываем файл /etc/corosync/corosync.conf и добавляем строки в секцию nodelist:
node {
ring0_addr: node2
nodeid: 2
}
node {
ring0_addr: node3
nodeid: 3
}В секции quorum меняем число голосов:
expected_votes: 3
Далее необходим рестарт сервиса corosync на первом узле:
node1$ sudo systemctl restart corosyncЗатем нужно скопировать файл authkey и отредактированный corosync.conf на узлы node2 и node3:
node1$ sudo scp /etc/corosync/{authkey,corosync.conf} node2:/etc/corosync/
node1$ sudo scp /etc/corosync/{authkey,corosync.conf} node3:/etc/corosync/На остальных узлах (на node1 кластер уже запущен) запустить кластер:
node2,3$ sudo crm cluster startС помощью монитора crm_mon можно убедиться, что кластер проинициализирован и запущен:
node1$ sudo crm_mon -AfrНа этом инициализация кластера без csync2 закончена.
Вспомогательные команды crm
При работе с кластером могут пригодиться некоторые crm-команды.
Для удобства команды и пояснения сведены в таблицу 3:

На этом все. Буду рад, если статья поможет кому-то в создании и настройке отказоустойчивого кластера с помощью утилиты crm.
