Весной администрация хабра любезно предоставила нам блог, чтобы мы рассказали о нашем экзерсисе с распознаванием номеров. Всё поддержание этой системы делалось просто из интереса и на энтузиазме, зато позволило пообщаться с интересными людьми, некоторым людям помочь, а самим найти подработку по совершенно другим тематикам.

В любых задачах обработки изображений 90% успеха — хорошая база данных. Репрезентативная и большая. Весной мы обещали выложить полную базу изображений того, что нам придёт. Подписка блога заканчивается, поэтому время выполнить обещание (блог может продлят, а может и нет). Наш сервер работал 95% времени, начиная с первого поста. Всё что пришло теперь доступно + мы сделали отдельные базы по вырезанным номерам и нарезанным символам.
Под катом ссылки на базу + её анализ + немного кода + небольшой рассказ о том, что будет сделано дальше с нашим сервером/жизнью проекта.
Базы по номерам у нас не размечены (нигде нет файла с правильной расшифровкой). Размечена только база по символам.
База необрезанных фотографий автомобилей (1.4 ГБ). Примерно 9300 кадров.
Размеры будут от пары сотен пикселей до десятка мегапикселей. Выглядят картинки так:

База вырезанных номеров + контрпримеров (260 МБ). Примерно 5000 номеров + 1200 контрпримеров.
Выглядят картинки так:

База нарезанных символов для российских номеров (60 МБ). Примерно 18 тысяч букв, цифр и контрпримеров.
*Маленькое дополнение. Папка «17» — пустая. В ней были буквы «O», но классификаторы не делали различия от неё и нуля, поэтому мы их объединили в папке «0».
Выглядят картинки так:
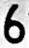

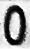
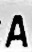


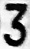

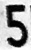

База основана на том, что мы собирали сами + на том, что нам присылали + ручное прореживание от плохих кадров. Для буков дана нарезанная база отрицательных примеров (папка за номером 22). Без отрицательной выборки почти невозможна работа реального алгоритма, буквы будут определяться на любом шуме. В отрицательной выборке содержатся куски буков, без этого порезанная пополам восьмёрка может быть принята за тройку. В конце статьи будет пример такого использования такой базы. Отрицательная выборка дана и для вырезанных номеров, если найдутся желающие обучить каскад по ним.
Из минусов базы:
— порядочно кадров снятых с монитора
— некоторые номера встречаются неоднократно и чаще других
— есть дубликаты изображений, хотя и не очень много
— прореживание кадров для базы с большими фотографиями неидеальное. На сервер приходили всё: совершенно не относящиеся к делу фотографии, пустые фотографии, фотографии с нечитаемыми номерами. Большую часть я вычистил, но остатки могут быть.
Как ни странно, но задача распознавания номеров актуальна в множестве ситуаций, зачастую не связанных с номерами. И, несмотря на то, что вроде как существуют десятки решений, есть множество проектов, где её нужно решить независимо и с нуля. Такая база является подспорьем таким проектам.
Интересна она и для тестирования алгоритмов машинного распознавания и классификации. Взять тот же MNIST. Синтетическая задача, но до сих пор многим интересна. А тут имеется возможность реального применения обученного алгоритма.
Сервер с распознаванием номеров мы планирует поддерживать в рабочем состоянии + иногда мы апдейтим алгоритм. Приложение на телефоны, как мы и предполагали, особо не выстрелило. Оно доступно в PlayStore + есть версия под iPhone. Приложения в целом рабочие, но какой-то дальнейшей их поддержки мы делать не будем. Да и особо большой базы не собралось. Код для обоих приложений открыт. Если хотите, можете допиливать самостоятельно.
С другой стороны мы были приятно удивлены, что наш сервер зачастую стали использовать как некий эталон для проверки своих алгоритмов. Раза три нам загоняли на сервер огромные базы. Точно мы не знаем, кто и зачем. Но, приятно. Видно, что люди потратили время, чтобы сравнить свой алгоритм с нашим, пусть даже далёким от идеала.
Отсюда родилась идея: небольшой кусок базы мы оставили себе. Если вдруг кому будет интересно, можем прогнать алгоритм по нашей базе (или дать базу вам), на условиях нераспространения базы и публикации результатов. Результаты мы опубликуем тут и тут, при публикации ставим ссылку на ваш сайт/контакт.
Нераспространение такой тестовой базы нужно чтобы избежать подгонки результатов, как делают при наличии открытых баз (например MNIST).
Если блог нам продлят, то о результатах и методологии оценки будем отчитываться на Хабре.
Нас уже раз пять просили обновить каскад. На это нужно потратить ещё несколько вечеров, но сейчас времени нет. Обязательно сделаем, представленная тут упорядоченная база — это большой кусок работы в этом направлении. Новая версия появится в нашем репозитории. Ориентировочно займусь на праздники январские, но могу не успеть. В принципе, если кому не лень, можно использовать представленную тут базу и посчитать по ней каскад. Как это сделать вот инструкция. Если сделаете, киньте нам, или прямо на гитхаб, мы обновим каскад на него.
Не смотря на то, что всю логику и алгоритмы мы опубликовали в прошлых статьях, исходники куска, где происходит распознавание букв номера мы пока публиковать не хотим (если вдруг решим отключить сервер окончательно, то, конечно, опубликуем).
Но всё же, нам хотелось бы показать способ, как можно распознавать номера быстро и просто. Поэтому мы перебрали несколько вариантов простых алгоритмов позволяющих распознать буквы, которые легко обучить (при наличии большой базы) и обучили по базе, которую выложили выше. Наилучшие проценты и наиболее простая работа на наш взгляд у SVM в библиотеке Accord (ML-библиотека проекта AForge). В принципе, всё аналогично делается и в OpenCV, SVM есть и там.
Обучение:
Распознавание реализуется двумя строчками:
Важно, чтобы входные данные были бинаризованы. Это значительно повышает точность работы. Приведу пример загрузки:
Пример обученного SVM'a. Процент правильно распознанных символов по независимой от обучающей выборке — 96%.
Из историй связанных с номерами. Сейчас в Казахстане происходит (или происходил) какой-то массовый тендер на установку систем распознавания номеров. Но компетентных фирм, связанных с системными решениями IT там не то очень мало, не то нет совсем. Где-то раз-два в месяц с нами связывается очередной менеджер оттуда и предлагает поставить им систему немедленно, уже обученную под номера страны. При этом путая слова «сервер» и «камера»…

В любых задачах обработки изображений 90% успеха — хорошая база данных. Репрезентативная и большая. Весной мы обещали выложить полную базу изображений того, что нам придёт. Подписка блога заканчивается, поэтому время выполнить обещание (блог может продлят, а может и нет). Наш сервер работал 95% времени, начиная с первого поста. Всё что пришло теперь доступно + мы сделали отдельные базы по вырезанным номерам и нарезанным символам.
Под катом ссылки на базу + её анализ + немного кода + небольшой рассказ о том, что будет сделано дальше с нашим сервером/жизнью проекта.
Сама база
Базы по номерам у нас не размечены (нигде нет файла с правильной расшифровкой). Размечена только база по символам.
База необрезанных фотографий автомобилей (1.4 ГБ). Примерно 9300 кадров.
Размеры будут от пары сотен пикселей до десятка мегапикселей. Выглядят картинки так:

База вырезанных номеров + контрпримеров (260 МБ). Примерно 5000 номеров + 1200 контрпримеров.
Выглядят картинки так:

База нарезанных символов для российских номеров (60 МБ). Примерно 18 тысяч букв, цифр и контрпримеров.
*Маленькое дополнение. Папка «17» — пустая. В ней были буквы «O», но классификаторы не делали различия от неё и нуля, поэтому мы их объединили в папке «0».
Выглядят картинки так:











Пара слов про базу
База основана на том, что мы собирали сами + на том, что нам присылали + ручное прореживание от плохих кадров. Для буков дана нарезанная база отрицательных примеров (папка за номером 22). Без отрицательной выборки почти невозможна работа реального алгоритма, буквы будут определяться на любом шуме. В отрицательной выборке содержатся куски буков, без этого порезанная пополам восьмёрка может быть принята за тройку. В конце статьи будет пример такого использования такой базы. Отрицательная выборка дана и для вырезанных номеров, если найдутся желающие обучить каскад по ним.
Из минусов базы:
— порядочно кадров снятых с монитора
— некоторые номера встречаются неоднократно и чаще других
— есть дубликаты изображений, хотя и не очень много
— прореживание кадров для базы с большими фотографиями неидеальное. На сервер приходили всё: совершенно не относящиеся к делу фотографии, пустые фотографии, фотографии с нечитаемыми номерами. Большую часть я вычистил, но остатки могут быть.
Зачем это нужно?
Как ни странно, но задача распознавания номеров актуальна в множестве ситуаций, зачастую не связанных с номерами. И, несмотря на то, что вроде как существуют десятки решений, есть множество проектов, где её нужно решить независимо и с нуля. Такая база является подспорьем таким проектам.
Интересна она и для тестирования алгоритмов машинного распознавания и классификации. Взять тот же MNIST. Синтетическая задача, но до сих пор многим интересна. А тут имеется возможность реального применения обученного алгоритма.
Дальнейшая жизнь проекта
Сервер с распознаванием номеров мы планирует поддерживать в рабочем состоянии + иногда мы апдейтим алгоритм. Приложение на телефоны, как мы и предполагали, особо не выстрелило. Оно доступно в PlayStore + есть версия под iPhone. Приложения в целом рабочие, но какой-то дальнейшей их поддержки мы делать не будем. Да и особо большой базы не собралось. Код для обоих приложений открыт. Если хотите, можете допиливать самостоятельно.
С другой стороны мы были приятно удивлены, что наш сервер зачастую стали использовать как некий эталон для проверки своих алгоритмов. Раза три нам загоняли на сервер огромные базы. Точно мы не знаем, кто и зачем. Но, приятно. Видно, что люди потратили время, чтобы сравнить свой алгоритм с нашим, пусть даже далёким от идеала.
Отсюда родилась идея: небольшой кусок базы мы оставили себе. Если вдруг кому будет интересно, можем прогнать алгоритм по нашей базе (или дать базу вам), на условиях нераспространения базы и публикации результатов. Результаты мы опубликуем тут и тут, при публикации ставим ссылку на ваш сайт/контакт.
Нераспространение такой тестовой базы нужно чтобы избежать подгонки результатов, как делают при наличии открытых баз (например MNIST).
Если блог нам продлят, то о результатах и методологии оценки будем отчитываться на Хабре.
Про каскад
Нас уже раз пять просили обновить каскад. На это нужно потратить ещё несколько вечеров, но сейчас времени нет. Обязательно сделаем, представленная тут упорядоченная база — это большой кусок работы в этом направлении. Новая версия появится в нашем репозитории. Ориентировочно займусь на праздники январские, но могу не успеть. В принципе, если кому не лень, можно использовать представленную тут базу и посчитать по ней каскад. Как это сделать вот инструкция. Если сделаете, киньте нам, или прямо на гитхаб, мы обновим каскад на него.
Обучение распознавания букв
Не смотря на то, что всю логику и алгоритмы мы опубликовали в прошлых статьях, исходники куска, где происходит распознавание букв номера мы пока публиковать не хотим (если вдруг решим отключить сервер окончательно, то, конечно, опубликуем).
Но всё же, нам хотелось бы показать способ, как можно распознавать номера быстро и просто. Поэтому мы перебрали несколько вариантов простых алгоритмов позволяющих распознать буквы, которые легко обучить (при наличии большой базы) и обучили по базе, которую выложили выше. Наилучшие проценты и наиболее простая работа на наш взгляд у SVM в библиотеке Accord (ML-библиотека проекта AForge). В принципе, всё аналогично делается и в OpenCV, SVM есть и там.
Обучение:
using Accord.MachineLearning.VectorMachines;
using Accord.MachineLearning.VectorMachines.Learning;
using Accord.Statistics.Kernels;
//Набор входных изображений, развёрнутых в одномерные массивы
double[][] inputs;
//Набор ответов чем являются входные изображения
int[] outputs;
//"Размазанность" гауссианы при обучении. Чем ниже значение, тем больше "обобщения" делает SVM
double sigma = 12;
//Количество классов при обучении. В номерах 10 цифр, 12 букв, + 1 класс с отрицательной выборкой
int classCount=23;
MulticlassSupportVectorLearning teacher = null;
//Параметры распознающей машины: длина массива на каждую фотографию, параметр ядра обучения, количество классов
//sigma - единственный настраиваемый параметр обучения. Я ставил где-то 10-20, изменялась точность незначительно.
machine = new MulticlassSupportVectorMachine(width*height, new Gaussian(sigma), classCount);
//Инициализация обучения
teacher = new MulticlassSupportVectorLearning(machine, inputs, outputs);
teacher.Algorithm = (svm, classInputs, classOutputs, i, j) => new SequentialMinimalOptimization(svm, classInputs, classOutputs) { CacheSize = 0 };
teacher.Run();
machine.Save("MachineForSymbol");
Распознавание реализуется двумя строчками:
MulticlassSupportVectorMachine machine = MulticlassSupportVectorMachine.Load("MachineForSymbol");
int output = machine.Compute(input);
Важно, чтобы входные данные были бинаризованы. Это значительно повышает точность работы. Приведу пример загрузки:
using AForge.Imaging;
using AForge.Imaging.Filters;
private static List<double> test(string str)
{
Bitmap bmp = new Bitmap(str);
//При обучении нужно, чтобы все изображения были единого размера. База которую мы привели позволяет обучатся на размере 34*60. Тут мы её немножко ужимаем, для скорости работы.
ResizeNearestNeighbor filter = new ResizeNearestNeighbor(17, 30);
int count = 0;
BitmapData bitmapData = bmp.LockBits(new Rectangle(0, 0, bmp.Width, bmp.Height),
ImageLockMode.ReadWrite, PixelFormat.Format24bppRgb);
List<double> res = new List<double>();
int width = bitmapData.Width;
int height = bitmapData.Height;
int stride = bitmapData.Stride;
int offset = stride - width*3;
unsafe
{
byte* ptr = (byte*)bitmapData.Scan0.ToPointer();
double summ = 0;
for (int y = 0; y < bitmapData.Height; y++)
{
for (int x = 0; x < bitmapData.Width; x++, ptr+=3)
{
//Можно загрузить ЧБ изображения, но тут предполагается, что работаем с цветными изображениями
res.Add((ptr[0] + ptr[1] + ptr[2]) / (3*255.0));
summ += (ptr[0] + ptr[1] + ptr[2]);
}
ptr += offset;
}
summ = summ / (3*255.0* bitmapData.Height * bitmapData.Width);
//Бинаризуем по среднему цвету изображения
for (int i = 0; i < res.Count; i++)
{
if (res[i]<summ)
res[i] = 0;
else
res[i] = 1;
}
}
bmp.UnlockBits(bitmapData);
return res;
}
Пример обученного SVM'a. Процент правильно распознанных символов по независимой от обучающей выборке — 96%.
P.S.
Из историй связанных с номерами. Сейчас в Казахстане происходит (или происходил) какой-то массовый тендер на установку систем распознавания номеров. Но компетентных фирм, связанных с системными решениями IT там не то очень мало, не то нет совсем. Где-то раз-два в месяц с нами связывается очередной менеджер оттуда и предлагает поставить им систему немедленно, уже обученную под номера страны. При этом путая слова «сервер» и «камера»…
