Несколько месяцев назад я писал статью про тихую революцию в ComputerVision. Про трансформеры. Эта статья про другую революцию в CV. Уже не такую тихую (статьи тут куда более известные). В статье я поговорю о StyleGan и их вариациях. Это лишь часть большого мира GAN'ов. Зато очень интересная.
В последний год-полтора появилось много различных способов управлять GAN-сетями. Качество многих сгенерированных объектов уже не отличается от реальности. Куда это придет? Попробуем поговорить об этом.
Сразу предупрежу, что я не эксперт именно в GAN’ах. Я почти 15 лет занимаюсь ComputerVision, но GAN это менее десяти процентов задач, и лишь последние годы. Так что возможно будут какие-то мелкие баги/что-то не знаю.
И, если вдруг кому-то удобнее. Вся эта статья есть в формате видео на Youtube.
Два слова про GAN
Буквально пару слов о том, что такое GAN:
Генеративно-состязательная сеть (Generative adversarial network, GAN) — алгоритм машинного обучения без учителя, построенный на комбинации из двух нейронных сетей, одна из которых генерирует образцы, а другая старается отличить правильные («подлинные») образцы от неправильных. Генеративно-состязательную сеть описал Ян Гудфеллоу из компании Google в 2014 году.
Использование этой техники позволяет в частности генерировать фотографии, которые человеческим глазом воспринимаются как натуральные изображения.
(c) Wikipedia
А почитать подробнее можно тут, тут и тут.
SlyleGan и почему именно он?
Оригинальный SlyleGan и его апдейт SlyleGan2 доступен уже несколько лет. Вы все видели эти "фотографии":

Но это не фото. Это сгенерированные лица. Отличить их от настоящих в целом можно. Но нужно внимательно вглядываться. Смотрите на мочки ушей, на блики в глазах, на отдельные волоски, на фон, и.т.д.
Сама идея StyleGan - не нова. Как и в любом GAN берется некоторый латентный вектор, который обучается дискриминатором.
Что такое "латентный вектор"? Это набор характеристик, описывающих человека как набор признаков. Например “белые волосы, мужчина, черная борода, 15 лет”, и.т.д. При этом, вектор может не иметь явной визуальной репрезентации.
Архитектура получается примерно такой (слева классика, справа первый StyleGAN):

Основное отличие от существовавших на тот момент подходов - регуляризация за счет шума в момент обучения + использование стиля на каждом сверточном слое, пропущенного через Mapping Network. Почитать подробнее можно тут и тут. Или посмотреть это видео.
Ключевой элемент в StyleGAN - латентный вектор. На вход сеть получает некоторый короткий код, по которому сеть генерит лицо. А что, если этот вектор начать изменять?
")

В втором StyleGan чуть-чуть поменяли нормализацию в сети. По сути это единственное серьезное отличие от первого (вот тут можно почитать подробнее)
Рассказывать про StyleGAN можно очень долго, но я не хотел бы углубляться, мой рассказ про другое (ссылок чтобы углубиться я дал достаточно). Ключевой поинт моего рассказа: мы можем задать лицо набором параметров, и потом работать с этими параметрами вместо лица (а как я расскажу чуть ниже).
Производительность
Но сперва, прежде чем перейдем к интересной части - поговорим о больном. С производительностью все плохо. Не так плохо как с некоторыми трансформерами, но все же:

Чтобы натренировать StyleGAN генерировать картинки лиц в хорошем разрешении - надо много времени. Для хорошего качества нужна неделя кластера из 8 TeslaV100 (140 т.р. на не самом дорогом https://immers.cloud/gpu/, примерно 290 т.р. на Амазоне https://aws.amazon.com/ru/ec2/instance-types/p3/ )
На 3090 будет подешевле и побыстрее, но пойди найди свободный кластер.
Конечно, появились подходы где это чуть лучше оптимизировано, но не сильно.
И все же, почему StyleGAN?
Как я сказал выше - у StyleGAN есть возможность манипулировать входным вектором. Самый базовый результат этого факта - можно редактировать изображения, сохраняя их реалистичность.
Но позвольте... Ведь StyleGAN генерирует только несуществующие картинки? Как я применю его к реальным лицам?

Пространство правильно обученного StyleGAN покрывает почти все пространство лиц. И наша задача - лишь найти код, который максимально похож на искомое лицо. Как это сделать? Наиболее наглядное описание, на мой взгляд, вот в этом видео. Если в двух словах:


Если хотите поиграться - вот оригинальный репозиторий для stylegan энкодера. А вот google Colab с готовой реализацией от автора видео выше (там надо только пару багов пофиксить). Получается как-то так:

")
Чуть подробнее про энкодинг
В целом, процесс энкодинга может выглядеть по разному. Есть много алгоритмов поиска и дальнейшей навигации в пространстве StyleGAN. Или статей, где эта задача решается с другой стороны(гит).
Поиск у разных алгоритмов может выглядеть так:

Ниже будет несколько вариантов энкодеров (у разных статей разные). Но, помните, что всегда можно найти лучшую проекцию.
Если хотите почитать про разные энкодинги подробнее, то можно, например, тут. Там есть ещё такие классные примеры как натянуть лицо на платье:

Редактирование
В видео выше можно посмотреть простые способы редактирования. Например:
Возраст
Пол
Улыбка
Поза
и.т.д....

Опять же, ссылку на статью с хорошим тюнингом я уже давал. Хотя там уже немного не чистый StyleGAN, в статье StyleGAN лишь помогает обучить дополнительную сеть для манипуляции признаками:

Композиция
Но есть много других интересных подходов к редактированию. Например свежая статья "Latent Composition":

Конечно, тут уже не достаточно "покрутить латентный код" или "усреднить два вектора". Используется хитрый способ чтобы вычислить значимую часть латентного вектора, определяющую выделенную область. У ребят есть Colab с примером. Энкодер (алгоритм нахождения максимально похожего StyleGAN лица) там работает чуть похуже, чем тот, что я использовал выше:

Но общую идею вполне можно запустить и протестить:

Удаление деталей
Аналогичным образом можно удалять лишние детали, стирать очки, и.т.д.:

И таких статей достаточно много:
Co Mod Gan - у ребят есть демо и сорсы
BRGM - восстановление половины изображения по второй половине
В целом задача называется inpainting. К ней есть много подходов, и StyleGAN - лишь часть из них.
Повороты
Не смотря на то что можно попробовать поворачивать лицо через латентную репрезентацию, есть много статей где результат лучше (1,2):

Текстовое описание
Пол года назад Google выпустил шикарную сеть CLIP (вот тут я делал более подробный обзор). Она была про взаимную привязку пространства эмбединга для текста и пространства эмбединга для изображения:
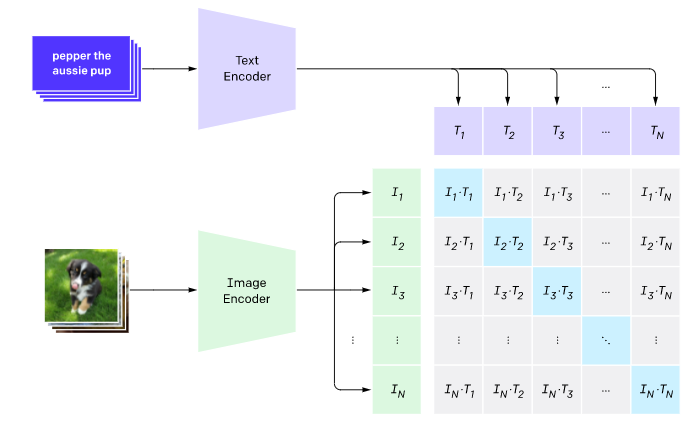
Основной смысл сети был в том, чтобы понимать какое описание подходит к какой картинке (дополнительный плюс этой работы - стабильность работы в разных доменах).
При этом, StyleGan - это такой же эмбединг, который выполняет роль описания изображения. Почему бы его не привязать у тексту? И действительно, есть очень интересная работа StyleCLIP, в которой можно изменять изображения вбивая текст.

У авторов есть интересный колаб где можно поэкспериментировать. У них тоже не очень хороший энкодинг в пространство StyleGAN:

Зато неплохо потом может добавлять разные детали (очки например), менять эмоции и прическу:


Другой домен
Другим интересным подходом можно назвать перенос из одного домена в другой. Под доменом тут подразумевается "стиль"/"способ отрисовки лица":
")
К статье, к сожалению, нет исходников. Зато есть исходники к другой статье, которая переносит в домен "аниме".
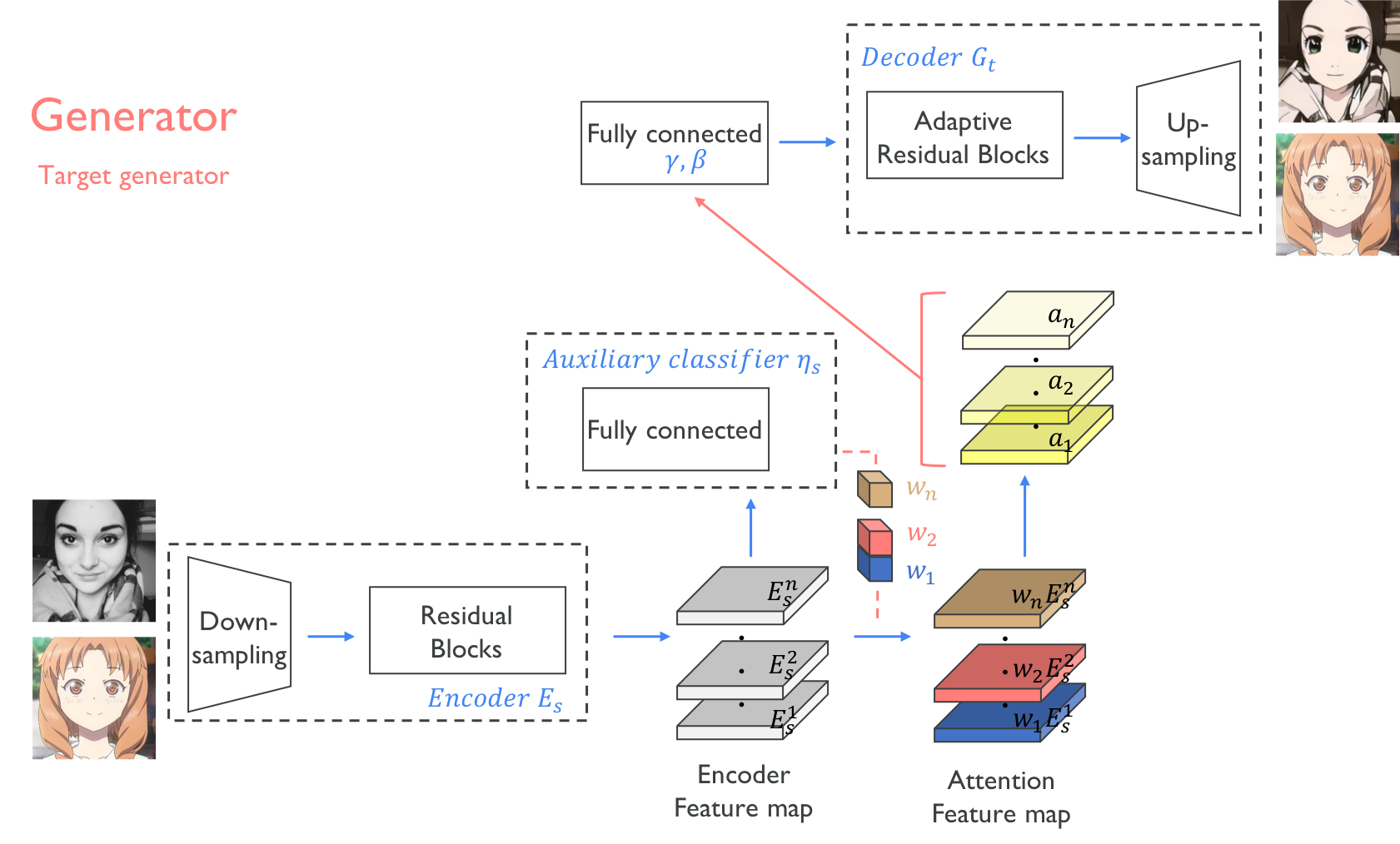
Правда она уже не про StyleGAN. Но тут, скорее про идею:) Вдруг захотите.

ПОЧЕМУ ТОЛЬКО ЛИЦА?!
А вот тут мы немножко прервемся и поговорим о теории. Вы не задумывались над вопросом почему большая часть StyleGAN работ про лица?
Если что, многие не задумываются;) Регулярно приходят и предложением генерировать одежды, дизайны, и.т.д. Но не все так просто.
Подумаем как можно математически представить лицо. Удивительно, но лицо - это достаточно простой объект. Ещё лет 20 назад начали появляться работы на тему 3DMM (чуть более свежие - 1,2), где оценивается базис, по которому раскладывается лицо. И компонентов у такого базиса обычно 100-300, в зависимости от работы и подробности эмоций.
В статьях по Face Recognition для распознавания лица обычно хватает 128, а иногда и 64 компонента для получения вероятности ложного совпадения на уровне 10^-5.
Это значит что 99% лиц и эмоций можно описать всего сотней-другой параметров. Это не много. При работе с лицом, StyleGAN работает, по сути, как алгоритм компрессии/декомпрессии (при этом пространство самого StyleGAN шире, там в зависимости от разрешения 512*(16±2) значений латентного вектора). Нужно определить всего сотню параметров лица - и этого будет достаточно, чтобы сгенерировать лицо.
А теперь внимание. Чем больше параметров - тем сложнее работать сети. Ниже я приведу много примеров из других областей работы. И, чем сложнее объект - тем хуже будет работать StyleGAN.
Посмотрим на варианты
В оригинальном StyleGAN можно посмотреть обученные сетки с генерацией:
Автомобилей
Котов
Лошадей
Церквей
При этом качество 1024*1024 есть только для лиц. Все остальное хуже, что уже намекает. Посмотрим как это выглядит:
Котики. Котики, наверное, один из самых хорошо работающих объектов. Особенно если там нет лап, или сидят они в стандартной позе:

Чем меньше лапок, чем меньше движений - тем лучше все работает. Котики, вообще хороший материал для StyleGAN. Вот работа, аналогичная латентной композиции, где можно скрещивать котов.
Машины. Машины с одной стороны хорошо определены. Пусть всего несколько тысяч основных моделей + пару сотен вариантов параметризации. Но на практике начинает вылезать слишком много проблем:

Посмотрите на геометрию, особенно на краях. Номера не читаемы либо не логичны. Отражения не соответствуют фону, и.т.д. С поворотами, фоном, колесами параметров становится уже не так мало. При этом, конечно, можно найти хорошие примеры. И да, если что, то в Latent Composition можно вполне дотюнинговать машинку.
Лошади. Вспомним правило: "Чем больше параметров - тем хуже работает StyleGAN". А лошадь, это уже и геометрия, и обвес, и всадник. И тут - все хуже и хуже:

Церкви. Можете ли вы параметризовать дома? Вряд ли. И у сети начинаются галлюцинации:

Глаза. Хороший пример где простая картинка параметризуется. Статей нет, но, скорее всего, оно тоже на StyleGAN:

Вот тут все более красиво и под музыку.
Одежда
Как вы понимаете, создавать глаза, котиков, лошадок и церкви - плохой бизнес кейс. Всем нужно модифицировать лица. Всем нужно делать какой-то дизайн. Все хотят рисовать одежду. А с одеждой засада. Параметров то уже много. Но ведь бизнес. И люди стараются находить корнеркейсы где все работает. Но, по порядку.
Самая популярная задача для генерации одежды - Virtual Try On. Даже датасет неплохой есть. К ней есть много очень разных подходов, но мы будем говорить только про GAN-подходы. В лоб все работает не очень хорошо:

Конечно, автор тренирует всего 4 дня на одной GPU.
Больше GPU-шек (4 штуки на 4 недели) дают более интересный, но все равно, далекий от идеального результат:

Зато итоговый результат позволяет производить манипуляции с изображением (опять же, добавить к обученному StyleGan conditional составляющую):

В целом, итоговый результат тоже далек от идеала. Но работает (n.b. - сорсов нет, так что доказательств тоже):

Две статьи выше, конечно, это 2019-2020 годы. С тех пор появился StyleGAN-2, и качество подросло. При почти той же загрузке (8 Tesla V100 на 12 дней) При правильной постановке задачи (одна и та же поза, отрубленная голова, руки не в карманах/без пальцев) можно получить такой результат:


Опять же, в данном случае нет исходников, так что гарантировать что все работает/что все это не CherryPicking/не кастомный подход - нельзя.
Модели. Вот ещё попытка создать работающий генератор людей + одежду. Как вы видите - даже не смотря на одинаковые и повторяющиеся позы, не смотря на минимум одежды - видно много проблем и огрехов. Хотя впечатление тоже неплохое.

Шмот. А вот неплохая статья где автор рассказывает как обучал сетки создания обуви и одежды:

Опять же, максимальное качество не сказать что супер - но уже неплохо (за счет того что все развернуто в одну проекцию).
А что с видео?
Сам по себе StyleGAN не нацелен на генерацию видео. И большая часть работ это какие-то хаки, нацеленные на то чтобы получить видео. Например вот тут люди используют изменение рта для анимации персонажей. Понятно, что штука очень узкоспециализированная. И в общем случае StyleGAN не решает таких вопросов.

Есть другие подходы стремящееся к видео. Например вот в этой работе генерируется бесконечная панорама. По сути добавили информацию про сдвиг и старую картинку:
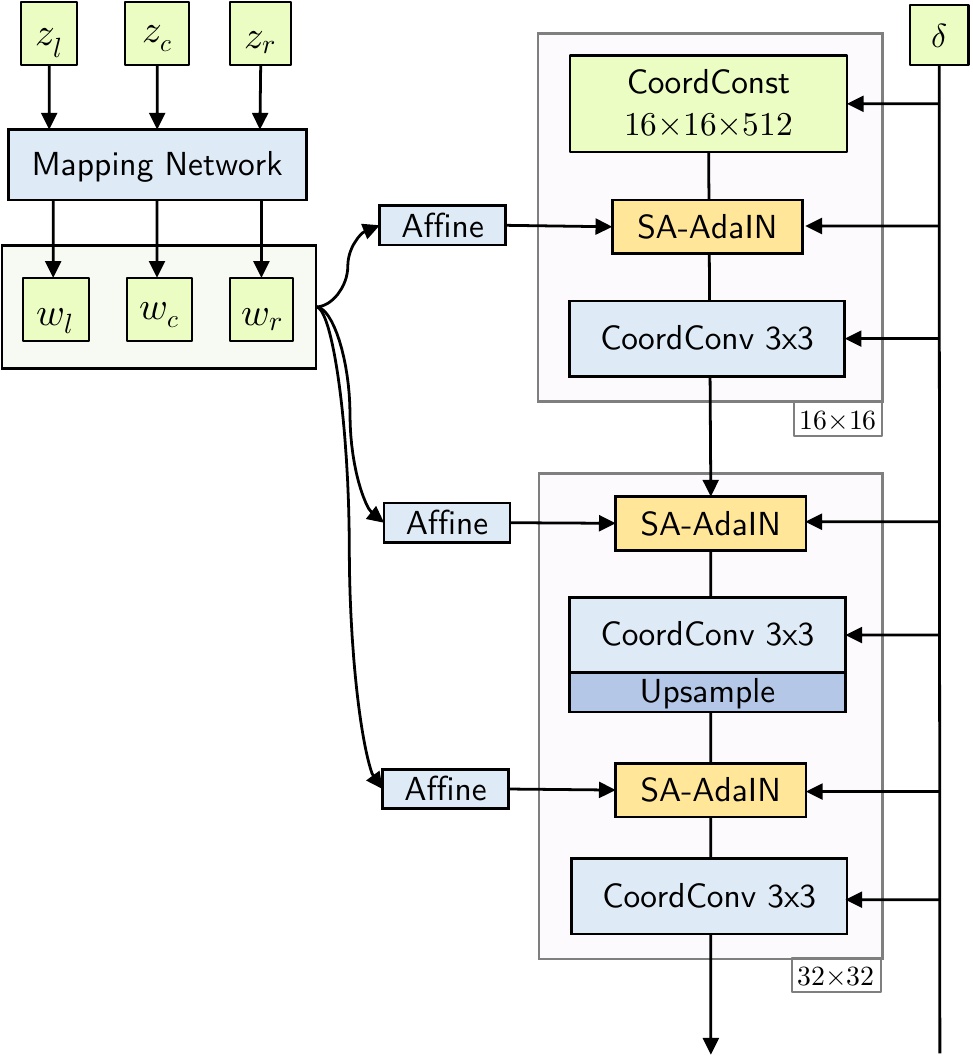

Переходя к следующему пункту, про то какие сети есть кроме StyleGAN - вот новая сетка от NVIDIA, которая частично решает вопрос плавной и аккуратной навигации в латентном пространстве:

А что дальше?
StyleGAN и StyleGAN2 - появились уже давно. Второй StyleGAN ещё 2019 года. И, несмотря на огромную популярность - понятно что нужно что-то новое. И сейчас появляется множество других идей и подходов которые может быть когда-нибудь выстрелят. Может быть это будет Alias GAN, который выпустила NVIDIA (про который я говорил в прошлом пункте). Может быть это будет какая-нибудь модификация на трансформерах, например такая:

А может быть это будут диффузионные модели, которыми занимаются Google Brain, Open Ai и много кто ещё.
Выводы
За последние пару лет в области GAN поменялось очень многое. Они становятся предсказуемыми , с ними можно работать, качество все лучше и лучше. Да, пока места где все работает очень ограничены. Да, обучать очень долго и дорого. Но это разрешимые проблемы. Так что ждем чего-нибудь интересного:)
P.S.
Если нахожу что-то новое и интересное - стараюсь рассказывать у себя на канале (tg, vk). На хабре стараюсь писать уже какие-то сформированные мысли, когда материала на статью накопилось. И да, все что тут расказано есть в формате видео.
