Компьютеры – это «железо». И сегодня мы вернулись в исходную точку, в том смысле, что сейчас редко найдешь физический хост, на котором выполняется одна единственная задача. Даже если на сервере крутится только одно приложение, оно, скорее всего, состоит из нескольких процессов, контейнеров или даже виртуальных машин (ВМ), и все они работают на одном сервере. Red Hat Enterprise Linux 7 неплохо справляется с распределением системных ресурсов в таких ситуациях, но по умолчанию ведет себя как добрая бабушка, угощающая внуков домашним пирогом и приговаривающая: «Всем поровну, всем поровну».

В теории принцип «всем поровну», конечно, прекрасен, но на практике некоторые процессы, контейнеры или ВМ оказываются важнее других, и, следовательно, должны получать больше.
В Linux уже давно есть средства управления использованием ресурсов (nice, ulimit и прочее), однако с появлением Red Hat Enterprise Linux 7 и systemd у нас наконец-то появился мощный набор таких инструментов, встроенный в саму ОС. Дело в том, что ключевой компонент systemd – это уже готовый, настроенный набор cgroups, который в полной мере задействуется на уровне ОС.
Хорошо, а что это вообще за cgroups, и причем здесь управление ресурсами или производительностью?
Начиная с вышедшей в январе 2008 года версии 2.6.24, в ядре Linux появилось то, что изначально было придумано и создано в Google под именем «process containers», а в Linux стало называться «control groups», сокращенно cgroups. Вкратце, cgroups – это механизм ядра, позволяющий ограничивать использование, вести учет и изолировать потребление системных ресурсов (ЦП, память, дисковый ввод/вывод, сеть и т. п.) на уровне коллекций процессов. Cgroups также могут замораживать процессы для проверки и перезапуска. Контроллеры cgroups впервые появились в 6-й версии Red Hat Enterprise Linux, но там их надо было настраивать вручную. А вот с приходом Red Hat Enterprise Linux 7 и systemd преднастроенный набор cgroups идет уже в комплекте с ОС.
Все это работает на уровне ядра ОС и поэтому гарантирует строгий контроль над каждым процессом. Так что теперь какому-нибудь зловреду крайне сложно нагрузить систему так, чтобы она перестала реагировать и зависла. Хотя, конечно, багованный код с прямым доступом к «железу» (например, драйверы), все еще на такое способен. При этом, Red Hat Enterprise Linux 7 предоставляет интерфейс для взаимодействия с cgroups, и вся работа с ними в основном ведется через команду systemd.
На диаграмме ниже, напоминающей нарезанный пирог, представлены три cgroups, которые по умолчанию есть на сервере Red Hat Enterprise Linux 7 – System, User и Machine. Каждая из этих групп называется «слайс» (slice – сектор). Как видно на рисунке, каждый слайс может иметь дочерние секторы-слайсы. И, как и в случае с тортом, в сумме все слайсы дают 100% соответствующего ресурса.
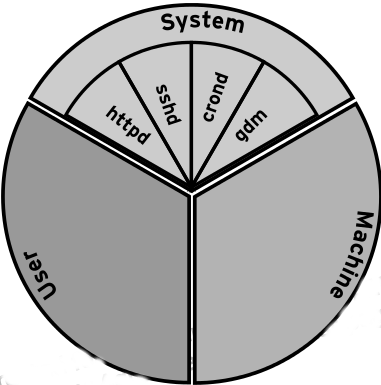
Теперь рассмотрим несколько концепций cgroups на примере процессорных ресурсов.
На рисунке выше видно, что процессорное время поровну делится между тремя слайсами верхнего уровня (System, User и Machine). Но так происходит только под нагрузкой. Если же какой-то процесс из слайса User попросит 100% процессорных ресурсов, и никому больше эти ресурсы в данный момент не нужны, то он получит все 100% процессорного времени.
Каждый из трех слайсов верхнего уровня предназначен для своего типа рабочих нагрузок, которым нарезаются дочерние сектора в рамках родительского слайса:
Кроме того, для управления использованием ресурсов применяется концепция так называемых «шар» (share – доля). Шара – это относительный числовой параметр; его значение имеет смысл только в сравнении со значениями других шар, входящих в ту же cgroup. По умолчанию все слайсы имеют шару, равную 1024. В слайсе System на рисунке выше для httpd, sshd, crond и gdm заданы CPU-шары, равные 1024. Значения шар для слайсов System, User и Machine тоже равны 1024. Немного запутанно? На самом деле это можно представить в виде дерева:
В этом списке у нас есть несколько запущенных демонов, пара пользователей и одна виртуальная машина. Теперь представим, что все они одновременно запрашивают всё процессорное время, какое только можно получить.
В итоге:
Кроме того, для любого демона, пользователя или виртуальной машины можно вводить не только относительные, но и абсолютные ограничения на потребление процессорного времени, причем не только одного, но и нескольких процессоров. Например, у слайса пользователя mrichter есть свойство CPUQuota. Если выставить его на 20 %, то mrichter ни при каких обстоятельствах не получит больше 20 % ресурсов одного ЦП. На многоядерных серверах CPUQuota может быть больше 100 %, чтобы слайс мог пользоваться ресурсами более чем одного процессора. Например, при CPUQuota = 200 % слайс может полностью задействовать два процессорных ядра. При этом важно понимать, что CPUQuota не резервирует, иначе говоря, не гарантирует заданный процент процессорного времени при любой загруженности системы – это лишь максимум, который может быть выделен слайсу с учетом всех прочих слайсов и настроек.
Как можно поменять настройки слайсов?
Для этого у каждого слайса есть настраиваемые свойства. И поскольку это Linux, мы можем вручную прописывать настройки в файлах конфигураций или же задавать из командной строки.
Во втором случае используется команда systemctl set-property. Вот что будет на экране, если набрать эту команду, добавить в конце имя слайса (в нашем случае User) и затем нажать клавишу Tab для отображения опций:
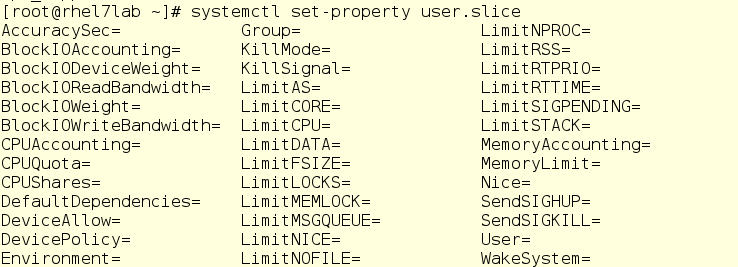
Не все свойства на этом скриншоте являются настройками cgroup. Нас в основном интересуют те, что начинаются на Block, CPU и Memory.
Если вы предпочитаете не командную строку, а config-файлы (например, для автоматизированного развертывания на нескольких хостах), то тогда придется заняться файлами в папке /etc/systemd/system. Эти файлы автоматически создаются при установке свойств с помощью команды systemctl, но их также можно создавать в текстовом редакторе, штамповать через Puppet или даже генерировать скриптами на лету.
Итак, с базовыми понятиями cgroups все должно быть ясно. В следующий раз пройдем по некоторым сценариям и посмотрим, как изменения тех или иных свойств влияют на производительность.
А буквально завтра приглашаем всех на Red Hat Forum Russia 2018 – будет возможность задать вопросы напрямую инженерам Red Hat.
Другие посты по cgroups из нашей серии «Борьба за ресурсы» доступны по ссылкам:

В теории принцип «всем поровну», конечно, прекрасен, но на практике некоторые процессы, контейнеры или ВМ оказываются важнее других, и, следовательно, должны получать больше.
В Linux уже давно есть средства управления использованием ресурсов (nice, ulimit и прочее), однако с появлением Red Hat Enterprise Linux 7 и systemd у нас наконец-то появился мощный набор таких инструментов, встроенный в саму ОС. Дело в том, что ключевой компонент systemd – это уже готовый, настроенный набор cgroups, который в полной мере задействуется на уровне ОС.
Хорошо, а что это вообще за cgroups, и причем здесь управление ресурсами или производительностью?
Контроль на уровне ядра
Начиная с вышедшей в январе 2008 года версии 2.6.24, в ядре Linux появилось то, что изначально было придумано и создано в Google под именем «process containers», а в Linux стало называться «control groups», сокращенно cgroups. Вкратце, cgroups – это механизм ядра, позволяющий ограничивать использование, вести учет и изолировать потребление системных ресурсов (ЦП, память, дисковый ввод/вывод, сеть и т. п.) на уровне коллекций процессов. Cgroups также могут замораживать процессы для проверки и перезапуска. Контроллеры cgroups впервые появились в 6-й версии Red Hat Enterprise Linux, но там их надо было настраивать вручную. А вот с приходом Red Hat Enterprise Linux 7 и systemd преднастроенный набор cgroups идет уже в комплекте с ОС.
Все это работает на уровне ядра ОС и поэтому гарантирует строгий контроль над каждым процессом. Так что теперь какому-нибудь зловреду крайне сложно нагрузить систему так, чтобы она перестала реагировать и зависла. Хотя, конечно, багованный код с прямым доступом к «железу» (например, драйверы), все еще на такое способен. При этом, Red Hat Enterprise Linux 7 предоставляет интерфейс для взаимодействия с cgroups, и вся работа с ними в основном ведется через команду systemd.
Свой кусок пирога
На диаграмме ниже, напоминающей нарезанный пирог, представлены три cgroups, которые по умолчанию есть на сервере Red Hat Enterprise Linux 7 – System, User и Machine. Каждая из этих групп называется «слайс» (slice – сектор). Как видно на рисунке, каждый слайс может иметь дочерние секторы-слайсы. И, как и в случае с тортом, в сумме все слайсы дают 100% соответствующего ресурса.

Теперь рассмотрим несколько концепций cgroups на примере процессорных ресурсов.
На рисунке выше видно, что процессорное время поровну делится между тремя слайсами верхнего уровня (System, User и Machine). Но так происходит только под нагрузкой. Если же какой-то процесс из слайса User попросит 100% процессорных ресурсов, и никому больше эти ресурсы в данный момент не нужны, то он получит все 100% процессорного времени.
Каждый из трех слайсов верхнего уровня предназначен для своего типа рабочих нагрузок, которым нарезаются дочерние сектора в рамках родительского слайса:
- System – демоны и сервисы.
- User – пользовательские сеансы. Каждый пользователь получает свой дочерний слайс, причем все сеансы с одинаковым UID «живут» в одном и том же слайсе, чтобы особо ушлые умники не могли получить ресурсов больше положенного.
- Machine – виртуальные машины, типа KVM-гостей.
Кроме того, для управления использованием ресурсов применяется концепция так называемых «шар» (share – доля). Шара – это относительный числовой параметр; его значение имеет смысл только в сравнении со значениями других шар, входящих в ту же cgroup. По умолчанию все слайсы имеют шару, равную 1024. В слайсе System на рисунке выше для httpd, sshd, crond и gdm заданы CPU-шары, равные 1024. Значения шар для слайсов System, User и Machine тоже равны 1024. Немного запутанно? На самом деле это можно представить в виде дерева:
- System — 1024
- httpd — 1024
- sshd — 1024
- crond — 1024
- gdm — 1024
- User — 1024
- bash (mrichter) — 1024
- bash (dorf) — 1024
- Machine — 1024
- testvm — 1024
В этом списке у нас есть несколько запущенных демонов, пара пользователей и одна виртуальная машина. Теперь представим, что все они одновременно запрашивают всё процессорное время, какое только можно получить.
В итоге:
- Слайс System получает 33,333% процессорного времени и поровну делит его между четырьмя демонами, что дает каждому из них по 8,25% ресурсов ЦП.
- Слайс User получает 33,333% процессорного времени и делит его между двумя пользователями, каждый из которых имеет по 16,5% ресурсов ЦП. Если пользователь mrichter выйдет из системы или остановит все свои запущенные процессы, то пользователю dorf станет доступно 33% ресурсов ЦП.
- Слайс Machine получает 33,333% процессорного времени. Если выключить ВМ или перевести ее в холостой режим, то слайсы System и User будут получать примерно по 50 % ресурсов ЦП, которые затем поделятся между их дочерними слайсами.
Кроме того, для любого демона, пользователя или виртуальной машины можно вводить не только относительные, но и абсолютные ограничения на потребление процессорного времени, причем не только одного, но и нескольких процессоров. Например, у слайса пользователя mrichter есть свойство CPUQuota. Если выставить его на 20 %, то mrichter ни при каких обстоятельствах не получит больше 20 % ресурсов одного ЦП. На многоядерных серверах CPUQuota может быть больше 100 %, чтобы слайс мог пользоваться ресурсами более чем одного процессора. Например, при CPUQuota = 200 % слайс может полностью задействовать два процессорных ядра. При этом важно понимать, что CPUQuota не резервирует, иначе говоря, не гарантирует заданный процент процессорного времени при любой загруженности системы – это лишь максимум, который может быть выделен слайсу с учетом всех прочих слайсов и настроек.
Выкручиваем на полную!
Как можно поменять настройки слайсов?
Для этого у каждого слайса есть настраиваемые свойства. И поскольку это Linux, мы можем вручную прописывать настройки в файлах конфигураций или же задавать из командной строки.
Во втором случае используется команда systemctl set-property. Вот что будет на экране, если набрать эту команду, добавить в конце имя слайса (в нашем случае User) и затем нажать клавишу Tab для отображения опций:

Не все свойства на этом скриншоте являются настройками cgroup. Нас в основном интересуют те, что начинаются на Block, CPU и Memory.
Если вы предпочитаете не командную строку, а config-файлы (например, для автоматизированного развертывания на нескольких хостах), то тогда придется заняться файлами в папке /etc/systemd/system. Эти файлы автоматически создаются при установке свойств с помощью команды systemctl, но их также можно создавать в текстовом редакторе, штамповать через Puppet или даже генерировать скриптами на лету.
Итак, с базовыми понятиями cgroups все должно быть ясно. В следующий раз пройдем по некоторым сценариям и посмотрим, как изменения тех или иных свойств влияют на производительность.
А буквально завтра приглашаем всех на Red Hat Forum Russia 2018 – будет возможность задать вопросы напрямую инженерам Red Hat.
Другие посты по cgroups из нашей серии «Борьба за ресурсы» доступны по ссылкам:
- Часть 2 – habr.com/company/redhatrussia/blog/424367
- Часть 3 – habr.com/company/redhatrussia/blog/425803
- Часть 4 – habr.com/company/redhatrussia/blog/427413
- Часть 5 – habr.com/company/redhatrussia/blog/429064
- Часть 6 – habr.com/company/redhatrussia/blog/430748
