Продолжаем изучать Control Groups (Cgroups) в Red Hat Enterprise Linux 7. Займемся памятью. Вы помните, что для распределения процессорного времени есть две регулировки: CPUShares для настройки относительных долей и CPUQuota для того, чтобы ограничивать пользователя, службу или виртуальную машину (ВМ) в абсолютных величинах (процентах) процессорного времени. Причем, обе эти регулировки можно использовать одновременно. Например, если для пользователя задана CPU-квота в 50 %, то его CPU-шара тоже будет приниматься во внимание до тех пор, пока он полностью не выберет свою квоту в 50 % процессорного времени.

Что касается оперативной памяти, то systemd предлагает только один способ регулировки, а именно…
Объем памяти, который может быть выделен пользователю или службе. Допустим, мы хотим ограничить пользователя mrichter 200 МБ ОЗУ. Если помните, его UID равен 1000, поэтому мы вводим следующую команду:
Теперь mrichter хочет проверить свои границы и запускает утилиту нагрузочного тестирования stress, которая начинает усиленно потреблять память. И stress очень быстро выдает ошибку:

По системному журналу видно, что stress был попросту прерван OOM (Out Of Memory) Killer.
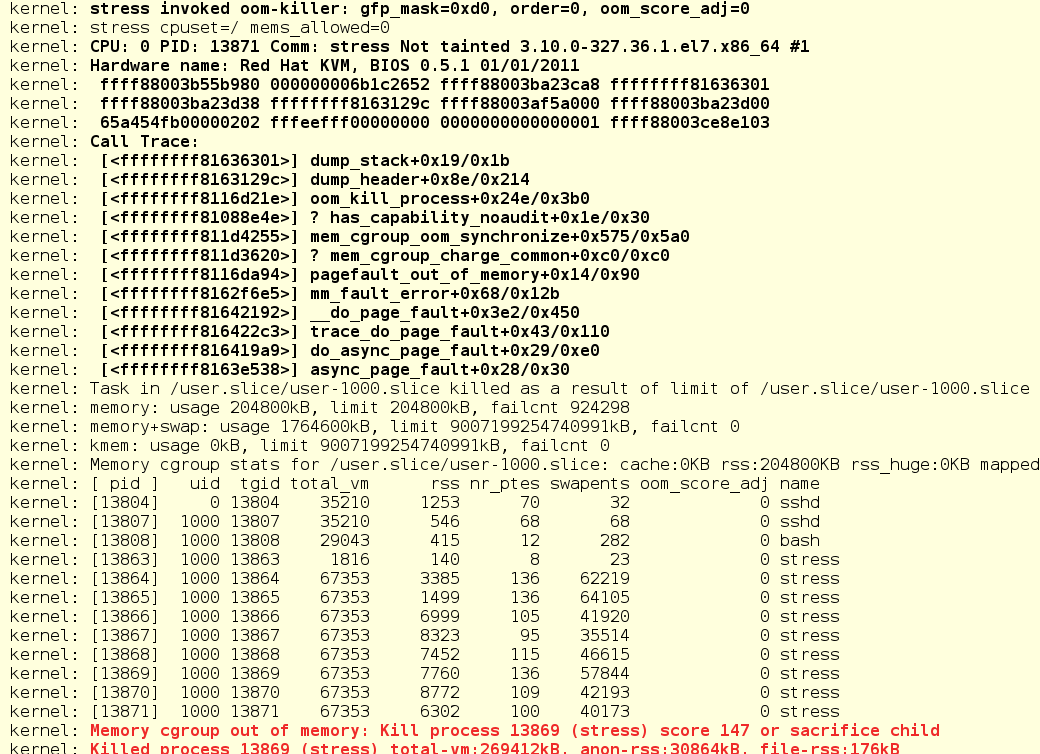
Здесь важно обратить внимание вот на что: по умолчанию ограничение на ОЗУ распространяется только на резидентную память. То есть, если процесс может уходить в файл подкачки («своп»), то он обойдет установленное ограничение. В нашем примере stress вылетел потому, что превысил ограничение на резидентную память.
А если мы не хотим, чтобы программа сливалась в своп?
Это, в общем-то, легко запретить. Ну или относительно легко… В общем, придется кое-куда залезть.
Есть такие настройки cgroup, до которых не добраться ни через команду systemctl, ни через юнит-файлы. Однако эти настройки можно менять на лету через файлы в папке /sys/fs/cgroup/. Вот как, к примеру, выглядит cgroup пользователя mrichter в части памяти:
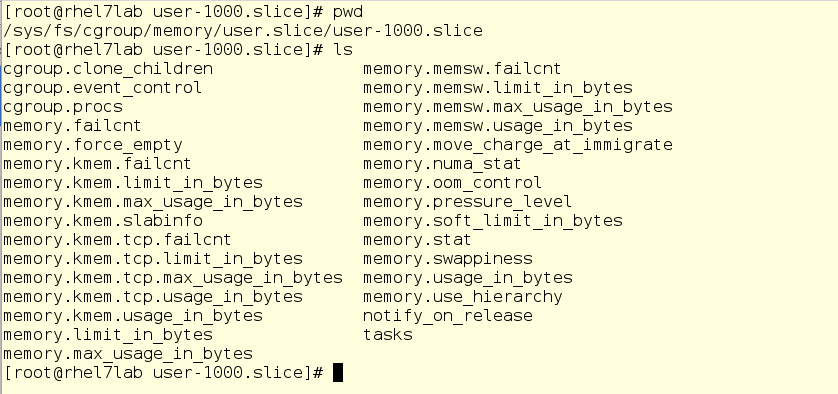
Файл, отвечающий за то, сколько памяти может уходить в своп, вполне очевидно называется memory.swappiness. Посмотрим, что у него внутри:

Если вам случалось играться с настройками ядра и подсистемой свопинга, то вы сразу увидите здесь стандартное значение параметра swappiness по умолчанию. Если поменять его на ноль, то ОЗУ-регулятор для пользователя mrichter вообще запретит ему использовать своп.

Кстати, здесь же можно глянуть статистику памяти для пользователя mrichter:
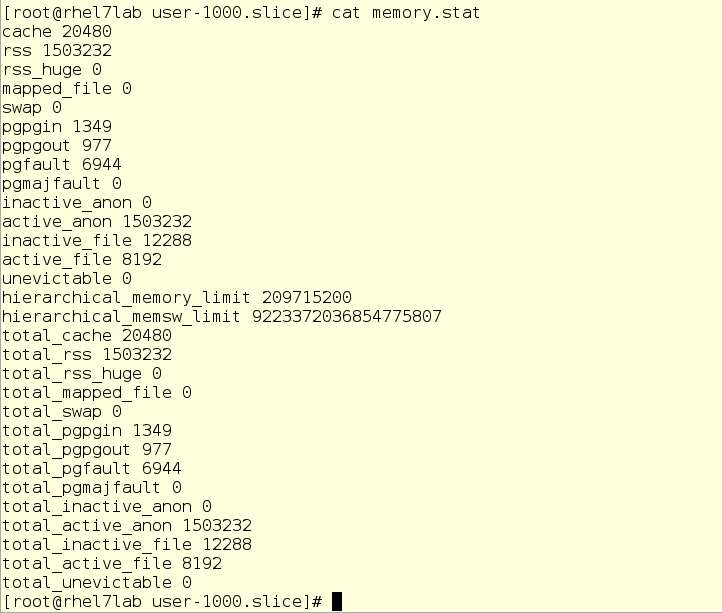
Значение параметра hierarchical_memory_limit – это тот самый MemoryLimit, который мы задали командой systemctl. Параметр hierarchical_memsw_limit представляет собой суммарный лимит (резидентная память и память в файле подачки). Мы запретили пользователю mrichter использовать файл подкачки, поэтому значение этого параметра такое странное.
Теперь о проблемах только что описанного подхода:
Справиться с этими проблемами поможет сценарий pam_exec (подробнее см. access.redhat.com/solutions/46199).
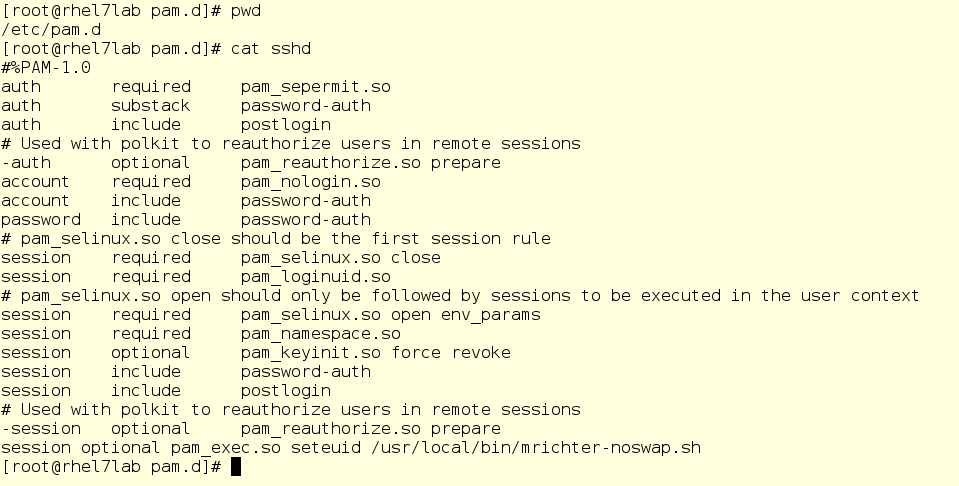
Вот какой сценарий мы создадим в папке /usr/local/bin:

А затем добавим его вызов в последнюю строку /etc/pam.d/sshd. В результате, этот сценарий будет запускаться при каждом входе пользователя через ssh. Именно поэтому мы и проверяем в сценарии, что это пользователь mrichter, прежде чем менять настройки.
Итак, мы отрезали пользователя mrichter от файла подкачки.

Можно конечно пойти еще дальше и менять конфигурационные файлы активной cgroup на лету, но мы пока отложим это рисковое дело. Тем не менее, общий метод, как менять настройки пользователя, вы уловили.
А со службами все еще проще. В юнит-файле службы можно использовать директиву ExecStartPost=, чтобы запускать сценарий, меняющий настройки. Например, вот как надо изменить юнит-файл службы foo, чтобы выключить свопинг:

Запускаем foo – и никакого свопинга:

Ладно, на сегодня, пожалуй, хватит с нас этого шаманства.
Но прежде чем закончить, давайте остановимся на документации по cgroup, в которой можно найти информацию обо всех этих скрытых настройках регуляторов. Вы можете установить пакет kernel-doc на свой компьютер, как это сделал я, загрузив его из репозитория «rhel-7-server-rpms».
После установки откройте папку /usr/share/docs, соответствующую вашему ядру, и перейдите в папку cgroups, где и содержится последняя информация по всем регуляторам.

В следующем раз мы поговорим о вводе-выводе. И, кстати, мы уже почти подошли к тому, чтобы узнать, как cgroups привели к появлению контейнеров (на самом деле cgroups – это ключевой компонент контейнеров в Red Hat Enterprise Linux и Red Hat OpenShift Container Platform).

Что касается оперативной памяти, то systemd предлагает только один способ регулировки, а именно…
Объем памяти, который может быть выделен пользователю или службе. Допустим, мы хотим ограничить пользователя mrichter 200 МБ ОЗУ. Если помните, его UID равен 1000, поэтому мы вводим следующую команду:
systemctl set-property user-1000.slice MemoryLimit=200M
Теперь mrichter хочет проверить свои границы и запускает утилиту нагрузочного тестирования stress, которая начинает усиленно потреблять память. И stress очень быстро выдает ошибку:

По системному журналу видно, что stress был попросту прерван OOM (Out Of Memory) Killer.

Здесь важно обратить внимание вот на что: по умолчанию ограничение на ОЗУ распространяется только на резидентную память. То есть, если процесс может уходить в файл подкачки («своп»), то он обойдет установленное ограничение. В нашем примере stress вылетел потому, что превысил ограничение на резидентную память.
А если мы не хотим, чтобы программа сливалась в своп?
Это, в общем-то, легко запретить. Ну или относительно легко… В общем, придется кое-куда залезть.
Есть такие настройки cgroup, до которых не добраться ни через команду systemctl, ни через юнит-файлы. Однако эти настройки можно менять на лету через файлы в папке /sys/fs/cgroup/. Вот как, к примеру, выглядит cgroup пользователя mrichter в части памяти:

Файл, отвечающий за то, сколько памяти может уходить в своп, вполне очевидно называется memory.swappiness. Посмотрим, что у него внутри:

Если вам случалось играться с настройками ядра и подсистемой свопинга, то вы сразу увидите здесь стандартное значение параметра swappiness по умолчанию. Если поменять его на ноль, то ОЗУ-регулятор для пользователя mrichter вообще запретит ему использовать своп.

Кстати, здесь же можно глянуть статистику памяти для пользователя mrichter:

Значение параметра hierarchical_memory_limit – это тот самый MemoryLimit, который мы задали командой systemctl. Параметр hierarchical_memsw_limit представляет собой суммарный лимит (резидентная память и память в файле подачки). Мы запретили пользователю mrichter использовать файл подкачки, поэтому значение этого параметра такое странное.
Теперь о проблемах только что описанного подхода:
- Вносить изменения в эти файлы можно только тогда, когда пользователь mrichter залогинился в систему. Пока он не войдет, его cgroup будет неактивна.
- Эти настройки не сохраняются после перезагрузки. Более того, они потеряются, если mrichter перелогинится.
Справиться с этими проблемами поможет сценарий pam_exec (подробнее см. access.redhat.com/solutions/46199).
Вот какой сценарий мы создадим в папке /usr/local/bin:

А затем добавим его вызов в последнюю строку /etc/pam.d/sshd. В результате, этот сценарий будет запускаться при каждом входе пользователя через ssh. Именно поэтому мы и проверяем в сценарии, что это пользователь mrichter, прежде чем менять настройки.

Итак, мы отрезали пользователя mrichter от файла подкачки.

Можно конечно пойти еще дальше и менять конфигурационные файлы активной cgroup на лету, но мы пока отложим это рисковое дело. Тем не менее, общий метод, как менять настройки пользователя, вы уловили.
А со службами все еще проще. В юнит-файле службы можно использовать директиву ExecStartPost=, чтобы запускать сценарий, меняющий настройки. Например, вот как надо изменить юнит-файл службы foo, чтобы выключить свопинг:

Запускаем foo – и никакого свопинга:

Ладно, на сегодня, пожалуй, хватит с нас этого шаманства.
Но прежде чем закончить, давайте остановимся на документации по cgroup, в которой можно найти информацию обо всех этих скрытых настройках регуляторов. Вы можете установить пакет kernel-doc на свой компьютер, как это сделал я, загрузив его из репозитория «rhel-7-server-rpms».

После установки откройте папку /usr/share/docs, соответствующую вашему ядру, и перейдите в папку cgroups, где и содержится последняя информация по всем регуляторам.

В следующем раз мы поговорим о вводе-выводе. И, кстати, мы уже почти подошли к тому, чтобы узнать, как cgroups привели к появлению контейнеров (на самом деле cgroups – это ключевой компонент контейнеров в Red Hat Enterprise Linux и Red Hat OpenShift Container Platform).
- Часть 1 – habr.com/company/redhatrussia/blog/423051
- Часть 2 – habr.com/company/redhatrussia/blog/424367
- Часть 4 – habr.com/company/redhatrussia/blog/427413
- Часть 5 – habr.com/company/redhatrussia/blog/429064
- Часть 6 – habr.com/company/redhatrussia/blog/430748
