
Утечки памяти похожи на сущности, паразитирующие на приложении. Они незаметно проникают в системы, поначалу не принося никакого вреда. Но если утечка оказывается достаточно сильной — она способна довести приложение до катастрофы. Например — сильно его замедлить или попросту «убить».

Автор статьи, перевод которой мы сегодня публикуем, предлагает поговорить об утечках памяти в JavaScript. В частности, речь пойдёт об управлении памятью в JavaScript, о том, как идентифицировать утечки памяти в реальных приложениях, и о том, как с бороться с утечками памяти.
Утечка памяти — это, в широком смысле, фрагмент памяти, выделенной приложению, который больше не нужен этому приложению, но не может быть возвращён операционной системе для дальнейшего использования. Другими словами это — блок памяти, который захвачен приложением без намерения пользоваться этой памятью в будущем.
Управление памятью — это механизм выделения системной памяти приложению, которое нуждается в ней, и механизм возврата ненужной памяти операционной системе. Существует множество подходов к управлению памятью. То, какой именно подход применяется, зависит от используемого языка программирования. Вот обзор нескольких распространённых подходов к управлению памятью:
Существуют и другие подходы к управлению памятью, используемые в разных языках программирования. Например, в C++11 используется идиома RAII, в Swift применяется механизм ARC. Но разговор об этом выходит за рамки данной статьи. Для того чтобы сравнить вышеупомянутые методы управления памятью, чтобы разобрать их плюсы и минусы, нужна отдельная статья.
JavaScript — язык, без которого веб-программисты не представляют своей работы, использует идею сборки мусора. Поэтому мы подробнее поговорим о том, как работает этот механизм.
Как уже было сказано, JavaScript — это язык, в котором используется концепция сборки мусора. В ходе работы JS-программ периодически запускается механизм, называемый сборщиком мусора. Он выясняет то, к каким участкам выделенной памяти можно получить доступ из кода приложения. То есть — то, на какие переменные имеются ссылки. Если сборщик мусора выясняет, что к какому-то участку памяти больше нет доступа из кода приложения, он освобождает эту память. Вышеописанный подход может быть реализован с помощью двух основных алгоритмов. Первый — это так называемый алгоритм пометок (Mark and Sweep). Он используется в JavaScript. Второй — это подсчёт ссылок (Reference Counting). Он применяется в Python и PHP.
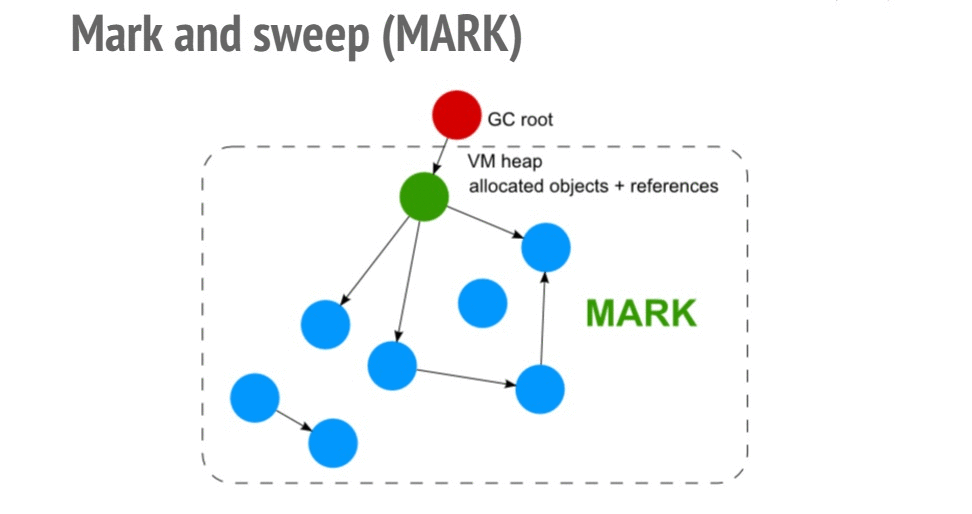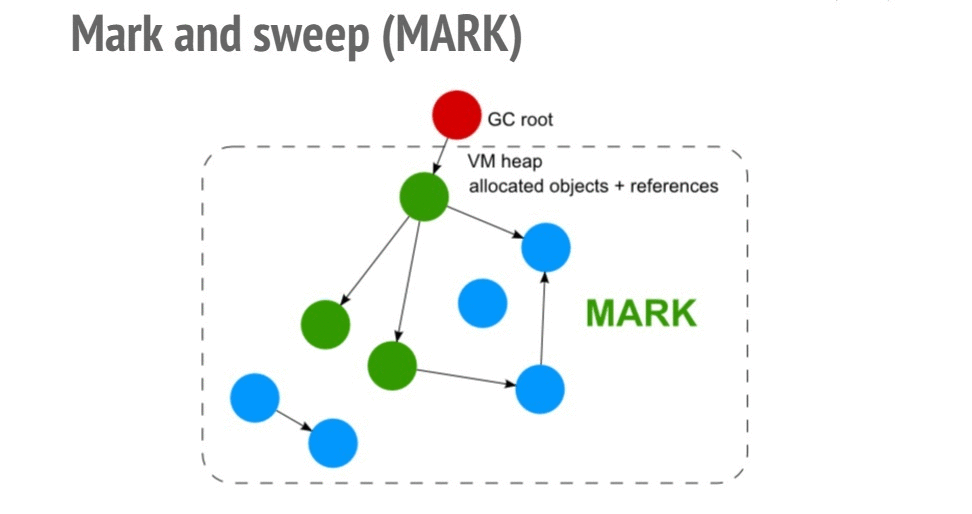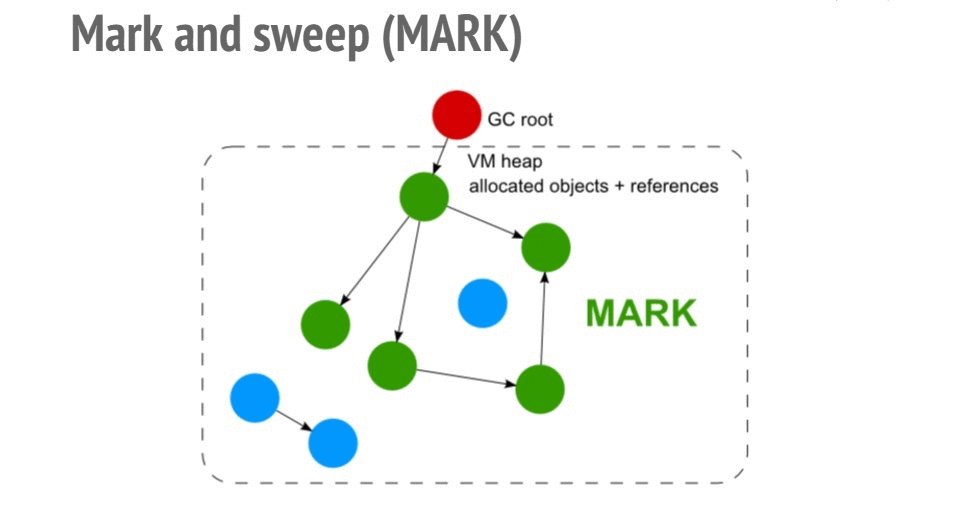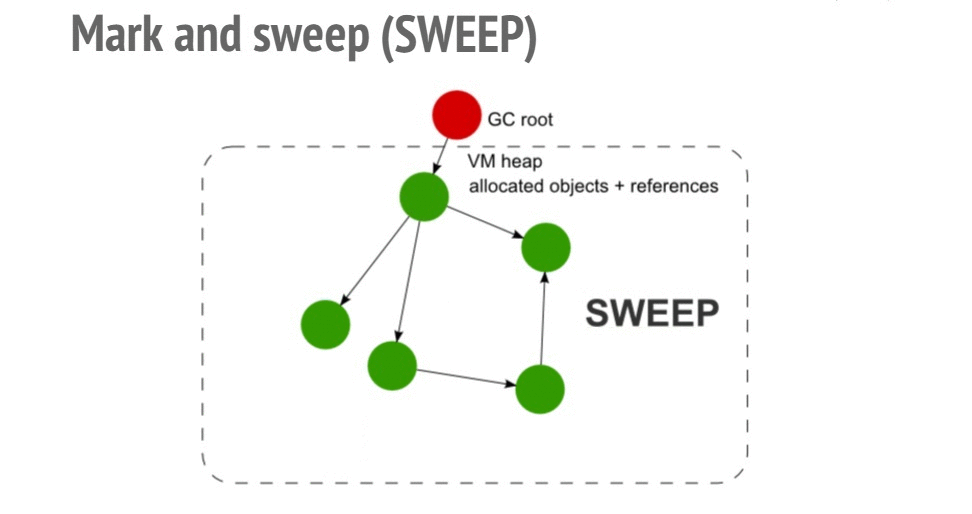
Фазы Mark (пометка) и Sweep (очистка) алгоритма Mark and Sweep
При реализации алгоритма пометок сначала создаётся список корневых узлов, представленных глобальными переменными окружения (в браузере это — объект
К настоящему моменту мы разобрали достаточно теоретических понятий, касающихся утечек памяти и сборки мусора. А значит — мы готовы к тому, чтобы посмотреть на то, как всё это выглядит в реальных приложениях. В этом разделе мы напишем Node.js-сервер, в котором есть утечка памяти. Мы попытаемся выявить эту утечку, используя различные инструменты, а потом её устраним.
В демонстрационных целях я написал Express-сервер, у которого есть маршрут с утечкой памяти. Этот сервер мы и будем отлаживать.
Здесь имеется массив
Здесь мы подходим к самому интересному. Написано много статей, рассказывающих о том, как, используя
Для того чтобы справиться с нашей проблемой, мы собираемся заняться отладкой в продакшне. То есть — мы позволим нашему серверу переполнить память во время его реального использования (по мере того, как он будет получать самые разные запросы к API). А после того, как обнаружим подозрительный рост объёма выделяемой им памяти, займёмся отладкой.
Для того чтобы разобраться с тем, что такое «дамп кучи», нам сначала надо выяснить смысл понятия «куча». Если описать это понятие максимально просто, то окажется, что куча — это то место, куда попадает всё то, для чего выделяется память. Всё это находится в куче до тех пор, пока сборщик мусора не уберёт из неё всё то, что будет признано ненужным. Дамп кучи — это нечто вроде снимка текущего состояния кучи. Дамп содержит все внутренние переменные и переменные, объявленные программистом. В нём представлена вся память, выделенная в куче на момент получения дампа.
В результате, если бы мы могли как-то сравнить дамп кучи только что запущенного сервера с дампом кучи сервера, работающего уже долго и переполняющего память, то мы смогли бы идентифицировать подозрительные объекты, которые не нужны приложению, но не удаляются сборщиком мусора.
Прежде чем продолжать разговор — поговорим о том, как создавать дампы кучи. Для решения этой задачи мы воспользуемся npm-пакетом heapdump, который позволяет программно получить дамп кучи сервера.
Установим пакет:
Внесём в код сервера некоторые изменения, которые позволят нам воспользоваться данным пакетом:
Здесь мы воспользовались данным пакетом для получения дампа свежезапущенного сервера. Так же мы создали API
Если ваш сервер работает в кластере Kubernetes, то вам не удастся, без дополнительных усилий, обратиться именно к тому поду, сервер, работающий в котором, потребляет слишком много памяти. Для того чтобы это сделать, можно воспользоваться перенаправлением портов. Кроме того, так как у вас не будет доступа к файловой системе, который нужен для загрузки файлов дампов, эти файлы лучше будет выгрузить во внешнее облачное хранилище (вроде S3).
И вот, сервер развёрнут. Он работает уже несколько дней. К нему поступает множество запросов (в нашем случае — лишь запросы одного вида) и мы обратили внимание на рост объёма памяти, потребляемой сервером. Заметить утечку памяти можно, пользуясь инструментами мониторинга наподобие Express Status Monitor, Clinic, Prometheus. После этого мы вызываем API для создания дампа кучи. Этот дамп будет содержать все объекты, которые не смог удалить сборщик мусора.
Вот как выглядит запрос, позволяющий создать дамп:
При создании дампа кучи принудительно запускается сборщик мусора. В результате нам не нужно беспокоиться о тех объектах, которые могут быть удалены сборщиком мусора в будущем, но пока находятся в куче. То есть — об объектах, при работе с которыми утечек памяти не происходит.
После того, как в нашем распоряжении окажутся оба дампа (дамп свежезапущенного сервера и дамп сервера, проработавшего некоторое время), мы можем приступить к их сравнению.
Получение дампа памяти — это блокирующая операция, на выполнение которой нужно много памяти. Поэтому выполнять её надо с осторожностью. Подробнее о возможных проблемах, возникающих в ходе этой операции, можно почитать здесь.
Запустим Chrome и нажмём клавишу

Загрузка дампов памяти на вкладке Memory инструментов разработчика Chrome
После загрузки обоих снимков нужно изменить

Начало сравнения снимков
Здесь мы можем проанализировать столбец
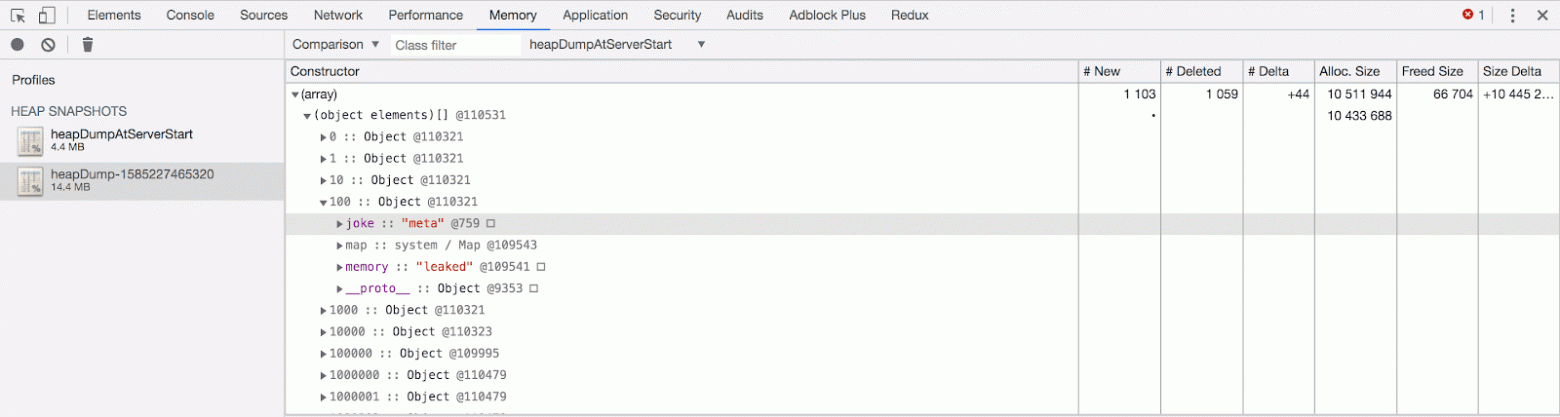
Анализ подозрительного массива
Эта методика позволит нам выйти на массив
Теперь, когда мы знаем о том, что «виновником торжества» является массив
Для того чтобы проверить действенность принятых мер, достаточно повторить вышеописанные шаги и снова сравнить снимки кучи.
Утечки памяти случаются в разных языках. В частности в — тех, в которых используются механизмы сборки мусора. Например — в JavaScript. Обычно исправить утечку несложно — настоящие сложности возникают лишь при её поиске.
В этом материале вы ознакомились с основами управления памятью, и с тем, как организовано управление памятью в разных языках. Здесь мы воспроизвели реальный сценарий утечки памяти и описали методику поиска и устранения проблемы.
Уважаемые читатели! Сталкивались ли вы с утечками памяти в своих веб-проектах?


Автор статьи, перевод которой мы сегодня публикуем, предлагает поговорить об утечках памяти в JavaScript. В частности, речь пойдёт об управлении памятью в JavaScript, о том, как идентифицировать утечки памяти в реальных приложениях, и о том, как с бороться с утечками памяти.
Что такое утечка памяти?
Утечка памяти — это, в широком смысле, фрагмент памяти, выделенной приложению, который больше не нужен этому приложению, но не может быть возвращён операционной системе для дальнейшего использования. Другими словами это — блок памяти, который захвачен приложением без намерения пользоваться этой памятью в будущем.
Управление памятью
Управление памятью — это механизм выделения системной памяти приложению, которое нуждается в ней, и механизм возврата ненужной памяти операционной системе. Существует множество подходов к управлению памятью. То, какой именно подход применяется, зависит от используемого языка программирования. Вот обзор нескольких распространённых подходов к управлению памятью:
- Ручное управление памятью. При использовании этого метода за выделение и освобождение памяти отвечает программист. Язык не предоставляет автоматизированных средств для решения этих задач. Хотя это и даёт разработчику огромную гибкость, это усложняет его работу. Такой подход к управлению памятью используется в C и C++. В распоряжении программиста, использующего эти языки, есть методы
mallocиfree, позволяющие ему выделять и освобождать память. - Применение концепции сборки мусора. Языки, в которых реализована идея сборки мусора, управляют памятью автоматически, полностью избавляя программиста от решения соответствующих задач. Программисту не нужно, в частности, заботиться об освобождении памяти, так как эту задачу решает встроенный сборщик мусора. То, как именно работает сборщик мусора, и то, когда именно выполняются сеансы освобождения памяти, скрыто от программиста. Концепция сборки мусора используется в большинстве современных языков программирования. Это — JavaScript, языки, основанные на JVM (Java, Scala, Kotlin), Golang, Python, Ruby и другие.
- Применение концепции владения памятью. При таком подходе каждая переменная должна иметь своего владельца. Как только владелец оказывается за пределами области видимости, значение в переменной уничтожается, освобождая память. Эта идея используется в Rust.
Существуют и другие подходы к управлению памятью, используемые в разных языках программирования. Например, в C++11 используется идиома RAII, в Swift применяется механизм ARC. Но разговор об этом выходит за рамки данной статьи. Для того чтобы сравнить вышеупомянутые методы управления памятью, чтобы разобрать их плюсы и минусы, нужна отдельная статья.
JavaScript — язык, без которого веб-программисты не представляют своей работы, использует идею сборки мусора. Поэтому мы подробнее поговорим о том, как работает этот механизм.
Сборка мусора в JavaScript
Как уже было сказано, JavaScript — это язык, в котором используется концепция сборки мусора. В ходе работы JS-программ периодически запускается механизм, называемый сборщиком мусора. Он выясняет то, к каким участкам выделенной памяти можно получить доступ из кода приложения. То есть — то, на какие переменные имеются ссылки. Если сборщик мусора выясняет, что к какому-то участку памяти больше нет доступа из кода приложения, он освобождает эту память. Вышеописанный подход может быть реализован с помощью двух основных алгоритмов. Первый — это так называемый алгоритм пометок (Mark and Sweep). Он используется в JavaScript. Второй — это подсчёт ссылок (Reference Counting). Он применяется в Python и PHP.
Фазы Mark (пометка) и Sweep (очистка) алгоритма Mark and Sweep
При реализации алгоритма пометок сначала создаётся список корневых узлов, представленных глобальными переменными окружения (в браузере это — объект
window), а затем осуществляется обход полученного дерева от корневых к листовым узлам с пометкой всех встреченных на пути объектов. Память в куче, которая занята непомеченными объектами, освобождается.Утечки памяти в Node.js-приложениях
К настоящему моменту мы разобрали достаточно теоретических понятий, касающихся утечек памяти и сборки мусора. А значит — мы готовы к тому, чтобы посмотреть на то, как всё это выглядит в реальных приложениях. В этом разделе мы напишем Node.js-сервер, в котором есть утечка памяти. Мы попытаемся выявить эту утечку, используя различные инструменты, а потом её устраним.
▍Знакомство с кодом, в котором есть утечка памяти
В демонстрационных целях я написал Express-сервер, у которого есть маршрут с утечкой памяти. Этот сервер мы и будем отлаживать.
const express = require('express')
const app = express();
const port = 3000;
const leaks = [];
app.get('/bloatMyServer', (req, res) => {
const redundantObj = {
memory: "leaked",
joke: "meta"
};
[...Array(10000)].map(i => leaks.push(redundantObj));
res.status(200).send({size: leaks.length})
});
app.listen(port, () => console.log(`Example app listening on port ${port}!`));
Здесь имеется массив
leaks, находящийся за пределами области видимости кода обработки запроса к API. В результате, каждый раз, когда выполняется соответствующий код, в массив просто добавляются новые элементы. Массив при этом никогда не очищается. Так как ссылка на этот массив после выхода из обработчика запроса никуда не девается, сборщик мусора никогда не освобождает занятую им память.▍Вызов утечки памяти
Здесь мы подходим к самому интересному. Написано много статей, рассказывающих о том, как, используя
node --inspect, отлаживать серверные утечки памяти, предварительно завалив сервер запросами с помощью чего-то вроде artillery. Но у такого подхода есть один важный недостаток. Представьте, что у вас есть API-сервер, у которого имеются тысячи конечных точек. Каждая из них принимает множество параметров, от особенностей которых зависит то, какой именно код будет вызван. В результате, в реальных условиях, если разработчик не знает о том, где кроется утечка памяти, ему, чтобы переполнить память, придётся по много раз обращаться к каждому API, используя все возможные комбинации параметров. Как по мне — так сделать это непросто. Решение подобной задачи, правда, облегчается при использовании чего-то вроде goreplay — системы, которая позволяет записывать и «воспроизводить» реальный трафик.Для того чтобы справиться с нашей проблемой, мы собираемся заняться отладкой в продакшне. То есть — мы позволим нашему серверу переполнить память во время его реального использования (по мере того, как он будет получать самые разные запросы к API). А после того, как обнаружим подозрительный рост объёма выделяемой им памяти, займёмся отладкой.
▍Дамп кучи
Для того чтобы разобраться с тем, что такое «дамп кучи», нам сначала надо выяснить смысл понятия «куча». Если описать это понятие максимально просто, то окажется, что куча — это то место, куда попадает всё то, для чего выделяется память. Всё это находится в куче до тех пор, пока сборщик мусора не уберёт из неё всё то, что будет признано ненужным. Дамп кучи — это нечто вроде снимка текущего состояния кучи. Дамп содержит все внутренние переменные и переменные, объявленные программистом. В нём представлена вся память, выделенная в куче на момент получения дампа.
В результате, если бы мы могли как-то сравнить дамп кучи только что запущенного сервера с дампом кучи сервера, работающего уже долго и переполняющего память, то мы смогли бы идентифицировать подозрительные объекты, которые не нужны приложению, но не удаляются сборщиком мусора.
Прежде чем продолжать разговор — поговорим о том, как создавать дампы кучи. Для решения этой задачи мы воспользуемся npm-пакетом heapdump, который позволяет программно получить дамп кучи сервера.
Установим пакет:
npm i heapdump
Внесём в код сервера некоторые изменения, которые позволят нам воспользоваться данным пакетом:
const express = require('express');
const heapdump = require("heapdump");
const app = express();
const port = 3000;
const leaks = [];
app.get('/bloatMyServer', (req, res) => {
const redundantObj = {
memory: "leaked",
joke: "meta"
};
[...Array(10000)].map(i => leaks.push(redundantObj));
res.status(200).send({size: leaks.length})
});
app.get('/heapdump', (req, res) => {
heapdump.writeSnapshot(`heapDump-${Date.now()}.heapsnapshot`, (err, filename) => {
console.log("Heap dump of a bloated server written to", filename);
res.status(200).send({msg: "successfully took a heap dump"})
});
});
app.listen(port, () => {
heapdump.writeSnapshot(`heapDumpAtServerStart.heapsnapshot`, (err, filename) => {
console.log("Heap dump of a fresh server written to", filename);
});
});
Здесь мы воспользовались данным пакетом для получения дампа свежезапущенного сервера. Так же мы создали API
/heapdump, предназначенный для создания кучи при обращении к нему. К этому API мы обратимся в тот момент, когда поймём, что сервер начал потреблять слишком много памяти.Если ваш сервер работает в кластере Kubernetes, то вам не удастся, без дополнительных усилий, обратиться именно к тому поду, сервер, работающий в котором, потребляет слишком много памяти. Для того чтобы это сделать, можно воспользоваться перенаправлением портов. Кроме того, так как у вас не будет доступа к файловой системе, который нужен для загрузки файлов дампов, эти файлы лучше будет выгрузить во внешнее облачное хранилище (вроде S3).
▍Выявление утечки памяти
И вот, сервер развёрнут. Он работает уже несколько дней. К нему поступает множество запросов (в нашем случае — лишь запросы одного вида) и мы обратили внимание на рост объёма памяти, потребляемой сервером. Заметить утечку памяти можно, пользуясь инструментами мониторинга наподобие Express Status Monitor, Clinic, Prometheus. После этого мы вызываем API для создания дампа кучи. Этот дамп будет содержать все объекты, которые не смог удалить сборщик мусора.
Вот как выглядит запрос, позволяющий создать дамп:
curl --location --request GET 'http://localhost:3000/heapdump'
При создании дампа кучи принудительно запускается сборщик мусора. В результате нам не нужно беспокоиться о тех объектах, которые могут быть удалены сборщиком мусора в будущем, но пока находятся в куче. То есть — об объектах, при работе с которыми утечек памяти не происходит.
После того, как в нашем распоряжении окажутся оба дампа (дамп свежезапущенного сервера и дамп сервера, проработавшего некоторое время), мы можем приступить к их сравнению.
Получение дампа памяти — это блокирующая операция, на выполнение которой нужно много памяти. Поэтому выполнять её надо с осторожностью. Подробнее о возможных проблемах, возникающих в ходе этой операции, можно почитать здесь.
Запустим Chrome и нажмём клавишу
F12. Это приведёт к открытию инструментов разработчика. Тут нужно перейти на вкладку Memory и выполнить загрузку обоих снимков памяти.
Загрузка дампов памяти на вкладке Memory инструментов разработчика Chrome
После загрузки обоих снимков нужно изменить
perspective на Comparison и щёлкнуть по снимку памяти сервера, который проработал некоторое время.
Начало сравнения снимков
Здесь мы можем проанализировать столбец
Constructor и поискать объекты, которые не может удалить сборщик мусора. Большая часть таких объектов будет представлена внутренними ссылками, которые используют узлы. Тут полезно воспользоваться одним приёмом, который заключается в сортировке списка по полю Alloc. Size. Это позволит быстро найти объекты, использующие больше всего памяти. Если развернуть блок (array), а затем — (object elements), то можно будет увидеть массив leaks, содержащий огромное количество объектов, которые невозможно удалить с помощью сборщика мусора.
Анализ подозрительного массива
Эта методика позволит нам выйти на массив
leaks и понять, что именно неправильная работа с ним является причиной утечки памяти.▍Исправление утечки памяти
Теперь, когда мы знаем о том, что «виновником торжества» является массив
leaks, мы можем проанализировать код и выяснить, что проблема заключается в том, что массив объявлен за пределами обработчика запроса. В результате оказывается, что ссылка на него никогда не удаляется. Исправить эту проблему довольно просто — достаточно перенести объявление массива в обработчик:app.get('/bloatMyServer', (req, res) => {
const redundantObj = {
memory: "leaked",
joke: "meta"
};
const leaks = [];
[...Array(10000)].map(i => leaks.push(redundantObj));
res.status(200).send({size: leaks.length})
});
Для того чтобы проверить действенность принятых мер, достаточно повторить вышеописанные шаги и снова сравнить снимки кучи.
Итоги
Утечки памяти случаются в разных языках. В частности в — тех, в которых используются механизмы сборки мусора. Например — в JavaScript. Обычно исправить утечку несложно — настоящие сложности возникают лишь при её поиске.
В этом материале вы ознакомились с основами управления памятью, и с тем, как организовано управление памятью в разных языках. Здесь мы воспроизвели реальный сценарий утечки памяти и описали методику поиска и устранения проблемы.
Уважаемые читатели! Сталкивались ли вы с утечками памяти в своих веб-проектах?

