Comments 17
Красивая визуализация для 2017 года moscowmarathon2017.datalaboratory.ru/results?runners=1,18
«данные подтверждают народную молву» — я бы скорее сказал народная молва определяет данные. Четырехчасовой пик обусловлен исключительно социальными причинами.
Механизм такой: мне нравится бегать, но соревноваться уже давно неинтересно.
Чтобы случайно не забить на бег я планирую себе марафон раз в полгода и бегу его на максимальном расслабоне и без нормальной подготовки, целясь на чуть быстрее четырех чтобы было не совсем стыдно. И таких как я — очень много среди регулярных бегунов.
Ну то есть этот график не говорит о том что в среднем хорошо пробежать из 4х. Этот график говорит о том что средний бегун думает что не стыдно пробежать из 4х.
Резюмируя хочу сказать что если Вы хотите отталкиваться от среднего уровня способностей а не от чужого мнения, то стоит целиться все таки на слегка побыстрее.
Ну и в заключение хочу подчеркнуть что цель на забег до которого месяц надо выбирать исходя из времени контрольных стартов, а не из статистики. Но я думаю Вы это итак понимаете :)
Механизм такой: мне нравится бегать, но соревноваться уже давно неинтересно.
Чтобы случайно не забить на бег я планирую себе марафон раз в полгода и бегу его на максимальном расслабоне и без нормальной подготовки, целясь на чуть быстрее четырех чтобы было не совсем стыдно. И таких как я — очень много среди регулярных бегунов.
Ну то есть этот график не говорит о том что в среднем хорошо пробежать из 4х. Этот график говорит о том что средний бегун думает что не стыдно пробежать из 4х.
Резюмируя хочу сказать что если Вы хотите отталкиваться от среднего уровня способностей а не от чужого мнения, то стоит целиться все таки на слегка побыстрее.
Ну и в заключение хочу подчеркнуть что цель на забег до которого месяц надо выбирать исходя из времени контрольных стартов, а не из статистики. Но я думаю Вы это итак понимаете :)
Теперь про «невероятный» разброс в обе стороны — тут тоже ничего странного и он легко объясним. Самая частая ситуация драматического ухудшения результата — это не травмы с болезнями. Это когда в одном сезоне у тебя этот старт целевой, а в следующем ты его уже бежишь как длительную. Отсюда и ситуации «в 18м добежал, в 19м нет» или «оба раза не добежал». Бежишь до 30го и сходишь, потому что цели финишировать и не стояло.
Плюс есть некоторое количество людей стартующих под чужими слотами, хотя в среднем не оч много.
Ситуации «что-то пошло совсем не так и я финишировал на 40 минут медленнее» разумеется тоже случаются но я предполагаю что их относительно мало
Плюс есть некоторое количество людей стартующих под чужими слотами, хотя в среднем не оч много.
Ситуации «что-то пошло совсем не так и я финишировал на 40 минут медленнее» разумеется тоже случаются но я предполагаю что их относительно мало
Марафон за 4 часа — это просто пробежка на расслабоне с низким темпом. Ну как обычная длительная тренировка, только, для большинства, чуть длинее.
Вы как-то совсем забыли про роль пейсмейкеров. Эти ребята собирают вокруг себя толпу и бегут на «ровный» результат, а пейсер на 4 часа — вообще суперзвезда марафона. Но и вокруг других «ровных» времен должны быть свои пики. И у меня есть ощущение, что в категории >4 часов то ли разные времена для пейсмейкеров были в разные годы, то ли кто-то из пейсов перестарался/наоборот отстал.
Можно посмотреть, за счет каких половозрастных групп прибавилось число участников от года к году.
На средний темп также очень влияет погода. Каждый градус, минимальная разница в облачности и осадках.
Марафон вообще ни на что не похож, если вы, конечно, не бегаете 30+км регулярно.
По всем прикидкам я должен был пробежать свой марафон из 4 часов легко, но было жарко, а опыта столь длинного бега не было. И в итоге первая 20-ка за 1:54, 30-ка за 2:55, а следующие 10км уже за 1:10. Последние 2км скорость была 8-9км/ч, чаще шел чем бежал. Итого 4:20.
На последней десятке работают те мышцы, о которых просто не знаешь. Например, жутко болел пресс, потому что спина отболела и перестала держать еще после 30км. Плюс очень непонятно, что делать с водой и едой.
Можно посмотреть, за счет каких половозрастных групп прибавилось число участников от года к году.
На средний темп также очень влияет погода. Каждый градус, минимальная разница в облачности и осадках.
Марафон вообще ни на что не похож, если вы, конечно, не бегаете 30+км регулярно.
По всем прикидкам я должен был пробежать свой марафон из 4 часов легко, но было жарко, а опыта столь длинного бега не было. И в итоге первая 20-ка за 1:54, 30-ка за 2:55, а следующие 10км уже за 1:10. Последние 2км скорость была 8-9км/ч, чаще шел чем бежал. Итого 4:20.
На последней десятке работают те мышцы, о которых просто не знаешь. Например, жутко болел пресс, потому что спина отболела и перестала держать еще после 30км. Плюс очень непонятно, что делать с водой и едой.
Плюс очень непонятно, что делать с водой и едой.Так есть же пункты питания и гели углеводные.
Пункты есть. Есть или не есть непонятно :) С какого-то момента есть уже неохота совсем. А вот надо или не надо — загадка. С гелями вроде как советуют быть осторожным и тоже тренировать организм на них, если начать их принимать уже в гонке возможны сюрпризы. С водой тоже советуют не перебарщивать, бывали случаи, что бегуны перебирали с водой и в обморок грохались. Сколько для этого ее надо выпить не сообщается.
Скажу как марафонец-любитель со стажем.
Все сказанное ниже опробовано на себе и более опытных товарищах.
Есть или не есть, вот в чем вопрос.
Есть! Однозначно. Можно конечно и пренебречь едой, но бежать будет тяжелее и восстановление будет дольше. Тело человека во время марафона испытывает огромные нагрузки и теряется много энергии. Поэтому ему нужна углеводная подпитка. Гели штука специфическая, жкт некоторых людей их не принимает. Поэтому перед серьезным забегом можно потренироваться с ними на длительной тренировке. Но гели дико удобнее долек апельсина, банана на пунктах питания. А на некоторых трейлах, вас и вовсе не пустят на старт без них. Плюс есть выбор вкусов.
Пить или не пить.
Пить! Без этого вам грозит обезвоживание, последствия будут даже хуже, чем при отказе от еды. Но пить не вволю, а просто чтобы слегка приглушить жажду. Если хлебать как конь, то можно и вовсе, что называется «коней двинуть». Потребность каждого человека в воде — сугубо индивидуальна, просто слушайте свой организм и ориентируйтесь на ощущения.
Все сказанное ниже опробовано на себе и более опытных товарищах.
Есть или не есть, вот в чем вопрос.
Есть! Однозначно. Можно конечно и пренебречь едой, но бежать будет тяжелее и восстановление будет дольше. Тело человека во время марафона испытывает огромные нагрузки и теряется много энергии. Поэтому ему нужна углеводная подпитка. Гели штука специфическая, жкт некоторых людей их не принимает. Поэтому перед серьезным забегом можно потренироваться с ними на длительной тренировке. Но гели дико удобнее долек апельсина, банана на пунктах питания. А на некоторых трейлах, вас и вовсе не пустят на старт без них. Плюс есть выбор вкусов.
Пить или не пить.
Пить! Без этого вам грозит обезвоживание, последствия будут даже хуже, чем при отказе от еды. Но пить не вволю, а просто чтобы слегка приглушить жажду. Если хлебать как конь, то можно и вовсе, что называется «коней двинуть». Потребность каждого человека в воде — сугубо индивидуальна, просто слушайте свой организм и ориентируйтесь на ощущения.
Мои попытки анализа данных с Московского марафона — github.com/ligurio/notebooks/tree/master/running/race-analytics
-del-
Отдельное спасибо за парсер и tqdm в нем!
Всегда пожалуйста
Все же немного переписал его, потому как 30 мин для парсинга многовато. Там страница может отдавать сразу по 1000 результатов вместо 10-ти. Время парсинга сокращается с 30 мин до 50 сек:
Можно навесить многопоточность, но здесь вряд ли она даст серьезный прирост по времени )
parser
import requests,csv
from bs4 import BeautifulSoup
from datetime import datetime
#замер времени
start = datetime.now()
def get_html(url):
with requests.Session() as session:
session.headers['Accept'] = 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
session.headers['User-Agent'] = 'Mozilla/5.0 (X11; Linux x86_64; rv:64.0) Gecko/20100101 Firefox/64.0'
r=session.get(url)
if r.status_code==404:
return ('404')
print('404')
else:
#r = requests.get(url)
return r.text
#name,result,place,country,category,temp
def write_csv(data):
f = open('results.txt','a',encoding='utf8',newline='')
f.write(f"{data['name']}\t"
f"{data['result']}\t"
f"{data['place']}\t"
f"{data['country']}\t"
f"{data['category']}\t"
f"{data['temp']}\n")
f.close()
def get_page_data(text):
soup=BeautifulSoup(text,'lxml')
ads = soup.find_all('a',class_='results-table__values')
#name,result,place,country,category,temp
for ad in ads:
try:
name=ad.find('div',class_='results-table__values-item-name').text.strip()
except:
name=''
try:
result=ad.find('div',class_='results-table__values-item text-r results-table__col-result').text.strip()
except:
result=''
try:
place=ad.find('div',class_='results-table__values-item-place').text.strip()
except:
place=''
try:
t=ad.find('div',class_='results-table__values-item-country').text.strip()
country=t.split(',')[0].strip()
category=t.split(',')[1].strip()
except:
country=t.split(',')[0].strip()
category=t.split(',')[1].strip()
try:
temp=ad.find('div',class_='results-table__values-item results-table__col-pace').text.strip()
except:
temp=''
#print(name,result,place,country,category,temp)
data={'name':name,
'result':result,
'place':place,
'country':country,
'category':category,
'temp':temp
}
write_csv(data)
def main():
url='https://results.runc.run/event/absolute_moscow_marathon_2018/finishers/distance/1/page/{}/page_size/1000/'
urls = [url.format(str(i)) for i in range(1, 11)]
#print(urls)
for i in range(len(urls)):
text = get_html(urls[i])
if text=='404': #если ошибка 404 - пропускаем страницу
pass
else:
get_page_data(text)
if __name__ == '__main__':
main()
print(datetime.now()- start)
Можно навесить многопоточность, но здесь вряд ли она даст серьезный прирост по времени )
А как вы время (result) привели к datetime?
При таком формате df['result'] = pd.to_datetime(df.result, format='%H:%M:%S') выдает:
1900-01-01 02:15:22
И часть «1900-01-01» мешает.
Если так:
data['time'] = pd.to_datetime(data['time']).dt.time
то, преобразуется в object вместо datetime64[ns] и графики не строятся правильно.
При таком формате df['result'] = pd.to_datetime(df.result, format='%H:%M:%S') выдает:
1900-01-01 02:15:22
И часть «1900-01-01» мешает.
Если так:
data['time'] = pd.to_datetime(data['time']).dt.time
то, преобразуется в object вместо datetime64[ns] и графики не строятся правильно.
Код на скорую руку, поэтому немного тяп-ляп
df = df[~df.result.isin(["DQ", "DNF"])]
df.reset_index(drop=True, inplace=True)
df['result'] = pd.to_timedelta(df['result'], unit="h")
df['time'] = df['result'].apply(lambda x: x.seconds/60)
df['sex'] = df.category.apply(lambda x: x.strip()[0])
df['age'] = df.category.apply(lambda x: int(x.strip()[1:]))
.apply пишут медленно работает. Убеждался в этом и сам. Но здесь, конечно, не критично.
А от не числовых значений избавился так (это проще, если не знаешь, что еще может встретиться кроме чисел):
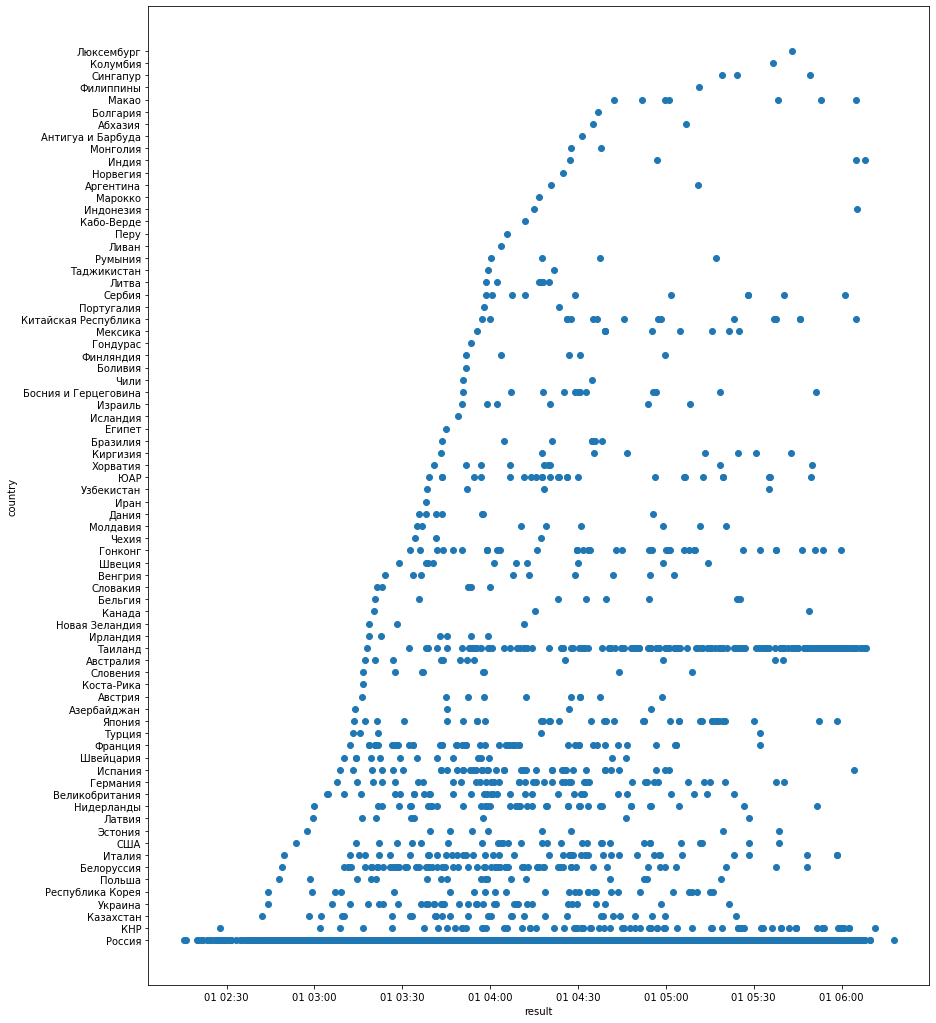
И вот вам еще график, как пробежали по странам за 2018 )
А от не числовых значений избавился так (это проще, если не знаешь, что еще может встретиться кроме чисел):
#выкинем все кроме цифр в строках:
df['result'] = df['result'].str.replace(r'[^0-9:]+', '')
#выкинем дисквалифицированных,т.к. у них теперь Nan
df = df.loc[df['result'] != '']
И вот вам еще график, как пробежали по странам за 2018 )
график

Sign up to leave a comment.
Заметки Дата Сайентиста: как измерить время забега марафона лежа на диване