Comments 535
liquibase хорош, но он решает некоторые проблемы:
- не получится при пулл реквесте сранивать дифы миграций, т.к. liqubase негативно реагирует на изменение файлов старых миграцией, которые уже накатаны в БД (сравнение по хеш-сумме) по этой причине придется для изменения миграции будет создаваьб новый файл, а значит и вся процедура будет в новом файле.
- Также есть проблемы при переключение веток и накатам и откатом миграцией, например:
- мы разрабатываем фичу накатили новые миграции,
- потом нас попросили глянуть баг, мы переключились накатили другие миграции
- вернулись к фиче и хотим миграции фичи откатить
Не стоит думать, что разработчики не знаю об доступных инструментах, просто есть вещи, которые на уровне кода проще делать.
Например код на SQL:
SELECT * FROM tablenameКод на PHP:
<?php
$data = [];
$fh = fopen(__DIR__ . '/data/tablename.csv');
$headers = fgetcsv($fh);
while(($row = fgetcsv($fh)) !== false){
$data[] = array_combine($headers, $row);
}
fclose($fh);
return $data;Каждый инструмент имеет свою специфику применения и исходя из специфики можно подобрать удобный в том или ином случае искусственный пример.
Ваш пример кода на php можно упростить до одной строчки, потому что куча php библиотек из composer это делают за тебя.
Алсо, ваш код для базы неверен. Если это селект внутри хранимки, то мы еще должны нпписать into somevar
А перед этим написать declare и прочую муть-обвязку функции (create or replace, returns, begin, end, $$)
Мне реально интересно, в каком случае хрпнтмка получится компактнее, чем php код.
CREATE PROCEDURE close_doc(p_doc_id INT, type TINYINT)
-- type - 1 закрытие, -1 открытие
BEGIN
-- Нельзя закрывать ЗПС и План производства
@msg := (SELECT raise_error('Документы данного типа нельзя закрывать если есть позиции с не нулевыми количествами.')
FROM t_docs d
INNER JOIN doc_pos dp ON d.id = dp.doc_id
WHERE d.doc_type_id IN (6, 8) -- ЗПС и План производства
AND IFNULL(dp.kol, 0) <> 0
AND d.id = p_doc_id)
;
-- Изменим текущие остатки
INSERT cur_stock (mat_id, org_id, org_id_ur, kol, reserve)
SELECT dp.mat_id, d.org_id_addr, d.org_id_ur
, IFNULL(dp.kol, 0) * -1 * t.credit_type * type kol
, IFNULL(dp.kol, 0) * -1 * IF(t.credit_type = 1, 1, 0) * type reserve
FROM t_docs d
INNER JOIN doc_pos dp ON d.id = dp.doc_id
INNER JOIN doc_types t ON d.doc_type_id = t.id
WHERE d.id = p_doc_id
AND t.credit_type IN (1, -1)
ON DUPLICATE KEY UPDATE cur_stock.kol = cur_stock.kol + IFNULL(dp.kol, 0) * -1 * t.credit_type * type
, cur_stock.reserve = cur_stock.reserve + IFNULL(dp.kol, 0) * -1 * IF(t.credit_type = 1, 1, 0) * type
;
DELETE cur_stock
FROM t_docs d
INNER JOIN doc_pos dp ON d.id = dp.doc_id
INNER JOIN cur_stock ON cur_stock.mat_id = dp.mat_id AND cur_stock.org_id = d.org_id_addr AND cur_stock.org_id_ur = d.org_id_ur
WHERE cur_stock.kol = 0
AND cur_stock.reserve = 0
AND d.id = p_doc_id;
END$
php:
<?php
function close_doc($p_doc_id, $type) {
DB:Statement("
@msg := (SELECT raise_error('Документы данного типа нельзя закрывать если есть позиции с не нулевыми количествами.')
FROM t_docs d
INNER JOIN doc_pos dp ON d.id = dp.doc_id
WHERE d.doc_type_id IN (6, 8) -- ЗПС и План производства
AND IFNULL(dp.kol, 0) <> 0
AND d.id = :p_doc_id)
", ['p_doc_id' => $p_doc_id]);
DB:Statement("
INSERT cur_stock (mat_id, org_id, org_id_ur, kol, reserve)
SELECT dp.mat_id, d.org_id_addr, d.org_id_ur
, IFNULL(dp.kol, 0) * -1 * t.credit_type * :type kol
, IFNULL(dp.kol, 0) * -1 * IF(t.credit_type = 1, 1, 0) * :type reserve
FROM t_docs d
INNER JOIN doc_pos dp ON d.id = dp.doc_id
INNER JOIN doc_types t ON d.doc_type_id = t.id
WHERE d.id = :p_doc_id
AND t.credit_type IN (1, -1)
ON DUPLICATE KEY UPDATE cur_stock.kol = cur_stock.kol + IFNULL(dp.kol, 0) * -1 * t.credit_type * :type
, cur_stock.reserve = cur_stock.reserve + IFNULL(dp.kol, 0) * -1 * IF(t.credit_type = 1, 1, 0) * :type
", ['p_doc_id' => $p_doc_id, 'type' => $type]);
DB:Statement("
DELETE cur_stock
FROM t_docs d
INNER JOIN doc_pos dp ON d.id = dp.doc_id
INNER JOIN cur_stock ON cur_stock.mat_id = dp.mat_id AND cur_stock.org_id = d.org_id_addr AND cur_stock.org_id_ur = d.org_id_ur
WHERE cur_stock.kol = 0
AND cur_stock.reserve = 0
AND d.id = :p_doc_id
", ['p_doc_id' => $p_doc_id]);
}
?>
PHP тут 3 раза отправит строчку в db, которая будет распарсена, составлен план выполнения, результаты сериализованые и десеарилизованны обратно + network latency на туда сюда.
БД все внутри процесса, без внутренних преобразований. Еще и проверит колонки и немножко даже типы на этапе компиляции. Кое где автодополнение от опечаток сразу убережет.
Для PHP надо что-то типа JOOQ хотя бы, чтоб не париться со сроковыми константами
Во-первых не знаю что у вас за БД, у меня ничего не проверяет.
Во-вторых от того что 3 раза строчка будет туда-сюда отправлено RPS типового сервиса изменится примерно на 0%
В-третьих затрат на десериализацию тут нет ибо и ответов особых нет
Не знаю как в РНР, в других ЯП библиотеки позволяют передать в одном вызове несколько запросов.
Парсинг SQL занимает наносекунды, составление плана в случае использования prepared statement также скорее всего берётся из кеша (а если и нет, то затраты на план — величина меньшего порядка, чем собственно выполнение).
В итоге — да, пару десятков мс сэкономить можно, при отсутствии передачи результатов. Стоит ли это усилий? Оптимизация собственно запросов может дать прирост скорости совсем других порядков. Ну а если всё остальное уже супер оптимизировано и всё равно медленно — миллисекунды не спасут, пожалуй, стоит задуматься о horizontal scalability.
Заблуждение. Построение плана сложного запроса требует анализа словаря БД, статистики (а это те же самые запросы к БД и анализ их результатов), выставления блокировки на добавление в список планов (что тормозит все остальные запросы, которые требуют хард-парсинга). Если такой запрос в итоге читает несколько блоков из кеша буферов, то задержки на парсинг будут в разы больше времени чтения.
Но справедливости ради должен сказать, что план запроса можно писать в sql запросе и базе не надо будет его создавать на ходу. Например

Так же есть хорошая статья по оптимизации запросов при помощи плана, включенного в sql
http://www.ibase.ru/files/articles/performance/Firebird%20Optimizer%20-%20ORDER%20vs%20SORT.pdf
В общем суть в том, что базе можно дать план с запросом, а не заставлять ее вычислять его.
Но я сторонник того чтобы все оборачивать в процедуры и по большей части обрабатывать на уровне БД, а не гонять по сети и нагружать веб сервер. Процедуры — это уже скомпилированный оптимизированный элемент внутри БД, он будет быстрее работать и давать уже готовый результат.
Все равно это ерундовые расходны на сколько нибудь реальных БД
Расходы ерундовые, если разработчики позаботились о том, чтобы каждый раз не делался hard_parse.
Я не знаю как в PG, а в Oracle например на идентичный текст запроса может быть одновременно множество планов выполнения, которые используются разными сессиями. Потому что планы зависят не только от текста запроса, но и еще от кучи параметров окружения сессии.
То есть даже использование bind переменных не гарантирует отсутствия повторного hard-parse.
И вот если разработчики об этом не подозревают или вообще используют какой-то кривой генератор SQL который каждый раз новый текст генерит, или литералы, то потом встает вопрос о горизонтальном масштабировании БД, выделении реплик и т.п.
Если же с базой данных работать с умом, то можно прекрасно без этого обходиться гораздо-гораздо дольше.
База данных — сердце любой крупной системы. Оптимизация в ней или в работе с ней может многократно ускорить работу, а отношение к БД как черному ящику с данными, приводит потом к появлению костылей типа самописных кешей и т.п.
Код на пхп тут ничем не лучше, потому что он делает все совершенно тоже самое, только из пхп.
Впрочем волшебные константы имхо это объективная проблема этого подхода. Да и волшебная бизнес логика тоже. Никаких пояснений или чего-то что могло бы помочь понять почему считаем именно так а не иначе.
Вычисления между данными разных типов.
Вот у вас в коде type tinyint. Я уже молчу про имя 'type' ужасное само по себе, да еще и ключевое слово в куче языков. Выходит этот type можно складывать с другими типа без проверок что мухи не сложились с котлетами.
Допустим у меня в базе есть
Коты и Собаки. Я хочу быть уверенным что случайно кто-то их не перемножит, а если перемножит то значит он знает что делает.
В го например это реализуется тривиально
type Dog int
type Cat int
все, теперь компилятор мне подскажет если где-то будет попытка их сложить без явного преобразования.
Еще интересно что если бы это был код на бэкенде, я бы проверил разные граничные условия — ну там select where ничего не вернул, может вывести ошибку. У вас же все это просто проглотится кодом. Для пользователя это обычно «я нажал на кнопку и ничего не случилось». Не самая приятная ситуация.
Я совершенно не умею читать сложные запросы в базах данных, задача проследить логику в таком коде для меня почти невыполнима. Поэтому я не понимаю когда топят за подобные сложные запросы.
Существуют задачи, которые только и решаются написанием сложных запросов. К слову, приведённые выше запросы ни разу не являются сложными — простые DML-ки с JOIN-ами пары таблиц. Реально сложный запрос может занимать пару страниц текста и обычно это не тупо пачка джойнов, а подзапросы, группировки и т.д. Обычно сложность запросов удачно получается ограничить за счет CTE. Заявление вида «я не умею читать сложный SQL» ничем не отличается от любого другого заявления вида «я не умею читать сложный код на %langname%» в плане обсуждаемой статьи.
Что касается типизации — postgresql позволяет заводить типы и можно сделать систему типов, также ограничивающие недопустимые операции, но большинство ошибок, с которыми приходилось сталкиваться, ни разу не связаны с такими проверками (да и не приходилось сталкиваться с проектами, где бы заморачивались введением типов).
Заявление вида «я не умею читать сложный SQL» ничем не отличается от любого другого заявления вида «я не умею читать сложный код на %langname%» в плане обсуждаемой статьи.
И поэтому есть принципы типа KISS, требуют разбивать сложный код на простые атомарные операции и т. п.
CREATE PROCEDURE close_docPHP:
// type - 1 закрытие, -1 открытие
function close_doc(int $p_doc_id, int $type)
{
// Нельзя закрывать ЗПС и План производства
$document = Document::find($p_doc_id)->with(['positions', 'type'])->one();
if (in_array($document->doc_type_id, [DocumentType::ZPS, DocumentType::PLAN_PROIZVODSTVA]) {
$cnt = $document->getPositions()->andWhere(['!=', new DbExpression('IFNULL(kol, 0)'), 0])->count();
if ($cnt > 0) {
throw new BusinessLogicException('Документы данного типа нельзя закрывать если есть позиции с не нулевыми количествами.');
}
}
// Изменим текущие остатки
$curStockList = $document->curStocks;
$newData = [];
foreach ($document->positions as $position) {
$newKol = ($position->kol ?? 0) * -1 * $type; // hack with multiplication by business value, be careful!
$curStock = ($curStockList[$position->mat_id] ?? null);
$newData[] = [
'org_id' => $document->org_id_addr, 'org_id_ur' => $document->org_id_ur, 'mat_id' => $position->mat_id,
'kol' => ($curStock === null ? 0 : $curStock->kol) + $newKol * $document->type->credit_type,
'reserve' => ($curStock === null ? 0 : $curStock->reserve) + $newKol * ($document->type->credit_type === 1 ? 1 : 0),
];
}
Yii::$app->db->queryBuilder->batchReplace(CurStock::tableName(), $newData)->execute();
CurStock::deleteAll([
'org_id' => $document->org_id_addr, 'org_id_ur' => $document->org_id_ur, 'mat_id' => array_column($document->positions, 'mat_id'),
'kol' => 0, 'reserve' => 0,
]);
}SQL: 32 строки, 28 строк логики
PHP: 33 строки, 22 строк логики
Строки логики это строки, которые остаются если убрать пустые строки и строки с закрывающими скобками.
На PHP на четверть меньше кода, при этом практически нет копипасты, в том числе для связи сущностей/таблиц по внешним ключам.
При этом переменные названы полными именами, в отличие от сокращений в SQL.
Наглядно видны взаимосвязи между сущностями — обрабатываются позиции и стоки, связанные с конкретным документом, а в SQL надо проверить джойны и фильтры, чтобы проверить, что это действительно так.
Наглядно видны условия возникновения ошибки, в отличие от хитрого SELECT raise_error(), который срабатывает только если WHERE вернул записи.
Типы документа это константы с говорящими названиями, а не магические значения с пояснениями в комменте.
Доработав ActiveQuery, можно было бы избавиться от задания длинного первичного ключа в deleteAll(), было бы примерно так:
$document->getCurStocks()->andWhere(['kol' => 0, 'reserve' => 0])->delete();Также можно отметить хак с умножением на тип закрытия. Такого обычно не ожидаешь от enum для обозначения бизнес-понятий, поэтому это усложняет понимание и поддержку.
П.С. ещё не нашёл что-то в ActiveRecord batchReplace… ну и такой лапшекод, по мне, просто невозможно поддерживать, тут у нас и ORM с магическими методами и QueryBuilder и тут только одному богу известно какими SQL-выражениями в итоге они станут и куски чистого SQL-я ('IFNULL(kol, 0)')
только работать правильно такой код не будет в многопользовательской системе…
Нормально все будет работать. Последовательный доступ, чтобы никто не поменял позиции во время расчетов, можно обеспечить через SELECT FOR UPDATE и прочими локами. Так же как это делает база при вызове процедуры.
ну ещё он медленнее раз в 5-10
Если это 10 миллисекунд по сравнению с 1 миллисекунд, то в большинстве случаев это неважно. Вряд ли у одного документа миллионы позиций.
ещё не нашёл что-то в ActiveRecord batchReplace
Да, это я по аналогии с batchInsert написал. Его можно самому добавить или имитировать через str_replace('INSERT INTO', 'REPLACE INTO').
ну и такой лапшекод, по мне, просто невозможно поддерживать
Там нет лапшекода, это совершенно обычный нормально структурированный код на PHP. Ничем не отличается от любого другого нормально написанного кода. Возможно вам так кажется из-за переносов строк в разметке Хабра, скопируйте в блокнот и проверьте. Можете открыть какой-нибудь известный компонент для другого фреймворка и сравнить.
тут у нас и ORM с магическими методами и QueryBuilder и тут только одному богу известно какими SQL-выражениями в итоге они станут
Это вам оно неизвестно. Мне например вполне известно — примерно такими же, как в вашем коде, а где-то даже и попроще. А если сомневаетесь, есть специальный метод, чтобы посмотреть сгенерированный SQL. А в интерфейсе еще и отладочная панель со списком отправленных в базу запросов.
QueryBuilder это часть ORM, они работают совместно. Я вам так тоже могу написать — у вас там и SELECT, и JOIN и WHERE, давайте уберем что-нибудь, а то слишком много всего)
и куски чистого SQL-я ('IFNULL(kol, 0)')
Так это недостаток вашей архитектуры, я же ваш пример рефакторил. Это у вас там количество может быть 0 и NULL. Как IFNULL кстати с индексами работает и прочей оптимизацией, не мешает планировщику оптимизировать? Ну и я вообще-то думал, что вы в курсе, что это можно без SQL написать, через OR или AND.
Последовательный доступ, чтобы никто не поменял позиции во время расчетов, можно обеспечить через SELECT FOR UPDATE и прочими локами.
Вот их-то и нету, поэтому будет работать неверно и остатки будут расходиться.
Если это 10 миллисекунд по сравнению с 1 миллисекунд, то в большинстве случаев это неважно. Вряд ли у одного документа миллионы позиций.
БП подразумевает что закрытие документов делается группой людей в определённый интервал времени + таблица остатков довольно конкурентный объект.
Да, это я по аналогии с batchInsert написал. Его можно самому добавить или имитировать через str_replace('INSERT INTO', 'REPLACE INTO').
Т.е. код всё таки не дописанный.
Так это недостаток вашей архитектуры, я же ваш пример рефакторил. Это у вас там количество может быть 0 и NULL. Как IFNULL кстати с индексами работает и прочей оптимизацией, не мешает планировщику оптимизировать?
Это не недостаток архитектуры, поле kol может быть NULL в данной системе. IFNULL никак не мешает оптимизатору, т.к. поле не индексное
Вот их-то и нету, поэтому будет работать неверно и остатки будут расходиться.
Ну так добавить-то это не проблема. Можно вообще это делать централизованно за пределами этой функции. У вас этого кода тоже нет, он находится в движке БД. А тут будет находиться в движке фреймворка или в другом инфраструктурном коде. В этом и плюс обычных языков, можно реализовать нужный функционал, если он не предусмотрен из коробки.
таблица остатков довольно конкурентный объект
Ну так мы же лочим только строки для документа.
Если он настолько конкурентный, что разница в 10 раз играет роль, то у вас система находится на грани производительности, и может упасть при любой дополнительной нагрузке.
Т.е. код всё таки не дописанный.
Дописанный. Допустим, у меня есть проект, где функция batchReplace уже есть, я написал ее один раз и использую везде где нужно. Или библиотеку подключил. Иначе в вашем коде надо считать исходники на C с реализацией IFNULL, INSERT, SELECT и т.д.
поле kol может быть NULL в данной системе.
IFNULL никак не мешает оптимизатору, т.к. поле не индексное
А кешированию или чтению результатов? Просто kol можно с диска прочитать, а тут вычисления.
Ситуация "Количество не указано" выглядит как смешение 2 сценариев обработки и повод для дополнительной нормализации. Но ок, может тут я не прав, и такие ситуации бывают.
Ну так добавить-то это не проблема. Можно вообще это делать централизованно за пределами этой функции. У вас этого кода тоже нет, он находится в движке БД. А тут будет находиться в движке фреймворка или в другом инфраструктурном коде.
Проблема, не проблема, а вот из-за таких горе программистов потом система и разваливается. В тестах работает, для 3х человек работает, а потом опа, остатки-то не правильные, а проблему такого рода ооочень сложно локализовать, пишут процедуры пересчёта остатков, которые пользователи должны периодически запускать. Так, например, в 1С было, в 7ке точно.
Да, за меня лочит данные СУБД. Как говорил Том Кайт:
Если можно, сделай это с помощью одного оператора SQL.
В моём коде СУБД гарантирует консистентность и транзакционность данных.
Притом я так и не понял как за Вас движок фреймворка залочит данные?
Напишите уж код который будет работать идентично моему.
Ну так мы же лочим только строки для документа.
Мда… (см. выше про горе программистов)
Дописанный. Допустим, у меня есть проект, где функция batchReplace уже есть
Ну дак приведите код, который будет работать как мой.
Я так понимаю
$document->curStocks
тоже самописный метод, ОРМ такое не сгенерит, тож приведите его хотя б справочно.
$document->getPositions()
Это, я так понимаю, ОРМ-ный метод, хотя для того чтобы он заработал надо ещё в php модель данных описать и связи…
Проблема, не проблема, а вот из-за таких горе программистов потом система и разваливается.
Мы не обсуждаем горе-программистов. Программисты на обычных языках, представьте себе, тоже знают, что такое транзакции и блокировки.
Напишите уж код который будет работать идентично моему.
Ну дак приведите код, который будет работать как мой.
Разговор был про компактность кода, а не про угадывание требований и их реализацию.
Будет что-то вроде:
Document::find($p_doc_id)->forUpdate()...Если метода forUpdate() нет в стандартном ActiveQuery, его можно самому написать. Это делается один раз.
Я так понимаю $document->curStocks тоже самописный метод
Это виртуальное свойство объекта, при первом обращении вызывается специальный метод, задающий связь сущностей, и заполняет свойство.
class Document
{
public function getCurStocks()
{
return $this->hasMany(CurStock::class, [
'org_id' => 'org_id_addr',
'org_id_ur' => 'org_id_ur',
'mat_id' => $this->getPositions()->select('id')
]);
}
public function getPositions()
{
return $this->hasMany(Position::class, ['doc_id' => 'id']);
}
}hasMany() возвращает объект запроса, который и возвращает данные для заполнения свойства. Это пишется один раз и потом используется везде, где нужно.
Вместо 'mat_id' => $this->getPositions()->select('id') наверно можно viaTable() использовать, но неохота лезть в документацию и разбираться как именно. Также наверно можно через обычный innerJoin() сделать.
$document->getPositions() Это, я так понимаю, ОРМ-ный метод, хотя для того чтобы он заработал надо ещё в php модель данных описать и связи…
Да, только вы связи описываете каждый раз в JOIN, а тут надо описать один раз.
Модель данных в БД тоже нужно описать, это таблицы с полями и их типами.
Да, за меня лочит данные СУБД.
А поясните пожалуйста подробнее, что и по каким критериям лочит база и чем это отличается от выполнения тех же самых запросов в PHP-коде, которые приводили вы? В вашем PHP-коде получается тоже не лочится то что нужно?
Ваш php код не работает так как мой.
Ну так это, насколько я понимаю, обычный лок для транзакции, и открывая транзакцию с нужным уровнем можно добиться того же эффекта. То есть о чем я и говорил — регулируется на уровне вызывающего кода, до вызова close_doc() стартуем транзакцию с нужным уровнем изоляции, да хоть SERIALIZABLE, хотя наверно должно хватить того который по умолчанию. В самой функции ничего не меняется.
$transaction = $db->startTransaction(Transaction::SERIALIZABLE);
$service->close_doc($doc_id, $type);
$transaction->commit();А как будет работать ваш код на PHP, если между INSERT и DELETE кто-то добавит запись с остатком равным 0? Она получается в первом запросе не учтется, а во втором удалится.
Ваш php код не работает так как мой.
Ну раз вы в третий раз повторяете, то и я повторю — разговор был о компактности кода, а не о работе окружающей его инфраструктуры. Тем более что хоть через транзакцию, хоть через forUpdate, новых строк в ней не добавляется.
По-умолчанию, REPEATABLE_READ, его недостаточно чтобы Ваш код отработал корректно, как мой.
Для любого кода я ес-но предполагал транзакцию, как Вы и написали (уровень дефолтный)
А как будет работать ваш код на PHP, если между INSERT и DELETE кто-то добавит запись с остатком равным 0? Она получается в первом запросе не учтется, а во втором удалится.
В моём коде такого не произойдёт, до коммита эти строки будут заблокированы.
разговор был о компактности кода, а не о работе окружающей его инфраструктуры
с FOR UPDATE будет работать, но я так и не увидел финального рабочего варианта. Да и о какой компактности может идти речь, если:
— у меня всего 3 (три(!)) логических оператора в процедуре, у вас куча императивного кода, что и как перебираем, какие циклы открываем, куча переменных и логических шагов
— плюс к этому надо поддерживать какую-то странную структуру называемую «моделью», притом руками, если «модель» разошлась с БД, то никакие инструменты об этом не скажут
— на каждую выборку Вам надо писать магический метод, там где я просто напишу
[INNER | LEFT] JOIN cur_stock ON…
у Вас будут методы, которые роняют производительность системы и закидывают БД запросами
— сам императивный подход выстраивает логику программы таким образом, что нам надо описывать действия и подталкивает на ошибки консистентности и провалов производительности, что мы и видим на примере Вашего кода
SQL подход, напротив, подталкивает к написанию такого кода, который будет выполняться целостно и быстро
Алгоритм на php:
* извлечём данные об остатках (сходим в базу)
* извлечём данные из позиций документа (сходим в базу)
* откроем цикл и медленно посчитаем нужные данные
* выгрузим новые данные в БД
* упс, заблокировать данные забыли, система наелась
Алгоритм на SQL:
* хочу обновить остатки с учётом новых позиций
— Ваш код будет работать в 5-10 раз дольше. С учётом общей нагрузки системы, если каждую процедуру переписать на php таким же образом, то система оч быстро превратиться в тыкву.
Скажем 400-600 документов по 70-150 позиций, 10 операторов начинают закрывать + в этот момент блочатся остатки даже на чтение…
Мда… не взлетит, не будет работать
Ну и я так и не увидел финальный рабочий код.
Кста, у меня тут ещё от дедлоков нет защиты, по хорошему бы дописать, но код и так быстрый, поэтому было не трэба.
Ваш код будет работать в 5-10 раз дольше.
я бы явно упомянул про такую вещь: вариант с несколькими запросами дольше просто потому, что запросов несколько, каждый из них требует заметное время на исполнение (IPC, а то и RPC) и выполняются они последовательно. как результат: блокировка будет висеть дольше.
на нагруженной системе это может привести к снежному кому блокировок.
в реальной жизни приложуха станет тыквой
Знаю, поэтому и написал "да хоть".
Для любого кода я ес-но предполагал транзакцию, как Вы и написали
Ну то есть у вас за пределами PHP кода работают какие-то механизмы, которые обеспечивают консистентность данных. Что ж вы от меня их требуете?
Я увидел, что в приведенном коде между DB:Statement('INSERT') и DB:Statement('DELETE') согласованность не обеспечивается, и предположил, что механизмы согласованности подразумеваются по умолчанию, и мы сравниваем только выразительность логики.
с FOR UPDATE будет работать, но я так и не увидел финального рабочего варианта
Ну и я так и не увидел финальный рабочий код.
Я не знаю ни ТЗ, ни CREATE TABLE, ни какие источники в каких сценариях пишут в эти таблицы. Приводите конкретный пример того, какую ситуацию мы предотвращаем. А то я уже сделал предположения, а вам они не нравятся.
Да и о какой компактности может идти речь
SQL: 32 строки, 28 строк логики
PHP: 33 строки, 22 строк логики
всего 3 (три(!)) логических оператора в процедуре
Если вы INSERT + SELECT + JOIN + WHERE считаете за 1 логический оператор, то тогда в PHP за 1 логический оператор будем считать блок кода между фигурными скобками. Тогда у меня 1 логический оператор.
А еще можно сделать, чтобы все функции возвращали bool при успешном выполнении и результат через аргументы по ссылке, тогда их можно будет соединить через &&. Тоже один логический оператор получается.
Прекращайте уже логические манипуляции.
у вас куча императивного кода
А у вас куча декларативного. Причем больше, чем императивного в PHP.
что и как перебираем, какие циклы открываем, куча переменных и логических шагов
Перебираем те же данные, что и у вас. Цикл там один. Переменных аж целых 4 штуки, уж куча так куча, причем $curStockList можно убрать, она осталась от предыдущего варианта кода. Вот кстати еще на одну строку меньше. А $newData в вашем коде тоже присутствует в неявном виде, и при изучении кода ее надо держать в голове, называется она "результат SELECT". Да в общем-то количество неподходящих записей и документ из таблицы t_docs тоже есть в неявном виде. Это минус вашего варианта, а не плюс.
А у вас какие таблицы читаем, по каким полям джойним, хотя они всегда одни и те же, и куча копипасты. А логические шаги, представьте себе, у нас одинаковые, потому что это один и тот же алгоритм, написанный на разных языках.
плюс к этому надо поддерживать какую-то странную структуру называемую «моделью»
А вам в БД таблицы поддерживать не надо, они там сами по себе появляются и изменяются?
если «модель» разошлась с БД
Так не надо лезть в продакшн БД руками помимо кода. Все изменения только через код. Так же как в вашем подходе не надо лезть в файлы БД шестнадцатиричным редактором.
на каждую выборку Вам надо писать магический метод, там где я просто напишу INNER JOIN
Это ложь. Я специально написал "Это пишется один раз и потом используется везде, где нужно". Это вы везде пишете INNER JOIN по одним и тем же полям, а здесь поля для связи описываются в однм месте. Не на каждую выборку отдельно, на все сразу, то есть используются в любых выборках, где нужен этот джойн.
В базе аналогично было бы следующее — описываем FOREIGN KEY с названием positions и потом ссылаемся на него FROM t_docs INNER JOIN doc_pos USING positions без всяких ON. Но такого пока нигде не сделали.
и закидывают БД запросами
Это тоже ложь. Методы сами не отправлют запрос в БД, они используются в запросах в вызывающем коде, и дополнительные подзапросы в них тоже сами не добавляют, если это не сделано специально вручную. Они просто описывают связь между таблицами, как FOREIGN KEY в базе.
что мы и видим на примере Вашего кода
Не видим. Потому что я это банально не написал. Потому что предполагал, что мы обсуждаем компактность кода.
SQL подход, напротив, подталкивает к написанию такого кода, который будет выполняться целостно и быстро
Нет, SQL выполняется целостно потому что в базе есть механизмы обеспечения целостности. К синтаксису SQL и компактности кода это не имеет никакого отношения.
Алгоритм на SQL:
хочу обновить остатки с учётом новых позиций
Перестаньте использовать логические манипуляции.
Алгоритм на SQL:
— Выбрать поднять ошибку. Непонятно, как это переводится на нормальный язык. Ой, оно же еще не всегда срабатывает, и вообще срабатывать не должно.
— Выбрать из таблицы t_docs, соединить с таблицей doc_pos через поля id и doc_id, соединить с таблицей doc_types через поля doc_type_id и id.
— Вставить результат в cur_stock.
— Удалить из таблицы cur_stock, соединить t_docs с таблицей doc_pos через поля id и doc_id, соединить с таблицей cur_stock через поля mat_id и mat_id, org_id и org_id, org_id_ur и org_id_ur, там где количество равно 0. Ой, там же во втором наборе полей для cur_stock не org_id, а org_id_addr.
если каждую процедуру переписать на php таким же образом, то система оч быстро превратиться в тыкву.
Да, много у кого работают нагруженные приложения на PHP, а они и не знают, что у них система в тыкву превратилась.
Скажем 400-600 документов по 70-150 позиций, 10 операторов начинают закрывать
Это не выглядит как большая нагрузка. В интернет-магазинах на PHP тысячи товаров в базе, десятки в корзинах, и миллионы пользователей, которые это покупают. И остатки там тоже отслеживаются.
Ну то есть у вас за пределами PHP кода работают какие-то механизмы, которые обеспечивают консистентность данных. Что ж вы от меня их требуете?
Я увидел, что в приведенном коде между DB:Statement('INSERT') и DB:Statement('DELETE') согласованность не обеспечивается, и предположил, что механизмы согласованности подразумеваются по умолчанию, и мы сравниваем только выразительность логики.
Нет, нет, я говорю совсем о другом.
И Ваш и мой код обеспечивается транзакцией (стандартной, REPEATABLE_READ), но Ваш код не работает как мой.
Т.е. и Ваш и мой код выглядит так:
START TRANSACTION;
<ВАШ_КОД>
COMMIT;
START TRANSACTION;
<МОЙ_КОД>
COMMIT;
Но Ваш код не работает так как мой код.
Нет, нет, я говорю совсем о другом.
И Ваш и мой код обеспечивается транзакцией
Я понял, но дело не в этом. Я говорю о том, что кроме приведенного кода есть другой код, который мы подразумеваем. Я подразумевал чуть больше, чем вы.
Раз вы пример ситуации не привели, снова сделаю предположение. В разных документах могут быть одинаковые mat_id, поэтому блокировки через FOR UPDATE по документу недостаточно, надо добавлять блокировку по mat_id.
- $document = Document::find($p_doc_id)->with(['positions', 'type'])->one();
+ $document = Document::find($p_doc_id)->forUpdate()->with(['positions', 'type'])->one();
- $curStockList = $document->curStocks;
+ $curStockList = $document->getCurStocks()->forUpdate()->all();То есть в таблице cur_stocks заблокируются записи по условию [org_id, org_id_ur, mat_id = [список]). Тогда мой код должен работать так, как ваш.
Поменяются 2 строки, новых строк не добавится.
я обновил код до 20 строк в соседней ветке
Зато потеряли begin/end и пару комментов. Если в моем коде так сделать, будет 17 строк.
WHEN MATCHED AND (s.kol + d.kol = 0 AND s.reserve + d.reserve = 0) THEN DELETEА это выглядит как потенциальный баг, когда одно количество положительное, а другое равное ему отрицательное. У вас при вставке умножается на -1, значит это возможно.
А это выглядит как потенциальный баг
А нет, не выглядит, это же выражение для ситуации до внесения изменений. Зато это дополнительный аргумент про сложность понимания и поддержки кода.
Вот именно про это я и говорил, когда горе программистов упоминал. А в моём случае, исключив императивный код, такой проблемы просто не возникало. Если можно, сделай это с помощью одного оператора SQL.
Ну и сейчас хоть Ваш код и соответствует моему, но работает очень медленно и в реальности не жизнеспособен.
Ещё BatchReplace я так и не увидел
Наконец-то Вы нужные FOR UPDATE'ы написали.
Ну так я бы написал их раньше, если бы вы отвечали на мои вопросы. А то вы требуете у меня, чтобы я догадался, что вы имеете в виду. Это вы знаете, что у вас есть в базе, что оно моделирует, и что в каком порядке вызывается, а для меня это просто какие-то таблицы и поля.
А в моём случае, исключив императивный код, такой проблемы просто не возникало.
Оно не возникало потому что в базе есть отдельно реализованные механизмы блокировки, а не из-за декларативности кода. Если бы вместо SQL можно было скрипты на python писать, движок бы все равно мог отслеживать используемые таблицы и блокировать нужные записи.
но работает очень медленно и в реальности не жизнеспособен.
Повторю, в сотнях интернет-магазинов на PHP логика написана в коде, остатки там отслеживаются, и все это работает нормально и достаточно быстро.
Ещё BatchReplace я так и не увидел
Зачем он вам, это библиотечный код, только в конце будет REPLACE вместо INSERT. В таком случае с вас исходники реализации INSERT INTO, будем их тоже учитывать.
Ну так я бы написал их раньше, если бы вы отвечали на мои вопросы. А то вы требуете у меня, чтобы я догадался, что вы имеете в виду. Это вы знаете, что у вас есть в базе, что оно моделирует, и что в каком порядке вызывается, а для меня это просто какие-то таблицы и поля.
На какие вопросы? Какие поля, какие таблицы? Я Вам привёл код, 3 оператора SQL, Вы попытались их повторить на php, получилось, но далеко не с первого раза и производительность и качество кода оставляет желать лучшего.
На какие вопросы?
"А поясните пожалуйста подробнее, что и по каким критериям лочит база и чем это отличается от выполнения тех же самых запросов в PHP-коде, которые приводили вы?"
"Приводите конкретный пример того, какую ситуацию мы предотвращаем."
но далеко не с первого раза
С первого. Потому что изначально речь шла про компактность, а требование "покажите блокировки" вы придумали потом. При этом сначала вы изложили его в виде "сделайте чтобы он работал так же как мой", не пояснив, как именно "так же", и про блокировки мне пришлось догадываться самому, а потом не объяснили, какие блокировки вам нужны, а какие подразумеваются, что мне тоже пришлось угадывать.
производительность и качество кода оставляет желать лучшего.
Производительность в 10 миллисекунд меня устраивает, даже если в вашем варианте 1 миллисекунда. Причем я даже не уверен, что будет сильно большая разница, так как за счет одинаковых селектов будет лучше работать кеширование самой базы. Условно, менеджер сначала открыл страницу с документом, там отобразились его позиции, потом нажал кнопку "закрыть документ", и тот же запрос выполнился для получения позиций при обработке. Но это надо замерять на практике.
В моем понимании качество кода низкое в вашем примере, в первую очередь из-за копипасты, подробнее я писал в первом же комментарии. То, что там перечислено, считается признаками плохого кода в обычных языках программирования.
Ну и не будет Ваш код работать 10мс, в реальных условиях
Слушайте, ну я не знаю, как еще по-другому вам написать. Я намеренно не писал в этом коде никакие блокировки и транзакции. Потому что разговора про это не было.
И засыпетесь на дефолтных во многих случаях настройках, когда каждая команда автоматически заворачивается в транзакцию, если нет явного начала...
Транзакцию я всегда всегда предполагаю от начала запроса.
А это иллюстрация того, что у всех разные "предположения", и их неплохо бы озвучивать, если вы хотите сравнивать поведение.
Зачем я должен задавать вопросы, если они уже были заданы? Вы привели свой пример в качестве ответа на вопрос "в каком случае хранимка получится компактнее, чем php код". Лично вас никто об этом не просил, вы сами вызвались.
Что я должен был объяснять?
Вы не должны были ничего объяснять, вы должны были не требовать показать блокировки, так как вопрос был про компактность. Сами начали спорить про компактность, а от меня почему-то блокировки потребовали. Вы подразумевали работающие транзакции, а я подразумевал работающие транзакции и блокировки. Почему вам можно что-то подразумевать, а мне нельзя?
Мой код без сайд эффектов, и SQL, и php
В вашем коде на PHP нет вызова START TRANSACTION, поэтому правильность поведения между INSERT и DELETE не гарантируется, так же как и между SELECT raise_error и SELECT данных для INSERT. Вы ее просто подразумевали. В вашем коде нет гарантии консистентности данных между INSERT и DELETE, в моем еще и между SELECT и INSERT.
а Вы попытались повторить, не получилось
Получилось. Вы хотели показать, что код на хранимках компактнее, а оказалось, что мой код на PHP компактнее вашего на SQL.
Ну и далее по пунктам:
1. ваш код не компактнее
2. + ещё должен быть какой-то самописный код batchReplace
3. почему то в свой код Вы не включили getPositions, getCurstock
4. декларация моделей
5. Ваш код работает существенно медленнее моего поэтому его невозможно применить в реальных условиях
Ну в принципе да, если забить на целостность данных, на производительность, на простоту поддержки, забыть про то, чтобы код работал надо поддерживать модели, на каждый джоин и каждую выборку надо написать свой магический метод, то да Ваш код можно назвать более «компактным»
Ваш код работает существенно медленнее моего поэтому его невозможно применить в реальных условиях
Это утверждение нуждается в доказательстве.
Ну в принципе да, если забить на [...] на простоту поддержки
Есть мнение, что код на PHP как раз проще в поддержке для того, кто его написал, чем ваш код на SQL.
Это утверждение нуждается в доказательстве.
Подготовьте рабочий php код. Если готовы, то я готов подготовить тестовые данные.
Неа. Вы утверждение сделали, вам и доказывать.
Подождите, вы же уже сделали утверждение, хотя кода у вас нет. Ну вот уже и доказывайте.
Какой-то у Вас не конструктив, а упражнения в софистике… ))
Какой-то у Вас не конструктив, а упражнения в софистике…
Я просто считаю утверждения "Ваш код работает существенно медленнее моего поэтому его невозможно применить в реальных условиях" без конкретных цифр — неконструктивными.
Экспертное мнение.
Ну вот мое "экспертное мнение" состоит в том, что при выносе логики из SQL скорость падает, конечно, но не настолько, чтобы было "невозможно применить в реальных условиях". В конце концов, у меня тут под боком энтерпрайз-приложение, тысячи реальных установок, логика на application-сервере, и работает.
Дело же не в том, что медленнее. Дело в том, насколько медленнее.
Насколько я понял, мнение michael_vostrikov приблизительно такое же.
Да, все верно.
— существенно более производительна, а значит
— гораздо дольше времени не требует горизонтального масштабирования, следовательно
— требует меньше ресурсов на администрирование
— содержит меньше кода
— содержит меньше ошибок (пример выше, забыли написать FOR UPDATE, данные поплыли)
— ну и как следствие, проще разрабатывать и поддерживать, требуется меньше разработчиков
В общем использование фич СУБД, существенно упрощает разработку, нежели пытаться изобретать велосипеды и писать всё это вручную.
michael_vostrikov, Михаил, ну добейте тогда уж код до состояния, чтобы мы могли сравнить производительность
А мой опыт говорит о том, что если то же самое реализовать на SQL, то система в целом:
А, простите, какой у вас опыт разработки крупных систем вне SQL?
Потому что мой опыт прямо противоречит вашему, и что мы будем с этим делать?
и что мы будем с этим делать?
Ну мы с Михаилом договорились рассмотреть на каком-нть примере. В принципе этот пример, о котором сейчас дискутируем вполне подходит. В него ещё включить, то что мы с ним уже рассматривали: получение списка товаров с ценами + добавить в него еще немного реальных условий
переписывал несколько систем на SQL, т.к. системы не справлялись с нагрузкой и были очень сложны в поддержке
Ну вот я переписывал несколько систем с SQL, потому что стоимость поддержки и количество ошибок были избыточными. При переходе на application стоимость поддержки (и развития) уменьшилась, а производительность не упала.
то у Вас должны были быть фор апдейты чтобы код работал так как мой
Вот когда я понял, что вы подразумеваете под "так как мой", я их написал. А то транзакции вы подразумеваете, а другие механизмы нет, поди разберись.
ваш код не компактнее
Компактнее. Там меньше строк кода, цифры я приводил.
ещё должен быть какой-то самописный код batchReplace
А у вас должен быть реализован INSERT INTO. Он у вас уже есть в базе? А у меня уже есть batchReplace в приложении, я просто подключил нужную библиотеку.
почему то в свой код Вы не включили getPositions, getCurstock
Я уже несколько раз повторил почему — потому что они описываются один раз и используются в любых джойнах этих таблиц. Вы вот почему-то CREATE TABLE и FOREIGN KEY не включили.
декларация моделей
А у вас декларация таблиц.
Ваш код работает существенно медленнее моего поэтому его невозможно применить в реальных условиях
Недоказанное утверждение про "существенно" и "невозможно". Аналогичный код работает во многих приложениях. Вы говорили про 10 одновременно работающих операторов, это довольно мало. Возможно у вас это серьезная нагрузка потому что база занята выполнением логики. Тут вот пишут про несколько сотен запросов на страницу для Drupal, тут для Magento получилось уменьшить с 2000 до 270+, это популярные продукты, которые много где используются. Правда там наверно селекты в основном.
если забить на целостность данных
С нужными forUpdate() ничего не надо забивать, количество строк кода от них не меняется.
чтобы код работал надо поддерживать модели
А чтобы ваш код работал, надо поддерживать таблицы. Почему таблицы поддерживать можно, а модели нельзя?
на каждый джоин и каждую выборку надо написать свой магический метод
Я не знаю, почему вы так решили, но если вам нравится верить в эти выдумки, дело ваше. Фактов это не меняет. Как я уже писал в другом комментарии, на любой FOREIGN KEY магический метод пишется один раз, а не на каждый джойн и выборку.
А у вас декларация таблиц.
А у Вас таблицы сами появляются?
Вы вот почему-то CREATE TABLE и FOREIGN KEY не включили.
Потому что CREATE TABLE и FOREIGN KEY в Вашем и в моём коде будут идентичные.
Почему таблицы поддерживать можно, а модели нельзя?
Вам надо поддерживать и модели, и таблицы. Ещё и руками следить за соответствием моделей и таблиц.
А у Вас таблицы сами появляются?
Таблицы вполне могут создаваться из моделей. EF CodeFirst, вот это всё.
Потому что CREATE TABLE и FOREIGN KEY в Вашем и в моём коде будут идентичные.
Не обязательно.
Вам надо поддерживать и модели, и таблицы. Ещё и руками следить за соответствием моделей и таблиц.
Еще раз: code-first development. Структура описывается в коде, из кода генерится БД, из кода генерятся запросы. Никто БД руками не трогает.
А у Вас таблицы сами появляются?
Таблицы в базе задаются и изменяются через механизм миграций, миграция это код на PHP.
Потому что CREATE TABLE и FOREIGN KEY в Вашем и в моём коде будут идентичные.
Вы свой код написали до того, как я написал свой. При этом по каким-то причинам не включили туда объявления таблиц и внешних ключей. Вот я не включил объявление классов моделей AR и связей между ними в свой код по тем же причинам.
Вам надо поддерживать и модели, и таблицы. Ещё и руками следить за соответствием моделей и таблиц.
Прекращайте уже делать недоказанные утверждения, если не знаете, как разрабатываются приложения с логикой в коде) Изменения делаются через механизм миграций, руками в базу никто не лазит. Они же гарантируют идентичность dev, test и prod базы.
А еще, представьте себе, в случае SPA на фронтенде в JavaScript снова эти же классы описаны — пользователь, заказ и т.д. И на это тоже есть обоснованные причины.
Прекращайте уже делать недоказанные утверждения, если не знаете, как разрабатываются приложения с логикой в коде) Изменения делаются через механизм миграций, руками в базу никто не лазит. Они же гарантируют идентичность dev, test и prod базы.
Я предполагал следующее: и у меня и у Вас механизм миграций создаёт таблицы в БД. А модели у Вас сами обновляются после миграций?
Давайте уже финальный код допилите, я могу тестовые данные подготовить. Мы ж с Вами хотели попробовать что-то подобное сделать, вот давайте это пример и добьём до конца.
Я предполагал следующее: и у меня и у Вас механизм миграций создаёт таблицы в БД. А модели у Вас сами обновляются после миграций?
Вы, простите за прямой вопрос, так и не поняли, что миграции получаются из моделей?
В Yii надо поменять модель и написать миграцию. Вернее, список полей модели берется из БД, поэтому "поменять модель" означает обычно "обновить коммент с PHPDoc, чтобы PHPStorm нужные подсказки генерировал". В Symfony кажется схема генерируется из описания модели. В любом случае руками следить не надо, запустил yii migrate up, и все отсутствующие миграции накатились.
Мы ж с Вами хотели попробовать что-то подобное сделать
Давайте, через пару дней выложу.
Точнее так работает Doctrine, которая является ORM по умолчанию в Symfony. Но её можно подключать и к Laravel, например. И, если ничего не путаю, то Yii3 будет е' поддерживать из коробки как одну из опций.
Например, у меня есть 2 миграции
Миграция 1:
CREATE TABLE users (
id INT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT
, name VARCHAR(191) NOT NULL
)Миграция 2:
ALTER TABLE users
ADD email VARCHAR(191) UNIQUEЧто было в ОРМ модели в момент первой миграции и как надо изменить ОРМ модель чтобы получилась вторая миграци? И как мне ролбекнуть 2ю миграцию?
class InitialMigration : Migration {
public void Up(MigrationBuilder migrationBuilder) {
migrationBuilder.AddColumn<int>(
name: "id",
table: "users")
.HasDatabaseGeneratedOption(
DatabaseGeneratedOption.Identity);
migrationBuilder.AddColumn<string>(
name: "name",
table: "users",
sqlType: "VARCHAR(191)");
}
}
class FirstMigration : Migration {
public void Up(MigrationBuilder migrationBuilder) {
migrationBuilder.AddColumn<string>(
name: "email",
table: "users",
sqlType: "VARCHAR(191)",
unique: true);
}
public void Down(MigrationBuilder migrationBuilder) {
migrationBuilder.DropColumn<string>("users", "email")
}
}в ОРМ ничего нет, это код. Стейт весь хранится в БД. Когда код подключается, он видит какие миграции из тех что есть в БД отсутствуют в коде, и в зависимости от настроек докатывают обновления или выдают ошибку что состояние БД неожиданное
Как работать с миграциями дальше очевидно, если нет то вот небольшая дока: https://docs.microsoft.com/en-us/ef/core/managing-schemas/migrations/applying?tabs=dotnet-core-cli#command-line-tools
Было
/**
* @ORM/Entity
* @ORM/Table("users")
*/
class User
{
/**
* @ORM/Id
* @ORM/Column(type="integer")
* @ORM/GeneratedValue
*/
private int $id;
/**
* @ORM/Column(type="string", length="191")
*/
private string $name;
}стало
/**
* @ORM/Entity
* @ORM/Table("users")
*/
class User
{
/**
* @ORM/Id
* @ORM/Column(type="integer")
* @ORM/GeneratedValue
*/
private int $id;
/**
* @ORM/Column(type="string", length="191")
*/
private string $name;
/**
* @ORM/Column(type="string", length="191", unique="true", nullable="true")
*/
private string $email;
}Дальше можно запустить просто обновление схемы БД (не очень подходит для продакшена) — вычислит дифф и запустит ALTER TABLE, а можно запустить генерацию миграции, которая завернёт этот ALTER TABLE в PHP-код в up методе, а также сгенерирует обратный в down
Маппинг можно задавать аннотациями, как в примере, можно в XML, YAML и просто PHP-кодом "собрать".
В принципе Doctrine2 можно считать портом на PHP Hibernate из Java
* ORM/Column(type=«string», length=«255», unique=«true», nullable=«true»)
и мне сгенериться
ALTER TABLE users MODIFY email VARCHAR(255)
-- MIGRATION_ROLLBACK
ALTER TABLE users MODIFY email VARCHAR(191)
?
страшно как-то в каментах прогать… если конечно можно в XML, YAML, PHP то лучше…
А составные и/или DESC индексы как в модели декларируются?
а если что-нть посложнее надо, то тоже в модели делается?
ALTER TABLE users
ADD phone VARCHAR(30)
, ADD phone_clean VARCHAR(11) GENERATED ALWAYS AS (REGEXP_REPLACE(phone, '[^0-9]', '')) VIRTUAL
, ADD CONSTRAINT phone_chk CHECK (phone_clean IS NULL OR CHAR_LENGTH(phone_clean) = 11)
, ADD UNIQUE KEY users_phone_clean_uk (phone_clean)
Или такое уже не по фэншую создавать в базе? И поле phone_clean создаётся и поддерживается руками?
А, например, гео-поля и индексы как?
ALTER TABLE geo_objects
ADD geo_point POINT GENERATED ALWAYS AS (ST_SRID(POINT(lng, lat)), 4326)) STORED NOT NULL SRID 4326
, ADD SPATIAL INDEX (geo_point)
Да, сгенерятся ALTER TABLE users MODIFY email
Индексы всякие как параметры @Table задаются, например
@Table(name="ecommerce_products",indexes={@Index(name="search_idx", columns={"name", "email"}, options={"where": "(((id IS NOT NULL) AND (name IS NULL)) AND (email IS NULL))"})})
CHECK к @Column
Генерированные поля из коробки только по именованным sequence из сложного.
Геополей из коробки вроде нет, но делаются кастомные достаточно легко: https://www.doctrine-project.org/projects/doctrine-orm/en/2.7/cookbook/advanced-field-value-conversion-using-custom-mapping-types.html#the-mapping-type
1. уродливый синтаксис, который нужно знать
2. не предоставляет всех возможностей SQL
3. некоторый возможности предоставляет с дополнительным шаманством
4. PsyHaSTe ниже написал, что иногда в миграции надо ещё и руками залезать, подправлять
5. в итоге всё равно получаем SQL, который в БД выполняется
6. после добавления поля в модель ещё миграцию не забыть сгенерировать
7. а в итоге экономии то никакой и нет
Я пишу:
ALTER TABLE users ADD email VARCHAR(191) UNIQUE
-- MIGRATION_ROLLBACK
ALTER TABLE users DROP email
Вы пишите:
/**
* @ORM/Column(type="string", length="191", unique="true", nullable="true")
*/
private string $email;
Притом по кол-ву символов (которые так любит Михаил считать))) в SQL даже меньше.
Вот только ваши миграции не дают возможности увидеть итоговую схему БД, а модель в ORM — даёт.
Вам не кажется, что всё это дико напоминает велосипед с квадратными колёсами, который чтобы ехал надо ещё и уметь толкать:
Неа, не кажется. "Наша" задача — работать с СУБД из удобного нам языка программирования. ORM (не важно, тяжелый или легкий) и миграции — это достаточно удобный (не идеальный, нет) способ это делать. Взамен мы получаем всего ничего — всю функциональность удобного нам языка программирования, и, что более важно, его среды выполнения и среды разработки.
«Наша» задача — работать с СУБД из удобного нам языка программирования
Но ведь все равно приходится из другого языка отправлять SQL-запросы!
Или у вас библиотека позволяющая не знать SQL?
Или у вас библиотека позволяющая не знать SQL?
Именно. У нас есть инструмент, позволяющий для подавляющего большинства случаев не знать SQL.
Да, есть у нас такая библиотека, даже несколько: Linq2SQL, Linq2DB, Entity Framework, EF Core...
И как там сделать триггер?
Можно пару-тройку примеров, того как в этих библиотеках выглядит аналог джойна?
Джойнов там стараются избегать, потому что джойн обычно представляется коллекций связанных объектов. Так, в примере выше o.Lines — это строки заказа, то, что вы в РСУБД вы бы выражали через Orders JOIN OrderLines. Но если очень надо, то
orders.Join(customers, o => o.CustomerId, c => c.Id)И как там сделать триггер?
Никак. Триггеры — это логика на стороне БД, то есть то, чего мы явно хотим избежать.
Джойнов там стараются избегать, потому что джойн обычно представляется коллекций связанных объектов
Представим, что:
— у нас есть легаси: джойн plsql
— и есть легаси: триггер plsql
— а мы хотим всё это переписать на php или java-script и с использованием библиотек не требующих знания SQL
как это сделать?
Речь не о проектировании всей базы с нуля с новой архитектурой, а о том, чтобы переписать по частям всю живую базу.
как это сделать?
Легаси-джойны вас не волнуют, потому что вы все равно можете моделировать отношения в ORM. Если джойн слишком сложный (настолько сложный, что отношения не справляются), придется написать хелперный метод, который опирается на базовый джойн фреймворка, который я тоже показал выше.
Легаси-триггеры вы не описываете никак. Вы просто их используете вплоть до того момента, пока не готовы их убить и переписать как часть application-сервера.
Если у нас уже есть унаследованная архитектура с бизнес-логикой в СУБД — значит, мы не можем использовать подходы, предназначенные для архитектур с бизнес-логикой в коде. Кажется, всем кроме вас это очевидно.
Впрочем, это не означает что ORM в такой ситуации совсем бесполезна.
у нас есть легаси: джойн plsql
При переписывании на ORM он может либо исчезнуть, либо так и остаться джойном.
и есть легаси: триггер plsql
Он так и останется в базе пока его не заменят на что-то другое. ORM же не обязательно про него знать чтобы он работал.
С джойнами тут на любителя. Я лично активно стараюсь указать ORM, чтобы она сгенерировала JOIN там где нужно по логике, а не "джойнить" руками.
А аналоги триггеров — событийная модель или хуки, в том числе ORM часто их поддерживают"из коробки"
у нас есть легаси: джойн plsql
и есть легаси: триггер plsql
а мы хотим всё это переписать на php
как это сделать?
Вместо JOIN в ORM будут 2 запроса, основной и с WHERE id IN. Если джойн нужен для сортировки, то можно и джойн сделать.
MainEntity::find()->with('relationName')->all();
MainEntity::find()->join('relationName')->all();Поля для ON берутся из описания связи relationName.
Триггер в PHP будет вызовом обычной функции из другой функции.
function registerUser()
{
$user = new User();
$user->load($data);
$user->save();
$this->sendRegistrationEmail(); // действие после INSERT
}Аналог джойна тут в комментариях уже несколько раз приводили.
Что же до триггеров — то они не нужны если не ставить СУБД в центр архитектуры.
Смесь из ORM, QueryBuilder'а, SQL'я
Взамен куча оверхэда, ошибки, малопроизводительный и трудноподдерживаемый код.
Нет. Количество ошибок уменьшается, поддержка упрощается, производительность остается в допустимых рамках.
производительность остается в допустимых рамках
Насчёт удобства разработки я — верю!.. Но на скорость разве вообще нет накладных расходов на дополнительные слои абстракции?
Количество ошибок уменьшается, поддержка упрощается, производительность остается в допустимых рамках.
примеры показывают обратное
Вон Михаил выше пытался 3 оператора SQL написать на php, видели что получилось…
SQL: 28 строк логики
PHP: 22 строк логики
И оператор у меня один — блок кода между фигурными скобками.
SQL: 28 строк логики
PHP: 22 строк логики
И оператор у меня один — блок кода между фигурными скобками.
я говорю про производительность, простоту поддержки, консистентность данных, ну и про кол-во кода, Вы как-то упустили из него магические методы и прочее.
Допилите уже, пожалуйста, финальный код, будет что сравнить. Оформите в виде REST API. Мне видимо тоже надо вызовы на каком-нть ЯП сделать и результат в JSON'е отдавать, чтобы сопоставимый код был, который делает одно и тоже. Я бы сваял на Node, оч понравилась она мне в последнее время.
Тогда такое предложение, делаем 3 вещи:
1. закрытие документа, то которые выше
2. отображение списка товара с ценами, остатками. То которое уже делали, на нашей прошлой дискуссии, только его чутка усложнить надо, приблизив к реальности
3. загрузку прайс-листа от поставщика, пишется просто, но тоже наглядно покажет огромное преимущество SQL над императивной обработкой.
Примеры реализации задач самые, что ни на есть, живые.
Вы разрабатываете на PHP+MySQL8, я на MySQL8+Node
Финальный код Ваш и мой будет отличным материалом для статьи и объективной всесторонней оценки.
Если Вы берётесь, то я бы сформулировал требования, чёткое ТЗ, подготовил бы и описал структуру данных, наваял скрипты для тестовых данных.
Понимаю что, для того чтобы написать красивый код, который пойдёт на суд общественности, нужно время, да ещё и свободное время, поэтому чётких сроков не будем ставить, а раз в несколько дней связываться и интересоваться прогрессом. Но думаю за пару недель можно закончить.
Главное понять, берётесь Вы или нет?
Ещё бы это как-то оформить чтобы заинтересованные люди из комьюнити могли наблюдать за развитием батла. Как видим по последним статьям дискуссия нешуточная, интерес к теме есть.
Интересно как вы будете сравнивать простоту поддержки кода в рамках искусственного "баттла".
Интересно как вы будете сравнивать простоту поддержки кода в рамках искусственного «баттла».
Ну хоть что-то можно будет сравнить, а сейчас просто утверждения, что тот или иной код сложно поддерживать. Будет хотя бы код. Можно будет получить запрос от комьюнити на какую-нть доработку и посмотреть во что это выльется в моём коде и в коде Михаила. В общем начнётся конструктив.
Ну и кол-во кода будет одним из объективных критериев простоты поддержки.
ну и про кол-во кода, Вы как-то упустили из него магические методы и прочее
Я уже несколько раз написал, почему я их не привел — потому что они пишутся один раз на любое количество функций бизнес-логики, поэтому некорретно считать их вместе с кодом одной функции.
Тогда такое предложение, делаем 3 вещи
Я думал, мы хотели сначала сравнить производительность закрытия документов через базу и через приложение. Я уже код почти дописал.
Если Вы берётесь, то я бы сформулировал требования, чёткое ТЗ
Главное понять, берётесь Вы или нет?
Давайте попробуем.
Я думал, мы хотели сначала сравнить производительность закрытия документов через базу и через приложение. Я уже код почти дописал.
Да, давайте конечно сначала сравним то что уже будет написано. Если будет готовое приложение, то Вам добавить туда функционал будет уже не сложно.
Давайте попробуем.
Отлично!
простоту поддержки,
Ну вот и мы вам про простоту поддержки. Для меня код на C# намного более поддерживаем, чем код на любой вариации SQL.
Ну вот этот код который я показал — его не руками пишут, он гененируется. Добавил поля в модель, сказал "фас", он сгенерировал вот эти Up/Down самостоятельно. Тут весь процесс описан по шагам: https://docs.microsoft.com/en-us/ef/ef6/modeling/code-first/migrations/
Иногда возомжно её надо руками подправить чтобы например индексы создать или тот же SqlType проставить нестандартный, но в целом оно генерённое.
Да, высказался и привёл 2 идентично работающих листинга
Неа, не идентичных. Например, поведение транзакций не определено, а, значит, не идентично.
Мой код без сайд эффектов,
Да нет, ваш код только и состоит, что из побочных эффектов, как ожидаемых (запись в БД), так и неожиданных (блокировки).
Неа, не идентичных. Например, поведение транзакций не определено, а, значит, не идентично.
Ещё раз повторяю: оба листигна моего кода работаю идентично в равных условиях, хоть с автокоммитом, хоть завёрнутым в транзакцию. Автокоммит не обеспечит нужной целостности, но оба листинга будут работать одинаково.
Код Михаила, который он привёл в первый раз, без FOR UPDATE, не работает идентично моему коду, хоть с автокоммитом, хоть завёрнутым в транзакцию.
Да нет, ваш код только и состоит, что из побочных эффектов, как ожидаемых (запись в БД), так и неожиданных (блокировки).
Мда… Изучайте документацию СУБД, там явно описано как работают блокировки при DML операциях, как обеспечивается целостность.
Ещё раз повторяю: оба листигна моего кода работаю идентично в равных условиях, хоть с автокоммитом, хоть завёрнутым в транзакцию.
… вот только эти "равные условия" никем не гарантированы. Но не суть, на самом деле.
Изучайте документацию СУБД, там явно описано как работают блокировки при DML операциях, как обеспечивается целостность.
То, что побочные эффекты явно описаны, не означает, что они перестали быть побочными эффектами.
Это не побочные эффекты, это явные механизмы СУБД, которые обеспечивают целостность данных.
От того, что это явные механизмы, они побочными эффектами быть не перестают.
Почитайте что такое ACID
Почитайте, что такое побочные эффекты.
Так, для сравнения миров. Написано на C# с использованием linq2db. Все типобезопасно, те же три запроса только вставку переписал через MERGE и добавил тразакцию. Я бы с удовольствием посмотрел на код написанный спомощью JOOQ
void CloseDoc(IDataContext db, int docId, short type)
{
using var tran = db.BeginTransaction();
var documentQuery = db.GetTable<Document>().Where(d => d.id == docId);
var validationQuery = documentQuery
.Where(d => d.doc_type_id.In(6, 8) && d.DocPosition.kol ?? 0 != 0);
if (validationQuery.Any())
throw new Exception("Документы данного типа нельзя закрывать если есть позиции с не нулевыми количествами.");
var sourceQuery = from d in documentQuery
where d.DocType.credit_type.In(1, -1)
select new CurrentStock
{
mat_id = d.DocPosition.mat_id,
org_id = d.org_id_addr,
org_id_ur = d.org_id_ur,
kol = - (d.DocPosition.kol ?? 0) * d.DocType.credit_type * type,
reserve = - (d.DocPosition.kol ?? 0) * (d.DocType.credit_type == 1 ? 1 : 0) * type
};
db.GetTable<CurrentStock>()
.Merge()
.Using(sourceQuery)
.OnTargetKey()
.InsertWhenNotMatched()
.UpdateWhenMatched((t, s) => new CurrentStock
{
kol = t.kol + s.kol,
reserve = t.reserve + s.reserve
})
.Merge();
var deleteQuery =
from cs in db.GetTable<CurrentStock>()
from d in documentQuery.InnerJoin(d => cs.mat_id == dp.mat_id && cs.org_id == d.org_id_addr && cs.org_id_ur == d.org_id_ur)
where cs.kol == 0 && cs.reserve == 0
select cs;
deleteQuery.Delete();
tran.Commit();
}только вставку переписал через MERGE
А что делает MERGE?
А какой SQL код получается в итоге?
П.С. безотносительно всего: мне читается такой код ооочень тяжело…
MERGE'то ещё и DELETE умеет делать, поэтому тут вообще одним оператором можно обойтись и без уродливого ОРМ'а.
Будет что-то типа:
MERGE INTO cur_stock s
USING (
SELECT dp.mat_id, d.org_id_addr, d.org_id_ur
, IFNULL(dp.kol, 0) * -1 * t.credit_type * type kol
, IFNULL(dp.kol, 0) * -1 * IF(t.credit_type = 1, 1, 0) * type reserve
, CASE
WHEN d.doc_type_id IN (6, 8) -- ЗПС и План производства
AND IFNULL(dp.kol, 0) <> 0
THEN raise_error('Документы данного типа нельзя закрывать если есть позиции с не нулевыми количествами.')
END check_data
FROM t_docs d
INNER JOIN doc_pos dp ON d.id = dp.doc_id
INNER JOIN doc_types t ON d.doc_type_id = t.id
WHERE d.id = p_doc_id
AND t.credit_type IN (1, -1)
) d ON (d.mat_id = s.mat_id AND d.org_id_addr = s.org_id_addr AND d.org_id_ur = s.org_id_addr)
WHEN NOT MATCHED INSERT (mat_id, org_id, org_id_ur, kol, reserve)
VALUES (mat_id, org_id, org_id_ur, kol, reserve)
WHEN MATCHED AND (s.kol + d.kol = 0 AND s.reserve + d.reserve = 0) THEN DELETE
WHEN MATCHED UPDATE SET s.kol = s.kol + d.kol, s.reserve = s.reserve + d.reserve
Изящно, компактно, красиво, предельно эффективно. Чтение нужных данных всего 1 раз производится.
П.С. кстати, сюда же и проверку данных можно засунуть!!!
Сейчас подправлю запрос… Вот сейчас получилось просто шедеврально, вся логика в 20 строк кода и в один проход данных!
Могу и так написать, кода будет еще меньше.
… а вот теперь попробуйте переиспользовать часть логики из этого кода. Например, чтобы везде, где кто-то пытается закрыть документ, выполнялась проверка WHEN d.doc_type_id IN (6, 8) AND IFNULL(dp.kol, 0) <> 0 THEN raise
Точнее это функция, которая запускает такой код в триггере на таблицу t_docs
SELECT close_doc(d.new_id, IF(d.new_closed = 1 AND d.old_closed IS NULL, 1, -1))
INTO msg
FROM t_docs_tmp_trg d
WHERE d.time = 'A'
AND d.type = 'U'
AND (d.new_closed = 1 AND d.old_closed IS NULL
OR d.new_closed IS NULL AND d.old_closed = 1
)
;
И как вы гарантируете, что какой-то разработчик просто не решит сам проставить статус "закрыто" или удалить строчку, минуя вашу процедуру?
"какой-то разработчик просто не решит сам проставить статус" — а у разработчика нет прав в БД на update/delete
У разработчика, который разрабатывает код, который работает с БД, нет прав написать код, который проставляет статус?
Для вас разработчик и клиент одна роль в БД?
Но в общем случаю да.
Грант execute не подразумевает update, delete, а права разработчика в БД не подразумевает права dbowner, не говоря уже supervisor
Для вас разработчик и клиент одна роль в БД?
А при чем тут клиент-то? Я об этапе разработки говорю.
права разработчика в БД не подразумевает права dbowner
… и как же он разработку ведет?
Вы не имеете опыта DB разработки совсем?
Давать разработчику права dbowner и тем более supervisor совсем необязательно и даже нельзя, если разработчиков более одного
Имею. Удивительным образом, на локальных БД, в которых я веду разработку, у меня права dbo (и sa на весь сервер, чего уж).
Вы создаёте базу и её объекты от имени dbo. От его же имени выдаёте нужным ролям нужные разрешения на эти объекты.
А когда вы разрабатываете клиент к этой базе, использующий созданные объекты базы, вы делаете это с connection string, соответствующей роли пользователя.
Если клиент имеет админский доступ, значит вы либо используете подход code-first (когда база создаётся из клиента), либо что-то делаете неправильно. Локальность базы ничего не меняет в этом смысле.
Ну вот и что мне мешает создать в БД процедуру, которая обновит статус документа? И выдать роли пользователя на нее права?
Вам как разработчику базы — совершенно ничего. Как разработчик базы, вы имеете к ней полный доступ на фазе разработки, и предполагается, что вы используете его во благо.
Точно так же ничего не мешает локальному администратору отформатировать диск без бекапа. Он просто не должен этого делать, потому что это неправильно, и предполагается, что он и не станет.
Все остальные не могут создать в БД процедуру, которая обновит статус документа.
Это всё равно, что спросить — а что, если предприимчивый девелопер найдёт в vTable вашего класса указатель на private-метод и вызовет его напрямую, в обход публичного интерфейса вашего класса?
Разумеется, в этом случае всё сломается, но так и должно быть.
У разработчика этой базы данных есть возможность поступить так. Он не должен так делать, но если сделает, то это он нарушил контракт.
А у разработчика клиента к этой базе такой возможности быть не должно.
В контексте базы данных это решается выдачей нужных разрешений и невыдачей ненужных.
Всё это, разумеется, применимо к ситуации, когда база содержит логику, а не является безмозглым хранилищем для среднего слоя.
Это всё равно, что спросить — а что, если предприимчивый девелопер найдёт в vTable вашего класса указатель на private-метод и вызовет его напрямую, в обход публичного интерфейса вашего класса?
Нет, не то же самое. Уровень необходимого вмешательства другой.
Он не должен так делать, но если сделает, то это он нарушил контракт.
А откуда он это знает? Где зафиксирован этот контракт?
А откуда он это знает? Где зафиксирован этот контракт?
Так ведь вы его, как разработчик базы, сами и создаёте!
И предполагается, что создаёте вы его таким, чтобы он позволял всё нужное и не позволял всё ненужное.
Вы же спрашиваете, что будет, если вы, единственный создатель и властитель контракта, его же будете нарушать.
Разумеется, ничего хорошего не будет, но так предположение в том и состоит, что вы, единственный, кто имеет техническую возможность нарушить свой собственный контракт, как раз и не станете этого делать. Иначе это осознанное стреляние в ногу.
Так ведь вы его, как разработчик базы, сами и создаёте!
[...]
Вы же спрашиваете, что будет, если вы, единственный создатель и властитель контракта, его же будете нарушать.
В том-то и дело, что не единственный. Разработчиков больше одного.
И предполагается, что создаёте вы его таким, чтобы он позволял всё нужное и не позволял всё ненужное.
Вот о том и речь: я не могу создать контракт сущности документа в СУБД таким образом, чтобы из него было очевидно другим разработчикам в этой СУБД, что такие-то поля документа нельзя менять кроме как через процедуру, которая содержит бизнес-логику.
Да, это так :(
Помогают:
- Документация
- Общая атмосфера "мы пишем базу с логикой", где первой мыслью каждого участника должно быть смотреть в документацию, что вызывать для удаления
- Инструменты проверки зависимостей между хранимыми объектами и анализа использования инструкций sql
Стопроцентного решения нет.
— не юзаем хранимки для изменения данных
— естественный контракт для модификации данных это всем известные методы INSERT/UPDATE/DELETE на таблицу
— обязательные параметры и типы параметров у нас описываются в CREATE TABLE
— простые валидейшены по-возможности описываем CHECK'ами
— бизнес логику и сложные проверки выносим в процедуру которая вызывается в триггере
— процедура работает через временную таблицу как описано у меня статье
— бизнес логику и проверки в процедуре описываем декларативно
А что делает MERGE?
А какой SQL код получается в итоге?
Была бы база я бы выложил. MREGE синтаксис можно почитать в документации
П.С. безотносительно всего: мне читается такой код ооочень тяжело…
Это с непривычки, нужно понимать что SELECT всегда в конце — иначе типы не вывести. Ну и синтаксис современного C#, не знаю как у вас с ним.
Если присмотритесть я почти не делал JOIN — все сделает библиотека через ассоциации между таблицами, их еще называют навигациями по свойствам.
Также я один раз задал фильтр по docId и больше этим не страдаю. Так уменьшается количество возможных багов (условие по JOIN неправильное, забыли фильтр наложить). Декомпозиция запросов в полный рост — то чего не хватает SQL.
Запчасти запросов я разложил по переменым, хотя можно было в некоторых местах и не делать этого. Все для того чтобы спокойно можно было каждый запрос проверить в дебаге.
К чему я веду — если иметь првильный тул, действительно можно обойтись без хранимок с минимумом оверхеда и максимальным mainteinability.
P.S.
Кстати, данный код будет работать на всех базах поддерживающих MERGE. Бибилиотека за вас учтет особенности синтаксиса нужной базы данных.
Это с непривычки
нет. SQL тем и ценен, что он близок к человеческому языку, можно пару лет не прикасаться и не заглядывая в справочники написать запрос.
про прочитать я и не говорю — минимального знания английского достаточно чтобы прочитать 90% запросов на разных диалектах SQL (про машиногенерируемые запросы на несколько килобайт я не говорю).
P. S. «но сатана недолго ждал реванша», пропихнули в стандарт всякие '$.floor[*].apt[*] ? (@.area > 40 && @.area < 90)' для работы с json
нет. SQL тем и ценен, что он близок к человеческому языку, можно пару лет не прикасаться и не заглядывая в справочники написать запрос.
Это пока вам не придется писать оконные функции, Merge.
Ну в общем, ваше дело, а я прекрасно читаю LINQ и не хочу тратить время на написание SQL, склейку строк, нюансы синтаксиса. Рефакторить LINQ одно удовольствие, а вот SQL — тут без ста грам DataGrip, еще тот квест.
Вот пример, где кастомное решение рвет чистый SQL как тузик грелку:
Есть 1000 записей вида (int Id1, int Id2) в памяти приложения. Нужно выбрать из таблицы TableX все записи у которых совпадают эти два поля.
Вот решение с использованием ORM, удачи в написании SQL:
var items = // список элементов
using var tempTable = db.CreateTampTable("#Items", items);
// записи влетают в базу за секунду
var query =
from x in db.GetTable<TableX>()
from t in tempTable.InnerJoin(t => t.Id1 == x.tId1 && t.Id2 == x.Id2)
select x;SELECT x
FROM TableX x
INNER JOIN Items t ON t.Id1 == x.tId1 AND t.Id2 == x.Id2
А откуда у вас таблица Items взялась? Её в БД нет, она только в памяти клиента...
using var tempTable = db.CreateTampTable("#Items", items);её создаёт
Видимо неверно предположил. А какие SQL команды будут выполнены на сервере в приведённом Dansoid коде?
Да, этот код её создаёт (только она называется #Items, видимо для совместимости с MS SQL Server).
Вот только если вы отказываетесь от ORM — у вас не будет этого кода.
На php в своё время писал подобную процедуру самостоятельно, никаких сложностей.
А в MySQL 8 c JSON_TABLE сейчас даже не надо создавать временные таблицы для подобного
let items = [{id1: 1, id2: 2}, {id1: 3, id2: 4}];
let [res] = db.query(`
SELECT x.*
FROM JSON_TABLE(?, '$[*]'
COLUMNS (id1 INT PATH '$.id1', id2 INT PATH '$.id2')) i
INNER JOIN TableX x ON i.id1 == x.tId1 AND i.id2 == x.Id2
`, [items]);
Точно так же будет выглядеть на JOOQ и практически любом ОРМ
Показать можете? Я смотрел на JOOQ, мило и только. Как там с переиспользванием запросв?
Да мне кажется дока вполне полноценно описывает возможности. Переиспользовать конечно можно, любые билдеры запросов всегда чистые, а значит композирутся как угодно. Ну взять тот же раст:
let items = Integrations::table.filter(dsl::CompanyId.eq("ff00-abcd"));
let total_count = items.count();
let top10 = items.take(10).load();Наличие отстуствие всяких специализированных merge/оконных функций/этц это уже к фичастости фреймворка. Где-то есть, где-то нет. В linq2db например есть, но зато там есть другие проблемы.
Да мне кажется дока вполне полноценно описывает возможности.
Покажите мне query decomposition на JOOQ, я задолбался искать
В linq2db например есть, но зато там есть другие проблемы.
Хотелось бы о них услышать
Покажите мне query decomposition на JOOQ, я задолбался искать
Там все на мутабельных билдерах, но в целом это не мешает, достаточно вметсо переменной использовать функцию возвращающую билдер.
Хотелось бы о них услышать
Ну в частности я не смог заскаффолдить свою базу. Там какая-то хитрая ерунда на .tt шаблонах (в 2020 году-то), которая ни на винде, ни на тем более рабочей убунту станции не заработала. Плюс да, были проблемы, начиная от того что драйве не экспейкпил имена табликек (например табличку Users в постгре нужно писать исключительно как "Users" в кавычках, иначе он её не увидит) и заканчивая тем что на кажое поле каждой модели нужно было атрибут вешать.
LinqToDB.Linq.LinqException: Member 'Cars.CompanyId' is not a table column.
На этом я забил на свои попытки в эту сторону лезть и смирился с обжект трекингом и EF, там хотя бы тулинг работающий на коре и переиспользование моделек.
CREATE PROCEDURE close_doc(p_doc_id INT, type TINYINT) -- type - 1 закрытие, -1 открытие
Будем честными, для меня достаточно этого комментария, чтобы избегать этой хранимой процедуры, пока есть такая возможность.
habr.com/ru/post/203048
Как показывает практика: при желании — можно упростить до 0 строк кода. А ещё можно убедить бизнес в том, что им это вообще не нужно и вообще ничего не делать — так тоже бывает.
Основная проблема логики в базе, очень мало людей умеют ее готовить.
Основной плюс логики в базе, работа с множествами там где они лежат с использованием механизмов оптимизации СУБД. Плюс небольшое преимущество в транзациях. Ну и потребление ресурсов.
Основные минусы, менее развиты инструментарий и сложность с поиском людей которые умеют и готовы этим заниматься.
Да, отсутствие фрэймворков, это скорее плюс СУБД. Потому как сейчас уже есть целый пласт «фрэймворк разработчиков», которые helloword без двух-трех фрэйморков и гига памяти написать не могут, а на выходе сайты визитки на 20МБ.
select @result = isnull(CAST(@res as nvarchar(max)),'')
if CHARINDEX ('<status>Error</status>', @result) > 0 or CHARINDEX ('<status>OK</status>', @result) = 0 ...Если вы что-то не умеете готовить не значит, что это плохо.
Так говорят только те программисты, которые не готовы отвечать за проект в целом. Которые не думают о том, как с этим проектом будут работать другие люди, через 3-5-10 лет.
Если кто-то «умеет готовить» Perl — это не значит, что новый большой проект в 2020 году нужно писать на нем
сложность с поиском людей которые умеют и готовы этим заниматься.
Представляете, но это реально сложность. Есть проекты которые переписывали с нуля, не смотря на то, что они отлично работали, только потому, что найти программистов, которые бы их поддерживали было невозможно.
Я не говорю, что нужно брать проект и писать его на SQL.
Это действительно не лучшая идея именно в следствии сложности с персоналом. Вам будет реально не просто набрать людей, обучить их и ввести в проект, поскольку для того же ООП есть хоть какие-то распространенные шаблоны и практики, для SQL с этим все значительно хуже.
Но с другой стороны, найти толковых разработчиков на любой другой стэк тоже ОЧЕНЬ не просто.
О плюсах.
Удобный полный доступ ко всем функциям используемого диалекта SQL, а не только к общему подмножеству, используемому ORM-фреймворком.
Как результат — возрастающее желание, которому трудно сопротивляться, перетащить в базу ещё больше логики, потому что очень изящно всё с sum() over(partition by) получается.
Возможность тонкой настройки конкурентности и избежания дедлоков, хинтами и перестановкой операторов.
Как результат — все блокировки пессимистичные (гарантия успеха финального update), и при этом никто никому не мешает.
Избежание ORM-сгенерированных запросов, которые выполняются ужасно долго, хотя если переписать вручную чуть иначе — мгновенно.
Возможность быстрого написания тонких клиентов на любых фреймворках к этой базе-приложению. Одновременно нескольких, для клиентов из разных областей — один на ASP.NET MVC Core, один в MS Excel, один в MS Access, один на powershell. При правильной инкапсуляции изменение функционала базы-приложения часто не требует никаких изменений в этом зоопарке клиентов вообще.
И почему пессимистичность блокировок — это гарантия успеха финального апдейта?
Полностью избежать дедлоков нельзя. Их можно сильно уменьшить, если обращаться к данным в одном порядке и использовать updlock для тех данных, которые в итоге предполагается обновить.
Использовать один и тот же порядок доступа к данным можно и из ORM, но там а) нет хинтов, и б) если вдруг запрос странслируется недостаточно оптимально, можно получить эскалацию блокировки. Например, при запросе множества "1 родитель + его дети" ORM, чтобы избежать ситуации n+1, может запросить всю структуру одним запросом, но с вложенным (select count(*)) для собственного удобства парсинга результата, что плохо для блокировки. Или таки скатывается в n+1, что тоже не фонтан.
Пессимистичность блокировок — гарантия успеха в смысле их противопоставления оптимистичным блокировкам. ORM в основном работают по оптимистичным блокировкам — при чтении из базы ничего не блокируется, а при последующем обновлении обновление выполняется только если соответствующие поля не были изменены с момента запроса (т.е. к условию update .. where id = 42 автоматически дописывается and field1 = 'asd' and field2 is null). Если значения полей оказываются иные, база возвращает "0 rows affected", и ORM транслирует это в исключение "Оптимизм не оправдался, обновите свою картину мира и попробуйте снова". Механизм проверки, конечно, можно отключить, но это отложенное стреляние в ногу.
Разумеется, всё это верно для областей, где, собственно, важно быть уверенным, что обновление вносится именно в ту версию объекта, которая была прочитана из базы (складской учёт, денежные транзакции). В других областях может быть совершенно безвредно переписать объект его новейшей версией безотносительно оригинального состояния (редактирование постов на форуме).
при чтении из базы ничего не блокируется
Зависит от текущего transaction isolation level + самой структуры запроса — SELECT FOR UPDATE очень даже блокирует на чтение. То же самое с подзапросами.
В других областях может быть совершенно безвредно переписать объект
Шеф, тут пришло несколько тредов на запись с клиента и мы всё проэтосамили
А могли бы подробнее рассказать, о каких именно хинтах идёт речь, как именно вы обращаетесь к данным в одном порядке, если речь о распределенной системе?
о каких именно хинтах идёт речь
В большинстве случаев updlock.
updlock, rowlock, readpast для таблиц с элементами на обработку первым освободившимся воркером.
updlock, paglock, holdlock для исключения возможности появления новых записей, удовлетворяющих некоему where, за период обработки старых (оптимально работает при наличии индекса, покрывающего where — ставит лок на соответствующую его страницу; иначе может заблокировать всю таблицу).
Иногда xlock.
Очень редко, по крайней необходимости, tablock, xlock.
Эффект от хинтов в деле предотвращения дедлоков косвенный; количество дедлоков уменьшается за счёт того, что некоторые чтения, которые были бы иначе успешны и в конце могли привести к дедлоку, превращаются в обычные ожидания до того, как дедлок мог бы произойти. Основной эффект от хинтов — максимально возможная конкурентность при гарантии исключения случайной двойной обработки данных разными клиентами.
как именно вы обращаетесь к данным в одном порядке, если речь о распределенной системе
Порядок обращения имеет смысл в рамках одной транзакции.
Если одна транзакция считывает сначала фрукты, потом овощи, а другая — овощи, потом фрукты, то вероятность дедлока между ними выше, чем если обе считывают сначала овощи, потом фрукты, или наоборот.
Если одна транзакция заинтересована только в овощах, а вторая только во фруктах, порядок их запуска не имеет значения.
Вынесение этой логики в базу позволяет легко унифицировать этот порядок для всех клиентов и легко его поменять, если когда оптимизатор запросов решит, что данных в таблицах набралось достаточно много, чтобы перестроить планы запросов.
Работал в одной компании, все запросы писались из ОРМ. При необходимости взять подобный лок просто вызывалась хелпер-функция, которая просто начинала транзакцию и брала лок нужного уровня прежде чем начнут выполняться сгенерированные ОРМкой запросы.
Да и вообще, странно обсуждать что ОРМ чего-то не умеет если у любой орм есть метод myDb.Sql("SELECT ANYTHING FROM ANYWHERE")
Вы описываете мир, где интеграция нескольких приложений/проектов идёт через базу данных.
Я в таком мире жил некоторое время, очень неприятное место.
Все таблицы скрыты от простых юзеров, доступ на чтение через view, на запись через хранимки. Иначе ведь нельзя ничего менять в структуре, а то разные приложения будут ломаться. С разным релиз циклом.
Любые изменения — это большое трудное ревью.
И всё это в pl/sql, который реально хорошо знает 3 человека, а java знают тысячи.
На мой взгляд более эффективно закрывать базы данных с помощью rest api. Потому что в ресте хорошо проработана версионность и можно поддерживать разные версии апи, так что клиенты не будут знать о том, что внутри что-то поменялось, может мы вообще ушли с сиквела на Mongo. Апи остался тем же. Также код самого апи довольно прямолинейный и может быть написан на популярном языке с развитыми тулами, вроде той же java, c#, typescript.
При этом никто не запрещает делать тонкие оптимизации, там где они нужны. Профилируйте, ищите узкие места, переносите код в хранимки. Но пожалуйста, не делайте интеграцию через базу данных!
" pl/sql, который реально хорошо знает 3 человека, а java знают тысячи.", что и требовалось показать, ибо потом эти тысячи будут плюсовать статьи объясняющие что хранимые функции БД это плохо.
- даже если вы хорошо знаете pl/sql язык тупо не позволяет нормально писать многие вещи, да и вообще крайне слаб по сравнению с любой современной альтернативой. Экосистема (тулинг, библиотеки, ...) конечно же являются частью оценки языка по шкале лучше/хуже
- вы живете в реальном мире, и нанимаете людей с рынка а не из страны фиолетовых эльфов. Если ваш подход требует нанятия дорогих супер-редких специалистов а конкуренты могут грести всех подряд, то с деньгами в конторе все будет хуже. В пределе это ударит по вам же, потому что ЗП платятся как раз из этих денег.
Вопрос-то в том, почему их тысячи. Практически на любых языках их тысячи, люди зачастую знают несколько языков и фреймворков к ним (PHP/JS, PHP/Go, Java/Kotlin), а вот на SQL почему-то мало. Самый вероятный вариант — потому что сложность разработки одной и той же бизнес-логики на нем выше.
По поводу кривых запросов из orm, в целом согласен, кроме самых простых вещей, генератор запросов в тех орм, что приходилось использовать никуда не годится. Очень легко получить N+1, даже в простом случае. На любых более менее крупных проектах, мы используем только материализатор, а запросы пишем сами. Конкретно на шарпе используем Dapper — мне лично больше не нужно
Как результат — все блокировки пессимистичные (гарантия успеха финального update), и при этом никто никому не мешает.Вы уверены, что именно это хотели сказать?
Да.
Но, действительно, можно понять по-разному.
Полная версия:
Все блокировки пессимистичные, но, благодаря наложению блокировок минимально необходимым образом:
- транзакции, которые хотят изменять разные участки таблицы, не мешают друг другу;
- транзакции, которые хотят в будущем изменять участки таблицы, не мешают другим их читать в настоящем, хотя блокировка уже наложена;
- транзакции которые хотят изменять один и тот же участок таблицы, культурно выстраиваются в очередь,
скорее всегоможно надеяться, без дедлоков.
Удобный полный доступ ко всем функциям используемого диалекта SQL, а не только к общему подмножеству, используемому ORM-фреймворком.
Это может быть как плюсом, так и минусом, например сменить СУБД после написания такого богатого кода может быть тяжело или невозможно. "Да кому оно может пона..." — вот мне понадобилось, 1.5 года назад, на текущем проекте с постгреса на монгу переехали. Выиграли довольно много перфоманса. Изменений в логике было 0, весь переезд — написание скриптов на дамп данных из постгри и засовывание их в монгу, да замена постгрес драйвера на монго. И хотя я был сторонником найма ДБА инженера чтобы решить вопрос в рамках постгри, так тоже можно решать вопросы. А в другом примере когда у нас была оракловая БД и решили на постгрес переехать там была эпопея на год работы целой команды. Такие дела.
Да сколько можно-то, чукчи-писатели, блин. Перечитайте статью с комментариями или посмотрите видео. Далеко не вся бизнес-логика у них в хранимках. В хранимках у них то, что обычно делается в ваша-любимая-ORM + непосредственно отдают из БД json минуя сериализацию/десериализацию на бэке. Все остальное у них в бэкенде на go почему-то названным прокси-сервисом (хотя если с бэка убрать доменную модель и килотонны логики по формированию sql-запросов, он похудеет настолько, что захочется его назвать проксей)
В хранимках у них логика, логика принятия решений
Про метрики и логи тоже соглашусь, всё надеюсь увидеть комментарий под статьей как другие компании решали такие вопросы в БД.
Да точно так же как и везде. У Базы тоже есть логи. Если этих логов не достаточно, у вас под рукой база, пишете в нее все что вам нужно.
Это даже проще, не нужно ни каких монстров сборщиков логов, которые разве, что кофе не заваривают, не нужен( как правило ) никакой ETL, если необходимо все штатными методами собирается в общее хранилище.
Только вот SQL СУБД так себе для хранения логов. Это WORM данные, которые нужно хорошо сжимать и часто строить полнотекстовые индексы.
Если с последним еще можно справиться, то со сжатием обычно беда.
А не надо их там хранить. Вы же не храните все свои логи в виде сырых текстовых файлов?
Так и тут, пишите в табличку с датой в названии, а сборщик логов считает, отправит в хранилище, а табличку удалит
Так "cборщик логов считает" или "не нужно ни каких монстров сборщиков логов"?
Только вот проектов такого масштаба ОЧЕНЬ мало, единицы, а тот же elasticsearch пихают в проекты в которых он оказывается самой большой частью.
Это вообще интересная ситуация, когда логер у вас кратно больше остального проекта, потребляет половину ресурсов и большую часть ресурсов по сложности обслуживания и разворачивания.
Хранение логов в БД в рамках одного сервера с основными данными вызывает проблемы даже с бэкапами базы
Если ваш проект до рос до такого масштаба, что хранение логов в субд вызывает у вас проблемы
Ну то есть почти сразу, если считать за проблемы то, что (а) СУБД стоит дороже, чем дисковое пространство и (б) функциональность работы со структурированными логами в СУБД хуже, чем в специализированном инструменте.
Только вот проектов такого масштаба ОЧЕНЬ мало, единицы
Ну вот у меня таких проектов подавляющее большинство.
Это вообще интересная ситуация, когда логер у вас кратно больше остального проекта, потребляет половину ресурсов и большую часть ресурсов по сложности обслуживания и разворачивания.
Не, у меня ровно обратная ситуация: как только логи выносятся из БД, количество необходимых ресурсов резко уменьшается.
У нас некоторые сервисы генерируют десятки тысяч строк логов в секунду. Обычная БД кони двинет скорее всего от такого потока, как минимум. Не говоря уже о том что это архитектура через одно место.
Если же стабильность сервисов возможно обеспечить, только если логировать их через строчку кода, то вероятно логирование не самая большая проблема.
Вообще логи это хорошо, полезно и нужно. Но не стоит забывать, что у приложения есть и бизнес задача. И если техническая задача логирования, требует ресурсов на порядок больше чем бизнес задача, то вероятно, что-то сделано не так, приложения же работают не ради логов.
Есть логи от бизнеса. Аудит изменения объектов, например. С полным исходным и новым состоянием вдобавок к метаданным.
Если так много логов, то вероятно основная рабочая нагрузка еще выше
Конечно, нет. "Основная рабочая нагрузка" может порождать сильно больше одной записи логов на одну рабочую операцию.
Я бы даже сказал, это вопрос адекватности сбора логов, зачем логировать данные больше чем выполнять с ними операции?
Я понимаю, разработчик хочет видеть буквально все, можно после каждой строки стэк трэйс в лог выгружать, так вообще все в нем будет.
Но нужно понимать, системы они не для логирования живут, а для рабочей нагрузки. Система логирования не должна требовать ресурсов больше чем все остальное вместе взятое если речь идет не о низко стабильном прототипе.
Сильно больше это сколько?
Иногда на порядки. Т.е. "рабочая нагрузка" — это запрос в веб-сервис, ответом которого выступает одна строка с адресом, а логи — это полное тело запроса туда, полное тело ответа, плюс все необходимые корреляторы.
И хранятся они столько же времени сколько основная рабочая нагрузка?
А вот сколько они хранятся — это уже не так важно, потому что надо сначала их эффективно и быстро записать. Кстати, сделать эффективное удаление с хвоста — тоже не то что бы самая прямолинейная операция.
Я бы даже сказал, это вопрос адекватности сбора логов, зачем логировать данные больше чем выполнять с ними операции?
Затем, что иногда это единственный способ понять, что пошло не так в ходе операции.
Система логирования не должна требовать ресурсов больше чем все остальное вместе взятое если речь идет не о низко стабильном прототипе.
Ну да. Собственно, у меня так и есть. А вот если бы я попробовал это сделать поверх той же БД, где крутится бизнес, все бы легло.
Есть для этих целей логическая репликация куда угодно. И в этом где угодно настройки постгреса можно так подкрутить, что он вам полнотекстовый поиск сделает. Никто не мешает пересобрать целевую базу со страницами в 512 кб и отключить хранение текста в тостах, заменив его сжатием. И вот вам одноколоночная СУБД с полнотекстовым поиском. Прибавьте туда несколько различных типов индексов для JSON/HSTORE и, вполне возможно, что этого хватит с лихвой.
Я много всякой дичи могу придумать, и троллейбус из буханки и двух спиц собрать, только зачем?
Я лучше сделаю нормальную архитектуру где логи будут отправляться туда, где им самое место — в ELK/Clickhouse/Loki/whatever, где будет нормальный tracing запросов через Jaeger и так далее. А в БД будет только то, что необходимо — такие хранимки, которые работают эффективно ближе к данным, а не вся бизнес-логика.
Я тут пару лет назад уже поработал в швейцарском аналоге Avito, у них аж 4-звенка, но это не спасло:
- Фронтенд
- Какой-то движок шаблонизации, написаный на Си в виде модуля Apache, который на ходу собирал JSON. Ошибешься в шаблоне — в JSON добавится лишняя запятая и фронт перестанет его жевать.
- Транзакционный движок опять же на Си, реализующий бизнес-логику: принимает данные от 2 слоя и ходящит в базу.
- Собсно PostgreSQL, в котором, если всего выше мало, еще штук 300-500 хранимок немаленьких которые вызывает (3). Реализует вторую часть бизнес-логики.
И всё это для сайта у которого посетителей то кот наплакал и работал он на 8, кажется, серверах железных.
Так что нет, не надо нам извращений.
А по существу — аргумент всего один. В БД переносится только бизнес-логика, а не вся логика целиком.
Все шаблоны, фреймворки и прочая фигня остаётся на фронте, который теперь занимается только тем, чем реально должен: получает запрос от клиента, разбирает его, передает базе, получает ответ от базы и красиво предоставляет его клиенту.
Я когда-то давно принимал участие в таком же проекте. И таки должен заметить что хранить бизнес-логику вместе с данными — это чертовски удобно. Например, мы получаем строгую типизацию и в принципе исключаем ошибки типа "ой, в базе поле называется не совсем так как мы написали в фронте".
И да, безопасность. Взломанный фронт просто в принципе не может дропнуть базу или прочитать те данные, которые ему знать не положено.
Например, мы получаем строгую типизацию и в принципе исключаем ошибки типа "ой, в базе поле называется не совсем так как мы написали в беке".
Ну так с нормальным интерфейсом к БД вы в своём Java/PHP/C++/%YouNameIt% получите ровно то же самое, только с нормальным ЯП, а не кастрированным.
1. SELECT FOR UPDATE/SKIP LOCKED в начале долгой бизнес логики в базе, с вызовом кучи процедур, некоторые из которых автономные транзакции, TRY/CATCH блоком с ROLLBACK и COMMIT.
Лепить такую процедуру во фронте это всегда иметь шанс не закомиттить транзакцию по банальной причине отвала приложения или чего-то еще. А потом ловить дедлоки.
2. Курсор на выборку и изменение данных. (FOR item IN (SELECT) DO LOOP)
Либо вы грузите DTO/POJO/POCO в клиента, делаете изменения. Времени больше уходит, плюс накладные расходы сети.
Лепить такую процедуру во фронте это всегда иметь шанс не закомиттить транзакцию по банальной причине отвала приложения или чего-то еще. А потом ловить дедлоки.
Если ваш язык не умеет в RAII или хотя бы using, то я могу вам только посочувствовать.
приложение фризнуло или упало в дамп,
сеть пропала и вернулась через минут 10, когда вся база уже встала,
сама операционка словила kernel panic/bluescreen и т.п.
Но это всё и с базой может произойти.
Далее, любая ваша транзакция в базе это ресурсы. Когда ваша транзакция выполняется сравнительно длительное время, то все эти ресурсы ждут коммита. Тогда как ключевая задача в работе с БД это максимально быстро получить/сохранить данные. Перенося транзакционность на клиента вы увеличиваете время, пока ресурсы не будут освобождены. По базе стоят лимиты на этот счет и в случае высокой нагрузки, схема транзакция на клиенте откажет раньше, чем схема транзакций на базе.
Тогда как ключевая задача в работе с БД это максимально быстро получить/сохранить данные.
Это в каком-то вашем, вероятно узком, контексте. SQL РСУБД не для этого создавались, просто оказалось, что чистая имплементация реляционных алгебры и исчисления практически неприменима, и тогда начались всякие хаки РМД — сортировки, индексы, оптимизаторы, хинты игнорировать оптимизации и т. д., и т. п. И от основной задачи SQL на момент создания, всё дальше и дальше с каждым годом.
И теперь надо работать с тем, что есть. Например, план может строиться по не правильной ветке. И что проще, изменить одну вьюшку добавив хинт или менять код в 20 сервисах?
Проще — поменять код в одной библиотеке.
Если сервисы дошли до такой стадии — то вам и в БД вьюху менять не позволят, с той же самой формулировкой.
Ну, если подходить к архитектуре с позиций "чтобы тут можно было что-то незаметно для начальства и коллег поменять", то СУБД, конечно же, все конкуренции — вот только задача обычно обратная ставится.
А как вы гарантируете, что никто не заметит?
И речь идет о приложениях, а не коллективе.
Не могу себе представить нарушающий гарантию кейс.
Да легко. Вы поменяли хинты, план поменялся, 9 кейсов улучшилось, один радикально ухудшился.
И речь не о производительности, а именно о смене инфраструктуры, замене одной таблицы другой, переделкой в мат.вьюшку и т.д.
С трудом могу представить себе такое развитие событий. В вашей практике такое было?
Ну да.
И речь не о производительности,
Как же так? Вот выше вы же пишете: "Например, план может строиться по не правильной ветке. И что проще, изменить одну вьюшку добавив хинт"
замене одной таблицы другой
А в этом случае уже надо корректность гарантировать, это еще веселее.
Был такой пример. У меня как-то был запрос вида
SELECT TOP 10 *
FROM ...
JOIN ... JOIN ... JOIN JOIN JOIN JOIN
WHERE %REALLY_RARE_CONDITION%
ORDER BY IDИ анализатор видя TOP 10 ORDER BY ID радостно принимался луп джоинами это дело пилить. План запроса в итоге выглядел вот так:
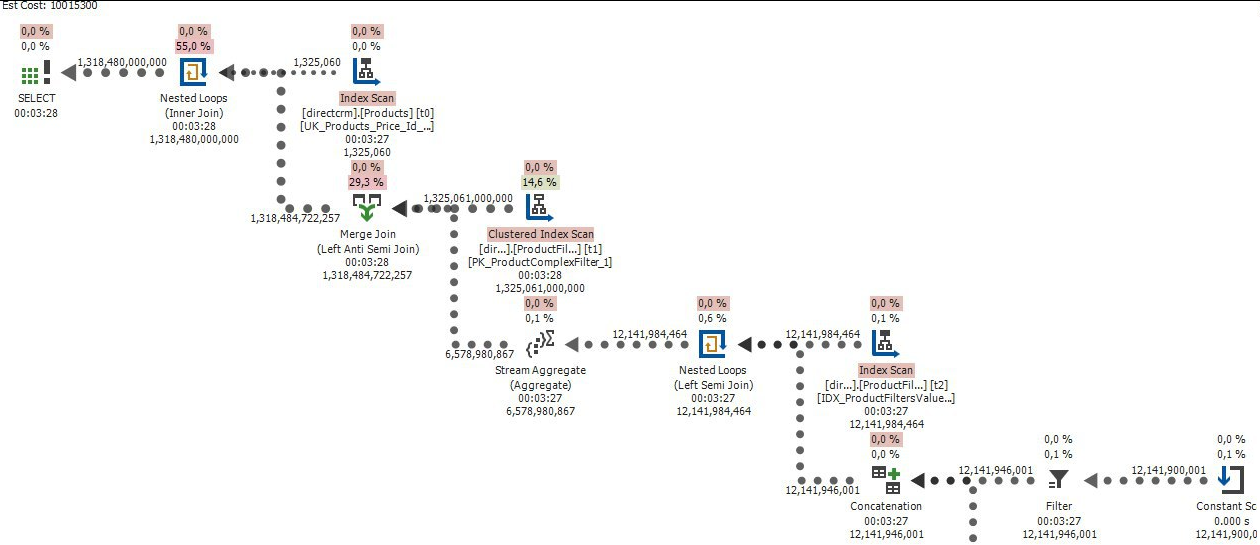
1.5 триллиона строк выгружено, время работы почти 4 минуты — ну норм для запроса, да?
При этом если сделать хэш джоин то время запроса падает до миллисекунд.
В итоге я нашел как отключить эвристику, достаточно сделать:
... то же самое
ORDER BY IF 1 = 1 THEN ID ELSE 0после чего эта кверя и многие другие ускорились. Ну, я это закоммитил в одно из базовых мест которые генерировали квери чтобы ускорить их все. А потом через неделю ко мне прибежали с ребята из соседней команды и сказал что их запросы наоборот на порядок замедлелись и вместо 1с начали выполняться по минуте. Ровно из-за этого фикса, который на моих задачах выиграл 3 порядка времени, а на их — замедлил.
Так я научился правилу "не 'чини' базовый кейс если не проверил что ничего не ухудшил".
Если вы говорите о десяти сервисах, то с хорошей вероятностью у вас и баз больше одной.
Ну так и в чем проще поменять несколько баз, чем несколько сервисов?
Опять же, процитирую вам ваше же, с которого началось обсуждение:
Например, план может строиться по не правильной ветке. И что проще, изменить одну вьюшку добавив хинт или менять код в 20 сервисах?
Так вот, если у вас двадцать сервисов, то и баз у вас сильно больше одной, поэтому стоимость изменения с точки зрения количества мест будет более-менее одинаковой.
Взломанный бэк просто в принципе не может дропнуть базу или прочитать те данные, которые ему знать не положено.
Да запросто может, даже взламывать не надо, достаточно SQL-инъекции при вызове хранимой процедуры.
$id = $_GET['id'];
...
$db->query('CALL get_order(' . $id . ')');
// http://.../order?id=(SELECT 123456 FROM user WHERE username = 'admin' AND auth_key like 'O%')
->
// CALL get_order((SELECT 123456 FROM user WHERE username = 'admin' AND auth_key like 'O%'))Перебираем символы ключа авторизации по одному, получаем 404 на неправильный символ, данные заказа 123456 на правильный.
Эээ… Вы всерьез пишете такой код и так вызываете процедуры? Про байндинг параметров не слышали?
Но вообще я имел в виду другой юзкейс. Например, у нас сайт обрабатывает запросы на покупку товаров. Соответственно, база ему в принципе не даст доступ к данным поставщиков, например. Или к финансовой информации. Или ещё куда-то, куда ему не надо.
Слышали конечно, но вы же говорите "в принципе". В принципе можно, и даже не очень сложно. А уж если бэк взломан, то тем более.
Соответственно, база ему в принципе не даст доступ к данным поставщиков
Опять же не "в принципе", а зависит от того, как вы разрешения настроите.
Слышали конечно, но вы же говорите «в принципе». В принципе можно, и даже не очень сложно. А уж если бэк взломан, то тем более.
В принципе можно написать и
eval($_GET['id'])Прекрасная иллюстрация того, насколько дырявый PHP. Но вы же так не пишете, надеюсь?
Опять же не «в принципе», а зависит от того, как вы разрешения настроите.
Ну как бы да. А еще я могу выставить базу голой задницей в Интернет и даже без пароля.
Но мы же говорим о каких-то вменямых проектах, а не «настрой wordpress по гайду с двача»?
Кстати вопрос — а как вы планируете избежать инъекций повис в воздухе.
При том, что backend коннектиться как postgres и ВСЕ данные в схеме public.
Это я о своем опыте перехода с хранимок на node.js
Разговора, как их избежать не было, был разговор, что хранимки это принципиально безопасно.
Избегать так, как это обычно и делается — через использование драйвера, который поддерживает именованные параметры.
Т.е. для того, что возможно по определению в схеме "логика в БД" путем разделения данных и обработки, нужно внедрять дополнительные инструменты.
Получается так?
Ну а почему нет. Что и произошло.
То, что делал один DB-разработчик теперь делает 5 backend-разработчиков
Получается так?
Нет. Мой пример как раз и показывает, что никакого "по определению" нет. Что с логикой в БД, что с логикой не в БД, вам надо следить за SQL-инъекциями в запросах и экранировать параметры.
Никаких дополнительных инструментов тут нет. Подпрограмма, которой вы подключаетесь к БД из приложения и получаете результаты и есть драйвер БД. Без него вы не сможете ни хранимку вызвать, ни запрос выполнить. В каких-то старых драйверах может не быть поддержки именованных параметров, современные все поддерживают.
Вот смотрите, если клиент не может сделать select, инъекция возможна? Клиент имеет только один грант в одной конкретной схеме "execute"
Это, то, что я подразумевал под понятием "по определению", потому что, в этом случае логика в БД. И без разницы, какой драйвер.
Я ошибаюсь ?
Если только execute, то конечно. Но все равно можно использовать что-то типа CALL get_order(VERSION()) для получения информации о системе или вызова каких-то внутренних функций, которые напрямую вызываться не должны.
CALL get_order(makePremiumSubscriptionForUser(123));
Что и требовалось показать.
А каким образом вы собрались вызвать внутренние функции, если клиент имеет грант execution только в одной схеме БД ?
Ну я предположил, что где бизнес-процедуры, там и бизнес-функции. Не знаток прав доступа в СУБД, для вызова функций разве нужен не execute?
Однако
Я всегда предполагал, что есть бизнес процесс и бизнес функция.
Есть хранимая функция и хранимая процедура.
Что такое бизнес процедура, я не знаю.
По поводу прав.
Если, право на вызов функции даётся в одной конкретной схеме или вообще одну конкретную функцию, то клиент вообще никак штатно не сможет выполнить никаких других функций в принципе.
Что такое бизнес процедура, я не знаю.
Да вроде очевидно же, хранимая процедура, которая связана с бизнес-логикой. Так же как и бизнес-функция это функция, которая связана с бизнес-логикой. VERSION() это системная функция и с бизнес-логикой не связана, а makePremiumSubscriptionForUser() связана.
Если, право на вызов функции даётся в одной конкретной схеме
То клиент может вызывать функции, которые находятся в этой схеме. Если get_order() и makePremiumSubscriptionForUser() находятся в одной схеме business_logic, значит он может вызывать обе.
или вообще одну конкретную функцию
Ну вот создали новую функцию и забыли ограничить права. Раз их надо отдельно на каждую назначать, это вполне вероятно.
Если вы не знаток СУБД зачем спорите и что доказываете ?
Во-первых, я сказал, что я не знаток прав в СУБД. Во-вторых, я спорю и доказываю не на тему прав в СУБД, поэтому мое знание прав СУБД роли не играет. Мне достаточно того, что мой пример работает, а значит никакого "в принципе" нет. Нужно делать специальные действия, чтобы этого избежать, так же, как и с логикой не в БД. А при том, что некоторые специалисты БД вообще не сразу видят здесь проблему, хотя приведен рабочий код, то вполне вероятно, что и не предусмотрят такой вариант.
"Ну вот создали новую функцию и забыли ограничить права."
Мы что обсуждаем — особенности разработки промышленных информационных систем или студенческие курсовики?
Что значить забыл?
И без тестов на прод выложил?
И сколько такой горе разраб проживет в реальности?
А чем дискуссия вообще ?
Мы обсуждаем сложность поддержки кода, и как частный случай предотвращение SQL-инъекций. С логикой в БД в коде приложения нужно предпринимать те же самые действия по их предотвращению, как и с логикой в самом приложении. Поэтому с этой стороны никакой разницы нет.
А стремиться обходиться без SELECT, писать процедуру на любую выборку данных и раздавать на всё права, чтобы не использовать именованные параметры, мне кажется гораздо сложнее, чем просто использовать именованные параметры.
Конечно вам кажется сложным, если у вас нет опыта программирования в СУБД. Это обычное дело.
Для вас важна скорость разработки, хотя в данном случае у меня есть как минимум один пример обратного. Для меня безопасность данных это принципиально. Ибо каждая система ценнна настолько насколько ценны ее данные.
И ещё, сложности поддержи кода я не обсуждаю. Потому как не вижу сложностей.
Оно мне кажется более сложным по количеству действий, а не по тому, сколько чего там надо изучать.
Для меня безопасность данных это принципиально.
Ну так вот дело в том, что с бизнес-логикой в приложении данные тоже в безопасности. Вероятность, что взломают сервер, немного выше, чем что взломают БД, но это вопрос не принципиальный, а количественный. При правильной настройке окружения такого вообще не должно происходить. Мы же обсуждаем разработку промышленных информационных систем, а не студенческие курсовики.
Не ограничить, а назначить. Если забыли, прав на вызов ни у кого не будет. Поэтому забыть невозможно. Главное сознательно не давать права тем, кому они не положены
Клиент имеет только один грант в одной конкретной схеме "execute"
Чтобы использовать такой подход, надо сначала всех пользователей перенести в БД как пользователей БД. И тут-то выясняется, что СУБД в плане авторизации пользователей, к примеру, не умеют в SAML или там в OpenID Connect...
Но тогда никакой абсолютной защиты от инъекций система прав не даёт. Инъекции всё ещё возможны, просто они будут не давать пользователю абсолютные "права", а лишь расширять их до прав клиента.
1. Все запросы должны быть параметризованы
2. Frontend не должен иметь доступа к таблицам. Только View, Function, Procedure;
3. Каждый модуль проэкта иметь свою Application Role на доступ к View, Function, Procedure
4. Вся логика должна быть покрыта юнит-тестами и load тестами.
Это так, в кратце. Есть еще требования к написанию процедур и триггеров.
Вот, именно это я выше описал. Это ад, при хоть сколько-нибудь большом проекте.
Потому что вся работа с базой завязана на одно узкое место: команду dba.
Ладно бы, если вас было несколько десятков, но dba в всегда один и он ничего не успевает.
А ещё высшие степени вроде "вся, каждый" и так далее намекает на далекость от реального мира промышленной разработки :)) всё то каждый не окупается, всегда должен быть баланс между затратами и выхлопом, чтобы бизнес деньги заработал
3) Прекрасно делается ролевой доступ по записям и полям вне базы. Фильтрация данных же перед запросом…
Если хранимая процедура написана примерно так
CREATE OR REPLACE FUNCTION get_order(p_id number)
...
select * into order from orders where id=p_id;
....
то можно пытаться инжектить сколь угодно.
Прочитайте пример внимательнее. Там нет динамического SQL в процедуре, там вообще неважно, как она написана, уязвимость возникает при вызове процедуры из приложения. Если у вас в приложении данные не экранируются (то есть присутствует SQL-инъекция), то в параметр p_id попадет результат SELECT, который выполняется до вызова процедуры.
Если при этом ему разрешено делать SELECT, то возможны.
Select-ы если и разрешаются, то на определенные таблицы/view и возможно даже с ограничениями по строкам.
А если выставлять наружу полный доступ к БД то не надо удивляться к инъекциям.
У меня запрос не ко всей базе, а к одной таблице пользователей.
Наружу никто и не выставляет, в моем примере доступ разрешен приложению на сервере.
Я серьезно не понимаю, с какой целью надо разрешать SQL-инъекции в приложении и пытаться от них защититься настройкой всего и вся, рискуя где-нибудь что-нибудь забыть и получить дыру в безопасности. Именованные параметры в приложении защищают от SQL-инъекций гарантированно и сложностей в использовании не имеют.
Будете ли вы потом настраивать доступ к процедурам, это дело десятое. Разговор был о том, защищают ли хранимые процедуры от SQL-инъекций и доступа к тому чему не надо. Ответ — нет, не защищают. Защищают права доступа, с этим никто и не спорил.
Так в моем пример ничего в обход процедуры не меняется, нужен доступ только на чтение. Тем более вместо SELECT там можно функцию какую-нибудь, к которой есть доступ, использовать нестандартным образом. Я согласен, что если всё закрыть, то SQL-инъекция ничего особенного не сделает, но это не то же самое, что "в принципе", с которого начался разговор. От SQL-инъекций можно и в приложении закрыться, и гораздо проще.
get_orders(). Можете удостовериться, что никакого динамического SQL в ней нет.<?php
$pdo = new PDO('mysql:host=localhost', 'root', 'root', [PDO::ATTR_ERRMODE => PDO::ERRMODE_EXCEPTION]);
// init
// $pdo->exec("DROP DATABASE app_database");
try {
$pdo->exec('USE app_database');
} catch (PDOException $ex) {
$pdo->exec("CREATE DATABASE app_database");
$pdo->exec("USE app_database");
$pdo->exec("CREATE TABLE orders (id INT PRIMARY KEY, name VARCHAR(20))");
$pdo->exec("CREATE TABLE users (username VARCHAR(20) PRIMARY KEY, password_hash VARCHAR(20))");
$pdo->exec("INSERT INTO orders (id, name) VALUES (1, 'Order 1'), (2, 'Order 2')");
$pdo->exec("INSERT INTO users (username, password_hash) VALUES ('admin', 'qwerty'), ('user', 'abcdef')");
$sql = "
CREATE PROCEDURE get_orders(IN order_id INT)
BEGIN
SELECT * FROM orders WHERE id = order_id;
END
";
$pdo->exec($sql);
}
// business logic
$id = $_GET['id'] ?? 0;
$sql = "CALL get_orders(" . $id . ")"; // intended SQL-injection
$stmt = $pdo->prepare($sql);
$stmt->execute();
$row = $stmt->fetch();
if (empty($row)) {
echo 'Order not found';
} else {
echo 'ID: ' . $row['id'] . ' | Name: ' . $row['name'];
}
Запуск:
php -S 127.0.0.1:8080 code.php
Далее открываем ссылки:
http://127.0.0.1:8080/code.php?id=1
http://127.0.0.1:8080/code.php?id=2
http://127.0.0.1:8080/code.php?id=(SELECT 1 FROM users WHERE username='admin' AND password_hash LIKE 'a%')
(заказ не найден)
http://127.0.0.1:8080/code.php?id=(SELECT 1 FROM users WHERE username='admin' AND password_hash LIKE 'q%')"
(заказ найден)
http://127.0.0.1:8080/code.php?id=(SELECT 1 FROM users WHERE username='admin' AND password_hash LIKE 'qa%')
(заказ не найден)
http://127.0.0.1:8080/code.php?id=(SELECT 1 FROM users WHERE username='admin' AND password_hash LIKE 'qw%')
(заказ найден)
На правильных символах хеша пароля администратора заказ открывается, на неправильных нет.
Отсюда вывод — бизнес-логика в хранимых процедурах не защищает от SQL-инъекций в приложении. Надо использовать именованные параметры в любом случае.
$id = $_GET['id'] ?? 0;
$sql = "CALL get_orders(" . $id . ")";
То при
$id="(SELECT 1 FROM users WHERE username='admin' AND password_hash LIKE 'qw%')"Результирующая строка у вас будет следующей:
CALL get_orders((SELECT 1 FROM users WHERE username='admin' AND password_hash LIKE 'qw%'))То есть сначала у вас выполниться вложенный запрос
(SELECT 1 FROM users WHERE username='admin' AND password_hash LIKE 'qw%')То есть сначала у вас выполниться вложенный запрос
Инъекция происходит как раз на уровне PHP
Я знаю, в предыдущем комментарии я именно это и написал:
"уязвимость возникает при вызове процедуры из приложения"
"Если в приложении данные не экранируются, то в параметр p_id попадет результат SELECT, который выполняется до вызова процедуры."
И именно поэтому даже с хранимыми процедурами SQL-инъекции все равно существуют и все равно представляют опасность. Потому что от приложения, которое читает из базы и в котором происходит подстановка данных пользователя в запрос, вы избавиться не можете. А значит в приложении все равно надо принимать меры для их предотвращения (использовать связывание переменных), поэтому с этой точки зрения никакой разницы, где находится логика, нет. Наверно в третий раз уже это объясняю.
$id = $_GET['id'] ?? 0;
$sql = "CALL get_orders(" . $id . ")";
$pdo->exec($sql);
На что-то в таком духе:
$id = $_GET['id'] ?? 0;
$sql = "CALL get_orders(:id_param)";
$pdo->bindParam(':id_param', $id , PDO::PARAM_INT);
$pdo->exec($sql);
Результаты останутся теми же?
Ну одно да потому. Да, со связыванием переменных результаты будут другими, это именно то, для чего я и придумал этот пример. Почему вы решили, что я не понимаю, как он работает?
Я привел этот пример в ответ на утверждение:
"А по существу — аргумент всего один. В БД переносится только бизнес-логика, а не вся логика целиком. Взломанный бэк просто в принципе не может дропнуть базу или прочитать те данные, которые ему знать не положено."
Основной метод чтения "данных, которые ему знать не положено" — это SQL-инъекция. Мой пример показывает, что даже если бизнес-логика в БД, то все равно существует возможность использовать SQL-инъекцию для чтения данных, которые знать не положено. Думаете хакер, который взломал бэк, будет связывание переменных использовать?
"даже если бизнес-логика в БД, то все равно существует возможность использовать SQL-инъекцию для чтения данных, которые знать не положено" — в случае если DB разработчик предоставил клиенту привилегию SELECT. А если только execute + row level security? Что будет делать хакер после взлома backend?
Я же согласился с вами в другой ветке, что в этом случае SQL-инъекция опасности не представляет. Но для этого надо регистрировать весь миллион пользователей через движок аутентификации СУБД и следить за тем, чтобы всем были назначены нужные права на нужные объекты.
Но кроме SQL-инъекций может быть просто неправильный ввод. Вводит пользователь строку с кавычкой, и получает ошибку, потому что в запросе такие же кавычки для строковых аргументов процедуры. То есть данные все равно надо экранировать или передавать через именованные параметры. А если это делать, то и SQL-инъекций не будет, и все равно хакер не прочитает данные, которые знать не положено.
Опять же, вон LinguaLeo сделали логику в базе, а у них все равно уязвимости есть. Может права нужные не назначили, может что-то не предусмотрели, хотя вроде делали специалисты по БД. То есть тоже не гаранития и не "в принципе". И вот здесь уже повяляется вопрос подключения биюлиотек для валидации, предотвращения CSRF и т.д.
Вероятность взлома сервера выше, чем вероятность взлома базы, но в большинстве случаев упрощение поддержки и масштабирования это более важный критерий.
В результате приходим опять к тому же выводу — дискутировать том хорошо или плохо хранить бизнес логику в БД тоже самое что рассуждать о мести сферического коня в вакууме. Смысла никакого.
У меня например проект максимум 1000 пользователей, QPS максимум 100.
На кой мне весь этот зоопарк в backend если PostgreSQL отлично справляется с запасом и по безопасности и по FTS, и по логирование и по обработке Json.
Ну одно да потому. Да, со связыванием переменных результаты будут другими, это именно то, для чего я и придумал этот пример. Почему вы решили, что я не понимаю, как он работает?
Я не говорил о вашем понимании или непонимании. В вашем примере возможность чтения «данных, которые ему знать не положено» отнесена к недостаткам SQL, в то время, как это недостаток избранного вами метода формирования запроса, который вы передаете СУБД. Аналогичным образом вы можете передать в функцию eval() код, полученный из входного строкового параметра и попенять на то, что у вас возникла возможность выполнения произвольного кода. Но претензии ведь не к eval(), а к методу его использования.
Я привел этот пример в ответ на утверждение:
«А по существу — аргумент всего один. В БД переносится только бизнес-логика, а не вся логика целиком. Взломанный бэк просто в принципе не может дропнуть базу или прочитать те данные, которые ему знать не положено.»
Опять-таки могу предложить вам модифицировать ваш пример так, чтобы во входной строке был не запрос на выборку данных, а какой-либо DML-оператор, и посмотреть на результат.
Основной метод чтения «данных, которые ему знать не положено» — это SQL-инъекция. Мой пример показывает, что даже если бизнес-логика в БД, то все равно существует возможность использовать SQL-инъекцию для чтения данных, которые знать не положено. Думаете хакер, который взломал бэк, будет связывание переменных использовать?
В этом утверждении я могу частично согласиться с вами, но что значить «хакер взломал бэк»? Если хакер путем формирования запросов выполнил произвольный SQL, то мы возвращаемся к вопросу о том, что параметры в БД надо передавать через связывание. Если же хакер имеет доступ к приложению, то скорее всего ему известны учетные данные подключения к БД и тут ситуация такова, что вопрос совсем не к использованию или неиспользованию хранимых процедур.
Я не говорил о вашем понимании или непонимании.
Говорили. В предыдущем комментарии вы рассказывали, как работает мой пример, значит почему-то решили, что я этого не понимаю.
В вашем примере возможность чтения «данных, которые ему знать не положено» отнесена к недостаткам SQL, в то время, как это недостаток избранного вами метода формирования запроса, который вы передаете СУБД.
С чего вы так решили? Я нигде не говорил, что это недостаток SQL. Я сказал, что логика в процедурах не защищает от SQL-инъекций, и от них все равно надо защищаться в приложении. То есть, что у SQL здесь нет премущества перед логикой в приложении, которое ему почему-то приписывают. Отсутствие преимущества, а не недостаток.
SQL-инъекция это по определению недостаток метода формирования запроса. А формирование запроса происходит в приложении в обоих подходах.
Опять-таки могу предложить вам модифицировать ваш пример так, чтобы во входной строке был не запрос на выборку данных, а какой-либо DML-оператор, и посмотреть на результат.
Зачем? Разгвоор был про "прочитать те данные, которые ему знать не положено", про это и есть пример.
Чтение хеша пароля администратора это достаточно серьезная уязвимость, чтобы задуматься о предотвращении SQL-инъекций, даже если DML нельзя выполнять.
Если хакер путем формирования запросов выполнил произвольный SQL, то мы возвращаемся к вопросу о том, что параметры в БД надо передавать через связывание
Да. Именно поэтому никакой разницы в методах предотвращения SQL-инъекций в приложении нет, поэтому это не является плюсом подхода "логика в БД".
Поэтому реализация бизнес-логики на сервере БД более безопасна.
… а потом нам надо будет добавить в эту систему список всех пользователей с возможностью фильтрации и сортировки по любой колонке. Ваши предложения?
view или функция, возвращающая курсор.
Мне казалось, для них все равно нужен SELECT, нет?
Естественно, доступная только с высшими привилегиями доступа.
Гм, а на основании чего определяются привилегии?
Естественно, не возвращающая критичные поля вроде хеша.
На фоне персданных пользователей (соленые) хэши их паролей — мелочи.
Если персданные критичны, то они не возвращаются функцией, потому что критичны и видеть их в списке никому не требуется.
К чему вы клоните своими вопросами?
Если персданные критичны, то они не возвращаются функцией, потому что критичны и видеть их в списке никому не требуется.
Что значит — не требуется? Администратор вполне может их видеть, может ему надо поискать пользователя по их сочетанию.
К чему вы клоните своими вопросами?
К тому, что не очень понятно, почему реализация бизнес-логики на сервере БД более безопасна, чем ее же реализация на сервере приложений.
Если, конечно, вы не проксируете пользователя прямо в БД.
Раздавать всем права вручную не кажется мне более безопасным, потому что при управлении вручную есть вероятность ошибки. Особенно если появляются сложные правила вида "младший менеджер может утверждать документы, если его начальник в отпуске".
Кроме того, от SQL-инъекций все равно надо защищаться в приложении, чтобы запрос не падал при введении пользователем строки с кавычками. Поэтому с этой точки зрения никакой разницы где находится логика нет.
Чем что? Права в конечном итоге всегда раздаются вручную. Вопрос только в том, какие абстракции имеются в системе управления правами.
Только пользователи и роли СУБД или дополнительный контроль доступа в ядре системы, который может реализовать контроль доступа на более сложном логическом уровне, чем колонки и записи таблиц. Например права назначаются на единицу штатного расписания, и конкретный человек получает доступ в момент выполнения приказа о назначении в отделе кадров. А сам набор доступов состоит из логических прав на просмотр и изменение справочников и документов системы, а не конкретных таблиц.
При условии инкапсуляции данных в API СУБД, это все реализуется однократно в серверной части и автоматически соблюдается любыми клиентами: windows, веб, мобильные приложения и т.п.
Что касается «защиты от инъекций», это проблема программистов-школьников, которая даже не достойна упоминания. Обращение в СУБД с использованием литералов недопустимо за редчайшими обоснованными исключениями. И главные причины строгого использования bind-переменных — это плохое влияние литералов на общую производительность СУБД и проблемы совместимости форматов чисел и дат. Если формат даты или разделитель числа на сервере СУБД и в вызывающем приложении разойдутся, то будут сбои или, хуже того, параметры будут интерпретированы неверно.
При условии инкапсуляции данных в API СУБД, это все реализуется однократно в серверной части и автоматически соблюдается любыми клиентами: windows, веб, мобильные приложения и т.п.
Ровно то же самое будет, если вы инкапсулируете правила безопасности в прикладном сервисе и запретите доступ в БД чему-либо кроме этого сервиса.
Ну и во-вторых, зачем тащить это на бекенд со всеми его недостатками, когда это отлично делается в базе, никаких красивых фреймворков, менеджеров зависимостей, синтаксических сахаров не надо для таких задач.
Таким образом убирается лишняя точка отказа, причем очень вероятного отказа.
Не ровно то же, потому запретить доступ всему кроме конкретного сервиса в общем случае нельзя.
Что такое "в общем случае"? В общем случае много чего нельзя.
наешь логин/пароль, ip не забанен — добро пожаловать в базу делать ad hoc sql нарушая все правила бекенда.
Вот только доступа по IP нет, потому что СУБД в своей собственной сети, в периметре которой только аппликейшн-сервер и точка входа для администратора. И логина/пароля тоже нет, потому что вход по какому-нибудь аналогу integrated security.
когда это отлично делается в базе
Что "это"?
никаких красивых фреймворков, менеджеров зависимостей, синтаксических сахаров не надо для таких задач.
Каких задач?
Таким образом убирается лишняя точка отказа, причем очень вероятного отказа.
А в случае, когда у вас нет бизнес-логики в БД у вас убирается точка отказа в виде кода в БД. И это, заметим, тоже весьма вероятный отказ (судя, по крайней мере, по моему личному опыту).
не кажется мне более безопасным
Чем что?
Это вы написали "более безопасна", не знаю, что вы под этим подразумевали. Я предположил, что речь идет про логику в базе и логику в коде.
Права в конечном итоге всегда раздаются вручную.
Ага, только когда логика в коде, пользователь кода в принципе не может прочитать или вызвать никакие таблицы, вью, функции или процедуры. У него нет прямого доступа в БД, в отличие от вашего варианта. Поэтому и права на них настраивать не надо и следить за их соблюдением.
При условии инкапсуляции данных в API СУБД, это все реализуется однократно в серверной части и автоматически соблюдается любыми клиентами: windows, веб, мобильные приложения и т.п.
Ну так с логикой не в БД все то же самое — все реализуется однократно в API, а windows, веб, мобильные приложения и т.п. используют это API.
Что касается «защиты от инъекций», это проблема программистов-школьников, которая даже не достойна упоминания.
"Защита от инъекций" это то, с чего началась эта ветка, это основная сущность, которую тут надо упоминать.
Обращение в СУБД с использованием литералов недопустимо за редчайшими обоснованными исключениями.
Я знаю, я именно это и написал. И именно поэтому логика в базе этот аспект безопасности приложения никак не улучшает.
Ага, только когда логика в коде, пользователь кода в принципе не может прочитать или вызвать никакие таблицы, вью, функции или процедуры. У него нет прямого доступа в БД, в отличие от вашего варианта. Поэтому и права на них настраивать не надо и следить за их соблюдением.
Чаще всего консистентность данных в базе разрушается не пользователями, а программистами, которые допускают ошибки в бекенде или руками правят данные в базе или запускают некорректные скрипты пакетной обработки. И вот от этого всего защищают бизнес-правила инкапсулированные в БД в виде FK, констрейнов, триггеров или полного запрета на DML и замену его процедурами изменения данных, которые контролируют их согласованность.
И если этого не делать, то сами программисты бекенда потом вынуждены в коде делать кучу лишних проверок и обработчиков неконсистентных данных. Документов без строк, ссылок на несуществующие или неактуальные элементы справочников, запросы, возвращающие несколько записей, когда по логике должна быть одна, неуникальная нумерация (буквально на той неделе столкнулись в смежной системе) и т.п.
Потому что все эти неконсистентности в данных обычно никто не правит или просто не может выловить, откуда они появляются.
И как тут уже кто-то писал, начинаются ежедневные запуски процедур пересчета регистра остатков, и прочие чисто технические обработки, которые мусор под ковер заметают.
Поэтому НУЖНО бизнес-логику, относящуюся к консистентности, контролировать в БД и приходится обрезать права всем, кто обращается в БД, в том числе бекенду.
Чаще всего консистентность данных в базе разрушается не пользователями, а программистами, [....] от этого всего защищают бизнес-правила инкапсулированные в БД в виде FK, констрейнов, триггеров или [...] процедурами изменения данных
А констрейны, триггеры и процедуры изменения данных не программисты пишут?
Не вижу логической связи.
Вы писали "Права раздаются вручную, поэтому реализация бизнес-логики на сервере БД более безопасна."
Я написал "Раздавать всем права вручную не кажется мне более безопасным.".
или руками правят данные в базе
Ну когда логика в базе, то да, программисты постоянно что-то правят руками в базе. Когда логика в коде, руками лазить в продакшн-базу запрещено. Если где-то не запрещено, значит там кривой код и плохая организация разработки. Работал я на таком проекте, говорю из опыта.
Чаще всего консистентность данных в базе разрушается программистами, которые запускают некорректные скрипты пакетной обработки
У вас программисты запускают непротестированные скрипты пакетной обработки на продакшн-базе? Ну тогда проблема в организации разработки, а не в том, где находится логика. Хотя я вполне допускаю, что при логике в базе такие ошибки более вероятны, потому что сложно организовать отдельную тестовую среду, идентичную продакшену.
И вот от этого всего защищают бизнес-правила инкапсулированные в БД в виде FK, констрейнов, триггеров или полного запрета на DML и замену его процедурами изменения данных, которые контролируют их согласованность.
А вот с логикой в коде от всего этого защищают классы, функции и API.
Что у вас защищает от ошибок запуска некорректно написанной процедуры? Если ничего, тогда нет совершенно никакой разницы с запуском некорректного скрипта пакетной обработки с логикой.
И если этого не делать, то сами программисты бекенда потом вынуждены в коде делать кучу лишних проверок и обработчиков неконсистентных данных.
Потому что все эти неконсистентности в данных обычно никто не правит или просто не может выловить, откуда они появляются.
Ну у вас возможно так. А обычно с логикой в коде неконсистентные данные в базе не появляются. А если уж появились, то пишется программа их исправления, а не их обработка в логике.
Документов без строк, ссылок на несуществующие или неактуальные элементы справочников
Если документы без строк запрещены, то в коде есть на это проверка, и некорректные данные в базу не попадают.
Для того, чтобы не было ссылок на несуществующие строки таблиц, есть FOREIGN KEY. Даже если логика в коде, то никто не запрещает их использовать.
Поэтому НУЖНО бизнес-логику, относящуюся к консистентности, контролировать в БД
Нет, нужно правильно писать логику. Если данные в базе неконсистентны, значит логика их помещения туда неправильная. Размещение неправильной логики в процедурах не сделает ее волшебным образом правильной. А если программисты не умеют пользоваться транзакциями, проще их один раз научить, чем постоянно поддерживать логику в БД.
А теперь пытаемся распространить этот подход на таблицу с гридами, которые можно фильтровать и сортировать по любой колонке.
Проверка данных на фронте вместо констрейнтов это странно, но некоторые именно так и поступают .
Так, а с тестами как? Не нужны? БЛ не тестируют?
Плюс вчера уже была статья про доступ к «защищенному» бэку, когда база спокойно отдала хэши паролей, соль и другие вещи других юзеров.
А если у меня все данные не помещаются на один сервер?
Или если процессорных мощностей одного сервера не хватает?
А если у меня приложение должно работать в 30 региональных экземплярах расположенных по всему миру?
Оказывается, что база данных никаким образом не может хранить и энфорсить всю бизнес логику моего приложения. Значит, мне придется либо часть логики класть в базу, а часть оставлять в "фронтенде", либо уже сдаться и использовать базу просто как коробочку для строк. К тому же таких коробочек у меня десятки в каждом экземпляре приложения. А всю логику поддержания целостности данных реализовать снаружи. Более того, по мере развития моего приложения, я могу менять выбор базы данных, мигрировать на другие движки, которые например дешевле. Ведь платить за работу 200 баз данных довольно дорого и если я сэкономлю 20% миграцией на другой движок, руководство это вполне одобрит.
Но это конечно специфический пример, просто, чтобы показать, что не всегда можно всю бизнес логику положить в базу. Мы же тут собрались как писатели глобальных стартапов на миллиарды пользователей? :))
А что если ваш фронт нужно горизонтально масштабировать, а что если он от базы отваливается по сетевым причинам?
На счет миграции, это кончено хорошая мантра, но в реальных проектах оно так не работает. От миграции движка базы отказываются до тех по пока это возможно, а потом миграция вопреки замечательной мантре про ORM требует огромного кол-ва ресурсов и очень трудоемка, я бы сказал что по затратам еще вопрос что дешевле, сменить движок субд с логикой в субд или с логикой за ее пределами.
Если у нас проект с не высокой нагрузкой, миграция между стораджами особо ему не нужна, его вытянет любой сторадж. Если же архитектор увлекается миграцией ради модных технологий, от него лучше держаться подальше.
Если же у вас проект близкий к хайлоад( чтобы это не значило ), т.е. вы уперлись в сторадж и штатные методы для его оптимизации исчерпаны. То миграция на другой сторажд, вместе с миграцией данных, в любом случае будет болью, которая потребует заметно переработки в том числе и кода, включая костыли для поддержки нескольких версий, а так же костыли необходимы для миграции без остановки сервисов.
Так что, если вы ПОСТОЯННО в рамках одного проекта прыгаете с одного стораджа на другой и у вас этот процесс не требует ресурсов, то вероятно вы зря прыгаете.
Хотя кончено бывают исключения и я заранее извиняюсь если я их не учел, было бы интересно про них прочитать на примере реальных проектов.
Так выгнали, приходит новый и говорит "нужно менять СУБД" :)
А миграция между стораджами может дать фичи, доступные в одном и недоступные в другом, что может изменить скорость некоторых операций на порядок.
Изменение скорости операции на порядок, чаще всего, говорит о том, что или изначально радикально промахнулись со стораджем или недостаточно квалификации у специалистов с этим самы стораджем работающих.
Вообще смена стораджа практически ни чем не отличается, с точки зрения причин, от смены платформы, вы же не пытаете раз в месяц все перенести с .net на java, а потом на go.
При этом же вам станут доступны фичи не доступные в одном и доступные в другом, а скорость некоторых операции может возрасти на порядок.
В разные этапы жизни продукта некоторые используемые фичи одного стораджа могут оказаться не важны или менее важны чем фичи другого. Просто фичу из продукта выкинули или вынесли данные для неё из стораджа, например, разделили OLTP и OLAP
Причины может и те же на высоком уровне ("А не позволяет нам эффективно сделать Х, а Б позволяет"), но вот стоимость перехода может сильно отличаться, особенно если целенаправленно или даже случайно были предприняты меры уменьшения для разделения зависимости от вендора.
Смена стораджа в любом крупном проекте это сложная задача, ее сложность, особенно в разрезе того, что у вас судя по комментариям выше десятки тысяч строк логов в секунду, умножается на кол-во данных которые вам требуется целостно смигрировать.
И по сложности эта задача, особенно на проектах с большим количеством данных сопоставима с миграцией на другой стэк( не такая же, но это величины одного порядка ).
Сложность смены одного SQL стораджа на другой напрямую зависит от того насколько код (хоть в хранимках, хоть в обычный) зависим от вендора. Как-то так получается, что при активном использовании средств DBAL в обычном коде, он гораздо более портабелен чем хранимки.
Более того, на моём личном опыте, даже если средств DBAL не используется, то гораздо проще мигрировать чистый SQL, а не хранимки, триггеры и т. п.
Комментарий выше относился к проектам в которых имеет смысл смена хранилища.
Вероятно это крупные проекты, с большим кол-во оптимизаций. Смена хранилища в мелком проекте не вызывает существенных проблем вне зависимости от стэка, главное чтобы у мигрирующих квалификации хватило.
Если мы говорим о крупном проекте с большим кол-во оптимизаций под хранилище, смена хранилища в нем в любом случае является крайне сложной задачей.
Безусловно код мигрировать вероятно будет проще, но нельзя сказать, что это не сравнимы по сложности величины.
Исходя из этого, я считают аргумент про возможность миграции несколько надуманным, в простых случаях она не имеет смысла, в сложных она в любом случае крайне затруднена.
Никто не говорит про ПОСТОЯННЫЕ миграции, но даже одна миграция в человеко-годы это дорогое удовольствие.
В каждом большом эволюционирующем проекте постоянно приходится пересматривать, где что хранится. И мигрировать.
Я здесь вижу и постоянно и мигрировать.
Да, миграция в человеко годы это дорогое «удовольствие». Она в любом случае дорогое «удовольствие», что с логикой в базе, что с логикой в мидл слое. Если у вас миграция не является дорогим удовольствием, очень вероятно, что она вам не нужна.
Ну пересматривать приходится. Не обязательно это приводит к переезду. И не обязательно хранилище это БД. Иногда это какие-нибудь кэшеры. Иногда эластики.
Она в любом случае дорогое «удовольствие», что с логикой в базе, что с логикой в мидл слое.
Нет, с логикой в бекенде оно не дорогое, я вам живой пример дал, буквально за пару недель смигрировали без каких-либо проблем.
Да, это проще решается на языках высокого уровня. Но на них же проще и угробить весь смысл такой конфигурации.
Ну я тоже могу придумывать требования на ходу. Например, вам надо пройти сертификацию на PCI DSS.
Или у вас обрабатывается финансовая информация и вам нужна 100% транзакционность: любой запрос от клиента либо будет выполнен полностью либо полностью отклонен. Любые потери данных недопустимы. Любой ответ должен содержать актуальные на момент ответа данные. Вы все ещё захотите хранить что-то в Redis?
У меня такое же впечатление сложилось от статьи.
Мне кажется, что автор никогда особо с хранимыми процедурами не работал. Слышал… но не работал.
Ответ зачем нужны хранимые процедуры и в каких случаях и что они дают тянет на отдельную статью.
Я правда больше по PL/SQL Oracle, а не plpgsql. Но подозреваю, что разница небольшая.
Но так… по мелочам:
если записывать все изменения хранимок как новый CREATE OR REPLACE PROCEDURE, то на кодревью будет ад: всегда новый файл, который непонятно с чем сравнивать.
Эта фраза вообще не понятна. Чем отличается код в git для php, java, python и любой любого другого языка от языка хранимых процедур (тела пакета как текстовой файл в git)?
Не понял этого заявления от слова "совсем". Это же не бинарные файлы!
И, кстати, нормально из git накатывается на бд…
В мире pl/pgsql нужно страдать. В этом языке просто нет менеджера зависимостей.
Зависимости от чего? назначение процедур — выполнение каких то атомарных действий бизнес логики. То же касается фремворков… какие еще фремворки? Атомарные действия, очень желательно без внутренних промежуточных commit, и фремвоки как то мало совместимы.
Сложно даже представить, как удобно организовать unit-тесты в хранимках на pl/pgsql. Я ни разу не пробовал. Поделитесь пожалуйста в комментариях.
unit тесты на языке встроенных процедур, мне кажется, никто не пишет. Хотя могу и ошибаться, но, на мой взгляд, это просто неудобно. Для этого хорошо идут unit тесты на middle слое (на java|python и пр.)
Хотя, если нет middle слоя, то выполнить (ну на PL/SQL Oracle например) процедуру (без CREATE) на лету в sqlplus не проблемно.
Сравните две функции, которые делают одно и то же на php и pl/pgsql
Кстати, это то же показательно то что выбрано в качестве сравнения.
Императивный стиль в пакетах — это на крайний случай. Все же SQL это декларативный язык и появление функции в том виде как привел автор "FUNCTION sum(x int, y int)" это признак что то не то с архитектурой ПО. Так не делают… Типичный пример как не должен выглядеть код пакета с точки зрения производительности.
Все же не понимаю, зачем высказывать свое мнение статьей если никогда в теме не работал.
Поднять хайп и заработать карму еще одной статьей?
Вы будете тесты руками запускать каждый раз при изменении бизнес-логики?
Вы понимаете, что декларативность в SQL — это хорошо и мощно для очень узкого круга задач, но мир разработки пошёл другим путём оставив языки запросов, регулярки и штуки типа Prolog вне области описания бизнес-логики? И это произошло не потому, что люди просто не понимали или не были готовы к вызовам, а из-за банального удобства и выразительности выше уровня конца 80х.
В статье, кстати, описаны плюсы хранимок и их применимость.
Вы будете тесты руками запускать каждый раз при изменении бизнес-логики?
Я немного не понял… А что unit тесты они какой то магией запускаются?
И тесты пишутся под изменение бизнес логики. И запускаются как минимум руками (разработчиком или тестировщиком). И даже если они запускаются "как бы автоматически" (maven например), то это все одно "руками", а не магией.
Я опять же не понимаю, в чем разница запуска тестов на одном языке (java, python и т.д.) от запуска тестов на другом языке (PL/SQL например).
мир разработки пошёл другим путём оставив языки запросов
Точно такой же довод "мир разработки пошел.." я слышал от человека, который "знает" как использовать "магию" jpa в spring boot. Причем он до конца не понимал, что под капотом hibernate все тот же язык sql.
Это, кстати, совсем не означает, что я не использую все эти удобства. Но прекрасно осознаю что под капотом.
К слову, ср… ч на тему в каком месте лучше держать бизнес логику "в БД во встроенных процедурах и представлениях" или в "middle слое" я принципиально не поддерживаю.
Приходилось делать и так и так.
И вообще, обычно определяется не "высшими соображениями", а банально сочетанием и специализацией разработчиков в конкретном проекте, сроками проекта, кодовой базой и другими объективными причинами.
Я опять же не понимаю, в чем разница запуска тестов на одном языке (java, python и т.д.) от запуска тестов на другом языке (PL/SQL например).
Юнит-тесты на java, python и т. п. — стэйтлесс, просто команду в консоли запустить. На PL/SQL нужно развернуть базу в ожидаемое тестами состояние, включая актуальные версии тестируемых процедуры.
stateless unit unit тест, предполагающий работу, например, java модуля с внешними данными из БД, то же предполагает что эти данные заранее подготовлены (прямо в БД или через различные механизмы эмуляции источника).
Ничем принципиально не отличается от такого же теста, при котором на тестовой схеме БД накатывает и слепок данных и тестируемые пакеты.
И то же, в принципе, команду запустить (sqlplus c указанием файла. ну или шел, в котором предварительно из git забирается)
И это даже если не пользоваться инструментами, а все писать руками.
Вся разница только в том, что unit тест java выполняется в JVM, в PL/SQL тест в Oracle DB окружении.
Юнит тест не может предполагать работу модуля с внешними данными по определению, это уже интеграционный тест.
не буду спорить о терминологии.
Тест, который проверяет работу изолированного модуля на пред подготовленных детерминированных данных, входящих в состав теста я оформляю как юнит тест (org.junit) и называют "unit тест".
Данные при этом могут и из физической БД браться/заливаться в рамках теста (иногда и так) и подсовываться через интерфейсы… от задачи зависит.
Хочется называть это интеграционным — да пожалуйста. Не принципиально. Все одно всегда приходится от терминологии договариваться с новыми людьми..
Авто тесты запускаются из Team City по коммиту в ветку релиза. Для Оракла есть utplsql для написания тесто.
Есть куча проектов, где бизнес логика зашита в PLSQL. Это позволяет сильно повысить безопасность, скорость разработки и производительность. Некоторые вещи без хранимок просто не получается сделать.
unit тесты на языке встроенных процедур, мне кажется, никто не пишет
Я, к примеру писал. Правда это было больше 10 лет назад и на Oracle. Ничего особенного. Пишешь тестовый скрипт для каждого модуля и прогоняешь при изменении. Структура корпоративной базы данных ведь не каждый день меняется (если нормально спроектирована) — для этого надо чтобы структура бизнеса поменялась. А в этом случае запуск тестового скрипта — далеко не самая большая проблема фирмы.
"Можно обложить echo"
Можно обложиться Raise Notice
В чем разница ?
class UserController
{
function makeSomethingAction()
{
...
echo "run f1()\n";
f1($v1, $v2, g($v3));
echo "run f2()\n";
f2($v4);
echo "run f3()\n";
f3();
echo "done\n";
}
}
GET /user/make-something?params...
// output
run f1();
run f2();Пишем echo, обновляем страницу, в ответе от сервера видим, что падение возникает при вызове f2(). От изменений до получения результата одно промежуточное действие, которое и так всегда делается при изменениях.
Как это будет в вашем варианте?
:-)
Да никакой разницы
Вызываем хранимую функцию
psql -с " select func()"
Смотрим вывод
Какой такой psql -с? Мы отлаживаем GET-запрос в браузере. На сайте есть страница, она не работает. Мы добавили echo/raise notice в код бизнес-логики. Что дальше, какие действия в вашем примере?
Удивляет меня логика любителей логики в БД. Был задан вопрос "в чем разница", я привел конкретный пример, который показывает, в чем разница. Вежливо написал и вежливо задал вопрос, на который не получил ответа. Вам сложно признать, что в описанном кейсе с хранимыми процедурами больше действий требуется? Нет, признавать мы не будем, приводить аргументы для обратного мы тоже не будем, будем ставить минусы.
Если у вас код бизнес логики прямо в ее представлении у меня для вас плохие новости, так делать не надо.
Вы на вопрос-то ответьте, не надо теоретизировать.
У вас для вызова кода логики используется браузер. Оставим в стороне корректность такой декомпозиции.
Вы вызываете метод браузером и смотрите «std out».
При использовании хранимых процедур их вызов производится путем подключения к базе.
Вы так же вызываете ваш метод и смотрите его output.
В значимости от реализации клиента можно смотреть как различные «echo», так и использовать промежуточные select внутри процедуры.
Разницы вообще никакой не будет.
У вас для вызова кода логики используется браузер. Оставим в стороне корректность такой декомпозиции.
В любом веб-приложении с интерфейсом пользователя для вызова кода логики используется браузер.
При использовании хранимых процедур их вызов производится путем подключения к базе.
Пользователь веб-приложения подключается к базе?
Разницы вообще никакой не будет.
Ну давайте я еще раз опишу этот кейс, раз вы на вопрос не ответили. Есть страница на сайте с ошибкой. Для конкретности давайте возьмем отправку формы на 10 полей. Если логика в коде, мы пишем echo в разных местах логики, обновляем страницу и проверяем вывод. Всё, это все действия. При этом неважно, как организовано приложение, MVC на сервере или API с SPA, вызов API тоже можно открыть в отдельной вкладке. Какие действия будут, если логика в БД? Мы написали raise notice, а дальше что?
Если обновить страницу, никакого вывода raise notice на странице не будет, значит разница определенно есть, значит ваше утверждение неверно.
Пользователь веб-приложения подключается к базе?
Пользователь веб приложения не отлаживает веб приложения, ему вообще странно видеть
run f1();
run f2();
Если вы отлаживаетесь во фронтэнде, то все абсолютно так же, только вместо вызовов f1, f2, f3 у вас идут вызовы хранимых процедур.
Если вы отлаживаете бэкэнд, то вместо вызова api, вы подключаетесь к базе и взываете хранимую процедуру.
Хранимая процедура так же как и вызов api формирует output в котором вы можете выводить, все что вашей душе угодно.
Гипотетически и веб сервисы( api ) можно реализовать на базе СУБД, но так обычно не делают.
Если аутпут хранимки неправильный или она падает, то что дальше делать?
В указанном примере у вас упала f2 представляющая из себя вызов api бэкенда.
Это не чем не отличается от, у вас упала f2 представляющая из себя вызов хранимой процедуры.
Как дебажить бекенд я представляю. Дебажить хранимку у меня ни разу не получалось. Хотя я последний раз лет 5 назад пробовал, мб с тех пор что-то и поменялось. А так — смотришь логи STMT PREPARED/STMT EXECUTED и пытаешься угадать, что не так.
а что именно вы понимаете под «дебажить»?
Выполнять код построчно, код, выполняющийся над множеством элементов — поэлементно, смотреть значения всех переменных в скоупе в watch, возможность их изменять, в стиле
@Id := SELECT TOP 1 ID FROM ...
-- тут мы поняли что @id в дебаге какой-то неправильный и прям руками поменяли его на другой, в этой отладочной сессии.Возможность перескакивать между инструкциями: например, есть три селекта, но я хочу выполнить только первый и третий на некоторых итерациях.
Ну все в таком духе. И если без последнего жить можно — нато просто перезапускать 100500 раз с комментированием/раскомментированием строк, то первые критично важны.
Вы упорно уходите от ответа. Это уже о многом говорит, но я попрошу еще раз. В статье было утверждение, что с echo отлаживать проще. При этом подразумевались ситуации наподобие моего примера. В начале этой ветки был задан вопрос "в чем разница с raise notice". Я привел пример, в котором с моей точки зрения в случае логики в БД действий для отладки будет больше, и конкретный список действий для логики в коде. Если с вашей точки зрения это не так, приведите пожалуйста свой список действий в качестве ответа на вопрос "Мы написали raise notice, а дальше что?" Не надо всех уверять "да там то же самое, правда-правда", все могут сами сравнить и проверить, так это или нет. В частности меня интересует передача 10 полей формы в процедуру, я для этого их и упомянул. Нужен конкретный список действий от воспроизведения ошибки до получения вывода, который начинается с "написали raise notice".
Пользователь веб приложения не отлаживает веб приложения
Ваша фраза, в ответ на которую я это написал, была не про отладку, а про вызов процедур. Вы сказали, что в случае логики в коде метод вызывается браузером, а в случае логики в базе нет. Это не так, в веб-приложении логика всегда вызывается браузером, независимо от того, где она находится.
В хранимых процедурах вы можете «разбавить» выполнение различными выводами и увидеть их в подключении к базе( чем бы вы его не выполняли ), поскольку хранимые процедуры выполняются в СУБД.
В java приложении вы можете «разбавить» выполнение различными выводами и увидеть их в отладчике IDE или в логе.
Во всех указанных сценариях вы можете использовать echo вывод для отладки, хотя это и не лучший из возможных вариантов.
Последовательность действий вам написали в первом же ответе. Это команда получения вывода хранимой процедуры в postgresql( для любой другой субд она будет очень похожей ).
Вот простейший пример запроса который в соединение выдаст сообщение.
DO language plpgsql $$
BEGIN
RAISE NOTICE 'TEST';
END
$$;
Скоро, надеюсь будет статья — "как переписали проект на стадии разработки на node.js и что из этого получилось".
Пока текущие результаты — штат увеличился в 5 раз, сроки сдвинулись, вопросы безопасности и разделения доступа отложены .
1. ± Сам язык — Oracle PL/SQL. Процедурный, чуть понавороченее pl/pgsql, формально есть объекты. Но 50% разработчиков больше и не используют)
2. + Отладка. Есть отладчик и профилировщик.
3. − Сбор метрик. Готового решения не знаю.
4. − Масштабирование. Все, как в статье.
5. − Зависимости. Тоже беда.
6. ± Фреймворки. Их нет, но сама стандартная библиотека содержит базу для работу с XML, JSON и пр.
7. + Юнит-тесты. Есть utPLSQL
8. ± Появились DataGrip и прочие. Этого должно хватить.
Да, многие +-ы несколько натянутые, но если писать ядро бизнес-логики, а не навороченный интеграционный сервис, то они таки будут плюсами в сравнении с другими языками.
P.S. Не призываю начать срочно выносить бизнес-логику в БД
Ну для оракла есть офигенный сбор метрик в виде AWR отчёта из коробки, на пг чуть сложнее, но тоже можно
Тут в статье ещё упоминали производительность. Вы забыли что PL/SQL легко компилируется в бинарный код, начиная кажется с 11g. Специально для выполнения сложных расчетов в процедурном коде.
В смысле он и так всегда компилируется в момент сохранения в БД (в отличие от PL/pgSQL), но в данном случае я имел в виду трансляцию в Си с последующей компиляцией.
На самом деле PL/SQL — отличный язык. Просто конкуренция высокая)
Ах да, точно, с 9-ки можно было, но там всё было нетривиально. А в 11 довели до ума, но механизм под капотом тот же, насколько я помню.
Язык отличный, это правда. Когда переходил на Постгрес после 12 лет на Оракле, то пролил много слёз. Хотя позже там нашлось много потрясающих вещей, которых нет в Оракле :-)
Как выяснилось автор не указал один плюс хранимых функций — безопасность данных и разделение доступа.
И как следствие — меньше проблем при сертификация информационной системы.
И вообще говорить о плюсах и минусах в отрыве от конкретной предметной области и бизнес требованиях это как обсуждать сферического коня в вакууме.
Ну флаг is_delete это классика.
Ничего не удалять, только переименовать ;-)
Ага, до сих пор вспоминаю проект, где на каждую таблицу заводилось CREATE_XXX/UPDATE_XXX/DELETE_XXX, с абсолютно идентичным и тупым кодом, который может любая ОРМ сгенерировать за секунду. Уж не знаю, кто в здравом уме может назвать это хорошим подходом
Оно идентично и тупо, только пока никакой фактической логики не придумано, и эти методы — просто заглушки. Потом, когда появляется дополнительная логика, которую надо выполнять при CREATE/UPDATE/DELETE, вы её в эти методы помещаете, и они уже больше не идентичные.
По той же причине при создании класса советуют сразу заводить в нём свойства (properties), а не поля (fields). Чтобы потом, когда появится логика, поместить её в геттер/сеттер свойства и не ломать весь код, который эти свойства использует.
Хорошая аналогия с классами и свойствами получилась: она прекрасно демонстрирует разницу между нормальными языками программирования и SQL.
Все языки движутся в сторону упрощения заведения свойств. В C# программисту доступны автоматические свойства (auto properties), которые синтаксически отличаются от поля только добавлением { get; set; }, но при этом сохраняют преимущества свойств. В Kotlin пошли ещё дальше, там автосвойство объявляется синтаксически проще чем поле. Даже в консервативной Java существует Lombok, который умеет, в том числе, добавлять методы доступа к полям, превращая их в автосвойства.
В то же время в SQL, кажется, все C(R)UD-заглушки так и пишутся вручную...
… что еще веселее, в C# если уж ты сделал свойство (особенно автосвойство), то без ухищрений сторонний программист в нижележащее поле не запишет. А в SQL надо помнить конвенцию.
Раз уж пришли к необходимости процедур и вьюшек, то потратили 1 день и написали тулзу, которая генерирует весь код. У нас такая, задаете ей вьюшку, она по ней создает метод C# для SELECT и POCO к нему. Задаете ей таблицу, она к ней генерирует INSERT/UPDATE/DELETE PL/SQL процедуры. Задаете ей PL/SQL процедуру, она к ней генерирует C# методы.
Оговорюсь, у нас специально отсутствует ORM.
У вас отсутствует ОРМ, зато есть инхаус генератор вьюшек… Мне не кажется это хорошим и поддерживаемым решением.
ORM даёт оверхед от 10% и выше, в зависимости от продукта. Базу мы менять не собираемся, так что этот плюс ORM мимо.
ORM даёт оверхед от 10% и выше, в зависимости от продукта.
Citation needed
Базу мы менять не собираемся, так что этот плюс ORM мимо.
Так никто не собирается, пока внезапно не соберётся.
Citation needed
Не знаком с вашим основным языком. Для .NET Core:
github.com/FransBouma/RawDataAccessBencher/blob/master/Results/20200721_netcore31.txt
Так никто не собирается, пока внезапно не соберётся.
На мой взгляд, это overengineering для энтерпрайза.
То есть речь шла про 10% относительно времени передачи данных из СУБД в код? Ну, тогда возможно. Остается вопрос, какое это время от общего времени работы сервиса. А то у меня обычно оказывается, что почти всё время это работа логики и обработка запроса движком, а не передача данных по гигабитной сетке.
На мой взгляд, это overengineering для энтерпрайза.
Нет, я выше писал пример, у нас переезд помог перестать падать под нагрузкой. И нет, если бы мы делали всё в SQL изначально то за 5 наносек без падений оно бы не работало.
То есть речь шла про 10% относительно времени передачи данных из СУБД в код? Ну, тогда возможно. Остается вопрос, какое это время от общего времени работы сервиса. А то у меня обычно оказывается, что почти всё время это работа логики и обработка запроса движком, а не передача данных по гигабитной сетке.
Какие передачи по сети? Сравниваются показатели у различных ORM с контрольным образцом, если сеть плохая, то тоже самое влияние оказывается и на контрольный образец.
Вот за 2 года работы над проектом ни одному такому методу не понадобилось кастомной логики, кроме мб одного — удаление корневой сущности требовало большого количества оптимизаций, чтобы был CLUSTER INDEX DELETE который быстро работает. Зато оверхед на написание и поддержку всего этого добра был прекрасный. Добавить новую колонку — в ОРМ одно свойство в моделе и команда "сгенерируй мне миграцию которая добавляет поле", в этом адовом котле — поправсь все хранимки. которые создают, удаляют, обновляют или селектят эту сущность.
Да правда ваша, мельком есть упоминание 'редкий кейс'. Я даже не заметил сразу. Прошу, прощения
Безопасность данных редкий кейс?
Это мягко говоря странно.
В общем получается так — если вас не волнует безопасность ваших данных, не используйте хранимые функции для реализации бизнес логики .
По факту я вижу только два варианта дырочек:
— Отсутствие экранирования параметров SQL запроса. Но это очень простой паттерн и такие ошибки только Junior допускают, но code review они не пройдут, а если использовать ORM, то не экранировать становится ещё сложнее.
— Ошибка в бизнес-логике типа забыли поставить if (isAdmin()), но точно такие же ошибки можно и в БД допустить в настройке ролей.
"сертификация информационной системы" это что-то как будто с другой планеты. Хорошо что я больше не работаю в окологосударственных структурах.
Да, во многих СУБД достаточно сложно структурировать код, в том же mysql никогда не будет пакетов, потому что если надо много кода — то бери Oracle где можно писать очень хорошие решения на хранимых процедурах, которые будут не несколько ms экономить, а часы. Сбор метрик и обработчики ошибок тоже есть.
А главное — реализация больших транзакций на базе РНР, в том же ларавель — запаритесь. Если существенно используются транзакции то без хранимых процедур порой сложно. Хранение временных результатов больших обьёмов — сразу надо использвать какой нить редис, а в оракле все это есть и очень удобно.
Чем внимательнее перечитываю статью, тем больше сомнений.
"Отладка хранимых процедур — это неудобно. "
Меня терзают смутные сомнения, что данная статья исключительно ради хайпа.
То, что автор не имеет никакого опыта в разработке для PostgreSQL явно видно: "Это надо делать в pgadmin (включив специальное расширение)."
О каком СПЕЦИАЛЬНОМ расширении идёт речь? И почему именно НАДО?
Я например pgadmin не использую вообще. Что я потерял?
Разрешите пояснить вместо автора.
Есть такое расширение "pldebugger" (нужно его собрать и поставить на сервер, код тут: https://git.postgresql.org/gitweb/?p=pldebugger.git), которое позволяет ставить break-points в коде хранимых процедур. Я тоже pgadmin не использую, это просто какая-то запредельная жесть, но слышал что он умеет работать с этим расширением из коробки.
Еще его понимает DBeaver (https://github.com/dbeaver/dbeaver/wiki/PGDebugger). Я как-то раз попытался эту связку настроить и поюзать, но оно толком не работало, постоянно вылетало с ошибками.
А установка break-points от raise exception чем то принципиально отличается?
Вообще-то отличается, и довольно сильно. Это позволяет не прерывать поток исполнения, подсматривать значения переменных, вычислять выражения (если вам вдруг это понадобилось, но вы заранее не предусмотрели это в коде). А динамические языки еще и разрешают перескакивать через строчки кода и изменять значения переменных прямо на лету. Только не говорите мне что не знаете как работать с отладчиком :-)
Но без этого вполне можно жить, я согласен. И я сам, как уже сказал выше, отказался от этой идеи из-за кривой реализации, и вернулся к "raise notice" (но уж точно не "raise exception"). Но было бы очень круто иметь нормальный отладчик. Всё зависит от количества кода в ваших процедурах, на самом деле.
В Oracle PL/SQL код группируется в пакеты, и там есть глобальные переменные, и пакеты могут легко иметь размер больше десяти тысяч строк. Там отладка просто неоходима, и там это реализовано на высшем уровне. В Postgres всё чуть проще.
Для дебагинга конечно raise notice. В принципе всегда этим пользуюсь, единственно, чуть изменил и сделал надстройку, что бы можно было отключать вывод отладочной информации. Т.е. отдельная схема и функция для отладочной печати.
Да, пока вполне хватает, в крайнем проекте 5 МБ кода, принципиальных сложностей не было. После того как разработал шаблоны и общую архитектуру пошла просто кодировка новых функций
По поводу пакетов и глобальных переменных, да этим Oracle выгодно отличается.
По поводу дебагинга хранимок, если сделают конечно пригодится, слов нет. Но и сейчас неплохо жить можно. Пока не слышал, чтобы были планы на дебагер в PostgreSQL. Поживем, увидим
Я точно так же использую кастомную функцию вывода отладочной информации, и контролирую её поведение при помощи set_config() для текущей сесии.
Пока не слышал, чтобы были планы на дебагер в PostgreSQL.
Код проекта PLDebugger хостится на git.postgresql.org, то есть это расширение официально принято сообществом. Но если посмотреть на лог коммитов, то приходит понимание что это никому особо не нужно. И нет поддержки в IDE. Нет и не будет, потому что реально никто и не просит (см. например тут, тут, или тут и т.д.).
А насчет «Вред хранимых процедур», чем ближе логика к данным, тем больше шансов эту логику соблюсти. Выносить логику на уровень приложения создаст проблему, когда программер забудет вызывать вашу php функцию при изменении данных.
Если же хранимка будет вызываться из, допустим, SQL триггера, то данные будут модифицированы согласно логики.
А вообще, название статьи «Вред хранимых процедур» абсурдно.
Выше шансы соблюсти логику, когда она видна, не прячется за информационным шумом
Странно, ожидал в части про версионирование что-то про шедевральную api_get_wordtranslate_v5 (v5 потому что версионирование не нужно, для тех кто не догадался). Больше деталей по теме и откуда скрин можно узнать из твита. Рекомендую к прочтению!
В произвольном порядке по тезисам статьи:
Кейс «ради безопасности спрятать данные и наружу дать только хранимки» — не редкий. В контексте базы можно алгоритмически доказать, что определенные данные хранятся правильно, и никуда не утекут и не перезапишутся. Удачи в убеждении аудиторов, что ваш супер-пупер микросервис на PHP с последним Laravel ни при каких обстоятельствах не потеряет часть данных.
Рефакторинг — на тестовой БД новую версию кода можно загрузить в один клик, про PHP не знаю, в Джаве даже с hotswap'ом не всегда быстрее будет.
Юнит-тесты — пишутся и на SQL и на других языках, если уж приспичит. Просто они не так нужны, но это уже другое дело.
Зависимости, фреймворки — чтоооооо? Нет, просто, что? Зачем? Вам не хватает библиотеки isEven из мира JavaScript? В базе уже по умолчанию есть «валидация запроса» и «аутентификация с авторизацией» (пусть даже и не в том виде, что подразумевал автор), а ещё богатейший функционал для работы с данными, для чего, собственно, база данных и нужна. Да, порой что-то нужно писать руками, и это может ранить тонкие чувства программиста-снежинки, но по поводу «пихать всё подряд из внешнего мира в нашу кодовую базу» всё-таки смотрите пункт про безопасность.
Про метрики повеселило. Зачем вам вообще нужны метрики? Что бы рисовать диаграмму в Графане, в который всё-равно никто не смотрит, но который можно показывать на фоне и делать умный вид на фотографиях и созвонах? К тому же, у базы есть свои метрики, проверить работает ли она, сколько ресурсов кто жрёт, общая информация по запросам и таблицам тоже есть. Что бы понимать и правильно интерпретировать их требуются минимальные знания о базе, которыми автор не обладает, но, наверное, при желании можно вывести и в Прометея.
Про масштабирование — вот тут в первый (вернее, последний) раз автор затронул что-то важное. С одной стороны — да, базу просто так не раздробить на десятки нод. С другой — все эти ноды всё-равно должны писать в какую-то БД и получать данные из какой-то БД. С третьей — есть ситуации, когда БД одним запросом/хранимкой способна перемолоть такой объем данных, от которых кубернетес-кластер из микросервисов на Go и PHP может очень сильно загрустить. Без каких-то конкретных примеров использования сравнивать «масштабируемость ради масштабируемости» — очень глупое занятие.
Отладка/логирование — выше уже было сказано, есть инструменты, учитесь пользоваться.
Версионирование — ничего не мешает настроить CI/CD пайплайн, и ставить новую версию базы на прод только из git'a, после прогона всех тестов на тестовой. Не особо понимаю, чем это отличается от стандартной работы с кодом, но автору виднее.
В сухом остатке — под вопросом масштабирование, и автору не нравится язык — не хватает новомодных фичечек и сахарочка. Ну окей.
Что, на мой взгляд, совершенно правильно сделал тот чувак из Lingualeo — перетряхнул все отделы, и сократил количество таблиц с 500 до 12. Это — реально та работа, которая требует согласования по всем уровням, и без главного архитектора/CTO обычными программистами не делается. Если без фанатизма, то ничего не мешает теперь вернуться всем к привычной схеме работы: «есть база — клепаем поверх микросервисы, хранимки используем только так, как нас проинструктировали, сами в них не лезем».
БД может одновременно жить в нескольких релизах для разных пользователей. И релизы можно переключать буквально в пару действий.
Что, на мой взгляд, совершенно правильно сделал тот чувак из Lingualeo — перетряхнул все отделы, и сократил количество таблиц с 500 до 12.
Ага, способ которым он их сократил это отдельная тема для разговора. Спихал всё в одну таблицу, вместо названия таблицы используется специальный id сущности, данные рядом в JSON. Подробности есть в докладе. Получилась key-value база по сути. Оно в общем-то работает, но разбираться с этим скорее всего будет сложно.
А после того, как он все перетряхнул, там куча уязвимостей появилась, выше приводили ссылку на Twitter.
Что-то комментарий в стиле "Деды писали". Юнит-тесты не нужны, мониторинг — шашечки для зумеров, зависимтсоти — фигня, ведь так весело в 547 писать какую-нибудь топологическую сортировку или энкодинг точек в формат Google Maps. Один вот этот комментарий
Рефакторинг — на тестовой БД новую версию кода можно загрузить в один клик, про PHP не знаю, в Джаве даже с hotswap'ом не всегда быстрее будет.
Показателен. Рефакторинг не про то во сколько кликов куда-то что-то грузить. А на авторизации БД который хватит всем выпал в осадок.
Хорошо, что я не живу в вашем мире.
Огромное пожелание автору: прежде чем писать о плюсах и минусах хранимок, попробуйте реализовать на middle-слое бизнес-логику витрин данных для сложной аналитики на базе террабайт так в 200.
Применять правила хай-лоад разработки для всей разработки в целом — некорректно.
OLAP-кубы на noSQL решениях это сильно. Звучит как заявка на победу. Прямо вижу как вы пытаетесь реализовать снежинку на Mongo...
Подождите, а я думал, что OLAP-кубы — это уже noSQL решения, разве нет? Куб — это разве реляционная структура?
А что мешает кубу быть реляционной структурой?
В моем (признаюсь, ограниченном) опыте работы с OLAP-решениями, они как раз денормализованы, чтобы уметь быстро отдавать аналитику. И некоторые из них даже не умели SQL.
Несоответствие 3НФ — ещё не повод обзывать данные нереляционными...
Они не денормализованы, они разрежены. Это 2 разных термина, и означают они немного разные вещи. Хотя внешне это похоже. Что же касается "не умели SQL", то тут проблема в том, что языка структурных запросов просто недостаточно для работы с OLAP-кубами. Формально, нормально транслировать их научилась только одна СУБД (Oracle). Для всех остальных это ад, и OLAP для них этот как правило отдельное ПО, которое базу использует только как хранилище. И да, в качестве хранилища можно использовать noSQL решения, но реализация MOLAP (на многомерных структурах) по сути является костылем, и в разы сложнее реализации ROLAP (на реляционных структурах).
Нет. Описанием OLAP-куба является "проекция отношений фактов". Что само по себе термин из реляционной алгебры. Ну и хронологически, OLAP-кубы существовали до появления современных noSQL решений.
Я тут уже писал. Рано уходить от SQL. Появились NewSQL решения, скоростные что черти. Я лично в восторге от MemSQL, я такого драйва на сотнях миллионах записей еще не видел. Хотя по их блогам там и милиарды за доли секунды процесаются, естественно в разумных рамках и с кучей нод.
https://www.memsql.com/blog/memsql-processing-shatters-trillion-rows-per-second-barrier/
Вам даже не надо TimeSeries базу искать, оно там автоматом! работает на том же SQL.
Я как-то ошибся в джоинах и получилось 80 миллионов на 80 миллионов cartesian exposion ( сколько там нулей будет ). Он это скушал за 3 минуты на двух 16-ти ядерных машинах. А я то думал чего это он начал так медленно это исполнять, а он стойко такую массу операций провел и сгрупировал, что и не укладывается в голове.
И вот тут хранимки мне будут как раз-таки самой большой проблемой.
Есть опыт миграции сервисов с одного хранилища данных на другое, при переезде с оркала на постгрес это как раз и была основная проблема.
А если проект еще и не покрыт авто-тестами… добро пожаловать в мир бесконечных, самых чудесных и непонятных багов.
Проект, на котором наблюдал такую ситуацию (и тим-лид которого, любил процедурки) в итоге переписывали с нуля, конечно, не только из-за обилия процедур в базе, но и их в том числе.
разбиение логики на бэк и базу производит к взрыву мозга программистов
А если весь бэк ограничить базой данных?
Какие будут последствия?
К вопросу о размещении логики в базе или в коде это мало отношения имеет, и уж точно не в пользу базы, даже если имеет.
Ну а декомпозиции верные технически, но неверные в точки зрения эксперта предметной области объясняются просто в подавляющем большинстве случаев: эти эксперты не доносят свои знания предметной области до технических специалистов. В лучшем случае полагая "это же очевидно, что остатки конкретного товара на складе могут быть отрицательными в случае пересортицы". А по выставленному менеджментом флоу разработки даже для уточняющих вопросов они или вообще недоступны, или доступны через испорченный телефон с огромным пингом.
Давайте расскажу сказку на ночь.
Жил был программист. Программист как программист, уровня миддл или даже выше. Но была с ним одно беда — не любил он хранимую рутину. Не, триггер на получение ключа из сиквенса он еще написать мог, но все что больше — считал плохим тоном. Ибо логика должна была быть на миддл-слое. И получил он как-то раз задачу, обновить данные в неком дереве, которое представляло из себя сеть Петри. Только обновить данные нужно было хитро, в зависимости от результата агрегации данных нижестоящих узлов. Ну и решил он задачку как обычно. А потом остался он без премии, и чуть не остался без работы. Поскольку мозг нужно включать, и понимать, что иногда накладные расходы на многократную передачу данных на сторону, агрегацию их там и последующее их обновление могут быть такими, что будут по сути Dos-атакой. База лежала 4 часа.
Вот и вся сказка.
ПС: а еще он забыл отключить индексы, за что ему поставили отдельный памятник.
Мозг вообще полезно включать. У меня вот тоже сказка есть. Решили как-то задачу ежедневного начисления процентов по счетам клиентов сделать SQL-запросом, а то PHP в цикле по всем счетам работал медленно. Первый вариант вообще летал по двум табличкам (в первой данные договора — даты, ставки и т. п., во второй — приходно-расходные операции). Потом требования (алгоритмы и представления результатов) и ограничения (от регулятора) усложнялись, добавлялись костыли типа табличек с списком дат и временные таблицы, запрос разрастался и уже требовал пары часов для перерасчёта. Потом появился продукт с совершенно другим алгоритмом начисления, натянули его на этот запрос, криво, не без кувалды и такой-то матери, требовал уже почти всей ночи, но ещё хватало с запасом от конца до начала операционного дня. Потом резко увеличилось количество активных счетов (кризис, массовые невыплаты или пролонгации) и в "операционную ночь" еле вкладывались. Переписали на хранимку — ускорение раза в два. База по сути заблокирована на время пересчёта. И тут внезапно, "мы выходим в онлайн 24/7, баланс должен меняться ровно в полночь"… Несколько месяцев ещё помучались с хранимками, перехали с mysql на postgre по причинам скорости, юротдел намекал, что нас и лицензии могут лишить из-за ошибок в балансах, плюнули, переписали на PHP, и в 1000 потоков запустили расчёт, благо облако.
В мире pl/pgsql нужно страдать. В этом языке просто нет менеджера зависимостей.
Так это благодать по нынешним временам :)
{kind=link}
Забыли еще один плюс ХП: PL/SQL сконструирован для удобной работы с базой данных. Так что для сложных баз данных логику извлечения данных и, особенно, сохранения имеет смысл делать на ХП.
Именно, для удобной работы с базой данных, а не для удобного преобразования одних данных в другие с принятиями решений в граничных случаях. Думать о хранимках имеет смысл начинать, имхо, когда на одну бизнес-операцию тысячи и миллионы сущностей начинают с базы считываться и в неё же потом записываться. И при этом простым SELECT/UPDATE не выражаются и/или индексы не могут использоваться.
Не совсем. Хранимки становятся нужны, когда у тебя в джаве — класс Order, а в базе — десяток нормализованных таблиц. При этом по этой же базе хотят гонять аналитические запросы или ETL, а к базе прилагается собственный DBA.
Лучше, конечно, не увлекаться нормализацией и держать схему БД как можно проще, но получается не всегда, как по техническим, так и по организационным причинам.
в этом есть некая ностальгия по языку Pascal
В данном случае не Паскаль, а Ада.
PL/SQL является диалектом Ады.
Полное b2b (только не бизнес-ту-бизнес, а Боль-Тоска-Безисходность) и очереди заблокированных скл-сесий в бд.
Удивительно почему в комментариях об этом никто не вспомнил.
Отдельный треш начинается если среди хранимок — есть функции и если (о ужас) их начинают использовать в скл-запросах.
Например в предикатах.
Или (ужас в квардрате) в качестве датасорсов, например в виде table-функций (если в терминах oracle-субд).
Представте как тут цбо-оптимизатору здорово «получается» всякие кардиналити расчитывать, при оптимизации таких запросов.
рдбмс-субд были придуманы в первую очередь как скл-энжин.
Именно и только в таком качестве, в общем случае, они и должны использоваться, не надо туда пихать логику.
Для логики есть мидл-тиер.
Кроме того, запихав логику в бд потом вдруг выясниться, что между базой и клиентами базы — крайне трудно впихнуть какой то кеш-слой например.
Бикоз-оф вынос логики в базу провоцирует клинетов, обращаться в бд, не на уровне скл-команд, а на уровне апи этой логики — дёргая хранимки.
Ну и, стало быть, если потом захочется (а захочется, прям очень) кеш какой то, между клиентами и базой — надо будет чтобы этот кеш — понимал протокол вызова хранимок, как минимум.
Аргумент про отсутствие ООП и ФПв языке вообще ни о чем. Ни ООП, ни ФП — не панацея и не серебрянная пуля. Никто не позиционирует PL/pgSQL как язык ООП или ФП, а то что ООП и ФП волокут куда надо и не надо это скорее беда, чем развитие.
Версионирование — всё отлично версионируется, если рассматривать процедуры как код, а не данные. К переключении на другую ветку добавляется загрузка кода в БД, при правильно поставленном процессе, это одна команда. Единстенная сложность — необходимо иметь персональную копию базы, с которой работает данный разработчик. Для очень больших проектов может быть затруднительным иметь полновесную копию базы, поэтому если разработчику нужна собственная копия, она чаще всего не содержит актуального объёма данных.
Сам язык pl/pgsql — согласен с тем, что язык несколько устарел на фоне новомодных языков и у кого-то может вызывать отвращение. Это не проблема, не всем же писать хранимки. Гораздо большей проблемой является отсутствие адекватных удобных IDE для PostgreSQL, почему-то почти у всех получается средство администрирования, но не IDE. Для Oracle есть PL/SQL Developer, это именно IDE, а не средство администрирования. JetBrains сделали DataGrip и у них почти получилось, но почему-то считают некоторые фичи PL/SQL Developer-а не приоритетными для себя. Для себя пока использую EMS SQL Manager, он пока далёк от IDE, но у компании была платная версия и техподдержка достаточно неплохо отвечает (хотя некоторые из пары десятков зарепорченных проблем пока не поправили). Приведённый в статье пример дурацкий — никогда не понимал заведения локальной переменной для результата, чтобы его вернуть в тех случаях, когда можно написать return с выражением (или даже несколько return-ов).
Отладка — кстати, SQL Manager умеет работать с расширением и они даже зачем-то написали собственный отладчик, эмулирующий исполнение pl/pgsql-кода. Что там в DataGrip-е не помню (не успел посмотреть), но не вижу проблем в интеграции pldgbapi, оно ведь открытое. Помнится, лет 10-12 назад чтобы отлаживать php, надо было ставить Zend Studio и работать через неё. Что касается echo, raise notice/raise warning вообще мало чем отличаются от них, их всегда видно в любом нормальном клиенте. Мало того, при настройках по умолчанию, raise warning можно посмотреть в серверных логах (и это успешно используется для разбора проблем на проде). В общем, довод просто переполнен субъективностью.
Логирование и обработка ошибок — вообще-то предполагается, что код в БД кто-то вызывает. И этот кто-то должен получить описание ошибки (вместе со стактрейсом). Обычно нет необходимости ловить все ошибки внутри хранимок, достаточно ловить лишь некоторые ошибки (no_data_found/too_many_rows/raise_exception/и т.п. и обычно в таких ошибках нет необходимости собирать стактрейс). Если у вас код изобилует when others then — это повод задуматься о не совсем хорошем качестве кода. Конечно, минус pl/pgsql в том, что get diagnostics должен быть написан прямо в exception-блоке и его нельзя вынести в функцию, но значение этого минуса не сильно велико.
Сбор метрик — нет смысла в сборке метрик чисто на pl/pgsql-код в отрыве от мониторинга БД в целом, а уж средств мониторинга PostgreSQL хоть отбавляй.
Масштабирование — тут частично соглашусь, но напомню, что не всем нужно становиться Google. Да и в PostgreSQL есть репликация, для read-only запросов вполне можно использовать реплики.
Зависимости — тут согласен. Но с другой стороны, база обычно довольно близка к бизнес-логике и чисто библиотечных задач тут не так много, чтобы это было большой проблемой. Ну если упороться, то в postgresql есть расширения и они обычно могут устанавливаться через пакетный менеджер, встроенный в ОС.
Фреймворки — а кто сказал, что на хранимках должна быть абсолютно вся система? Роутинг, валидация запроса, движок шаблонов — это задачи, которые должны решаться за пределами БД. Хотя БД и может быть источником вспомогательной информации для этих задач, основная часть их исполнения — не задачи БД.
Юнит-тесты — вот в этом отношении хранимки ближе к БД чем к коду. Впрочем, на один из проектов, с которым приходилось сталкиваться, было организовано тестирование, но это было тестирование целого расчета (когда загружалось референсное состояние БД, загружались хранимки и запускались расчеты с последующей проверкой корректности).
Рефакторинг — опять же, аппеляция к наличию инструментов, а не к языку.
Единстенная сложность — необходимо иметь персональную копию базы, с которой работает данный разработчик.
Эта сложность замечательно разрешена у Microsoft( было бы очень удобно, если для postgres было бы что-то подобное ).
В VS, проект с базой храниться в виде текстовых файлов, а работает с ней разработчик в стиле management studio.
При этом при прогоне любых тестов из файлов генерируется база.
Т.е. фактически вы работаете с базой, но она у вас офлайн и версионная в любой системе управления версий.
Плюс вы в любой момент можете между двумя такими или реальными базами получить diff по структуре.
Поправляю postgrespro.ru/docs/postgresql/11/jit-decision
> Это устаревший процедурный язык из девяностых
Ну да а php прям ноу-хау. Нафталин да еще какой.
> Уж если использовать какие-то хранимки, то на чистом SQL или v8 (т.е. javascript).
Ну да очень улыбнуло на счет js, тут без комментариев. Особенно деньги надо на нем считать (ПС сарказм)
> Т.е. все очень медленно и печально.
А php прям скорость во плоти. Go его на несколько порядков обходит. Не говоря уже о спринтерах. И что то я сомневаюсь что: схема sql — php -sql будет быстрее чем sql procedure. Особенно на последних версиях PG.
Транзакционность, эффективное использование индексов, возможность управлять блокировками и т.д.
О том, что есть нормальные специальные типы проектов, описывающих базы данных, которые хранятся в SourceControl и вместе с кодом приложения нормально раскладываются по веткам — тоже не слышал. Не знать это — нормально. Не нормально с таким уровнем знаний лезть в написание статей и пытаться чему-то учить других
Эта статья, скорее, ответ на другую статью, а не самостоятельная. И автор той статьи о версионировании кода харнимок сказал примерно следующее: файл со снэпшотом всех хранимок размером в пару мегабайт, его и коммитим в гит.
А можно подробнее про "нормальные специальные типы проектов"? Гугл ничего не показывает :) Желательно не специфичное для конкретного сочетания вендора SQL и языка/платформы приложения ("прокси-сервера"). Вроде что-то подобное есть в VisualStudio для MS SQL Server и C#+.Net, но ради перехода на храмки менять полностью стэк и, скоре всего, команду, как-то не хочется.
dbmstools.com/categories/version-control-tools
Использовал Visual Studio Database Project — хорошая штука, можно генерить схему и по существующей базе, но лучше внедрять чем раньше, тем лучше. У нас были проблемы с натягиванием на легаси базы (лично не занимался, но говорили, что связи между разными базами ломали все). Кроме схем/хранимок можно версионировать и содержимое статических таблиц (конфигов) через пост деплоймент мерж скрипты.
Если да, то можно вам вопрос: стаж и начально-средний стек (от джуна до мидла)?
Я работал на проектах где все было в базе, небольшой движок даже вьюхи рендерил по базе.
На время разработки — все жутко плевались, ну это не показатель ибо еффект «попередников». Но реальные проблемы были. Рефакторинг — поменялась какая-то часто используемая функция или таблица, ищи-свищи все места, где оно влияет. Версионирование хранимок решается спец тулзами, из бессплатного и нативного — МС ДБ проект. Но натянуть его на старые базы так и не получилось. В дебатах с архитектором на вопрос «Как удобно дебажить», ответ — «А зачем?», все в принтах и выбросом ошибки с указанием строки вручную (рано или поздно это переставало соотвествовать реальности, конечно же). Фича, которую я бы запилил с нуля (да даже с новым проектом) за неделю делалась месяц. Из плюсов —
В общем, сейчас бы я на такой проект и за +500 не перешел бы.
Был опыт работы в проекте, где одна известная швейцарская фирма
пыталась реализовать бизнес логику банковского бэкофиса на plsql, oracle.
Несколько неудачных попыток, проект, вышедший из под контроля и в
итоге 40 mio€ убытков.
В общем, возможность реализации сложной логики на sql очень сомнительна.
Всякие PHP/Python/Java бекенды легко в последующем пилятся на куски для первода на сервис оринтированный подход. И это позволяет строить горизонтально масштабируемые решения.
А засовыванием бизнес-логики в plsql — это монолит на веки вечные и распил его практически нереален… и если даже и удается что-то то с очень большой болью и переписыванием только больших кусков сразу.
Так что только и остается — покупать все более мощные сервера под БД.
ЗЫ у меня в конторе как раз такая ситуация… знаю о чем говорю…
Давно вы голову от SQL не подымали. Вот SQL Database котрорая масштабирутся и быстра как молния.
https://www.memsql.com/software/
Нет ровным счетом никаких проблем с распилом базы на куски аналогично распилу монолита на сервисы. Тут единственная проблема — лицензии.
А общение баз между собой? FOREIGN TABLES?
Ни в коем случае. Есть нативные средства. К примеру, для Oracle — это гетерогенные службы (heterogeneous services). Только вот если мы говорим о способе общения как у сервисов (а один сервис ничего не знает о состоянии другого, и общение идет через апи) то это скорее transparent gateways или rpc (один инстанс базы вполне в состоянии дернуть хранимую другого инстанса и ничего не знать при этом о структурах данных второго, что как раз ближе всего к сервисной архитектуре).
Проблемы, которые вы описываете, не вызываются хранимыми процедурами как таковыми. Если вы решили вопрос конкурентности доступа к базе через синхронизационные объекты на клиенте, скорее всего, вы что-то сделали не так.
Но ведь внутри SQL Server нет семафоров и мьютексов? Синхронизация доступа делается хинтами, чаще всего updlock.
Неужели вы делали CLR-процедуры, которые использовали семафоры и мьютексы?
вывод, мне кажется, очевиден: сложную логику нет смысла реализовывать внутри sql.
насчёт простой у меня нет ответа. с одной стороны, транзакции минимальной длины (это важно в нагруженных системах), с другой — множество сложных систем стихийно выросли из простых, перенося логику в sql мы усложняем развитие проекта.
наверное, отношение к ним должно быть как к ассемблерным вставкам: использовать допустимо, но точечно, там, где выигрыш производительности важнее, чем простота/поддерживаемость/переносимость кода.
del
Получается что зло — не хранимки сами по себе, а отсутствие инструментария.
1я проблема в том, что нет версионирования «из коробки». Но позвольте, у DDL тоже нет версионирования! Это решается Liquibase и подобными штуками. Собственно это уже обсудили.
Вторая проблема — старый язык для хранимок. Да еще и разный в разных БД. То есть по-доброму надо чтобы кто-то окрысился и написал транспилер из более-менее человеческого языка в разные языки хранимых процедур. Так уже проделывали с JS, webassembly, всякими typescript/coffeescript, SASS и даже с ранними версиями С++. «Если б я был султан», я бы попробовал lua для начала. Ну или сразу бэкенд к llvm.
Web разработка породила целый класс программистов не понимающих что такое ACID, уровни изоляции транзакций, триггеры, процедуры — зато с легкость могут настрогать ORM лапшекод, благо еще знают как оптимизировать SELECT запросы.
Но вот, вот на подходе следующее поколение, которое не умеет и этого.
Откуда у вас "не знают", "не понимающих"? Я вот понимаю и знаю. Знаю, что это боль если даже один на проекте работаешь. И чем больше народу на проекте, тем больше боль.
Что есть люди, которые знают и понимают, но используют всю мощь конкретной СУБД только когда другие методы исчерпаны. Относятся к первой харнимке на проекте как к первому гвоздю в крышку его гроба. Шутка. Как к сигналу, что надо серьёзно ещё раз подумать над архитектурой проекта вообще и выбранной модели хранения данных.
… а из чего вы делаете такие далекоидущие выводы?
Как я понял смысл и цель этой публикации под громким названием, — собрать как можно больше комментариев. Автор молодец, — цель достигнута.
А по сути вопроса — однобокий взгляд со своей колокольни.
Но.
1. Часть её все-же должна быть там. Если кому интересно, могу развернуто описать.
2. API. Да-да, нормально спроектированная БД (не созданная через ORM), должна иметь API. Никогда бэк не должен делать прямые запросы к таблицам\вьюхам. Только запрос к хранимкам. Бэк не должна интересовать структура и тип БД. Бэк интересуют интерфейсы БД, через которые он может получить или сохранить данные.
Если кому интересно, могу развернуто описать.
Мне интересно, напишите. Желательно статьёй.
Если ты извлекаешь данные из БД, а потом преобразовываешь их, обогащаешь их (данными из той же БД), фильтуешь их, сортируешь их, и прочее, то не надо так делать. Это всё может сделать БД, гораздо быстрее чем бэк.
Главное баланс. Не надо делать лишние действия над данными, данными владеет БД, пусть она делает эти действия.
Итак, выше в комментариях было утверждение "Ваш код работает существенно медленнее моего поэтому его невозможно применить в реальных условиях". Это было сказано про код, который я приводил здесь.
Я сделал приложение, которое проверяет, сколько запросов в секунду можно выполнить с логикой в коде и с логикой в хранимой процедуре.
Репозиторий:
https://github.com/michael-vostrikov/stocks
Веб-интерфейса нет, одновременная работа пользователей имитируется запуском консольных команд в параллельных процессах. Бизнес-логика находится только в DocumentManagerController::closeDoc(), остальной код инфраструктурный и может использоваться в любой другой функции бизнес-логики.
Количество тестовых данных основано на сведениях в этом комментарии — "Скажем 400-600 документов по 70-150 позиций, 10 операторов начинают закрывать". Только документов чуть побольше.
Я убрал сокращения в названиях полей и таблиц для лучшей читаемости, а также добавил документу поле "status" и соответствующую проверку, чтобы нельзя было закрыть документ дважды.
Разворачивание проекта.
php composer.phar install
php yii migrate/up
php yii test-data/addЕсть следующие консольные команды.
php yii test-data/add
php yii test-data/deleteДобавляет/удаляет тестовые данные. По умолчанию добавляется 10000 документов, в каждом по 70-150 позиций, то есть всего позиций около 1 млн. Количество можно указывать после test-data/add.
php yii document-manager/close 1 1
php yii document-manager/close-by-procedure 1 1Выполняет закрытие документа с логикой в приложении и с логикой в хранимой процедуре. Аргументы команды соответствуют аргументам процедуры закрытия документа — documentId, closingType. Второй аргумент должен быть 1 или -1.
Эти команды запускаются в нагрузочном тестировании, они имитируют работу пользователя.
php yii document-manager/emulate-document-page 1Запускается в нагрузочном тестировании перед одной из предыдущих. Предполагается, что эта команда имитирует открытие страницы в веб-интерфейсе, и нужна, чтобы проверить, как это влияет на кеширование запросов.
php yii performance-test/run-app --testing-time=10 --emulate-document-page=0
php yii performance-test/run-db --testing-time=10 --emulate-document-page=0
php yii performance-test/run-app --testing-time=10 --emulate-document-page=1
php yii performance-test/run-db --testing-time=10 --emulate-document-page=1Запускает нагрузочное тестирование. Тестирование производится 10 секунд, подсчитывается количество процессов, запущенных за это время. Предполагается, что количество процессов показывает возможное количество одновременно работающих пользователей (операторов). Запускаются команды document-manager/close и document-manager/close-by-procedure, id документа и тип закрытия генерируются случайно. Перед запуском удаляются все записи из таблицы current_stock и сбрасывается статус всех документов. Полное время тестирования получается немного больше, так как происходит ожидание закрытия оставшихся процессов.
Параметр --emulate-document-page задает режим, при котором перед закрытием дополнительно выполняется команда document-manager/emulate-document-page, команды соединяются через &&.
php yii performance-test/run-page --testing-time=10То же самое для проверки только страницы документа.
php yii performance-test/run-pure-calls 600Чистые вызовы логики внутри одного процесса. Здесь тестирование стандартное, задается количество запросов и замеряется время выполнения.
Результаты
Тестирование производилось на ноутбуке Lenovo, процессор AMD Ryzen 3 3200U, оперативная память 8 Гб, база находится на SSD, операционная система Ubuntu 19.10.
Приведены значения, близкие к средним на нескольких запусках. Основное значение "Requests per second", а "Estimated request time" это просто его инверсия 1/x.
php yii performance-test/run-app --testing-time=10 --emulate-document-page=0
Total requests: 422
Total time: 11.137261867523
Requests per second: 37.890821372403
Estimated request time: 0.026391615799818
php yii performance-test/run-db --testing-time=10 --emulate-document-page=0
Total requests: 601
Total time: 10.433739185333
Requests per second: 57.601593189604
Estimated request time: 0.017360630924015База всего в 1.5 раза быстрее приложения. Это потому что запрос в базу занимает только некоторую часть от полной обработки действия пользователя.
php yii performance-test/run-app --testing-time=10 --emulate-document-page=1
Total requests: 264
Total time: 12.679631948471
Requests per second: 20.82079362184
Estimated request time: 0.048028908895724
php yii performance-test/run-db --testing-time=10 --emulate-document-page=1
Total requests: 301
Total time: 11.834552049637
Requests per second: 25.434000267821
Estimated request time: 0.03931744866989То же самое, но с предварительной имитацией открытия страницы документа. Различие совсем небольшое, база всего в 1.2 раза быстрее приложения. Число запросов стало меньше потому что фактически выполняется 2 запроса, которые считаются как один.
Что насчет кеширования базы? Можно оценить по времени выполнения запроса.
php yii performance-test/run-page --testing-time=10
Total requests: 479
Total time: 10.713885784149
Requests per second: 44.708335486333
Estimated request time: 0.02236719370386
app: 0.048028909 - 0.022367193 = 0.025661716
было: 0.026391616
db: 0.039317449 - 0.022367193 = 0.016950256
было: 0.017360631С одной стороны стало чуть меньше, с другой различие в пределах погрешности. То есть нельзя строго сказать, что кеширование играет значительную роль.
php yii performance-test/run-pure-calls 600
App:
Call number: 600
Total time: 11.216256141663
Calls per second: 53.493785486167
DB:
Call number: 600
Total time: 2.4592180252075
Calls per second: 243.9799943924Чистые вызовы логики в цикле в пределах одного процесса. Это просто для информации, надо понимать, что с реальной нагрузкой это имеет мало общего. Здесь база в 4 с лишним раза быстрее приложения.
Вывод. С логикой в приложении имеется небольшое замедление обработки запроса пользователя по сравнению с логикой в базе. На реальной нагрузке различие менее чем в 2 раза. Таким образом, утверждение "этот код работает существенно медленнее, поэтому его невозможно применить в реальных условиях" неверно.
Глубоко не изучал, но замечания и комментарии сходу:
— насчёт вывода списка позиций, это Ваша додумка чистой воды, такого БП нет, тестим чистое закрытие документа. В реале: реестр документов, клацают на крыжик «закрыто» если на бумаге нет вычерков
— 10к доков это тоже совсем уж детские данные, база за месяц работы, в реале 5-10 лет
— в таблице текущих остатков в реале
~ 10к-100к (из до 500к наименований) * 3-10 складов * 3-6 юрлиц
Но конечно мне надо покопать Ваш код, займусь этим. Выводы тоже неверные. Во-первых, в 2 раза это существенно, с учётом того что мой код ничем Вашему не уступает, а с моей точки зрения он лучше (с Вашей наоборот). Во-вторых, на бОльших данных разрыв начнёт увеличиваться. В-третьих, в реальных условиях, с появлением новых конкурирующих API-сервисов, деградация производительности app-приложения будет возрастать куда сильнее чем SQL'я. Именно поэтому я хочу довести затею до конца и реализовать все 3 сервиса, о которых писал выше.
Будем продолжать?
Сейчас ход за мной. С меня:
— анализ Вашего кода
— чёткое ТЗ с тестовыми данными по оставшимся двум сервисам
Ещё хочу Вас попросить, допилить немного приложение, хочется получить именно REST API JSON сервис, чтобы можно было его подёргать, например, autocanon'ом типа:
autocanon «localhost/api/orm/close-doc?id=random»
autocanon «localhost/api/sql/close-doc?id=random»
Будет более наглядно, т.к., действительно, много работы за пределами обработки данных.
Ещё, пояснения по моему коду: это реальный код, писался более 5-6 лет назад, но это как раз тот случай, когда за код не стыдно и он прекрасно работает и прост в поддержке. Да, сейчас я вижу мелкие недочёты, например, Вы упомянули параметр type, действительно плохое название. В системе есть понятие credit_type, это то, как документ (или что-то ещё) влияет на баланс.
Т.е., например, тип документа «Отгрузка» credit_type = 1, тип документа «Оплата» credit_type = -1; План, Счёт, Прайс credit_type = 0 (никак не влияет на баланс)
— отгрузили товар на 100к * credit_type (1) = 100к — баланс +100к (проще говоря нам должны 100к), но остатки на складах при credit_type=1 уменьшаются
— пришла оплата на 120к * credit_type (-1) = -120к — суммарный итоговый баланс -20к (мы должны 20к)
Т.о. правильно было назвать этот параметр что-то типа document_action_credit_type. Но код и так прекрасно работал все эти годы и не требовал рефакторинга. О качестве кода ещё свидетельствует то, что Вы, сторонний человек, его с лёгкостью отрефакторили на пхп, не уточняя у меня никаких ньюансов. Ну только реализовали сначала однопользовательскую логику, но это, я считаю, просто стиль мышления императивного языка. Кстати, более чем уверен, что у Вас в рабочих проектах не везде где нужно написаны ForUpdate, а это как бомба замедленного действия.
Ещё ремарка о первом запросе:
-- Нельзя закрывать ЗПС и План производства
SET @msg := (SELECT raise_error('Документы данного типа нельзя закрывать если есть позиции с не нулевыми количествами.')
FROM documents d
INNER JOIN document_positions dp ON d.id = dp.document_id
WHERE d.document_type_id IN (6, 8) -- ЗПС и План производства
AND IFNULL(dp.cnt, 0) <> 0
AND d.id = p_doc_id)
В нём у меня содержится намеренный технический долг: в нём нет FOR UPDATE, потому что у документов этих типов credit_type = 0, они не влияют ни на баланс, ни на остатки.
По хорошему конечно надо было вообще завести в типах документов флаг can_not_close_with_no_zero_cnt_pos, ну в общем это всё преждевременная оптимизация которая оказалась не нужна.
Ещё не существенный момент: у меня процедура вызывается не напрямую, а из триггера, именно когда меняется поле status, поэтому нет проверки на то что поле изменилось. Но это лирика, Вы всё правильно отрефакторили.
П.С. ещё заметил, индексы cnt лишние, они нигде не используется
Во-первых, в 2 раза это существенно,
Неа, когда речь идет о 20/40 rps — это несущественно.
И понимаете, именно в этом и проблема: нет никакого определения, что важно, а что нет.
с учётом того что мой код ничем Вашему не уступает,
Это для вас так. Но, скажем, для меня это не так.
Во-вторых, на бОльших данных разрыв начнёт увеличиваться.
Или нет. Или начнет, но несущественно.
В-третьих, в реальных условиях, с появлением новых конкурирующих API-сервисов, деградация производительности app-приложения будет возрастать куда сильнее чем SQL'я.
С чего бы это? А главное, откуда у вас конкурирующие API-сервисы на одной БД, если это настоятельно нерекомендуемая схема?
насчёт вывода списка позиций, это Ваша додумка чистой воды
Естественно, это касалось моего утверждения "Причем я даже не уверен, что будет сильно большая разница, так как за счет одинаковых селектов будет лучше работать кеширование самой базы". Кейс "открыть страницу сущности, нажать кнопку изменения" очень частый в бизнес-приложениях.
10к доков это тоже совсем уж детские данные
Вы же сами хотели данные подготовить. Я просто сделал чтобы было достаточно, но чтобы не ждать по полчаса пока они загружаются.
Во-первых, в 2 раза это существенно
В 1.5. А на фоне нагрузки на чтение в 1.2.
Во-вторых, на бОльших данных разрыв начнёт увеличиваться.
Сделал в 10 раз больше, так же 37/57 запросов в секунду.
В-третьих, с появлением новых конкурирующих API-сервисов, деградация производительности app-приложения будет возрастать куда сильнее чем SQL'я.
Еще одно необоснованное утверждение.
Кроме того, приложения гораздо проще запустить в нескольких экземплярах, чем базу, которая к данным привязана.
О качестве кода ещё свидетельствует то, что Вы, сторонний человек, его с лёгкостью отрефакторили на пхп, не уточняя у меня никаких ньюансов.
Нет, тут просто кода мало. Я, сторонний человек, говорю, что в этом коде сложно разбираться. Особенно если таких процедур будет несколько десятков. Например, оказалось, что есть еще и credit_type == 0, что из кода непонятно.
Ну только реализовали сначала однопользовательскую логику, но это, я считаю, просто стиль мышления императивного языка.
Можете верить в то, что вам нравится, но я еще раз повторю, что отсутствие блокировок это было намеренное действие. Потому что вы сами не написали в коде транзакции и потому что разговор был про выражение логики на разных языках. Мне, в отличие от вас, за анализ этой предметной области никто не платит, чтобы делать его когда не требуется.
Кстати, более чем уверен, что у Вас в рабочих проектах не везде где нужно написаны ForUpdate, а это как бомба замедленного действия.
У меня в рабочих проектах нет нужды перекладывать данные из одной таблицы в другую. Мне кажется, у вас тут явно какая-то избыточность, но без знания предметной области и бизнес-требований нельзя сказать, как сделать правильно. FOR UPDATE мне понадобился кажется один раз, когда надо было реализовать требование "не более N сущностей на пользователя".
По хорошему конечно надо было вообще завести в типах документов флаг can_not_close_with_no_zero_cnt_pos
Эм, нет, по-хорошему надо сделать функцию, которая принимает тип документа и выдает результат, можно его закрывать или нет. А в комментарии к ней написать то, что вы в предыдущем предложении написали. А то кто-нибудь там ноль поставит вместо единицы, и сиди гадай почему везде так, а в одной строчке по-другому. Вот это и есть сложность поддержки.
ещё заметил, индексы cnt лишние, они нигде не используются
Согласен, хотел что-то проверить и забыл убрать их из кода.
Будем продолжать?
хочется получить именно REST API JSON сервис
Ок.
Эндпойнты добавлю сегодня.
П.С.2 Михаил, если Вы тестили конкурентные запросы, то должны были нарваться на deadlock-ки, т.к. ни в моём коде, ни в Вашем, нет кода который бы это предотвратил. Странно, если Вы не нарвались на них, возможно с тестами что то не так.....
Документ всегда выбирается и лочится первым. Два документа в одной транзакции не закрываются. Откуда дедлоки?
если Вы тестили конкурентные запросы, то должны были нарваться на deadlock-ки
Странно, если Вы не нарвались на них, возможно с тестами что то не так
Это потому что там при создании процесса ввод-вывод делается в отдельные пайпы, а не в общие stdin/stdout, поэтому этих исключений не видно, хотя они есть.
Добавил обработку и рестарт транзакции, стало 33 запроса в секунду для логики в коде. Чуть поменьше, ну ок.
Кстати, пробовал сделать SERIALIZABLE без FOR UPDATE. Получается также 33 запроса в секунду, уменьшения производительности не наблюдается. Ошибки с локами тоже есть.
JSON сервис
Добавил веб-интерфейс с ответами в JSON. URL такие же, как вы указали.
Не стал делать красивую валидацию параметров, которая возвращает сообщение в json, оставим это на потом.
Получился первый рефакторинг, так как логика теперь вызывается из 2 мест. Появился класс \App\Service\DocumentService, в котором находится логика.
Можно отметить функцию \App\Service\BaseService::executeWithRetry(). Она повторяет любое действие при возникновении исключения заданное количество раз или по другому условию. Например, в \App\Service\BaseService::runInTransaction() она используется для запуска в транзакции с откатом и повторением при ошибке. Может использоваться для всего, где есть исключения, для повторения при ошибках сети или файловой системы например.
Это к вопросу о переиспользовании кода. Думаю, аналог в базе будет сложно написать.
Рестарты зря сделали, лучше было побороть Deadlock'и.
SERIALIZABLE даст просадку когда будут параллельные чтения, а этот сервис у нас по сути всё пишет.
То что написали json api оч хорошо.
executeWithRetry — я не претендую выносить всю работу в процедуры, я даж в общем случае не за процедуры, точнее мне нет особой разницы, можно и в процедурах писать императивный код и это будет ещё больший ад. Я топлю за пакетную обработку данных SQL выражениями, а executeWithRetry я конечно буду реализовывать на Node, если не удастся победить дедлоки и придётся слать повторы запросов.
Особый восторг у меня лично вызывает процедура, которая парсит!!! данные из клиентского заказа, сформированного пользователем в Excel и сохраненного, как текст с разделителями.
ИМХО под «вся бизнес-логика построена на хранимых процедурах» обычно имеется в виду несколько иное.
Не знаю, как там "обычно", но я примеры с парсингом файлов в хранимках тоже встречал. Обычно они проходили под лозунгом "мы для SQL писать умеем, а для этого вашего на чем у вас там UI — нет, поэтому напишем тут".
> Особенно, когда в нашем прекрасном мире где-то совсем рядом есть объекты, интерфейсы, слои архитектуры, юнит-тесты, фреймворки
Стандарты безопасного программирования для авто-, авиа-, медицинской, космической промышленности массу вещей, сахара и т.д. выбрасывают за борт, например.
А основная обсуждаемая проблема в таких дискуссиях, как раз каково назначение хранимок. Одни вообще видят их бессмысленными на своих проектах, другие отводят им исключительно роль затыкания узких мест в производительности, третьи — почти все гвозди, а так бы и все забивали, если СУБД могли легко как HTTP сервера работать в паблике.
Большинству проектов не нужно безопасное программирование. Вернее было бы неплохо, но если бесплатно или совсем небольшого, единицы процентов, удорожания разработки.
А если таких примеров много видел, а удачных ни одного?
И в паблике удачные никто и не показывает. В лучшем случае констатируют "вы просто не умеете их готовить", но не описывают как правильно организовать работу с хранимками и прочими триггерами в условиях командной или даже мультикомандной разработки нескольких фич одновременно.
Кстати, соглашусь с соседним комментатором: если мой опыт наблюдения за тем, как другие люди (т.е. я-то знаю, что я не умею готовить хранимки, но они утверждают, что умеют) раз за разом на разных проектах и в разных командах применяют хранимки, показывает, что хранимки мне не подходят, на основании чего я должен сделать вывод, что они мне подойдут?
единственная проблема с хранимками — разработчики, которые не умеют в хранимки и три простыни кода засовывают в одну процедуру, еще делают 5-6 вложенных вызовов хранимок внутри хранимок, или вообще навернут дичь с триггером на INSERT на таблицу в которую данные льются по 100 раз в секунду, а потом жалуются, что:
1. хранимка и весь этот ваш SQL тормозит
2. тяжело поддерживать и понимать код
3. код очень хрупкий, любое изменение, может быть валидным SQL, но вызывать ужасную ошибку на уровне бизнес-логики
решение:
1. НЕ ПОДПУСКАТЬ формошлепов, яваскриптеров и пограмистов к написанию хранимок. Хранимки должны писать только Админами базы (DBA) или как минимум людьми, которые несколько лет ботали движок базы и знают тонкости работы базы, движка хранения(storage engine), планировщика запросов. Именно потому, что хранимка это часть схемы базы данных, и требуются спец знания движка. для написание эффективных хранимок.
2. Архитектурно продумывать схему базы и активно ее менять/поддерживать, как только растет база/клиенты/данные. Считайте, что база это еще один бекенд (ядро бекенда) для вашего бекенд-приложения
3. Хранить схему в виде кода (DDL), настраивать CI/CD на тестовый стенд
4. Писать бизнесовые тесты. Очень много проблем, когда код хранимки вроде бы парсится как валидный SQL, но с точки зрения бизнес-логики не валиден. В этом плане прблемы такие же как и в тестировании фронт-енда и решается также. Также как фронтендеры используют Селениум и headless chrome/DOM для тестов фронта, нужно брать бекап реальной базы и прогонять типовые сценарии через все хранимки, чтобы все расчтеты в базе были правильными. Эмулировать реальную нагрузку функционально. Нагрузочно тестировать тоже нужно.
тот факт, что почти все банки в пост-советском пространстве используют АБС, где ядро написано на хранимках (например Новосибирский ЦФТ), и ни копейки там не теряется в их системах, говорит, что на хранимках можно построить многомиллионный бизнес и сответствовать всем требованиям разных регуляторов.
Обычно на тормоза SQL не жалуются. Собственно часто начинают писать хранимки, когда другими средствами приемлемую скорость получить не получается. Только одни ограничиваются переносом только критических по скорости частей логики в базу, а другие переносят практически всё.
Жалуются как раз на сложность разработки и сопровождения.
лечилось тем, что база делилась надвое: на горячие операционные данные для OLTP, и на холодные исторические данные для OLAP. Такие решения не всегда будут очевидны бекендеру, а для DBA это один из шаблонов проектирования.
По моему опыту сложность разработки и сопровождения получается от того, что бекенд приложения ведет, а база остается ведомой. Когда залепят фичу в приложении, а потом думают как это засунуть в базу и перелопачивают хранимки затронутые изменением.
Я бы сказал, что когда растет сложность надо наоборот: делать базу — ядром системы, которое ведет вперед разработку продукта, независимо от бекенда.
Ну и соотв-но нужно иметь отдельного человека/команду которая только работает со схемой базы и ее развитием, и не отвлекается на бекенд.
А этот человек сможет принять решение, что пора уже вообще от РСУБД отказаться для каких-то фич и что-то другое использовать? На моей практике DBA до последнего пытаются решить задачи средствами RDBMS причём конкретной, идей типа "MySQL плохо подходит для этой задачи, давайте перйдём для неё на Postgres или вообще Kafka" не дожд'шься
Такие решения не всегда будут очевидны бекендеру, а для DBA это один из шаблонов проектирования.
Вообще-то, на проекте такого масштаба должен быть уже и архитектор (который в курсе про разделение данных по потреблению), потому что кто же иначе будет принимать решение о том, как функциональность делится между разными физическими компонентами.
Я бы сказал, что когда растет сложность надо наоборот: делать базу — ядром системы, которое ведет вперед разработку продукта, независимо от бекенда.
Это может быть оправданно, если у вас центр всего бизнес-процесса — это данные, причем хранящиеся в одном месте.
Вред хранимых процедур