Comments 90
Поправка, Fabrics для nvme не имеет никакого отношения к FC (fiber channel). Это просто внешняя шина PCI-E через специальные PCI-E коммутаторы. А вот про nvme over tcp через ядро я не знал, спасибо.
https://www.dolphinics.com/solutions/nvme_over_pcie_fabrics.html

О, спасибо! Возьму на заметку.
C fiber channel/RDMA тоже часто называют NVMe over Fabrics: https://nvmexpress.org/wp-content/uploads/NVMe_Over_Fabrics.pdf
Это просто внешняя шина PCI-E через специальные PCI-E коммутаторы
Pcie это один из транспортов. Есть отдельная спека nvme-of https://nvmexpress.org/wp-content/uploads/NVMe-over-Fabrics-1.1a-2021.07.12-Ratified.pdf Согласно этой спеке фабрикой для nvme-of может быть все перечисленное - fiber channel, RDMA, TCP. Появится какой-то новый транспорт и его добавят спеку - он тоже будет фабрикой.
То, что у вас на скрине и по ссылке, это довольно специализированные и кастомные решения, которые пытаются вытащить pcie наружу и сделать какое-то подобие сетевой фабрики из него (с учетом, что pcie пакетный и поддерживает свитчи прямо по спеке, ложится неплохо). Nvme об этом ничего не знает. Для него это не фабрика, а такой же pcie как на материнке в сервере. Вся идея той же компании liquid, свитч которой на скрине, это предоставить composable infrastructure минимальными изменениями стека. Это значит можно воткнуть в такой свитч видеокарту или ссд, и они будут работать. И система на другом конце тоже ничего подозрительного не заметит.
На самом деле, самый торт начнётся примерно через 12 часов. Я жду, когда приедет федекс с двумя серверами. Dell R710 и Dell R730. Плюс десятигигабитный свитч. Все это дело будет установлено в эти сервера, и я буду тестировать во всех возможных комбинациях Raid. Плюс проверим, что быстрее через nvmet: M.2 или SSD.
Будет круто почитать. Еще бы сравнение такого удаленного диска с каким-то NFS. И сценарий, где он всетаки будет шарится между несколькими машинами.
Вот как раз это и проверю. Ждите большого экселя.
Сам сижу, жду, когда федекс приедет. Буквально с минуты на минуту должен здесь быть.
Хм, а если на одной из сторон примонтировать раздел в RW, а другой в RO, то по идее ничего сломаться на файловой системе не должно. Например один клиент пишет другие читают.
Да, в принципе так должно работать. Собственно говоря, как я написал в статье, когда я примонтировал раздел удалённо, он автоматически перемонтировался на хосте в -RO режиме. И продолжал жить нормально, несмотря ни на что.
У меня были проблемы с его размонтированием на клиенте после того, как упало соединение между компьютерами.
Но, собственно говоря, я щас как раз сижу перед двумя серверами и пытаюсь это решить.
Мы тоже тестируем данную технологию. NVME-OF через RDMA на 56 Гбит/с -> LVM на гипервизорах. Показывает очень хорошие показатели. Очень!
У меня были проблемы с его размонтированием на клиенте после того, как упало соединение между компьютерами.
Как я понимаю, проблема возникает если диск примонтирован и теряется соединение с источником диска?
Удалось ли решить проблему?
Ещё как удалось. Продолжение сериала ожидайте в понедельник. Я почти закончил статью.
Кстати, а как вы тестировали скорость?
У нас есть кластер Ceph. К сожалению, добиться от него полной утилизации ssd на одну виртуалку не получается. (Но крайне мере пока у нас это не вышло).
Поэтому мы ищем решение которое позволит получить лучшую утилизацию ресурсов.
У нас есть набор железок, которые еще не доехали до prod-а, и есть на чем погонять. Это U.2 NVME, SSD и даже RAM диск отдавали. У нас в распоряжении 56 Гб/с карточки с поддержкой RDMA (Mellanox) - используем Ethernet.
Обязательно проверяем сеть - iperf.
Потом замеры fio локально (блочные устройства). И далее отдаем устройства по nvme-of (rdma) и проверяем на удаленном сервере.
В тестах специально использовали прямое подключение между серверами (DAC), чтобы избежать лишних задержек. Нас интересует процент потерь.
Замеряем:
последовательную запись/чтение 4M блоками, QD=32
пиковые IOPS запись/чтение 4K блоками, QD=128
задержки случайной записи/чтения 4K блоками, QD=1
В итоге:
Последовательное чтение/запись упирается в ширину полосы и устройства
Максимальные IOPS до 700 K IOPS вытягивает
SSD на 100% можно считать
NVME локально показывает больше, около 10% не дожали
Задержки примерно +10 us
т.е. на SSD почти не заметно
на NVME до 10%, что как раз и показывает в пиковых IOPS
на RAM существенно можно больше
Дополнительно проверяли сколько можно выжать из Виртуалки (KVM). Там, конечно, уже сама виртуализация большие накладные расходы дает.
По сравнению с CEPH даже на NVME (что является кощунством по отношению к NVME) это выглядит очень вкусно.
Сейчас мы на тестовом стенде играемся для обкатки технологии.
Но сталкиваемся ошибками в ядре при определенных сценариях. Особенно при отключении выборочных дисков.
Поэтому интересен ваш опыт и ваше видение вариантов эксплуатации.
Спасибо за развёрнутый ответ.
А как именно вы меряете? Какой утилитой?
Сейчас мы на тестовом стенде играемся для обкатки технологии.
честно говоря, я не понимаю этого сценария.
условно, вместо 20 хостов с локальными nvme в стойке теперь 19 хостов без nvme и 1 с пачкой накопителей. что принципиально поменялось?
как тут обеспечивать отказоустойчивость? миграцию на другие носители? да хотя бы консистентный бэкап?
У нас есть кластер Ceph. К сожалению, добиться от него полной утилизации ssd на одну виртуалку не получается.
посмотрите на https://yourcmc.ru/git/vitalif/vitastor
это попытка сделать цеф с вменяемыми задержками.
Появилась гибкость. Если мы облачный провайдер и хотим людям дать ssd, то очень неприятно, если мы ограничены платформой конкретной и то, что в неё установлено.
Отказоустойчивость по всякому можно обеспечить. Давать готовый рейд, собирать его на стороне хоста. Тут как раз открывается куда больше возможностей, тк nvme это всего лишь протокол и за ним что угодно может быть.
Тут как раз открывается куда больше возможностей, тк nvme это всего лишь протокол и за ним что угодно может быть.
я уже писал в комментариях к следующей статье, что приобретается/теряется в сравнении с iSCSI?
Приобретается думаю скорость и унификация экосистемы вокруг более современного протокола. Сейчас вот начинают выходить nvme-of решения - ничего подобного по скорости и масштабируемости на iscsi не получишь.
Что теряется - тут сложно сказать. Протоколы очень похожи по своим задачам.
Приобретается думаю скорость и унификация экосистемы вокруг более современного протокола
прирост скорости надо подтверждать тестами.
«более современный протокол» само по себе не является достоинством (скорее, наоборот, «более широко поддерживаемый протокол со стабильной реализацией» стоит рассматривать как достоинство)
Как минимум, этот протокол имеет аппаратное ускорение во всяких DPU. И банально сам написан для сверхбыстрых nvme устройств, а значит семантика там заложена соответствующая. Об этом пишет SNIA (кто у нас заведует развитием технологий хранения) и есть бенмарчки, показывающие полное преимущество над iscsi https://dl.acm.org/doi/pdf/10.1145/3239563 И это уже не первое исследование, которое показывает практически идентичную скорость direct attach storage и nvme-of. iscsi такого не может и близко.
и есть бенмарчки, показывающие полное преимущество над iscsi https://dl.acm.org/doi/pdf/10.1145/3239563
это уже интереснее. но фактически тут сравнивают релизацию nvmeof с помощью spdk с классическим iscsitarget.
Как минимум, этот протокол имеет аппаратное ускорение во всяких DPU.
у мелланокса есть какой-то оффлоад для iscsi, глубоко не копал.
https://network.nvidia.com/sites/default/files/doc-2020/cs-starwind2.pdf
это уже интереснее. но фактически тут сравнивают релизацию nvmeof с помощью spdk с классическим iscsitarget.
А в чем проблема? SPDK ничего магического не делает, просто пользуется тем, что ему дает nvme протокол. Это, к слову, о важности новизны. Множество очередей, NUMA-friendly и т.д. SPDK много чего внутри делает для максимальной эффективности. iscsi я так понимаю особо об этом не парится как и многие компоненты линукса, работающие с блочными устройствами.
Я вот сейчас хочу попробовать как раз собрать RAID0 на SPDK и посмотреть, как на нем софт будет работать. mdraid чертовски медлительная херня.
у мелланокса есть какой-то оффлоад для iscsi, глубоко не копал.
Чето мало чего написано, но раз там речь о software based iscsi, то наверное там разве что TCP offload. Для nvme-of DPU умеют работать с локальным nvme диском полностью минуя CPU. Ну и понятно дело имеют эмулировать nvme pcie устройство, что тоже снимает с CPU необходимость работать с сетью.
Есть такое понятие, как файловый Кеш. То что пишется - далеко не сразу оказывается на диске. То что читается Далеко не всегда читается непосредственно с диска (может читаться из кеша). Без механизма Синхронизации кешей вы можете прочесть мусор. Именно для решения подобных проблем и существуют кластерные файловые системы.
Сможете осветить эти вопросы в будущей статье?
Конечно. Оставляйте заявки, называлось дело :-)
Из интересного, у nvme инициатора в современных ядрах есть свой multipath драйвер, который никак не связан с dm-multipath, и не требует multipathd.
Хм. Это очень интересно!
Я, признаться честно, про multipath даже и не знал. Я на самом деле работаю по следующей системе: Прочитал доки, попробовал на живой системе, написал статью. До multipath даже не добрался.
А это очень интересно. Кажется, можно будет распределять нагрузку между сетевыми картами.
Если вы почитаете оригинальные стати, на которые я ссылаюсь в самом начале — при работе в серверном сегменте очень легко напороться на проблемы и задержки. С ними-то как раз я и буду бороться в следующей статье.
И уже есть платформы, которые умеют двухпортовые nvme диски. У тех же супермикро такие есть. Можно строить отказоустойчивую двухголовую хранилку.
Пардон, а поподробнее можно? Как она становится отказоустойчивой, если у неё две головы?
У супермикро есть линейка платформ storage bridge bay с двумя контроллерами и двух портовыми дисками. Вот например модельки чисто под nvme
https://www.supermicro.com/en/products/system/2U/2028/SSG-2028R-DN2R24L.cfm
https://www.supermicro.com/en/products/system/2U/2028/SSG-2028R-DN2R48L.cfm
Как она становится отказоустойчивой, если у неё две головы?
Если одна голова отвалится, то вторая может продолжить обслуживать файловую систему. Получится идентичному тому как работают энтерпрайзные хранилки.
У этих платформ есть даже внутренний сетевой канал между нодами, чтобы они могли хартбиты посылать друг другу и через IPMI через fencing убивать соседа, если он себе плохо ведет.
А, вот вы о чём. Я бы больше боялся бы что отвалится диск.
nvmet означает nmve-transport
nvmet - это nvme target. Драйвер содержит общий код реализции nvme таргета, а протоколо-специфичные вещи лежат, соответственно в nvmet-tcp, nvmet-rdma и т.д.
Просто торт!

NVME — это ключ к загрузке любой системы за 3 секунды
А можно сюда выхлоп systemd-analyze blame с Вашей системы?
Наверное, на системе с coreboot и тщательно вылизанной загрузкой можно и за 3, но попотеть придется.
Держите.
6.125s NetworkManager-wait-online.service
2.523s fwupd.service
2.166s plymouth-quit-wait.service
1.646s systemd-udev-settle.service
1.580s snap-core18-2246.mount
1.488s snap-core18-2253.mount
1.409s snap-snap\x2dstore-547.mount
1.310s snap-telegram\x2ddesktop-3544.mount
1.239s snap-slack-48.mount
1.138s snap-xmind-11.mount
1.103s systemd-backlight@backlight:intel_backlight.service
1.088s snap-gnome\x2d3\x2d34\x2d1804-72.mount
1.019s mysql.service
992ms snap-gnome\x2d3\x2d38\x2d2004-76.mount
936ms snap-kde\x2dframeworks\x2d5\x2dcore18-32.mount
883ms snap-firefox-777.mount
835ms snap-core20-1242.mount
778ms snap-kdiskmark-59.mount
709ms plymouth-read-write.service
676ms snap-firefox-767.mount
659ms snap-telegram\x2ddesktop-3530.mount
582ms snap-core-11743.mount
514ms snapd.service
512ms snap-youtube\x2ddl-4572.mount
472ms snap-shotcut-571.mount
424ms snap-gnome\x2d3\x2d38\x2d2004-87.mount
395ms dev-nvme0n1p6.device
374ms snap-gnome\x2d3\x2d34\x2d1804-77.mount
329ms snap-shotcut-568.mount
286ms snap-vlc-2344.mount
281ms upower.service
232ms snap-snap\x2dstore-558.mount
202ms cups.service
193ms udisks2.service
190ms snap-slack-49.mount
176ms networkd-dispatcher.service
169ms accounts-daemon.service
135ms snap-core20-1270.mount
129ms systemd-resolved.service
125ms RepetierServer.service
115ms snap-gtk\x2dcommon\x2dthemes-1519.mount
114ms snap-dbeaver\x2dce-149.mount
109ms ModemManager.service
105ms NetworkManager.service
105ms bluetooth.service
104ms avahi-daemon.service
104ms systemd-rfkill.service
100ms apparmor.service
97ms systemd-timesyncd.service
97ms ua-timer.service
95ms systemd-logind.service
92ms user@1000.service
89ms iio-sensor-proxy.service
89ms lvm2-monitor.service
89ms libvirtd.service
88ms snap-core-11993.mount
86ms polkit.service
84ms e2scrub_reap.service
82ms snap-jami-227.mount
82ms power-profiles-daemon.service
81ms apport.service
76ms systemd-udev-trigger.service
76ms update-notifier-download.service
73ms switcheroo-control.service
73ms systemd-journal-flush.service
70ms snapd.apparmor.service
69ms gpu-manager.service
61ms thermald.service
60ms snap-gnome\x2d3\x2d28\x2d1804-161.mount
60ms systemd-machined.service
57ms wpa_supplicant.service
57ms secureboot-db.service
57ms systemd-udevd.service
55ms grub-common.service
51ms open-fprintd.service
51ms qemu-kvm.service
45ms snap-caprine-48.mount
43ms swapfile.swap
42ms gdm.service
41ms keyboard-setup.service
39ms systemd-journald.service
38ms rsyslog.service
34ms bolt.service
32ms systemd-tmpfiles-setup.service
30ms colord.service
29ms run-qemu.mount
28ms snap-bare-5.mount
24ms multipathd.service
24ms systemd-modules-load.service
23ms libvirt-guests.service
21ms binfmt-support.service
21ms systemd-random-seed.service
20ms snapd.seeded.service
20ms packagekit.service
20ms systemd-fsck@dev-disk-by\x2duuid-56CF\x2d31C2.service
20ms systemd-tmpfiles-clean.service
18ms run-rpc_pipefs.mount
15ms plymouth-start.service
14ms alsa-restore.service
13ms modprobe@drm.service
13ms grub-initrd-fallback.service
11ms systemd-tmpfiles-setup-dev.service
11ms systemd-sysctl.service
10ms rtkit-daemon.service
10ms dev-hugepages.mount
9ms dev-mqueue.mount
9ms systemd-backlight@leds:platform::kbd_backlight.service
9ms systemd-sysusers.service
9ms sys-kernel-debug.mount
8ms sys-kernel-tracing.mount
8ms motd-news.service
8ms proc-sys-fs-binfmt_misc.mount
7ms kerneloops.service
7ms systemd-remount-fs.service
6ms kmod-static-nodes.service
6ms console-setup.service
6ms modprobe@configfs.service
5ms finalrd.service
5ms modprobe@fuse.service
5ms dev-loop6.device
5ms user-runtime-dir@1000.service
4ms nfs-config.service
4ms systemd-update-utmp.service
4ms dev-loop1.device
4ms systemd-user-sessions.service
4ms dev-loop3.device
4ms boot-efi.mount
4ms dev-loop5.device
3ms dev-loop4.device
3ms systemd-update-utmp-runlevel.service
3ms dev-loop2.device
3ms dev-loop12.device
3ms dev-loop14.device
3ms dev-loop11.device
3ms dev-loop8.device
3ms dev-loop15.device
3ms dev-loop13.device
3ms dev-loop17.device
3ms dev-loop24.device
3ms openvpn.service
3ms dev-loop10.device
3ms dev-loop25.device
3ms dev-loop21.device
2ms sys-fs-fuse-connections.mount
2ms rpcbind.service
2ms libvirtd.socket
2ms ufw.service
2ms dev-loop18.device
2ms sys-kernel-config.mount
2ms dev-loop27.device
1ms dev-loop9.device
1ms dev-loop16.device
1ms snapd.socket
1ms dev-loop23.device
1ms dev-loop7.device
1ms dev-loop0.device
1ms dev-loop26.device
1ms dev-loop28.device
1ms dev-loop19.device
1ms dev-loop30.device
1ms dev-loop22.device
1ms setvtrgb.service
580us dev-loop20.device
573us dev-loop29.device
25us blk-availability.serviceСистема, кстати, Lenovo Yoga C940. Не знаю, что там последний сервис, который за шесть секунд стартует, но система становится доступной буквально за 3. Кстати, интересное дело, приличная часть всех этих стартов — это Снаповские пакеты. Может мне из посносить?
он ожидает, пока сетевые интерфейсы поднимутся и получат ip-адрес.
До включения логгера много всего происходит, включая UEFI. Вы же считаете 3 сек. не от момента нажатия кнопки питания, а от появления первой строки вывода ядра или экрана GRUB, так? У Вас неплохо сбалансирована загрузка, кстати. Система совсем свежая?
А снапы... Сами смотрите, они Вам реально нужны? Не хочу давать советов, не зная задач. Наверное, лучше почитать вот это и решить самому.
Реально оно не сильно тормозит систему, грузясь в бэкграунде. Если бы надо было систему после включения в жесткий реалтайм вводить как можно быстрее, например, для выдачи данных с камеры заднего вида в авто - стоило бы, а так...
А как шо по секьюрности? Так же получается любой "дурак" с nvmet-cli на борту, доступом к сети и знаниями куда подключаться, может это сделать?
Напишу в следующей публикации. Но, в этой я упомянул - подключение работает только от определённых хостов.
Это лайк! Я почему спрашиваю - просто нафиг та samba нужна(условно), если есть шо-то модное, современное, молодежное.
Самбу и nfs это не заменит в любом случае. Скорее iscsi. В спеке есть только аутентификация, чтобы чисто защитить от подключения любого "дурака" снаружи. Если TCP, то естественно все это можно обернуть в TLS, но не более того. Никакой авторизации, разграничения прав, ничего этого нет и вряд ли будет. Это низкоуровневый интерфейс для блочных устройств. Авторизация это уже дело систем выше уровнем. По сути, это все делается для облачных провайдеров, которые имеют полный контроль над фабрикой, а клиент видит только то, что у него в системе новое устройство появилось.
Вот это ояень важно, поэтому и спросил. По идее на сервере мы же задаем права пользователей к разделам, папкам. Получается эти заданные права реплицируются на клиента nvmet? Думаю этого достаточно для секретности. Хотя я говорю мыслю, как чайник, поэтому поправьте, если что..
Короче да, хотелось бы сравнения с samba-й и nfs-ом до кучи.
Дык, nvme это блочное устройство. Какие там на нем права и разделы, и есть ли они вообще там, nvme до этого нет никакого дела. Его дело предоставить клиенту доступ к чему-то по nvme протоколу. На той стороне ведь может даже не диск быть, а все что угодно, хоть флоппи дисковод. Nvme это просто протокол, ему это все ортогонально. Ему сказали дай мне 4к блок по вот такому LBA, он его и выдаст.
Согласен. Но что-то же выдает права rw-x - все эти.. Ядро не ядро. Я хз, кто этим занимается.
Их выдает драйвер файловой системы, что находится несколькими уровнями выше nvme протокола. Вот, например, исходник ext4 и где у него в inode лежат те самые права https://github.com/torvalds/linux/blob/master/fs/ext4/ext4.h#L784
nvme дает блочное устройство, на этом уровне нет ни прав, ни файлов, ни файловой системы. Есть блоки, в которых лежат рандомные байты. Кто и как их трактовать будет nvme пофиг. Это все равно, что задаваться вопросом, где мои HTTP куки для авторизации пользователя, когда мы обсуждаем ethernet протокол. Поэтому и сравнение с самбой и нфс тут не провести - это просто совершенно разные вещи.
Правильный вопрос не кто "выдаёт", а кто проверяет. Так вот, при подключении диска по сети как блочного устройства права на файлы проверять будет клиент, а не сервер.
Я думаю, не надо пояснять почему проверка прав на клиенте в общем случае — плохая идея?
Хороший вопрос. Я так сходу в спеке не нашёл упоминаний подобного, чтобы nvme как-то сказал, что доступ только на чтение. Неизвестно будет ли подобный юзкейс вообще рассматриваться или все же до юзера мы все равно отдаём iscsi
Тут, судя по всему, доступ есть доступ. Либо он у тебя есть, либо его нет.
К одному устройству могут получить доступ несколько хостов одновременно. Это работает. В пределах разумного, конечно. В одну и ту же fs писать не получится, но если вы организуете 3 lvm volume и каждый хост будет писать в свой раздел, то это работает.
Да, тут, как нижу объяснили, и как я.сказал в статье - это не распределённая файловая система. Тут писать может только один клиент в один отрезок времени. Тут мы даже далеко от самой концепции фс.
Можете разврнуть вот эту мысль "Диски в адаптере. Внимание! Не используйте в настоящих серверах! Для этого есть форм-факторы получше" ? у меня как раз сервер и я планировал поставить в него такую конструкцию AOC-SLG3-2M2 | Add-on Cards | Accessories | Products - Super Micro Computer, Inc.
Зависит от того, как вы будете обслуживать сервер. Если эти nvme у вас для кеша, и один из них умрёт, то вам пофиг. Останавливаете сервер и меняете диск.
M.2 порты не поддерживают горячую замену. А жаль. Есть еще U.2 порты. Я их щас изучаю. Проблема в том, что U.2 совместимые диски стоят в три раза дороже серверных M.2
Проблема в том, что U.2 совместимые диски стоят в три раза дороже серверных M.2
Плохо как-то смотрите, у микрона они стоят плюс-минус одинаково.
https://www.kns.ru/product/ssd-disk-micron-7300-pro-1-92tb-mtfdhbe1t9tdf/
https://www.kns.ru/product/ssd-disk-micron-7300-pro-1-92tb-mtfdhbg1t9tdf/
Хм. Интересно. Я буду здесь искать. У меня нет доступа к Московским магазинам. Но, спасибо за наводку.
Тут ещё есть прикол в том, что U.2 идёт с существенно более дорогим контроллером. Нужен S140, с другой стороны M.2 вообще ничего не требует. Соответственно, здесь нужно включать оценку по принципу цена/быстрота/скорость восстановления от сбоев.
U.2 требует тоже самое что m.2, подключение к шине pcie, как вы это сделаете ему без разницы, это просто другой форм фактор.
В общем вы правы. Я просто не знаю, как эта шина подводится от процессора к дискам?
Как правило, оба подключены напрямую к процессору. U.2 так уж точно, т.к. здесь речь о high-end дисках. Обычно от бекплейна идут кабели в oculink порты. m.2 бывает подключаются к чипсету на интел платформах, но это все равно полноценные линии pcie, которые в конечном итоге упираются в процессор.
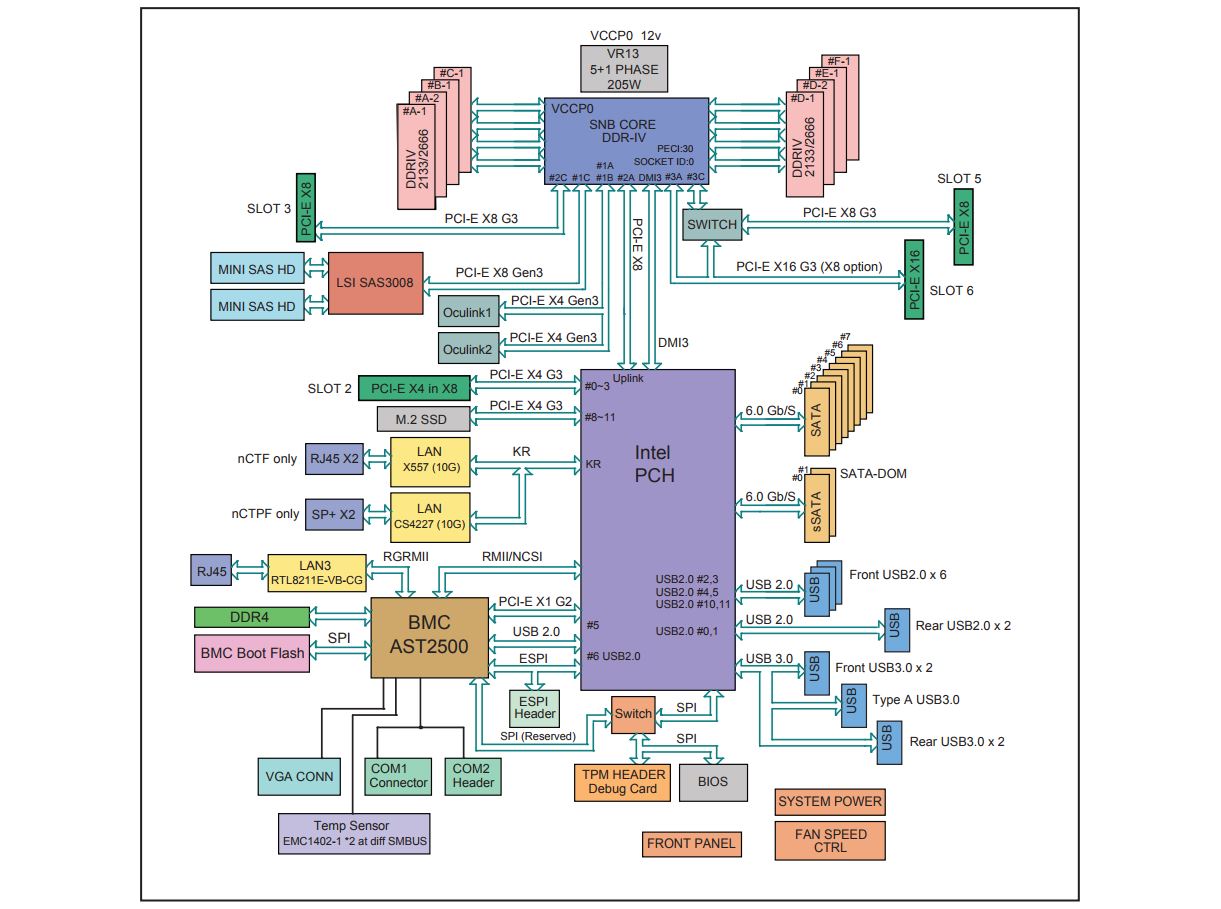
https://polyworks.kz/wp-content/uploads/2017/09/Supermicro-X11SPH-nCTF-Block-Diagram.jpg
Нужен S140
Это какие-то приколы делл? Зачем нужна эта безделушка? Почитал, какая-то плата с контроллером, но при этом рейд софтварный и требует драйвера в винде (для линукса вроде умеет прикидываться mdraid и линукс ничего про этот контроллер не знает). Зачем оно нужно? Что винда, что линукс умеют без сторонних средств делать зеркало для загрузочного раздела. На остальных дисках это чудо тем более не нужно, рейд можно чем угодно настроить.
Я конечно понимаю, прикольно, когда рейд настраивается из под UEFI и логотип делл красуется, но какая-то пустая трата денег в нынешние времена. Я бы понял, если бы рейд там аппаратный был, но для U.2 это было бы вообще кощунство.
Если честно, я просто не совсем в теме. Сижу и с удовольствием записываю всё, что вы тут говорите. Конечно, с самими дисками без контроллеров работать проще и дешевле. Я просто понятия не имею, как правильно собрать сервер с nvme ssd. А с этим было-бы интересно разобраться.
Я вот как раз не теме всех этих делл и прочих энтерпрайзов, где понапихано непонятных всяких контроллеров за огромные деньги и ниодной нормальной схемы, чтобы понять, как это поделие все работает.
Я бы собирал очень просто. Взял бы любую платформу, где U.2 бекплейн имеет прямое подключение к процессору для каждого диска, минуя даже pcie свитчи. Если не хочется с NUMA бодаться, то взять однопроцессорную.
Вот пример топовый топ https://www.supermicro.com/en/Aplus/system/2U/2124/AS-2124US-TNRP.cfm 24 диска, 96 pcie 4.0 линий, напрямую идущих из процессора. Тут конечно ретаймеры понадобились, но для 4.0 похоже по-другому уже никак.
Красиво, но уж очень дорого. Тут ещё есть вопрос в гигабайтах диска по гигабиту сети.
Ну ethernet 100G/200G/400G/800G не зря делают. Не факт правда, что процы смогут вывезти такие скорости.
Есть вот такая платформа https://www.supermicro.com/en/Aplus/system/1U/1114/AS-1114S-WN10RT.cfm Дешево, но скорости все равно огромные можно достичь
Продолжение ждем?

{kind=link}
А все ли врут? Продолжаем издеваться над NVME