Мы уже рассказывали про некоторые работы исследователей из московского Центра искусственного интеллекта Samsung. Недавно вышла статья «f-BRS: Rethinking Backpropagating Refinement for Interactive Segmentation» Константина Софиюка, Ильи Петрова, Ольги Бариновой и Антона Конушина, которая была принята на всемирную конференцию по компьютерному зрению CVPR 2020. И в этом посте мы расскажем, о чем пишут наши коллеги в этой работе и об интерактивной сегментации как прикладной задаче компьютерного зрения в целом.

В широком смысле «сегментация», как следует из Оксфордского словаря, — это разделение чего-либо на несколько частей, либо одна из таких частей. В нашем случае сегментация — это задача в компьютерном зрении, которая позволяет разделить цифровое изображение на разные части (сегменты) в соответствии с тем, какому объекту какие пиксели принадлежат. Таким образом мы получаем попиксельную маску объекта.
Виды сегментации:
Применений сегментации изображений масса. Семантическая и инстанс-сегментация могут использоваться в беспилотных автомобилях и роботах. Камеры служат для получения точной визуальной информации об окружающей среде (наряду с остальной информацией от датчиков и сенсоров), но критически важное условие правильной работы — насколько хорошо алгоритм понимает, что сейчас окружает робота.
Другая область применения — медицина, где с помощью семантической или инстанс-сегментации можно проанализировать рентгенографические и электронно-микроскопические снимки — например, в стоматологии, пульмонологии, онкологии, генетике и т.д. С помощью сегментации анализируют спутниковые изображения и карты, скопления людей и объекты глубокого космоса.
Ручная разметка позволила собрать датасеты (например, ImageNet и Microsoft COCO), лежащие в основе всех современных достижений компьютерного зрения. Один из самых ценных и трудоёмких видов разметки — сегментация изображений. Отличие интерактивной сегментации в том, что она требует участия пользователя на протяжении всего процесса. В частности, пользователь может выделять нужные объекты и исправлять ошибки алгоритма с помощью кликов. Интерактивная сегментация может использоваться в различных приложениях и для редактирования изображений. Например, в Paint 3D на Windows 10 есть функция выделения областей изображения кликом.
В данной работе рассматривается кликовая (click-based) интерактивная сегментация: пользователь выделяет нужные объекты с помощью позитивных или негативных кликов. Позитивные клики указывают, что область клика относится к нужному объекту, а негативные — что не относится.
Большая часть алгоритмов интерактивной сегментации, основанной на кликах (click-based), содержит backbone-сеть, предобученную на датасете ImageNet. На вход backbone-сеть получает само изображение и карты позитивных и негативных кликов. На выходе модель создает сегментационную маску для нужного объекта. Основная проблема такого подхода — невозможно скорректировать результат ответа нейросети. Эта проблема возникает из-за особенностей нейронных сетей — в некотором смысле они являются черными ящиками, и никто не может гарантировать, что у обученной модели всегда будет выполняться очевидный для людей инвариант: под позитивным кликом всегда должна быть маска объекта, а под негативным — нет. Пример: пользователь ставит клик на объекте, но нейросеть почему-то не выделяет область под кликом. Кликает еще раз — результат не меняется, потому что нейросеть выдала неправильный ответ на заданный клик, и этот ответ не поддается коррекции.
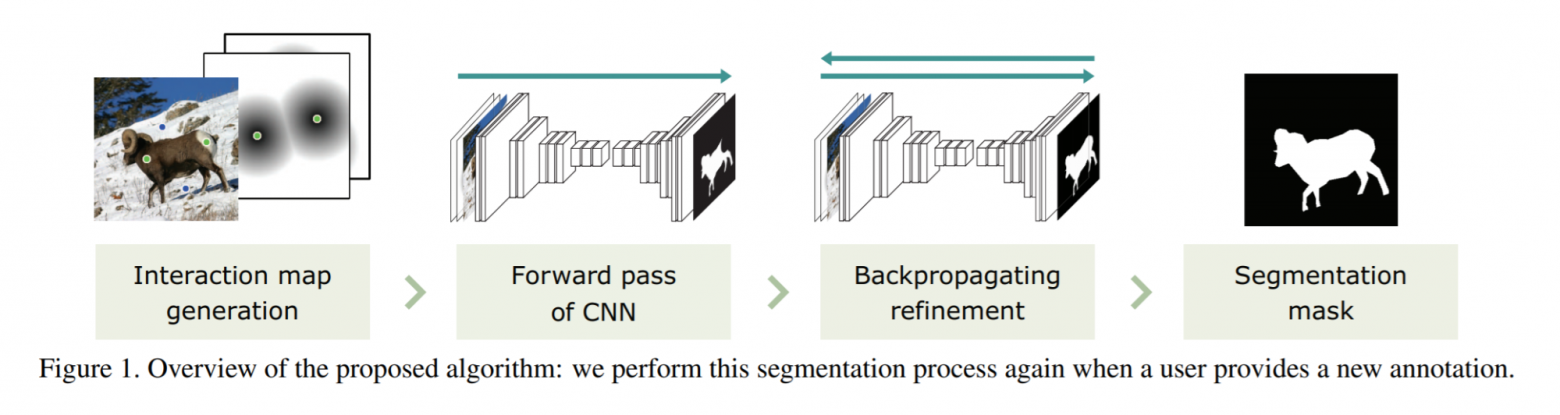
Как можно разрешить эту проблему? На конференции CVPR 2019 авторы из Гарварда и университета Корё в совместной работе Interactive Image Segmentation via Backpropagating Refinement Scheme представили технику для улучшения существующих алгоритмов интерактивной сегментации. Сначала по пользовательскому вводу создаются карты с позитивными и негативными кликами. Они передаются в сверточную нейронную сеть вместе с исходным изображением, и дальше все стандартно – нейросеть генерирует карту вероятностей. В этой карте для каждого пикселя задается вероятность того, что данный пиксель принадлежит к нужному нам объекту. Поскольку нейросеть не гарантирует, что в указанных кликах будут корректные предсказания, авторы предложили использовать схему уточняющих обратных проходов (backpropagating refinement scheme, BRS), в результате применения которой при следующем прямом проходе получается корректная сегментационная маска.
Источник
За счёт чего это достигается? В BRS решается следующая оптимизационная задача — необходимо минимизировать среднеквадратичную ошибку (MSE loss) предсказания только в тех точках, где находятся пользовательские клики. Для этого попиксельно модифицируется карта расстояний пользовательских кликов (distance maps) так, чтобы выход сети лучше им соответствовал. На наш взгляд интуиция, объясняющая успех такого решения, берёт своё начало с методов adversarial attacks (заметим, что авторы в своей статье не провели подобной аналогии). Благодаря открытию adversarial attacks, стало известно, что небольшие изменения входов сети (обычно это просто RGB изображение) могут кардинально повлиять на итоговый результат предсказания. BRS по своей сути является той же самой оптимизационной задачей, которую решают для осуществления adversarial attacks.

BRS имеет и свои минусы. Главный его недостаток — долгое время работы, поскольку на каждой итерации совершается обратный проход по всей сети.
Прежде чем переходить к описанию предложенного решения, обратимся к недавней статье авторов из московского Центра искусственного интеллекта Samsung, в которой решается задача инстанс-сегментации. Представленная архитектура построена на основе предобученной на ImageNet сети. В ней есть:

«Голова» сети принимает на вход клик, и затем вся сеть подстраивается под заданный объект.
Почему мы обратились к этой статье? Совсем недавно авторы из московского Центра искусственного интеллекта Samsung открыли, что BRS, о которой говорилось выше, можно применять к любой части сети. Это открытие вместе с переосмыслением идей из рассмотренной выше статьи позволило создать f-BRS — Feature Backpropagating Refinement Scheme — в которой любой выход промежуточного слоя сети может выступать в качестве целевой переменной оптимизации. В f-BRS оптимизируется только небольшой набор параметров внутри сети, а именно scale и bias для признаков фиксированного слоя. Это сохраняет точность и существенно повышает скорость работы алгоритма.
У метода f-BRS есть несколько возможных конфигураций (f-BRS-A, f-BRS-B, f-BRS-C). Они отличаются положением промежуточных слоев, которые должны быть оптимизированы. В экспериментах рассматриваются только промежуточные слои декодера DeepLabV3+, что позволяет обеспечить снижение вычислительных затрат на обратный проход BRS.
Представленная архитектура выглядит так:
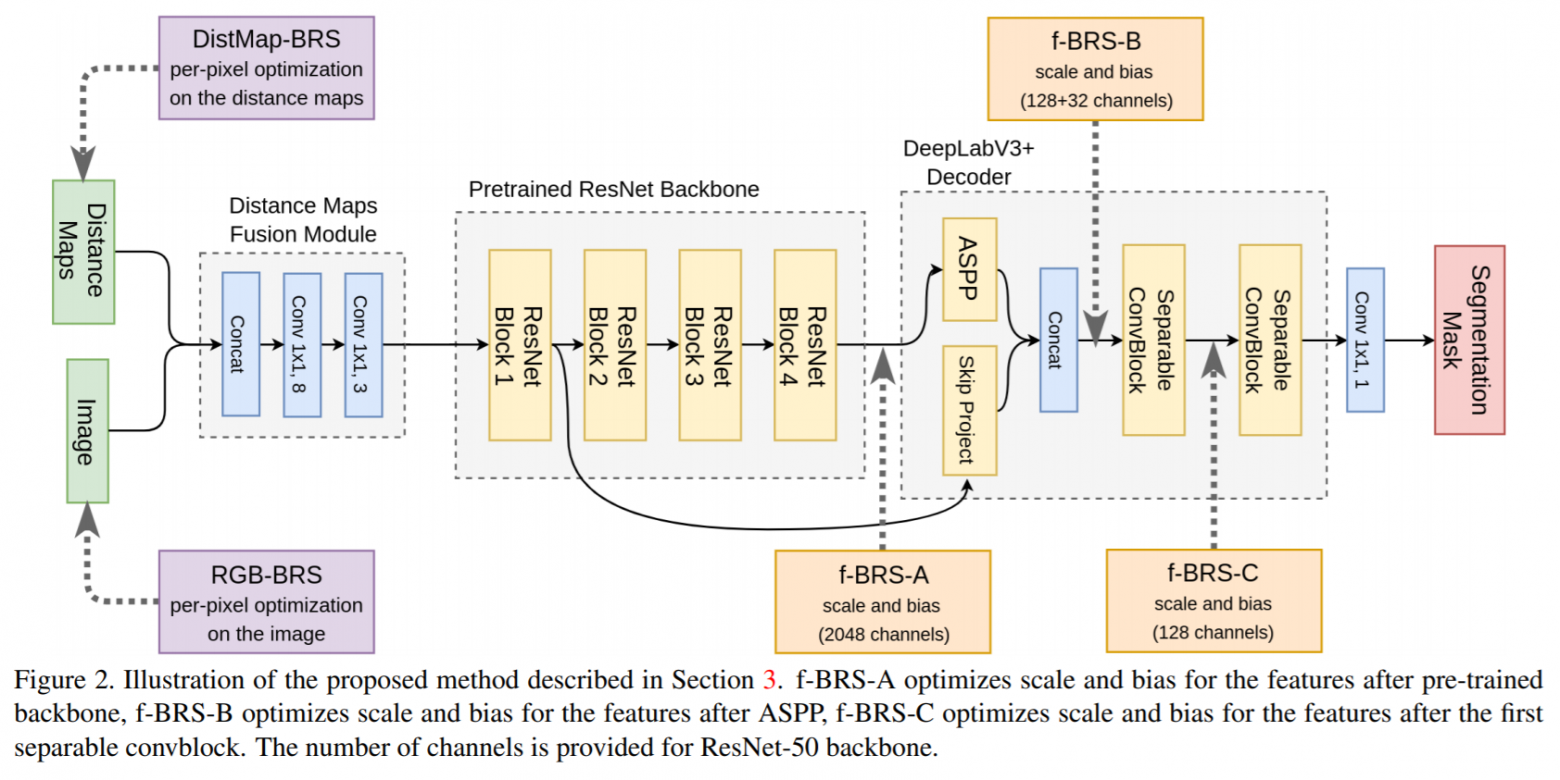
Существует два подхода для модифицирования промежуточных слоев — попиксельный (pixel-wise) и поканальный (channel-wise). В pixel-wise подходе, имея тензор 100x100 по ширине и высоте и 64 по глубине, мы получаем 100x100x64x2=12800000 параметров. Чем больше число параметров, тем больше вероятность, что сеть будет переобучаться. Кроме того, все значения карты признаков оптимизируются независимо, что может приводить к проблеме «локального переобучения» (см. иллюстрацию ниже). В channel-wise подходе мы работаем только с 64 каналами и обучаем гораздо меньше параметров, что делает подход устойчивым к переобучению.
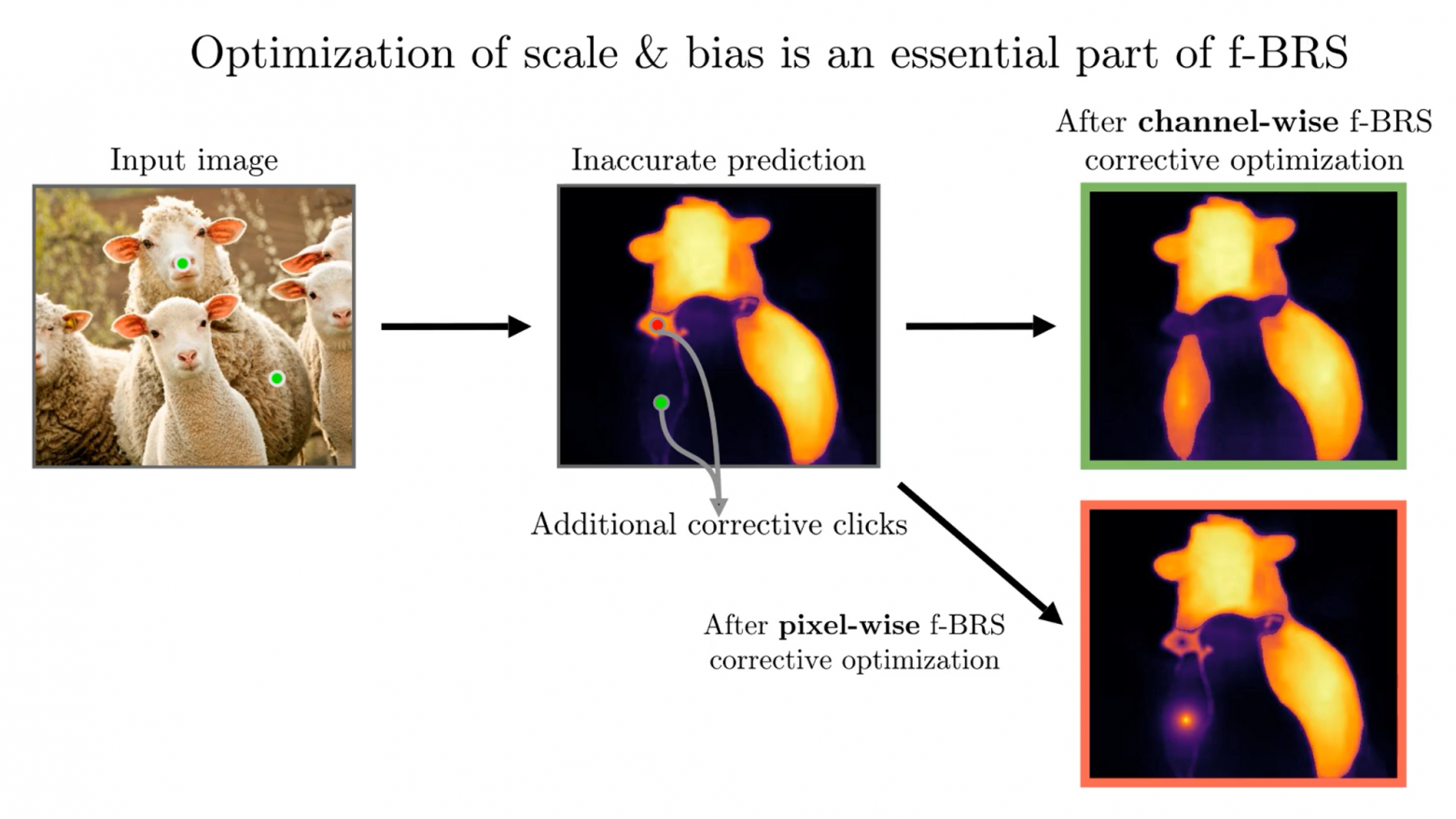
Поканальный (channel-wise) подход решает проблему локального переобучения — сеть понимает, где объект «овца», а где объект «ягненок»
Еще одно нововведение, которое представлено в статье — техника Zoom-In, которая позволяет улучшить качество интерактивной сегментации. В предыдущих работах по интерактивной сегментации использовались кропы изображений, чтобы ускорить модель и сохранить мелкие детали в масках сегментации. Это позволяет получить более точные маски маленьких объектов, но, с другой стороны, результаты могут стать хуже в случае, если исходное разрешение объекта больше разрешения кропа.
Эксперименты показали, что 1-3 кликов достаточно, чтобы нейросеть достигла 80% меры Жаккара (Intersection over Union, IoU) по отношению к ground truth-маске. То есть, начиная с третьего клика, можно получать кропы в соответствии с ограничивающим прямоугольником (bounding box) маски объекта и применять интерактивную сегментацию только к нужному участку изображения.
Пошагово технику Zoom-In можно записать следующим образом:
Ниже показана визуализация применения Zoom-In.

Zoom-In улучшил результаты во всех экспериментах и использовался по умолчанию вместе с f-BRS. При этом Zoom-In можно применять и вместе с другими моделями для интерактивной сегментации.
Эксперименты проводились на четырех датасетах: GrabCut, Berkeley, DAVIS и SBD.
Во всех случаях f-BRS устанавливает новую планку качества в интерактивной сегментации.
Пример — сравнение результатов, в первом ряду используется предложенная f-BRS, во втором BRS не задействована.
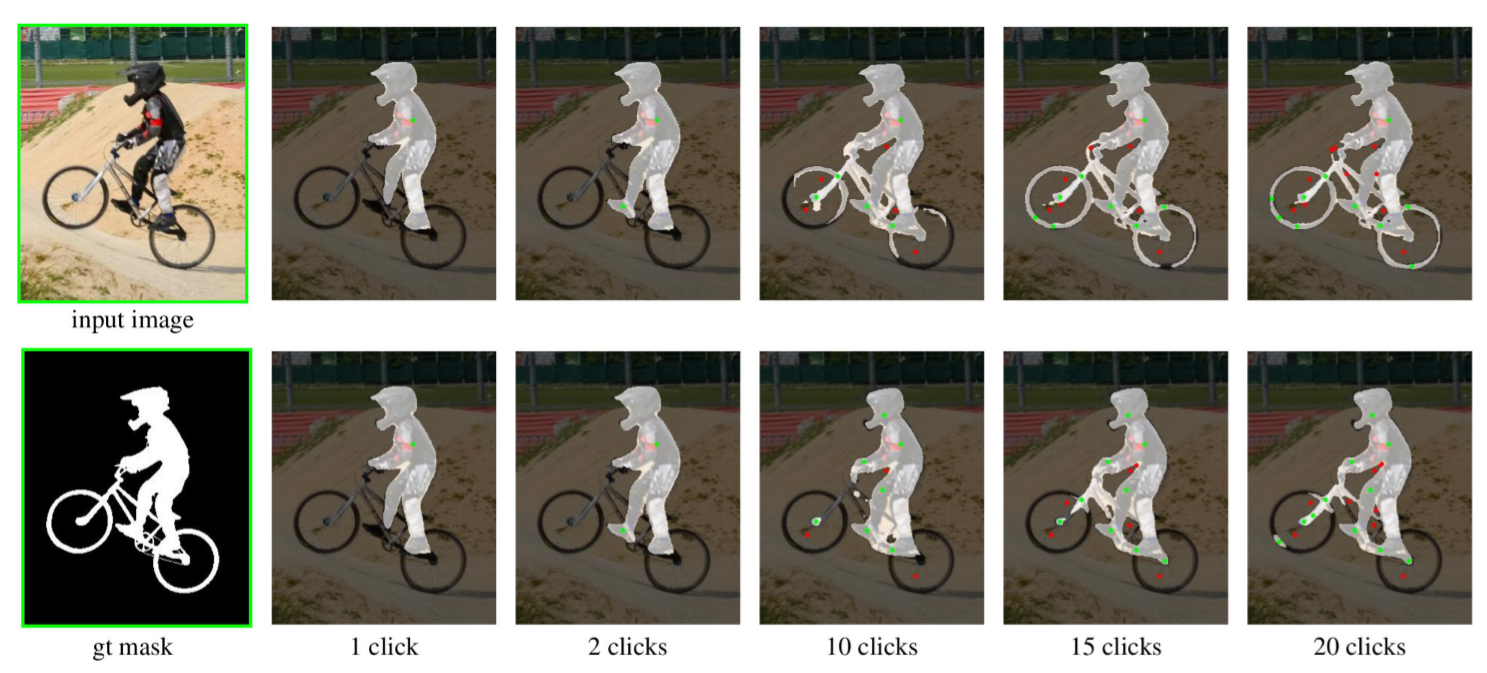
Что здесь бросается в глаза? Без f-BRS, несмотря на настойчивые попытки пользователя включить велосипед в область положительной сегментации, модель продолжает наращивать маску, относящуюся к спортсмену. Получается, что f-BRS требует меньше кликов, то есть гораздо меньше работы по ручной сегментации.
Для тех, кто дочитал наш пост до конца и готов воспроизвести результат, создав собственные иллюстрации, мы предлагаем взять код к статье здесь и посмотреть видеопрезентацию на CVPR 2020 — здесь.
А тех, кто сейчас только поставил перед собой задачу с нуля научиться решать задачи в области машинного зрения при помощи нейросетей, мы приглашаем записаться на наш бесплатный онлайн-курс на Stepik! В финале курса вы уже осознанно решите прикладную задачу компьютерного зрения и можно будет двигаться в более продвинутую область сегментации изображений.
 Автор статьи:
Автор статьи:
Юлия Чуркина
Специалист по управлению проектами,
Центр искусственного интеллекта Samsung
Что такое сегментация?
В широком смысле «сегментация», как следует из Оксфордского словаря, — это разделение чего-либо на несколько частей, либо одна из таких частей. В нашем случае сегментация — это задача в компьютерном зрении, которая позволяет разделить цифровое изображение на разные части (сегменты) в соответствии с тем, какому объекту какие пиксели принадлежат. Таким образом мы получаем попиксельную маску объекта.
Виды сегментации:
- Семантическая сегментация (Semantic segmentation) — определяет принадлежность наборов пикселей на изображении к определенным классам объектов (например, кошки, собаки, люди, цветы, автомобили и т.д.).
- Инстанс-сегментация (Instance segmentation) — в отличие от семантической сегментации, в этой задаче каждый объект внутри одного класса выделяется отдельными сегментами. Например, если на изображении пять кошек, две собаки и десять растений, семантическая сегментация просто выделит все области, на которых есть кошки, собаки или растения, не разделяя отдельные объекты внутри каждого класса (определит, что на изображении есть кошки, собаки и растения), в то время как инстанс-сегментация выделит каждую кошку, собаку и растение как отдельный объект.
- Паноптическая сегментация (Panoptic segmentation) — объединяет задачи семантической и инстанс-сегментации. Также в задаче паноптической сегментации каждому пикселю изображения должна быть присвоена ровно одна метка.
Зачем она нужна?
Применений сегментации изображений масса. Семантическая и инстанс-сегментация могут использоваться в беспилотных автомобилях и роботах. Камеры служат для получения точной визуальной информации об окружающей среде (наряду с остальной информацией от датчиков и сенсоров), но критически важное условие правильной работы — насколько хорошо алгоритм понимает, что сейчас окружает робота.
Другая область применения — медицина, где с помощью семантической или инстанс-сегментации можно проанализировать рентгенографические и электронно-микроскопические снимки — например, в стоматологии, пульмонологии, онкологии, генетике и т.д. С помощью сегментации анализируют спутниковые изображения и карты, скопления людей и объекты глубокого космоса.
Интерактивная сегментация изображений
Ручная разметка позволила собрать датасеты (например, ImageNet и Microsoft COCO), лежащие в основе всех современных достижений компьютерного зрения. Один из самых ценных и трудоёмких видов разметки — сегментация изображений. Отличие интерактивной сегментации в том, что она требует участия пользователя на протяжении всего процесса. В частности, пользователь может выделять нужные объекты и исправлять ошибки алгоритма с помощью кликов. Интерактивная сегментация может использоваться в различных приложениях и для редактирования изображений. Например, в Paint 3D на Windows 10 есть функция выделения областей изображения кликом.
Про задачу и существующие способы её решения
В данной работе рассматривается кликовая (click-based) интерактивная сегментация: пользователь выделяет нужные объекты с помощью позитивных или негативных кликов. Позитивные клики указывают, что область клика относится к нужному объекту, а негативные — что не относится.
Большая часть алгоритмов интерактивной сегментации, основанной на кликах (click-based), содержит backbone-сеть, предобученную на датасете ImageNet. На вход backbone-сеть получает само изображение и карты позитивных и негативных кликов. На выходе модель создает сегментационную маску для нужного объекта. Основная проблема такого подхода — невозможно скорректировать результат ответа нейросети. Эта проблема возникает из-за особенностей нейронных сетей — в некотором смысле они являются черными ящиками, и никто не может гарантировать, что у обученной модели всегда будет выполняться очевидный для людей инвариант: под позитивным кликом всегда должна быть маска объекта, а под негативным — нет. Пример: пользователь ставит клик на объекте, но нейросеть почему-то не выделяет область под кликом. Кликает еще раз — результат не меняется, потому что нейросеть выдала неправильный ответ на заданный клик, и этот ответ не поддается коррекции.
Как можно разрешить эту проблему? На конференции CVPR 2019 авторы из Гарварда и университета Корё в совместной работе Interactive Image Segmentation via Backpropagating Refinement Scheme представили технику для улучшения существующих алгоритмов интерактивной сегментации. Сначала по пользовательскому вводу создаются карты с позитивными и негативными кликами. Они передаются в сверточную нейронную сеть вместе с исходным изображением, и дальше все стандартно – нейросеть генерирует карту вероятностей. В этой карте для каждого пикселя задается вероятность того, что данный пиксель принадлежит к нужному нам объекту. Поскольку нейросеть не гарантирует, что в указанных кликах будут корректные предсказания, авторы предложили использовать схему уточняющих обратных проходов (backpropagating refinement scheme, BRS), в результате применения которой при следующем прямом проходе получается корректная сегментационная маска.
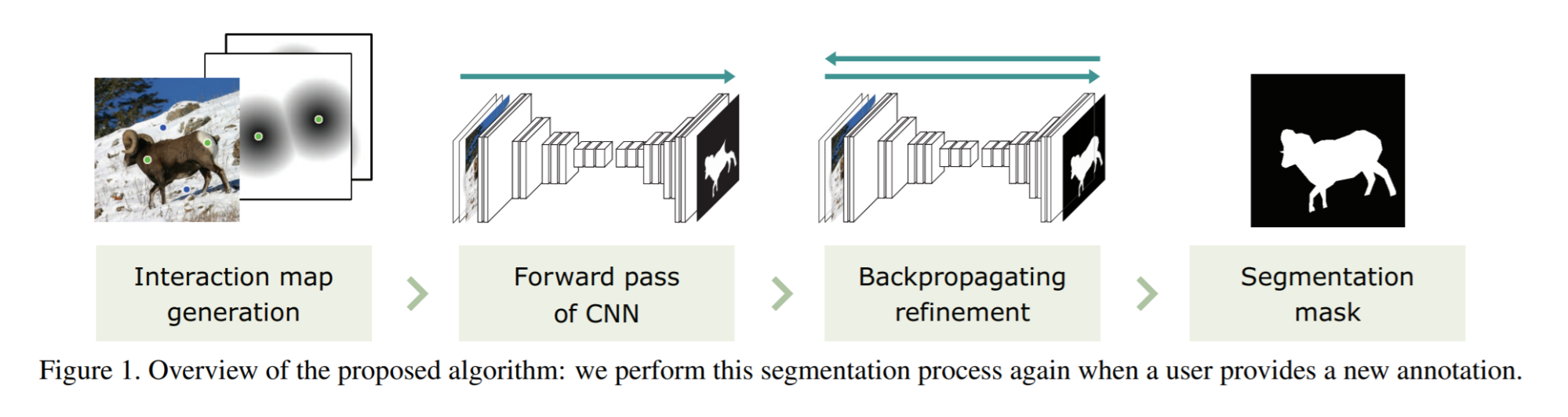
Источник
За счёт чего это достигается? В BRS решается следующая оптимизационная задача — необходимо минимизировать среднеквадратичную ошибку (MSE loss) предсказания только в тех точках, где находятся пользовательские клики. Для этого попиксельно модифицируется карта расстояний пользовательских кликов (distance maps) так, чтобы выход сети лучше им соответствовал. На наш взгляд интуиция, объясняющая успех такого решения, берёт своё начало с методов adversarial attacks (заметим, что авторы в своей статье не провели подобной аналогии). Благодаря открытию adversarial attacks, стало известно, что небольшие изменения входов сети (обычно это просто RGB изображение) могут кардинально повлиять на итоговый результат предсказания. BRS по своей сути является той же самой оптимизационной задачей, которую решают для осуществления adversarial attacks.
BRS имеет и свои минусы. Главный его недостаток — долгое время работы, поскольку на каждой итерации совершается обратный проход по всей сети.
Предлагаемое решение
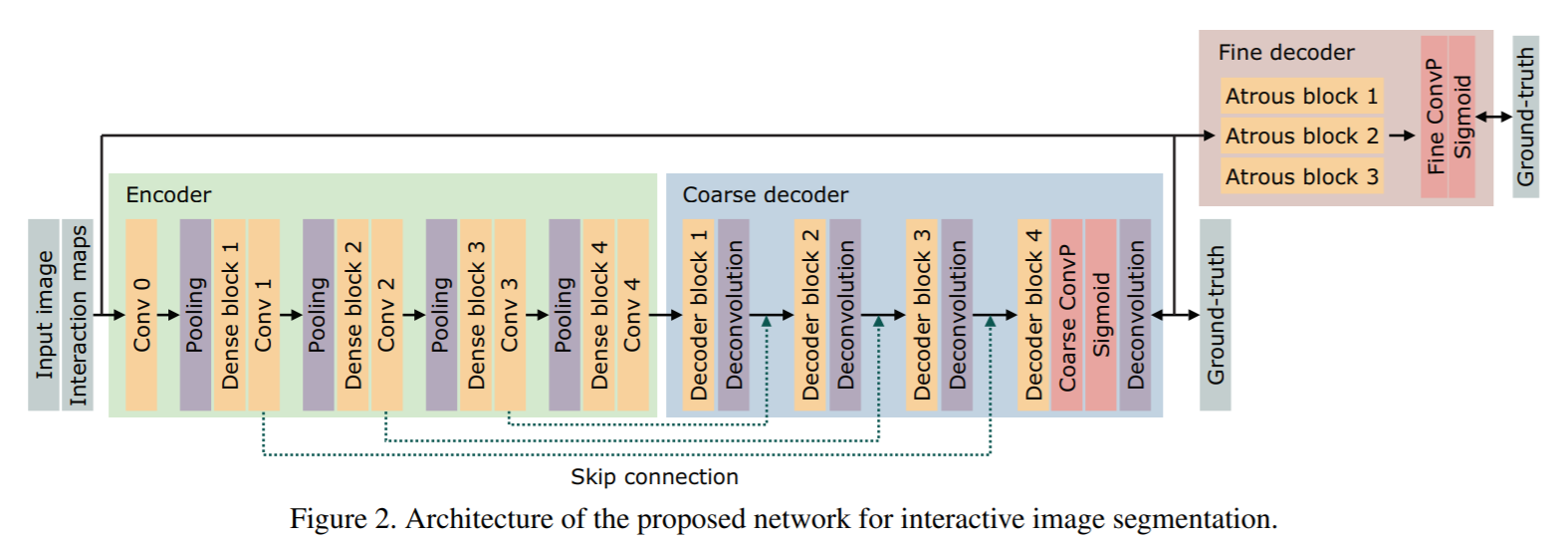
Прежде чем переходить к описанию предложенного решения, обратимся к недавней статье авторов из московского Центра искусственного интеллекта Samsung, в которой решается задача инстанс-сегментации. Представленная архитектура построена на основе предобученной на ImageNet сети. В ней есть:
- Instance selection network. Она предсказывает маски объектов по заданным координатам, адаптируясь под каждый конкретный объект с помощью операции AdaIN — адаптивной раздельной нормализации (Adaptive Instance Normalization).
- Сеть-контроллер (controller network), которая извлекает признак из backbone-сети в координатах (x, y), пропускает его через полносвязные слои, а затем с помощью полученных параметров настраивает AdaIN-слои в Instance selection network.
- Блок Relative CoordConv помогает отличить похожие объекты, расположенные в разных местах изображения, путем добавления к признакам сети пространственной информации о координатах (x, y)

«Голова» сети принимает на вход клик, и затем вся сеть подстраивается под заданный объект.
Почему мы обратились к этой статье? Совсем недавно авторы из московского Центра искусственного интеллекта Samsung открыли, что BRS, о которой говорилось выше, можно применять к любой части сети. Это открытие вместе с переосмыслением идей из рассмотренной выше статьи позволило создать f-BRS — Feature Backpropagating Refinement Scheme — в которой любой выход промежуточного слоя сети может выступать в качестве целевой переменной оптимизации. В f-BRS оптимизируется только небольшой набор параметров внутри сети, а именно scale и bias для признаков фиксированного слоя. Это сохраняет точность и существенно повышает скорость работы алгоритма.
У метода f-BRS есть несколько возможных конфигураций (f-BRS-A, f-BRS-B, f-BRS-C). Они отличаются положением промежуточных слоев, которые должны быть оптимизированы. В экспериментах рассматриваются только промежуточные слои декодера DeepLabV3+, что позволяет обеспечить снижение вычислительных затрат на обратный проход BRS.
Представленная архитектура выглядит так:
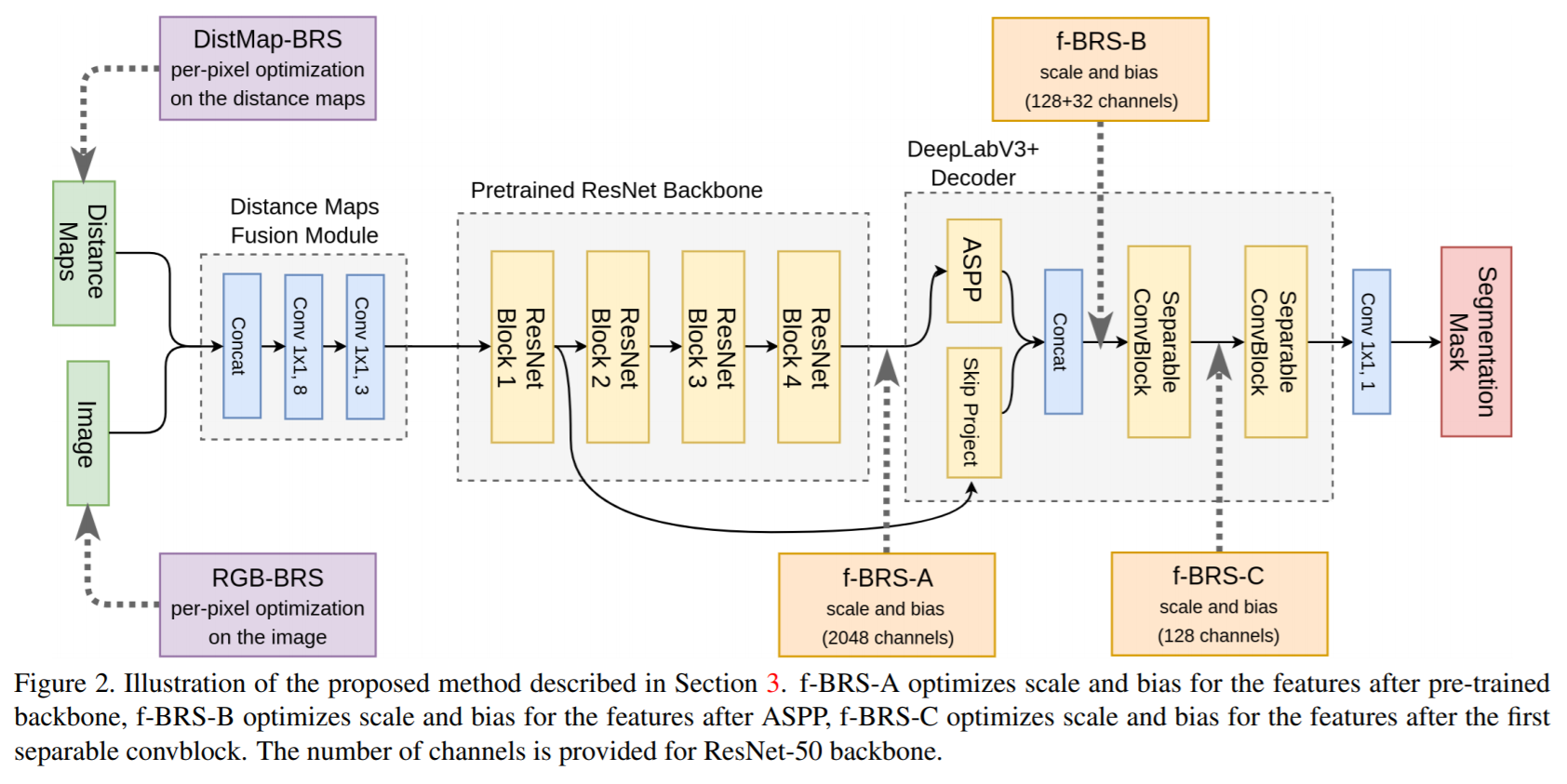
Существует два подхода для модифицирования промежуточных слоев — попиксельный (pixel-wise) и поканальный (channel-wise). В pixel-wise подходе, имея тензор 100x100 по ширине и высоте и 64 по глубине, мы получаем 100x100x64x2=12800000 параметров. Чем больше число параметров, тем больше вероятность, что сеть будет переобучаться. Кроме того, все значения карты признаков оптимизируются независимо, что может приводить к проблеме «локального переобучения» (см. иллюстрацию ниже). В channel-wise подходе мы работаем только с 64 каналами и обучаем гораздо меньше параметров, что делает подход устойчивым к переобучению.
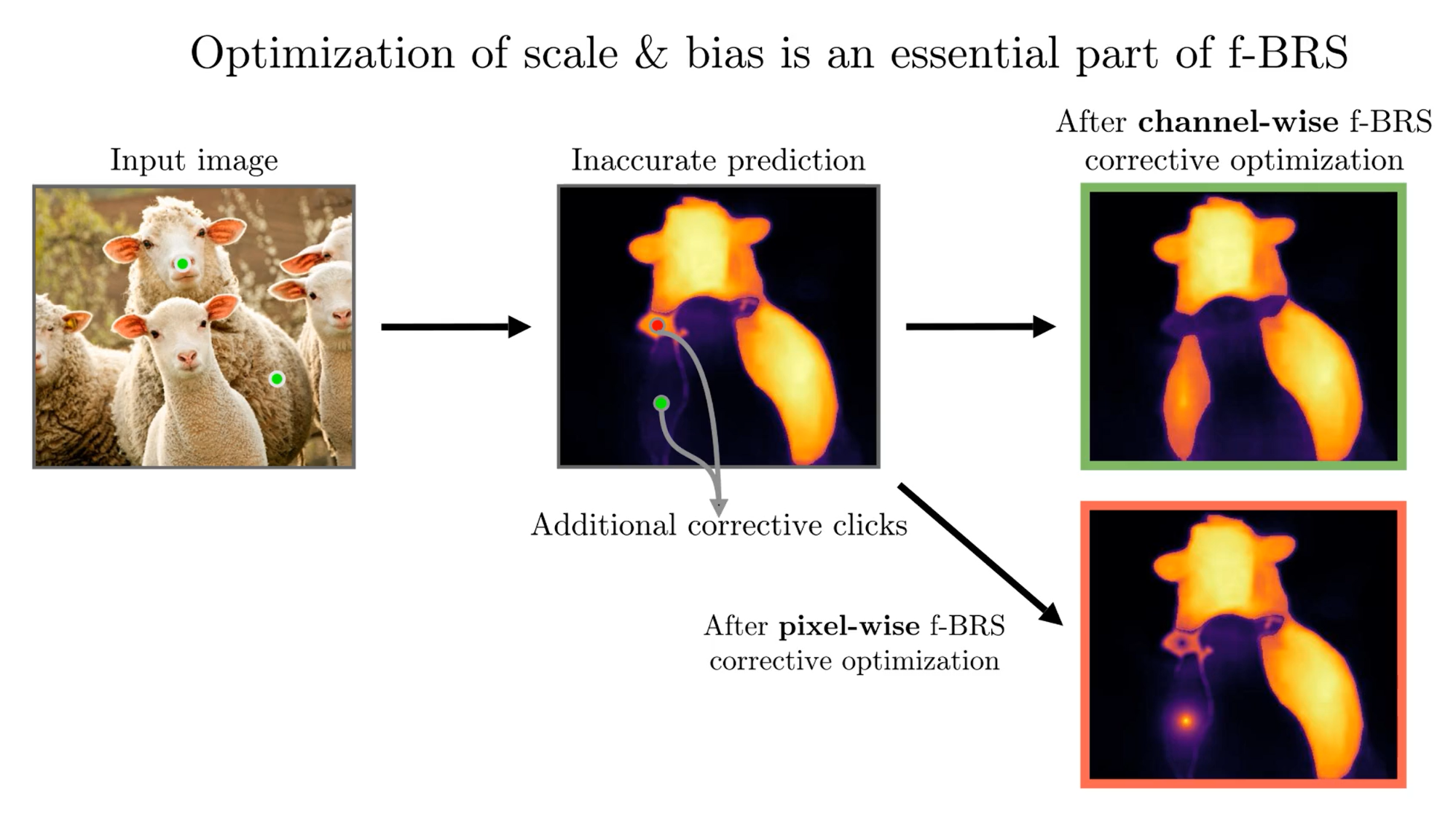
Поканальный (channel-wise) подход решает проблему локального переобучения — сеть понимает, где объект «овца», а где объект «ягненок»
Еще одно нововведение, которое представлено в статье — техника Zoom-In, которая позволяет улучшить качество интерактивной сегментации. В предыдущих работах по интерактивной сегментации использовались кропы изображений, чтобы ускорить модель и сохранить мелкие детали в масках сегментации. Это позволяет получить более точные маски маленьких объектов, но, с другой стороны, результаты могут стать хуже в случае, если исходное разрешение объекта больше разрешения кропа.
Эксперименты показали, что 1-3 кликов достаточно, чтобы нейросеть достигла 80% меры Жаккара (Intersection over Union, IoU) по отношению к ground truth-маске. То есть, начиная с третьего клика, можно получать кропы в соответствии с ограничивающим прямоугольником (bounding box) маски объекта и применять интерактивную сегментацию только к нужному участку изображения.
Пошагово технику Zoom-In можно записать следующим образом:
- Сначала находим ограничивающий прямоугольник для предсказанной маски объекта.
- Расширяем прямоугольник на 40% по каждой из сторон.
- Получаем кроп изображения по границам прямоугольника.
- Увеличиваем разрешение полученного фрагмента изображения (изначально была картинка в низком разрешении).
- Снова делаем предсказание маски объекта.
Ниже показана визуализация применения Zoom-In.
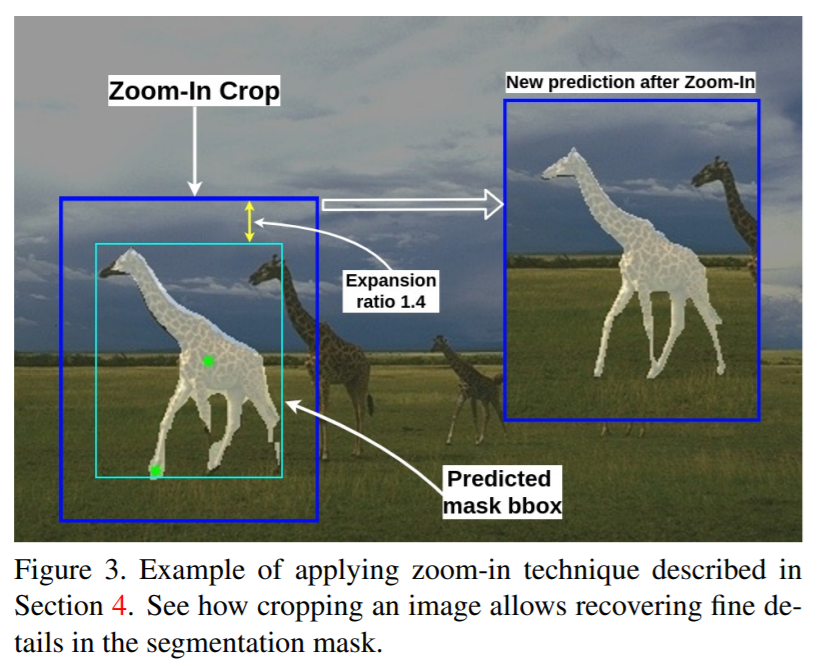
Zoom-In улучшил результаты во всех экспериментах и использовался по умолчанию вместе с f-BRS. При этом Zoom-In можно применять и вместе с другими моделями для интерактивной сегментации.
Датасеты и результаты
Эксперименты проводились на четырех датасетах: GrabCut, Berkeley, DAVIS и SBD.
Во всех случаях f-BRS устанавливает новую планку качества в интерактивной сегментации.
Пример — сравнение результатов, в первом ряду используется предложенная f-BRS, во втором BRS не задействована.
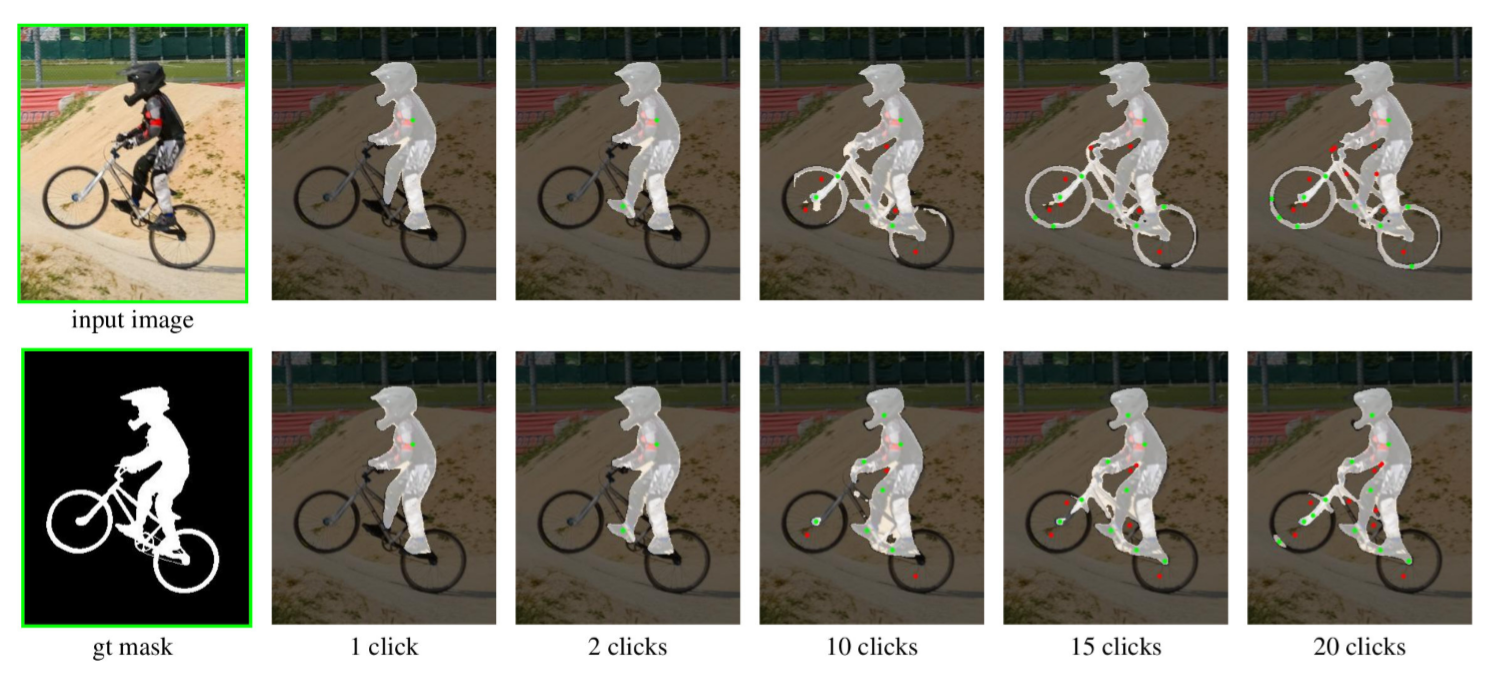
Что здесь бросается в глаза? Без f-BRS, несмотря на настойчивые попытки пользователя включить велосипед в область положительной сегментации, модель продолжает наращивать маску, относящуюся к спортсмену. Получается, что f-BRS требует меньше кликов, то есть гораздо меньше работы по ручной сегментации.
Для тех, кто дочитал наш пост до конца и готов воспроизвести результат, создав собственные иллюстрации, мы предлагаем взять код к статье здесь и посмотреть видеопрезентацию на CVPR 2020 — здесь.
А тех, кто сейчас только поставил перед собой задачу с нуля научиться решать задачи в области машинного зрения при помощи нейросетей, мы приглашаем записаться на наш бесплатный онлайн-курс на Stepik! В финале курса вы уже осознанно решите прикладную задачу компьютерного зрения и можно будет двигаться в более продвинутую область сегментации изображений.
 Автор статьи:
Автор статьи:Юлия Чуркина
Специалист по управлению проектами,
Центр искусственного интеллекта Samsung
