
В современной компьютерной лингвистике понимание смысла написанного или сказанного достигается с помощью моделей естественного языка (NLU). С постепенным ростом аудитории виртуальных ассистентов Салют встает вопрос об оптимизации наших сервисов, работающих с естественным языком. Для этого оказывается целесообразно использовать одну сильную модель NLU для решения сразу нескольких задач обработки текста. В этой статье мы расскажем, как можно использовать многозадачное обучение для улучшения векторных представлений и обучения более универсальной модели NLU на примере SBERT.
В высоконагруженных сервисах обработки текста решается целый ряд различных задач NLP:
- Распознавание намерений.
- Выделение именованных сущностей.
- Сентиментный анализ.
- Анализ токсичности.
- Поиск похожих запросов.
Каждая из этих задач обладает своей спецификой и, вообще говоря, требует построения и обучения отдельной модели. Однако, поддерживать и исполнять для каждой такой задачи отдельную NLU-модель непрактично – сильно возрастает время обработки запроса и потребляемая (видео)память. Вместо этого мы используем одну сильную модель NLU для извлечения универсальных признаков из текста. Поверх этих признаков мы применяем относительно легковесные модели (адаптеры), которые и решают прикладные NLP-задачи. При этом NLU и адаптеры могут исполняться на разных машинах – это позволяет удобнее разворачивать и масштабировать решения.

Но как сделать признаки, выделяемые базовой моделью NLU, достаточно универсальными, чтобы поверх них можно было построить качественную NLP-модель? Давайте разбираться.
По традиции представляем реализацию нашего подхода на Python 3 и TensorFlow 1.15. С полным пошаговым руководством и примерами кода можно ознакомиться тут – Colab.
Также мы выкладываем в публичный доступ обновленную русскую модель SBERT-NLU класса BERT-large [427 млн. параметров] версии Multitask: huggingface [tensorflow, pytorch].
Многозадачное обучение. Зачем это нужно?
В процессе эксплуатации моделей NLU мы обнаружили, что фичи, выделяемые моделями обученными под одну задачу (например NLI), можно вполне успешно переиспользовать для других downstream-задач (например, для классификации или сентиментного анализа). Для этого на векторах, выделенных базовой моделью, обучается легковесная модель (адаптер), заточенная под решение новой задачи. Базовая модель при этом не изменяется.
При этом качество таких моделей-адаптеров обычно получается всё-таки хуже, чем если бы под каждую задачу мы обучили свою NLU-модель. Причина – новые данные используются только для моделей-адаптеров и не улучшают базовую модель. С этим нам помогает справиться multitask learning.
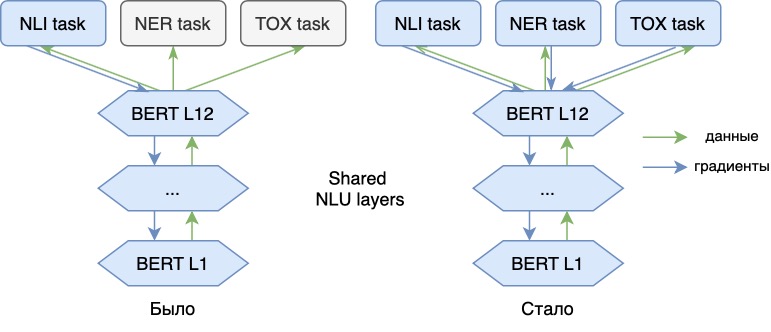
Теперь мы обучаем языковую модель не только на основной NLI-задаче, но и на дополнительных (NER, анализ токсичности). Добавление новых задач позволяет добавить новых «смыслов» векторам нашей модели, делает их более универсальными. Тем самым модель сможет отразить в своих векторах информацию, например, об эмоциональных оттенках речи фразы или о части речи каждого слова в тексте. С векторными представлениями такой модели указанные задачи можно будет решить эффективнее.
0. Эксперимент
В качестве примера рассмотрим обучение NLU на трёх задачах:
- Sentence representation (NLI).
- Named entity recognition (NER).
- Sentiment analysis.
Для обучения основной задачи векторизации предложений мы, как и в прошлый раз, используем набор данных для Natural Language Inference, содержащий пары предложений с метками, которые указывают на следствие («entailment»), противоречие («contradiction») или отсутствие смысловой связи («neutral») между предложениями. Для этих данных на базе модели BERT мы выучим такое векторное представление, что сходство между соответствующими парами предложений будет больше, чем сходство между противоречащими или нейтральными по отношению друг к другу.
NER-голову будем обучать, воспользовавшись датасетом с платформы kaggle. Эта модель будет относить каждый токен обрабатываемого предложения к одному из нескольких типов именованных сущностей в формате IOB. Ее задача – многоклассовая классификация.
Для задачи сентиментного анализа возьмём данные соревнования Tweet Sentiment Extraction. Суть этого контеста состоит в предсказании эмоционального окраса комментариев к постам в twitter. В датасете присутствует три класса – позитивный, нейтральный и негативный окрас реплики. Для этого примера будем выделять только два класса: positive и negative. Задача будет представлять из себя бинарную классификацию.
В качестве базовой модели векторизации используем предобученную английскую BERT-base.
План эксперимента:
- Подготовка наборов данных.
- Реализация генератора батчей.
- Определение функции потерь.
- Построение модели.
- Подготовка процесса валидации.
- Обучение модели.
- Обсуждение результатов и выводы.
1. Подготовка данных
Для начала загрузим датасеты, необходимые для обучения основной модели векторизации предложений – [SNLI, MNLI] и для её валидации – [STS SICK]. Кроме этого нам понадобится предобученная английская модель BERT. К счастью, всё это лежит в открытом доступе:
Далее перейдем на платформу kaggle и скачаем оттуда данные для сентиментного анализа – тут нам нужен именно train.csv. Для этих данных выделим в отдельный класс негативные примеры, остальное объединим в общую группу (positive, neutral):
Осталось забрать данные для NER и подготовить их в формате [text, ner_labels]:
2. Батч-генератор
Теперь напишем процедуру генерации пакета примеров для обучения нейросети. Ввиду того, что на вход мы теперь получаем не один, а уже три датасета, генераторов тоже понадобится больше:
для NLI-задачи при помощи генератора триплетов мы будем порождать тройки
[anchor, positive, negative]:
для задач классификации NER и Toxic используем один и тот же генератор данных, порождающий пары [sample, label]. Тут мы случайным образом выбираем несколько примеров с их метками классов из представленных датасетов и формируем пакет:
Наконец, объединим три генератора в общий комплексный генератор, который будет конкатенировать все три типа пакета данных в один для обучения модели:
3. Функция потерь
Теперь для каждой задачи определим свою функцию ошибки, а затем скомбинируем их для итоговой функции потерь:
- Задачу «сближения» перефразированных предложений всё также сформулируем как задачу ранжирования и в качестве функции ошибки используем уже известный по прошлой работе немного изменённый Softmax Loss:

- Для задачи сентиментного анализа будем использовать классический Binary Cross Entropy Loss:
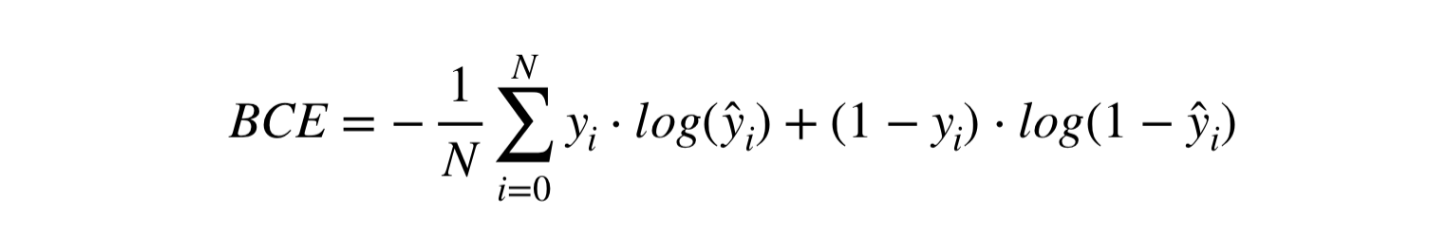
- NER-задачу будем представлять как мультиклассовую классификацию для последовательности токенов-слов, поэтому для каждого токена будем считать CrossEnrtopyLoss:

- Эти функции ошибки мы скомбинируем в общий Joint-loss, при этом задав важность каждой составляющей ошибки для целевой задачи экспертными весами:
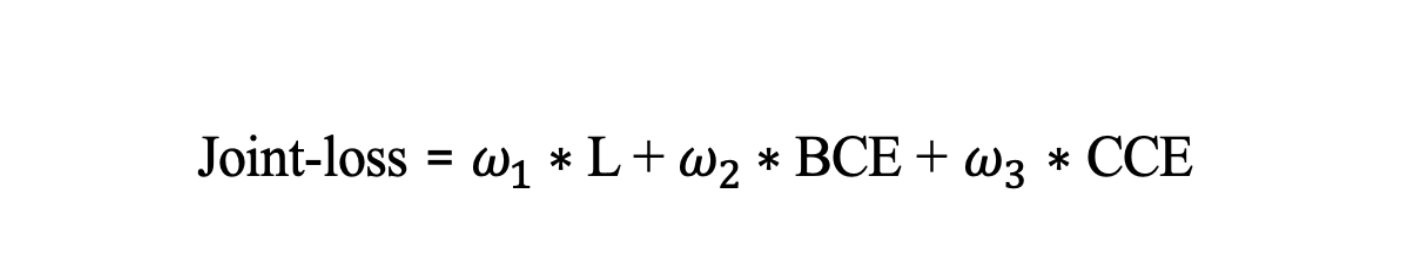
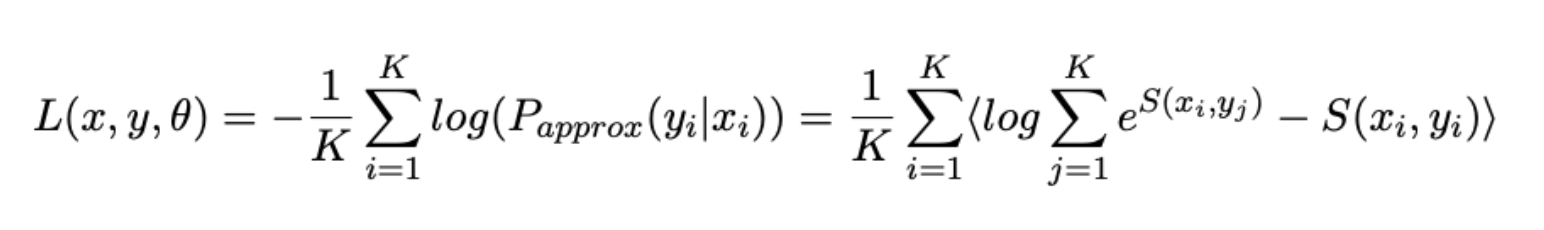


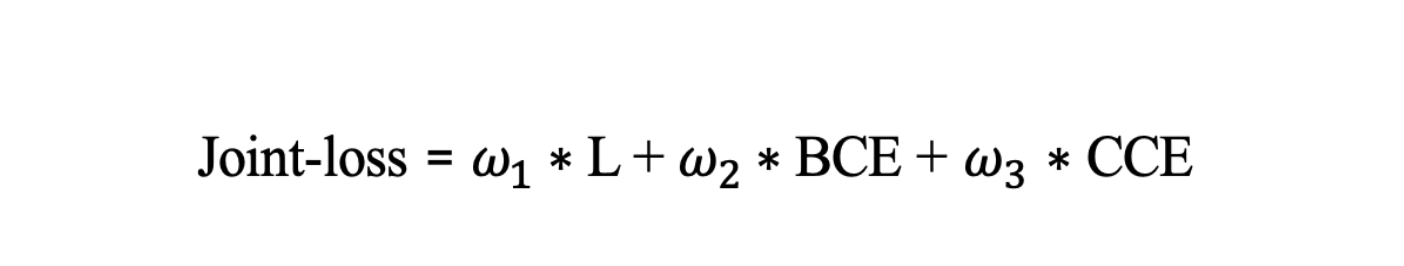
4. Архитектура модели
Наша модель состоит из основной NLU-части (здесь используем BERT-base) и трёх «голов»-адаптеров, специфичных для каждой задачи.
Для задач NLI и Toxic c последнего слоя BERT будем забирать усреднённые эмбеддинги токенов (используем masked mean pooling). Для задачи NER мы применим эмбеддинги токенов c выхода 8-го encoder-слоя. При обучении sentence-level представлений эмбеддинги для token-level задач лучше брать с промежуточных слоев модели.
Примерно выглядит это вот так:

Архитектура multitask-модели
Код для сборки модели:
5. Валидация результатов
Для валидации модели векторизации предложений используем наборы данных STS 2012–2016 и SICK 2014.
Как и SNLI, данный датасет содержит пары предложений. Векторизуем их моделью с помощью модели и оценим сходство между предложениями, вычислив косинусную близость между их векторами. В качестве метрики будем вычислять ранговую корреляцию с метками из датасета.
Код Callback, содержащего эту логику:
https://gist.githubusercontent.com/gaphex/f2d2e1a9c849ba9d69a3014da705968f/raw/8ac26c3b236979625a906591dd594b9fd8640483/pearsonr_callback.py.
Задача определения токсичности комментариев будет проверяться по метрике AUC. Разбиение данных стратифицировано относительно распределения классов.
https://gist.github.com/Ab1992ao/873227b0834ebe43c95b4b5fe029eb95.
Качество разметки NER будем оценивать по двум метрикам – accuracy и F1-мере.
https://gist.github.com/Ab1992ao/e3ea080d36d2bf2d0c1ddc17aa4b9e99.
6. Процесс обучения
Мы на финишной прямой. Теперь у нас есть: данные, модель и пайплайн валидации. Перейдем теперь к гиперпараметрам и ресурсам для обучения.
По классике в нашем распоряжении Colab с видеоускорителем NVIDIA K80 (12Гб)/T80(16Гб) – в зависимости от вашей активности в этой среде. Чтобы всё наше произведение мультитаск-искусства влезло в память, важно правильно выбрать максимальную длину обрабатываемой последовательности (seq_len) и, конечно же, размер батча.
В этом эксперименте мы ограничимся снова 24 токенами для sentence task, что будет достаточно для кодирования большей части данных, используемых при обучении. Для sentiment и ner-task используем такую же длину последовательности.
Увеличение размера батча крайне положительно влияет на сходимость модели – выберем максимальный, который поместится в память нашего GPU.
В качестве оптимизатора будем использовать старый добрый Adam с небольшим learning rate. Обучать модель будем до схождения, 25 эпох должно хватить.
Параметры обучения:
- batch size = 96/72 для BERT-base (16 гб памяти или 12 гб соответственно);
- max_seq_len = 24;
- Optimizer Adam;
- Learning rate ~2e-6;
- Метрики — [SpearmanR, F1, AUC];
- Кол-во эпох ~25.
Сравним метрики адаптеров обученных поверх старой и новой версии модели SBERT.

Как видно, за счет многозадачного дообучения удалось довольно существенно поднять качество по дополнительным задачам NER и TOX. Важно, что это не повредило основной функциональности модели — метрики на датасетах STS и SICK остались на прежнем уровне.
7. Возможности для дальнейшего улучшения
Аугментация
В рамках своей работы мы используем дополнительные манипуляции, которые помогают получать более точные и устойчивые модели.
Во время генерации батча мы применяем ряд аугментаций, среди которых можно выделить следующие: на уровне букв, на уровне слов, изменение регистра и удаление пунктуации.
На уровне букв это:
1) удаление «првет»;
2) повтор «приввет»;
3) перемена местами двух рядом стоящих символов «приевт»;
4) замена на близкую на клавиатуре клавишу «приает»;
5) замена на фонетически близкую букву «превет».
На уровне слов это:
1) перемена местами двух или более слов;
2) вставка слов паразитов – «ну, это самое, как бы».
Для того, чтобы модель была более устойчивой к изменениям регистра и пунктуации, в некоторых примерах пунктуация может быть удалена. Для случайного токена может быть изменён регистр.
Аугментации, связанные с изменением слов и символов, применяются для 3% батча, а с пунктуацией и капитализацией – для 30%.
8. Результаты и выводы
В данной статье мы познакомились с понятием Multitask Leaning и применили эти знания для улучшения векторных представлений языковой модели.
Используя эти методы, мы улучшили модель NLU для русского языка SBERT-multitask и опубликовали её. Эту версию модели мы дообучили для решения задач NER, сентиментного анализа и анализа токсичности.
Мы замерили метрики для обоих версий модели SBERT на бенчмарке русских языковых моделей RussianGLUE. Хотя задачи RuGLUE и не участвовали в процессе многозадачного дообучения, метрики у второй версии модели слегка поднялись. Обучение модели одним задачам расширило её кругозор и улучшило качество и на других.

У нас в планах дальнейшее развитие моделей естественного языка SBERT. Из направлений можно выделить: ускорение и дистилляцию, улучшение базовой архитектуры и добавление новых задач. О них мы расскажем в следующих статьях. Если вы интересуетесь технологиями NLP и хотите внедрять их в новые продукты для широкой аудитории – приходите к нам на собеседование.
Мы желаем вам удачи в исследованиях!
За помощь в подготовке материалов статьи благодарю Andriljo и Ibragim_bad.
