Специально к старту курса «Машинное обучение» в этом материале представляем сравнение BOHB и HyperBand — двух передовых алгоритмов оптимизации гиперпараметров нейронной сети и простого случайного поиска оптимальных гиперпараметров. Сравнение выполняется с помощью платформы neptune.ai — инструмента для управления экспериментами в области ИИ. Рисунки, графики, таблицы результатов сравнения — всё это вы найдете под катом.
Если вы хотите больше узнать о современных алгоритмах оптимизации гиперпараметров (HPO), в этой статье я расскажу вам, что это такое и как они работают. Как исследователь ML я довольно много читал о них, а также использовал современные алгоритмы HPO, и я поделюсь с вами тем, что обнаружил.
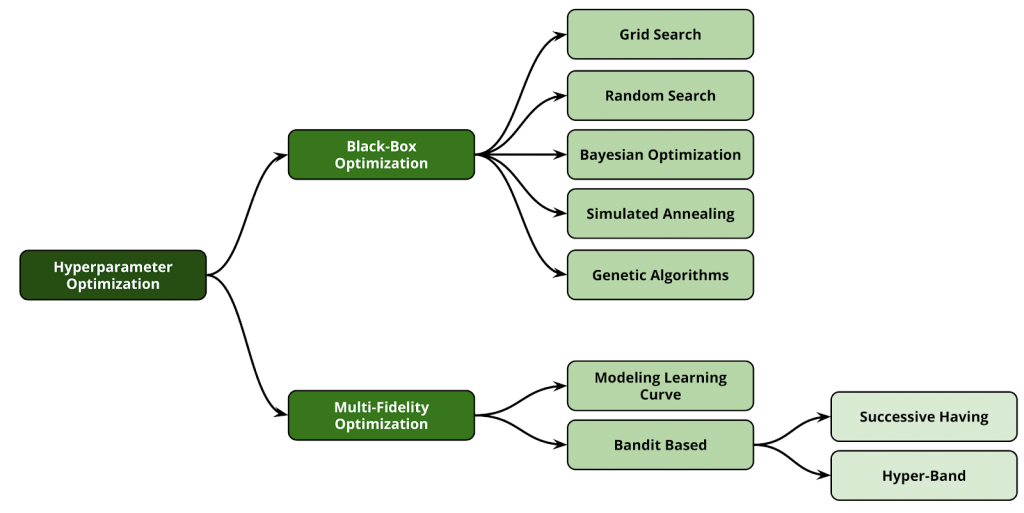
HPO — это метод, помогающий решить задачу настройки гиперпараметров алгоритмов машинного обучения. Выдающиеся алгоритмы ML имеют множество разных и сложных гиперпараметров, порождающих огромное пространство поиска. Многие стартапы предпочитают применять глубокое обучение в ядре своих конвейеров, а пространство поиска в методах глубокого обучения даже больше, чем у традиционных алгоритмов ML. Тонкая настройка в огромном пространстве поиска — сложная задача. Чтобы решить задачи HPO, мы должны применять основанные на данных методы. Ручные методы неэффективны. В этом смысле предлагалось множество подходов:

Изображение из статьи Automated Machine Learning: State-of-The-Art and Open Challenges
Мы обсудим четыре основных наиболее эффективных метода.
Чтобы понимать байесовскую оптимизацию, мы должны немного знать о сеточном поиске и методах случайного поиска, хорошо объяснённых в этой статье. Я просто напишу резюме этих методов.
Предположим, что пространство поиска состоит только из двух гиперпараметров, один из которых значим, а другой — нет. Мы хотим настроить их так, чтобы повысить точность модели. Если каждый из них имеет 3 разных значения, то всё пространство поиска имеет 9 возможных вариантов. Можно попробовать каждый из них, чтобы найти оптимальное значение для обоих гиперпараметров.

Изображение из статьи Random Search for Hyper-Parameter Optimization
Но, как видно на рисунке выше, методом сеточного поиска лучшее значение для важного гиперпараметра не найдено. Одним из решений этой проблемы может быть случайное прохождение по пространству поиска, как показано на рисунке ниже.
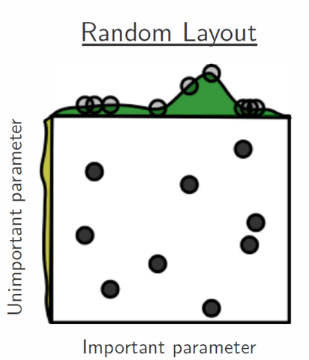
Изображение из статьи Random Search for Hyper-Parameter Optimization
Случайный поиск в конечном счёте приводит к оптимальному ответу, но это просто случайный поиск. Есть ли способ поиска разумнее? Да, есть, это байесовская оптимизация, предложенная J. Mockus. Вы найдёте более подробную информацию о байесовской оптимизации в Bayesian Optimization Primer и в Practical Bayesian Optimization of Machine Learning Algorithms.
В сущности байесовская оптимизация — это вероятностная модель, которая изучает дорогостоящую целевую функцию путём обучения на основе предыдущих наблюдений. Она имеет две мощные особенности: суррогатную модель и функцию сбора данных.

Изображение из главы Hyperparameter Optimization книги об AutoML, авторы Матиас Фойер, Фрэнк Хаттер
На рисунке выше видно хорошее объяснение байесовской оптимизации, основанное на главе об оптимизации гиперпараметров из книги Automated Machine Learning. На этом рисунке мы хотим найти истинную целевую функцию, показанную в виде пунктирной линии. Представьте себе, что у нас есть один непрерывный гиперпараметр, и на второй итерации мы наблюдали две чёрные точки, а затем установили суррогатную (регрессионную) модель, которая показана чёрной линией. Синяя область вокруг чёрной линии — это неопределённость.
Кроме того, у нас есть функция сбора. Эта функция — способ, которым мы исследуем пространство поиска для нахождения нового оптимального значения наблюдения. Другими словами, функция сбора помогает улучшить суррогатную модель и выбрать следующее значение. На изображении выше функция сбора данных показана в виде оранжевой кривой. Максимальное значение функции сбора означает, что неопределённость максимальна, а прогнозируемое значение невелико.
Ключевое преимущество байесовской оптимизации — это то, что она может очень хорошо работать с функцией чёрного ящика. Кроме того, БО эффективна в отношении данных и устойчива к шуму. Но она не может хорошо работать с параллельными ресурсами в дуэте, поскольку процесс оптимизации последователен.
Кадр из лекции Мариуса Линдауэра на открытой конференции по Data Science
Пришло время посмотреть некоторые реализации Байесовской оптимизации. Я перечислил самые популярные из них:
В байесовском методе оценка целевой функции стоит очень дорого. Есть ли более дешёвый способ оценить целевую функцию? Ответ на этот вопрос — методы оптимизации Multi Fidelity. Я расскажу вам о:
В качестве дополнительного ресурса: в следующем видео Андреас Мюллер прекрасно объяснил методы оптимизации Multi Fidelity.
Андреас Мюллер: Applied Machine Learning 2019
Последовательное деление пополам пытается дать наибольший бюджет наиболее перспективным методам. Метод предполагает, что всё конфигурирование можно остановить на ранней стадии и получить оценку валидации.
Представьте, что у вас есть N различных конфигураций и бюджет ß (например время). Как видно на рисунке ниже, в каждой итерации последовательное деление пополам сохраняет лучшую половину конфигураций и отбрасывает половину не самых удачных алгоритмов. Это продолжается до тех пор, пока мы не получим одну-единственную конфигурацию. Метод завершает работу, когда достигает максимума своего бюджета.

Рисунок из поста в блоге automl.org
Последовательное деление пополам впервые предложено в статье Кевина Джеймисона и Амита Талвалкара Non-stochastic Best Arm Identification and Hyperparameter Optimization.
В последовательном делении пополам существует компромисс между тем, сколько конфигураций нужно выбрать в начале, и тем, сколько разрезов нужно. В следующем разделе вы увидите, как эту проблему решает Hyperband.
Этот метод — расширение последовательных алгоритмов деления пополам, предложенное в статье Novel Bandit-Based Approach to Hyperparameter Optimization от Лиши Ли и других авторов.
Я уже упоминал, что метод последовательного деления пополам страдает из-за компромисса между выбором числа конфигураций и распределением бюджета. Чтобы решить эту проблему, HyperBand для поиска наилучших конфигураций предлагает часто выполнять последовательное деление пополам с различными бюджетами. На рисунке ниже видно, что HyperBand производительнее по сравнению со случайным поиском.
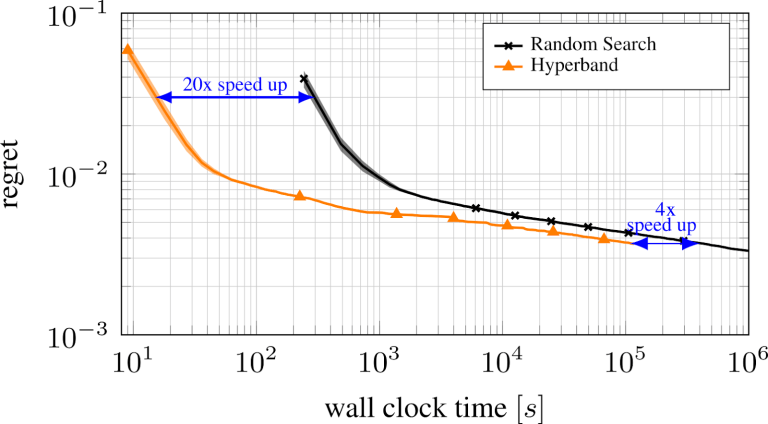
Рисунок из блога automl.org
Простую реализацию HyperBand можно найти в репозитории HpBandSter от automl.org. Если вам интересно, как применять этот инструмент на Python, ознакомьтесь с документацией.
BOHB — передовой алгоритм оптимизации гиперпараметров, предложенный в работе BOHB: Robust and Efficient Hyperparameter Optimization at Scale, написанной Стефаном Фолкнером, Аароном Кляйном и Фрэнком Хаттером. Идея BOHB основана на одном простом вопросе: почему мы постоянно выполняем последовательное деление пополам?
Вместо слепого повторения последовательного деления пополам BOHB использует алгоритм байесовской оптимизации. На самом деле BOHB сочетает в себе HyperBand и байесовскую оптимизацию, чтобы эффективно использовать оба этих алгоритма. Дэн Райан прекрасно объясняет метод BOHB в своей презентации.
Отличная презентация Дэна Райана об эффективной и гибкой оптимизации гиперпараметров на PyData Miami 2019
BOHB — это метод оптимизации Multi Fidelity, такие методы зависят от бюджета, поэтому важно найти его косвенные издержки. С другой стороны, BOHB надёжен, гибок и масштабируем. Если вам нужна более подробная информация, взгляните на официальный пост в блоге о BOHB от Андре Биденкаппа и Фрэнка Хаттера.
Кроме того, HpBandSter — это хорошая реализация BOHB и HyperBand. Документация по BOHB находится здесь.
Теперь, когда мы знакомы со всеми этими методами, воспользуемся Neptune и проведём некоторые эксперименты и сравнения. Если вы хотите провести эксперименты вместе со мной, то:
Поскольку я решил провести эксперименты в равных условиях, я использовал HpBandSter, который имеет реализацию BOHB, с Hyperband и RandomSearch в качестве оптимизатора. Официальный пример можно найти здесь. Основываясь на этом примере, мы имеем небольшую свёрточную нейронную сеть на Pytorch, которая настроена для набора данных MNIST. Я запустил этот пример с тремя оптимизаторами:
Для каждого оптимизатора я использовал следующие бюджеты:
Это означает, что для изучения возможностей оптимизаторов мы запустили различные комбинации по крайней мере 26 экспериментов. Кроме того, в этом примере мы хотим найти наилучшую конфигурацию для CNN на основе следующих гиперпараметров.
Конфигурация взята из документации hpbandster
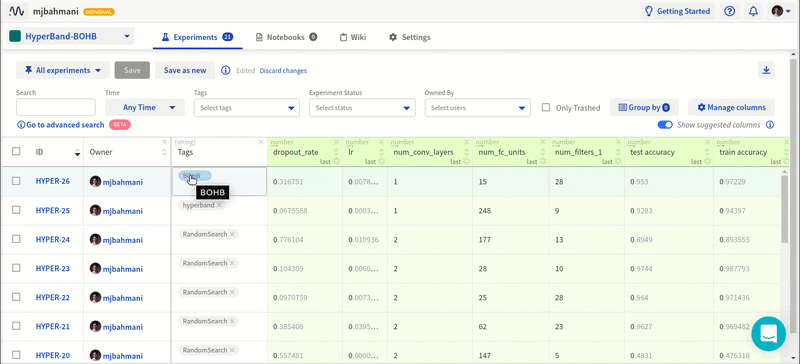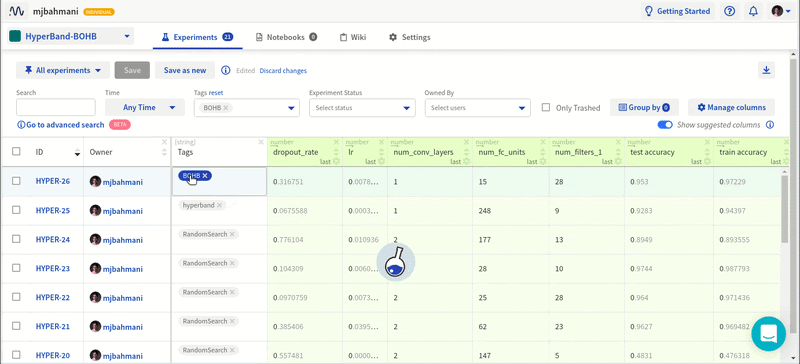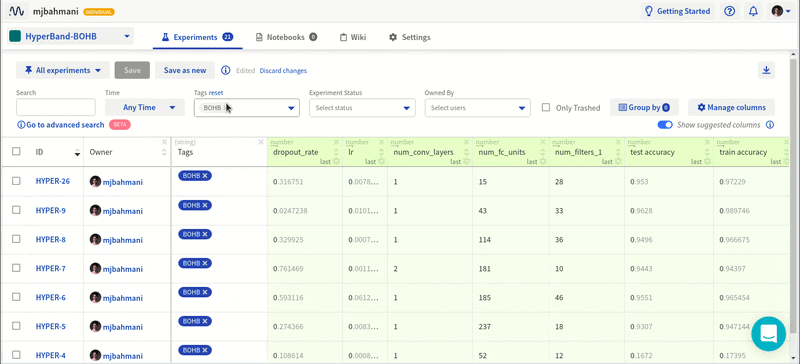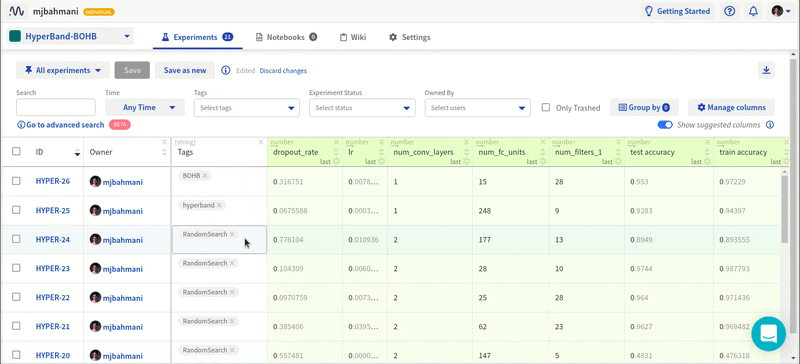
Проведя эти эксперименты с различными конфигурациями в Neptune, я получил содержательные результаты.
Все эксперименты в Neptune
Здесь мы видим неплохой контраст между оптимизаторами при
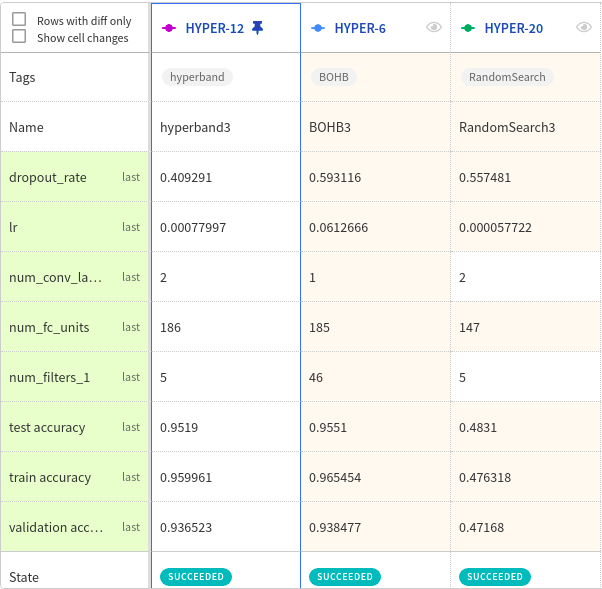
Сравнение BOHB, HyperBand и случайного поиска для
В конечном счете при

Если вы хотите больше узнать о современных алгоритмах оптимизации гиперпараметров (HPO), в этой статье я расскажу вам, что это такое и как они работают. Как исследователь ML я довольно много читал о них, а также использовал современные алгоритмы HPO, и я поделюсь с вами тем, что обнаружил.
Оглавление
- Немного о подходах HPO
- Что такое байесовская оптимизация и почему этот метод эффективен?
- Как работают современные алгоритмы оптимизации гиперпараметров?
- HyperBand против BOHB
Немного о подходах HPO
HPO — это метод, помогающий решить задачу настройки гиперпараметров алгоритмов машинного обучения. Выдающиеся алгоритмы ML имеют множество разных и сложных гиперпараметров, порождающих огромное пространство поиска. Многие стартапы предпочитают применять глубокое обучение в ядре своих конвейеров, а пространство поиска в методах глубокого обучения даже больше, чем у традиционных алгоритмов ML. Тонкая настройка в огромном пространстве поиска — сложная задача. Чтобы решить задачи HPO, мы должны применять основанные на данных методы. Ручные методы неэффективны. В этом смысле предлагалось множество подходов:
Изображение из статьи Automated Machine Learning: State-of-The-Art and Open Challenges
Мы обсудим четыре основных наиболее эффективных метода.
Байесовская оптимизация
Чтобы понимать байесовскую оптимизацию, мы должны немного знать о сеточном поиске и методах случайного поиска, хорошо объяснённых в этой статье. Я просто напишу резюме этих методов.
Предположим, что пространство поиска состоит только из двух гиперпараметров, один из которых значим, а другой — нет. Мы хотим настроить их так, чтобы повысить точность модели. Если каждый из них имеет 3 разных значения, то всё пространство поиска имеет 9 возможных вариантов. Можно попробовать каждый из них, чтобы найти оптимальное значение для обоих гиперпараметров.
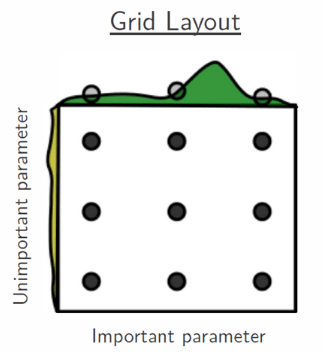
Изображение из статьи Random Search for Hyper-Parameter Optimization
Но, как видно на рисунке выше, методом сеточного поиска лучшее значение для важного гиперпараметра не найдено. Одним из решений этой проблемы может быть случайное прохождение по пространству поиска, как показано на рисунке ниже.
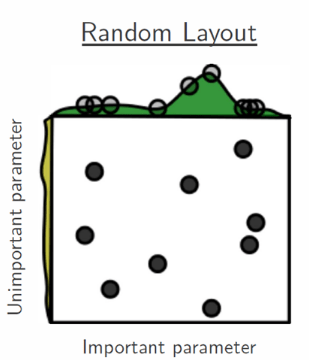
Изображение из статьи Random Search for Hyper-Parameter Optimization
Почему байесовская оптимизация эффективна?
Случайный поиск в конечном счёте приводит к оптимальному ответу, но это просто случайный поиск. Есть ли способ поиска разумнее? Да, есть, это байесовская оптимизация, предложенная J. Mockus. Вы найдёте более подробную информацию о байесовской оптимизации в Bayesian Optimization Primer и в Practical Bayesian Optimization of Machine Learning Algorithms.
В сущности байесовская оптимизация — это вероятностная модель, которая изучает дорогостоящую целевую функцию путём обучения на основе предыдущих наблюдений. Она имеет две мощные особенности: суррогатную модель и функцию сбора данных.
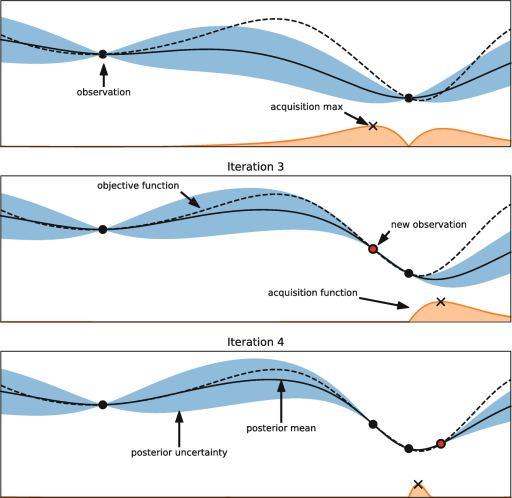
Изображение из главы Hyperparameter Optimization книги об AutoML, авторы Матиас Фойер, Фрэнк Хаттер
На рисунке выше видно хорошее объяснение байесовской оптимизации, основанное на главе об оптимизации гиперпараметров из книги Automated Machine Learning. На этом рисунке мы хотим найти истинную целевую функцию, показанную в виде пунктирной линии. Представьте себе, что у нас есть один непрерывный гиперпараметр, и на второй итерации мы наблюдали две чёрные точки, а затем установили суррогатную (регрессионную) модель, которая показана чёрной линией. Синяя область вокруг чёрной линии — это неопределённость.
Кроме того, у нас есть функция сбора. Эта функция — способ, которым мы исследуем пространство поиска для нахождения нового оптимального значения наблюдения. Другими словами, функция сбора помогает улучшить суррогатную модель и выбрать следующее значение. На изображении выше функция сбора данных показана в виде оранжевой кривой. Максимальное значение функции сбора означает, что неопределённость максимальна, а прогнозируемое значение невелико.
Байесовская оптимизация: за и против
Ключевое преимущество байесовской оптимизации — это то, что она может очень хорошо работать с функцией чёрного ящика. Кроме того, БО эффективна в отношении данных и устойчива к шуму. Но она не может хорошо работать с параллельными ресурсами в дуэте, поскольку процесс оптимизации последователен.
Кадр из лекции Мариуса Линдауэра на открытой конференции по Data Science
Реализации байесовской оптимизации
Пришло время посмотреть некоторые реализации Байесовской оптимизации. Я перечислил самые популярные из них:
| Название реализации | Суррогатная модель | Ссылки |
|---|---|---|
| SMAC | Случайный лес | Статья, GitHub |
| HYPEROPT | Tree Parzen estimator | Статья, GitHub |
| MOE | Гауссовский процесс | Статья, GitHub |
| scikit-optimize | Гауссовский процесс, случайный лес и т.д. | GitHub |
Оптимизация Multi Fidelity
В байесовском методе оценка целевой функции стоит очень дорого. Есть ли более дешёвый способ оценить целевую функцию? Ответ на этот вопрос — методы оптимизации Multi Fidelity. Я расскажу вам о:
- Последовательное деление пополам
- HyperBand
- BOHB
В качестве дополнительного ресурса: в следующем видео Андреас Мюллер прекрасно объяснил методы оптимизации Multi Fidelity.
Андреас Мюллер: Applied Machine Learning 2019
Последовательное деление на два
Последовательное деление пополам пытается дать наибольший бюджет наиболее перспективным методам. Метод предполагает, что всё конфигурирование можно остановить на ранней стадии и получить оценку валидации.
Представьте, что у вас есть N различных конфигураций и бюджет ß (например время). Как видно на рисунке ниже, в каждой итерации последовательное деление пополам сохраняет лучшую половину конфигураций и отбрасывает половину не самых удачных алгоритмов. Это продолжается до тех пор, пока мы не получим одну-единственную конфигурацию. Метод завершает работу, когда достигает максимума своего бюджета.
Рисунок из поста в блоге automl.org
Последовательное деление пополам впервые предложено в статье Кевина Джеймисона и Амита Талвалкара Non-stochastic Best Arm Identification and Hyperparameter Optimization.
В чем проблема последовательного деления пополам?
В последовательном делении пополам существует компромисс между тем, сколько конфигураций нужно выбрать в начале, и тем, сколько разрезов нужно. В следующем разделе вы увидите, как эту проблему решает Hyperband.
HyperBand
Этот метод — расширение последовательных алгоритмов деления пополам, предложенное в статье Novel Bandit-Based Approach to Hyperparameter Optimization от Лиши Ли и других авторов.
Я уже упоминал, что метод последовательного деления пополам страдает из-за компромисса между выбором числа конфигураций и распределением бюджета. Чтобы решить эту проблему, HyperBand для поиска наилучших конфигураций предлагает часто выполнять последовательное деление пополам с различными бюджетами. На рисунке ниже видно, что HyperBand производительнее по сравнению со случайным поиском.
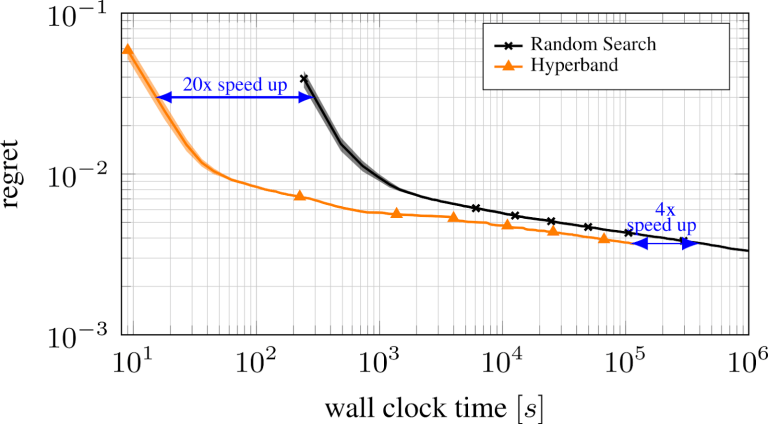
Рисунок из блога automl.org
Простую реализацию HyperBand можно найти в репозитории HpBandSter от automl.org. Если вам интересно, как применять этот инструмент на Python, ознакомьтесь с документацией.
BOHB
BOHB — передовой алгоритм оптимизации гиперпараметров, предложенный в работе BOHB: Robust and Efficient Hyperparameter Optimization at Scale, написанной Стефаном Фолкнером, Аароном Кляйном и Фрэнком Хаттером. Идея BOHB основана на одном простом вопросе: почему мы постоянно выполняем последовательное деление пополам?
Вместо слепого повторения последовательного деления пополам BOHB использует алгоритм байесовской оптимизации. На самом деле BOHB сочетает в себе HyperBand и байесовскую оптимизацию, чтобы эффективно использовать оба этих алгоритма. Дэн Райан прекрасно объясняет метод BOHB в своей презентации.
Отличная презентация Дэна Райана об эффективной и гибкой оптимизации гиперпараметров на PyData Miami 2019
BOHB — это метод оптимизации Multi Fidelity, такие методы зависят от бюджета, поэтому важно найти его косвенные издержки. С другой стороны, BOHB надёжен, гибок и масштабируем. Если вам нужна более подробная информация, взгляните на официальный пост в блоге о BOHB от Андре Биденкаппа и Фрэнка Хаттера.
Кроме того, HpBandSter — это хорошая реализация BOHB и HyperBand. Документация по BOHB находится здесь.
Случайный поиск, HyperBand и BOHB результаты сравнения в Neptune
Теперь, когда мы знакомы со всеми этими методами, воспользуемся Neptune и проведём некоторые эксперименты и сравнения. Если вы хотите провести эксперименты вместе со мной, то:
- Установите HpBandSter на локальную машину.
- Воспользуйтесь примером по этой ссылке.
- Установите бюджет конфигурации.
- Выполните один и тот же эксперимент с каждым оптимизатором.
- Следите за экспериментами с помощью Neptune.
Поскольку я решил провести эксперименты в равных условиях, я использовал HpBandSter, который имеет реализацию BOHB, с Hyperband и RandomSearch в качестве оптимизатора. Официальный пример можно найти здесь. Основываясь на этом примере, мы имеем небольшую свёрточную нейронную сеть на Pytorch, которая настроена для набора данных MNIST. Я запустил этот пример с тремя оптимизаторами:
- BOHB.
- HyperBand.
- RandomSearch.
Для каждого оптимизатора я использовал следующие бюджеты:
| Конфигурации | Значение диапазона |
|---|---|
| Минимальный бюджет | [1] |
| Максимальный бюджет | [1,2,3,4,5] |
| Число итераций | [1,2,3,4,8,10] |
Это означает, что для изучения возможностей оптимизаторов мы запустили различные комбинации по крайней мере 26 экспериментов. Кроме того, в этом примере мы хотим найти наилучшую конфигурацию для CNN на основе следующих гиперпараметров.
| Название параметра | Диапазон |
|---|---|
| Скорость обучения | [1e-6, 1e-2] |
| Количество слоев свертки | [1,3] |
| Количество фильтров в первом слое конфигурации | [4, 64] |
| Процент отсева | [0, 0.9] |
| Количество скрытых нейронов в полносвязном слое | [8,256] |
Конфигурация взята из документации hpbandster
Проведя эти эксперименты с различными конфигурациями в Neptune, я получил содержательные результаты.
Все эксперименты в Neptune
Здесь мы видим неплохой контраст между оптимизаторами при
n_iteration=3 и max_budget=3. Я считаю, что, если увеличу количество итераций, все оптимизаторы в конечном счёте станут производительнее, но при значительном бюджете лучше работает BOHB.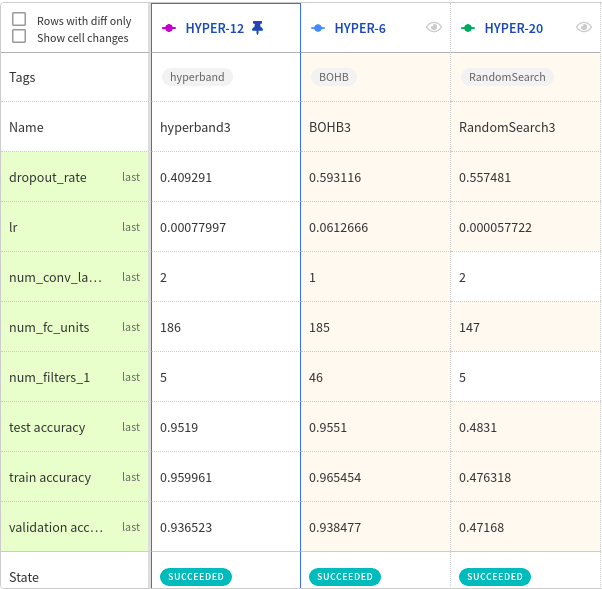
Сравнение BOHB, HyperBand и случайного поиска для
n_iteration=3 и max_budget=3В конечном счете при
max_budget=5 и n_iteration=4 каждый оптимизатор находит одну лучшую конфигурацию, которую вы можете проверить в следующей таблице.| Гиперпараметр | Диапазон перед настройкой | После настройки – случайный поиск | После настройки – HyperBand | После настройки – BOHB |
|---|---|---|---|---|
| Скорость обучения | [1e-6, 1e-2] | 0.010 | 0.00031 | 0.0078 |
| Количество слоев свертки | [1,3] | 2 | 1 | 1 |
| Количество фильтров в первом слое конфигурации | [4, 64] | 13 | 9 | 28 |
| Процент отсева | [0, 0.9] | 0.77 | 0.06 | 0.31 |
| Количество скрытых нейронов в полносвязном слое | [8,256] | 177 | 248 | 15 |

- Обучение профессии Data Science
- Обучение профессии Data Analyst
- Онлайн-буткемп по Data Analytics
- Курс «Python для веб-разработки»
Eще курсы
- Обучение профессии C#-разработчик
- Продвинутый курс «Machine Learning Pro + Deep Learning»
- Курс «Математика и Machine Learning для Data Science»
- Курс по Machine Learning
- Разработчик игр на Unity
- Профессия Веб-разработчик
- Профессия Java-разработчик
- Курс по JavaScript
- C++ разработчик
- Курс по аналитике данных
- Курс по DevOps
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
Рекомендуемые статьи
- Сколько зарабатывает дата-сайентист: обзор зарплат и вакансий в 2020
- Сколько зарабатывает аналитик данных: обзор зарплат и вакансий в 2020
- Как стать Data Scientist без онлайн-курсов
- 450 бесплатных курсов от Лиги Плюща
- Как изучать Machine Learning 5 дней в неделю 9 месяцев подряд
- Machine Learning и Computer Vision в добывающей промышленности
