Больше никогда не тратьте время на настройку гиперпараметров

Я стал дата-сайентистом, потому что мне нравится находить решения для сложных задач. Творческая часть работы и информация, которую я получаю из данных, – это то, что мне нравится больше всего. Такие скучные вещи, как очистка данных, предварительная обработка и настройка гиперпараметров, приносят мне мало удовольствия, и поэтому я стараюсь максимально автоматизировать эти задачи.
Если вам также нравится автоматизировать скучные вещи, вам понравится библиотека, которую я собираюсь рассмотреть в этой статье.
В настоящее время в области машинного обучения преобладают глубокое обучение в случае перцептивных проблем и методы повышения эффективности для регрессионных проблем.
В наши дни никто не использует линейную регрессию из Scikit-Learn для прогнозирования цен на жильё в соревнованиях Kaggle, потому что метод XGboost более точен.
Однако гиперпараметры XGboost сложно настроить. Их много, и инженеры по машинному обучению тратят много времени на их настройку.
Представляем Xgboost-AutoTune
Я рад поделиться с вами библиотекой Xgboost AutoTune, разработанной Сильвией Оливией из MIT. Эта библиотека стала предпочтительным для меня вариантом для автоматической настройки XGboost.
Давайте рассмотрим её на примере набора климатических данных. Мы будем предсказывать повышение температуры в зависимости от концентрации парниковых газов и оценивать влияние каждого газа.
Прежде всего мы импортируем набор данных и построим графики концентраций газов для CO2, CH4, N20 и синтетических газов:
После выполнения этого кода мы увидим, как увеличилось количество парниковых газов за последние 140 лет:

Круто, теперь мы можем импортировать нашу библиотеку, о которой я упоминал ранее, но на всякий случай, если вы не скачали репозиторий, я покажу код и здесь:
По сути, всё, что вам нужно знать, – это то, что основным методом этой библиотеки является параметр «fit_parameters», вам просто нужно вызвать его, и он выполнит всю тяжёлую работу по поиску лучших значений для ваших гиперпараметров. Вот так:
Обратите внимание, что мы указали метрику оценки для моделей (в данном случае среднеквадратичная логарифмическая ошибка RMSLE) и исходную модель – XGBRegressor, потому что это регрессионная задача (другой вариант – это задача классификации).
Круто, мы только что построили наилучшую возможную модель XGboost с помощью двух строк кода, теперь давайте рассчитаем прогнозы:
Код выведет график с прогнозируемой температурой на основе реальных значений из тестового датасета:
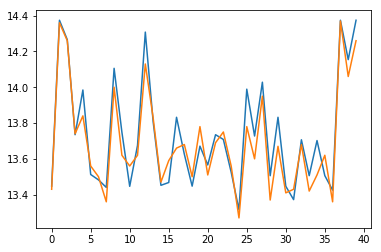
Теперь, если мы хотим узнать, какие газы являются наиболее влиятельными в эффекте потепления, мы можем выполнить следующий код:
Мы получим график:
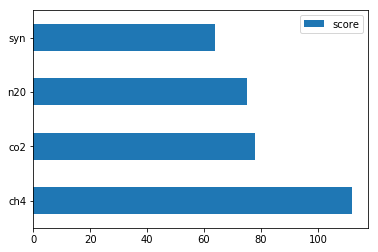
Как и ожидалось, CO2 – это газ с самым сильным эффектом, это неудивительно, но мы также видим, что CH4 также имеет довольно сильный эффект, а самое главное – эта модель была очень быстрой в обучении.
Заключение
Градиентный бустинг является наиболее часто используемым алгоритмом для задач регрессии и классификации, не требующим глубокого обучения, из-за его высокой точности, интерпретируемости и скорости.
К сожалению, хотя экосистема Python предоставляет библиотеку XGboost, она не так обширна, как другие библиотеки, такие как Scikit-Learn, и настройка параметров должна выполняться специалистами по данным вручную, что доставляет много боли.
Вот почему я считаю эту библиотеку жемчужиной, которой нужно поделиться.
Моё последнее размышление: Нанимать специалистов по данным стоит дорого, и их время лучше всего тратить на нетривиальную работу. Вы можете представить себе директора по продажам, делающего холодные звонки? Конечно, нет, это не его работа.
Что ж, к сожалению, многие дата-сайенс специалисты являются мастерами на все руки, их работа очень часто включает в себя поиск данных, их очистку, приём данных, выбор модели для использования, кодирование модели, написание скрипта для настройки модели, развёртывание модели, представление модели бизнесу и бог знает что ещё.
Итак, чем больше инструментов для автоматизации есть у специалиста по данным, тем больше он может сосредоточиться на своей самой важной работе: осмыслении данных и извлечении из них ценности. Надеюсь, вам понравилась эта статья и она поможет вам быстрее обучать ваши модели. Удачного кодинга и не забывайте про промокод HABR — он дает дополнительные 10% к скидке на баннере.

Другие профессии и курсы
ПРОФЕССИИ
КУРСЫ
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия Frontend-разработчик
- Профессия Этичный хакер
- Профессия C++ разработчик
- Профессия Разработчик игр на Unity
- Профессия Веб-разработчик
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
КУРСЫ
- Курс по Data Engineering
- Курс по Machine Learning
- Курс «Математика и Machine Learning для Data Science»
- Курс «Python для веб-разработки»
- Курс «Алгоритмы и структуры данных»
- Курс по аналитике данных
- Курс по DevOps
