Ни для кого не секрет, что основной опыт и экспертиза в тематике SOC в России (да в принципе и в мире) сосредоточена преимущественно на вопросах контроля и обеспечения безопасности корпоративных сетей. Это видно из релизов, докладов на конференциях, круглых столов и так далее. Но по мере развития угроз (не будем вспоминать набивший оскомину Stuxnet, но, тем не менее, не пройдем мимо Black/Gray Energy, Industroyer и Triton) и нормативных требований закона «О безопасности критической информационной инфраструктуры РФ) все чаще поднимается вопрос о необходимости охватить вниманием SOC и святая святых всех индустриальных компаний – сегменты АСУ ТП. Мы делали первый аккуратный подход к этому снаряду примерно полтора года назад (1, 2). С тех пор опыта и исследований стало чуть больше, и мы почувствовали в себе силы запустить полноценный цикл материалов, посвященных вопросам SOC OT. Начнем с того, чем отличаются технологии и процессы давно привычного нам корпоративного SOC от SOC индустриального (до кадровых вопросов дело дойдет своим чередом). Если тематика вам небезразлична — прошу под кат.

Чтобы разбор был предметным, сначала зафиксируем, что мы сравниваем SOC OT с той структурой центра мониторинга, которая реализована у нас в Solar JSOC.
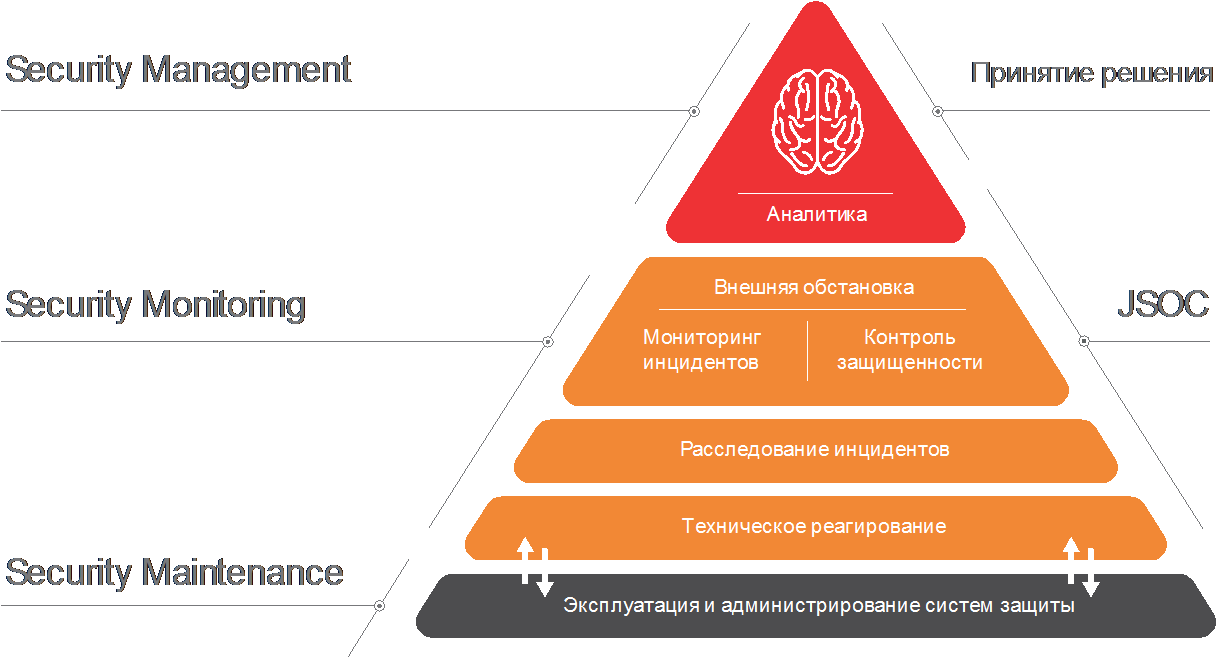
Помимо прочего, она позволит нам обсуждать эти различия в разрезе задач центра ГосСОПКА, в зону ответственности которого входят и индустриальные сегменты.
Подробности о каждом уровне модели модно найти в более ранних статьях про инвентаризацию инфраструктуры, мониторинг, Threat Intelligence (1, 2), контроль защищенности, кадровый состав и процессы. В текущем материале мы сконцентрируемся на центральном блоке Security Monitoring (особенности процессов реагирования и расследования в АСУ ТП будут в дальнейших статьях).
Кажется, что в области мониторинга событий, корреляции и выявления инцидентов все уже определено и известно. И даже преодоление воздушного зазора для сбора событий безопасности – тематика достаточно испытанная. Но, тем не менее, есть парочка нюансов, на которые однозначно стоит обратить внимание.
Общая архитектура SOC. Несмотря на, казалось бы, простое решение с воздушным зазором, ситуация для больших федеральных компаний с распределенными объектами (особенно это актуально для электроэнергетики), достаточно сложная. Количество объектов измеряется тысячами, зачастую на них даже нет возможности разместить сервер сбора событий, каждый из объектов достаточно компактен, но может генерировать значимые события информационной безопасности. Еще сверху на описанную ситуацию часто накладывается проблема каналов связи, настолько узких, что хоть сколько-то значимая нагрузка на передачу событий в «центр» начинает мешать работе основных приложений.
Поэтому как правильно разложить компоненты SIEM по площадкам – вопрос очень непраздный. К нему мы вернемся в одном из наших дальнейших материалов, посколькуполя данного дневника слишком малы чтобы вместить его для одной статьи информации будет слишком много.
Специализация и профилирование Use-Case. Даже не касаясь темы совершенно специализированных сценариев, актуальных только для сегмента АСУ ТП, стоит отметить, что даже стандартные инциденты в АСУ ТП имеют совершенно иное значение и критичность. Мы все давно уже привыкли к использованию утилит удаленного администрирования (Remote Admin Tools) в корпоративной сети. Но очевидно, что критичность такого инцидента, как и в принципе успешной связи с Интернетом в закрытой технологической сети, – огромна. То же самое касается установки новой системной службы на технологическом АРМ, факту выявления ВПО, который требует обязательного расследования и т.д.
Немалые ограничения в работу Use-Case вносят и ограничения на внедрение СЗИ (обычно технологические сегменты ими не очень богаты), и использование устаревших, legacy-версий операционных систем (да и на установку Sysmon технологи смотрят с недоверием).
И все же очень большой объем Use-Case корпоративной среды может успешно применяться к сегменту АСУ ТП и обеспечивать достаточно высокий уровень общего контроля инфраструктуры.
Ну и сложно пройти мимо святая святых – SCADA-систем. Если на уровне СЗИ, операционных систем и сетевых потоков все сегменты хоть немного, но похожи, то при движении вглубь возникают ключевые различия. В терминах корпоративных сетей и сегментов все грезят о бизнес-мониторинге и подключении бизнес-приложений. И процесс этот, хотя и сложный (логи мутируют и не хотят притворяться CEF, нормальная информация может быть получена только из базы, но администраторы ругаются и жалуются на спад быстродействия), но в целом реализуемый. В технологическом сегменте при подключении систем верхнего и среднего уровня эти проблемы возводятся в абсолют в связи с космической критичностью технологического простоя. Для того чтобы сделать первые шаги к подключению источника, нужно:
Грусть, тоска, бизнес-процессы. И это при том, что, как правило, оборудование АСУ ТП отличается достаточно емким, полным, понятным и качественным журналированием.
Но, к счастью (или по стечению обстоятельств), обычно в сегментах АСУ ТП может быть реализован другой подход. Большинство протоколов в них не подразумевают шифрования или маскирования передаваемой информации. Поэтому одним из частых подходов для мониторинга и разбора управляющих команд является внедрение индустриальных систем обнаружения вторжений или индустриальных межсетевых экранов, которые позволяют работать с копией или фактическим сетевым трафиком и разбирать протоколы и управляющие команды с последующим журналированием. Часть из них, в том числе, имеет внутри встроенный базовый корреляционный движок (избавляя нас от ужаса нормализации, категорирования и профилирования событий), но не являясь при этом полноценной заменой SIEM-системе.
Не трогай,
Двигаемся дальше. Казалось бы, вопросы инвентаризации в сети АСУ ТП должны быть наименее болезненными. Сеть достаточно статичная, оборудование изолированно от общих сегментов, внесение изменений в архитектуру требует целого рабочего проекта. Сказка относительно корпоративных сетей – «Просто фиксируй модель и заноси в CMDB». Но, как обычно, есть нюанс: для сегмента АСУ ТП появление любого нового оборудования – один из крайне важных признаков инцидента или атаки, и выявлять его надо в обязательном порядке. И при всем при этом классические способы инвентаризации (щадящие режимы работы сканеров уязвимостей) вызывают у технологов, да и у безопасников АСУ ТП сильнейшую аллергию. И в корпоративной сети не редки случаи, когда даже Inventory Scan в неудачном режиме в неудачное время мог «положить» какое-то специфическое приложение. В АСУ ТП такие риски никто на себя брать, естественно, не готов.
Поэтому основным инструментом инвентаризации в АСУ ТП (помимо ручного контроля) служат уже упомянутые ранее системы разбора сетевого трафика и индустриальные системы обнаружения вторжений. Каждый новый узел, появившись в сети, начинает коммуницировать с соседями. И способы, и протоколы коммуникации, специфика пакетов и служебных полей позволяют не только быстро увидеть нового «соседа», но и достаточно четко его идентифицировать.
Процесс выявления и управления уязвимостей, наоборот, более консервативный. Как правило, инфраструктура обновляется и патчится нечасто и очень контролируемо, список прикладного ПО и технологического оборудования зафиксирован. Поэтому для определения списка и состояния актуальных уязвимостей в сегменте АСУ ТП обычно достаточно определить версионность ключевого ПО и свериться с бюллетенями производителей. В итоге от режима агрессивного сканирования и проверки ПО мы уходим к методам технического и ручного аудита версионности и аналитике эксперта из отрасли.
Аналогичным образом строится процесс анализа или выявления угроз. Как правило разово зафиксированная модель модернизируются либо по факту критического перестроения инфраструктуры (добавления новых узлов, обновления версии прошивок критичного оборудования и т.д.), либо по факту выявления новой актуальной для инфраструктуры уязвимости и/или нового вектора атаки. Однако с ними тоже не все так просто.
OT Threat Intelligence или снятся ли изолированным сетям индикаторы компрометации
Может ли информация о новых угрозах и векторах атаки быть бесполезной? Хочется сразу ответить «нет», но давайте вместе попробуем поразбираться в применимости классических данных TI в зрелом OT сегменте.
Информация TI обычно представляют собой feeds (потоки данных) или IoC (индикаторы компрометации для выявления конкретной malware или хакерского инструментария). Они содержат следующие характеристики:
В итоге для атак, направленных на АСУ ТП, гораздо больший вес приобретает крайне редкая на рынке TI информация о TTP, тактиках и подходах злоумышленников к атаке, которая позволит соответствующим образом адаптировать защитные механизмы и подходы к мониторингу и выявлению угроз в сегменте.
Эти и многие другие нюансы заставляют очень серьезно и вдумчиво подходить к процессу построения такого SOC или выбору подрядчика, а также всерьез задуматься о стратегии формирования SOC OT. Должен ли он пересекаться с SOC IT или функционировать отдельно от него, возможно ли какое-то взаимообогащение и синергия в процессах, командах и решаемых задачах. В ближайшей нашей статье мы попробуем осветить разные подходы международных команд к этому вопросу. Будьте безопасны во всех аспектах своей инфраструктуры и жизни.

Чтобы разбор был предметным, сначала зафиксируем, что мы сравниваем SOC OT с той структурой центра мониторинга, которая реализована у нас в Solar JSOC.

Помимо прочего, она позволит нам обсуждать эти различия в разрезе задач центра ГосСОПКА, в зону ответственности которого входят и индустриальные сегменты.
Подробности о каждом уровне модели модно найти в более ранних статьях про инвентаризацию инфраструктуры, мониторинг, Threat Intelligence (1, 2), контроль защищенности, кадровый состав и процессы. В текущем материале мы сконцентрируемся на центральном блоке Security Monitoring (особенности процессов реагирования и расследования в АСУ ТП будут в дальнейших статьях).
Театр начинается с вешалки, а SOC — с мониторинга
Кажется, что в области мониторинга событий, корреляции и выявления инцидентов все уже определено и известно. И даже преодоление воздушного зазора для сбора событий безопасности – тематика достаточно испытанная. Но, тем не менее, есть парочка нюансов, на которые однозначно стоит обратить внимание.
Общая архитектура SOC. Несмотря на, казалось бы, простое решение с воздушным зазором, ситуация для больших федеральных компаний с распределенными объектами (особенно это актуально для электроэнергетики), достаточно сложная. Количество объектов измеряется тысячами, зачастую на них даже нет возможности разместить сервер сбора событий, каждый из объектов достаточно компактен, но может генерировать значимые события информационной безопасности. Еще сверху на описанную ситуацию часто накладывается проблема каналов связи, настолько узких, что хоть сколько-то значимая нагрузка на передачу событий в «центр» начинает мешать работе основных приложений.
Поэтому как правильно разложить компоненты SIEM по площадкам – вопрос очень непраздный. К нему мы вернемся в одном из наших дальнейших материалов, поскольку
Специализация и профилирование Use-Case. Даже не касаясь темы совершенно специализированных сценариев, актуальных только для сегмента АСУ ТП, стоит отметить, что даже стандартные инциденты в АСУ ТП имеют совершенно иное значение и критичность. Мы все давно уже привыкли к использованию утилит удаленного администрирования (Remote Admin Tools) в корпоративной сети. Но очевидно, что критичность такого инцидента, как и в принципе успешной связи с Интернетом в закрытой технологической сети, – огромна. То же самое касается установки новой системной службы на технологическом АРМ, факту выявления ВПО, который требует обязательного расследования и т.д.
Немалые ограничения в работу Use-Case вносят и ограничения на внедрение СЗИ (обычно технологические сегменты ими не очень богаты), и использование устаревших, legacy-версий операционных систем (да и на установку Sysmon технологи смотрят с недоверием).
И все же очень большой объем Use-Case корпоративной среды может успешно применяться к сегменту АСУ ТП и обеспечивать достаточно высокий уровень общего контроля инфраструктуры.
Ну и сложно пройти мимо святая святых – SCADA-систем. Если на уровне СЗИ, операционных систем и сетевых потоков все сегменты хоть немного, но похожи, то при движении вглубь возникают ключевые различия. В терминах корпоративных сетей и сегментов все грезят о бизнес-мониторинге и подключении бизнес-приложений. И процесс этот, хотя и сложный (логи мутируют и не хотят притворяться CEF, нормальная информация может быть получена только из базы, но администраторы ругаются и жалуются на спад быстродействия), но в целом реализуемый. В технологическом сегменте при подключении систем верхнего и среднего уровня эти проблемы возводятся в абсолют в связи с космической критичностью технологического простоя. Для того чтобы сделать первые шаги к подключению источника, нужно:
- Собрать стенд и проверить успешность получения событий
- Нарисовать общее архитектурное решение со всеми техническими подробностями
- Согласовать его за несколько месяцев с вендором
- Провериться еще раз на стенде заказчика с эмуляцией боевой нагрузки
- Очень осторожно (как в анекдоте про ежиков) внедрить решение в продуктив
Грусть, тоска, бизнес-процессы. И это при том, что, как правило, оборудование АСУ ТП отличается достаточно емким, полным, понятным и качественным журналированием.
Но, к счастью (или по стечению обстоятельств), обычно в сегментах АСУ ТП может быть реализован другой подход. Большинство протоколов в них не подразумевают шифрования или маскирования передаваемой информации. Поэтому одним из частых подходов для мониторинга и разбора управляющих команд является внедрение индустриальных систем обнаружения вторжений или индустриальных межсетевых экранов, которые позволяют работать с копией или фактическим сетевым трафиком и разбирать протоколы и управляющие команды с последующим журналированием. Часть из них, в том числе, имеет внутри встроенный базовый корреляционный движок (избавляя нас от ужаса нормализации, категорирования и профилирования событий), но не являясь при этом полноценной заменой SIEM-системе.
Не трогай, это на новый год АСУ ТП, или Особенности работы с хостами и уязвимостями в АСУ ТП
Двигаемся дальше. Казалось бы, вопросы инвентаризации в сети АСУ ТП должны быть наименее болезненными. Сеть достаточно статичная, оборудование изолированно от общих сегментов, внесение изменений в архитектуру требует целого рабочего проекта. Сказка относительно корпоративных сетей – «Просто фиксируй модель и заноси в CMDB». Но, как обычно, есть нюанс: для сегмента АСУ ТП появление любого нового оборудования – один из крайне важных признаков инцидента или атаки, и выявлять его надо в обязательном порядке. И при всем при этом классические способы инвентаризации (щадящие режимы работы сканеров уязвимостей) вызывают у технологов, да и у безопасников АСУ ТП сильнейшую аллергию. И в корпоративной сети не редки случаи, когда даже Inventory Scan в неудачном режиме в неудачное время мог «положить» какое-то специфическое приложение. В АСУ ТП такие риски никто на себя брать, естественно, не готов.
Поэтому основным инструментом инвентаризации в АСУ ТП (помимо ручного контроля) служат уже упомянутые ранее системы разбора сетевого трафика и индустриальные системы обнаружения вторжений. Каждый новый узел, появившись в сети, начинает коммуницировать с соседями. И способы, и протоколы коммуникации, специфика пакетов и служебных полей позволяют не только быстро увидеть нового «соседа», но и достаточно четко его идентифицировать.
Процесс выявления и управления уязвимостей, наоборот, более консервативный. Как правило, инфраструктура обновляется и патчится нечасто и очень контролируемо, список прикладного ПО и технологического оборудования зафиксирован. Поэтому для определения списка и состояния актуальных уязвимостей в сегменте АСУ ТП обычно достаточно определить версионность ключевого ПО и свериться с бюллетенями производителей. В итоге от режима агрессивного сканирования и проверки ПО мы уходим к методам технического и ручного аудита версионности и аналитике эксперта из отрасли.
Аналогичным образом строится процесс анализа или выявления угроз. Как правило разово зафиксированная модель модернизируются либо по факту критического перестроения инфраструктуры (добавления новых узлов, обновления версии прошивок критичного оборудования и т.д.), либо по факту выявления новой актуальной для инфраструктуры уязвимости и/или нового вектора атаки. Однако с ними тоже не все так просто.
OT Threat Intelligence или снятся ли изолированным сетям индикаторы компрометации
Может ли информация о новых угрозах и векторах атаки быть бесполезной? Хочется сразу ответить «нет», но давайте вместе попробуем поразбираться в применимости классических данных TI в зрелом OT сегменте.
Информация TI обычно представляют собой feeds (потоки данных) или IoC (индикаторы компрометации для выявления конкретной malware или хакерского инструментария). Они содержат следующие характеристики:
- Сетевые индикаторы (IP-адреса, URL, доменные имена), нацеленные на выявление взаимодействия злоумышленника с сетью интернет для upload «полезной» нагрузки на зараженный хост, компрометации данных через фишинг или связи бота с центром управления для передачи хоста под контроль злоумышленника. Если мы говорим о действительно изолированном сегменте, такие соединения по умолчанию будут неуспешны, и злоумышленники не получат контроль над потенциально зараженной машиной. Тем не менее, фиксация таких попыток и выявление пусть и не активированной, «шальной» вредоносной утилиты в критичном сегменте производства тоже очень важна.
- Индикаторы хостового уровня (MD5-сумма процесса, его название, изменяемые при установке/запуске ветки реестра и т.д.), нацеленные на выявление признаков активности злоумышленника на сервере/рабочей станции в процессе запуска/закрепления вредоносной утилиты. Опять же, при общей полезности информации в зрелом сегменте АСУ ТП шансов запуститься у такого рода утилиты немного. Антивирусное ПО, адаптированное под технологические процессы, как правило, функционирует даже не в режиме работы сигнатур, а в режиме whitelisting, по умолчанию вычищая все подозрительное, что оно встречает на подконтрольных ему хостах. И точно так же – важно фиксировать запуск «странных» утилит на хостах сегмента АСУ ТП. В данном случае TI используется как инструмент атрибуции вектора атаки и злоумышленника.
В итоге для атак, направленных на АСУ ТП, гораздо больший вес приобретает крайне редкая на рынке TI информация о TTP, тактиках и подходах злоумышленников к атаке, которая позволит соответствующим образом адаптировать защитные механизмы и подходы к мониторингу и выявлению угроз в сегменте.
Эти и многие другие нюансы заставляют очень серьезно и вдумчиво подходить к процессу построения такого SOC или выбору подрядчика, а также всерьез задуматься о стратегии формирования SOC OT. Должен ли он пересекаться с SOC IT или функционировать отдельно от него, возможно ли какое-то взаимообогащение и синергия в процессах, командах и решаемых задачах. В ближайшей нашей статье мы попробуем осветить разные подходы международных команд к этому вопросу. Будьте безопасны во всех аспектах своей инфраструктуры и жизни.
